前端大模型入门:使用Transformers.js手搓纯网页版RAG(二)- qwen1.5-0.5B - 纯前端不调接口
书接上文,本文完了RAG的后半部分,在浏览器运行qwen1.5-0.5B实现了增强搜索全流程。但受限于浏览器和模型性能,仅适合于研究、离线和高隐私场景,但对前端小伙伴来说大模型也不是那么遥不可及了,附带全部代码,动手试试吧! 纯前端,不适用第三方接口
1 准备工作
1.1 前置知识
- 读完前端大模型入门:使用Transformers.js实现纯网页版RAG(一)
- 了解WebML 前端大模型入门:Transformer.js 和 Xenova
- 基本的前端开发知识,esm和async/await
1.2页面代码框架
<!DOCTYPE html>
<html lang="en"><head><meta charset="UTF-8" /><title>网页端侧增强搜索</title>
</head><body><div id="app"><div><input type="text" id="question" /><button id="search">提问</button></div><div id="info"></div></div><script type="module">import {pipeline,env,cos_sim,} from "https://cdn.jsdelivr.net/npm/@xenova/transformers@2.17.2/dist/transformers.min.js";env.remoteHost = "https://hf-mirror.com";// 后续代码位置</script>
</body></html>1.3 chrom/edge浏览器
目前测试firefox模型缓存有问题,建议用这两个,首次加载模型需要点时间,后续就不需要了,记住刷新时按F5不要清空缓存了。
2 搜索代码实现 - R
2.1 准备好知识库和初始化向量库
前一篇文章已经介绍了相关内容,本文知识库有些不一样,因为是需要给大模型去生成回答,而不是直接给出答案,所以合并在了一起。
const knowledges = ["问:洛基在征服地球的尝试中使用了什么神秘的物体?\n答:六角宝","问:复仇者联盟的哪两名成员创造了奥创?\n答:托尼·斯塔克(钢铁侠)和布鲁斯·班纳(绿巨人浩克)。","问:灭霸如何实现了他在宇宙中消灭一半生命的计划?\n答:通过使用六颗无限宝石","问:复仇者联盟用什么方法扭转了灭霸的行动?\n通过时间旅行收集宝石。","问:复仇者联盟的哪位成员牺牲了自己来打败灭霸?\n答:托尼·斯塔克(钢铁侠)",];const verctorStore = [];2.2 定义打印输出和参数
topK控制送给大模型处理的最匹配的知识数量上下,越多的知识条数prompt越大会导致处理用时越长,一般三个最匹配的知识就差不多够用了,尤其是在网页中运行时
const infoEl = document.getElementById("info");const print = text => infoEl.innerHTML = text;const knowEl = document.getElementById("knowEl");const topK = 3;2.3 准备好嵌入和生成模型
嵌入使用 bge-base ,回答生成使用qwen1.5-0.5B
const embedPipe = pipeline("feature-extraction", "Xenova/bge-base-zh-v1.5", {progress_callback: (d) => {infoEl.innerHTML = `embed:${JSON.stringify(d)}`;},});const chatPipe = pipeline('text-generation', 'Xenova/Qwen1.5-0.5B-Chat', {progress_callback: (d) => {infoEl.innerHTML = `chat:${JSON.stringify(d)}`;},});2.4 定义向量库数据初始方法
这个不多赘述,和前一篇的类似
const buildVector = async () => {if (!verctorStore.size) {const embedding = await embedPipe;print(`构建向量库`)const output = await embedding(knowledges, {pooling: "mean",normalize: true,});knowledges.forEach((q, i) => {verctorStore[i] = output[i];});}};
2.5 定义问答主方法
这里也不赘述过多,和上一篇不同之处在于:根据score从大到小排序,选出topK传入生成方法
const search = async () => {const start = Date.now()const embedding = await embedPipe;const question = document.getElementById("question").value;const [qVector] = await embedding([question], {pooling: "mean",normalize: true,});await buildVector();const scores = verctorStore.map((q, i) => {return {score: cos_sim(qVector.data, verctorStore[i].data),knowledge: knowledges[i],index: i,};});scores.sort((a, b) => b.score - a.score);const picks = scores.slice(0, topK)const docs = picks.map(e => e.knowledge)const answer = await generateAnswer(question, docs.join('\n'))print(answer + `(用时:${Date.now()- start}ms)`)};document.querySelector("#search").onclick = search;3 生成代码实现 - G
这一部分主要介绍generateAnser的实现
3.1 定义prompt
这部分自己测试时可多调整下,prompt定义的越好效果越好
const prompt =`请根据【上下文】回答【问题】,当得不到较为准确的答案时,必须回答我不知道。【上下文】${context}【问题】${question}请给出你的答案:`3.2 构建消息和输入
const messages = [{ role: 'system', content: '你是一个分析助手,根据上下文回答问题。必须生成更人性化的答案。' },{ role: 'user', content: prompt }]console.log(messages)// 生成chaconst text = generator.tokenizer.apply_chat_template(messages, {tokenize: false,add_generation_prompt: true,});console.log(text)3.3 等待回答返回首个答案
print(`思考中...`)const output = await generator(text, {max_new_tokens: 128,do_sample: false,return_full_text: false,});console.log(output)return output[0].generated_text;4 运行测试
4.1 等待模型加载就绪
嵌入和千问整体有接近1G的数据下载,需要稍微等待下,直到看到下图所示结果

