计算物理精解【8】-计算原理精解【5】
文章目录
- logistic模型
- 多元回归分析
- 多元回归分析概览
- 1. 多元回归的概念与重要性
- 2. 多元回归在实际应用中的例子
- 3. 多元回归在预测和解释数据中的优势和局限性
- 4. 多元回归的优缺点及改进建议
- 多元线性回归分析详解
- 一、原理
- 二、性质
- 三、计算
- 四、例子与例题
- 五、应用场景
- 六、优缺点
- 七、实际案例
- 多元非线性回归分析详解
- 一、原理
- 二、应用场景
- 三、优缺点
- 四、案例分析
- 例子
- 例题
- 连结函数
- 线性模型
- 广义线性模型(GLM)
- 连结函数(Link Function)
- Logistic模型
- 1. Logistic模型的定义和起源
- 2. Logistic模型的数学公式和物理意义
- 数学公式
- 物理意义
- 3. Logistic模型在各个领域的应用案例
- 4. Logistic模型的优点和局限性
- 优点
- 局限性
- 5. Logistic模型的实例或数据
- Logistic模型的局限性
- Logistic回归分析
- 1. 定义
- 2. 计算
- 3. 性质
- 4. 例子
- 5. 例题
- 例子:研究生录取预测
- 数据集描述:
- 分析步骤:
- 例题:
- 参考文献
logistic模型
多元回归分析
多元回归分析概览
1. 多元回归的概念与重要性
多元回归分析是一种统计技术,它用于探究两个或多个自变量(解释变量)与因变量(响应变量)之间的线性关系。通过构建一个包含多个自变量的数学模型,多元回归能够更全面地捕捉现实世界中复杂现象的本质,揭示变量间的相互作用及其对因变量的综合影响。这一方法在经济预测、市场分析、医学研究、社会科学等多个领域内具有广泛的应用价值和重要性,因为它能够帮助研究者理解数据背后的规律,从而做出更为精准的决策和预测。
2. 多元回归在实际应用中的例子
- 经济学:经济学家利用多元回归分析预测国家GDP增长,通过分析投资、消费、出口等多个经济指标的影响来构建预测模型。
- 市场营销:营销人员通过分析顾客年龄、性别、收入水平及购买历史等多因素,建立多元回归模型来预测产品销售量,优化营销策略。
- 医疗健康:研究人员利用多元回归探究饮食习惯、运动量、遗传因子等因素对特定疾病风险的影响,为疾病预防提供科学依据。
- 环境科学:环境科学家通过多元回归分析评估不同污染源(如工业排放、汽车尾气等)对空气质量的影响,为环境保护政策制定提供依据。
3. 多元回归在预测和解释数据中的优势和局限性
优势:
- 综合分析能力:多元回归能够同时考虑多个自变量对因变量的影响,提供全面的分析视角。
- 预测精度高:当自变量与因变量之间存在明确的线性关系时,多元回归模型能够提供较为准确的预测。
- 解释性强:模型参数直接反映了各自变量对因变量的影响程度,便于理解和解释。
局限性:
- 线性假设:多元回归基于自变量与因变量之间线性关系的假设,对于非线性关系可能不适用。
- 多重共线性:自变量间的高度相关性可能导致模型参数估计不稳定,影响模型解释力。
- 数据要求严格:要求数据满足一定的假设条件,如正态性、独立性、等方差性等,否则可能影响模型的有效性。
4. 多元回归的优缺点及改进建议
优点:
- 理论成熟:多元回归作为经典的统计方法,理论基础坚实,应用广泛。
- 操作简便:借助现代统计软件,多元回归的分析过程相对简单快捷。
缺点:
- 对异常值敏感:极端数据点可能对模型结果产生较大影响。
- 模型复杂性限制:对于高度复杂或非线性的数据关系,多元回归可能无法充分捕捉。
改进建议:
- 数据预处理:在进行多元回归分析前,应进行数据清洗,剔除异常值,确保数据满足模型假设。
- 考虑非线性关系:对于可能存在非线性关系的数据,可以尝试使用多项式回归、广义线性模型或机器学习算法等方法。
- 处理多重共线性:采用变量选择、主成分回归、岭回归等方法减轻多重共线性的影响。
- 交叉验证:通过交叉验证评估模型性能,确保模型的泛化能力。
综上所述,多元回归分析作为一种强大的统计工具,在数据分析与预测中发挥着重要作用,但同时也需关注其局限性,并采取相应的改进措施以提高分析的准确性和可靠性。
多元线性回归分析详解
一、原理
多元线性回归分析是一种统计分析方法,用于研究两个或两个以上的自变量(解释变量)与一个因变量(响应变量)之间的线性关系。其基本原理可以概括为:因变量y的变化可以由两部分解释,一部分是由k个自变量x的变化引起的y的变化部分,另一部分是由其他随机因素引起的y的变化部分。多元线性回归模型的一般形式为:
Y = β 0 + β 1 X 1 + β 2 X 2 + ⋯ + β k X k + ϵ Y = \beta_0 + \beta_1X_1 + \beta_2X_2 + \cdots + \beta_kX_k + \epsilon Y=β0+β1X1+β2X2+⋯+βkXk+ϵ
其中,Y是因变量, X 1 , X 2 , … , X k X_1, X_2, \ldots, X_k X1,X2,…,Xk是自变量, β 0 , β 1 , … , β k \beta_0, \beta_1, \ldots, \beta_k β0,β1,…,βk是回归系数,代表各自变量对因变量的影响程度, ϵ \epsilon ϵ是误差项,表示模型未能解释的部分。
二、性质
- 线性性:模型假设自变量与因变量之间存在线性关系。
- 独立性:模型中的每个观察值都应该是相互独立的。
- 正态性:因变量和自变量都应该服从正态分布,或至少误差项 ϵ \epsilon ϵ应服从正态分布。
- 同方差性:误差项的方差应为常数,不随自变量的变化而变化。
- 无多重共线性:自变量之间不应存在高度相关性,以避免模型估计的不稳定。
三、计算
多元线性回归模型的参数估计通常采用最小二乘法,即通过最小化误差项平方和来求解回归系数。具体计算过程可以借助统计软件(如SPSS、R、Python的scikit-learn等)完成。计算步骤一般包括:
- 收集数据:包括因变量和多个自变量的观测值。
- 设定模型:根据问题背景和数据特点,设定多元线性回归模型的形式。
- 参数估计:使用最小二乘法或其他优化算法估计回归系数。
- 模型检验:对模型进行显著性检验、共线性诊断等,确保模型的合理性和有效性。
四、例子与例题
例子:假设我们要研究某地区房价(Y)与房屋面积( X 1 X_1 X1)、地理位置评分( X 2 X_2 X2)、房龄( X 3 X_3 X3)之间的关系。我们可以收集相关数据,设定多元线性回归模型,并通过计算得到如下回归方程:
Y = β 0 + β 1 X 1 + β 2 X 2 + β 3 X 3 Y = \beta_0 + \beta_1X_1 + \beta_2X_2 + \beta_3X_3 Y=β0+β1X1+β2X2+β3X3
其中, β 0 , β 1 , β 2 , β 3 \beta_0, \beta_1, \beta_2, \beta_3 β0,β1,β2,β3分别表示常数项、房屋面积、地理位置评分、房龄对房价的影响系数。
例题:具体计算过程可能涉及复杂的数学推导,但通常统计软件会自动完成。例如,在SPSS中,用户只需输入数据并指定因变量和自变量,软件即可输出回归系数、显著性检验结果等关键信息。
五、应用场景
多元线性回归分析广泛应用于各个领域,包括但不限于:
- 经济学:研究收入、教育水平、失业率等因素对消费支出的影响。
- 市场营销:分析广告投入、促销活动、产品特性等因素对销售额的影响。
- 医学研究:探讨多种生活方式因素(如饮食、运动)对健康指标(如血压、血糖)的影响。
- 房地产评估:利用房屋面积、地理位置、房龄等因素预测房价。
- 金融分析:分析宏观经济指标、公司财务指标等对股票价格或收益率的影响。
六、优缺点
优点:
- 全面性强:能够考虑多个自变量对因变量的影响,提供更为全面的分析视角。
- 解释性好:回归系数具有明确的解释意义,能够量化各自变量对因变量的影响程度。
- 预测精度高:在自变量与因变量之间存在线性关系的情况下,预测结果较为准确。
缺点:
- 线性假设限制:当数据存在非线性关系时,模型拟合效果可能不佳。
