计算机视觉方面的一些模块
# __all__ 是一个可选的列表,定义在模块级别。当使用 from ... import * 语句时,如果模块中定义了
# __all__,则只有 __all__ 列表中的名称会被导入。这是模块作者控制哪些公开API被导入的一种方式。
# 使用 * 导入的行为
# 如果模块中有 __all__ 列表:只有 __all__ 列表中的名称会被导入
# 如果模块中没有 __all__ 列表:Python 解释器会尝试导入模块中定义的所有公共名称(即不
# 是以下划线 _ 开头的名称)。但是,这通常不包括以单下划线或双下划线开头的特殊方法或变量
def autopad(k, p=None, d=1): # kernel, padding, dilation
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x): # (b,c1,...)
# (b,c1,...)-->(b,c2,...),卷积块
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
class Conv2(Conv):
def __init__(self, c1, c2, k=3, s=1, p=None, g=1, d=1, act=True):
super().__init__(c1, c2, k, s, p, g=g, d=d, act=act)
self.cv2 = nn.Conv2d(c1, c2, 1, s, autopad(1, p, d), groups=g, dilation=d, bias=False) # add 1x1 conv
def forward(self, x): # (b,c1,...)
# self.cv2(x):(b,c1,...)-->(b,c2,...) # 点卷积
# self.conv(x):(b,c1,...)-->(b,c2,...) # 普通卷积
# 先把两种卷积的处理结果做残差,之后批次标准化,激活函数
return self.act(self.bn(self.conv(x) + self.cv2(x)))
def forward_fuse(self, x): # (b,c1,...)
return self.act(self.bn(self.conv(x)))
def fuse_convs(self):
# 具有conv权重w形状的全0张量
w = torch.zeros_like(self.conv.weight.data)
i = [x // 2 for x in w.shape[2:]] # (1,1)
# 将w中最后两维1:2的数据用cv2的权重替换
w[:, :, i[0] : i[0] + 1, i[1] : i[1] + 1] = self.cv2.weight.data.clone()
# 用conv.weight和w做残差,结果做为conv的权重
self.conv.weight.data += w
self.__delattr__("cv2") # 删除cv2属性
self.forward = self.forward_fuse # 更改对象的forward方法
class DWConv(Conv):
# 假设 c1 = 6(输入通道数),c2 = 8(输出通道数),并且最大公约数 g = math.gcd(6, 8) = 2
# g是指组数,输出通道数 (8):表示最终的输出通道数。输入通道组数 (3):表示每个输出通道对应的输入通道的一个子集(组),
# 这里每个组包含 3 个输入通道。卷积核大小 (3x3):表示卷积核的大小,这里是 3x3。
def __init__(self, c1, c2, k=1, s=1, d=1, act=True): # ch_in, ch_out, kernel, stride, dilation, activation
super().__init__(c1, c2, k, s, g=math.gcd(c1, c2), d=d, act=act)
class LightConv(nn.Module):
def __init__(self, c1, c2, k=1, act=nn.ReLU()):
super().__init__()
self.conv1 = Conv(c1, c2, 1, act=False) # 点卷积
self.conv2 = DWConv(c2, c2, k, act=act) # 深度卷积
def forward(self, x): # (b,c1,...)
# (b,c1,...)-->(b,c2,...)
# 先点卷积切换通道,之后深度卷积处理
# 用light_conv.conv1.conv.weight来访问属性权重
# conv2_weight.shape[18, 1, 3, 3]
# 18指输出和输入通道被分成18组,每组包含1个通道,
# 每个组包含 1个输出和输入通道。18表示最终的输出通道数。
# 输入通道组数 (18):表示每个输出通道对应的输入通道的一个子集(组),这里每个组包含 1个输入通道。
# 卷积核大小 (3x3):表示卷积核的大小,这里是 3x3。
return self.conv2(self.conv1(x))
class DWConvTranspose2d(nn.ConvTranspose2d):
def __init__(self, c1, c2, k=1, s=1, p1=0, p2=0): # ch_in, ch_out, kernel, stride, padding, padding_out
super().__init__(c1, c2, k, s, p1, p2, groups=math.gcd(c1, c2))
class ConvTranspose(nn.Module):
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=2, s=2, p=0, bn=True, act=True):
super().__init__()
self.conv_transpose = nn.ConvTranspose2d(c1, c2, k, s, p, bias=not bn)
self.bn = nn.BatchNorm2d(c2) if bn else nn.Identity()
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv_transpose(x)))
def forward_fuse(self, x):
return self.act(self.conv_transpose(x))
class Focus(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
super().__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act=act)
def forward(self, x):
# 这里的切片切分空间操作,是先切分奇数行奇数列,之后是偶数行奇数列,之后奇数行偶数列,之后是偶数行偶数列
# 之后在通道维度合并特征,整个空间采样每个像素位置都被恰好取样了一次。没有任何像素被重复取样,没有任何像素被遗漏
# 合并特征后经过卷积处理,我第一感觉是这样采样,有助于模型发现图片数据的行梯度和列梯度的变化
return self.conv(torch.cat((x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]), 1))
class GhostConv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, g=1, act=True):
super().__init__()
c_ = c2 // 2 # hidden channels
self.cv1 = Conv(c1, c_, k, s, None, g, act=act)
self.cv2 = Conv(c_, c_, 5, 1, None, c_, act=act) # 核大小为5的深度卷积
def forward(self, x): # (b,c1,...)
# gc=GhostConv(6,12,k=3)时,cv1.conv.weight.shape[6, 6, 3, 3]
y = self.cv1(x) # (b,c_,...)
# self.cv2(y):(b,c_,...)-->(b,c_,...)
# 之后在通道维度合并通道,变成(b,2c_,...)
# cv2是步长为1,核大小为5的深度卷积
return torch.cat((y, self.cv2(y)), 1)
class RepConv(nn.Module):
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=3, s=1, p=1, g=1, d=1, act=True, bn=False, deploy=False):
super().__init__()
assert k == 3 and p == 1
self.g = g
self.c1 = c1
self.c2 = c2
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
# 使用批次标准化的条件
self.bn = nn.BatchNorm2d(num_features=c1) if bn and c2 == c1 and s == 1 else None
self.conv1 = Conv(c1, c2, k, s, p=p, g=g, act=False) #普通卷积
self.conv2 = Conv(c1, c2, 1, s, p=(p - k // 2), g=g, act=False) # 点卷积
def forward_fuse(self, x): # (b,c1,...) 卷积块处理
