Spark 的 Skew Join 详解
Skew Join 是 Spark 中为了解决数据倾斜问题而设计的一种优化机制。数据倾斜是指在分布式计算中,由于某些 key 具有大量数据,而其他 key 数据较少,导致某些分区的数据量特别大,造成计算负载不均衡。数据倾斜会导致个别节点出现性能瓶颈,影响整个任务的完成时间。
Skew Join 的优化机制在 Spark 中主要解决了 JOIN 操作中的数据倾斜问题。为了更好地理解 Skew Join 的原理和实现,我们需要从数据倾斜产生的原因、Spark 如何识别数据倾斜、以及 Skew Join 的优化策略和底层实现等方面来进行详细解释。
一、什么是数据倾斜
数据倾斜指的是当某些 key 关联了异常大量的数据,而其他 key 关联的数据量较少时,数据分布的不均衡会导致计算瓶颈。例如,在 JOIN 操作中,如果表 A 中某个 key 具有大量的数据,而表 B 中同样的 key 也有大量数据,当这两个表基于这个 key 进行 JOIN 时,由于该 key 被分配到一个或少数几个分区,相关的任务会处理大量的数据,而其他分区的任务数据量却较少。这会导致部分任务比其他任务运行时间长,从而影响整个任务的执行时间。
二、Spark 中如何识别数据倾斜
在执行 JOIN 操作时,Spark 会通过数据采样和统计信息来检测是否存在数据倾斜。Spark SQL 可以通过分析数据分布,计算每个 key 的数据量,当发现某些 key 占据了大量的行时,Spark 会将其标记为 "倾斜的 key"。对于这些倾斜的 key,Spark 会进行特殊处理,避免过度集中在某些分区中。
Spark 的 Skew Join 优化主要依赖于配置参数和数据采样来检测并处理这些倾斜的 key。
检测数据倾斜的主要参数:
- spark.sql.autoSkewJoin.enabled: 默认是
false,如果设置为true,Spark 会自动检测和处理数据倾斜的JOIN操作。 - spark.sql.skewJoin.threshold: 用来设定 Spark 如何判断某个分区是否倾斜。该参数设置的值是数据倾斜的阈值,通常是一个比例值,如果某个分区的数据量超过该比例值,则会被视为倾斜的分区。
三、Skew Join 的底层原理
当 Spark 识别出 JOIN 中存在数据倾斜时,Skew Join 会将倾斜的 key 拆分成多个子任务分别处理。具体而言,Skew Join 的主要思想是将倾斜的 key 拆分到多个不同的分区,从而将任务的计算负载均匀分布,避免单个分区处理过多数据。
以下是 Skew Join 的执行流程:
-
普通的非倾斜
对于普通的非倾斜key处理:key,Skew Join没有特别的处理方式,Spark 直接按照key进行Shuffle,将数据发送到相应的分区,并进行JOIN操作。 -
倾斜的
key处理:
对于检测到的倾斜 key,Spark 会进行特殊处理,具体步骤如下:
- Spark 会将倾斜的
key的数据进行重新分片,将大数据量的倾斜key拆分成多个子分区。 - 然后对于每一个子分区,分别与另一个表中的对应数据进行
JOIN。 - 通过多次
JOIN操作,将这些子分区结果合并为最终的JOIN输出结果。
3. Hash Salt(哈希加盐):
为了避免倾斜的 key 被集中到同一个分区,Spark 会通过对倾斜的 key 添加一个随机的 salt(盐值)来打散数据。具体来说,Spark 会将倾斜的 key 拆分成多个子 key,通过附加随机数(salt),使得这些子 key 被分布到不同的分区。
伪代码展示:
// 倾斜 key 的原始 join
tableA.join(tableB, "key")// Skew Join 处理
val skewKeys = getSkewKeys()
for (skewKey <- skewKeys) {val saltedTableA = tableA.filter($"key" === skewKey).withColumn("salt", rand())val saltedTableB = tableB.filter($"key" === skewKey).withColumn("salt", rand())saltedTableA.join(saltedTableB, Seq("key", "salt"))
}
通过引入 salt,可以有效地将数据均匀分布到不同的分区,减少单个分区处理的数据量。
四、Skew Join 的源代码实现
在 Spark SQL 中,Skew Join 是作为 PhysicalPlan 中 Join 的一个优化执行计划。关键类为 EnsureRequirements,其主要职责是对 Join 的物理计划执行前进行必要的调整,包括处理数据倾斜的 Skew Join 优化。
