AIGC学习笔记—minimind详解+训练+推理
前言
这个开源项目是带我的一个导师,推荐我看的,记录一下整个过程,总结一下收获。这个项目的slogan是“大道至简”,确实很简。作者说是这个项目为了帮助初学者快速入门大语言模型(LLM),通过从零开始训练一个仅26MB的微型语言模型MiniMind,最快可在3小时内完成。降低学习LLM的门槛,让更多人能够轻松上手。
MiniMind极其轻量,约为GPT-3的1/7000,适合普通个人GPU进行快速推理和训练。项目基于DeepSeek-V2和Llama3结构,涵盖数据处理、预训练、指令微调(SFT)、偏好优化(DPO)等全部阶段,支持混合专家(MoE)模型。所有代码、数据集及其来源均公开,兼容主流框架,如transformers和DeepSpeed,支持单机单卡及多卡训练,并提供模型测试及OpenAI API接口。
下面放一个官方给的结果

一、使用conda搭建环境
这里不做过多赘述了,创建一个这个项目的独立虚拟环境,在这个环境下装所需的库,如下是我的软硬件环境配置(根据自己情况酌情变动):
- Windows11
- Python == 3.9
- Pytorch == 2.1.2
- CUDA == 11.8
- requirements.txt
二、准备数据集
下载到./dataset/目录下
| MiniMind训练数据集 | 下载地址 |
| tokenizer训练集 | HuggingFace / 百度网盘 |
| Pretrain数据 | Seq-Monkey官方 / 百度网盘 / HuggingFace |
| SFT数据 | 匠数大模型SFT数据集 |
| DPO数据 | Huggingface |
这里我就是用官方的了,后续我会打包整体的上传上去,免费下载,要不**某网盘还得冲svip,为了这个会员我差点叫了一声爸爸.....但是这里我想解释一下这个数据集,因为一开始我确实不了解,记录下来
Tokenizer训练集:这个数据集用于训练分词器(tokenizer),其任务是将文本数据转化为模型可以处理的词汇单元。
Pretrain数据:用于模型的预训练确保模型能够学习通用的语言模式。
SFT数据:该数据集专门用于指令微调(SFT),使模型能够更好地理解和执行用户的具体指令。SFT是提高模型实际应用能力的重要步骤。
DPO数据:这个数据集主要用于偏好优化(DPO),旨在帮助模型通过用户反馈来改进模型输出的质量和相关性,从而更好地满足用户需求。
三、训练tokenizer
话不多说先上代码,在记录一下我在看这个代码中了解的知识以及总结。
def train_tokenizer():# 读取JSONL文件并提取文本数据def read_texts_from_jsonl(file_path):with open(file_path, 'r', encoding='utf-8') as f:for line in f:data = json.loads(line)yield data['text']# 数据集路径data_path = './dataset/tokenizer/tokenizer_train.jsonl'# 初始化分词器(tokenizer),使用BPE模型tokenizer = Tokenizer(models.BPE())# 预处理为字节级别tokenizer.pre_tokenizer = pre_tokenizers.ByteLevel(add_prefix_space=False)# 定义特殊tokenspecial_tokens = ["<unk>", "<s>", "</s>"] # 未知token、开始token、结束token# 设置训练器并添加特殊tokentrainer = trainers.BpeTrainer(vocab_size=6400, # 词汇表大小special_tokens=special_tokens, # 确保这三个token被包含show_progress=True,# 初始化字母表initial_alphabet=pre_tokenizers.ByteLevel.alphabet())# 读取文本数据texts = read_texts_from_jsonl(data_path)print(texts)exit()# 训练tokenizertokenizer.train_from_iterator(texts, trainer=trainer)# 设置解码器tokenizer.decoder = decoders.ByteLevel()# 检查特殊token的索引assert tokenizer.token_to_id("<unk>") == 0assert tokenizer.token_to_id("<s>") == 1assert tokenizer.token_to_id("</s>") == 2# 保存tokenizertokenizer_dir = "./model/yzh_minimind_tokenizer"os.makedirs(tokenizer_dir, exist_ok=True)tokenizer.save(os.path.join(tokenizer_dir, "tokenizer.json")) # 保存tokenizer模型# 保存BPE模型tokenizer.model.save("./model/yzh_minimind_tokenizer")# 手动创建配置文件config = {"add_bos_token": False,"add_eos_token": False,"add_prefix_space": True,"added_tokens_decoder": {"0": {"content": "<unk>","lstrip": False,"normalized": False,"rstrip": False,"single_word": False,"special": True},"1": {"content": "<s>","lstrip": False,"normalized": False,"rstrip": False,"single_word": False,"special": True},"2": {"content": "</s>","lstrip": False,"normalized": False,"rstrip": False,"single_word": False,"special": True}},"additional_special_tokens": [],"bos_token": "<s>","clean_up_tokenization_spaces": False,"eos_token": "</s>","legacy": True,"model_max_length": 1000000000000000019884624838656,"pad_token": None,"sp_model_kwargs": {},"spaces_between_special_tokens": False,"tokenizer_class": "PreTrainedTokenizerFast","unk_token": "<unk>","use_default_system_prompt": False,"chat_template": "{% if messages[0]['role'] == 'system' %}{% set system_message = messages[0]['content'] %}{% endif %}{% if system_message is defined %}{{ system_message }}{% endif %}{% for message in messages %}{% set content = message['content'] %}{% if message['role'] == 'user' %}{{ '<s>user\\n' + content + '</s>\\n<s>assistant\\n' }}{% elif message['role'] == 'assistant' %}{{ content + '</s>' + '\\n' }}{% endif %}{% endfor %}"}# 保存配置文件with open(os.path.join(tokenizer_dir, "tokenizer_config.json"), "w", encoding="utf-8") as config_file:json.dump(config, config_file, ensure_ascii=False, indent=4)print("Tokenizer training completed and saved.")从代码上来看,分词器使用的是BPE模型Tokenizer(models.BPE()),这条代码就是初始化一个字节对编码(Byte Pair Encoding,BPE)分词器,直接使用库就可以,但是这里我建议同学们去了解一下BPE,这里我推荐一篇博客,供大家学习。BPE 算法原理及使用指南【深入浅出】-CSDN博客
小辉问:这里面有几个库的函数解释一下
gpt答:
相关文章:
AIGC学习笔记—minimind详解+训练+推理
前言 这个开源项目是带我的一个导师,推荐我看的,记录一下整个过程,总结一下收获。这个项目的slogan是“大道至简”,确实很简。作者说是这个项目为了帮助初学者快速入门大语言模型(LLM),通过从零…...

