Elasticsearch学习笔记(1)
初识 Elasticsearch
认识和安装
Elasticsearch 是由 Elastic 公司开发的一套强大的搜索引擎技术,属于 Elastic 技术栈的一部分。完整的技术栈包括:
- Elasticsearch:用于数据存储、计算和搜索。
- Logstash/Beats:用于数据收集。
- Kibana:用于数据可视化。
这套技术栈通常被称为 elastic stack (ELK),广泛应用于日志收集、系统监控和状态分析等场景。
而elasticsearch是elastic stack的核心,负责存储、搜索、分析数据。

核心组件
Elasticsearch 是整个技术栈的核心,提供了强大的数据存储、搜索和分析功能。
Kibana 是一个用于操作 Elasticsearch 的可视化控制台,它通过 RESTful API 与 Elasticsearch 进行交互,让用户能够更直观地管理和分析数据。Kibana 的主要功能包括:
- 数据搜索与展示:支持对 Elasticsearch 数据的灵活搜索和展示。
- 统计与聚合:能够对数据进行统计分析,并生成图表和报表。
- 集群状态监控:提供对 Elasticsearch 集群健康状态的监控。
- 开发控制台(DevTools):提供语法提示,帮助用户更方便地使用 Elasticsearch 的 RESTful API。
安装elasticsearch
通过下面的Docker命令(Windows 命令提示符)即可安装单机版本的elasticsearch:
docker run -d ^--name es ^-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" ^-e "discovery.type=single-node" ^-v es-data:/usr/share/elasticsearch/data ^-v es-plugins:/usr/share/elasticsearch/plugins ^--privileged ^--network hm-net ^-p 9200:9200 ^-p 9300:9300 ^elasticsearch:7.12.1
安装完成后,访问9200端口,即可看到响应的Elasticsearch服务的基本信息:

安装Kibana
通过下面的Docker命令(Windows 命令提示符),即可部署Kibana:
docker run -d ^--name kibana ^-e ELASTICSEARCH_HOSTS=http://es:9200 ^--network=hm-net ^-p 5601:5601 ^kibana:7.12.1
安装完成后,直接访问5601端口,即可看到控制台页面:

选择Explore on my own之后,进入主页面:

然后选中Dev tools,进入开发工具页面:

