RabbitMQ——消息的可靠性处理
1.业务分析
在业务的开发中,我们通常将业务的非核心业务交给MQ来处理,比如支付,在支付过后,我们需要扣减余额,修改支付单状态,修改订单状态,发送短信提醒用户,给用户增加积分等等(可能真是场景并非这么简单,这里举个例子),在这套业务中,修改订单状态,发送短信提醒用户,给用户增加积分这三个业务在特定场景下并非是核心业务,所以把他放在MQ消息队列中进行处理,在非核心业务执行的时候,可能出现多个问题,导致数据不一致,比如用户买了东西,发现自己的钱已经扣了,但是页面显示的还是未支付状态,这种情况就非常严重了,造成这个现象的原因可能有多种,比如,网络丢包,发布消息者挂了,MQ挂了,消费者挂了等等,可能有硬件层面,也可能有软件层面,甚至是网络层面,对于这一系列问题,我们应该尽量的保证消息的可靠性,让数据一致性得到保证,接下来,从三个方面进行分析,以及提出解决方案,不过具体还是得看业务需求,是否需要数据的强一致性。
2.发送者的可靠性
2-1:发送者重连
消息的发布有三个角色,发布者,MQ,消费者,在发消息的时候需要和MQ进行连接,这个连接时一个网络连接,如果因为网络问题,消息发送失败,可能会导致数据不一致产生。
解决方案:在发布者的application.yaml中配置
spring:rabbitmq:connection-timeout: 1s # 设置MQ的连接超时时间template:retry:enabled: true # 开启超时重试机制initial-interval: 1000ms # 失败后的初始等待时间multiplier: 1 # 失败后下次的等待时长倍数,下次等待时长 = initial-interval * multiplier,如果是2,第一此初始化1秒,2秒,4秒,以此类推max-attempts: 3 # 最大重试次数注意:当网络不稳定的时候,利用重试机制可以有效提高消息发送的成功率。不过SpringAMQP提供的重试机制是阻塞式的重试,也就是说多次重试等待的过程中,当前线程是被阻塞的,会影响业务性能。如果对于业务性能有要求,建议禁用重试机制。如果一定要使用,请合理配置等待时长和重试次数,当然也可以考虑使用异步线程来执行发送消息的代码。
2-2:发送者确认机制
SpringAMQP提供了Publisher Confirm和Publisher Return两种确认机制。开启确机制认后,当发送者发送消息给MQ后,MQ会返回确认结果给发送者,发送者再证实这个返回结果。返回的结果有以下几种情况:
- 消息投递到了MQ,但是路由失败。此时会通过PublisherReturn返回路由异常原因,然后返回ACK,告知投递成功
- 临时消息投递到了MQ,并且入队成功,返回ACK,告知投递成功
- 持久消息投递到了MQ,并且入队完成持久化,返回ACK,告知投递成功
- 其它情况都会返回NACK,告知投递失败