计算机毕业设计 在线项目管理与任务分配系统的设计与实现 Java实战项目 附源码+文档+视频讲解
博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌ 🍅文末获取源码联系🍅 👇🏻 精…...

小程序用户截屏事件
原生小程序: wx.setScreenBrightness({value: 0.5 }); 参数值: value屏幕亮度值,范围 0~1,0 最暗,1 最亮 uniapp: uni.setScreenBrightness({value: 0.5 }); 参数值: value屏幕亮度值&a…...

HashMap为什么线程不安全?如何实现线程安全
HashMap线程不安全的原因主要可以从以下几个方面解释: 1. 数据覆盖 假设两个线程同时执行put操作,并且它们操作的键产生相同的哈希码,导致它们应该被插入到同一个桶中。以下是可能发生的情况: 线程A读取桶位置为空,准…...

Python爬虫之requests模块(一)
Python爬虫之requests模块(一) 学完urllib之后对爬虫应该有一定的了解了,随后就来学习鼎鼎有名的requests模块吧。 一、requests简介。 1、什么是request模块? requests其实就是py原生的一个基于网络请求的模块,模拟…...

当微服务中调度返回大数据量时如何处理
FeignClient 和 Dubbo 可能不是最佳选择。以下是一些适合处理大数据量的技术和方法: 消息队列 简介:消息队列是一种异步通信方式,用于在不同系统之间传递消息。常见的消息队列包括 RabbitMQ、Kafka、ActiveMQ 等。 优点:消息队列…...
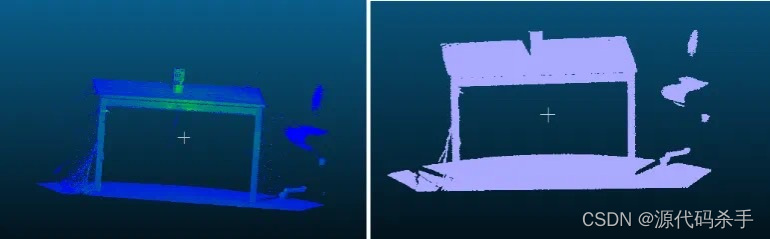
【项目经验分享】深度学习点云算法毕业设计项目案例定制
以下是深度学习与点云算法相关的毕业设计项目案例,涵盖了点云数据的分类、分割、重建、配准、目标检测等多个领域,适用于智能驾驶、机器人导航、3D建模等多个应用场景: 案例截图: 基于PointNet的3D点云分类与分割PointNet在大规…...

