Hbase高阶知识:HBase的协处理器(Coprocessor)原理、使用实例、高级技巧和案例分析
目录
第一章 Hbase概述与基础知识
1.1 HBase的架构与数据模型
1.2 什么是协处理器
1.3 协处理器的优势
第二章 协处理器的工作原理
2.1 协处理器的运行机制
2.2 协处理器的注册与监听
2.3 协处理器与RegionServer的交互
第三章 协处理器的类型
3.1 端点协处理器
3.2 区域协处理器
3.3 区域协处理器的应用实例
3.3.1 数据校验
3.3.2 实时数据分析
第四章 协处理器的高级使用技巧
4.1 数据聚合与计算
4.1.1 数据过滤优化代码实例
4.2 实现自定义业务逻辑
4.3 性能优化技巧
第五章 使用场景与案例分析
5.1 数据校验场景
5.2 实时数据分析场景
5.3 复杂查询与分析场景
第一章 Hbase概述与基础知识
1.1 HBase的架构与数据模型
HBase,作为一个开源的、分布式的、可扩展的以及基于列的NoSQL数据库,已被广泛应用于存储大规模数据集。其架构设计和数据模型是理解HBase工作原理和性能特点的基础。
HBase的架构由多个关键组件构成,包括Client、Zookeeper、Master和RegionServer等。其中,Client负责与用户进行交互,接收用户的请求并返回结果;Zookeeper则负责协调和管理HBase集群中的各个组件,确保系统的高可用性;Master节点负责管理HBase表的元数据,以及RegionServer的负载均衡和故障恢复;而RegionServer则是实际存储数据的地方,它会处理来自Client的数据读写请求。
在数据模型方面,HBase采用了表(Table)、行(Row)、列族(Column Family)、列(Column)和单元格(Cell)的概念。与关系型数据库不同的是,HBase中的数据是按照列族进行物理存储的。每个表由多个行组成,每行都有一个唯一的行键(Rowkey)进行标识。而每个行又可以包含多个列族,每个列族下可以动态地添加或删除列。这种灵活的数据模型使得HBase能够轻松应对复杂多变的数据存储需求[2]。
HBase的列族设计对其性能有着重要影响。由于HBase中的数据是按照列族进行存储的,因此同一个列族中的数据会被存储在相邻的位置,这有利于提高数据访问的局部性。同时,HBase还支持对列族进行压缩和编码等优化操作,以进一步提高存储效率和查询性能[3]。
HBase的架构设计和数据模型共同决定了其高性能、高可扩展性和灵活多变的特点。这使得HBase成为处理大规模数据集的理想选择之一。,通过引入协处理器(Coprocessor)等机制来扩展HBase的功能和提高其查询性能就是其中的一个重要方向。
1.2 什么是协处理器
HBase协处理器,作为一种在服务器端运行的轻量级Java程序,为开发人员提供了一种强大的机制,允许他们在HBase的数据操作过程中插入自定义逻辑。这种能力使得开发人员可以在服务器端进行高效的数据处理,而不必将大量数据传输到客户端进行处理,从而大大降低了网络延迟并提高了整体处理效率。
协处理器的设计初衷是为了优化HBase的数据处理性能。在传统的客户端-服务器架构中,客户端负责发起数据请求,服务器则负责处理这些请求并返回结果。当涉及到大规模数据处理时,这种架构可能会因为网络传输的延迟而变得效率低下。协处理器的出现正是为了解决这个问题。通过在服务器端运行自定义的逻辑代码,协处理器可以减少客户端与服务器之间的数据交换次数,将数据处理的逻辑尽可能地靠近数据存储的位置,从而提高了数据处理的效率[9]。
HBase协处理器允许开发人员在数据读取(Get)或扫描(Scan)操作之前或之后执行自定义的代码。这些代码可以直接访问HBase的内部数据结构,并进行复杂的数据处理操作,如数据过滤、聚合计算等。这种能力使得协处理器在处理大规模数据时具有极高的灵活性和效率。
HBase协处理器还提供了观察者(Observer)和终端(Endpoint)两种类型的接口。观察者接口允许开发人员在数据修改操作(如Put、Delete)之前或之后执行自定义的代码,从而实现对数据变更的实时监控和处理。而终端接口则允许开发人员定义一些自定义的RPC服务,客户端可以通过调用这些服务来执行复杂的数据处理操作。
HBase协处理器是一种强大的服务器端编程机制,它允许开发人员在HBase的数据操作过程中插入自定义逻辑,从而优化数据处理性能并降低网络延迟。通过合理地使用协处理器,开发人员可以构建出更加高效、灵活的HBase应用。
虽然协处理器带来了很多好处,但在使用时也需要谨慎考虑其潜在的影响。例如,过度复杂的协处理器逻辑可能会增加服务器的处理负担,甚至导致性能下降。因此,在设计协处理器时,开发人员需要充分权衡其带来的好处与潜在的风险,并确保其逻辑代码的简洁性和高效性。同时,对于不需要实时处理或复杂逻辑的数据操作,仍然可以使用传统的客户端-服务器架构进行处理,以充分利用HBase的分布式存储和并行处理能力。
1.3 协处理器的优势
HBase协处理器作为一种在服务器端运行的轻量级Java程序,为HBase的数据处理带来了显著的优势。这些优势主要体现在减少网络延迟、增强功能以及提高性能三个方面。
减少网络延迟:在传统的数据库处理模式中,客户端需要向服务器发送请求,服务器处理后再将结果返回给客户端,这个过程涉及多次的网络传输,因此会产生较大的网络延迟。而HBase协处理器允许在服务器端直接处理数据,这意味着部分或全部的数据处理逻辑可以在服务器端完成,从而减少了客户端与服务器之间的数据传输次数。这种处理模式显著降低了网络延迟,提高了系统的响应速度。
增强功能:HBase协处理器的另一个重要优势是支持自定义逻辑。开发人员可以根据实际需求,在协处理器中编写特定的处理逻辑,从而在不修改HBase核心代码的情况下扩展其功能。这种灵活性使得HBase能够适应更多的应用场景,满足用户多样化的需求。例如,可以通过协处理器实现复杂的数据过滤、聚合操作,或者定义特定的数据访问控制策略等。
提高性能:通过在服务器端进行数据处理,HBase协处理器还可以减少数据处理的中间环节,从而提高整体性能。在传统的处理模式中,数据需要在客户端和服务器之间进行多次传输和转换,这不仅增加了网络负担,还降低了处理效率。而协处理器可以将部分处理逻辑移至服务器端执行,减少了数据传输和转换的次数,从而提高了处理性能。此外,协处理器还可以利用服务器端的计算资源进行优化,进一步提升数据处理的速度和效率。
HBase协处理器通过减少网络延迟、增强功能以及提高性能等方面的优势,为HBase的数据处理提供了强大的支持。这些优势使得HBase在处理大规模数据集时能够更加高效、灵活和可靠,满足了现代应用对数据存储和处理的高性能需求。
第二章 协处理器的工作原理
2.1 协处理器的运行机制
HBase协处理器作为独立的Java进程,与RegionServer紧密集成,共同运行在HBase的服务器端。这种设计使得协处理器能够深度介入HBase的数据处理流程,通过注册并监听特定的事件,实现在事件触发时执行开发人员定义的自定义逻辑。这些事件通常包括数据读取、数据写入、数据扫描等关键操作,而自定义逻辑则涵盖了数据过滤、数据校验、数据聚合等多种功能。
在协处理器的运行过程中,当其监听到某个注册的事件发生时,会立即触发相应的处理函数。这些处理函数是开发人员根据业务需求预先定义的,它们能够在服务器端直接对数据进行处理,从而避免了将数据传输到客户端再进行处理的网络开销。这种在数据源端进行数据处理的方式,显著减少了网络延迟,提高了数据处理的整体效率。
协处理器的运行机制还具有高度的灵活性和可扩展性。开发人员可以根据实际需求,为不同的表或列族定义不同的协处理器,以实现精细化的数据处理控制。同时,由于协处理器是基于Java编写的,因此可以充分利用Java丰富的库和工具,以及强大的跨平台能力,来构建功能强大且易于维护的数据处理逻辑。
HBase协处理器的运行机制是通过在服务器端注册并监听事件,触发并执行预定义的自定义逻辑,从而实现高效、灵活且可扩展的数据处理。这种机制不仅降低了网络延迟,提高了处理效率,还为HBase的功能增强和性能优化提供了强大的支持。
