深入理解MySQL InnoDB中的B+索引机制
目录
一、InnoDB中的B+ 树索引介绍
二、聚簇索引
(一)使用记录主键值的大小进行排序
页内记录排序
页之间的排序
目录项页的排序
(二)叶子节点存储完整的用户记录
数据即索引
自动创建
(三)聚簇索引的优缺点
三、二级索引
(一)二级索引的特点
基于非主键列排序
叶子节点存储部分数据
(二)二级索引的工作流程
(三)二级索引的优缺点
四、联合索引
(一)联合索引的特点
多列排序规则
联合索引的组成
(二)联合索引与单列索引的区别
联合索引
单列索引
(三)联合索引的优缺点
(四)联合索引的使用建议
五、总结
参考文献、书籍及链接
干货分享,感谢您的阅读!
在现代数据库系统中,索引是提高数据检索速度的关键机制之一。InnoDB作为MySQL的默认存储引擎,采用了高效的B+树结构来实现其索引功能。这种结构不仅确保了数据的快速检索,还支持高效的插入、更新和删除操作。理解InnoDB中的B+树索引对于数据库优化和性能调优至关重要。
为了更好地理解 InnoDB 中 B+ 树索引的工作机制,我们从创建一个示例表index_demo开始,并通过详细的示意图展示记录在页中的存储结构及索引的作用。
CREATE TABLE index_demo (c1 INT,c2 INT,c3 CHAR(1),PRIMARY KEY (c1)
) ROW_FORMAT = Compact;
这个表中有两个 INT 类型的列 c1 和 c2,一个 CHAR(1) 类型的列 c3,并且 c1 列为主键。表的行格式为 Compact。其基础可见:
一、InnoDB中的B+ 树索引介绍
B+ 树索引是一种自平衡的树结构,其节点分为内部节点和叶子节点:
- 内部节点(Internal Nodes):用于索引导航,存储键值和指向子节点的指针。
- 叶子节点(Leaf Nodes):存储实际的数据记录或指向数据记录的指针(称为记录指针)。
在 B+ 树中,所有的数据记录都存储在叶子节点中,而内部节点仅用于存储键值和导航信息。

不论是存放用户记录的数据页,还是存放目录项记录的数据页,我们都把它们存放到B+树这个数据结构中,所以我们也称这些数据页为节点。
从图中可以看出来,我们的实际用户记录都存放在B+树的最底层的节点上,这些节点也被称为叶子节点或叶节点,其余用来存放目录项的节点称为非叶子节点或者内节点,其中B+树最上面的那个节点也称为根节点。
依据InnoDB存储引擎B+树的树高推导:当树高为4时,可以存放200百多亿行数据。这样的数据容量,可以满足绝大部分应用的需求,因此我们可以说在绝大部分应用中,B+树高度为3或4就可以满足数据存储的需求。B+树这种高扇出低树高的特征,也大大的提高了主键查询性能。
二、聚簇索引
在InnoDB存储引擎中,聚簇索引(Clustered Index)是数据存储和索引的一种特殊而重要的结构。聚簇索引主要特点:

(一)使用记录主键值的大小进行排序
聚簇索引通过主键值对记录和页进行排序,这涉及三个方面:
页内记录排序
在每个页内,记录按照主键值的大小顺序排成一个单向链表,确保了页内记录的有序性,方便快速查找。页内的记录被划分成若干个组,每个组中主键值最大的记录在页内的偏移量会被当作槽依次存放在页目录中(当然Supermum记录比任何用户记录都大),我们可以在页目录内通过二分法定位到主键列等于某个值的记录。
页之间的排序
存放用户记录的页按照页内记录的主键大小顺序排成一个双向链表。这种结构使得范围查询和顺序扫描更加高效。
目录项页的排序
存放目录项记录的页根据页内目录项记录的主键大小顺序排成一个双向链表。不同层次的页同样遵循这种排序规则,确保树的平衡性和查询效率。
(二)叶子节点存储完整的用户记录
B+树的叶子节点存储的是完整的用户记录,即包括所有列的值(包括隐藏列),在InnoDB中,叶子节点不仅仅是索引,还包含了实际的数据记录。这种特性使得聚簇索引与普通索引有所不同。
数据即索引
聚簇索引中的叶子节点存储了完整的用户记录,因此聚簇索引就是数据的存储方式。换句话说,索引即数据,数据即索引。
自动创建
在InnoDB存储引擎中,聚簇索引会自动为每个表创建,并且不需要在MySQL语句中显式使用INDEX语句去创建。通常情况下,聚簇索引是基于表的主键创建的。
(三)聚簇索引的优缺点
| 聚簇索引的优点 | 聚簇索引的缺点 |
|---|---|
| 快速数据访问:由于数据和索引存储在一起,基于主键的查询非常高效,不需要额外的索引查找。 | 插入和删除成本较高:由于需要维护数据的有序性,插入和删除操作可能需要移动大量记录,导致性能开销。 |
| 有序数据存储:记录按照主键顺序存储,适合范围查询和顺序扫描,提高查询性能。 | 更新成本较高:如果更新操作导致主键变化,会引发记录的重新定位和页的重新排序,影响性能。 |
聚簇索引是InnoDB存储引擎中一种关键的索引类型,通过主键排序和存储完整用户记录,提供了高效的数据访问和有序的数据存储。在优化数据库性能时,理解和合理使用聚簇索引可以显著提升查询和数据操作的效率。具体优化可见:MySQL索引性能优化分析。
三、二级索引
聚簇索引只能在搜索条件是主键值时才能发挥作用,因为B+树中的数据都是按照主键进行排序的。那如果我们想以别的列作为搜索条件该咋办呢?难道只能从头到尾沿着链表依次遍历记录么?不,我们可以多建几棵B+树,不同的B+树中的数据采用不同的排序规则。比方说我们用c2列的大小作为数据页、页中记录的排序规则,再建一棵B+树,效果如下图所示:
![]()
在InnoDB存储引擎中,除了聚簇索引(Clustered Index),我们还可以使用二级索引(Secondary Index)来提高非主键列上的查询性能。二级索引是一种基于非主键列的B+树结构,用于快速定位数据记录。
(一)二级索引的特点
基于非主键列排序
二级索引的B+树结构基于指定的非主键列进行排序,这包括以下几个方面:
- 页内记录排序:在每个页内,记录按照指定列(例如c2列)的大小顺序排成一个单向链表。
- 页之间的排序:存放用户记录的页按照页内记录的指定列顺序排成一个双向链表。这种结构便于快速范围查询和顺序扫描。
- 目录项页的排序:存放目录项记录的页根据页内目录项记录的指定列顺序排成一个双向链表,不同层次的页同样遵循这种排序规则。
叶子节点存储部分数据
与聚簇索引不同,二级索引的叶子节点存储的是索引列和主键列的值,而不是完整的用户记录。这种设计减少了存储空间的占用,但在查询过程中需要进行回表操作以获取完整的用户记录。
(二)二级索引的工作流程
假设我们创建了一个基于c2列的二级索引,并通过c2列的值查找某些记录,以查找c2列的值为4的记录为例,查找过程如下::
-
确定目录项记录页
从根页面开始,根据c2列的值
4定位到目录项记录所在的页,通过页44快速定位到目录项记录所在的页为页42(因为2 < 4 < 9)。 -
通过目录项记录页确定用户记录真实所在的页
在页42中,根据c2列的值确定实际存储用户记录的页。由于c2列没有唯一性约束,值为4的记录可能分布在多个数据页中。最终确定实际存储用户记录的页在页34和页35中(因为
2 < 4 ≤ 4)。 -
在真实存储用户记录的页中定位到具体的记录
在页34和页35中定位到具体的记录,但二级索引的叶子节点中仅存储c2列和主键列c1的值。
-
回表操作
根据主键值到聚簇索引中查找完整的用户记录。这个过程称为回表操作,即从二级索引定位到主键,再通过主键在聚簇索引中查找完整记录。
(三)二级索引的优缺点
| 二级索引的优点 | 二级索引的缺点 |
|---|---|
| 提高查询效率:基于非主键列的查询可以利用二级索引快速定位数据,减少全表扫描的开销。 | 回表操作:查询完整记录时需要回表操作,增加了一次I/O开销。 |
| 灵活性:可以为多个列创建二级索引,提升多种查询条件下的性能。 | 占用空间:虽然叶子节点不存储完整记录,但仍会占用额外的存储空间。 |
二级索引通过基于非主键列排序和存储索引列与主键列的值,为非主键列的查询提供了高效的解决方案。然而,由于叶子节点仅存储部分数据,查询完整记录时需要回表操作。因此,合理使用和配置二级索引,对于提升数据库查询性能至关重要。 具体优化可见:MySQL索引性能优化分析。
四、联合索引
在InnoDB存储引擎中,联合索引(Composite Index)是一种基于多个列的索引,用于提高复杂查询的效率。联合索引通过对多个列进行排序,能够更有效地处理包含多个条件的查询。
同时以多个列的大小作为排序规则,也就是同时为多个列建立索引,比方说我们想让B+树按照c2和c3列的大小进行排序,这个包含两层含义:
- 先把各个记录和页按照
c2列进行排序。 - 在记录的
c2列相同的情况下,采用c3列进行排序
为c2和c3列建立的索引的示意图如下:

如图所示,我们需要注意一下几点:
-
每条
目录项记录都由c2、c3、页号这三个部分组成,各条记录先按照c2列的值进行排序,如果记录的c2列相同,则按照c3列的值进行排序。 -
B+树叶子节点处的用户记录由c2、c3和主键c1列组成。
(一)联合索引的特点
多列排序规则
联合索引按照多个列的值进行排序,其排序规则包括以下两个层次:
- 第一列排序:首先按照第一个指定列(例如c2列)的值进行排序。
- 第二列排序:在第一列相同的情况下,按照第二个指定列(例如c3列)的值进行排序。
在这个结构中,每个目录项记录由c2、c3和页号组成,叶子节点存储c2、c3和主键c1。
联合索引的组成
- 目录项记录:每条目录项记录由c2、c3和页号组成,先按照c2列排序,如果c2列相同,则按照c3列排序。
- 叶子节点记录:叶子节点处的用户记录包含c2、c3和主键c1列。这种结构使得查询包含c2和c3列的条件时更加高效。
(二)联合索引与单列索引的区别
联合索引
- 建立联合索引会生成一棵B+树,该树按照c2和c3列进行排序。
- 查询时,如果使用c2和c3作为条件,能够快速定位记录,减少查询时间。
单列索引
- 为c2和c3分别建立索引会生成两棵独立的B+树,每棵树分别按照c2或c3进行排序。
- 查询时,如果只使用c2或c3作为条件,可以利用相应的索引。但如果同时使用c2和c3作为条件,可能需要进行多次索引查找和合并操作,增加查询开销。
(三)联合索引的优缺点
| 联合索引的优点 | 联合索引的缺点 |
|---|---|
| 高效的多列查询:联合索引能够显著提高包含多个列条件的查询性能。 | 插入和维护成本较高:由于需要对多个列进行排序和维护,插入和更新操作可能较慢。 |
| 减少单列索引的数量:通过一个联合索引代替多个单列索引,可以节省存储空间。 | 部分匹配限制:联合索引在查询中只能高效利用前缀列,如果查询条件不包括索引的最左列,索引的利用率会降低。 |
(四)联合索引的使用建议
前缀匹配原则
联合索引在查询中按照列的顺序生效,因此查询条件应尽量包括索引的最左列(即前缀列)。例如,创建了(c2, c3)的联合索引后,查询条件包含c2或(c2, c3)时能够有效利用索引。
适用场景
联合索引适用于需要同时基于多个列进行查询的场景。例如,在电商系统中,可以为商品类别和价格区间创建联合索引,以优化相关查询。
联合索引是InnoDB中一种重要的索引类型,通过对多个列进行排序和索引,提高了多列查询的性能。与单列索引相比,联合索引在处理复杂查询时更加高效。然而,合理的索引设计和使用对于优化数据库性能至关重要。理解联合索引的工作原理和最佳实践,可以帮助我们更好地利用MySQL数据库。 具体优化可见:MySQL索引性能优化分析。
五、总结
InnoDB中的索引是提高数据检索效率的关键。本文介绍了三种主要索引类型:
- 聚簇索引:基于主键排序存储完整的用户记录,适合快速主键查询和范围查询。
- 二级索引:基于非主键列排序,提升非主键查询性能,但需要回表操作。
- 联合索引:基于多个列排序,适用于复杂查询,能够显著提升多列条件查询的效率。
通过合理使用和配置这些索引,能有效提升数据库查询和数据操作的性能。理解索引的工作机制和最佳实践,对于优化MySQL数据库性能至关重要。
参考文献、书籍及链接
- 《MySQL技术内幕:InnoDB存储引擎》(第2版):MySQL技术内幕 (豆瓣)
- 《MySQL 是怎样运行的:从根儿上理解 MySQL》
- 《Inside InnoDB: The InnoDB Storage Engine》:MySQL :: MySQL 8.0 Reference Manual :: 15 The InnoDB Storage Engine
- 《InnoDB: The Ultimate Guide》:https://www.percona.com/blog/2018/06/05/innodb-the-ultimate-guide/
- 《InnoDB Storage Engine Internals》:https://mariadb.com/kb/en/innodb-storage-engine-internals/
- InnoDB的数据页结构
- InnoDB存储引擎B+树的树高推导_b+树一般多少层-CSDN博客
- MySQL索引性能优化分析_mysql索引和性能分析(实战)-CSDN博客
相关文章:
深入理解MySQL InnoDB中的B+索引机制
目录 一、InnoDB中的B 树索引介绍 二、聚簇索引 (一)使用记录主键值的大小进行排序 页内记录排序 页之间的排序 目录项页的排序 (二)叶子节点存储完整的用户记录 数据即索引 自动创建 (三)聚簇索引…...