返回ACK不需要重发,NACK需要重发
在publisher模块的application.yaml中添加配置:
spring:rabbitmq:publisher-confirm-type: correlated # 开启publisher confirm机制,并设置confirm类型publisher-returns: true # 开启publisher return机制这里 publisher-confirm-type 有三种模式可选:
- none : 关闭confirm机制
- simple:同步阻塞等待MQ的回执
- correlated:MQ异步回调返回回执
一般推荐使用 correlated,回调机制。
每个RabbitTemplate只能配置一个ReturnCallback,因此我们可以在配置类中统一设置。我们在publisher模块定义一个配置类:
@Configuration
@RequiredArgsConstructor
@Slf4j
public class MqConfig {private final RabbitTemplate rabbitTemplate;@PostConstructpublic void init(){rabbitTemplate.setReturnsCallback(new RabbitTemplate.ReturnsCallback() {@Overridepublic void returnedMessage(ReturnedMessage returnedMessage) {log.error("触发returnCallback");log.debug("exchange:{}",returnedMessage.getExchange());log.debug("message:{}",returnedMessage.getMessage());log.debug("routingKey:{}",returnedMessage.getRoutingKey());log.debug("replyCode:{}",returnedMessage.getReplyCode());log.debug("replyText:{}",returnedMessage.getReplyText());}});}
}由于每个消息发送时的处理逻辑不一定相同,因此ConfirmCallback需要在每次发消息时定义。具体来说,是在调用RabbitTemplate中的convertAndSend方法时,多传递一个参数:
@RabbitListener(bindings = @QueueBinding(value = @Queue(name = "simple2.queue"),exchange = @Exchange(name = "simple2.direct"),key = "simple2"))public void testPublisherConfirmRule() {CorrelationData cd = new CorrelationData(UUID.randomUUID().toString());cd.getFuture().addCallback(new ListenableFutureCallback<CorrelationData.Confirm>() {@Overridepublic void onFailure(Throwable ex) {// Future发生异常时的处理逻辑,基本不会触发log.error("Future发生异常时的处理逻辑", ex);}@Overridepublic void onSuccess(CorrelationData.Confirm result) {if (result.isAck()){log.debug("发送消息成功,收到ACK!");}else {log.error("发送消息失败,收到NACK!");//TODO: 重发消息}}});//交换机名称String exchange = "simple2.direct";//消息String message = "hello mq";//发送消息rabbitTemplate.convertAndSend(exchange, "simple2", message, cd);}3.MQ的可靠性
在默认情况下,RabbitMQ会将接受到的消息保存在内存中以降低消息收发的延迟。这样会导致两个问题:
- 一旦MQ宕机,内存中的消息会丢失
- 内存空间有限,当消费者故障或处理过慢时,会导致消息积压,引发MQ阻塞
方案一:数据持久化
数据持久化包括三个方面:交换机持久化,队列持久化,消息持久化
SpringAMQP默认生成的交换机和队列以及发消息都是持久化的
方案二:lazy queue(既能保证并发能力,又不用写内存)
从RabbitMQ的3.6.0版本开始,就增加了LazyQueue的概念,也就是惰性队列。惰性队列的特征如下:
- 接收到消息后直接存入磁盘,不再存储到内存
- 消费者要消费消息时才会从磁盘中读取并加载到内存(可以提前缓存部分消息到内存,最多2048条)在3.12版本后,所有队列都是LazyQueue模式,无法更改。
那如何把queue变成lazy queue,可以基于声明bean的形式,也可以通过注解的方式
@Bean
public Queue lazyQueue(){return QueueBuilder.durable("lazy.queue").lazy() // 开启Lazy模式.build();
}@RabbitListener(queuesToDeclare = @Queue(name = "lazy.queue",durable = "true",arguments = @Argument(name = "x-queue-mode", value = "lazy") //这两个是固定的
))
public void listenLazyQueue(String msg){log.info("接收到 lazy.queue的消息:{}", msg);
}开启持久化和生产者确认时,RabbitMQ只有在消息持久化完成后才会给生产者返回ACK回执
4.消费者的可靠性
4-1:消费者确认机制
消费者确认机制时为了确认消费者是否成功处理消息。当消费者处理消息结束后,应该向RabbitMQ发送一个回执,告知RabbitMQ自己消息的处理状态。状态有三种:
- ack:成功的处理了消息,RabbitMQ队列中删除这个消息
- nack:消息处理失败,RabbitMQ就会再次给消费者投递消息,持续投递
- reject:消息处理失败,RabbitMQ队列中删除这个消息(一般是消息内容有问题,所以拒绝)