倒排索引
Elasticsearch 之所以能够提供高性能的搜索功能,主要归功于其底层的倒排索引技术。倒排索引是一种特殊的数据结构,它能够极大地提高文本搜索的效率。
正向索引
在传统的数据库系统中,如 MySQL,通常使用的是正向索引。正向索引是基于记录的 ID 或其他字段创建的索引。例如,给定一个商品表 tb_goods,如果为 id 字段创建索引,那么根据 id 查询时,可以直接通过索引快速定位到记录。
然而,如果需要根据 title 字段进行模糊查询,传统的正向索引就无法高效地处理。在这种情况下,数据库系统通常需要进行全表扫描,逐行检查 title 字段是否包含用户搜索的关键词。这种逐行扫描的方式在大数据量的情况下效率非常低下。
倒排索引
倒排索引是对正向索引的一种特殊处理,它将文档中的每个词条与包含该词条的文档进行关联。倒排索引中有两个核心概念:
- 文档(Document):用于搜索的数据单元,例如一个网页、一个商品信息等。
- 词条(Term):对文档数据或用户搜索数据进行分词后得到的具有含义的词语。例如,“我是中国人” 可以被分词为 “我”、“是”、“中国人”、“中国”、“国人” 等词条。
创建倒排索引的流程如下:
- 分词:将每个文档的数据进行分词,得到一个个词条。
- 创建索引表:创建一个表,每行数据包括词条、词条所在的文档 ID、词条在文档中的位置等信息。
- 索引优化:由于词条具有唯一性,可以为词条创建索引,例如使用哈希表结构索引。
倒排索引的搜索流程如下(以搜索 “华为手机” 为例):
- 分词:用户输入 “华为手机”,对其进行分词,得到词条 “华为” 和 “手机”。
- 查找词条:拿着词条在倒排索引中查找,得到包含这些词条的文档 ID。
- 获取文档:根据文档 ID 在正向索引中查找具体的文档。
通过倒排索引,搜索过程可以避免全表扫描,因为词条和文档 ID 都建立了索引,查询速度非常快。
正向索引与倒排索引的对比
正向索引:
优点:
- 可以为多个字段创建索引。
- 根据索引字段进行搜索和排序时速度非常快。
缺点:
- 根据非索引字段或索引字段中的部分词条查找时,只能进行全表扫描。
倒排索引:
优点:
- 根据词条进行搜索和模糊搜索时速度非常快。
缺点:
- 只能为词条创建索引,而不是字段。
- 无法根据字段进行排序。
总结来说,正向索引适用于精确查询和排序,而倒排索引则适用于全文搜索和模糊查询。Elasticsearch 通过结合这两种索引技术,提供了高效的全文搜索能力。
基础概念
Elasticsearch 中有许多独特的概念,与传统的关系型数据库(如 MySQL)有所不同,但也有相似之处。理解这些概念对于掌握 Elasticsearch 的使用至关重要。
文档和字段
Elasticsearch 是面向文档(Document)存储的,文档可以是数据库中的一条商品数据、一个订单信息等。文档数据会被序列化为 JSON 格式后存储在 Elasticsearch 中。
每个 JSON 文档中包含多个字段(Field),类似于数据库中的列。字段是文档的基本组成部分,每个字段都有其数据类型和值。
索引和映射
索引(Index)是相同类型的文档的集合。例如:
- 所有用户文档可以组织在一起,称为用户的索引。
- 所有商品的文档可以组织在一起,称为商品的索引。
- 所有订单的文档可以组织在一起,称为订单的索引。
索引类似于数据库中的表。数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。因此,索引库中就有映射(Mapping),是索引中文档的字段约束信息,类似表的结构约束。
MySQL 与 Elasticsearch 的对比
以下是 MySQL 与 Elasticsearch 中一些关键概念的对比:
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(Index)是文档的集合,类似数据库的表(Table) |
| Row | Document | 文档(Document)是一条条的数据,类似数据库中的行(Row),文档都是 JSON 格式 |
| Column | Field | 字段(Field)是 JSON 文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL 是 Elasticsearch 提供的 JSON 风格的请求语句,用来操作 Elasticsearch,实现 CRUD |
是否可以完全替代 MySQL?
虽然 Elasticsearch 在搜索和分析方面表现出色,但它并不能完全替代 MySQL。两者各有擅长之处:
-
MySQL:擅长事务类型操作,可以确保数据的安全和一致性。
-
Elasticsearch:擅长海量数据的搜索、分析、计算。
在企业中,通常会结合使用两者:
-
对安全性要求较高的写操作,使用 MySQL 实现。
-
对查询性能要求较高的搜索需求,使用 Elasticsearch 实现。
-
两者再基于某种方式,实现数据的同步,保证一致性。