【Redis 源码】2项目结构说明
1 文件目录结构 deps 这个目录主要包含 Redis 所依赖的第三方代码库。 Jemalloc,内存分配器,默认情况下选择该内存分配器来代替 Linux 系统的 libc-malloc,libc-malloc 性能不高,且碎片化严重。hiredis,这是官方 C 语…...

RP2040 C SDK GPIO和IRQ 唤醒功能使用
RP2040 C SDK GPIO和中断功能使用 SIO介绍 手册27页: The Single-cycle IO block (SIO) contains several peripherals that require low-latency, deterministic access from the processors. It is accessed via each processor’s IOPORT: this is an auxiliary…...
@Transactional导致数据库连接数不够
在Spring中进行事务管理非常简单,只需要在方法上加上注解Transactional,Spring就可以自动帮我们进行事务的开启、提交、回滚操作。甚至很多人心里已经将Spring事务Transactional划上了等号,只要有数据库相关操作就直接给方法加上Transactiona…...

python3中的string 和bytes有什么区别
在Python中,string(字符串)和bytes(字节序列)是两种不同的数据类型,分别用于表示文本和二进制数据。它们的主要区别在于存储的数据类型、编码方式以及使用场景。 1. 存储数据类型 string (字符串,str):用来表示文本数据。string是一个Unicode字符串,其中的每个字符是…...

C~排序算法
在C/C中,有多种排序算法可供选择,每种算法都有其特定的应用场景和特点。下面介绍几种常用的排序算法,包括冒泡排序、选择排序、插入排序、快速排序、归并排序和堆排序,并给出相应的示例代码和解释。 冒泡排序(Bubble …...

基于github创建个人主页
基于github创建个人主页 站在巨人的肩膀上,首先选一个创建主页的仓库进行fork,具体可以参照这篇文章https://blog.csdn.net/qd1813100174/article/details/128604858主要总结下需要修改的地方: 1)仓库名字要和github的名字一致&a…...

apt update时出现证书相关问题,可以关闭apt验证
vi /etc/apt/apt.conf.d/99disable-signature-verification 添加以下内容: Acquire::AllowInsecureRepositories "true"; Acquire::AllowDowngradeToInsecureRepositories "true"; Acquire::AllowUnauthenticated "true"; 参考链…...
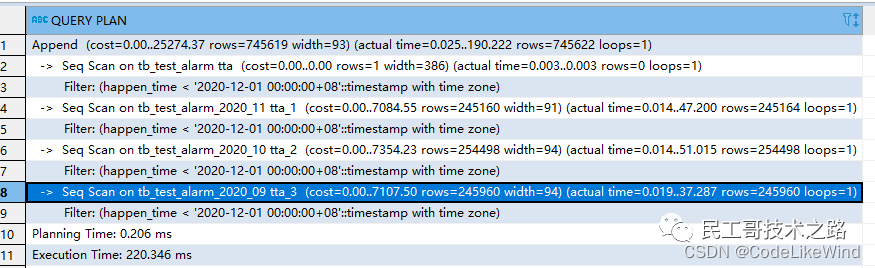
进阶数据库系列(十三):PostgreSQL 分区分表
概述 在组件开发迭代的过程中,随着使用时间的增加,数据库中的数据量也不断增加,因此数据库查询越来越慢。 通常加速数据库的方法很多,如添加特定的索引,将日志目录换到单独的磁盘分区,调整数据库引擎的参…...

翻译:Recent Event Camera Innovations: A Survey
摘要 基于事件的视觉受到人类视觉系统的启发,提供了变革性的功能,例如低延迟、高动态范围和降低功耗。本文对事件相机进行了全面的调查,并追溯了事件相机的发展历程。它介绍了事件相机的基本原理,将其与传统的帧相机进行了比较&am…...