- 多重共线性问题:自变量之间的高度相关性可能导致模型估计的不稳定。
- 数据要求严格:需要满足独立性、正态性、同方差性等假设条件,否则可能影响模型的有效性。
七、实际案例
以房地产评估中的房价预测为例,某研究团队收集了某地区近年来房屋成交数据,包括房屋面积、地理位置评分、房龄等自变量以及实际成交价格作为因变量。通过设定多元线性回归模型并借助统计软件进行分析,他们得出了各自变量对房价的影响系数。结果表明,房屋面积和地理位置评分对房价有显著的正向影响,而房龄则对房价有负向影响。这一发现为房地产评估提供了重要参考依据,有助于更准确地预测房价走势。
多元非线性回归分析详解
一、原理
多元非线性回归分析是指包含两个以上变量的非线性回归模型。这类模型用于描述因变量与自变量之间非线性关系的复杂情况。在多元非线性回归分析中,因变量Y是多个自变量X1, X2, …, Xn的非线性函数,数学上通常表示为:
Y = f ( X 1 , X 2 , . . . , X n ; θ ) + ϵ Y = f(X_1, X_2, ..., X_n; \theta) + \epsilon Y=f(X1,X2,...,Xn;θ)+ϵ
其中, f f f是非线性函数, θ \theta θ是需要估计的参数, ϵ \epsilon ϵ是误差项。由于非线性模型通常难以直接求解,传统做法是通过适当的数学变换(如对数变换、指数变换等)尝试将其转化为线性模型,但并非所有非线性模型都能成功线性化。对于无法线性化的模型,则直接采用非线性优化方法进行参数估计,如最小二乘法结合数值优化算法(如梯度下降法、牛顿法等)。
二、应用场景
多元非线性回归分析的应用场景非常广泛,包括但不限于以下几个领域:
- 生物统计学:用于研究生物过程中的非线性关系,如药物在体内的代谢过程。
- 经济学:分析经济变量之间的复杂关系,如市场趋势、消费者行为等。
- 工程学:模拟和预测工程系统的行为,如机械部件的应力-应变关系。
- 环境科学:研究环境因素与生态系统之间的关系,如气候变化对生态系统的影响。
- 医学研究:研究药物剂量与疗效之间的关系,或疾病的进展模型。
- 金融分析:预测股票价格、评估风险和回报之间的关系。
- 房地产评估:用于房价预测,考虑位置、面积、市场趋势等多种因素。
- 销售预测:预测产品销售量,考虑季节性因素、促销活动等非线性因素。
三、优缺点
优点:
- 强大的拟合能力:能够处理变量之间的复杂关系,拟合线性回归无法捕捉的曲线或非直线关系。
- 灵活性:模型形式多样,如多项式、指数、对数和Sigmoid函数等,适应不同的数据模式。
- 更好地反映现实世界:现实世界中的许多现象并不是线性的,非线性回归可以更准确地描述这些现象。
- 预测能力:由于非线性模型能够适应数据的复杂性,因此通常能够提供更准确的预测。
缺点:
- 模型复杂性:非线性模型通常比线性模型更复杂,需要更多的专业知识来构建和解释。
- 参数估计的困难:参数估计可能不如线性回归那样直观和简单,需要使用数值优化方法,计算复杂且可能陷入局部最小值。
- 计算成本:非线性回归通常需要更多的计算资源和时间,特别是当模型复杂或数据集很大时。
- 模型诊断的挑战:非线性模型的诊断比线性模型更复杂,需要更高级的统计技术来检测模型假设的违反。
- 过度拟合风险:如果模型过于复杂,可能会过度拟合数据,降低模型的泛化能力。
四、案例分析
以房地产评估中的房价预测为例,假设我们希望通过多个自变量(如房屋面积、位置评分、房龄、周边设施完善度等)来预测房价。由于房价与这些自变量之间可能存在非线性关系(如房价随房屋面积的增加而增加,但增加速度可能逐渐放缓),因此适合采用多元非线性回归模型。
具体建模过程中,我们可以首先收集相关数据,并进行必要的数据预处理(如缺失值处理、异常值检测等)。然后,根据数据的特性和领域知识选择合适的非线性模型形式(如多项式回归模型、指数模型等)。接着,使用非线性回归方法进行参数估计,并对模型进行诊断和优化。最后,利用训练好的模型进行房价预测,并评估其预测精度和泛化能力。
通过以上案例分析可以看出,多元非线性回归分析在房地产评估等实际应用中具有重要价值,能够帮助我们更准确地理解和预测复杂现象。
例子
假设我们正在研究一个农业生产问题,目标是预测某种作物的产量(Y),我们考虑的自变量包括土壤湿度(X1)、施肥量(X2)和温度(X3)。由于这些因素与作物产量之间的关系可能不是线性的,我们决定使用多元非线性回归分析。
我们假设模型的形式为:
Y = β 0 + β 1 ⋅ log ( X 1 ) + β 2 ⋅ X 2 2 + β 3 ⋅ X 3 + ϵ Y = \beta_0 + \beta_1 \cdot \log(X_1) + \beta_2 \cdot X_2^2 + \beta_3 \cdot \sqrt{X_3} + \epsilon Y=β0+β1⋅log(X1)+β2⋅X22+β3⋅X3+ϵ
这里,我们选择了对数函数、二次函数和平方根函数来捕捉自变量与因变量之间的非线性关系。
例题
为了具体说明多元非线性回归分析的计算过程,我们构造一个简化的数据集(如下表所示),并使用Python的scipy.optimize库来拟合模型。
| 土壤湿度 (X1) | 施肥量 (X2) | 温度 (X3) | 产量 (Y) |
|---|---|---|---|
| 60 | 100 | 20 | 250 |
| 70 | 150 | 25 | 300 |
| 80 | 200 | 30 | 360 |
| … | … | … | … |
(注意:这里只列出了部分数据,实际分析时应包含更多观测值。)
Python代码实现:
首先,我们需要导入必要的库,并定义非线性模型函数。
import numpy as np
from scipy.optimize import curve_fit# 定义非线性模型函数
def nonlinear_model(X, beta0, beta1, beta2, beta3):X1, X2, X3 = Xreturn beta0 + beta1 * np.log(X1) + beta2 * X2**2 + beta3 * np.sqrt(X3)# 假设数据(这里只列出了部分,实际应包含完整数据集)
X_data = np.array([[60, 100, 20],[70, 150, 25],[80, 200, 30],# ... (其他数据)
])
Y_data = np.array([250, 300, 360, # ... (其他数据对应的Y值)])# 使用curve_fit函数拟合模型
params, covariance = curve_fit(nonlinear_model, X_data, Y_data)# 输出拟合参数
print("拟合参数:", params)
在这段代码中,我们首先导入了numpy和scipy.optimize库。然后,我们定义了非线性模型函数nonlinear_model,它接受自变量X(一个包含X1, X2, X3的数组)和回归参数beta0, beta1, beta2, beta3,并返回预测的Y值。
接下来,我们构造了包含自变量和因变量观测值的数据集(这里只列出了部分数据)。最后,我们使用curve_fit函数来拟合模型,并输出拟合参数。
结果解释:
curve_fit函数会返回拟合参数(即beta0, beta1, beta2, beta3的值)和参数的协方差矩阵。拟合参数告诉我们每个自变量在模型中的权重和形式,而协方差矩阵可以用于评估参数估计的不确定性。
通过这个例子,我们可以看到多元非线性回归分析如何用于实际问题中,以及如何使用Python代码来实现这一过程。在实际应用中,数据集通常更加复杂和庞大,但基本原理和步骤是相似的。
连结函数
在统计学和机器学习中,线性模型是一类广泛使用的模型,它们通过线性组合输入特征来预测输出目标。而连结函数(Link Function)则在线性模型,尤其是在广义线性模型(Generalized Linear Model, GLM)中扮演着重要角色。下面是对这两个概念的详细解释:
线性模型
线性模型的基本形式可以表示为:
y = β 0 + β 1 x 1 + β 2 x 2 + ⋯ + β p x p + ϵ y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_p x_p + \epsilon y=β0+β1x1+β2x2+⋯+βpxp+ϵ
其中:
- y y y 是输出变量(目标变量)。
- x 1 , x 2 , … , x p x_1, x_2, \ldots, x_p x1,x2,…,xp 是输入变量(特征)。
- β 0 , β 1 , β 2 , … , β p \beta_0, \beta_1, \beta_2, \ldots, \beta_p β0,β1,β2,…,βp 是模型参数。
- ϵ \epsilon ϵ 是误差项,代表模型未能解释的部分。
线性模型假设输出变量 y y y 与输入变量 x 1 , x 2 , … , x p x_1, x_2, \ldots, x_p x1,x2,…,xp 之间存在线性关系。
广义线性模型(GLM)
广义线性模型是线性模型的扩展,它允许输出变量 y y y 的分布不仅限于正态分布,还可以是其他分布,如二项分布、泊松分布等。GLM 由三个部分组成:
- 随机部分:指定输出变量 y y y 的概率分布。
- 系统部分:通过线性预测器 η = β 0 + β 1 x 1 + β 2 x 2 + ⋯ + β p x p \eta = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_p x_p η=β0+β1x1+β2x2+⋯+βpxp 来建立输入变量与输出变量之间的关系。
- 连结函数:将系统部分(线性预测器)与随机部分(输出变量的期望)连接起来。
连结函数(Link Function)
连结函数 g ( ⋅ ) g(\cdot) g(⋅) 在广义线性模型中用于将线性预测器 η \eta η 与输出变量 y y y 的期望 μ \mu μ 联系起来。具体地,它满足:
g ( μ ) = η g(\mu) = \eta g(μ)=η
其中:
- μ = E ( y ) \mu = E(y) μ=E(y) 是输出变量 y y y 的期望。
- η = β 0 + β 1 x 1 + β 2 x 2 + ⋯ + β p x p \eta = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_p x_p η=β0+β1x1+β2x2+⋯+βpxp 是线性预测器。
常见的连结函数有:
- 恒等连结(Identity Link): g ( μ ) = μ g(\mu) = \mu g(μ)=μ,适用于正态分布。
- 对数连结(Log Link): g ( μ ) = log ( μ ) g(\mu) = \log(\mu) g(μ)=log(μ),适用于泊松分布、伽马分布等。
- Logit 连结(Logit Link,也叫作 Logistic 连结): g ( μ ) = log ( μ 1 − μ ) g(\mu) = \log\left(\frac{\mu}{1-\mu}\right) g(μ)=log(1−μμ),适用于二项分布(用于逻辑回归)。
- Probit 连结(Probit Link): g ( μ ) = Φ − 1 ( μ ) g(\mu) = \Phi^{-1}(\mu) g(μ)=Φ−1(μ),其中 Φ \Phi Φ 是标准正态分布的累积分布函数,适用于二项分布。
连结函数的选择取决于输出变量 y y y 的分布以及具体问题的需求。通过合适的连结函数,广义线性模型能够灵活地适应各种类型的数据和分布,从而得到更准确的预测和推断结果。
Logistic模型
1. Logistic模型的定义和起源
Logistic模型,又称为逻辑斯谛模型,最早由比利时数学家Pierre-François Verhulst于1838-1847年间引入,用于描述人口增长受到资源限制的情况。该模型是对Malthus人口模型的修正,后者假设人口以指数方式无限增长,而Logistic模型则考虑了环境容纳量(即资源限制)对人口增长的影响,使得人口增长呈现S型曲线。Logistic模型不仅在人口学中有重要应用,还被广泛推广到其他领域,如生物学、生态学、经济学、医学和机器学习等。
2. Logistic模型的数学公式和物理意义
数学公式
Logistic模型的数学公式可以表示为:
d N ( t ) d t = r N ( t ) ( 1 − N ( t ) K ) \frac{dN(t)}{dt} = rN(t)\left(1 - \frac{N(t)}{K}\right) dtdN(t)=rN(t)(1−KN(t))
其中:
- N ( t ) N(t) N(t) 表示t时刻的人口数量或种群大小。
- r r r 是内禀增长率,表示在无限资源条件下种群的瞬时增长率。
- K K K 是环境容纳量,即种群所能达到的最大稳定值。
该微分方程有解析解:
N ( t ) = K 1 + ( K N 0 − 1 ) e − r t N(t) = \frac{K}{1 + \left(\frac{K}{N_0} - 1\right)e^{-rt}} N(t)=1+(N0K−1)e−rtK
其中 N 0 = N ( 0 ) N_0 = N(0) N0=N(0) 是初始时刻的种群大小。
物理意义
Logistic模型描述了种群增长受到资源限制的情况。当种群数量较小时,资源相对丰富,种群增长率接近 r r r;随着种群数量的增加,资源变得稀缺,增长率逐渐降低;当种群数量接近 K K K时,增长率趋于0,种群数量趋于稳定。这种S型增长曲线符合许多实际生物种群的增长规律。
3. Logistic模型在各个领域的应用案例
- 生物学和生态学:用于描述生物种群的增长动态,如某种动物或植物在特定环境下的增长情况。
- 经济学:用于市场预测,如新产品推广初期的市场接受度增长,以及市场饱和后的稳定状态。
- 医学:在流行病学中用于预测疾病的传播速度和最终感染人数;在临床研究中用于Logistic回归分析,根据患者的医疗数据判断病情发展或治疗效果。
- 机器学习:Logistic回归模型是机器学习中常用的分类算法之一,用于处理二分类或多分类问题,如垃圾邮件识别、情感分析等。
4. Logistic模型的优点和局限性
优点
- 模型简单:Logistic模型形式简洁,易于理解和实现。
- 适用范围广:不仅适用于人口和种群增长问题,还可以推广到多个领域。
- 解释性强:模型参数具有明确的物理意义(如内禀增长率、环境容纳量)。
局限性
- 假设条件严格:模型假设资源限制是唯一的限制因素,且资源利用方式是线性的,这在实际应用中可能不完全成立。
- 对初始条件敏感:模型的预测结果对初始条件(如初始种群大小)较为敏感。
- 弱分类器:在机器学习领域,Logistic回归模型是一个弱分类器,对于复杂数据的分类效果可能不如其他算法(如决策树、随机森林等)。
5. Logistic模型的实例或数据
以医学领域为例,Logistic回归模型常被用于疾病诊断。假设有一份关于某种疾病的数据集,包含患者的医疗指标(如年龄、性别、血压、血糖等)和疾病诊断结果(患病/未患病,用1/0表示)。通过Logistic回归分析,可以建立一个预测模型,用于根据患者的医疗指标预测其患病概率。具体实现时,可以使用统计软件(如R、SPSS)或机器学习框架(如Python的scikit-learn库)来拟合Logistic回归模型,并评估其预测性能。
Logistic模型的局限性
-
模型假设的严格性:
- Logistic模型通常基于一系列假设,如数据必须来自随机样本、自变量间不存在多重共线性等。这些假设在实际应用中可能难以完全满足,从而影响模型的准确性和可靠性。
-
对数据和场景的适应能力:
- Logistic模型是一个弱分类器,其对数据和场景的适应能力有一定局限性。与一些更为复杂的模型(如决策树、随机森林等)相比,Logistic模型在复杂数据或非线性关系较强的场景下的表现可能不够出色。
-
分类精度可能不高:
- Logistic模型在某些情况下容易欠拟合,即模型对训练数据的拟合程度不足,导致分类精度可能无法达到很高的水平。这可能是由于模型本身的简单性,或者数据中的非线性关系未能被充分捕捉所致。