IK 分词器
Elasticsearch 的关键在于倒排索引,而倒排索引依赖于对文档内容的分词。分词是将文本数据分解为有意义的词条(Term)的过程。对于中文文本,由于中文没有像英文那样的自然分隔符(如空格),因此需要专门的中文分词算法。IK 分词器(IK Analyzer)就是这样一个高效、精准的中文分词工具。
安装 IK 分词器插件
IK 分词器是一个开源的中文分词插件,适用于 Elasticsearch。安装 IK 分词器可以显著提高中文文本的分词效果。以下是在 Windows 系统上安装 IK 分词器(IK Analyzer)的步骤:
方案一:在线安装
进入 Elasticsearch 容器:
运行以下命令进入正在运行的 Elasticsearch 容器:
docker exec -it es /bin/bash安装 IK 分词器插件:
在容器内部运行以下命令来安装 IK 分词器插件:
bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip请注意,你需要将 7.12.1 替换为你正在使用的 Elasticsearch 版本号。
退出容器:
安装完成后,退出容器:
exit重启 Elasticsearch 容器:
安装完成后,你需要重启 Elasticsearch 容器以使插件生效:
docker restart es方案二:离线安装
下载 IK 分词器插件:
从 GitHub 页面下载 IK 分词器插件的压缩文件。
将插件文件上传到容器:
将下载的压缩文件上传到 Elasticsearch 容器的 /usr/share/elasticsearch/plugins 目录下。你可以使用 docker cp 命令来完成这个操作:
docker cp /path/to/elasticsearch-analysis-ik-7.12.1.zip es:/usr/share/elasticsearch/plugins/进入 Elasticsearch 容器:
运行以下命令进入正在运行的 Elasticsearch 容器:
docker exec -it es /bin/bash解压插件文件:
在容器内部解压插件文件:
cd /usr/share/elasticsearch/plugins
unzip elasticsearch-analysis-ik-7.12.1.zip
rm elasticsearch-analysis-ik-7.12.1.zip退出容器:
解压完成后,退出容器:
exit重启 Elasticsearch 容器:
安装完成后,你需要重启 Elasticsearch 容器以使插件生效:
docker restart esIK分词器包含三种模式
- standard:标准分词器
- ik_smart:智能语义切分
- ik_max_word:最细粒度切分
首先,测试 Elasticsearch 官方提供的标准分词器:
POST /_analyze
{"analyzer": "standard","text": "我是中国人"
}执行结果如下:
{"tokens" : [{"token" : "我","start_offset" : 0,"end_offset" : 1,"type" : "<IDEOGRAPHIC>","position" : 0},{"token" : "是","start_offset" : 1,"end_offset" : 2,"type" : "<IDEOGRAPHIC>","position" : 1},{"token" : "中","start_offset" : 2,"end_offset" : 3,"type" : "<IDEOGRAPHIC>","position" : 2},{"token" : "国","start_offset" : 3,"end_offset" : 4,"type" : "<IDEOGRAPHIC>","position" : 3},{"token" : "人","start_offset" : 4,"end_offset" : 5,"type" : "<IDEOGRAPHIC>","position" : 4}]
}
可以看到,标准分词器只能 1 字 1 词条,无法正确对中文做分词。
接下来,测试 IK 分词器的 ik_smart 模式:
POST /_analyze
{"analyzer": "ik_smart","text": "我是中国人"
}执行结果如下:
{"tokens" : [{"token" : "我","start_offset" : 0,"end_offset" : 1,"type" : "CN_CHAR","position" : 0},{"token" : "是","start_offset" : 1,"end_offset" : 2,"type" : "CN_CHAR","position" : 1},{"token" : "中国人","start_offset" : 2,"end_offset" : 5,"type" : "CN_WORD","position" : 2}]
}
最后,测试 IK 分词器的 ik_max_word 模式:
POST /_analyze
{"analyzer": "ik_max_word","text": "我是中国人"
}执行结果如下:
{"tokens" : [{"token" : "我","start_offset" : 0,"end_offset" : 1,"type" : "CN_CHAR","position" : 0},{"token" : "是","start_offset" : 1,"end_offset" : 2,"type" : "CN_CHAR","position" : 1},{"token" : "中国人","start_offset" : 2,"end_offset" : 5,"type" : "CN_WORD","position" : 2},{"token" : "中国","start_offset" : 2,"end_offset" : 4,"type" : "CN_WORD","position" : 3},{"token" : "国人","start_offset" : 3,"end_offset" : 5,"type" : "CN_WORD","position" : 4}]
}
IK 分词器的 ik_smart 模式适用于大多数场景,能够根据上下文进行智能分词;而 ik_max_word 模式则尽可能多地切分出词条,适用于需要更细粒度分词的场景。
拓展词典
进入容器后
cd /usr/share/elasticsearch/config/analysis-ik
ls查看文件内容:
cat extra_main.dic

总结
分词器的作用是什么?
分词器在搜索引擎中有两个主要作用:
- 创建倒排索引时,对文档分词:在索引阶段,分词器将文档内容分解成一个个的词条(tokens),并将这些词条与文档关联起来,形成倒排索引。倒排索引是搜索引擎的核心数据结构,用于快速查找包含特定词条的文档。
- 用户搜索时,对输入的内容分词:在搜索阶段,分词器将用户输入的查询内容分解成一个个的词条,然后搜索引擎根据这些词条在倒排索引中查找匹配的文档。
IK 分词器有几种模式?
IK 分词器提供了两种分词模式:
- ik_smart:智能切分,粗粒度:ik_smart 模式会进行智能切分,通常会生成较少的词条,适用于需要较粗粒度分词的场景。
- ik_max_word:最细切分,细粒度:ik_max_word 模式会进行最细粒度的切分,尽可能生成更多的词条,适用于需要细粒度分词的场景。
IK 分词器如何拓展词条?如何停用词条?
IK 分词器可以通过配置文件 IKAnalyzer.cfg.xml 来拓展词条和停用词条。
拓展词条:
- 在 IKAnalyzer.cfg.xml 文件中,通过 <entry key="ext_dict"> 标签指定拓展词典文件的路径。
- 在拓展词典文件中添加你想要拓展的词条。
停用词条:
- 在 IKAnalyzer.cfg.xml 文件中,通过 <entry key="ext_stopwords"> 标签指定停用词典文件的路径。
- 在停用词典文件中添加你想要停用的词条。
示例配置
IKAnalyzer.cfg.xml 示例
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!-- 用户可以在这里配置自己的扩展字典 --><entry key="ext_dict">mydict.dic</entry><!-- 用户可以在这里配置自己的扩展停止词字典 --><entry key="ext_stopwords">stopword.dic</entry>
</properties>自定义词典文件 mydict.dic 示例
自定义词汇1
自定义词汇2停用词典文件 stopword.dic 示例
的
是
在相关文章:
Elasticsearch学习笔记(1)
初识 Elasticsearch 认识和安装 Elasticsearch 是由 Elastic 公司开发的一套强大的搜索引擎技术,属于 Elastic 技术栈的一部分。完整的技术栈包括: Elasticsearch:用于数据存储、计算和搜索。Logstash/Beats:用于数据收集。Kib…...