语言的输入
编程语言提供最基本的输入输出,输入一个预期的数据也不是看起来那么简单,如下一一展开。 不同输入形式 C语言scanf提供格式串输入,程序员负责配置正确的格式,比如%d整型,%s为字符串。可能出现格式串和变量格式、个数不…...

2024年中国电子学会青少年软件编程(Python)等级考试(二级)核心考点速查卡
考前练习 2024年03月中国电子学会青少年软件编程(Python)等级考试试卷(二级)答案 解析 2024年06月中国电子学会青少年软件编程(Python)等级考试试卷(二级)答案 解析 知识点描述 …...

OpenCV系列教程二:基本图像增强(数值运算)、滤波器(去噪、边缘检测)
文章目录 一、基本图像增强(数值运算)1.1 加法 (cv2.add)1.1.1 图像与标量相加(调节亮度)1.1.2 图像与图像相加(两个图像shape要相同)1.1.3 图像的加权加法(渐变切换&…...

什么是文件完整性监控(FIM)
组织经常使用基于文件的系统来组织、存储和管理信息。文件完整性监控(FIM)是一种用于监控和验证文件和系统完整性的技术,识别用户并提醒用户对文件、文件夹和配置进行未经授权或意外的变更是 FIM 的主要目标,有助于保护关键数据和…...
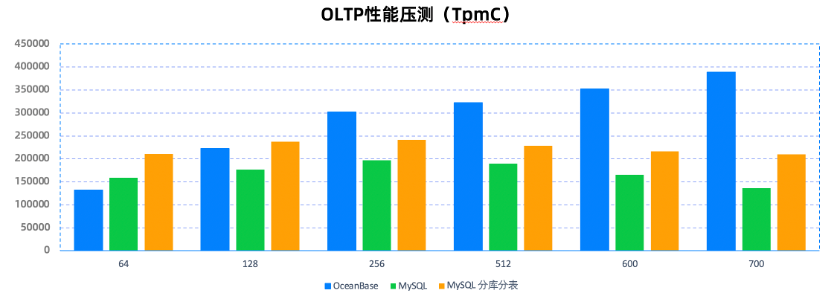
分库分表还是分布式?如何用 OceanBase的单机分布式一体化从根本上解决问题
随着企业业务规模的不断增长,单机集中式的数据库系统逐渐难以承载企业日益增长的数据存储与处理需求。因此,MySQL 的分库分表方案成为了众多企业应对数据存储量激增及数据处理能力需求扩张的“止痛药”。尽管这一方案短期内有效缓解了企业面临的大规模数…...

怎么查看网站是否被谷歌收录,哪些因素影响着网站是否被谷歌收录
一、怎么查看网站是否被谷歌收录 查看网站是否被谷歌收录,有多种方法可供选择,以下是几种常用的方式: 1.使用“site:”指令: 在谷歌搜索引擎的搜索框中输入“site:你的域名网址”(注意使用英文冒号&#x…...
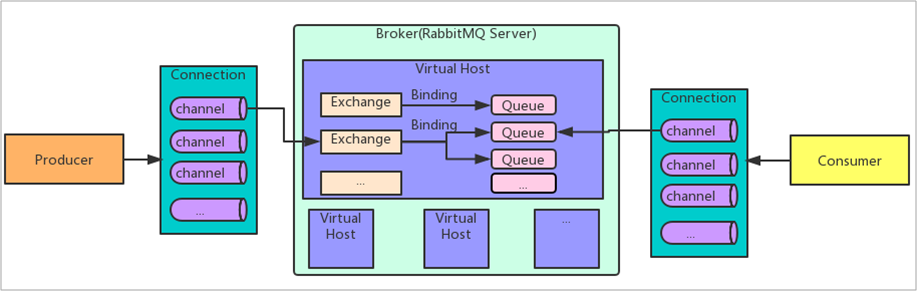
【RabbitMQ】面试题
在本篇文章中,主要是介绍RabbitMQ一些常见的面试题。对于前几篇文章的代码,都已经在码云中给出,链接是mq-test: 学习RabbitMQ的一些简单案例 (gitee.com),如果存在问题的话欢迎各位提出,望共同进步。 MQ的作用以及应用…...