2.2 协处理器的注册与监听
在HBase中,协处理器的注册是启用其功能的首要步骤。这一过程可以通过两种主要方式实现:配置文件注册和API注册。配置文件注册通常是在HBase的配置文件hbase-site.xml中指定协处理器的相关信息,包括协处理器的类名、路径以及需要应用到的表或区域等。这种方式适用于在系统启动时就加载并激活协处理器的情况。而API注册则提供了更为灵活的方式,允许在运行时动态地添加、移除或更新协处理器。通过HBase提供的API,开发人员可以编程地控制协处理器的注册行为,从而更好地满足实际应用场景的需求。
注册完成后,协处理器便开始监听HBase中的特定事件。这些事件通常与HBase的数据操作密切相关,如Get、Put、Delete等。当这些事件发生时,协处理器会被触发并执行相应的回调函数。回调函数是协处理器中预定义的特定方法,用于处理不同类型的事件。例如,在Get操作中,协处理器可以通过回调函数对数据进行预处理或过滤,从而只返回满足特定条件的数据给客户端;在Put操作中,协处理器可以利用回调函数进行数据校验或转换,确保写入数据的正确性和一致性。
通过注册与监听机制,协处理器能够深度集成到HBase的数据处理流程中,为系统提供强大的扩展能力和灵活性。这种机制使得开发人员能够在不修改HBase核心代码的情况下,通过编写自定义的协处理器逻辑来优化数据操作、增强系统功能或实现特定的业务需求。同时,由于协处理器是在服务器端运行的轻量级Java程序,因此它能够充分利用服务器的计算资源,减少客户端与服务器之间的数据传输和处理延迟,从而提高整个系统的性能和响应速度。
协处理器的注册与监听是HBase中实现高效数据处理和功能扩展的关键机制之一。通过合理配置和编写协处理器逻辑,开发人员能够显著提升HBase系统的性能和灵活性,从而更好地满足大规模数据处理和分析的需求。
2.3 协处理器与RegionServer的交互
协处理器与RegionServer之间的交互是HBase协处理器工作机制中的核心环节,主要通过CoprocessorHost这一组件实现。CoprocessorHost作为RegionServer中负责协处理器管理的关键部分,承担着加载、卸载及调用协处理器的重要任务。
当RegionServer接收到来自客户端的请求时,它会根据这些请求的具体类型和所涉及的数据范围,决定是否需要调用相应的协处理器来处理。这种处理方式能够使得数据操作更加灵活高效,因为协处理器允许开发者在服务器端直接插入自定义的数据处理逻辑,从而减少了不必要的数据传输和网络延迟。
在协处理器与RegionServer的交互过程中,CoprocessorHost起到了桥梁和中介的作用。它不仅要负责加载和初始化协处理器,还要在适当的时候调用协处理器中定义的回调函数来处理特定的事件。这些回调函数是协处理器功能的具体实现,它们可以根据不同的业务需求来执行数据过滤、数据校验、数据聚合等操作。
CoprocessorHost还需要负责协处理器的生命周期管理,包括在协处理器完成任务后的卸载和资源回收等工作。这确保了HBase系统的稳定性和高效性,避免了因协处理器管理不当而引发的性能问题或资源泄漏。
协处理器与RegionServer的交互是HBase协处理器工作机制中的重要一环,它通过CoprocessorHost组件实现了协处理器的有效管理和高效调用,从而提升了HBase系统的整体性能和扩展性。这种交互方式不仅充分发挥了协处理器的优势,还为开发者提供了更加灵活和强大的数据处理能力。
在实际应用中,开发者可以通过配置文件或API来注册和配置协处理器,以便在HBase系统中实现特定的业务需求。同时,HBase也提供了丰富的API和工具来支持协处理器的开发和调试,使得开发者能够更加方便地利用协处理器的功能来优化和提升HBase系统的性能。随着HBase技术的不断发展和完善,协处理器将会在未来发挥更加重要的作用,为大规模数据处理和分析提供更加高效和灵活的解决方案。
第三章 协处理器的类型
3.1 端点协处理器
端点协处理器(Endpoint Coprocessor)是HBase协处理器的一种类型,其主要特点是通过远程过程调用(RPC)暴露自定义服务,允许客户端直接调用这些服务以执行特定的数据处理逻辑。这种机制为开发者提供了一种灵活且高效的方式,以在HBase服务器端扩展功能,而无需修改HBase的核心代码。
端点协处理器的使用场景广泛,例如,可以实现复杂的数据聚合、过滤或转换操作,这些操作在服务器端执行可以显著减少网络传输的数据量,从而提高整体性能。此外,端点协处理器还可以用于实现特定的业务逻辑,如数据验证、访问控制等。
在HBase中,开发者可以通过实现特定的接口来定义端点协处理器的行为。这些接口通常包括处理RPC请求的方法,以及定义返回给客户端的响应。一旦端点协处理器被部署到HBase集群中,客户端就可以通过RPC调用这些服务,以执行自定义的数据处理操作。
虽然端点协处理器提供了强大的功能扩展能力,但也需要谨慎使用。因为不当的使用可能会导致服务器端资源的过度消耗,甚至影响整个HBase集群的稳定性。因此,在设计和实现端点协处理器时,开发者需要充分考虑其性能影响和资源消耗,以确保其在实际环境中的可行性和可靠性。
总的来说,端点协处理器是HBase协处理器体系中的重要组成部分,它通过RPC暴露自定义服务的方式,为开发者提供了一种灵活且高效的功能扩展机制。通过合理利用端点协处理器,开发者可以进一步提升HBase的数据处理能力和业务适应性。
3.2 区域协处理器
区域协处理器(Region Coprocessor)是HBase协处理器的一种重要类型,它与HBase表的Region紧密关联,能够在服务器端对表上的操作进行拦截和处理。这种协处理器允许开发人员在不改变HBase核心代码的情况下,向Region级别的数据操作注入自定义逻辑,从而提供更为灵活和高效的数据处理能力。
区域协处理器的工作原理主要基于事件驱动模型。在HBase中,每个Region都负责维护一部分数据,并处理针对这部分数据的读写请求。当客户端发起数据操作请求时,这些请求会被路由到相应的Region进行处理。而区域协处理器则注册在这些Region上,通过监听特定的事件(如数据读取、写入、删除等),在事件触发时执行相应的回调函数。
这些回调函数是开发人员在协处理器中自定义的,它们可以包含各种复杂的数据处理逻辑,如数据过滤、数据校验、数据聚合以及访问控制等。当特定事件发生时,HBase会调用这些回调函数,从而执行开发人员定义的自定义逻辑。这种机制使得区域协处理器能够深入HBase的内部处理流程,实现更为精细和高效的数据控制。
与端点协处理器不同,区域协处理器主要关注于Region级别的数据操作。它们能够直接访问和操作Region中的数据,而无需通过RPC调用等额外开销。这使得区域协处理器在处理大量数据时具有更高的性能和更低的延迟。同时,由于它们与Region紧密关联,因此可以轻松地实现数据的分区处理和并行处理,从而进一步提高数据处理效率。
总的来说,区域协处理器是HBase中一种强大的扩展机制,它允许开发人员在服务器端对数据操作进行精细控制,提供更为高效和灵活的数据处理能力。通过合理地利用区域协处理器,开发人员可以优化HBase的性能和功能,满足各种复杂的应用需求。在实际应用中,区域协处理器被广泛应用于数据过滤、数据校验、访问控制以及复杂数据分析等场景,为HBase的广泛应用提供了有力支持。
-
关键方法
-
prePut(HTableInterface table, Put put, WALEdit edit, Durability durability):在执行 Put 操作之前被调用,用户可以在这里对 Put 对象进行修改、验证或执行其他预处理操作。例如,可以检查要插入的数据是否符合某些规则,如果不符合则可以抛出异常阻止数据插入。 -
postPut(HTableInterface table, Put put, WALEdit edit, Durability durability):在 Put 操作完成后被调用,可用于执行一些后续处理,如更新相关的索引表或记录操作日志等。 -