SpringAMQP已经实现了消息确认功能。并允许我们通过配置文件选择ACK处理方式,有三种方式:
- none:不处理。即消息投递给消费者后立刻ack,消息会立刻从MQ删除。非常不安全,不建议使用
- manual:手动模式。需要自己在业务代码中调用api,发送ack或reject,存在业务入侵,但更灵活
- auto:自动模式。SpringAMQP利用AOP对我们的消息处理逻辑做了环绕增强,当业务正常执行时则自动返回ack.当业务出现异常时,根据异常判断返回不同结果:
- 如果是业务异常,会自动返回nack
- 如果是消息处理或校验异常,自动返回reject
需要配置在消费的application.yaml中
spring:rabbitmq:listener:simple:acknowledge-mode: auto # 自动ack4-2:失败重试机制
SpringAMQP提供了消费者失败重试机制,在消费者出现异常时利用本地重试,而不是无限的requeue到mq。通过在消费者的application.yaml文件中添加配置来开启重试机制:
spring:rabbitmq:listener: # 这里注意区别,发布者有个失败重连机制和这个配置很像simple:retry:enabled: true # 开启消费者失败重试initial-interval: 1000ms # 初识的失败等待时长为1秒multiplier: 1 # 失败的等待时长倍数,下次等待时长 = multiplier * last-intervalmax-attempts: 3 # 最大重试次数stateless: true # true无状态;false有状态。如果业务中包含事务,这里改为false在开启重试模式后,重试次数耗尽,如果消息依然失败,则需要有MessageRecoverer接口来处理,它包含三种不同的实现:
- RejectAndDontRequeueRecoverer:重试耗尽后,直接reject,丢弃消息。默认是这种方式
- ImmediateRequeueMessageRecoverer:重试耗尽后,返回nack,消息重新入队
- RepublishMessageRecoverer:重试耗尽后,将失败消息投递到指定的交换机
第三种示例图

1)在consumer服务中定义处理失败消息的交换机和队列
@Bean
public DirectExchange errorMessageExchange(){return new DirectExchange("error.direct");
}
@Bean
public Queue errorQueue(){return new Queue("error.queue", true);
}
@Bean
public Binding errorBinding(Queue errorQueue, DirectExchange errorMessageExchange){return BindingBuilder.bind(errorQueue).to(errorMessageExchange).with("error");
}2)定义一个RepublishMessageRecoverer,关联队列和交换机
@Bean
public MessageRecoverer republishMessageRecoverer(RabbitTemplate rabbitTemplate){return new RepublishMessageRecoverer(rabbitTemplate, "error.direct", "error");
}完整代码:
@Configuration
@ConditionalOnProperty(name = "spring.rabbitmq.listener.simple.retry.enabled", havingValue = "true")
public class ErrorMessageConfig {@Beanpublic DirectExchange errorMessageExchange(){return new DirectExchange("error.direct");}@Beanpublic Queue errorQueue(){return new Queue("error.queue", true);}@Beanpublic Binding errorBinding(Queue errorQueue, DirectExchange errorMessageExchange){return BindingBuilder.bind(errorQueue).to(errorMessageExchange).with("error");}@Beanpublic MessageRecoverer republishMessageRecoverer(RabbitTemplate rabbitTemplate){return new RepublishMessageRecoverer(rabbitTemplate, "error.direct", "error"); //第二个参数是routingKey}
}4-3:幂等性业务
在程序开发中,是指同一个业务,执行一次或多次对业务状态的运行是一致的。
如果网络问题出现故障,有可能出现把一个业务做了多次,比如扣减库存,总不能扣减两次吧,于是可以采取对每一个消息指定一个消息id,id值唯一,然后执行完这个消息后,把这个消息id存到数据库里,然后每次执行消息的时候,可以去数据库查一下有没有这个消息,如果有,就代表这个消息之前执行过了,于是就不对这个消息做处理。
在做注册消息转换器为bean的时候,可以设置消息的id,然后我们接受消息的时候用Message来接就可以
@Bean
public MessageConverter messageConverter(){// 1.定义消息转换器Jackson2JsonMessageConverter jjmc = new Jackson2JsonMessageConverter();// 2.配置自动创建消息id,用于识别不同消息,也可以在业务中基于ID判断是否是重复消息jjmc.setCreateMessageIds(true);return jjmc;
}用Message接,然后message.getMessageProperties().getMessageId() 获取id,那这个id做业务判断就可以了。
以上是对于非幂等业务的一种方案,但明显这种方案不太好。影响mq性能。
另一种就是基于具体业务逻辑来进行判断来实现业务的幂等,比如我在一个业务执行前,先判断这个业务的一个状态,如果状态以及修改过了,我直接不做处理就行了,如果没有,我在进行修改。
5.延迟消息
5-1:死信交换机
当一个队列中的消息满足下列情况之一时,可以成为死信(dead letter):
-
消费者使用
basic.reject或basic.nack声明消费失败,并且消息的requeue参数设置为false -
消息是一个过期消息,超时无人消费
-
要投递的队列消息满了,无法投递
如果一个队列中的消息已经成为死信,并且这个队列通过dead-letter-exchange属性指定了一个交换机,那么队列中的死信就会投递到这个交换机中,而这个交换机就称为死信交换机(Dead Letter Exchange)。而此时加入有队列与死信交换机绑定,则最终死信就会被投递到这个队列中。