Python软体中使用TensorFlow实现一个简单的神经网络:从零开始
使用TensorFlow实现一个简单的神经网络:从零开始 在现代数据科学和机器学习领域,神经网络是一个强大的工具。TensorFlow是一个广泛使用的开源库,专门用于机器学习和深度学习。本文将详细介绍如何使用TensorFlow实现一个简单的神经网络。我们将从基础概念开始,逐步深入到代…...
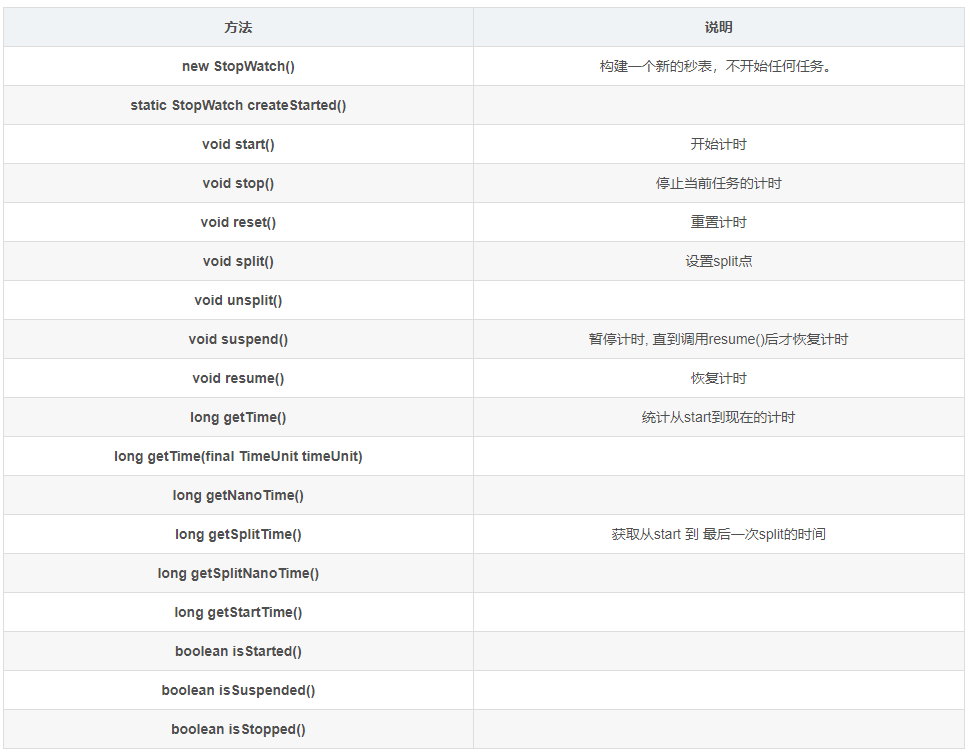
StopWath,apache commons lang3 包下的一个任务执行时间监视器的使用
StopWath是 apache commons lang3 包下的一个任务执行时间监视器,与我们平时常用的秒表的行为比较类似,我们先看一下其中的一些重要方法: <!-- https://mvnrepository.com/artifact/org.apache.commons/commons-lang3 --> <dependen…...

ELMO理论
目录 1 优点 2 缺点 3.知识点个人笔记 2018年3月份,ELMo出世,该paper是NAACL18 Best Paper。在之前2013年的word2vec及2014年的GloVe的工作中,每个词对应一个vector,对于多义词无能为力。ELMo的工作对于此,提出了一…...