以下是 EnsureRequirements 中处理数据倾斜的相关部分源代码:
private def applySkewJoin(plan: SparkPlan): SparkPlan = plan match {case join @ ShuffledHashJoinExec(_, _, _, _, left, right) =>// 检查是否有数据倾斜if (isSkewed(join)) {// 处理 skew join,使用 hash salt 拆分倾斜的 keyval skewJoin = handleSkewJoin(join)skewJoin} else {join}case other => other
}
在 EnsureRequirements 中,applySkewJoin 函数会检测当前的 JOIN 是否存在数据倾斜问题。如果检测到数据倾斜,handleSkewJoin 函数会对数据进行处理,创建一个带有 salt 的 Skew Join 执行计划。
具体实现步骤:
-
检测数据倾斜:
isSkewed(join)函数负责检测JOIN中的分区是否有数据倾斜。通常,通过采样和统计每个分区的数据量,来判断某个分区的数据量是否超出设定的阈值(spark.sql.skewJoin.threshold)。 -
处理倾斜数据:
handleSkewJoin(join)函数是Skew Join的核心实现。它会通过对倾斜的key添加salt进行打散,使得数据均匀分布到多个子分区。
private def handleSkewJoin(join: ShuffledHashJoinExec): SparkPlan = {val skewKeys = getSkewKeys(join)val saltedLeft = splitAndSalt(join.left, skewKeys)val saltedRight = splitAndSalt(join.right, skewKeys)saltedLeft.join(saltedRight)
}private def splitAndSalt(plan: SparkPlan, skewKeys: Seq[KeyType]): SparkPlan = {// 对每个倾斜 key 进行拆分并添加 saltplan.transform {case rdd: RDD[_] => rdd.mapPartitionsInternal { iter =>iter.flatMap { row =>val key = getJoinKey(row)if (skewKeys.contains(key)) {val salt = Random.nextInt(numSplits) // 随机生成 saltSome((key, salt, row))} else {Some((key, row))}}}}
}
在上面的代码中,splitAndSalt 函数将每个倾斜的 key 拆分成多个子 key,并为它们添加随机 salt,从而打散数据,均匀分布到不同的分区。
五、Skew Join 的优化策略
Spark 中 Skew Join 的优化需要考虑以下几个方面:
-
自动启用 Skew Join:通过设置
spark.sql.autoSkewJoin.enabled为true,Spark 会自动检测并处理倾斜的JOIN操作。对于那些倾斜的分区,Spark 会自动进行Skew Join优化。 -
调优 salt 值:
salt的值影响了倾斜数据被打散的粒度。通过调节salt的随机范围,可以控制数据的打散程度。如果salt的范围太小,数据可能仍然集中在某些分区;如果范围太大,则可能会产生过多的小分区,导致计算开销增加。 -
采样优化:通过调整采样参数,Spark 可以更好地识别出数据倾斜的
key,从而提高Skew Join的处理效率。spark.sql.skewJoin.threshold参数允许用户设定数据倾斜的阈值。 -
数据预处理:在某些场景中,用户可以通过在数据加载和预处理阶段手动解决数据倾斜问题。例如,用户可以通过聚合或者过滤数据的方式,减少倾斜
key的数据量。
六、总结
Skew Join 是 Spark 中为了解决数据倾斜问题而提供的一种重要优化机制。其核心思想是通过检测数据倾斜的 key,并对这些 key 进行分片和哈希加盐处理,使得倾斜的数据被均匀分布到不同的分区,从而避免计算负载的不均衡。通过 Skew Join,Spark 可以显著提高 JOIN 操作的性能,尤其是在数据倾斜严重的场景下。
合理的参数调优和数据预处理是确保 Skew Join 有效的关键。
相关文章:

Spark 的 Skew Join 详解
Skew Join 是 Spark 中为了解决数据倾斜问题而设计的一种优化机制。数据倾斜是指在分布式计算中,由于某些 key 具有大量数据,而其他 key 数据较少,导致某些分区的数据量特别大,造成计算负载不均衡。数据倾斜会导致个别节点出现性能…...

讯飞星火编排创建智能体学习(一)最简单的智能体构建
目录 开篇 智能体的概念 编排创建智能体 创建第一个智能体 编辑 大模型节点 测试与调试 开篇 前段时间在华为全联接大会上看到讯飞星火企业级智能体平台的演示,对于拖放的可视化设计非常喜欢,刚开始以为是企业用户才有的,回来之后查…...

mac-m1安装nvm,docker,miniconda
1.安装minicondaMAC OS(M1)安装配置miniconda_mac-mini m1 conda-CSDN博客 2.安装nvm(用第二个方法)Mac电脑安装nvm(node包版本管理工具)-CSDN博客 3.安装docker dmg下载链接docker-toolbox-mac-docker-for-mac安装包下载_开源镜像站-阿里云 教程MacOS系…...

STM32F407之Flash
寄存器分类 一般寄存器分为只读存储器 (ROM) 随机存储器(RAM) 只读存储器 只读存储器也被称为ROM 在正常工作时只能读不能写。 只读存储器经历的阶段 ROM->PROM->EPROM->EEPROM ->Flash 优点:掉电不丢失,解构简单 缺点:只适…...
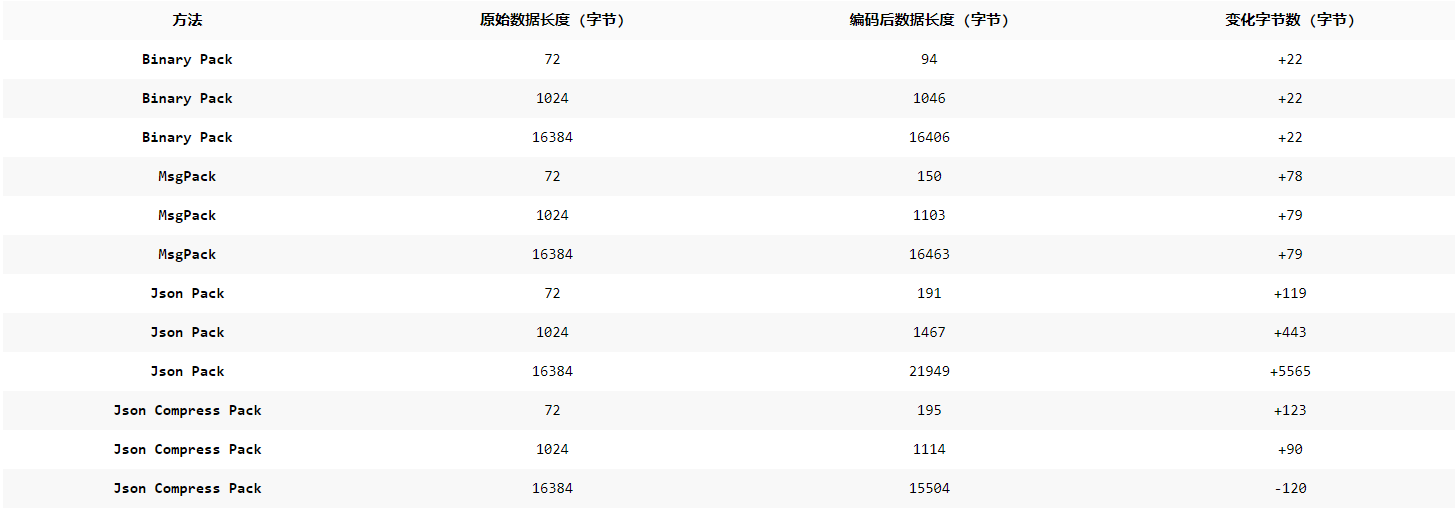
优化 Go 语言数据打包:性能基准测试与分析
场景:在局域网内,需要将多个机器网卡上抓到的数据包同步到一个机器上。 原有方案:tcpdump -w 写入文件,然后定时调用 rsync 进行同步。 改造方案:使用 Go 重写这个抓包逻辑及同步逻辑,直接将抓到的包通过网…...