react是一种语言?
React 不是一种编程语言,而是一种用于构建用户界面的 JavaScript 库。它由 Facebook 开发,并广泛用于开发单页应用程序(SPA)。React 允许你将 UI 拆分成独立的、可复用的组件,这些组件可以接收输入(称为“p…...

如何区分这个ip是真实ip,不是虚假的ip
区分一个IP地址是真实IP还是虚假IP(伪造IP)是非常重要的,特别是在网络安全、数据采集和其他与IP相关的业务场景中。虚假IP(也称为伪造IP或假冒IP)可以通过多种方式被创建,如代理、VPN、或IP欺骗(…...

【软件测试】详解软件测试中的测试级别
目录 一、测试级别二、组件测试三、开发者测试3.1测试与调试3.2 组件测试目标3.3 测试功能 四、稳健性测试4.1 效率的测试4.2 测试可维护性4.3 测试策略4.4 白盒测试 一、测试级别 软件系统通常是由许多子系统组成的,而这些子系统又是由多个组件组成的,…...

一条sql在MySQL中是怎么执行的
目录 一、MySQL总体架构二、各层的作用1、连接层2、应用层3、存储引擎层 一、MySQL总体架构 作为常问八股文,相信不少小伙伴当年都被问到过这个问题,回答这个问题我们首先得知道MySQL服务器基本架构,主要分为连接层,应用层和存储…...
)
Git | Dockerized GitLab 安装使用(简单实操版)
1. 详细步骤 1.1 安装启动 postgresql 服务 docker pull sameersbn/postgresql:14-20230628docker run --name gitlab-postgresql -d \--env DB_NAMEgitlabhq_production \--env DB_USERgitlab --env DB_PASSpassword \--env DB_EXTENSIONpg_trgm,btree_gist \--volume /srv/…...

SpringCloud简介 Ribbon Eureka 远程调用RestTemplate类 openfeign
〇、SpringCloud 0.区别于单体项目和soa架构,微服务架构每个服务独立,灵活。 1. spring cloud是一个完整的微服务框架,springCloud包括三个体系: spring cloud Netflix spring cloud Alibaba spring 其他 2.spring cloud 版本命名…...

微信小程序开发系列之-微信小程序性能优化
微信小程序开发系列之-微信小程序性能优化 性能优化是任何应用开发中的重要组成部分,尤其是在移动环境中。对于微信小程序而言,随着用户量的增加和应用功能的丰富,性能优化显得尤为关键。良好的性能不仅提升用户体验,还能增加用户…...

线程池面试集
目录 线程池中提交一个任务的流程是怎样的? 线程池有五种状态 如何优雅的停止一个线程? 线程池的核心线程数、最大线程数该如何设置? 如何理解Java并发中的可见性、原子性、有序性? Java死锁如何避免? 线程池中提交一个任务的流程是怎样的? 线程池有五种状态 如何优…...

从密码学看盲拍合约:智能合约的隐私与安全新革命!
文章目录 前言一、什么是盲拍合约?二、盲拍合约的优势1.时间压力的缓解2.绑定与秘密的挑战 三、盲拍合约的工作原理1.提交盲出价2.披露出价3.结束拍卖4.退款机制 四、代码示例总结 前言 随着区块链技术的发展,智能合约在各种场景中的应用越来越广泛。盲…...
)
c++学习笔记(47)
七、_public.cpp #include "_public.h" // 如果信号量已存在,获取信号量;如果信号量不存在,则创建它并初始化为 value。 // 如果用于互斥锁,value 填 1,sem_flg 填 SEM_UNDO。 // 如果用于生产消费者模型&am…...