EMU 街机模拟器编译方法
安装ubuntu 16.04 下载gcc 8.2 安装 然后安装automake 1.16 ,1.15 安装jdk8 sdk 里面配套的ndk 21e 编译库 cd ~/emu-ex-plus-alpha/imagine/bundle/all/ export IMAGINE_PATH/home/lxm/emu-ex-plus-alpha/imagine export ANDROID_SDK_ROOT/home/lxm/Sdk export ANDROID_NDK_…...
)
c++开发之编译curl(windows版本)
在 Windows 上编译支持 OpenSSL 的 cURL 库并不简单,因为涉及到多个库的依赖关系以及工具链的配置。以下是编译支持 OpenSSL 的 cURL 库的详尽步骤: 环境要求 编译工具链: MinGW 或 Visual StudioCMakePerl (用于编译 OpenSSL)NASM (用于编译…...

IT运维挑战与对策:构建高效一体化运维管理体系
在当今数字化时代,IT运维作为企业运营的核心支撑,其重要性不言而喻。然而,随着业务规模的扩大和技术的不断革新,IT运维团队面临着前所未有的挑战。本文旨在深度剖析当前IT运维中存在的主要问题,并探索一体化解决方案&a…...

前海石公园的停车点探寻
前海石公园是真的很美,很多看海人,很多钓鱼佬,很多抓螃蟹的人,很多挖沙子的人,很多拍照的人,尤其是没有大太阳的时间段或每天傍晚或每个放假的时候人气超高,故前海石公园停车真的很紧张。由于前…...

嵌入式学习--线性表Day01
嵌入式学习--线性表Day01 顺序表 1.1数组的插入、删除操作 1.2修改为last版本 1.3顺序表相关操作 顺序表、单向链表、单向循环链表、双向链表、双向循环链表、顺序栈、链式栈、循环队列(顺序队列)、链式队列 1)逻辑结构:线性结构 …...

Rust 全局变量的最佳实践 lazy_static/OnceLock/Mutex/RwLock
在实际项目开发中,难免需要用到全局变量,比如全局配置信息,全局内存池等,此类数据结构可能在多处需要被使用,保存为全局变量可以很方便的进行修改与读取。 在Rust中,如果只是读取静态变量是比较简单的&…...

【L波段差分干涉SAR卫星(陆地探测一号01组)】
L波段差分干涉SAR卫星(陆地探测一号01组) L波段差分干涉SAR卫星(陆地探测一号01组)是我国自主研发的重要卫星系统,以下是对该卫星的详细介绍: 一、基本信息 卫星组成:陆地探测一号01组由A星…...

第五部分:6---信号的递达
目录 信号的递达流程: 信号在什么时候递达? 用户态和内核态: 内核态、用户态在页表的映射关系: 操作系统如何得知当前执行状态是用户态还是内核态? 操作系统如何处理被捕捉的信号? 信号的递达流程&am…...

深入解析 ARM64 SOC RK3568的 /proc/interrupts 输出
在 Linux 系统中,/proc/interrupts 文件提供了系统中断的详细信息,是性能分析和故障排除的重要工具。本文将重点解析 RK3568环境下该文件的输出格式及其背后的结构。 什么是 /proc/interrupts? /proc/interrupts 文件记录了所有中断的信息&…...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...

Linux简单的操作
ls ls 查看当前目录 ll 查看详细内容 ls -a 查看所有的内容 ls --help 查看方法文档 pwd pwd 查看当前路径 cd cd 转路径 cd .. 转上一级路径 cd 名 转换路径 …...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

ESP32 I2S音频总线学习笔记(四): INMP441采集音频并实时播放
简介 前面两期文章我们介绍了I2S的读取和写入,一个是通过INMP441麦克风模块采集音频,一个是通过PCM5102A模块播放音频,那如果我们将两者结合起来,将麦克风采集到的音频通过PCM5102A播放,是不是就可以做一个扩音器了呢…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

【HTTP三个基础问题】
面试官您好!HTTP是超文本传输协议,是互联网上客户端和服务器之间传输超文本数据(比如文字、图片、音频、视频等)的核心协议,当前互联网应用最广泛的版本是HTTP1.1,它基于经典的C/S模型,也就是客…...

ArcGIS Pro制作水平横向图例+多级标注
今天介绍下载ArcGIS Pro中如何设置水平横向图例。 之前我们介绍了ArcGIS的横向图例制作:ArcGIS横向、多列图例、顺序重排、符号居中、批量更改图例符号等等(ArcGIS出图图例8大技巧),那这次我们看看ArcGIS Pro如何更加快捷的操作。…...