-
对多重共线性数据的敏感性:
- Logistic模型对多重共线性数据较为敏感。多重共线性是指自变量之间存在高度相关性,这可能导致模型参数估计不准确,进而影响模型的预测性能。
-
难以处理非线性问题:
- Logistic模型的决策边界是线性的,这意味着它难以直接用于解决非线性问题。对于非线性关系较强的数据集,可能需要采用其他非线性模型(如神经网络、支持向量机等)来获得更好的预测效果。
-
数据不平衡问题的挑战:
- Logistic模型在处理数据不平衡问题时可能面临挑战。当数据集中某一类别的样本数量远多于另一类别时,模型可能倾向于预测样本数量较多的类别,从而导致对少数类别的预测性能下降。
-
特征筛选的局限性:
- Logistic回归本身无法直接进行特征筛选,即模型不会自动识别哪些特征对预测结果更为重要。因此,在使用Logistic模型之前,可能需要通过其他方法(如基于树的方法、主成分分析等)进行特征选择或降维处理。
Logistic回归分析
1. 定义
Logistic回归分析,又称为逻辑回归分析,是一种广义的线性回归分析模型,主要用于处理因变量为分类变量(尤其是二分类变量)的回归分析。在二分类问题中,Logistic回归分析通过Sigmoid函数将线性回归的输出转换为介于0和1之间的概率值,从而进行类别的预测。
2. 计算
Logistic回归分析的核心在于构建以下线性表达式,并通过极大似然估计等方法求解参数:
log ( p 1 − p ) = β 0 + β 1 X 1 + β 2 X 2 + ⋯ + β n X n \log\left(\frac{p}{1-p}\right) = \beta_0 + \beta_1X_1 + \beta_2X_2 + \cdots + \beta_nX_n log(1−pp)=β0+β1X1+β2X2+⋯+βnXn
其中, p p p 是事件发生的概率(即因变量取值为1的概率), 1 − p 1-p 1−p 是事件不发生的概率; β 0 , β 1 , … , β n \beta_0, \beta_1, \ldots, \beta_n β0,β1,…,βn 是需要求解的模型参数; X 1 , X 2 , … , X n X_1, X_2, \ldots, X_n X1,X2,…,Xn 是自变量。
通过Sigmoid函数将线性表达式的结果转换为概率值:
p = 1 1 + e − ( β 0 + β 1 X 1 + β 2 X 2 + ⋯ + β n X n ) p = \frac{1}{1 + e^{-(\beta_0 + \beta_1X_1 + \beta_2X_2 + \cdots + \beta_nX_n)}} p=1+e−(β0+β1X1+β2X2+⋯+βnXn)1
在实际计算中,常采用梯度下降法、牛顿法或其他优化算法来求解参数 β 0 , β 1 , … , β n \beta_0, \beta_1, \ldots, \beta_n β0,β1,…,βn。
3. 性质
- 非线性转换:通过Sigmoid函数将线性回归的输出转换为概率值,使得模型能够处理分类问题。
- 解释性强:模型参数具有明确的解释意义,即自变量变化一个单位时,事件发生概率的对数几率变化。
- 适用范围广:不仅适用于二分类问题,还可以扩展为多分类问题(通过softmax函数)。
4. 例子
假设我们研究一个政治候选人是否赢得选举的因素。因变量是二元的(0/1),表示输或赢;自变量可能包括花在竞选上的钱、花在竞选上的时间、候选人是否是现任者等。通过收集相关数据,我们可以构建Logistic回归模型来分析这些因素对选举结果的影响。
5. 例题
例题:研究GRE(研究生入学考试成绩)和GPA(平均分)对研究生录取结果的影响。
数据:假设我们有一个数据集,包含学生的GRE成绩、GPA以及是否被研究生院录取的信息(录取为1,未录取为0)。
步骤:
-
数据预处理:将录取结果转换为二元变量(0/1),检查并处理缺失值。
-
模型构建:使用Logistic回归模型,将GRE成绩和GPA作为自变量,录取结果作为因变量。
-
参数求解:采用极大似然估计法求解模型参数。
-
结果解释:分析模型参数,解释GRE成绩和GPA对录取结果的影响。例如,如果GRE成绩的系数为正且显著,说明GRE成绩越高,被录取的概率越大。
-
模型评估:使用混淆矩阵、准确率、召回率等指标评估模型的性能。
通过以上步骤,我们可以得到一个用于预测研究生录取结果的Logistic回归模型,并根据模型参数分析GRE成绩和GPA对录取结果的影响程度。
Logistic回归分析,又称为逻辑回归,是一种广泛应用于统计分析和机器学习中的分类方法,特别适用于处理二分类问题。下面我将通过详细的例子和例题来解释Logistic回归分析。
例子:研究生录取预测
假设我们有一个数据集,包含申请研究生院的学生的GRE成绩(GRE)、平均分(GPA)以及他们本科院校的排名(Rank),我们的目标是预测一个学生是否能被研究生院录取。因变量是二元的,即录取(1)或不录取(0)。
数据集描述:
- 因变量:录取(1/0)
- 自变量:
- GRE:连续变量
- GPA:连续变量
- Rank:分类变量,取值1到4,其中1代表最高声望的院校,4代表最低声望的院校
分析步骤:
-
数据准备:收集并整理数据,确保数据的完整性和准确性。
-
模型建立:使用Logistic回归模型来拟合数据。在Logistic回归中,因变量Y(录取与否)的对数几率是自变量X的线性函数,即:
log ( P ( Y = 1 ∣ X ) P ( Y = 0 ∣ X ) ) = β 0 + β 1 ⋅ GRE + β 2 ⋅ GPA + β 3 ⋅ Rank \log\left(\frac{P(Y=1|X)}{P(Y=0|X)}\right) = \beta_0 + \beta_1 \cdot \text{GRE} + \beta_2 \cdot \text{GPA} + \beta_3 \cdot \text{Rank} log(P(Y=0∣X)P(Y=1∣X))=β0+β1⋅GRE+β2⋅GPA+β3⋅Rank
其中, P ( Y = 1 ∣ X ) P(Y=1|X) P(Y=1∣X)表示在给定自变量X的条件下,学生被录取的概率。
-
参数估计:通过最大似然估计法求解模型中的回归系数 β 0 , β 1 , β 2 , β 3 \beta_0, \beta_1, \beta_2, \beta_3 β0,β1,β2,β3。这些系数反映了自变量对因变量对数几率的影响程度。
-
模型评估:使用拟合优度检验(如Hosmer-Lemeshow检验)和系数显著性检验(如Wald检验)来评估模型的拟合效果和各个自变量的显著性。
-
预测与解释:使用拟合好的模型对新数据进行预测,并根据回归系数解释各自变量对录取概率的影响。例如,GRE每增加一个单位,录取的对数几率增加多少;GPA每增加一个单位,录取的对数几率增加多少;以及不同本科院校排名的学生被录取的概率差异。
例题:
题目:假设你已经拟合了一个Logistic回归模型来预测研究生录取情况,并得到了以下回归系数(仅作示例):
| 变量 | 回归系数 |
|---|---|
| 截距 | -1.5 |
| GRE | 0.002 |
| GPA | 0.804 |
| Rank=2 | -0.675 |
| Rank=3 | -1.010 |
| Rank=4 | -1.535 |
(注意:在实际分析中,Rank变量通常会通过设置哑变量来处理,这里为了简化说明直接列出了不同等级的系数)
问题:
-
GRE每增加一个单位,录取的对数几率如何变化?
- 答案:GRE每增加一个单位,录取的对数几率增加0.002。
-
GPA增加一个单位,被录取的概率大约增加多少?(这里需要近似计算,因为是对数几率的变化)
- 答案:由于是对数几率的变化,直接转化为概率变化较为复杂。但一般来说,GPA的增加会显著提高被录取的概率。具体增加多少取决于当前的GPA水平和模型的其他参数。
-
相比于本科院校排名为1的学生,排名为4的学生被录取的对数几率降低了多少?
- 答案:降低了1.535个单位。
参考文献
- 文心一言
相关文章:

计算物理精解【8】-计算原理精解【5】
文章目录 logistic模型多元回归分析多元回归分析概览1. 多元回归的概念与重要性2. 多元回归在实际应用中的例子3. 多元回归在预测和解释数据中的优势和局限性4. 多元回归的优缺点及改进建议 多元线性回归分析详解一、原理二、性质三、计算四、例子与例题五、应用场景六、优缺点…...

【Linux】 tcp | 解除服务器对tcp连接的限制 | 物联网项目配置
一、修改tcp连接限制 1、编辑 vi /etc/sysctl.conf 2、内容 net.ipv4.tcp_keepalive_intvl 75 net.ipv4.tcp_keepalive_probes 9 net.ipv4.tcp_keepalive_time 7200 net.ipv4.ip_local_port_range 1024 65535 net.ipv4.ip_conntrack_max 20000 net.ipv4.tcp_max_tw_bucket…...
如何隐藏Windows10「安全删除硬件」里的USB无线网卡
本方法参照了原文《如何隐藏Windows10「安全删除硬件」里的USB无线网卡》里面的方法,但是文章中的描述我的实际情况不太一样,于是我针对自己的实际情况进行了调整,经过测试可以成功隐藏Windows10「安全删除硬件」里的USB无线网卡。 先说一下…...