preGet(HTableInterface table, Get get, RegionCoprocessorEnvironment env):在执行 Get 操作之前调用,可用于对 Get 请求进行修改或添加额外的条件过滤。例如,可以根据用户的权限对 Get 请求进行限制,只返回用户有权访问的数据。 -
postGet(HTableInterface table, Get get, Result result, RegionCoprocessorEnvironment env):在 Get 操作完成后调用,可对查询结果进行进一步处理或分析。比如,可以对查询结果进行缓存或进行数据统计。
-
3.3 区域协处理器的应用实例
区域协处理器作为HBase功能扩展的重要手段,在实际应用中具有广泛的用途。以下将通过数据校验和实时数据分析两个具体实例,详细阐述区域协处理器的应用。
3.3.1 数据校验
在HBase中,数据的一致性和准确性是至关重要的。然而,随着数据规模的不断扩大,数据错误和异常的可能性也随之增加。为了确保数据的正确性,可以使用区域协处理器来实现数据校验功能。
可以编写一个自定义的区域协处理器,在数据写入(Put)操作发生时进行校验。协处理器可以定义一系列校验规则,如字段格式、数据范围、唯一性约束等,对写入的数据进行逐一检查。若数据不符合校验规则,协处理器将拒绝写入操作,并返回相应的错误信息给客户端。
通过这种方式,区域协处理器能够在数据写入HBase之前及时发现并纠正潜在的数据错误,从而确保数据的准确性和一致性。
3.3.2 实时数据分析
HBase作为大数据存储解决方案,经常需要应对实时数据分析的场景。区域协处理器在这方面同样能够发挥重要作用。
以实时计算数据表的聚合指标为例,如求和、平均值、最大值等。通常,这些聚合操作需要在大量数据上进行计算,如果将所有数据拉取到客户端进行计算,将会造成巨大的网络开销和计算延迟。而使用区域协处理器,可以将这些聚合操作下推到服务器端进行。
具体实现上,可以编写一个区域协处理器,在扫描(Scan)操作发生时进行聚合计算。协处理器会遍历指定范围内的数据,按照定义的聚合函数进行计算,并将结果返回给客户端。这样,客户端只需要接收聚合结果,而无需处理原始数据,大大降低了网络传输开销和计算复杂度。
通过区域协处理器的实时数据分析功能,可以更加高效地处理大规模数据集,满足实时性要求较高的数据分析场景。
区域协处理器在HBase中的应用实例涵盖了数据校验和实时数据分析等多个方面。这些实例充分展示了区域协处理器在扩展HBase功能、提升数据处理效率方面的强大能力。随着HBase技术的不断发展和完善,相信区域协处理器将在更多领域发挥其独特的优势。
第四章 协处理器的高级使用技巧
4.1 数据聚合与计算
在HBase中,数据的聚合与计算是常见的操作,尤其在面对大规模数据集时。传统的做法是将数据从HBase中读取出来,然后在客户端进行聚合和计算。然而,这种方法在处理大量数据时可能会遇到性能瓶颈,主要原因是数据传输的开销以及客户端处理能力的限制。
协处理器通过允许在服务器端执行自定义逻辑,为这类问题提供了一个高效的解决方案。具体而言,开发人员可以利用协处理器在服务器端直接进行数据的聚合与计算,从而避免了大量不必要的数据传输。这不仅降低了网络延迟,还提高了整体的处理效率。
RegionObserver是HBase协处理器中的一种重要类型,它允许开发人员对Region级别的操作进行拦截和处理。通过使用RegionObserver,我们可以在服务器端对多个Region的数据进行汇总和统计。例如,假设我们需要计算某个表中所有数据的总和,可以编写一个RegionObserver,在每个Region上执行部分聚合操作(如求和),然后将这些部分结果合并得到最终结果。
协处理器还支持更复杂的计算逻辑。通过结合使用端点协处理器和区域协处理器,我们可以在服务器端构建强大的数据处理流水线。例如,可以利用端点协处理器暴露一个RPC服务,允许客户端提交复杂的计算任务;然后,在服务器端通过区域协处理器对这些任务进行分解和执行,最后将计算结果返回给客户端。
4.1.1 数据过滤优化代码实例
在 RegionObserver 的 preGet 方法中,可以根据具体的业务需求对 Get 请求进行更精细的过滤。例如,假设我们有一个存储用户信息的 HBase 表,其中包含用户的年龄、性别等字段。如果我们只需要查询年龄大于 30 岁的男性用户的信息,可以在 preGet 方法中添加如下代码:
public boolean preGet(HTableInterface table, Get get, RegionCoprocessorEnvironment env) {FilterList filterList = new FilterList(FilterList.Operator.MUST_PASS_ALL);QualifierFilter ageFilter = new QualifierFilter(CompareOp.GREATER_OR_EQUAL, new BinaryComparator(Bytes.toBytes("age")));ValueFilter genderFilter = new ValueFilter(CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes("male")));filterList.addFilter(ageFilter);filterList.addFilter(genderFilter);get.setFilter(filterList);return true;
}
这样,在数据读取时就可以在服务器端直接对数据进行过滤,减少不必要的数据传输到客户端,提高查询效率。
4.2 实现自定义业务逻辑
在HBase中,协处理器为开发者提供了一个强大的工具,使他们能够在不改变HBase核心代码的前提下,实现各种自定义业务逻辑。这些业务逻辑可以涉及数据的校验、转换、加密等多个方面,大大增强了HBase的灵活性和可扩展性。
数据校验是一个重要的应用场景。在数据存储之前,通过协处理器对数据进行有效性检查,可以确保数据的准确性和一致性。例如,可以编写一个协处理器来验证输入数据的格式是否正确,或者检查数据是否满足某些业务规则。如果数据不符合要求,协处理器可以阻止其写入HBase,从而避免脏数据的产生。
数据转换也是协处理器的一个重要用途。在某些情况下,原始数据可能需要进行格式转换或数据清洗,以适应HBase的数据模型或满足特定的业务需求。通过协处理器,可以在数据写入之前对其进行必要的转换。例如,可以将日期字符串转换为统一的日期格式,或者将不同来源的数据进行标准化处理。
数据加密是另一个值得关注的场景。为了确保数据的安全性,有时需要对敏感数据进行加密处理。利用协处理器,可以在数据写入HBase之前对其进行加密,并在读取时进行解密。这种端到端的加密方式可以保护数据在传输和存储过程中的安全性,防止数据泄露和非法访问。
要实现这些自定义业务逻辑,开发人员需要编写相应的协处理器代码,并将其部署到HBase集群中。HBase提供了丰富的API和工具来支持协处理器的开发和部署。开发人员可以利用这些资源来创建功能强大的协处理器,以满足各种复杂的业务需求。
协处理器的设计和实现需要谨慎考虑性能和可扩展性。由于协处理器在服务器端运行,如果处理逻辑过于复杂或资源消耗过大,可能会对HBase集群的性能产生负面影响。因此,在开发协处理器时,应遵循最佳实践,确保代码的高效性和健壮性。
例如,对于存储用户密码的列,在数据插入时可以对密码进行加密存储,在数据查询时再进行解密。以下是一个简单的使用 Java 的加密库(如 Bouncy Castle)进行加密和解密的示例:
import org.bouncycastle.jce.provider.BouncyCastleProvider;
import javax.crypto.Cipher;
import javax.crypto.spec.SecretKeySpec;