return self.act(self.conv(x))
def forward(self, x):
id_out = 0 if self.bn is None else self.bn(x)
# 如果id_out =self.bn(x),普通卷积和点卷积和原数据的批次标准化做残差连接
return self.act(self.conv1(x) + self.conv2(x) + id_out)
# 将各个卷积核及其偏置融合成一个等效的卷积核和偏置。
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.conv1)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.conv2)
kernelid, biasid = self._fuse_bn_tensor(self.bn)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
# 对于 batch normalization 层,如果存在 self.bn,则构造一个中间变量 self.id_tensor,
# 这是一个形状为 (c1, input_dim, 3, 3) 的张量,其中心位置为 1,其余位置为 0。
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, Conv):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
elif isinstance(branch, nn.BatchNorm2d):
if not hasattr(self, "id_tensor"):
input_dim = self.c1 // self.g
kernel_value = np.zeros((self.c1, input_dim, 3, 3), dtype=np.float32)
for i in range(self.c1):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
# 这个方法创建一个新的卷积层,该层包含了等效的卷积核和偏置,并删除不再需要的旧卷积层。
def fuse_convs(self):
if hasattr(self, "conv"):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.conv = nn.Conv2d(
in_channels=self.conv1.conv.in_channels,
out_channels=self.conv1.conv.out_channels,
kernel_size=self.conv1.conv.kernel_size,
stride=self.conv1.conv.stride,
padding=self.conv1.conv.padding,
dilation=self.conv1.conv.dilation,
groups=self.conv1.conv.groups,
bias=True,
).requires_grad_(False)
self.conv.weight.data = kernel
self.conv.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__("conv1")
self.__delattr__("conv2")
if hasattr(self, "nm"):
self.__delattr__("nm")
if hasattr(self, "bn"):
self.__delattr__("bn")
if hasattr(self, "id_tensor"):
self.__delattr__("id_tensor")
class ChannelAttention(nn.Module):
# 这个通道注意力少了一个压缩点卷积,有意为之吗?
def __init__(self, channels: int) -> None:
super().__init__()
self.pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Conv2d(channels, channels, 1, 1, 0, bias=True) # 点卷积
self.act = nn.Sigmoid()
def forward(self, x: torch.Tensor) -> torch.Tensor: # (b,c,...)
# 平均池化后,每个通道经过点卷积混合通道信息,sigmoid为通道打重要性分数
# 之后对原数据加权,这样随着训练的进行,重要的特征会越来越明显,不重要的特征会被忽略
return x * self.act(self.fc(self.pool(x)))
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super().__init__()
assert kernel_size in {3, 7}, "kernel size must be 3 or 7"
padding = 3 if kernel_size == 7 else 1
self.cv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.act = nn.Sigmoid()
def forward(self, x):# (b,c,...)
# 首先对x在索引1的维度求均值和最大值,就是对通道维度聚合操作,之后聚合后形状为(b,1,...),之后在特征轴合并特征
# 之后经过卷积处理,通道变成1,之后sigmoid处理,这样sigmoid会给每个空间位置打分,这个分数表示空间位置对当前任务的重要性
# 之后与原数据加权,这样空间的重要性被分配到各个通道的空间中
return x * self.act(self.cv1(torch.cat([torch.mean(x, 1, keepdim=True), torch.max(x, 1, keepdim=True)[0]], 1)))
class CBAM(nn.Module):
def __init__(self, c1, kernel_size=7):
super().__init__()
self.channel_attention = ChannelAttention(c1) # 通道注意力
self.spatial_attention = SpatialAttention(kernel_size) # 空间注意力
def forward(self, x): #(b,c1,...)
# 先做通道注意力,之后做空间注意力
return self.spatial_attention(self.channel_attention(x))
class Concat(nn.Module):
def __init__(self, dimension=1):
super().__init__()
self.d = dimension
def forward(self, x): # (b,c1)
return torch.cat(x, self.d) # 对列表元素在通道维度合并特征
# GhostBottleneck 类是一个用于卷积神经网络中的瓶颈模块
class GhostBottleneck(nn.Module):
def __init__(self, c1, c2, k=3, s=1):
super().__init__()
c_ = c2 // 2
self.conv = nn.Sequential(
# GhostConv:用于减少参数数量的模块。
GhostConv(c1, c_, 1, 1), # 点卷积切换通道,之后和深度卷积后的数据在通道维度合并
# DWConv:深度可分离卷积,用于降低计算复杂度
DWConv(c_, c_, k, s, act=False) if s == 2 else nn.Identity(), # dw
GhostConv(c_, c2, 1, 1, act=False), # pw-linear
)
# nn.Identity() 是 PyTorch 中的一个类,它代表一个不执行任何操作的模块。当你实例化 nn.Identity()
# 并将其作为模块的一部分时,它实际上会返回输入而不做任何改变。shortcut:用于实现残差连接的路径。
self.shortcut = (
nn.Sequential(DWConv(c1, c1, k, s, act=False), Conv(c1, c2, 1, 1, act=False)) if s == 2
else nn.Conv2d(c1, c2, kernel_size=1, stride=1, padding=0, bias=False) if c1 != c2 else nn.Identity()
)
def forward(self, x): # (b,c1,...)
return self.conv(x) + self.shortcut(x)
class DFL(nn.Module):
def __init__(self, c1=16):
super().__init__()
# 点卷积
self.conv = nn.Conv2d(c1, 1, 1, bias=False).requires_grad_(False)
x = torch.arange(c1, dtype=torch.float)
# 设置conv的权重
self.conv.weight.data[:] = nn.Parameter(x.view(1, c1, 1, 1)) # (1,c,1,1)
self.c1 = c1
def forward(self, x):
b, _, a = x.shape # batch, channels, anchors
