关于 NLP 应用方向与深度训练的核心流程
文章目录
- 主流应用方向
- 核心流程(5步)
- 1.选定语言模型结构
- 2.收集标注数据
- 3.forward 正向传播
- 4.backward 反向传播
- 5.使用模型预测真实场景
主流应用方向
- 文本分类
- 文本匹配
- 序列标注
- 生成式任务
核心流程(5步)

基本流程实现的先后顺序(每一步都包含很多技术点):
1.选定语言模型结构
- 语言模型作用
判断那一句话相对更合理,相对不合理的会得到较底的分值,需要挑选成句概率分值最高的。 - 评价指标:PPL(Perplexity) 困惑度
- 评估一个语言模型在给定数据集上的预测效果
- PPL 值与成句概率成反比(PPL 越小,成句概率越高)
- 模型分类
- SLM 统计语言模型
ngram - NLM 神经语言模型(2003)
RNN(循环神经网络)
LSTM(RNN 进阶版)
CNN(卷积神经网络)
GRU - PLM 预训练语言模型(2018)
- 基于 Transformer 架构
- BERT(预训练模型)
生成式任务是逐词预测,bert 是预测缺失的词或者句子前后关系 - GPT
生成式模型 - 一系列类 bert 模型
- BERT(预训练模型)
- 基于 Transformer 架构
- LLM 大语言模型(2023)
GhatGPT
- SLM 统计语言模型
2.收集标注数据
- 样本数据
- 预测数据
3.forward 正向传播
- 模型超参数随机初始化
- 训练轮数:epoch_num
- 每次训练样本个数:batch_size
- 样本文本长度:window_size
- 学习率:lr
- 隐藏层:hidden_size
- 模型层数:layer_num
-
构建词表
load_vocab -
构建数据集
dataset -
模型组成
-
离散值连续化(可选)
- Padding(可选)
- 将不同长度的文本补齐或截断到统一长度
- 使得不同长度的文本可以放在同一个batch内运算
- 补齐所使用的token需要有对应的embedding向量
- embedding 层
- 作用:
- 将字符转为向量
将离散型的输入数据(如单词、类别等)映射到连续的向量空间中 - 核心
将离散值转化为向量
- 将字符转为向量
- 形状:[vocab_dim, hidden_size]
hidden_size 是embedding 的下一层模型的输入形状
- 作用:
- Padding(可选)
-
模型结构处理连续数据
-
pooling 池化层
embedding 结果要先转置后才能 pooling
embedding.transpose(1,2)- 作用
- 降低后续网络层的输入维度
- 缩减模型大小
-提高计算速度 - 提高鲁棒性,防止过拟合
- 分类
- 平均池化
- 最大池化
- 作用
-
全连接层
- 作用
- 将前面层提取到的特征进行组合和加权
- 参数可通过反向传播学习,适应不同数据和任务
- 提高模型的表示能力
- 更好地捕捉数据中的复杂模式和关系
- 通过堆叠多个全连接层,结合非线性激活函数,模型就可以学习更复杂的非线性映射
- 分类与回归
- 分类任务中
- 将特征映射到不同类别的概率分布上
- 方便模型对输入进行分类
- 回归任务中
生成连续值的预测
- 分类任务中
- 参数
- 权重(Weights)
- 是模型中每个神经元或连接的参数
- 权重矩阵定义了输入和输出之间的关系
- 偏置(Biases)
额外参数,与权重一起用于计算激活函数的输入
- 权重(Weights)
- 作用
-
激活函数(可选)
不会改变输入内容的形状- 作用
- 引入非线性变换
- 全连接层仅可线性变换
- 将激活函数结果传递给下一个全连接层,可在学习复杂任务时,更好的表达数据的抽象特征
- 约束输出范围
- 提高模型的数值稳定性
- 引入非线性变换
- 常用激活函数
- Sigmoid
- tanh
RNN 自带一个 tanh - Relu
可以防止梯度消失问题 - Gelu
- 作用
-
Normalization 归一化层(可选)
对输入数据进行归一化处理,使其具有零均值和单位方差,加速模型训练过程,提高模型稳定性和收敛速度
- 代码
from torch.nn import BatchNorm1d
self.bn1 = BatchNorm1d(50) - 分类
- 批量归一化 batch normalization
对每一层的向量求平均,再求标准差,之后进行公式计算,获得可训练参数- 样本与其他样本归一化,适合 cv
- 适合两张图片之间相似度评价
- 层归一化 layer normalization
纵向向量求平均,再求标准差,之后进行公式计算,获得可训练参数- 样本内进行归一化,适合 nlp
- 适合文本
- 批量归一化 batch normalization
- dropout 层(可选)
- 代码
from torch.nn import Dropout
self.dropout = Dropout(0.5) - 是一种常用的正则化技术
- 作用
- 减少神经网络的过拟合
- 提高模型的泛化能力
- 强制网络学习更加健壮和泛化的特征
- 减少神经元之间的依赖关系
- 使得网络更加鲁棒
- 在训练期间
- 随机“丢弃”一些神经元
以一定的概率(通常在0.2到0.5之间)随机地将隐藏单元的输出置为零 - 保持总体期望值不变
将其余值按比例进行缩放
- 随机“丢弃”一些神经元
- 在测试期间
Dropout不会应用,而是将所有神经元的输出乘以保留概率,以保持输出的期望值
- 作用
- 代码
-
-
获取预测值
-
计算 loss
是指预测值与样本真实值之间的loss计算。- 常见 loss 函数
- 均方差(MSE)
回归场景 - 交叉熵(Cross Entropy)
分类场景 - BCE 0/1损失
分类场景,一般输入为 sigmod 的输出 - 指数损失
- 对数损失
- Hinge损失
- 均方差(MSE)
- 常见 loss 函数
4.backward 反向传播
- Optimizer 优化器
-
Adam
- SGD 进阶版
- 在模型的权重没有收敛之前(没有训练到预期结果之前),不断循环计算,历史每轮的梯度都参与计算。
- 可无脑选择使用的优化器。是非常好的baseLine,一般出问题,不会因为adam 出问题。
- 特点

