【JavaSE系列】IO流
目录
前言
一、IO流概述
二、IO流体系结构
三、File相关的流
1. FileInputStream
2. FileOutputStream
3. FileReader
4. FileWriter
四、缓冲流
五、转换流
1. InputStreamReader
2. OutputStreamWriter
六、数据流
七、对象流
八、打印流
九、标准输入输出流
十、压缩和解压缩流
十一、字节数组流
1. 基本使用
2. 对象克隆
总结
前言
在Java编程中,输入输出(I/O)操作是处理数据流的核心部分。无论是从文件读取数据、将数据写入到磁盘,还是通过网络进行通信,都需要使用I/O流来实现。Java提供了丰富的I/O流类库,它们不仅能够高效地处理各种类型的数据,还提供了灵活的方式来装饰和扩展这些基本功能。本篇博客旨在介绍Java I/O流的基础知识,包括其分类、体系结构以及如何使用不同类型的流来完成日常开发中的常见任务。
一、IO流概述
IO流指的是程序中数据的流动。数据可以从内存流动到硬盘,也可以从硬盘流动到内存。 Java中IO流最基本的作用是完成文件的读和写。

根据数据流向分为输入流和输出流,输入和输出是相对于内存而言的。 输入流指的是从硬盘到内存(输入又叫做读:read) ;输出流指的是从内存到硬盘(输出又叫做写:write)。根据读写数据形式分为字节流和字符流。字节流指的是一次读取一个字节,适合读取非文本数据,例如图片、声音、视频等文件;字符流指的是一次读取一个字符,只适合读取普通文本,不适合读取二进制文件。
注意:Java的所有IO流中凡是以Stream结尾的都是字节流。凡是以Reader和Writer结尾的都是字符流。
根据流在IO操作中的作用和实现方式来分类可以分为节点流和处理流。 节点流负责数据源和数据目的地的连接,是IO中最基本的组成部分;处理流对节点流进行装饰/包装,提供更多高级处理操作,方便用户进行数据处理。
二、IO流体系结构

三、File相关的流
1. FileInputStream
文件字节输入流,可以读取任何文件。使用FileInputStream读取的文件中有中文时,有可能读取到中文某个汉字的一半,在将byte[]数组转换为String时可能出现乱码问题,因此FileInputStream不太适合读取纯文本。FileInputStream常用方法如下:
| 方法 | 描述 |
|---|---|
| FileInputStream(String name); | 构造方法,创建一个文件字节输入流对象,参数是文件的路径 |
| int read(); | 从文件读取一个字节(8个二进制位),返回值读取到的字节本身,如果读不到任何数据返回-1 |
| int read(byte[] b); | 一次读取多个字节,如果文件内容足够多,则一次最多读取b.length个字节。返回值是读取到字节总数。如果没有读取到任何数据,则返回 -1 |
| int read(byte[] b, int off, int len); | 读到数据后向byte数组中存放时,从off开始存放,最多读取len个字节。读取不到任何数据则返回 -1 |
| long skip(long n); | 跳过n个字节 |
| int available(); | 返回流中剩余的估计字节数量 |
| void close() | 关闭流 |
下面我们在某一路径下创建一个1.txt的文件,在其中写入一串英文字符串,如下图所示:

我们可以使用FileInputStream一个字节一个字节地读取我们写好的txt文件,代码如下:
public void testFileInputStream() throws IOException {FileInputStream fis = null;try {fis = new FileInputStream("D:\\Code\\study\\JavaCode\\JavaSEDemo\\base\\src\\main\\java\\cn\\javase\\base\\io\\1.txt");int readByte;while ((readByte = fis.read()) != -1) {System.out.print((char) readByte);}} catch (IOException e) {throw new RuntimeException(e);} finally {if (fis != null) {fis.close();}}
}我们也可以每次读取多个字节,代码如下:
public void testFileInputStream2() throws IOException {FileInputStream fis = null;try {fis = new FileInputStream("D:\\Code\\study\\JavaCode\\JavaSEDemo\\base\\src\\main\\java\\cn\\javase\\base\\io\\1.txt");byte[] bytes = new byte[fis.available()];int readBytes;while ((readBytes = fis.read(bytes)) != -1) {String str = new String(bytes, 0, readBytes);System.out.print(str);}} catch (IOException e) {throw new RuntimeException(e);} finally {if (fis != null) {fis.close();}}
}两者的运行结果均如下:

2. FileOutputStream
FileOutputStream 是文件字节输出流。常用方法如下:
| 方法 | 描述 |
|---|---|
| FileOutputStream(String name); | 构造方法,创建输出流,先将文件清空,再不断写入 |
| FileOutputStream(String name, boolean append); | 构造方法,创建输出流,在原文件最后面以追加形式不断写入 |
| write(int b); | 写一个字节 |
| void write(byte[] b); | 将字节数组中所有数据全部写出 |
| void write(byte[] b, int off, int len); | 将字节数组的一部分写出 |
| void close() | 关闭流 |
| void flush() | 刷新 |
下面是一个示例:
public void testFileOutputStream() {FileOutputStream fos = null;try {fos = new FileOutputStream("D:\\Code\\study\\JavaCode\\JavaSEDemo\\base\\src\\main\\java\\cn\\javase\\base\\io\\2.txt");String str = "aBcDeFgH";fos.write(str.getBytes());fos.flush();} catch (IOException e) {throw new RuntimeException(e);} finally {if (fos != null) {try {fos.close();} catch (IOException e) {e.printStackTrace();}}}
}运行结果如下图所示:

下面我们利用上面的FileInputStream和FileOutputStram来实现文件复制,这边我复制的是一个视频文件,具体代码如下所示:
public void testFileOutputStream2() throws FileNotFoundException {String uri = "D:\\Code\\study\\JavaCode\\JavaSEDemo\\base\\src\\main\\java\\cn\\javase\\base\\io\\video.mp4"; // 定义资源路径FileInputStream fis = new FileInputStream(uri);FileOutputStream fos = new FileOutputStream(uri.replace("video", "video_copy"));byte[] bytes = new byte[1024]; // 每次读取1KBint len;try {while ((len = fis.read(bytes)) != -1) {;fos.write(bytes, 0, len);}fos.flush();} catch (IOException e) {throw new RuntimeException(e);} finally {try {fis.close();fos.close();} catch (IOException e) {throw new RuntimeException(e);}}
}运行结果如下图所示,可以看到拷贝后的文件与拷贝前的文件大小相同,说明拷贝没有问题。


补充:我们在使用流的时候,需要手动关闭流,每次这样比较麻烦,代码结构看起来也比较混乱。Java7提供了一个try-with-resources新特性,可以自动关闭资源(凡是实现了AutoCloseable接口的流都可以使用try-with-resources,都会自动关闭)。try-with-resources语法格式如下:
try (ResourceType resource1 = new ResourceType(...);ResourceType2 resource2 = new ResourceType2(...)) {// 使用资源的代码 } catch (ExceptionType1 e1) {// 异常处理代码 } catch (ExceptionType2 e2) {// 另一个异常处理代码 } finally {// 可选的 finally 块 }
3. FileReader
FileReader是文件字符输入流,默认采用UTF-8读取文件,一次读取至少一个字符,与FileInputStream类似,不同的是,FileReader读取的是char,FileInputStream读取的是byte。FileReader常用方法如下所示:
| 方法 | 描述 |
|---|---|
| FileReader(String fileName); | 构造方法 |
| int read(); | 读取一个字符 |
| int read(char[] cbuf); | 读取一个字符数组 |
| int read(char[] cbuf, int off, int len); | 读取某个区间的字符数组 |
| long skip(long n); | 跳过n个字符 |
| void close() | 关闭流 |
下面是一个示例代码:
public void testReadFile() throws FileNotFoundException {try(FileReader fileReader = new FileReader("D:\\Code\\study\\JavaCode\\JavaSEDemo\\base\\src\\main\\java\\cn\\javase\\base\\io\\_01_File相关的流\\汉字.txt")) {char[] chars = new char[2];int len;while ((len = fileReader.read(chars)) != -1) {System.out.print(new String(chars, 0, len));}} catch (IOException e) {System.out.println(e.getMessage());}
}运行结果如下图所示:

4. FileWriter
FileWriter是文件字符输出流,默认采用UTF-8,用于对普通文本文件进行输出,常用的方法如下所示:
| 方法 | 描述 |
|---|---|
| FileWriter(String fileName); | 构造方法 |
| FileWriter(String fileName, boolean append); | 构造方法 |
| void write(char[] cbuf); | 写字符数组 |
| void write(char[] cbuf, int off, int len); | 将字符数组的某个区间写出 |
| void write(String str); | 写字符串 |
| void write(String str, int off, int len); | 将字符串的某个区间写出 |
| void flush(); | 刷新 |
| void close(); | 关闭流 |
| Writer append(CharSequence csq, int start, int end); | 追加文本 |
下面是一个使用示例:
public void testFileWriter() {try(FileWriter fileWriter = new FileWriter("D:\\Code\\study\\JavaCode\\JavaSEDemo\\base\\src\\main\\java\\cn\\javase\\base\\io\\_01_File相关的流\\文本输出.txt")) {fileWriter.write("Hello World!");fileWriter.write("I'm a file writer.", 0, 10);fileWriter.write("\n人生如戏,喝不喝Java".toCharArray());fileWriter.write("\n人生如戏,喝不喝Java".toCharArray(), 0, 5);fileWriter.flush();} catch (IOException e) {throw new RuntimeException(e);}
}运行结果如下图所示:

补充: 上述读取或者写出文件的时候,我们采用的是绝对路径,除了使用绝对路径,我们还可以使用相对路径和资源文件夹的路径。相对路径指的是从整个项目目录下开始的路径,资源文件夹路径在Maven结构下指的是resources目录下开始的路径,有关这两个路径的使用,如下图所示,可以帮助大家更好地理解:

四、缓冲流
缓冲流读写速度快,能够提高读写的效率,与上面提到的四种流对应的缓冲流有BufferedInputStream、BufferedOutputStream(适合读写非普通文本文件)、 BufferedReader和BufferedWriter(适合读写普通文本文件)。缓冲流都是处理流/包装流,FileInputStream和FileOutputStream是节点流。
缓冲流的读写速度快,原理是:在内存中准备了一个缓存。读的时候从缓存中读。写的时候将缓存中的数据一次写出。都是在减少和磁盘的交互次数。如何理解缓冲区?家里盖房子,有一堆砖头要搬在工地100米外,单字节的读取就好比你一个人每次搬一块砖头,从堆砖头的地方搬到工地,这样肯定效率低下。然而聪明的人类会用小推车,每次先搬砖头搬到小车上,再利用小推车运到工地上去,这样你再从小推车上取砖头是不是方便多了呀!这样效率就会大大提高,缓冲流就好比我们的小推车,给数据暂时提供一个可存放的空间。那么,缓冲流的输出效率是如何提高的?在缓冲区中先将字符数据存储起来,当缓冲区达到一定大小或者需要刷新缓冲区时,再将数据一次性输出到目标设备。输入效率是如何提高的? read()方法从缓冲区中读取数据。当缓冲区中的数据不足时,它会自动从底层输入流中读取一定大小的数据,并将数据存储到缓冲区中。大部分情况下,我们调用read()方法时,都是从缓冲区中读取,而不需要和硬盘交互。下面是一个创建缓冲流的示例代码:
public static void main(String[] args) throws IOException {FileInputStream fis = new FileInputStream("relative.txt");BufferedInputStream bis = new BufferedInputStream(fis);System.out.println(bis);bis.close();
}从上面可以看到,我们关闭流只需要关闭最外层的处理流即可。当关闭处理流时,底层节点流也会关闭。下面,我们将测试一下节点流和缓冲流的效率,进行一下对比。这里,我采用的是拷贝司马相如的《上林赋》,具体代码如下图所示:
public static void main(String[] args) {String inputUrl = "D:\\Code\\study\\JavaCode\\JavaSEDemo\\base\\src\\main\\java\\cn\\javase\\base\\io\\_02_缓冲流\\效率测试文本-上林赋.txt";String outputUrl = inputUrl.replace("上林赋", "上林赋_copy");try(FileInputStream fileInputStream = new FileInputStream(inputUrl);FileOutputStream fileOutputStream = new FileOutputStream(outputUrl);BufferedInputStream bufferedInputStream = new BufferedInputStream(fileInputStream);BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(fileOutputStream)) {/* 使用节点流 */long begin = System.currentTimeMillis();int readByte;while ((readByte = fileInputStream.read()) != -1) {fileOutputStream.write(readByte);}fileOutputStream.flush();long end = System.currentTimeMillis();System.out.println("使用节点流耗时:" + (end - begin) + "ms");/* 使用缓冲流 */begin = System.currentTimeMillis();while ((readByte = bufferedInputStream.read()) != -1) {bufferedOutputStream.write(readByte);}bufferedOutputStream.flush();end = System.currentTimeMillis();System.out.println("使用缓冲流耗时:" + (end - begin) + "ms");} catch (IOException e) {throw new RuntimeException(e);}
}运行结果如下图所示,可以看到缓冲流的效率比节点流要高很多。