import java.security.Security;public class EncryptionObserver extends RegionObserver {private static final String ALGORITHM = "AES";private static final byte[] SECRET_KEY = "mysecretkey12345".getBytes();static {Security.addProvider(new BouncyCastleProvider());}public boolean prePut(HTableInterface table, Put put, WALEdit edit, Durability durability) {byte[] passwordColumn = Bytes.toBytes("password");for (KeyValue kv : put.get("user".getBytes(), passwordColumn)) {// 加密密码byte[] encryptedPassword = encrypt(kv.getValue());kv.setValue(encryptedPassword);}return true;}public boolean postGet(HTableInterface table, Get get, Result result, RegionCoprocessorEnvironment env) {byte[] passwordColumn = Bytes.toBytes("password");for (KeyValue kv : result.get("user".getBytes(), passwordColumn)) {// 解密密码byte[] decryptedPassword = decrypt(kv.getValue());kv.setValue(decryptedPassword);}return true;}private byte[] encrypt(byte[] data) {try {Cipher cipher = Cipher.getInstance(ALGORITHM, "BC");SecretKeySpec key = new SecretKeySpec(SECRET_KEY, ALGORITHM);cipher.init(Cipher.ENCRYPT_MODE, key);return cipher.doFinal(data);} catch (Exception e) {e.printStackTrace();return null;}}private byte[] decrypt(byte[] data) {try {Cipher cipher = Cipher.getInstance(ALGORITHM, "BC");SecretKeySpec key = new SecretKeySpec(SECRET_KEY, ALGORITHM);cipher.init(Cipher.DECRYPT_MODE, key);return cipher.doFinal(data);} catch (Exception e) {e.printStackTrace();return null;}}
}4.3 性能优化技巧
在HBase协处理器的使用过程中,性能优化是一个不可忽视的环节。以下是一些建议的性能优化技巧,这些技巧有助于提升协处理器的执行效率,从而优化HBase集群的整体性能。
简化逻辑以减少计算负担是关键。协处理器中的自定义逻辑应尽量简洁高效,避免复杂的算法和冗长的计算过程。这是因为协处理器与RegionServer紧密集成,其执行效率直接影响到RegionServer的响应速度。因此,开发者在编写协处理器代码时,应充分考虑性能因素,尽量采用轻量级的数据结构和算法。
利用缓存机制提升数据访问速度也是一个有效的优化手段。HBase本身提供了丰富的缓存支持,协处理器可以充分利用这些缓存机制来减少数据访问的延迟。例如,对于经常访问的热点数据,可以将其缓存在内存中,以减少对磁盘的频繁访问。此外,还可以通过合理配置HBase的缓存参数,如块大小、缓存比例等,来进一步提升缓存效果。
例如,在一个经常需要查询某个用户最近一周活动记录的场景中,可以在 RegionObserver 的 postGet 方法中对查询结果进行缓存。如果后续在短时间内再次查询相同用户的最近一周活动记录,可以直接从缓存中获取结果,而不需要再次从 HBase 中读取数据。以下是一个简单的缓存实现示例(使用 Guava 的 Cache 库):
import com.google.common.cache.CacheBuilder;
import com.google.common.cache.CacheLoader;
import com.google.common.cache.LoadingCache;public class ActivityCacheObserver extends RegionObserver {private LoadingCache<String, Result> activityCache;public ActivityCacheObserver() {activityCache = CacheBuilder.newBuilder().maximumSize(1000) // 设置缓存最大容量.expireAfterWrite(10, TimeUnit.MINUTES) // 设置缓存过期时间为 10 分钟.build(new CacheLoader<String, Result>() {@Overridepublic Result load(String userId) throws Exception {// 从 HBase 中查询用户活动记录Get get = new Get(Bytes.toBytes(userId));get.addFamily(Bytes.toBytes("activity"));Result result = table.get(get);return result;}});}public boolean postGet(HTableInterface table, Get get, Result result, RegionCoprocessorEnvironment env) {byte[] userIdColumn = Bytes.toBytes("user_id");for (KeyValue kv : result.get("activity".getBytes(), userIdColumn)) {String userId = Bytes.toString(kv.getValue());// 将查询结果存入缓存activityCache.put(userId, result);}return true;}public Result getFromCache(String userId) {try {return activityCache.get(userId);} catch (ExecutionException e) {e.printStackTrace();return null;}}
}再者,发挥并行处理的优势以加速数据处理是提升协处理器性能的另一个重要途径。HBase作为一个分布式数据库,天生具备并行处理的能力。协处理器可以利用这一优势,将大规模的数据处理任务分解为多个小任务,并在多个RegionServer上并行执行。这种并行处理方式能够显著缩短数据处理的时间,提高整体的处理效率。为了实现这一点,开发者需要熟悉HBase的并行处理模型,并合理设计协处理器的任务划分和调度策略。
值得注意的是,持续优化和监控是保持高性能的关键。随着数据量的增长和业务需求的变化,HBase集群的性能可能会面临新的挑战。因此,开发者需要定期对协处理器的性能进行评估和调整,以确保其始终保持在最佳状态。同时,还应建立完善的监控机制,实时监控协处理器的运行情况和性能指标,以便及时发现并解决潜在的性能问题。