- 实现

- 一阶动量
历史 n 轮梯度差值 - 二阶动量
历史 n 轮梯度的平方差 - 避免由于一阶动量与二阶动量初始值为零向量,引起参数估计偏向于 0 的问题
- 一阶动量偏差修正
一阶动量历史累计值/(1-超参数 t 次方) - 二阶动量偏差修正
二阶动量历史累计值/(1-超参数 t 次方)
- 一阶动量偏差修正
- 权重更新
- 一阶动量
-
SGD
计算逻辑:新权重 = 旧权重 - 学习率 * 梯度
- optmi->梯度归零
optimizer.zero_grad() - loss->反向传播,计算梯度
loss.backward() - optim->更新权重
optimizer.step()
-
5.使用模型预测真实场景
经过前4步,得到训练好的模型,将模型投放到真实场景进行预测。
相关文章:
关于 NLP 应用方向与深度训练的核心流程
文章目录 主流应用方向核心流程(5步)1.选定语言模型结构2.收集标注数据3.forward 正向传播4.backward 反向传播5.使用模型预测真实场景 主流应用方向 文本分类文本匹配序列标注生成式任务 核心流程(5步) 基本流程实现的先后顺序…...

linux如何启用ipv6随机地址
简介 在 IPv6 中,临时随机地址(Temporary IPv6 Address)是一种为了提高隐私和安全而设计的功能。通常,默认的 IPv6 地址是基于设备的 MAC 地址生成的,容易导致跟踪和识别设备。启用临时 IPv6 地址可以避免这个问题&am…...

探索 Android DataBinding:实现数据与视图的完美融合
在 Android 开发中,数据与视图的交互一直是一个关键的问题。为了更好地实现数据的展示和更新,Google 推出了 DataBinding 库,它为开发者提供了一种简洁、高效的方式来处理数据与视图之间的绑定关系,大大提高了开发效率和代码的可读…...

Java 编码系列:线程基础与最佳实践
引言 在多任务处理和并发编程中,线程是不可或缺的一部分。Java 提供了丰富的线程管理和并发控制机制,使得开发者可以轻松地实现多线程应用。本文将深入探讨 Java 线程的基础知识,包括 Thread 类、Runnable 接口、Callable 接口以及线程的生命…...

《深度学习》—— ResNet 残差神经网络
文章目录 一、什么是ResNet?二、残差结构(Residual Structure)三、Batch Normalization(BN----批归一化) 一、什么是ResNet? ResNet 网络是在 2015年 由微软实验室中的何凯明等几位大神提出,斩获…...