补充:缓冲流的有两个特有方法(输入流),以下两个方法的作用是允许我们在读取数据流时回退到原来的位置(重复读取数据时用)
方法一:void mark(int readAheadLimit); 标记位置(在Java21版本中,参数无意义。低版本JDK中参数表示在标记处最多可以读取的字符数量,如果你读取的字符数超出的上限值,则调用reset()方法时出现IOException)
方法二:void reset(); 重新回到上一次标记的位置 这两个方法有先后顺序:先mark再reset,另外这两个方法不是在所有流中都能用。有些流中有这个方法,但是不能用。
五、转换流
转换流主要用来解决编解码中出现的乱码问题。
1. InputStreamReader
InputStreamReader为转换流,属于字符流,作用是将文件中的字节转换为程序中的字符。转换过程是一个解码的过程,主要用来解决读的乱码问题。那么,乱码问题是如何产生的呢?当我们指定的字符集和文件的字符集不一样时就有可能出现乱码。InputStreamReader常用的构造方法有两个:
- InputStreamReader(InputStream in, String charsetName) // 指定字符集
- InputStreamReader(InputStream in) // 采用平台默认字符集
FileReader是InputStreamReader的子类,而InputStreamReader是包装流,所以FileReader也是包装流。 FileReader的出现简化了代码的编写,以下代码本质上是一样的:
Reader reader = new InputStreamReader(new FileInputStream(“file.txt”)); //采用平台默认字符集
Reader reader = new FileReader(“file.txt”); //采用平台默认字符集下面是指定字符集的情况:
Reader reader = new InputStreamReader(new FileInputStream(“file.txt”), “GBK”);
Reader reader = new FileReader("e:/file1.txt", Charset.forName("GBK"));2. OutputStreamWriter
OutputStreamWriter是转换流,属于字符流,作用是将程序中的字符转换为文件中的字节。这个过程是一个编码的过程。OutputStreamWriter常用构造方法有两个:
- OutputStreamWriter(OutputStream out, String charsetName) // 使用指定的字符集
- OutputStreamWriter(OutputStream out) //采用平台默认字符集
与InputStreamReader类似,FileWriter是InputStreamReader的子类,以下代码本质是一样的:
Writer writer = new OutputStreamWriter(new FileOutputStream(“file1.txt”), “GBK”);
Writer writer = new FileWriter(“file1.txt”, Charset.forName(“GBK”));六、数据流
有两个类与数据流有关,为DataOutputStream和DataInputStream,这两个流都是包装流,读写数据专用的流。DataOutputStream直接将程序中的数据写入文件,不需要转码,效率高。程序中是什么样子,原封不动的写出去。写完后,文件是打不开的。即使打开也是乱码,文件中直接存储的是二进制。 使用DataOutputStream写的文件,只能使用DataInputStream去读取。并且读取的顺序需要和写入的顺序一致,这样才能保证数据恢复原样。两者的构造方法如下:
- DataInputStream(InputStream in)
- DataOutputStream(OutputStream out)
DataOutputStream写的方法如下有writeByte()、writeShort()、writeInt()、writeLong()、writeFloat()、writeDouble()、writeBoolean()、writeChar()、writeUTF(String) ;DataOutputStream读的方法有readByte()、readShort()、readInt()、readLong()、readFloat()、readDouble()、readBoolean()、readChar()、readUTF()。下面是一个示例代码:
public static void main(String[] args) throws Exception {String path = "D:\\Code\\study\\JavaCode\\JavaSEDemo\\base\\src\\main\\java\\cn\\javase\\base\\io\\_04_数据流\\1.txt";DataOutputStream dos = new DataOutputStream(new FileOutputStream(path));int a = 10;double b = 3.144;dos.writeInt(a);dos.writeDouble(b);dos.flush();dos.close();DataInputStream dis = new DataInputStream(new FileInputStream(path));System.out.println(dis.readInt());System.out.println(dis.readDouble());dis.close();}运行结果如下图所示:

七、对象流
ObjectOutputStream和ObjectInputStream这两个流,可以完成对象的序列化和反序列化,两者是包装流,其中,ObjectOutputStream用来完成对象的序列化,ObjectInputStream用来完成对象的反序列化。 序列化(Serial)指的是将Java对象转换为字节序列。反序列化(DeSerial)指的是将字节序列转换为Java对象。参与序列化和反序列化的java对象必须实现实现Serializable接口,编译器会自动给该类添加序列化版本号的属性serialVersionUID。如果某对象没有实现该接口就进行序列化,编译器会报如下错误:

在java中,是通过“类名 + 序列化版本号”来进行类的区分的。 serialVersionUID实际上是一种安全机制。在反序列化的时候,JVM会去检查存储Java对象的文件中的class的序列化版本号是否和当前Java程序中的class的序列化版本号是否一致。如果一致则可以反序列化。如果不一致则报错。 如果一个类实现了Serializable接口,还是建议将序列化版本号固定死,建议显示的定义出来,原因是:类有可能在开发中升级(改动),升级后会重新编译,如果没有固定死,编译器会重新分配一个新的序列化版本号,导致之前序列化的对象无法反序列化。
显示定义序列化版本号的语法:private static final long serialVersionUID = XXL;
为了保证显示定义的序列化版本号不会写错,建议使用 @java.io.Serial 注解进行标注。并且使用它还可以帮助我们随机生成序列化版本号。 如果我们希望某个属性不参与序列化,需要使用瞬时关键字transient修饰。下面是一个代码示例:
public void test() throws IOException, ClassNotFoundException {String path = "D:\\Code\\study\\JavaCode\\JavaSEDemo\\base\\src\\main\\java\\cn\\javase\\base\\io\\_05_对象流\\object";// 写对象ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(path));Student stu = new Student("张三", 23);oos.writeObject(stu);oos.flush();oos.close();// 读对象ObjectInputStream ois = new ObjectInputStream(new FileInputStream(path));Student object = (Student)ois.readObject();System.out.println(object.getAge() + object.getName() + object.getGender());
}其中提到的Student类如下图所示:
/*** 学生类*/
public class Student implements Serializable {@Serialprivate static final long serialVersionUID = 7826613280278208564L;private String name;private transient int age;private String gender;public Student() {}public Student(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public String getGender() {return gender;}public void setGender(String gender) {this.gender = gender;}}运行结果如下图所示:

更多序列化与反序列化的知识可以参考这篇博文:序列化与反序列化详解_java序列化和反序列化-CSDN博客
八、打印流
打印流有PrintStream和PrintWriter,其中PrintStream以字节形式打印,PrintWriter以字符形式打印。下面是一个示例代码:
public void test() throws FileNotFoundException {String path = "D:\\Code\\study\\JavaCode\\JavaSEDemo\\base\\src\\main\\java\\cn\\javase\\base\\io\\_06_打印流\\info.log";PrintStream printStream = new PrintStream(path); // PrintStream是包装流 printStream.append("你好");printStream.close();PrintWriter printWriter = new PrintWriter(path.replace("log", "log1")); // PrintWriter 是包装流 printWriter.append("你好abc");printWriter.close();
}运行结果如下图所示:

九、标准输入输出流
System.in获取到的InputStream就是一个标准输入流,标准输入流是用来接收用户在控制台上的输入的。标准输入流不需要关闭,它是一个系统级的全局的流,JVM负责最后的关闭。我们可以使用BufferedReader对标准输入流进行包装。这样可以方便的接收用户在控制台上的输入(这种方式太麻烦了,因此JDK中提供了更好用的Scanner)。我们可以修改输入流的方向(System.setIn()),让其指向文件。
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String s = br.readLine();System.out获取到的PrintStream就是一个标准输出流,标准输出流是用来向控制台上输出的。标准输出流不需要关闭,它是一个系统级的全局的流,JVM负责最后的关闭。 我们可以修改输出流的方向(System.setOut())。让其指向文件。
十、压缩和解压缩流
在IO体系中,有不同的压缩和解压缩流,这里以GZIPOutputStream(压缩)和GZIPInputStream(解压缩)为例,下面是压缩流的示例代码:
public static void main(String[] args) throws IOException {String path = "D:\\Code\\study\\JavaCode\\JavaSEDemo\\base\\src\\main\\java\\cn\\javase\\base\\io\\_07_压缩和解压缩流\\待压缩文本.txt";FileInputStream fileInputStream = new FileInputStream(path);GZIPOutputStream gzipOutputStream = new GZIPOutputStream(new FileOutputStream(path.replace("待压缩文本.txt", "待压缩文本.txt.gz")));byte[] buffer = new byte[1024];int read;while ((read = fileInputStream.read(buffer)) != -1) {gzipOutputStream.write(buffer, 0, read);}gzipOutputStream.finish(); // 在压缩完所有数据之后调用finish()方法,以确保所有未压缩的数据都被刷新到输出流中,并生成必要的 Gzip 结束标记,标志着压缩数据的结束。fileInputStream.close();gzipOutputStream.close();
} 运行结果如下,可以看到在指定的目录下生成了一个压缩文件。
下面是对应的解压缩的代码:
public static void main(String[] args) throws IOException {String path ="D:\\Code\\study\\JavaCode\\JavaSEDemo\\base\\src\\main\\java\\cn\\javase\\base\\io\\_07_压缩和解压缩流\\待压缩文本.txt.gz";GZIPInputStream gzipInputStream = new GZIPInputStream(new FileInputStream(path));FileOutputStream fileOutputStream = new FileOutputStream(path.replace("待压缩文本.txt.gz", "解压缩文本.txt"));byte[] buffer = new byte[1024];int len;while ((len = gzipInputStream.read(buffer)) != -1) {fileOutputStream.write(buffer, 0, len);}gzipInputStream.close();fileOutputStream.flush();fileOutputStream.close();
}运行结果如下,我们压缩后的文件重新解压缩回来了。

补充:实际上所有的输出流中,只有带有缓冲区的流才需要手动刷新,节点流是不需要手动刷新的,节点流在关闭的时候会自动刷新。
十一、字节数组流
1. 基本使用
ByteArrayInputStream和ByteArrayOutputStream都是内存操作流,不需要打开和关闭文件等操作。这些流是非常常用的,可以将它们看作开发中的常用工具,能够方便地读写字节数组、图像数据等内存中的数据。 ByteArrayInputStream和ByteArrayOutputStream都是节点流。 ByteArrayOutputStream,将数据写入到内存中的字节数组当中;ByteArrayInputStream,读取内存中某个字节数组中的数据。下面是一个示例代码:
public void test2() throws IOException {ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream(); // 是节点流,默认byte数组大小为32ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream);objectOutputStream.writeLong(3000L);objectOutputStream.writeBoolean(true);objectOutputStream.writeBoolean(false);objectOutputStream.writeUTF("人生如戏");objectOutputStream.flush();objectOutputStream.close();byte[] byteArray = byteArrayOutputStream.toByteArray(); // 转为byte数组ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(byteArray);ObjectInputStream objectInputStream = new ObjectInputStream(byteArrayInputStream);System.out.println(objectInputStream.readLong());System.out.println(objectInputStream.readBoolean());System.out.println(objectInputStream.readBoolean());System.out.println(objectInputStream.readUTF());objectInputStream.close();
}运行结果如下图所示:

2. 对象克隆
对象克隆参考博文:Java中对象的克隆_java 对象克隆-CSDN博客
我们除了重写clone()方法来完成对象的深克隆,也使用字节数组流也可以完成对象的深克隆。 原理是将要克隆的Java对象写到内存中的字节数组中,再从内存中的字节数组中读取对象,读取到的对象就是一个深克隆。 下面是一个示例代码:
public static void main(String[] args) throws IOException, ClassNotFoundException {User user = new User("张三", 23);ByteArrayOutputStream bos = new ByteArrayOutputStream();ObjectOutputStream oos = new ObjectOutputStream(bos);oos.writeObject(user);oos.flush();oos.close();ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());ObjectInputStream ois = new ObjectInputStream(bis);User user1 = (User) ois.readObject();user1.setName("李四");user1.setAge(11);System.out.println(user.getAge() + user.getName());System.out.println(user1.getAge() + user1.getName());ois.close();
}运行结果如下图所示,修改克隆后对象中的值,原来的对象中的值没有改变,说明这是一个深克隆。

小结一下对象克隆的方法:
- 调用Object的clone方法,默认是浅克隆,需要深克隆的话,就需要重写clone方法。
- 可以通过序列化和反序列化完成对象的克隆。
- 可以通过ByteArrayInputStream和ByteArrayOutputStream完成深克隆。
总结
通过本文的详细介绍,我们对Java I/O流有了更深入的理解。从最基本的节点流到复杂的处理流,Java为我们提供了一套强大而灵活的工具集,使得我们可以轻松地处理各种数据流。无论是字节流还是字符流,缓冲流或是转换流,每种流都有其独特的用途和优势。掌握这些知识点不仅可以帮助我们在日常开发中更加得心应手,还能让我们在面对复杂问题时游刃有余。希望这篇博客能成为你学习Java I/O流的一个良好起点,并激发你进一步探索这一领域的兴趣。
相关文章:
【JavaSE系列】IO流
目录 前言 一、IO流概述 二、IO流体系结构 三、File相关的流 1. FileInputStream 2. FileOutputStream 3. FileReader 4. FileWriter 四、缓冲流 五、转换流 1. InputStreamReader 2. OutputStreamWriter 六、数据流 七、对象流 八、打印流 九、标准输入输出流…...

深入探讨在线教育系统源码:搭建知识付费平台实战方案详解
知识付费平台是软件开发行业内炙手可热的项目,其受众群体非常广,也是很多小伙伴提问比较多的,今天小编将从在线教育系统源码开始,为大家讲解一个知识付费平台的搭建开发实战方案。 一、系统架构设计 搭建在线教育系统需考虑以下几…...

前端全屏模式切换
前端全屏模式切换 const isBigScreen ref(false) const handleScreen () > {if (isBigScreen.value) {document.exitFullscreen()isBigScreen.value false} else {isBigScreen.value truedocument.documentElement.requestFullscreen() // 请求全屏模式} }...

构建高可用和高防御力的云服务架构第二部分:SLB负载均衡(2/5)
在现代云服务中,负载均衡(Load Balancing)是一种关键技术,用于优化资源利用、最小化响应时间、提高系统的可伸缩性和可靠性。负载均衡器位于客户端和服务器之间,根据预设的策略将请求分发到多个服务器上,以…...

计算机毕业设计Python+Spark知识图谱微博舆情预测 微博推荐系统 微博可视化 微博数据分析 微博大数据 微博爬虫 Hadoop 大数据毕业设计
《PythonSpark知识图谱微博舆情预测》开题报告 一、课题背景与意义 随着互联网技术的飞速发展,社交媒体平台如微博已成为人们表达观点、交流信息的重要渠道。微博每天产生海量的数据,这些数据中蕴含着丰富的社会情绪、事件动态等信息,对于政…...

excel-VBA知识点记录
1、计算机硬件的组成部分 内存,一旦断电,存储在里面的数据就消失了,而硬盘是永久存储数据的,所以刚开始我们在文件里面编辑没有按保存的时候,数据是在内存里面的,一旦断电数据就没了,但我们点了…...

RabbitMQ——消息的可靠性处理
1.业务分析 在业务的开发中,我们通常将业务的非核心业务交给MQ来处理,比如支付,在支付过后,我们需要扣减余额,修改支付单状态,修改订单状态,发送短信提醒用户,给用户增加积分等等&am…...

babylon.js-1:入门篇
最近项目中使用到了 Babylon.js 这门技术,从今天开始,抽取自己写的比较好的拿出来,作为分享案例: 记录学习成果通过笔记的方式记录技术积累方便工作中查找翻阅实现案例 是什么 Babylon.js是一个基于WebGL的开源3D渲染引擎&…...

VS Code调整字体大小
##在工程目录底下.vscode/settings.json添加设置参数 {"editor.fontSize": 15,"window.zoomLevel": 1.5 }...