【SQL】未订购的客户
目录 语法 需求 示例 分析 代码 语法 SELECT columns FROM table1 LEFT JOIN table2 ON table1.common_field table2.common_field; LEFT JOIN(或称为左外连接)是SQL中的一种连接类型,它用于从两个或多个表中基于连接条件返回左表…...

Qt(9.28)
widget.cpp #include "widget.h"Widget::Widget(QWidget *parent): QWidget(parent) {QPushButton *btn1 new QPushButton("登录",this);this->setFixedSize(640,480);btn1->resize(80,40);btn1->move(200,300);btn1->setIcon(QIcon("C:…...

javascript-冒泡排序
前言:好久没学习算法了,今天看了一个视频课,之前掌握很好的冒泡排序居然没写出来? <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport"…...

第九届蓝桥杯嵌入式省赛程序设计题解析(基于HAL库)
一.题目分析 (1).题目 (2).题目分析 按键功能分析----存储位置的切换键 a. B1按下切换存储位置,切换后定时时间设定为当前位置存储的时间 b. B2短按切换时分秒高亮,设置完成后,长按把设置的时…...

MATLAB云计算集成:在云端扩展计算能力
摘要 MATLAB云计算集成是指将MATLAB的计算能力与云平台的弹性资源相结合,以实现高性能计算、数据处理和算法开发。本文详细介绍了MATLAB云计算的基本概念、优势、配置要点以及编程实践。 1. 云计算概述 云计算是一种通过互联网提供计算资源(如服务器、…...

基于BeagleBone Black的网页LED控制功能(flask+gpiod)
目录 项目介绍硬件介绍项目设计开发环境功能实现控制LED外设构建Webserver 功能展示项目总结 👉 【Funpack3-5】基于BeagleBone Black的网页LED控制功能 👉 Github: EmbeddedCamerata/BBB_led_flask_web_control 项目介绍 基于 BeagleBoard Black 开发板…...

【C语言】单片机map表详细解析
1、RO Size、RW Size、ROM Size分别是什么 首先将map文件翻到最下面,可以看到 1.1 RO Size:只读段 Code:程序的代码部分(也就是 .text 段),它存放了程序的指令和可执行代码。 RO Data:只读…...

Java中的继承和实现
Java中的继承和实现在面向对象编程中扮演着不同的角色,它们之间的主要区别可以从以下几个方面进行阐述: 1. 定义和用途 继承(Inheritance):继承是面向对象编程中的一个基本概念,它允许我们定义一个类&…...

uniapp云打包
ios打包 没有mac电脑,使用香蕉云编 先登录香蕉云编这个工具,新建csr文件——把csr文件下载到你电脑本地: 然后,登录苹果开发者中心 生成p12证书 1、点击+号创建证书 创建证书的时候一定要选择ios distribution app store and ad hoc类型的证书 2、上传刚才从本站生成的…...

端口安全技术原理与应用
目录 概述 端口安全原理 端口安全术语 二层安全地址配置 端口模式下配置 全局模式下配置 动态学习 二层数据包处理流程 三层安全地址配置 三层数据包处理流程 端口安全违例动作和安全地址老化时间 查看命令 端口安全的注意事项 小结 概述 园区网的接入安全关系着…...

数据集-目标检测系列-鲨鱼检测数据集 shark >> DataBall
数据集-目标检测系列-鲨鱼检测数据集 shark >> DataBall 数据集-目标检测系列-鲨鱼检测数据集 shark 数据量:6k 数据样例项目地址: gitcode: https://gitcode.com/DataBall/DataBall-detections-100s/overview github: https://github.com/Te…...

数字乡村解决方案-3
1. 国家大数据战略与数字乡村 中国第十三个五年规划纲要强调实施国家大数据战略,加快建设数字中国,推进数据资源整合和开放共享,保障数据安全,以大数据助力产业转型升级和提高社会治理的精准性与有效性。 2. 大数据与数字经济 …...