第五章 使用场景与案例分析
5.1 数据校验场景
在HBase的实际应用中,数据校验是一个重要的环节,它确保写入数据库的数据符合特定的规范和标准。通过使用RegionObserver协处理器,我们可以在数据写入之前对其进行有效的校验,从而保证数据的准确性和一致性。
RegionObserver协处理器允许我们拦截HBase的Put操作,这意味着每当有数据尝试写入数据库时,我们都可以自定义的校验逻辑进行检查。这种拦截机制为我们在服务器端执行数据校验提供了可能,避免了将校验逻辑放在客户端导致的网络延迟和性能瓶颈。
在校验过程中,我们可以根据业务需求定义各种校验规则。例如,我们可以检查写入的数据是否包含必要的字段、字段的格式是否正确、数据值是否在合理的范围内等。如果数据不符合这些规则,RegionObserver协处理器将有权拒绝该写入请求,并返回相应的错误信息给客户端。
通过RegionObserver协处理器进行数据校验还可以带来其他好处。例如,它可以减轻客户端的负担,因为客户端无需再执行复杂的校验逻辑;同时,它也可以提高数据库的安全性,因为恶意的数据写入请求将在服务器端被及时拦截和处理。
为了更有效地实现数据校验功能,我们可以结合HBase的其他特性,如使用过滤器(Filter)来进一步筛选和验证数据。过滤器允许我们在服务器端对数据进行更细粒度的控制,从而提高数据校验的准确性和效率。
例如,假设我们的系统中有不同级别的用户,普通用户只能查询和插入自己的相关数据,管理员用户可以查询和插入所有数据。我们可以在协处理器中根据用户的身份信息进行权限验证:
public boolean preGet(HTableInterface table, Get get, RegionCoprocessorEnvironment env) {// 获取当前用户身份信息(假设通过某种认证机制获取)User user = env.getUser();if (user.isAdmin()) {// 管理员用户,允许查询所有数据return true;} else {// 普通用户,添加过滤条件只查询自己的数据byte[] userIdColumn = Bytes.toBytes("user_id");byte[] currentUserId = user.getUserId();SingleColumnValueFilter filter = new SingleColumnValueFilter("data".getBytes(), userIdColumn, CompareOp.EQUAL, currentUserId);get.setFilter(filter);return true;}
}public boolean prePut(HTableInterface table, Put put, WALEdit edit, Durability durability) {// 获取当前用户身份信息User user = env.getUser();if (user.isAdmin()) {// 管理员用户,允许插入数据return true;} else {// 普通用户,检查插入数据的用户 ID 是否与当前用户一致byte[] userIdColumn = Bytes.toBytes("user_id");for (KeyValue kv : put.get("data".getBytes(), userIdColumn)) {byte[] insertedUserId = kv.getValue();if (!Bytes.equals(insertedUserId, user.getUserId())) {throw new SecurityException("普通用户无权插入其他用户的数据");}}return true;}
}5.2 实时数据分析场景
在物联网(IoT)的广阔应用场景中,实时数据分析已成为不可或缺的一环。随着智能设备数量的激增,这些设备不断生成海量的数据,如何对这些数据进行高效、实时的分析处理,提取有价值的信息,成为了一个亟待解决的问题。HBase协处理器,特别是RegionObserver类型,为这一挑战提供了有力的技术支撑。
RegionObserver协处理器能够监听HBase中的Get操作,这意味着每当有数据查询请求时,协处理器都会被触发。利用这一特性,我们可以在服务器端对查询结果进行实时的数据分析和处理。这种处理方式的优势在于,它减少了数据传输的延迟,因为所有的计算和分析工作都在数据所在的服务器端完成,避免了大量数据在客户端和服务器之间的往返传输。
以物联网中的温度传感器数据为例,假设我们有一个HBase表,其中存储了各个传感器在不同时间点采集的温度数据。现在,我们想要获取某个特定时间段内所有传感器的平均温度、最高温度以及最低温度。如果没有协处理器的支持,我们可能需要先从HBase表中检索出该时间段内的所有数据,然后在客户端进行复杂的计算和分析。然而,这种方式不仅效率低下,而且随着数据量的增长,网络传输和客户端计算的负担也会变得越来越重。
通过引入RegionObserver协处理器,我们可以将这部分计算和分析工作转移到服务器端进行。具体来说,我们可以编写一个自定义的RegionObserver协处理器,在其中实现温度数据的聚合计算逻辑。当HBase接收到一个查询某个时间段内温度数据的Get请求时,RegionObserver协处理器会被触发,并直接在服务器端对该时间段内的数据进行扫描、聚合和计算。计算完成后,协处理器只需将最终的结果(如平均温度、最高温度和最低温度)返回给客户端即可。
这种方式不仅大大减少了网络传输的数据量,还充分利用了HBase集群的计算资源,从而实现了高效、实时的数据分析。此外,由于所有的计算逻辑都封装在协处理器中,因此这种解决方案还具有良好的可扩展性和可维护性。我们可以根据实际需求灵活地调整协处理器的计算逻辑,以适应不同的数据分析场景。
5.3 复杂查询与分析场景
在处理大规模数据集时,复杂的查询和分析操作变得尤为关键。HBase协处理器,特别是RegionObserver类型,为这类操作提供了强大的支持。通过在服务器端进行数据过滤、聚合和计算,协处理器显著减少了数据传输量,从而提高了整体的处理效率。
以数据排序为例,当客户端发起一个包含排序需求的查询请求时,如果直接在客户端进行排序,那么需要先将大量的数据从服务器端拉取到客户端,这无疑会增加网络传输的负担和延迟。而通过使用RegionObserver协处理器,我们可以在服务器端就对数据进行排序操作。这样,只有排序后的结果集会被返回给客户端,大大减少了网络传输的数据量。
分组和统计操作也可以在服务器端通过协处理器高效地完成。比如,在进行数据分析时,我们可能需要按照某个特定的字段对数据进行分组,并计算每组的统计信息(如平均值、最大值、最小值等)。借助RegionObserver协处理器,我们可以在数据被查询的同时,直接在服务器端完成这些分组和统计操作,从而避免了大量不必要的数据传输和处理。
除了上述的排序、分组和统计操作外,协处理器还可以支持更复杂的查询逻辑。例如,我们可以使用协处理器实现基于多个字段的复合查询,或者在查询过程中动态地应用数据过滤条件。这些高级功能使得HBase在处理大规模数据集时更加灵活和高效。
总的来说,通过利用HBase协处理器在服务器端进行数据过滤、聚合和计算等操作,我们可以有效地应对复杂查询与分析场景中的挑战。这不仅提高了数据处理的效率,还降低了网络传输的成本,为大规模数据集的高效处理提供了有力的支持。
相关文章:
原理、使用实例、高级技巧和案例分析)
Hbase高阶知识:HBase的协处理器(Coprocessor)原理、使用实例、高级技巧和案例分析
目录 第一章 Hbase概述与基础知识 1.1 HBase的架构与数据模型 1.2 什么是协处理器 1.3 协处理器的优势 第二章 协处理器的工作原理 2.1 协处理器的运行机制 2.2 协处理器的注册与监听 2.3 协处理器与RegionServer的交互 第三章 协处理器的类型 3.1 端点协处理器 3.2…...