# (b,c,a)-->(b,4,16,a)-->(b,16,4,a)-->softmax-->conv-->(b,4,a)
# softmax在索引1的轴归一化
return self.conv(x.view(b, 4, self.c1, a).transpose(2, 1).softmax(1)).view(b, 4, a)
class Proto(nn.Module):
def __init__(self, c1, c_=256, c2=32):
super().__init__()
self.cv1 = Conv(c1, c_, k=3) # 普通卷积,核大小3
# 上采样,核大小是2
self.upsample = nn.ConvTranspose2d(c_, c_, 2, 2, 0, bias=True)
self.cv2 = Conv(c_, c_, k=3) # 普通卷积,核大小3
self.cv3 = Conv(c_, c2)# 点卷积
def forward(self, x):
# (b,h,w,c1)-->(b,h,w,c_)-->(b,2h,2w,c_)-->(b,2h,2w,c_)-->(b,2h,2w,c2)
return self.cv3(self.cv2(self.upsample(self.cv1(x))))
class HGStem(nn.Module):
def __init__(self, c1, cm, c2):
super().__init__()
# 核大小3,步长2
self.stem1 = Conv(c1, cm, 3, 2, act=nn.ReLU())
# 核大小2,步长1
self.stem2a = Conv(cm, cm // 2, 2, 1, 0, act=nn.ReLU())
self.stem2b = Conv(cm // 2, cm, 2, 1, 0, act=nn.ReLU()) # 核大小2,步长1
self.stem3 = Conv(cm * 2, cm, 3, 2, act=nn.ReLU()) # 核大小3,步长2
self.stem4 = Conv(cm, c2, 1, 1, act=nn.ReLU()) # 点卷积
# ceil_mode=True 指的是当计算输出尺寸的时候,使用向上取整而不是向下取整(默认行为)。这在某些情
# 况下可能会导致输出的大小比通常预期的大一点。
# 举个例子,如果输入的尺寸为 (N, C, H, W),其中 N 是batch size,C 是通道数,H 和 W 分别是高
# 度和宽度。假设 H 和 W 都是偶数,比如 (4, 4),那么应用上述的 MaxPool2d 层之后,如果使用默认的
# floor 模式,输出的高度和宽度将是 (3, 3);但如果使用了 ceil_mode=True,输出的高度和宽度将会是 (4, 4)。
self.pool = nn.MaxPool2d(kernel_size=2, stride=1, padding=0, ceil_mode=True)
def forward(self, x): # (b,h,w,c1)
x = self.stem1(x) # (b,h/2,w/2,cm)
x = F.pad(x, [0, 1, 0, 1])
x2 = self.stem2a(x) # (b,h/2,w/2,cm/2)
x2 = F.pad(x2, [0, 1, 0, 1])
x2 = self.stem2b(x2) # (b,h/2,w/2,cm)
x1 = self.pool(x) # (b,h/2,w/2,cm)
x = torch.cat([x1, x2], dim=1) # (b,h/2,w/2,2cm)
x = self.stem3(x) # (b,h/4,w/4,cm)
x = self.stem4(x) # (b,h/4,w/4,c2)
return x
class HGBlock(nn.Module):
def __init__(self, c1, cm, c2, k=3, n=6, lightconv=False, shortcut=False, act=nn.ReLU()):
super().__init__()
block = LightConv if lightconv else Conv
# 在nn.ModuleList中存储的对象是不同的对象,它们在内存中的地址也是不同的。nn.ModuleList是一个有序集合,
# 用于存储子模块,它可以像普通的Python列表一样索引,但它确保每个添加的项都是torch.nn.Module的实例或其子类。
# 每次调用block()时,都会创建一个新的实例,并将其添加到ModuleList中。这意味着每个block对象都有自己的状态和参数,
# 并且在模型的前向传播过程中会被独立地调用。
self.m = nn.ModuleList(block(c1 if i == 0 else cm, cm, k=k, act=act) for i in range(n))
self.sc = Conv(c1 + n * cm, c2 // 2, 1, 1, act=act) # 点卷积
self.ec = Conv(c2 // 2, c2, 1, 1, act=act) # 点卷积
self.add = shortcut and c1 == c2 # 残差条件
def forward(self, x):
y = [x]
# 这些block对象依次应用于输入数据
# 这段代码遍历self.m中的每个block对象,并将上一个block的输出作为当前block的输入,从而形成一个序
# 列化的处理流程。因为每次m(y[-1])处理后的结果都被添加到y中,而y[-1]是取出列表最后一个元素
# 这样每次m处理后的结果都被当成了下次的输入
y.extend(m(y[-1]) for m in self.m) # 6个卷积块处理
# 在通道轴合并特征
y = self.ec(self.sc(torch.cat(y, 1)))
# 满足残差条件,返回残差,否则返回处理后结果
return y + x if self.add else y
class SPP(nn.Module):
def __init__(self, c1, c2, k=(5, 9, 13)):
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1) # 点卷积
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1) # 点卷积
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x): # (b,h,w,c1)
x = self.cv1(x) # (b,h,w,c_)
# (b,h,w,c_)-->(b,h,w,4c_)-->(b,h,w,c2)
# 这里不同尺寸的最大池化核会处理相同的x,之后列表内的对象在索引1的轴(通道轴)合并
# self.m中的每个m处理的都是相同的输入x,而不是上一个最大池化的输出
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
class SPPF(nn.Module):
def __init__(self, c1, c2, k=5):
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1) # 点卷积
self.cv2 = Conv(c_ * 4, c2, 1, 1) # 点卷积
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
# (b,h,w,c1)-->(b,h,w,c_)
y = [self.cv1(x)]
# 通过列表推导式和extend方法将多次迭代的结果追加到y列表中。每次迭代都会使用self.m
# 处理列表y的最后一个元素,并将结果追加到y列表中。因此,y[-1]始终是指向列表中最新追加的元素
y.extend(self.m(y[-1]) for _ in range(3))
# 将列表y中的所有元素沿着通道维度(维度1)拼接起来
# (b,4c_,h,w)-->(b,c2,h,w)
return self.cv2(torch.cat(y, 1))
class C1(nn.Module):
def __init__(self, c1, c2, n=1):
super().__init__()
self.cv1 = Conv(c1, c2, 1, 1) # 点卷积
self.m = nn.Sequential(*(Conv(c2, c2, 3) for _ in range(n)))
def forward(self, x):
# (b,c1,h,w)-->(b,c2,h,w)
y = self.cv1(x)
# 序列化栈前后残差
return self.m(y) + y
class Bottleneck(nn.Module): # 标准瓶颈模块
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1) # 普通卷积
self.cv2 = Conv(c_, c2, k[1], 1, g=g) # g是groups
# 残差条件:shortcut为True并且c1 == c2
self.add = shortcut and c1 == c2
def forward(self, x): # (b,c1,h,w)
# self.cv2(self.cv1(x)):(b,c1,h,w)-->(b,c_,h,w)-->(b,c2,h,w)
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C2(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1) # 点卷积
self.cv2 = Conv(2 * self.c, c2, 1)
self.m = nn.Sequential(*(
Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n)))
def forward(self, x): # (b,c1,h,w)
# (b,c1,h,w)-->(b,2c,h,w)
# chunk(2, 1):将输出张量沿着通道维度(维度1)分割成两个部分,分别命名为a和b。
# 2是指分成两个部分,1指索引1的轴
a, b = self.cv1(x).chunk(2, 1)
# 将分割出的a传递给模块self.m,将处理后的a与未处理的b沿通道维度拼接起来。
# 将拼接后的张量再次通过卷积层cv2进行处理
# (b,2c,...)-->(b,c2,...)
return self.cv2(torch.cat((self.m(a), b), 1))
class C2f(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):# (b,c1,...)
# (b,c1,...)-->(b,2c,...),在通道维度分成两份
y = list(self.cv1(x).chunk(2, 1))
# 依次追加self.m中每个m处理后的结果,y[-1]是上个处理结果
y.extend(m(y[-1]) for m in self.m)
# 将列表中的所有特征图在通道轴合并
# (b,(2 + n)c,...)-->(b,c2,...)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
class SCDown(nn.Module):
def __init__(self, c1, c2, k, s):
super().__init__()
self.cv1 = Conv(c1, c2, 1, 1) # 点卷积
self.cv2 = Conv(c2, c2, k=k, s=s, g=c2, act=False)
def forward(self, x): # (b,c1,...)
# (b,c1,...)-->(b,c2,...)-->(b,c2,...)
# 先点卷积切换通道,之后深度卷积
return self.cv2(self.cv1(x))
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, attn_ratio=0.5):
super().__init__()
self.num_heads = num_heads # h
self.head_dim = dim // num_heads # dk
self.key_dim = int(self.head_dim * attn_ratio)
self.scale = self.key_dim**-0.5 # 缩放系数
nh_kd = self.key_dim * num_heads # 所有头加起来的维数
h = dim + nh_kd * 2 # 中间维度
self.qkv = Conv(dim, h, 1, act=False)
self.proj = Conv(dim, dim, 1, act=False) # 点卷积
# 深度卷积
self.pe = Conv(dim, dim, 3, 1, g=dim, act=False)
def forward(self, x): # (b,d,...)
B, C, H, W = x.shape
N = H * W
# (b,d,...)-->(b,h,...)
qkv = self.qkv(x)
# (b,h,...)-->(b,h,dk+k_dk*2,s),在通道维度进行拆分,q,k特征维度相同
# v单独一个特征维度
# q和k主要用于计算注意力权重,因此减少它们的特征维度可以减少冗余信息,提高计算效率。
# v用于根据注意力权重进行加权求和,保持较大的特征维度可以保留更多的信息。
q, k, v = qkv.view(B, self.num_heads, self.key_dim * 2 + self.head_dim, N).split(
[self.key_dim, self.key_dim, self.head_dim], dim=2
)
# (b,h,s_q,k_dk)@(b,h,k_dk,s_k)-->(b,h,s_q,s_k)
attn = (q.transpose(-2, -1) @ k) * self.scale
attn = attn.softmax(dim=-1) # 在s_k上归一化
# (b,h,dk,s_v)@(b,h,s_k,s_q)-->(b,h,dk,s_q)-->(b,d,h,w)
# v:(b,h,dk,s)-->(b,d,h,w)-->(b,d,...)
# 注意力后的v和经过深度卷积的v做残差
x = (v @ attn.transpose(-2, -1)).view(B, C, H, W) + self.pe(v.reshape(B, C, H, W))
# (b,d,h,w)-->(b,d,h,w)
x = self.proj(x)
return x
class PSA(nn.Module):
def __init__(self, c1, c2, e=0.5):
super().__init__()
assert c1 == c2
self.c = int(c1 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1) # 点卷积切通道
self.cv2 = Conv(2 * self.c, c1, 1)
self.attn = Attention(self.c, attn_ratio=0.5, num_heads=self.c // 64)
self.ffn = nn.Sequential(Conv(self.c, self.c * 2, 1), Conv(self.c * 2, self.c, 1, act=False))
def forward(self, x): # (b,c1,h,w)
# (b,c1,h,w)-->(b,2c,...),split会在通道维度拆分
a, b = self.cv1(x).split((self.c, self.c), dim=1)
# 对b做注意力前后的残差连接
b = b + self.attn(b) # (b,c,...)
# (b,c,...)-->(b,2c,...)-->(b,c,...)
# 整个多头自注意力过程没有层标准化和dropout
b = b + self.ffn(b) # 前馈前后残差
# 在通道维度合并a,b的特征,之后经过卷积处理
# (b,2c,...)-->(b,c1,...)
return self.cv2(torch.cat((a, b), 1))
class C2fCIB(C2f):
def __init__(self, c1, c2, n=1, shortcut=False, lk=False, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(CIB(self.c, self.c, shortcut, e=1.0, lk=lk) for _ in range(n))
class C3(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1) # 点卷积
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=((1, 1), (3, 3)), e=1.0) for _ in range(n)))
def forward(self, x): # (b,c1,...)
# x经过cv1,之后被m模块处理,另一个x经过cv2处理,之后两者在通道维度合并特征
# (b,c1,...)-->(b,c_,...)-->(b,c,...)
# b,c1,...)-->(b,c_,...)
# 之后在通道维度合并,-->(b,2c,...)-->(b,c2,...)
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
class C3x(C3):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
self.c_ = int(c2 * e)
self.m = nn.Sequential(*(Bottleneck(self.c_, self.c_, shortcut, g, k=((1, 3), (3, 1)), e=1) for _ in range(n)))
class C3TR(C3):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e)
self.m = TransformerBlock(c_, c_, 4, n)
class C3Ghost(C3):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
self.m = nn.Sequential(*(GhostBottleneck(c_, c_) for _ in range(n)))
class RepC3(nn.Module):
def __init__(self, c1, c2, n=3, e=1.0):
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c2, 1, 1)
self.cv2 = Conv(c1, c2, 1, 1)
self.m = nn.Sequential(*[RepConv(c_, c_) for _ in range(n)])
self.cv3 = Conv(c_, c2, 1, 1) if c_ != c2 else nn.Identity()
def forward(self, x):
return self.cv3(self.m(self.cv1(x)) + self.cv2(x))
相关文章:

计算机视觉方面的一些模块
# __all__ 是一个可选的列表,定义在模块级别。当使用 from ... import * 语句时,如果模块中定义了 # __all__,则只有 __all__ 列表中的名称会被导入。这是模块作者控制哪些公开API被导入的一种方式。 # 使用 * 导入的行为 # 如果模块中有 __a…...

进阶美颜功能技术开发方案:探索视频美颜SDK
视频美颜SDK(SoftwareDevelopmentKit)作为提升视频质量的重要工具,越来越多地被开发者关注与应用。接下俩,笔者将深入探讨进阶美颜功能的技术开发方案,助力开发者更好地利用视频美颜SDK。 一、视频美颜SDK的核心功能 …...

【重学 MySQL】三十八、group by的使用
【重学 MySQL】三十八、group by的使用 基本语法示例示例 1: 计算每个部门的员工数示例 2: 计算每个部门的平均工资示例 3: 结合 WHERE 子句 WITH ROLLUP基本用法示例注意事项 注意事项 GROUP BY 是 SQL 中一个非常重要的子句,它通常与聚合函数(如 COUNT…...

SSM框架VUE电影售票管理系统开发mysql数据库redis设计java编程计算机网页源码maven项目
一、源码特点 smm VUE电影售票管理系统是一套完善的完整信息管理类型系统,结合SSM框架和VUE、redis完成本系统,对理解vue java编程开发语言有帮助系统采用ssm框架(MVC模式开发),系 统具有完整的源代码和数据库&#…...