WPF文本框无法输入小数点
问题描述 在WPF项目中,文本框BInding双向绑定了数据Text“{UpdateSourceTriggerPropertyChanged}”,但手套数据是double类型,手动输入数据时,小数点输入不进去 解决办法: 在App.xaml.cs文件中添加语句: …...

R开头的后缀:RE
RE表示方位上的向后,一种时空上的折返,和表示否定意味的不。 68.re- 空间顺序 ①表示"向后,相反,不" RE表示正向抵抗的力的词语,和情绪的词语,用来表示一种极力的反抗和拒绝,包括…...

Vue2配置环境变量的注意事项
在实际开发中时常会遇到需要开发环境与生产环境中一些参数的替换,为了方便线上线下环境变量切换可以利用node中的process进行环境变量管理 实现步骤如下: 1.在 根目录 新增环境文件 .env.development 和 .env.production 注意文件名称保持一致( 需要强调的是文件中的变量名切…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

高等数学(下)题型笔记(八)空间解析几何与向量代数
目录 0 前言 1 向量的点乘 1.1 基本公式 1.2 例题 2 向量的叉乘 2.1 基础知识 2.2 例题 3 空间平面方程 3.1 基础知识 3.2 例题 4 空间直线方程 4.1 基础知识 4.2 例题 5 旋转曲面及其方程 5.1 基础知识 5.2 例题 6 空间曲面的法线与切平面 6.1 基础知识 6.2…...

代理篇12|深入理解 Vite中的Proxy接口代理配置
在前端开发中,常常会遇到 跨域请求接口 的情况。为了解决这个问题,Vite 和 Webpack 都提供了 proxy 代理功能,用于将本地开发请求转发到后端服务器。 什么是代理(proxy)? 代理是在开发过程中,前端项目通过开发服务器,将指定的请求“转发”到真实的后端服务器,从而绕…...

虚拟电厂发展三大趋势:市场化、技术主导、车网互联
市场化:从政策驱动到多元盈利 政策全面赋能 2025年4月,国家发改委、能源局发布《关于加快推进虚拟电厂发展的指导意见》,首次明确虚拟电厂为“独立市场主体”,提出硬性目标:2027年全国调节能力≥2000万千瓦࿰…...

[大语言模型]在个人电脑上部署ollama 并进行管理,最后配置AI程序开发助手.
ollama官网: 下载 https://ollama.com/ 安装 查看可以使用的模型 https://ollama.com/search 例如 https://ollama.com/library/deepseek-r1/tags # deepseek-r1:7bollama pull deepseek-r1:7b改token数量为409622 16384 ollama命令说明 ollama serve #:…...

Scrapy-Redis分布式爬虫架构的可扩展性与容错性增强:基于微服务与容器化的解决方案
在大数据时代,海量数据的采集与处理成为企业和研究机构获取信息的关键环节。Scrapy-Redis作为一种经典的分布式爬虫架构,在处理大规模数据抓取任务时展现出强大的能力。然而,随着业务规模的不断扩大和数据抓取需求的日益复杂,传统…...

libfmt: 现代C++的格式化工具库介绍与酷炫功能
libfmt: 现代C的格式化工具库介绍与酷炫功能 libfmt 是一个开源的C格式化库,提供了高效、安全的文本格式化功能,是C20中引入的std::format的基础实现。它比传统的printf和iostream更安全、更灵活、性能更好。 基本介绍 主要特点 类型安全:…...
HybridVLA——让单一LLM同时具备扩散和自回归动作预测能力:训练时既扩散也回归,但推理时则扩散
前言 如上一篇文章《dexcap升级版之DexWild》中的前言部分所说,在叠衣服的过程中,我会带着团队对比各种模型、方法、策略,毕竟针对各个场景始终寻找更优的解决方案,是我个人和我司「七月在线」的职责之一 且个人认为,…...

全面解析数据库:从基础概念到前沿应用
在数字化时代,数据已成为企业和社会发展的核心资产,而数据库作为存储、管理和处理数据的关键工具,在各个领域发挥着举足轻重的作用。从电商平台的商品信息管理,到社交网络的用户数据存储,再到金融行业的交易记录处理&a…...