海尔嵌入式硬件校招面试题及参考答案
使用 QT 的经验及对控件和信号与槽机制的了解 我使用 QT 有一段时间了,在项目开发中积累了较为丰富的经验。 QT 中的控件丰富多样,涵盖了各种常见的界面元素需求。例如按钮、文本框、列表框、进度条等。这些控件具有良好的可定制性,可以通过属性设置、样式表等方式来调整外观…...
贪心算法)
Leetcode基础算法篇|202409(4)贪心算法
贪心算法(Greedy Algorithm):一种在每次决策时,总是采取在当前状态下的最好选择,从而希望导致结果是最好或最优的算法。 学习链接:leetcode-notes/docs/ch04/04.04/04.04.02-Exercises.md at main datawha…...

echarts 导出pdf空白原因
问题阐述 页面样式: 导出pdf: 导出pdf,统计图部分为空白。 问题原因 由于代码中进行了dom字符串的复制,而echarts用canvas绘制,canvas内部内容不会进行复制,只会复制canvas节点,因此导出pdf空白。 解决…...

数据结构及基本算法
目录 第一章 概论 第一节 引言 第二节 基本概念和常用术语 第三节 算法的描述与分析 第二章 线性表 第一节 线性表定义和基本运算个 一、线性表的逻辑定义 二、线性表的基本运算 第二节 线性表的顺序存储和基本运算的实现 一、线性表的顺序存储 二、顺序表上基本运算…...