针对考研的C语言学习(定制化快速掌握重点3)
1.数组常见错误 数组传参实际传递的是数组的起始地址,若在函数中改变数组内容,数组本身也会发生变化 #include<stdio.h> void change_ch(char* str) {str[0] H; } int main() {char ch[] "hello";change_ch(ch);printf("%s\n&q…...

pikachu XXE(XML外部实体注入)通关
靶场:pikachu 环境: 系统:Windows10 服务器:PHPstudy2018 靶场:pikachu 关卡提示说:这是一个接收xml数据的api 常用的Payload 回显 <?xml version"1.0"?> <!DOCTYPE foo [ <!ENTITY …...

shell脚本定时任务通知到钉钉
shell脚本定时任务通知到钉钉 1、背景 前两天看了一下定时任务,垃圾清理、日志相关、系统巡检这些,有的服务器运行就有问题,或者不运行,正好最近在做运维标准重制运维手册,顺便把自动化这块优化一下,所…...
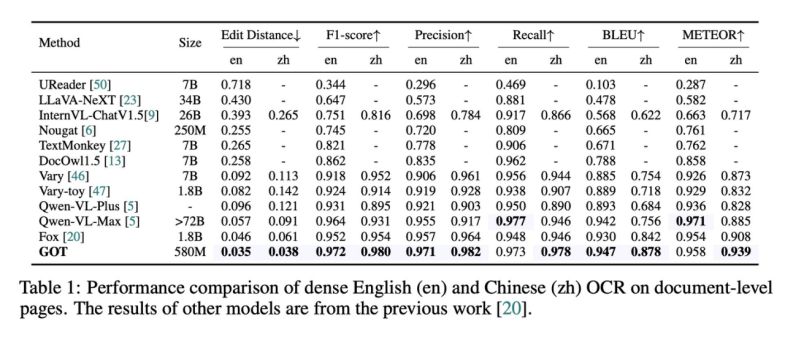
2.4K star的GOT-OCR2.0:端到端OCR 模型
GOT-OCR2.0是一款新一代的光学字符识别(OCR)技术,标志着人工智能在文本识别领域的重大进步。作为一款开源模型,GOT-OCR2.0不仅支持传统的文本和文档识别,还能够处理乐谱、图表以及复杂的数学公式,为用户提供…...

【JavaEE】——线程的安全问题和解决方式
阿华代码,不是逆风,就是我疯,你们的点赞收藏是我前进最大的动力!!希望本文内容能够帮助到你! 目录 一:问题引入 二:问题深入 1:举例说明 2:图解双线程计算…...

初步认识了解分布式系统
背景认识:我们要学习redis,还是得了解一下什么是分布式。为什么呢?因为redis只有在分布式系统中才能发挥它最大的作用,也就是领域展开,所以接下来我们就简单过一下什么是分布式系统 一些术语认识: &#x…...

react 为什么不能学习 vue3 进行静态节点标记优化性能?
因为 React 使用的是 JSX,而 JSX 本质上就是 JS 语言,是具有非常高的动态的,而 Vue 使用的 template 则是给了足够的约束,比如说 Vue 的 template 里面使用了很多特定的标记来做不同的事情,比如说 v-if 就是进行变量判…...

Elasticsearch黑窗口启动乱码问题解决方案
问题描述 elasticsearch启动后有乱码现象 解决方案: 提示:这里填写该问题的具体解决方案: 到 \config 文件下找到 jvm.options 文件 打开后 在文件末尾空白处 添加 -Dfile.encodingGBK 保存后重启即可。...

Logtus IT员工参加国际技术大会
Logtus IT的员工参加了国际技术大会,该大会致力于在金砖国家框架内开发俄罗斯的技术。该活动包括一个展览,俄罗斯开发商展示了他们的信息技术、电子和电信成就。展示了面向国内和国际市场(包括政府机构)的解决方案、产品和平台。 …...

ant design vue组件中table组件设置分组头部和固定总结栏
问题:遇到了个需求,不仅要设置分组的头部,还要在顶部有个统计总和的栏。 分组表头的配置主要是这个,就是套娃原理,不需要展示数据的直接写个title就行,需要展示数据的字段才需要详细的配置属性。 const co…...
2024年信息安全企业CRM选型与应用研究报告
数字化的生活给人们带来便利的同时也带来一定的信息安全隐患,如网络侵权、泄露用户隐私、黑客攻击等。在互联网高度发展的今天,信息安全与我们每个人、每个组织甚至每个国家都息息相关。 信息安全行业蓬勃发展。根据智研咨询数据,2021年&…...