车载诊断技术:汽车健康的守护者
一、车载诊断技术的发展历程 从最初简单的硬件设备到如今智能化、网络化的系统,车载诊断技术不断演进,为汽车安全和性能提供保障。 早期的汽车诊断检测技术处于比较原始的状态,主要依靠操作经验和主观评价。随着汽车工业的发展,车载诊断技术也经历了不同的阶段。20 世纪初…...

“天翼云息壤杯”高校AI大赛开启:国云的一场“造林”计划
文 | 智能相对论 作者 | 叶远风 2024年年初《政府工作报告》中明确提到了“人工智能”行动,人工智能的发展被提到前所未有的高度。 如何落实AI在数字经济发展中引擎作用,是业界当下面临的课题。 9月25日,“2024年中国国际信息通信展览会”…...

【怎样基于Okhttp3来实现各种各样的远程调用,表单、JSON、文件、文件流等待】
HTTP客户端工具 okhttp3 form/json/multipart 提供表达、json、混合表单、混合表单文件流传输等HTTP请求调用支持自定义配置默认客户端,参数列表如下: okhtt3.config.connectTimeout 连接超时,TimeUnit.SECONDSokhtt3.config.readTimeOut 读…...

excel统计分析(3): 一元线性回归分析
简介 用途:研究两个具有线性关系的变量之间的关系。 一元线性回归分析模型: ab参数由公式可得: 判定系数R2:评估回归模型的拟合效果。值越接近1,说明拟合效果越好;值越接近0,说明拟合效果越…...
)
Java 语言特性(面试系列1)
一、面向对象编程 1. 封装(Encapsulation) 定义:将数据(属性)和操作数据的方法绑定在一起,通过访问控制符(private、protected、public)隐藏内部实现细节。示例: public …...
)
进程地址空间(比特课总结)
一、进程地址空间 1. 环境变量 1 )⽤户级环境变量与系统级环境变量 全局属性:环境变量具有全局属性,会被⼦进程继承。例如当bash启动⼦进程时,环 境变量会⾃动传递给⼦进程。 本地变量限制:本地变量只在当前进程(ba…...

多模态商品数据接口:融合图像、语音与文字的下一代商品详情体验
一、多模态商品数据接口的技术架构 (一)多模态数据融合引擎 跨模态语义对齐 通过Transformer架构实现图像、语音、文字的语义关联。例如,当用户上传一张“蓝色连衣裙”的图片时,接口可自动提取图像中的颜色(RGB值&…...

华为OD机试-食堂供餐-二分法
import java.util.Arrays; import java.util.Scanner;public class DemoTest3 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint a in.nextIn…...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...

OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别
OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别 直接训练提示词嵌入向量的核心区别 您提到的代码: prompt_embedding = initial_embedding.clone().requires_grad_(True) optimizer = torch.optim.Adam([prompt_embedding...

代理篇12|深入理解 Vite中的Proxy接口代理配置
在前端开发中,常常会遇到 跨域请求接口 的情况。为了解决这个问题,Vite 和 Webpack 都提供了 proxy 代理功能,用于将本地开发请求转发到后端服务器。 什么是代理(proxy)? 代理是在开发过程中,前端项目通过开发服务器,将指定的请求“转发”到真实的后端服务器,从而绕…...

让回归模型不再被异常值“带跑偏“,MSE和Cauchy损失函数在噪声数据环境下的实战对比
在机器学习的回归分析中,损失函数的选择对模型性能具有决定性影响。均方误差(MSE)作为经典的损失函数,在处理干净数据时表现优异,但在面对包含异常值的噪声数据时,其对大误差的二次惩罚机制往往导致模型参数…...

深入浅出深度学习基础:从感知机到全连接神经网络的核心原理与应用
文章目录 前言一、感知机 (Perceptron)1.1 基础介绍1.1.1 感知机是什么?1.1.2 感知机的工作原理 1.2 感知机的简单应用:基本逻辑门1.2.1 逻辑与 (Logic AND)1.2.2 逻辑或 (Logic OR)1.2.3 逻辑与非 (Logic NAND) 1.3 感知机的实现1.3.1 简单实现 (基于阈…...

Java数值运算常见陷阱与规避方法
整数除法中的舍入问题 问题现象 当开发者预期进行浮点除法却误用整数除法时,会出现小数部分被截断的情况。典型错误模式如下: void process(int value) {double half = value / 2; // 整数除法导致截断// 使用half变量 }此时...