基于Hive和Hadoop的白酒分析系统
本项目是一个基于大数据技术的白酒分析系统,旨在为用户提供全面的白酒市场信息和深入的价格分析。系统采用 Hadoop 平台进行大规模数据存储和处理,利用 MapReduce 进行数据分析和处理,通过 Sqoop 实现数据的导入导出,以 Spark 为核…...

【软考】高速缓存的组成
目录 1. 说明2. 组成 1. 说明 1.高速缓存用来存放当前最活跃的程序和数据。2.高速缓存位于CPU 与主存之间。3.容量般在几千字节到几兆字节之间。4.速度一般比主存快 5~10 倍,由快速半导体存储器构成。5.其内容是主存局部域的副本,对程序员来说是透明的。…...
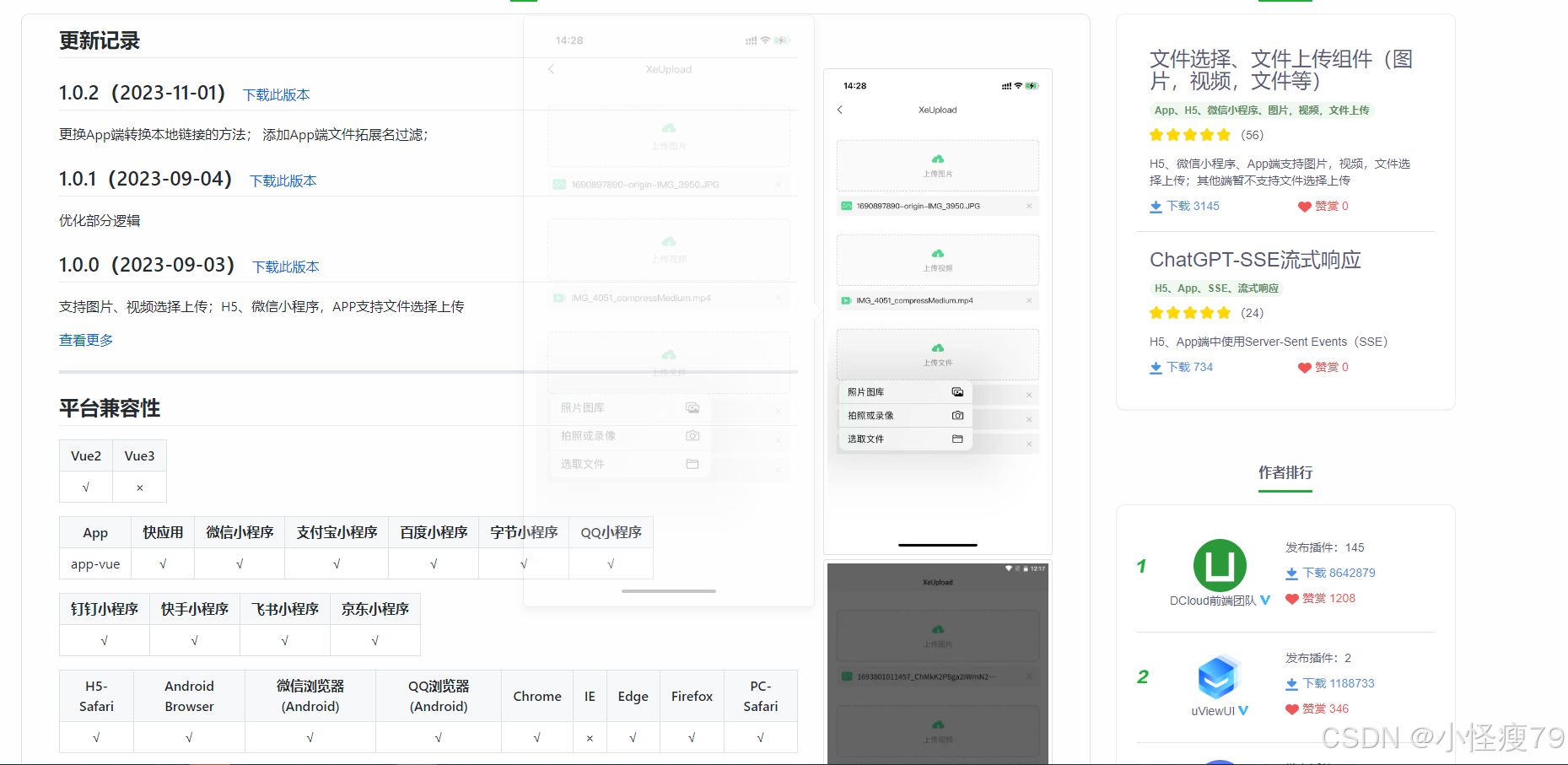
UniApp基于xe-upload实现文件上传组件
xe-upload地址:文件选择、文件上传组件(图片,视频,文件等) - DCloud 插件市场 致敬开发者!!! 感觉好用的话,给xe-upload的作者一个好评 背景:开发中经常会有…...