【后端开发】JavaEE初阶——计算机是如何工作的???
前言: 🌟🌟本期讲解计算机工作原理,希望能帮到屏幕前的你。 🌈上期博客在这里:【MySQL】MySQL中JDBC编程——MySQL驱动包安装——(超详解) 🌈感兴趣的小伙伴看一看小编主…...
源码安装postgresql16.3)
Linux(Ubuntu)源码安装postgresql16.3
文章目录 Linux(Ubuntu)源码安装postgresql016.3下载程序包编译安装软件初次执行configure错误调试1:configure: error: ICU library not found再次执行configureBuild 设置环境初始化数据库启动数据库参考 Linux(Ubuntu)源码安装…...
面向对象 | 7.6、多态)
Python 入门教程(7)面向对象 | 7.6、多态
文章目录 一、多态1、鸭子类型2、实现多态的机制2.1、鸭子类型2.2、继承与重写 3、Python多态的优势4、总结 前言: 在面向对象编程(OOP)中,多态(Polymorphism)是一种非常重要的概念,多态就是同一…...

Cilium + ebpf 系列文章-什么是ebpf?(一)
前言: 这篇非常非常干,很有可能读不懂。 这里非常非常推荐,建议使用Cilium官网的lab来辅助学习!!!Resources Library - IsovalentExplore Isovalents Resource Library, your one-stop destination for ins…...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...

vscode里如何用git
打开vs终端执行如下: 1 初始化 Git 仓库(如果尚未初始化) git init 2 添加文件到 Git 仓库 git add . 3 使用 git commit 命令来提交你的更改。确保在提交时加上一个有用的消息。 git commit -m "备注信息" 4 …...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

剑指offer20_链表中环的入口节点
链表中环的入口节点 给定一个链表,若其中包含环,则输出环的入口节点。 若其中不包含环,则输出null。 数据范围 节点 val 值取值范围 [ 1 , 1000 ] [1,1000] [1,1000]。 节点 val 值各不相同。 链表长度 [ 0 , 500 ] [0,500] [0,500]。 …...

第25节 Node.js 断言测试
Node.js的assert模块主要用于编写程序的单元测试时使用,通过断言可以提早发现和排查出错误。 稳定性: 5 - 锁定 这个模块可用于应用的单元测试,通过 require(assert) 可以使用这个模块。 assert.fail(actual, expected, message, operator) 使用参数…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...

Android 之 kotlin 语言学习笔记三(Kotlin-Java 互操作)
参考官方文档:https://developer.android.google.cn/kotlin/interop?hlzh-cn 一、Java(供 Kotlin 使用) 1、不得使用硬关键字 不要使用 Kotlin 的任何硬关键字作为方法的名称 或字段。允许使用 Kotlin 的软关键字、修饰符关键字和特殊标识…...

SAP学习笔记 - 开发26 - 前端Fiori开发 OData V2 和 V4 的差异 (Deepseek整理)
上一章用到了V2 的概念,其实 Fiori当中还有 V4,咱们这一章来总结一下 V2 和 V4。 SAP学习笔记 - 开发25 - 前端Fiori开发 Remote OData Service(使用远端Odata服务),代理中间件(ui5-middleware-simpleproxy)-CSDN博客…...

基于TurtleBot3在Gazebo地图实现机器人远程控制
1. TurtleBot3环境配置 # 下载TurtleBot3核心包 mkdir -p ~/catkin_ws/src cd ~/catkin_ws/src git clone -b noetic-devel https://github.com/ROBOTIS-GIT/turtlebot3.git git clone -b noetic https://github.com/ROBOTIS-GIT/turtlebot3_msgs.git git clone -b noetic-dev…...

[大语言模型]在个人电脑上部署ollama 并进行管理,最后配置AI程序开发助手.
ollama官网: 下载 https://ollama.com/ 安装 查看可以使用的模型 https://ollama.com/search 例如 https://ollama.com/library/deepseek-r1/tags # deepseek-r1:7bollama pull deepseek-r1:7b改token数量为409622 16384 ollama命令说明 ollama serve #:…...