vue3学习记录-computed
vue3学习记录-computed 1.为什么要用computed2.使用方法2.1 基本实例2.2 可写计算属性 1.为什么要用computed 写个购物车的案例 <script setup> import { ref, reactive,computed } from "vue" const tableData reactive([{ name: 商品1, price: 10, num: 1…...

SQLite3模块使用详解
目录 一、引言 1.1 SQLite3 简介 1.2 Python sqlite3 模块 二、连接数据库 2.1 导入 sqlite3 模块 2.2 连接数据库 2.3 创建游标对象 三、执行 SQL 语句 3.1 创建表 3.2 插入数据 3.3 查询数据 3.4 更新数据 3.5 删除数据 四、处理查询结果 4.1 fetchall() 4.2…...

防火墙详解(三)华为防火墙基础安全策略配置(命令行配置)
实验要求 根据实验要求配置防火墙: 合理部署防火墙安全策略以及安全区域实现内网用户可以访问外网用户,反之不能访问内网用户和外网用户均可以访问公司服务器 实验配置 步骤一:配置各个终端、防火墙端口IP地址 终端以服务器为例ÿ…...

假期学习--iOS中的static关键字
iOS中的static关键字 OC的static关键字 OC也提供了Static关键字,但是这个static关键字不能用于修饰成员变量,也就是说Static是不被允许修饰实例变量,同时Static关键字也不被允许修饰方法。Static关键字可以修饰全局变量,局部变量…...

Maya没有Arnold材质球
MAYA 没有Arnold材质球_哔哩哔哩_bilibili...

面试知识点总结篇三
一、arm中断流程和函数 ARM 中断流程 中断触发保存上下文中断向量表执行ISR - 清除中断标志恢复上下文返回中断 二、STM32任务间通信有哪些方式 消息队列、 信号量、共享内存、任务通知 三、uboot内存没驱动之前是怎么操作的 硬件初始化内存检测设置内存映射控制台初始化…...

数据加密标准(DES)详解:原理、步骤及Python实现
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「storm…...

每日OJ_牛客_OR59字符串中找出连续最长的数字串_双指针_C++_Java
目录 牛客_OR59字符串中找出连续最长的数字串 题目解析 C代码1 C代码2 C代码3 Java代码 牛客_OR59字符串中找出连续最长的数字串 字符串中找出连续最长的数字串_牛客题霸_牛客网 题目解析 双指针: 遍历整个字符串,遇到数字的时候,用双…...
虚幻引擎UE5如何云渲染,教程来了
步骤一:获取云渲染权限 访问渲染101官网,使用云渲码6666进行注册。 下载并安装渲染客户端。 步骤二:设置渲染环境 确保云渲染环境与您的本地环境一致,避免出错。 步骤三:任务提交 完成环境配置后,解析…...

使用Python实现图形学光照和着色的光线追踪算法
目录 使用Python实现图形学光照和着色的光线追踪算法引言1. 光线追踪算法概述2. Python实现光线追踪算法2.1 向量类2.2 光源类2.3 材质类2.4 物体类2.5 光线追踪器类2.6 使用示例 3. 实例分析4. 光线追踪算法的优缺点4.1 优点4.2 缺点 5. 改进方向6. 应用场景结论 使用Python实…...

通过openAI的Chat Completions API实现一个支持追问的ChatGPT功能集成
文章目录 前言准备工作代码实现思路完整代码实现备注前言 本文介绍如何通过openAI的Chat Completions API实现一个支持追问的后台功能,追问打个比方,就是当你问了一句”窗前明月光的下一句是什么?“之后,想再往下问就可以直接问”再下一句呢?“,模型也能基于上下文理解你…...

8,STM32CubeMX配置SPI工程(读取norflash的ID)
1,前言 单片机型号:STM32F407 编程环境 :STM32CubeMX Keil v5 硬件连接 :SPI1,CS/SS--->PB14 注:本工程在1,STM32CubeMX工程基础(配置Debug、时钟树)基础上完…...

【MATLAB源码-第178期】基于matlab的8PSK调制解调系统频偏估计及补偿算法仿真,对比补偿前后的星座图误码率。
操作环境: MATLAB 2022a 1、算法描述 在通信系统中,频率偏移是一种常见的问题,它会导致接收到的信号频率与发送信号的频率不完全匹配,进而影响通信质量。在调制技术中,QPSK(Quadrature Phase Shift Keyi…...

AIGC学习笔记—minimind详解+训练+推理
前言 这个开源项目是带我的一个导师,推荐我看的,记录一下整个过程,总结一下收获。这个项目的slogan是“大道至简”,确实很简。作者说是这个项目为了帮助初学者快速入门大语言模型(LLM),通过从零…...