死信交换机有什么作用呢?
-
收集那些因处理失败而被拒绝的消息
-
收集那些因队列满了而被拒绝的消息
-
收集因TTL(有效期)到期的消息
声明正常队列和正常交换机和的时候使用bean方式,因为正常队列要指定死信交换机,
@Beanpublic Queue normalQueue(){return QueueBuilder.durable("normal.queue").deadLetterExchange("dlx.direct").build();}发送者示例代码:给正常队列设置一个TTL,如果时间到了,把消息给死信交换机,模拟延迟消息
rabbitTemplate.convertAndSend("normal.direct", "hi", "hello", new MessagePostProcessor() {@Overridepublic Message postProcessMessage(Message message) throws AmqpException {message.getMessageProperties().setExpiration("1000000"); return message;}});5-2:延迟消息插件
先去社区下载 https://blog.rabbitmq.com/posts/2015/04/scheduling-messages-with-rabbitmq
去查看RabbitMQ的插件目录对应的数据卷。
docker volume inspect mq-plugins然后进入插件那么目录
docker exec -it mq rabbitmq-plugins enable rabbitmq_delayed_message_exchange这样插件就装好了
然后声明一个延迟交换机,基于注解方式
@RabbitListener(bindings = @QueueBinding(value = @Queue(name = "delay.queue", durable = "true"),exchange = @Exchange(name = "delay.direct", delayed = "true"),key = "delay"
))
public void listenDelayMessage(String msg){log.info("接收到delay.queue的延迟消息:{}", msg);
}基于bean方式
@Bean
public DirectExchange delayExchange(){return ExchangeBuilder.directExchange("delay.direct") // 指定交换机类型和名称.delayed() // 设置delay的属性为true.durable(true) // 持久化.build();
}发送延迟消息:
@Test
void testPublisherDelayMessage() {// 1.创建消息String message = "hello, delayed message";// 2.发送消息,利用消息后置处理器添加消息头rabbitTemplate.convertAndSend("delay.direct", "delay", message, new MessagePostProcessor() {@Overridepublic Message postProcessMessage(Message message) throws AmqpException {// 添加延迟消息属性message.getMessageProperties().setDelay(5000);return message;}});
}注意:
延迟消息插件内部会维护一个本地数据库表,同时使用Elang Timers功能实现计时。如果消息的延迟时间设置较长,可能会导致堆积的延迟消息非常多,会带来较大的CPU开销,同时延迟消息的时间会存在误差。
因此,不建议设置延迟时间过长的延迟消息。
相关文章:
RabbitMQ——消息的可靠性处理
1.业务分析 在业务的开发中,我们通常将业务的非核心业务交给MQ来处理,比如支付,在支付过后,我们需要扣减余额,修改支付单状态,修改订单状态,发送短信提醒用户,给用户增加积分等等&am…...

babylon.js-1:入门篇
最近项目中使用到了 Babylon.js 这门技术,从今天开始,抽取自己写的比较好的拿出来,作为分享案例: 记录学习成果通过笔记的方式记录技术积累方便工作中查找翻阅实现案例 是什么 Babylon.js是一个基于WebGL的开源3D渲染引擎&…...