4.2 输入提问
我的问题是“他是怎么实现计划的”,点击提问
4.3 检查控制台输出的prompt
可以看到匹配到的三个答案和问题
<|im_start|>system
你是一个分析助手,根据上下文回答问题。必须生成更人性化的答案。<|im_end|>
<|im_start|>user
请根据【上下文】回答【问题】,当得不到较为准确的答案时,必须回答我不知道。【上下文】问:灭霸如何实现了他在宇宙中消灭一半生命的计划?
答:通过使用六颗无限宝石
问:复仇者联盟用什么方法扭转了灭霸的行动?
通过时间旅行收集宝石。
问:洛基在征服地球的尝试中使用了什么神秘的物体?
答:六角宝【问题】他是怎么实现计划的请给出你的答案:<|im_end|>
<|im_start|>assistant
4.4 等待回复
耗时25s,有点长,但考虑到这是可以离线在端侧运行的非gpu版本,用于做一些后台任务还是可以的,结果如下
5 总结
5.1 qwen1.5-0.5B比预期效果好
结果比续期要好一些,因为比较新的web版本大模型就找到qwen1.5-0.5B的,后续有时间我会出一期试试llama3.2-1B,但整个过程会比较长 - 因为还涉及到模型迁移
5.2 除非离线和高隐私环境网页大模型暂不适用
受限于网页性能和WebGPU的支持在transformer.js处于实验性阶段,生成用时比较久,除非是离线环境,以及对隐私要求比较高的情况下,目前的响应速度还是比较慢的
最近眼睛肿了,今天就一篇吧,剩下时间休息了,明天又得上班 ~ 啊啊啊
相关文章:
前端大模型入门:使用Transformers.js手搓纯网页版RAG(二)- qwen1.5-0.5B - 纯前端不调接口
书接上文,本文完了RAG的后半部分,在浏览器运行qwen1.5-0.5B实现了增强搜索全流程。但受限于浏览器和模型性能,仅适合于研究、离线和高隐私场景,但对前端小伙伴来说大模型也不是那么遥不可及了,附带全部代码,…...

K-means聚类分析对比
K-means聚类分析,不同K值聚类对比,该内容是关于K-means聚类分析的,主要探讨了不同K值对聚类结果的影响。K-means聚类是一种常见的数据分析方法,用于将数据集划分为K个不同的类别。在这个过程中,选择合适的K值是非常关键…...

tar命令:压缩、解压的好工具
一、命令简介 用途: tar 命令用于创建归档文件(tarball),以及从归档文件中提取文件。 标签: 文件管理,归档。 特点: 归档文件可以保留原始文件和目录的层次结构,通常使用 .tar …...

Mac电脑上最简单安装Python的方式
背景 最近换了一台新的 MacBook Air 电脑,所有的开发软件都没有了,需要重新配环境,而我现在最常用的开发程序就是Python。这篇文章记录一下我新Mac电脑安装Python的全过程,也给大家一些思路上的提醒。 以下是我新电脑的配置&…...

Linux基础命令cd详解
cd(change directory)命令是 Linux 中用于更改当前工作目录的基础命令。它没有很多复杂的参数,但它的使用非常频繁。以下是 cd 命令的详细说明及示例。 基本语法 cd [选项] [路径] 常用选项 -L : 使用逻辑路径(默认选项&…...

【大模型对话 的界面搭建-Open WebUI】
Open WebUI 前身就是 Ollama WebUI,为 Ollama 提供一个可视化界面,可以完全离线运行,支持 Ollama 和兼容 OpenAI 的 API。 github网址 https://github.com/open-webui/open-webui安装 第一种 docker安装 如果ollama 安装在同一台服务器上&…...