计算机毕业设计 在线项目管理与任务分配系统的设计与实现 Java实战项目 附源码+文档+视频讲解
博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌ 🍅文末获取源码联系🍅 👇🏻 精…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

1.3 VSCode安装与环境配置
进入网址Visual Studio Code - Code Editing. Redefined下载.deb文件,然后打开终端,进入下载文件夹,键入命令 sudo dpkg -i code_1.100.3-1748872405_amd64.deb 在终端键入命令code即启动vscode 需要安装插件列表 1.Chinese简化 2.ros …...

SpringCloudGateway 自定义局部过滤器
场景: 将所有请求转化为同一路径请求(方便穿网配置)在请求头内标识原来路径,然后在将请求分发给不同服务 AllToOneGatewayFilterFactory import lombok.Getter; import lombok.Setter; import lombok.extern.slf4j.Slf4j; impor…...
:邮件营销与用户参与度的关键指标优化指南)
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南 在数字化营销时代,邮件列表效度、用户参与度和网站性能等指标往往决定着创业公司的增长成败。今天,我们将深入解析邮件打开率、网站可用性、页面参与时…...

人工智能(大型语言模型 LLMs)对不同学科的影响以及由此产生的新学习方式
今天是关于AI如何在教学中增强学生的学习体验,我把重要信息标红了。人文学科的价值被低估了 ⬇️ 转型与必要性 人工智能正在深刻地改变教育,这并非炒作,而是已经发生的巨大变革。教育机构和教育者不能忽视它,试图简单地禁止学生使…...
【C++特殊工具与技术】优化内存分配(一):C++中的内存分配
目录 一、C 内存的基本概念 1.1 内存的物理与逻辑结构 1.2 C 程序的内存区域划分 二、栈内存分配 2.1 栈内存的特点 2.2 栈内存分配示例 三、堆内存分配 3.1 new和delete操作符 4.2 内存泄漏与悬空指针问题 4.3 new和delete的重载 四、智能指针…...

站群服务器的应用场景都有哪些?
站群服务器主要是为了多个网站的托管和管理所设计的,可以通过集中管理和高效资源的分配,来支持多个独立的网站同时运行,让每一个网站都可以分配到独立的IP地址,避免出现IP关联的风险,用户还可以通过控制面板进行管理功…...

【p2p、分布式,区块链笔记 MESH】Bluetooth蓝牙通信 BLE Mesh协议的拓扑结构 定向转发机制
目录 节点的功能承载层(GATT/Adv)局限性: 拓扑关系定向转发机制定向转发意义 CG 节点的功能 节点的功能由节点支持的特性和功能决定。所有节点都能够发送和接收网格消息。节点还可以选择支持一个或多个附加功能,如 Configuration …...
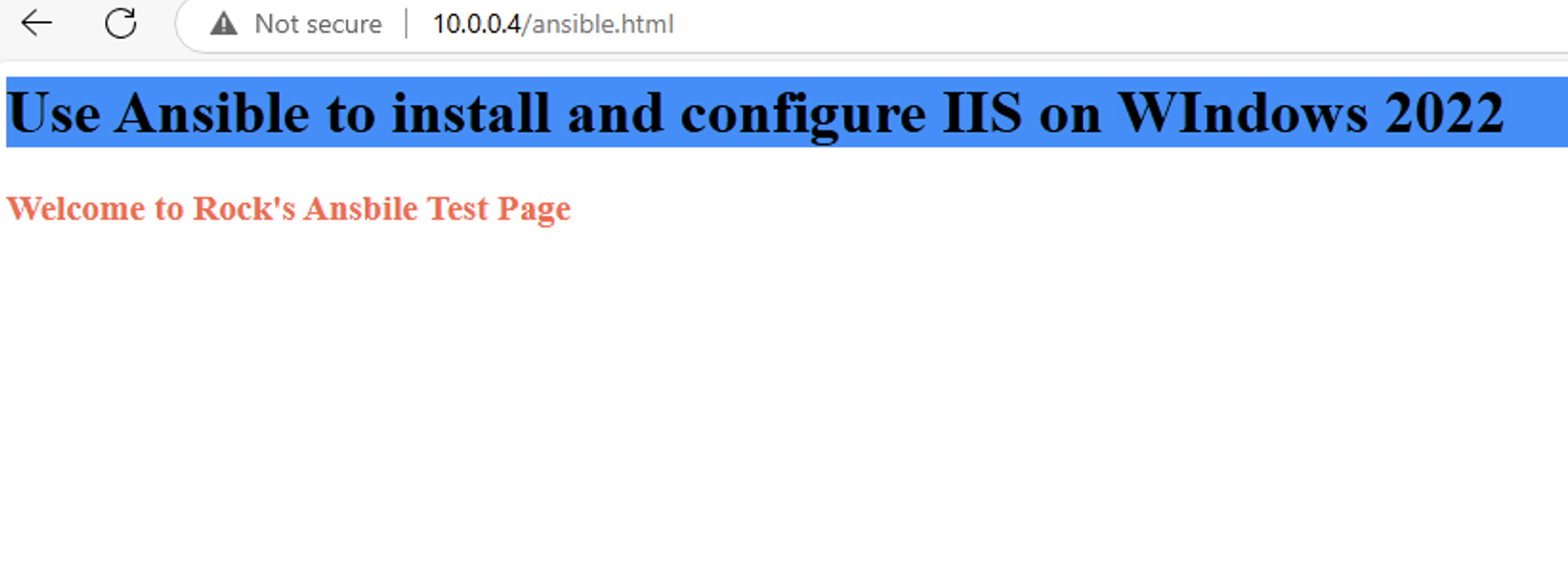
通过 Ansible 在 Windows 2022 上安装 IIS Web 服务器
拓扑结构 这是一个用于通过 Ansible 部署 IIS Web 服务器的实验室拓扑。 前提条件: 在被管理的节点上安装WinRm 准备一张自签名的证书 开放防火墙入站tcp 5985 5986端口 准备自签名证书 PS C:\Users\azureuser> $cert New-SelfSignedCertificate -DnsName &…...