VS Code调整字体大小
##在工程目录底下.vscode/settings.json添加设置参数 {"editor.fontSize": 15,"window.zoomLevel": 1.5 }...

Python基础语句教学
Python是一种高级的编程语言,由Guido van Rossum于1991年创建。它以简单易读的语法和强大的功能而闻名,被广泛用于科学计算、Web开发、数据分析等领域。 Python的应用领域广泛,可以用于开发桌面应用程序、Web应用、游戏、数据分析、人工智能等…...

ansible 配置
目录 1.集群自动化维护工具 ansible 2.ansible管理架构 3.安装ansible 4.Iventory主机模式 5.通过ping验证 6.ansible常用模块 7.命令行模块 7.1command模块 7.2shell模块 7.3scripts模块 7.4file模块 7.5copy模块 7.6yum模块 1.集群自动化维护工具 ansibl…...

堆排序算法详解:原理与Python实现
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「storm…...

[论文阅读] ChartInstruct: Instruction Tuning for Chart Comprehension and Reasoning
原文链接:http://arxiv.org/abs/2403.09028 源码链接:https://github.com/vis-nlp/ChartInstruct 启发:本文构建的instruction-tuning数据集以及使用该数据集对模型进行微调的过程都值得学习。 Abstract 研究对象:图表 研究…...

基于springboot+vue学生宿舍管理系统设计与实现
博主介绍:专注于Java vue .net php phython 小程序 等诸多技术领域和毕业项目实战、企业信息化系统建设,从业十五余年开发设计教学工作 ☆☆☆ 精彩专栏推荐订阅☆☆☆☆☆不然下次找不到哟 我的博客空间发布了1000毕设题目 方便大家学习使用 感兴趣的…...

【Android】模糊搜索与数据处理
【Android】模糊搜索与数据处理 本篇博客主要以根据输入内容动态获取城市为例进行讲解。 获取城市 这一部分主要是根据输入的信息去动态获取城市信息 首先定义了一个名为 NetUtil 的类,主要用于通过 HTTP 请求获取城市信息。 public class NetUtil {private stat…...

机器学习-KNN
KNN:K最邻近算法(K-Nearest Neighbor,KNN) 用特征空间中距离待分类对象的最近的K个样例点的类别来预测。 投票法:K 个样例的对数类别。 k1:最近邻分类 k 通常是奇数(因为我们根据这个K数据判断类别,如果…...

python 安装包 site-packages
1. site-packages 文件夹的位置 当我们通过 pip 或其他方式安装一个 Python 包时,这些包的文件就会被复制到 site-packages 文件夹下。 site-packages 文件夹通常位于 Python 的安装目录下的 Lib 文件夹内。具体的路径会根据你使用的操作系统和 Python 版本的不同而…...

大数据-151 Apache Druid 集群模式 配置启动【上篇】 超详细!
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完)HDFS(已更完)MapReduce(已更完&am…...