如何在算家云搭建text-generation-webui(文本生成)
一、text-generation-webui 简介 text-generation-webui 是一个流行的用于文本生成的 Gradio Web UI。支持 transformers、GPTQ、AWQ、EXL2、llama.cpp (GGUF)、Llama 模型。 它的特点如下, 3 种界面模式:default (two columns), notebook, chat支持多…...

【Java SE】初遇Java,数据类型,运算符
🔥博客主页🔥:【 坊钰_CSDN博客 】 欢迎各位点赞👍评论✍收藏⭐ 1. Java 概述 1.1 Java 是什么 Java 是一种高级计算机语言,是一种可以编写跨平台应用软件,完全面向对象的程序设计语言。Java 语言简单易学…...

XSS(内含DVWA)
目录 一.XSS的攻击方式: 1. 反射型 XSS(Reflected XSS) 2. 存储型 XSS(Stored XSS) 3. DOM型 XSS(DOM-based XSS) 总结 二..XSS的危害 三.常见的XSS方式 1.script标签 四.常见基本过滤方…...

【SpringCloud】环境和工程搭建
环境和工程搭建 1. 案例介绍1.1 需求1.2 服务拆分服务拆分原则服务拆分⽰例 2. 项目搭建 1. 案例介绍 1.1 需求 实现⼀个电商平台(不真实实现, 仅为演⽰) ⼀个电商平台包含的内容⾮常多, 以京东为例, 仅从⾸⻚上就可以看到巨多的功能 我们该如何实现呢? 如果把这些功能全部…...

基于Java开发的(控制台)模拟的多用户多级目录的文件系统
多级文件系统 1 设计目的 为了加深对文件系统内部功能和实现过程的理解,设计一个模拟的多用户多级目录的文件系统,并实现具体的文件物理结构、目录结构以及较为完善的文件操作命令集。 2 设计内容 2.1系统操作 操作命令风格:本文件系统的…...

tailwindcss group-hover 不生效
无效 <li class"group"><div class"tw-opacity-0 group-hover:tw-opacity-100" /> </li>配了tw前缀,group要改成tw-group // tailwind.config.jsmodule.exports {prefix: "tw-", }<li class"tw-group&q…...
)
python环境配置问题(个人经验)
很久没配置 python 新环境了,最近新项目需要进行配置,在配置过程中发现了不少问题,记录下。 问题1:fatal error: longintrepr.h: 没有那个文件或目录 这个问题的原因是新环境的 python 版本(3.10以上)与本地的版本(3.8.x)差异过…...

BERT训练之数据集处理(代码实现)
目录 1读取文件数据 2.生成下一句预测任务的数据 3.预测下一个句子 4.生成遮蔽语言模型任务的数据 5.从词元中得到遮掩的数据 6.将文本转化为预训练数据集 7.封装函数类 8.调用 import os import random import torch import dltools 1读取文件数据 def _read_wiki(data_d…...
一款辅助渗透测试过程,让渗透测试报告一键生成
《网安面试指南》http://mp.weixin.qq.com/s?__bizMzkwNjY1Mzc0Nw&mid2247484339&idx1&sn356300f169de74e7a778b04bfbbbd0ab&chksmc0e47aeff793f3f9a5f7abcfa57695e8944e52bca2de2c7a3eb1aecb3c1e6b9cb6abe509d51f&scene21#wechat_redirect 《Java代码审…...

力扣最热一百题——颜色分类
目录 题目链接:75. 颜色分类 - 力扣(LeetCode) 题目描述 示例 提示: 解法一:不要脸用sort Java写法: 运行时间 解法二:O1指针 Java写法: 重点 运行时间 C写法:…...
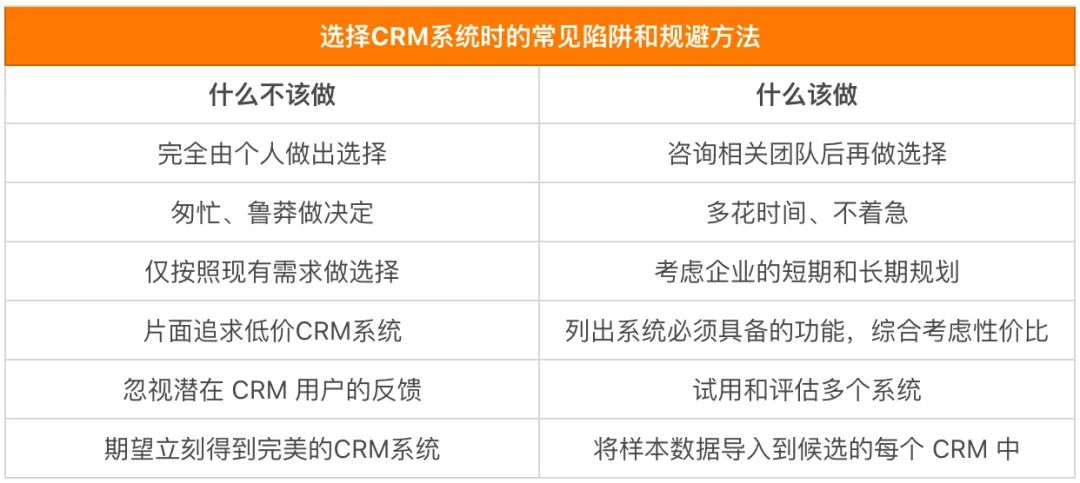
2024年工业制造企业CRM研究报告:需求清单、市场格局、案例分析
我国是世界上产业体系最完备的国家,拥有全球规模最大、门类最齐全的生产制造体系,在500种主要工业产品中,有四成以上产品产量位居全球第一。2023年制造业增加值达33万亿元,占世界的比重稳定在30%左右,我国制造业增加值…...