Python基础语句教学
Python是一种高级的编程语言,由Guido van Rossum于1991年创建。它以简单易读的语法和强大的功能而闻名,被广泛用于科学计算、Web开发、数据分析等领域。 Python的应用领域广泛,可以用于开发桌面应用程序、Web应用、游戏、数据分析、人工智能等…...

ansible 配置
目录 1.集群自动化维护工具 ansible 2.ansible管理架构 3.安装ansible 4.Iventory主机模式 5.通过ping验证 6.ansible常用模块 7.命令行模块 7.1command模块 7.2shell模块 7.3scripts模块 7.4file模块 7.5copy模块 7.6yum模块 1.集群自动化维护工具 ansibl…...

堆排序算法详解:原理与Python实现
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「storm…...

[论文阅读] ChartInstruct: Instruction Tuning for Chart Comprehension and Reasoning
原文链接:http://arxiv.org/abs/2403.09028 源码链接:https://github.com/vis-nlp/ChartInstruct 启发:本文构建的instruction-tuning数据集以及使用该数据集对模型进行微调的过程都值得学习。 Abstract 研究对象:图表 研究…...

基于springboot+vue学生宿舍管理系统设计与实现
博主介绍:专注于Java vue .net php phython 小程序 等诸多技术领域和毕业项目实战、企业信息化系统建设,从业十五余年开发设计教学工作 ☆☆☆ 精彩专栏推荐订阅☆☆☆☆☆不然下次找不到哟 我的博客空间发布了1000毕设题目 方便大家学习使用 感兴趣的…...

【Android】模糊搜索与数据处理
【Android】模糊搜索与数据处理 本篇博客主要以根据输入内容动态获取城市为例进行讲解。 获取城市 这一部分主要是根据输入的信息去动态获取城市信息 首先定义了一个名为 NetUtil 的类,主要用于通过 HTTP 请求获取城市信息。 public class NetUtil {private stat…...

机器学习-KNN
KNN:K最邻近算法(K-Nearest Neighbor,KNN) 用特征空间中距离待分类对象的最近的K个样例点的类别来预测。 投票法:K 个样例的对数类别。 k1:最近邻分类 k 通常是奇数(因为我们根据这个K数据判断类别,如果…...

python 安装包 site-packages
1. site-packages 文件夹的位置 当我们通过 pip 或其他方式安装一个 Python 包时,这些包的文件就会被复制到 site-packages 文件夹下。 site-packages 文件夹通常位于 Python 的安装目录下的 Lib 文件夹内。具体的路径会根据你使用的操作系统和 Python 版本的不同而…...

大数据-151 Apache Druid 集群模式 配置启动【上篇】 超详细!
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完)HDFS(已更完)MapReduce(已更完&am…...