CentOS8.5.2111(3)实验之DHCP服务器架设
一、实验目标 1.掌握DHCP服务器的主配置文件各项申明参数及操作及其含义 2. 具备DHCP 服务器、中继服务器的配置能力 3. 具备测试客户端正常获取服务器分配地址的能力 4. 具备DHCP服务器故障排除能力 二、实训原理/流程 (一)项目背景 …...
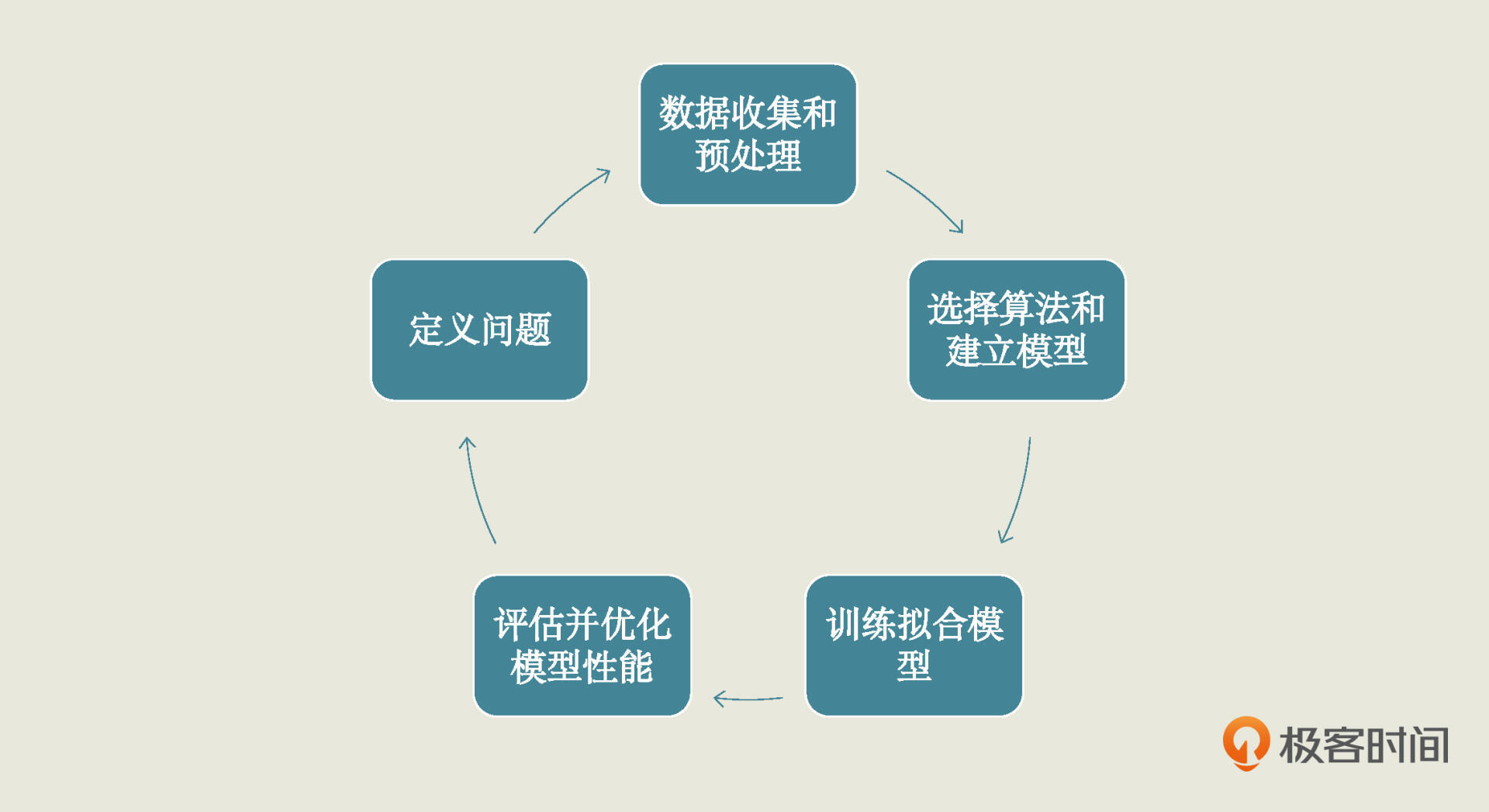
机器学习(4):机器学习项目步骤(一)——定义问题
1. 机器学习项目的五大步骤 定义问题 收集数据和预处理 选择算法和确定模型 训练拟合模型 评估优化模型性能 2. 定义问题的主要任务 刨析业务场景,设定清晰目标,同时还要确定当前问题属于哪一种机器学习类型。 3. “易速鲜花”项目案例 项目任务&a…...