以太网交换安全:端口隔离
一、端口隔离 以太交换网络中为了实现报文之间的二层广播域的隔离,用户通常将不同的端口加人不同的 VLAN大型网络中,业务需求种类繁多,只通过 VLAN实现报文的二层隔离,会浪费有限的VLAN资源。而采用端口隔离功能,则可…...

望繁信科技CTO李进峰受邀在上海外国语大学开展流程挖掘专题讲座
2023年,望繁信科技联合创始人兼CTO李进峰博士受邀在上海外国语大学国际工商管理学院(以下简称“上外管院”)开展专题讲座,畅谈流程挖掘的发展及对企业数字化转型的价值。演讲吸引了上外教授和来自各行各业的领军企业学员百余人。 …...

nicegui组件button用法深度解读,源代码IDE运行和调试通过
传奇开心果微博文系列 前言一、button 组件基本用法1. 最基本用法示例2. 创建带图标按钮 二、button按钮组件样式定制1. 按钮的尺寸调整2. 改变颜色示例3. 按钮的自定义字体大小4. 圆角形状示例5. 自定义边框6. 添加阴影7. 复合按钮8. 浮动按钮9. 可扩展浮动操作按钮QFAB10. 按…...
)
数据结构:树(并查集)
并查集(Union-Find Disjoint Sets 或 Disjoint Set Union,简称DSU)是一种树型的数据结构,主要用于处理一些不相交集合(Disjoint Sets)的合并及查询问题。在并查集中,通常将n个对象划分为不相交的…...

校园二手交易平台的小程序+ssm(lw+演示+源码+运行)
摘 要 随着社会的发展,社会的方方面面都在利用信息化时代的优势。互联网的优势和普及使得各种系统的开发成为必需。 本文以实际运用为开发背景,运用软件工程原理和开发方法,它主要是采用java语言技术和mysql数据库来完成对系统的设计。整个…...

代码随想录训练营第46天|回文子序列
647. 回文子串 class Solution { public:int count0;void check(string& s, int left, int right){while(left>0&&right<s.length()&&s[left]s[right]){count;left--;right;}}int countSubstrings(string s) {for(int i0; i<s.length(); i){chec…...
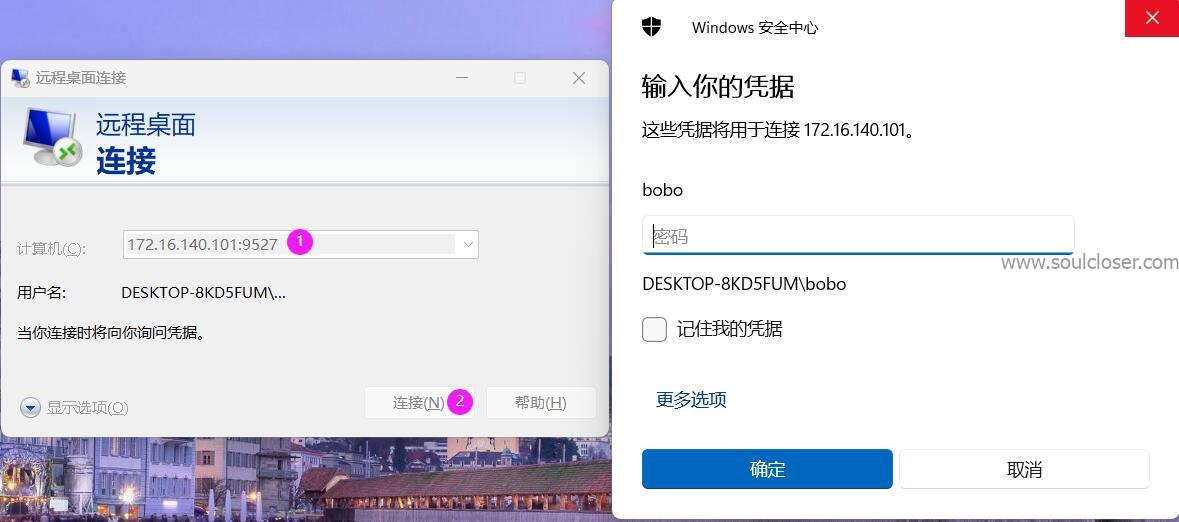
使用 PowerShell 命令更改 RDP 远程桌面端口(无需修改防火墙设置)
节选自原文:Windows远程桌面一站式指南 | BOBO Blog 原文目录 什么是RDP开启远程桌面 检查系统版本启用远程桌面连接Windows 在Windows电脑上在MAC电脑上在Android或iOS移动设备上主机名连接 自定义电脑名通过主机名远程桌面使用Hosts文件自定义远程主…...