软件设计之SSM(1)
软件设计之SSM(1) 路线图推荐: 【Java学习路线-极速版】【Java架构师技术图谱】 尚硅谷新版SSM框架全套视频教程,Spring6SpringBoot3最新SSM企业级开发 资料可以去尚硅谷官网免费领取 学习内容: Spring框架结构SpringIoC容器SpringIoC实践…...

STM32F745IE 能进定时器中断,无法进主循环
当你遇到STM32F745IE这类问题,即能够进入定时器中断但无法进入主循环(main() 函数中的循环),可能的原因和解决方法包括以下几个方面: 检查中断优先级和嵌套: 确保没有其他更高优先级的中断持续运行并阻止了主循环的执行。使用调试工具查看中断的进入和退出情况。检查中断…...

《凡人歌》中的IT职业启示录
《凡人歌》是由中央电视台、正午阳光、爱奇艺出品,简川訸执导,纪静蓉编剧,侯鸿亮任制片,殷桃、王骁领衔主演,章若楠、秦俊杰、张哲华、陈昊宇主演的都市话题剧 ,改编自纪静蓉的小说《我不是废柴》。该剧于2…...

go libreoffice word 转pdf
一、main.go 关键代码 完整代码 package mainimport ("fmt""github.com/jmoiron/sqlx""github.com/tealeg/xlsx""log""os/exec""path/filepath" ) import _ "github.com/go-sql-driver/mysql"import &q…...

打造双模兼容npm包:无缝支持require与import
为了实现一个npm包同时支持require和import,你需要确保你的包同时提供了CommonJS和ES6模块的入口点。这通常是通过在package.json文件中指定main和module字段来实现的,以及在构建过程中生成两种不同模块格式的文件。 以下是具体步骤: 设置pa…...

便捷将屏幕投射到安卓/iOS设备-屏幕投射到安卓/iOS设备,Windows/Mac电脑或智能电视上-供大家学习研究参考
1. 下载并安装软件(安卓苹果都需要) 确保 Android 设备和 Windows/Mac电脑都安装。启动应用程序并将 Android 设备和 Windows / Mac 了解到同一个wifi下面。 2、 发起投屏请求 在接收设备上:...

yolox训练自己的数据集
环境搭建 gpu按自己情况安装 nvidia-smi 查看自己的版本 CUDA和cudnn 按自己的安装,我的驱动551.76,注意不要用最新的,官网只要求驱动是大于等于,可以用低版本的cuda,我安装的是CUDA 11.1 cuda下载后,…...
Centos8.5.2111(1)之本地yum源搭建和docker部署与网络配置
由于后边可能要启动多个服务,避免服务之间相互干扰,本课程建议每个服务独立部署到一台主机上,这样做会导致资源占用过多,可能会影响系统的运行。服务器部署一般不采用GUI图形界面部署,而是采用命令行方式部署ÿ…...

基于SSM+小程序的自习室选座与门禁管理系统(自习室1)(源码+sql脚本+视频导入教程+文档)
👉文末查看项目功能视频演示获取源码sql脚本视频导入教程视频 1 、功能描述 1、管理员实现了首页、基础数据管理、论坛管理、公告信息管理、用户管理、座位管理等 2、用户实现了在论坛模块通过发帖与评论帖子的方式进行信息讨论,也能对账户进行在线充值…...

19c补丁后oracle属主变化,导致不能识别磁盘组
补丁后服务器重启,数据库再次无法启动 ORA01017: invalid username/password; logon denied Oracle 19c 在打上 19.23 或以上补丁版本后,存在与用户组权限相关的问题。具体表现为,Oracle 实例的运行用户(oracle)和集…...

盘古信息PCB行业解决方案:以全域场景重构,激活智造新未来
一、破局:PCB行业的时代之问 在数字经济蓬勃发展的浪潮中,PCB(印制电路板)作为 “电子产品之母”,其重要性愈发凸显。随着 5G、人工智能等新兴技术的加速渗透,PCB行业面临着前所未有的挑战与机遇。产品迭代…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

从深圳崛起的“机器之眼”:赴港乐动机器人的万亿赛道赶考路
进入2025年以来,尽管围绕人形机器人、具身智能等机器人赛道的质疑声不断,但全球市场热度依然高涨,入局者持续增加。 以国内市场为例,天眼查专业版数据显示,截至5月底,我国现存在业、存续状态的机器人相关企…...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...