【QT Quick】基础语法:导入外部JS文件及调试
在 QML 中,可以使用 JavaScript 来实现业务逻辑的灵活性和简化开发。接下来我们会学习如何导入 JavaScript 文件,并在 QML 中使用它,同时也会介绍如何调试这些 JavaScript 代码。 导入 JavaScript 文件 在 QML 中导入 JavaScript 文件的方式…...
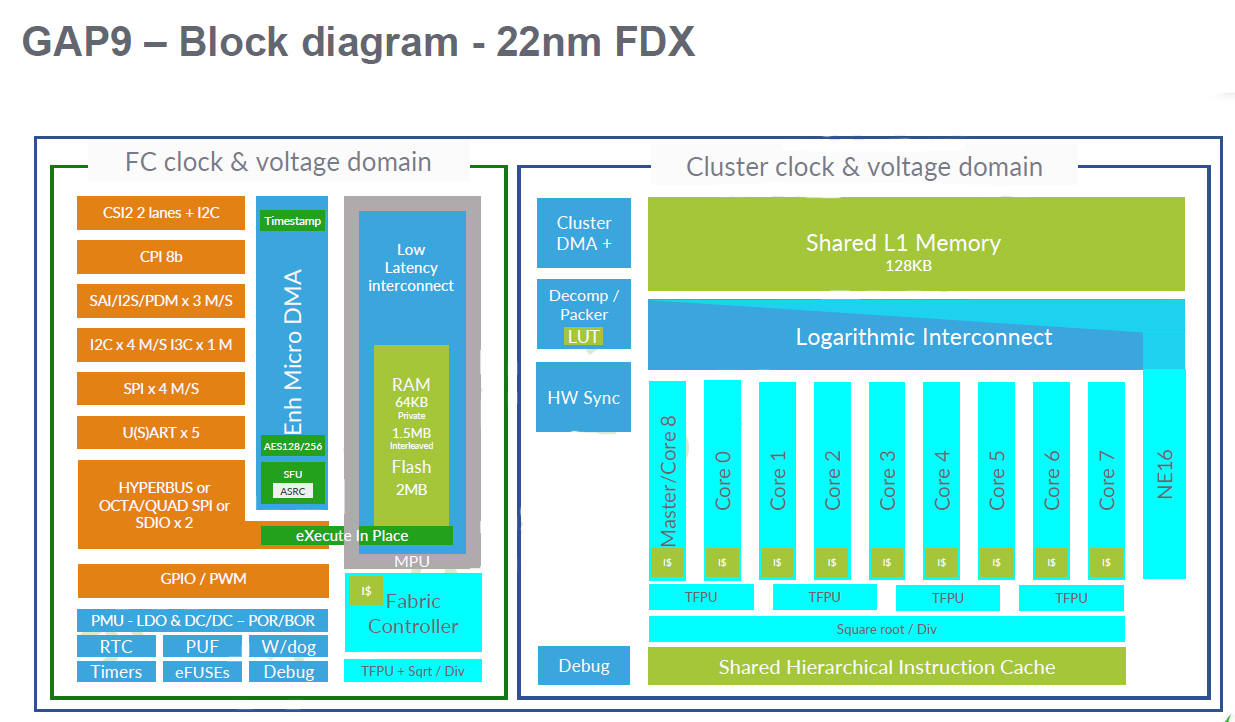
【质优价廉】GAP9 AI算力处理器赋能智能可听耳机,超低功耗畅享未来音频体验!
当今世界,智能可听设备已经成为了流行趋势。随后耳机市场的不断成长起来,消费者又对AI-ANC,AI-ENC(环境噪音消除)降噪的需求逐年增加,但是,用户对于产品体验的需求也从简单的需求,升…...