C#中Socket通信常用的方法
创建Socket 在C#中创建一个Socket对象的基本步骤如下: 引入命名空间: 首先,确保你的文件顶部包含了以下命名空间的引用: using System.Net; using System.Net.Sockets; 创建Socket实例: 你可以创建一个Socket实例&am…...

【JavaEE】——单例模式引起的多线程安全问题:“饿汉/懒汉”模式,及解决思路和方法(面试高频)
阿华代码,不是逆风,就是我疯,你们的点赞收藏是我前进最大的动力!!希望本文内容能够帮助到你! 目录 一:单例模式(singleton) 1:概念 二:“饿汉模…...

huggingface实现中文文本分类
目录 1 自定义数据集 2 分词 2.1 重写collate_fn方法 3 用BertModel加载预训练模型 4 模型试算 5 定义下游任务 6 训练 7 测试 #导包 import torch from datasets import load_from_disk #用于加载本地磁盘的datasets文件 1 自定义数据集 #自定义数据集 #…...
基于python+控制台+txt文档实现学生成绩管理系统(含课程实训报告)
目录 第一章 需求分析 第二章 系统设计 2.1 系统功能结构 2.1.1 学生信息管理系统的七大模块 2.1.2 系统业务流程 2.2 系统开发必备环境 第三章 主函数设计 3.1 主函数界面运行效果图 3.2 主函数的业务流程 3.3 函数设计 第四章 详细设计及实现 4.1 学生信息录入模块的设计与实…...

Spring Boot 整合MyBatis-Plus 实现多层次树结构的异步加载功能
文章目录 1,前言2,什么是多层次树结构?3,异步加载的意义4,技术选型与实现思路5,具体案例5.1,项目结构5.2,项目配置(pom.xml)5.3,配置文件…...

网络工程师指南:防火墙配置与管理命令大全,零基础入门到精通,收藏这一篇就够了
本指南详细介绍了防火墙的配置与管理命令,涵盖了防火墙的工作原理、常见配置命令、安全策略与访问控制、日志管理与故障排查,并通过实战案例展示了如何有效防御网络攻击。通过学习本指南,网络工程师能够系统掌握防火墙的配置与管理技能&#…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

pam_env.so模块配置解析
在PAM(Pluggable Authentication Modules)配置中, /etc/pam.d/su 文件相关配置含义如下: 配置解析 auth required pam_env.so1. 字段分解 字段值说明模块类型auth认证类模块,负责验证用户身份&am…...

《用户共鸣指数(E)驱动品牌大模型种草:如何抢占大模型搜索结果情感高地》
在注意力分散、内容高度同质化的时代,情感连接已成为品牌破圈的关键通道。我们在服务大量品牌客户的过程中发现,消费者对内容的“有感”程度,正日益成为影响品牌传播效率与转化率的核心变量。在生成式AI驱动的内容生成与推荐环境中࿰…...

【Go】3、Go语言进阶与依赖管理
前言 本系列文章参考自稀土掘金上的 【字节内部课】公开课,做自我学习总结整理。 Go语言并发编程 Go语言原生支持并发编程,它的核心机制是 Goroutine 协程、Channel 通道,并基于CSP(Communicating Sequential Processes࿰…...

HTML前端开发:JavaScript 常用事件详解
作为前端开发的核心,JavaScript 事件是用户与网页交互的基础。以下是常见事件的详细说明和用法示例: 1. onclick - 点击事件 当元素被单击时触发(左键点击) button.onclick function() {alert("按钮被点击了!&…...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...