bilibili实现批量发送弹幕功能
代码如下: import random import time import requests from tkinter import *# 弹幕内容列表 # lis_text [ # 京口瓜洲一水间,钟山只隔数重山。,君不见黄河之水天上来,奔流到海不复回。,起舞弄清影,何似在人间! # ] lis_te…...

如何查看上网记录及上网时间?5种按步操作的方法分享!【小白也能学会!】
“知己知彼,百战不殆”,在数字时代,了解自己的上网行为和时长,不仅能帮助我们更好地管理时间,还能提升工作效率和生活质量。 今天,我们就来分享五种简单易懂的方法,即便是网络小白也能轻松学会…...
Nisshinbo日清纺pvs1114太阳模拟器手测
Nisshinbo日清纺pvs1114太阳模拟器手测...
)
多线程复杂系统调试利器——assert()
调试复杂系统时,最大的难点在于定位问题,如果弄清楚了问题产生的机理,那么就能有针对性的进行解决。 调试复杂系统时,遇到不好定位的问题,就要大胆去猜、去怀疑、去假设,尤其是应该重点怀疑多线程访问&…...
【2024.9.28练习】青蛙的约会
题目描述 题目分析 由于两只青蛙都在跳跃导致变量多,不妨采用物理题中的相对运动思想,设青蛙A不动,青蛙B每次跳米,两只青蛙的距离为米。正常来说,只要模拟青蛙B与青蛙A的相对运动过程,最终当青蛙B与青蛙A距…...

Python入门:类的异步资源管理与回收( __del__ 方法中如何调用异步函数)
文章目录 📖 介绍 📖🏡 演示环境 🏡📒 文章内容 📒📝 使用上下文管理器📝 使用 `__del__` 方法📝 结合使用上下文管理器与 `__del__`📝 资源回收的重要性⚓️ 相关链接 ⚓️📖 介绍 📖 在编程中,资源的管理和回收至关重要,尤其是在处理网络请求时。频…...

Vim 调用外部命令学习笔记
Vim 外部命令集成完全指南 文章目录 Vim 外部命令集成完全指南核心概念理解命令语法解析语法对比 常用外部命令详解文本排序与去重文本筛选与搜索高级 grep 搜索技巧文本替换与编辑字符处理高级文本处理编程语言处理其他实用命令 范围操作示例指定行范围处理复合命令示例 实用技…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

Linux简单的操作
ls ls 查看当前目录 ll 查看详细内容 ls -a 查看所有的内容 ls --help 查看方法文档 pwd pwd 查看当前路径 cd cd 转路径 cd .. 转上一级路径 cd 名 转换路径 …...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

Unit 1 深度强化学习简介
Deep RL Course ——Unit 1 Introduction 从理论和实践层面深入学习深度强化学习。学会使用知名的深度强化学习库,例如 Stable Baselines3、RL Baselines3 Zoo、Sample Factory 和 CleanRL。在独特的环境中训练智能体,比如 SnowballFight、Huggy the Do…...

均衡后的SNRSINR
本文主要摘自参考文献中的前两篇,相关文献中经常会出现MIMO检测后的SINR不过一直没有找到相关数学推到过程,其中文献[1]中给出了相关原理在此仅做记录。 1. 系统模型 复信道模型 n t n_t nt 根发送天线, n r n_r nr 根接收天线的 MIMO 系…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...

网站指纹识别
网站指纹识别 网站的最基本组成:服务器(操作系统)、中间件(web容器)、脚本语言、数据厍 为什么要了解这些?举个例子:发现了一个文件读取漏洞,我们需要读/etc/passwd,如…...

代码随想录刷题day30
1、零钱兑换II 给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。 请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。 假设每一种面额的硬币有无限个。 题目数据保证结果符合 32 位带…...