用Flutter几年了,Flutter每个版本有什么区别?
用Flutter几年了,你知道Flutter每个版本有什么区别吗?不管是学习还是面试我们可能都需要了解这个信息。 Flutter 每个版本的用法基本都是一样的,每隔几天或者几周就会更新一个版本, 2018 年 12 月 5 日发布了1.x 版本&#…...

解决Qt每次修改代码后首次运行崩溃,后几次不崩溃问题
在使用unique_ptr声明成员变量后,我习惯性地在初始化构造列表中进行如下构造: 注意看,我将m_menuBtnGroup的父类指定为ui->center_menu_widget,这便是导致崩溃的根本原因,解决办法便是先用this初始化,后…...

语言的变量交换
不用第三个变量交换两个变量在面试题或者笔试题中无数次被提到,事实上,有些答案是理论性的,不是准确的。以整型为例,如下对比不同交换方式的差异。 不同的交换方式 利用中间变量c a; 00C02533 8B 45 F8 mov eax,dword ptr [a] 0…...

【muduo源码分析】「阻塞」「非阻塞」「同步」「异步」
欢迎来到 破晓的历程的 博客 ⛺️不负时光,不负己✈️ 文章目录 引言何为「muduo库」安装muduo库阻塞、非阻塞、同步、异步数据准备数据准备 引言 从本篇博客开始,我会陆续发表muduo库源码分析的相关文章。感谢大家的持续关注!!…...

顶顶通呼叫中心中间件-机器人话术挂机后是否处理完成事件
前言 问题:机器人放音的过程中,如果用户直接挂机就会继续匹配下一个流程,如果匹配上的是放音节点,还会进行放音,那么在数据库表中就会多出一条放音记录。 解决方法 一、话术添加一个全局挂机节点 需要在话术中添加一…...

Springboot Mybatis 动态SQL
动态SQL <?xml version"1.0" encoding"UTF-8" ?> <!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""https://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace"com.wzb.SqlImprove2024…...

ORM的了解
什么是ORM?为什么要用ORM?-CSDN博客 C高级编程(99)面向资源的设计思想(ORM)_c orm-CSDN博客 ORM:Object-Relational-Mapping 对象关系映射 -------------------------- 我想对数据库中的表A进行增删改…...

关于大模型的10个思考
9月28日,第四届“青年科学家50论坛”在南方科技大学举行,美国国家工程院外籍院士沈向洋做了《通用人工智能时代,我们应该怎样思考大模型》的主题演讲,并给出了他对大模型的10个思考。 以下是他10个思考的具体内容: 1…...
---> lambda 表达式底层实现机制)
CFR( Java 反编译器)---> lambda 表达式底层实现机制
一、安装教程 CFR(Class File Reader)是一个流行的Java反编译器,它可以将编译后的.class文件或整个.jar文件转换回Java源代码。以下是CFR的下载和使用教程: 下载CFR 访问CFR的官方网站或GitHub仓库:CFR的最新版本和所…...

《C++多态性:开启实际项目高效编程之门》
在 C的广阔编程世界中,多态性是一个强大而富有魅力的特性。它为程序员提供了极大的灵活性和可扩展性,使得代码能够更加优雅地应对复杂的业务需求。在实际项目中,理解和正确应用 C的多态性至关重要,它可以显著提高代码的质量、可维…...

UDS_5_输入输出控制功能单元
目录 一. 0x2F服务 一. 0x2F服务 InputOutputControlByIdentifier(0x2F)服务 用于替换服务器输入信号的值或内部功能控制电子系统的某个输出(执行器) •请求报文 A_Data Byte Parameter Name Cvt Byte Value #1 InputOutputControlByIdentifier Request SID M 0x2F dataI…...

CAD快捷键
CAD快捷键 功能快捷键描述直线L点PO多段线PL多用于描边构造线XL无限长直线射线RAY样条曲线SPL绘制光滑曲线–––圆弧A圆C矩形REC正多边形POL–––填充H圆角F倒角CHA–––打断BR分解X合并J–––创建块B插入块I 功能快捷键描述移动M复制CO擦除E修剪TR延伸EX拉伸S镜像MI偏移…...