CentOS8.5.2111(3)实验之DHCP服务器架设
一、实验目标 1.掌握DHCP服务器的主配置文件各项申明参数及操作及其含义 2. 具备DHCP 服务器、中继服务器的配置能力 3. 具备测试客户端正常获取服务器分配地址的能力 4. 具备DHCP服务器故障排除能力 二、实训原理/流程 (一)项目背景 …...
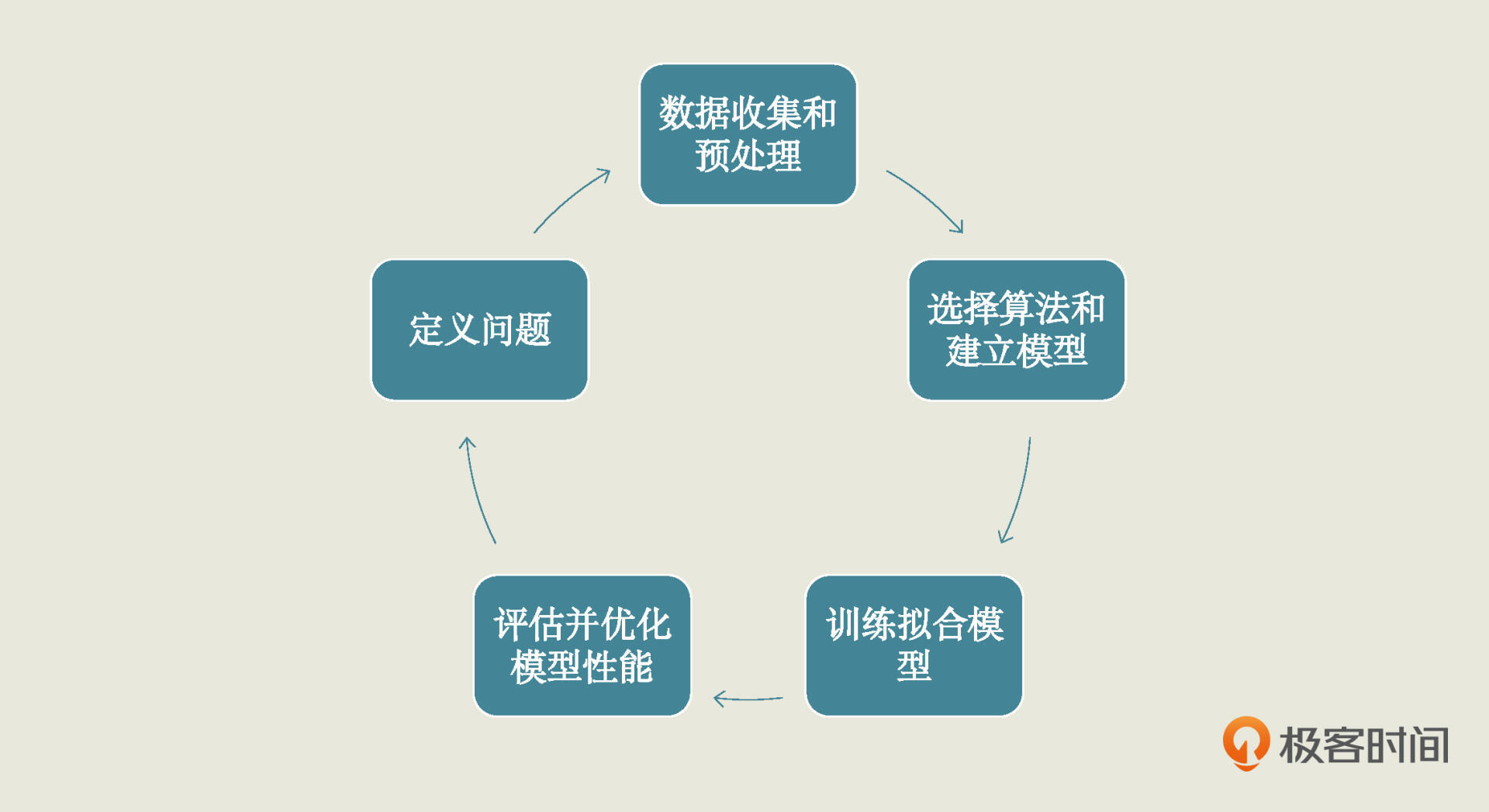
机器学习(4):机器学习项目步骤(一)——定义问题
1. 机器学习项目的五大步骤 定义问题 收集数据和预处理 选择算法和确定模型 训练拟合模型 评估优化模型性能 2. 定义问题的主要任务 刨析业务场景,设定清晰目标,同时还要确定当前问题属于哪一种机器学习类型。 3. “易速鲜花”项目案例 项目任务&a…...

java_网络服务相关_gateway_nacos_feign区别联系
1. spring-cloud-starter-gateway 作用:作为微服务架构的网关,统一入口,处理所有外部请求。 核心能力: 路由转发(基于路径、服务名等)过滤器(鉴权、限流、日志、Header 处理)支持负…...

【WiFi帧结构】
文章目录 帧结构MAC头部管理帧 帧结构 Wi-Fi的帧分为三部分组成:MAC头部frame bodyFCS,其中MAC是固定格式的,frame body是可变长度。 MAC头部有frame control,duration,address1,address2,addre…...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

五年级数学知识边界总结思考-下册
目录 一、背景二、过程1.观察物体小学五年级下册“观察物体”知识点详解:由来、作用与意义**一、知识点核心内容****二、知识点的由来:从生活实践到数学抽象****三、知识的作用:解决实际问题的工具****四、学习的意义:培养核心素养…...

CMake控制VS2022项目文件分组
我们可以通过 CMake 控制源文件的组织结构,使它们在 VS 解决方案资源管理器中以“组”(Filter)的形式进行分类展示。 🎯 目标 通过 CMake 脚本将 .cpp、.h 等源文件分组显示在 Visual Studio 2022 的解决方案资源管理器中。 ✅ 支持的方法汇总(共4种) 方法描述是否推荐…...

JAVA后端开发——多租户
数据隔离是多租户系统中的核心概念,确保一个租户(在这个系统中可能是一个公司或一个独立的客户)的数据对其他租户是不可见的。在 RuoYi 框架(您当前项目所使用的基础框架)中,这通常是通过在数据表中增加一个…...

Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习)
Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习) 一、Aspose.PDF 简介二、说明(⚠️仅供学习与研究使用)三、技术流程总览四、准备工作1. 下载 Jar 包2. Maven 项目依赖配置 五、字节码修改实现代码&#…...

嵌入式学习笔记DAY33(网络编程——TCP)
一、网络架构 C/S (client/server 客户端/服务器):由客户端和服务器端两个部分组成。客户端通常是用户使用的应用程序,负责提供用户界面和交互逻辑 ,接收用户输入,向服务器发送请求,并展示服务…...

【从零学习JVM|第三篇】类的生命周期(高频面试题)
前言: 在Java编程中,类的生命周期是指类从被加载到内存中开始,到被卸载出内存为止的整个过程。了解类的生命周期对于理解Java程序的运行机制以及性能优化非常重要。本文会深入探寻类的生命周期,让读者对此有深刻印象。 目录 …...