Spring MVC参数接收 总结
1. 简介 Spring MVC可以简化从前端接收参数的步骤。 2. Param传参 通过设定函数入参和添加标记来简化接受: //参数接收 RequestMapping("product") ResponseBody //接受/product?productgoods&id123 //1.名称必须相同,2.不传值不会不…...

Docekrfile和docker compose编写指南及注意事项
Dockerfile 基础语法 我们通过编写dockerfile,将每一层要做的事情使用语法固定下来,之后运行指令就可以通过docker来制作自己的镜像了。 构建镜像的指令:docker build /path -t imageName:tag 注意,docker build后的path必须是dockerfile…...

VITS源码解读6-训练推理
1. train.py 1.1 大体流程 执行main函数,调用多线程和run函数执行run函数,加载日志、数据集、模型、模型优化器for循环迭代数据batch,每次执行train_and_evaluate函数,训练模型 这里需要注意,源码中加载数据集用的分…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

【JVM】- 内存结构
引言 JVM:Java Virtual Machine 定义:Java虚拟机,Java二进制字节码的运行环境好处: 一次编写,到处运行自动内存管理,垃圾回收的功能数组下标越界检查(会抛异常,不会覆盖到其他代码…...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

【python异步多线程】异步多线程爬虫代码示例
claude生成的python多线程、异步代码示例,模拟20个网页的爬取,每个网页假设要0.5-2秒完成。 代码 Python多线程爬虫教程 核心概念 多线程:允许程序同时执行多个任务,提高IO密集型任务(如网络请求)的效率…...

CRMEB 框架中 PHP 上传扩展开发:涵盖本地上传及阿里云 OSS、腾讯云 COS、七牛云
目前已有本地上传、阿里云OSS上传、腾讯云COS上传、七牛云上传扩展 扩展入口文件 文件目录 crmeb\services\upload\Upload.php namespace crmeb\services\upload;use crmeb\basic\BaseManager; use think\facade\Config;/*** Class Upload* package crmeb\services\upload* …...

mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包
文章目录 现象:mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包遇到 rpm 命令找不到已经安装的 MySQL 包时,可能是因为以下几个原因:1.MySQL 不是通过 RPM 包安装的2.RPM 数据库损坏3.使用了不同的包名或路径4.使用其他包…...
)
Android第十三次面试总结(四大 组件基础)
Activity生命周期和四大启动模式详解 一、Activity 生命周期 Activity 的生命周期由一系列回调方法组成,用于管理其创建、可见性、焦点和销毁过程。以下是核心方法及其调用时机: onCreate() 调用时机:Activity 首次创建时调用。…...

中医有效性探讨
文章目录 西医是如何发展到以生物化学为药理基础的现代医学?传统医学奠基期(远古 - 17 世纪)近代医学转型期(17 世纪 - 19 世纪末)现代医学成熟期(20世纪至今) 中医的源远流长和一脉相承远古至…...

面向无人机海岸带生态系统监测的语义分割基准数据集
描述:海岸带生态系统的监测是维护生态平衡和可持续发展的重要任务。语义分割技术在遥感影像中的应用为海岸带生态系统的精准监测提供了有效手段。然而,目前该领域仍面临一个挑战,即缺乏公开的专门面向海岸带生态系统的语义分割基准数据集。受…...

动态 Web 开发技术入门篇
一、HTTP 协议核心 1.1 HTTP 基础 协议全称 :HyperText Transfer Protocol(超文本传输协议) 默认端口 :HTTP 使用 80 端口,HTTPS 使用 443 端口。 请求方法 : GET :用于获取资源,…...