使用Spring AI和MCP协议构建图片搜索服务
目录 使用Spring AI和MCP协议构建图片搜索服务 引言 技术栈概览 项目架构设计 架构图 服务端开发 1. 创建Spring Boot项目 2. 实现图片搜索工具 3. 配置传输模式 Stdio模式(本地调用) SSE模式(远程调用) 4. 注册工具提…...

七、数据库的完整性
七、数据库的完整性 主要内容 7.1 数据库的完整性概述 7.2 实体完整性 7.3 参照完整性 7.4 用户定义的完整性 7.5 触发器 7.6 SQL Server中数据库完整性的实现 7.7 小结 7.1 数据库的完整性概述 数据库完整性的含义 正确性 指数据的合法性 有效性 指数据是否属于所定…...

20个超级好用的 CSS 动画库
分享 20 个最佳 CSS 动画库。 它们中的大多数将生成纯 CSS 代码,而不需要任何外部库。 1.Animate.css 一个开箱即用型的跨浏览器动画库,可供你在项目中使用。 2.Magic Animations CSS3 一组简单的动画,可以包含在你的网页或应用项目中。 3.An…...
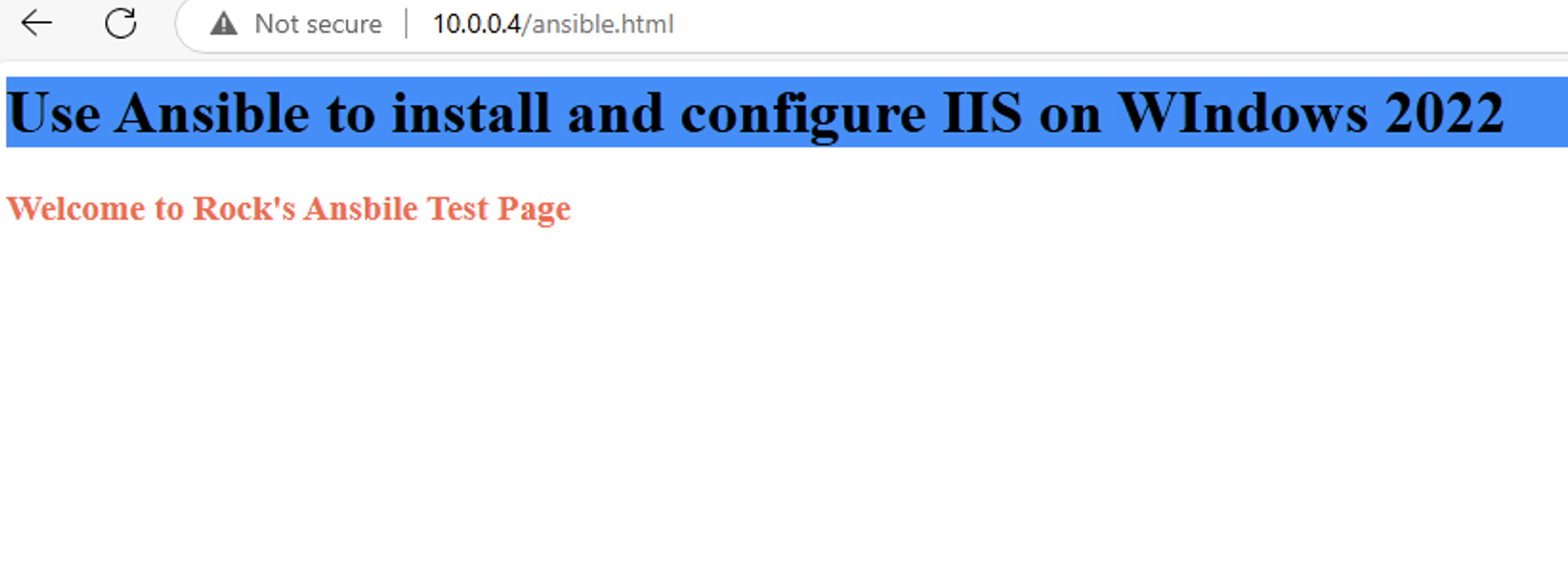
通过 Ansible 在 Windows 2022 上安装 IIS Web 服务器
拓扑结构 这是一个用于通过 Ansible 部署 IIS Web 服务器的实验室拓扑。 前提条件: 在被管理的节点上安装WinRm 准备一张自签名的证书 开放防火墙入站tcp 5985 5986端口 准备自签名证书 PS C:\Users\azureuser> $cert New-SelfSignedCertificate -DnsName &…...