Spring6梳理12——依赖注入之注入Map集合类型属性
以上笔记来源: 尚硅谷Spring零基础入门到进阶,一套搞定spring6全套视频教程(源码级讲解)https://www.bilibili.com/video/BV1kR4y1b7Qc 12 依赖注入之注入Map集合类型属性 12.1 创建Student类和Teacher类 Student类中创建了run…...

基于SpringBoot校园失物招领系统设计与实现
文未可获取一份本项目的java源码和数据库参考。 本课题的作用、意义,在国内外的研究现状和发展趋势,尚待研究的问题 作用:本课题的目的是使失物招领信息管理清晰化,透明化,便于操作,易于管理。通过功能模…...
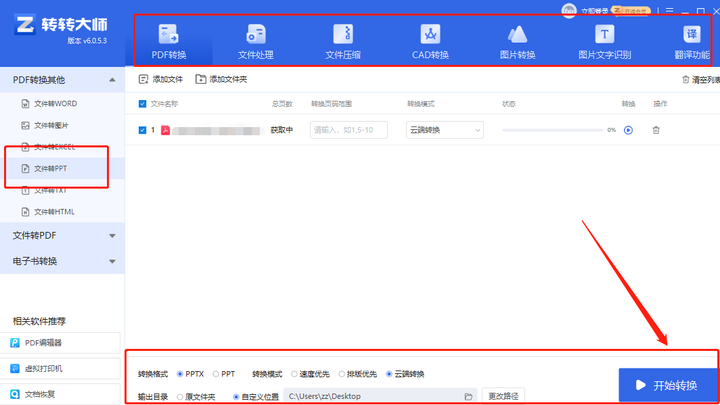
推荐4款2024年热门的PDF转ppt工具
有时候,我们为了方便,需要将PDF里面的内容直接转换的PPT的格式,既方便自己演示和讲解,也让我们可以更加灵活的进行文件的编辑和修改。如果大家不知道要如何进行操作的话,我可以为大家推荐几个比窘方便实用的PDF转换工具…...

AI写专著必备攻略:专业工具推荐,轻松开启学术专著创作之旅
学术专著写作困境与AI工具解决方案 学术专著的严谨性,离不开大量资料和数据的支持。资料的搜集和数据整合,往往是写作过程中最为繁琐和耗时的环节。研究者必须全面检索国内外的前沿文献,以确保这些文献的权威性和相关性,同时还要…...

intv_ai_mk11效果惊艳案例:为初创公司1小时生成完整BP商业计划书框架
intv_ai_mk11效果惊艳案例:为初创公司1小时生成完整BP商业计划书框架 1. 商业计划书生成效果展示 1.1 从零到完整的商业计划书 intv_ai_mk11在商业计划书生成方面展现出惊人的效率和质量。我们实测了一个真实案例:一家智能硬件初创公司需要准备融资用…...

微信小程序物流信息对接实战:发货接口的完整实现指南
1. 微信小程序物流对接的核心价值 对于电商类小程序来说,物流信息同步是用户体验的关键环节。当用户下单后,最关心的就是"我的包裹到哪了"。传统做法需要用户手动复制单号到第三方平台查询,而通过微信官方物流接口,可以…...
)
保姆级教程:用OpenAI Whisper给视频自动生成字幕(附Python代码)
视频创作者必备:用Whisper打造高效字幕工作流 每次剪辑视频最头疼的就是加字幕?作为过来人,我完全理解那种对着时间轴逐帧调整的痛苦。直到发现Whisper这个神器,我的工作效率直接翻了三倍。今天就把这套全自动字幕生成方案完整分享…...

Benchmark.js 配置选项终极指南:如何优化你的 JavaScript 性能测试环境
Benchmark.js 配置选项终极指南:如何优化你的 JavaScript 性能测试环境 【免费下载链接】benchmark.js A benchmarking library. As used on jsPerf.com. 项目地址: https://gitcode.com/gh_mirrors/be/benchmark.js Benchmark.js 是一款专业的 JavaScript 性…...

Godot-MCP:如何通过双向语义桥梁解决游戏开发中的创意断层问题
Godot-MCP:如何通过双向语义桥梁解决游戏开发中的创意断层问题 【免费下载链接】Godot-MCP An MCP for Godot that lets you create and edit games in the Godot game engine with tools like Claude 项目地址: https://gitcode.com/gh_mirrors/god/Godot-MCP …...

提升开发效率:Android Studio零障碍IDE本地化配置指南
提升开发效率:Android Studio零障碍IDE本地化配置指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 开发人员在使用…...

Qwen3-TTS快速部署教程:一键启动Web服务,3分钟开始声音克隆
Qwen3-TTS快速部署教程:一键启动Web服务,3分钟开始声音克隆 1. 为什么选择Qwen3-TTS进行语音克隆 想象一下这样的场景:你需要为海外客户录制多语言产品介绍,但雇佣专业配音演员成本高昂;或者想为自己的视频内容添加个…...

.NET源码生成器使用SyntaxTree生成代码及简化语法
一、SyntaxTree是什么SyntaxTree是语法树,是源代码的树形结构表示由Roslyn编译器生成在SourceGenerator中会自动生成整个源代码结构是1个SyntaxTreeSyntaxTree有一个根节点(SyntaxNode)每个SyntaxNode也包含一个SyntaxTree这样看整个源代码结构就是片“森林”public abstract p…...

Qwen3-8B快速体验报告:部署简单,中文理解能力确实强
Qwen3-8B快速体验报告:部署简单,中文理解能力确实强 1. 开箱即用的AI体验 最近在测试各种开源大模型时,我发现了Qwen3-8B这个宝藏模型。作为Qwen系列的最新成员,这个80亿参数的模型在中文理解和推理能力上表现突出,最…...