从零开始之AI面试小程序
从零开始之AI面试小程序
文章目录
- 从零开始之AI面试小程序
- 前言
- 一、工具列表
- 二、开发部署流程
- 1. VMWare安装
- 2. Centos安装
- 3. Centos环境配置
- 3.1. 更改子网IP
- 3.2. 配置静态IP地址
- 4. Docker和Docker Compose安装
- 5. Docker镜像加速源配置
- 6. 部署中间件
- 6.1. MySQL部署
- 6.2. Redis部署
- 7. 初始化数据库
- 8. 运行AI面试后端程序
- 8.1. 拉取源码
- 8.2. 配置JDK
- 8.3. 配置Maven
- 8.4. 配置字符编码
- 8.5. 配置服务器
- 8.5.1. 配置MySQL和Redis
- 8.5.2. 微信授权登录密钥
- 8.6. 运行后端程序
- 8.6.1. 编译项目
- 8.6.2. 运行项目
- 9. 运行AI面试前端程序
- 9.1. 安装NVM
- 9.2. 安装依赖
- 9.3. 运行前端
- 10. 运行AI面试小程序端程序
- 10.1. 安装依赖
- 10.2. 微信小程序配置
- 10.3. OSS配置
- 10.4. 运行小程序
- 11. Coze机器人配置
- 11.1. 自我介绍AI生成工作流配置
- 11.2. 面试结果AI评分工作流配置
- 11.3. 配置AI机器人
- 11.4. 获得个人访问令牌
- 11.5. 服务器端配置
- 11.5.1. API密钥配置
- 11.5.2. 聊天模型配置
- 12. Paraformer语音识别配置
- 12.1. 获得阿里灵积服务API Key
- 12.2. 服务器端配置
- 13. 阿里OSS配置
- 13.1. 获得STS密钥OSS
- 13.1.1. 获得访问密钥
- 13.1.2. 获得ARN
- 13.1.3. 为RAM角色授予文件权限
- 13.2. 获得公有密钥OSS
- 13.2.1. 获得访问密钥
- 13.3. 服务器端配置
- 三、操作流程
- 1. 管理端
- 1.1. 创建素材(非必选)
- 1.2. 创建题册
- 1.3. 创建题目
- 2. 小程序端
- 2.1. 自我介绍生成
- 2.2. AI面试
- 四、docker部署流程
- 1. 后端打包
- 1.1. 修改配置
- 1.2. 编译后端
- 1.3. 上传 Jar 包
- 1.4. 构建镜像
- 1.5. 编写docker服务启动脚本
- 1.6. 启动后端
- 2. 前端打包
- 2.1. 修改配置
- 2.2. 编译前端
- 2.3. 安装 Nginx
- 2.4. 配置 Nginx
- 2.5. 上传 dist 文件
- 2.6. 检验连通性
- 五、技术框架图
- 六、数据结构图
- 七、参考
前言
在如今人人皆可卷,万物皆可卷的社会中生活实属不易。本文将带领各位从零开始搭建并熟悉开发AI面试小程序,适合小白食用。程序还有些地方仍在完善,望海涵。
一、工具列表
- VMware workstation Pro 17
- Navicat premium 15
- Visual Studio Code
- Intellij IDEA
- JDK 17
- HBuilder X
- 微信开发者工具
- Postman
- FinalShell
二、开发部署流程
1. VMWare安装
VMWare安装流程传送门,VMWare Workstation Pro 于 2024年5月针对个人版本官网已免费,可自行下载即可。
2. Centos安装
Centos安装流程传送门,安装Cenos的目的是为了后面在此Linux系统上面装docker,在docker上面部署MySQL和Redis。除此之外后续的中间件啥的也都可安装在docker上,方便管理。如想直接在 物理机 上安装MySQL和Redis的可直接跳过。
3. Centos环境配置
本文将Centos系统配置为静态IP:192.168.30.131,对应的子网为192.168.30.0。防止每次服务器重启,对应的IP都会变化。
3.1. 更改子网IP
在“编辑(E) "上左键单击,然后在"虚拟网络编辑器(N)… "上左键单击。

进入虚拟网络编辑器页面后点击【更改设置】。

更改子网IP为192.168.30.0,选择为NAT模式。更改完成后,点击【NAT设置】按钮,进入NAT设置。

进入【NAT 设置】页面后,更改【网关IP】为192.168.30.2即可。

3.2. 配置静态IP地址
修改网卡配置,命令如下,其中的 ifcfg-ens33 为配置对应的网卡。
vi /etc/sysconfig/network-scripts/ifcfg-ens33

TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
IPADDR=192.168.30.131
NETMASK=255.255.255.0
GATEWAY=192.168.30.2
DNS1=114.114.114.114
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="abf7c9a3-58a8-4c34-850d-a565b5803f97"
DEVICE="ens33"
ONBOOT="yes"
其中需要注意如下几项:【IPADDR】、【NETMASK】、【GATEWAY】、【DNS1】。【IPADDR】为服务器的静态IP地址,【NETMASK】为服务器的网络掩码,【GATEWAY】为上个步骤配置的【网关 IP】,【DNS1】本文选的是114.114.114.114,也可根据环境自己更换。

4. Docker和Docker Compose安装
其中的Docker Compose需要根据对应的Docker版本安装,如果Docker为最新的版本,Docker Compose应为最新版本。Docker Compose若为github上下载下来,可直接上传到服务器的 /usr/local/bin/ 路径下,全路径为: /usr/local/bin/docker-compose
Docker和Docker Compose安装流程传送门
Docker Compose github传送门
5. Docker镜像加速源配置
可以解决docker和docker compose安装容器慢的问题。
创建或修改/etc/docker/daemon.json为如下
{"registry-mirrors": ["http://hub-mirror.c.163.com"]
}
Docker镜像加速源配置传送门
这个镜像源可以换成其他的,如果用了镜像加速源也不行。可参考 从零开始之Dify二次开发篇 中的 【将dify组件镜像转移到阿里云(可选)】部分 或 【Docker镜像库失效应对策略】教你两种方式快速下载镜像 。
6. 部署中间件
本文用到的中间件有MySQL和Redis,MySQL的版本为【8.0.27-1debian10】,Redis的版本为【6.2.6】。
6.1. MySQL部署
Docker安装MySQL传送门
6.2. Redis部署
通过docker拉取Redis的最新镜像,命令如下。
docker pull redis:latest
然后在服务器上启动Redis即可。
docker run --restart=always -p 6379:6379 --name redis -d redis:latest
7. 初始化数据库
从Gitee项目中拉取后端源码,AI面试后端源码传送门。进入对应SQL所在的目录【neuinterviewbackend\sql\mysql】,用 Navicat 分别执行【ruoyi-vue-pro.sql】和【interview202409191613.sql】,【ruoyi-vue-pro.sql】是ruoyi-vue-pro的基础表结构的SQL,【interview202409191613.sql】是AI面试的表结构的SQL。
8. 运行AI面试后端程序
8.1. 拉取源码
从Gitee项目中拉取后端源码,AI面试后端源码传送门。用 IDEA 打开项目。
8.2. 配置JDK
本AI面试后端需要的JDK为JDK17,通过【Project Structure】配置即可。

8.3. 配置Maven
Maven配置传送门,Maven的仓库配置可参考如下配置。
<mirrors>
<!-- 阿里镜像 --><mirror><id>alimaven</id><mirrorOf>central</mirrorOf><name>aliyun maven</name><url>http://maven.aliyun.com/nexus/content/repositories/central/</url></mirror><mirror><id>alimaven</id><name>aliyun maven</name><url>http://maven.aliyun.com/nexus/content/groups/public/</url><mirrorOf>central</mirrorOf></mirror><mirror><id>central</id><name>Maven Repository Switchboard</name><url>http://repo1.maven.org/maven2/</url><mirrorOf>central</mirrorOf></mirror><mirror><id>repo2</id><mirrorOf>central</mirrorOf><name>Human Readable Name for this Mirror.</name><url>http://repo2.maven.org/maven2/</url></mirror><mirror><id>ibiblio</id><mirrorOf>central</mirrorOf><name>Human Readable Name for this Mirror.</name><url>http://mirrors.ibiblio.org/pub/mirrors/maven2/</url></mirror><mirror><id>jboss-public-repository-group</id><mirrorOf>central</mirrorOf><name>JBoss Public Repository Group</name><url>http://repository.jboss.org/nexus/content/groups/public</url></mirror><mirror><id>google-maven-central</id><name>Google Maven Central</name><url>https://maven-central.storage.googleapis.com</url><mirrorOf>central</mirrorOf></mirror><!-- 中央仓库在中国的镜像 --><mirror><id>maven.net.cn</id><name>oneof the central mirrors in china</name><url>http://maven.net.cn/content/groups/public/</url><mirrorOf>central</mirrorOf></mirror></mirrors>
8.4. 配置字符编码
通过【Settings】进行配置字符编码。

8.5. 配置服务器
8.5.1. 配置MySQL和Redis
进入【yudao-server】模块下的【yudao-server/src/main/resources/application-local.yaml】。将对应的MySQL的地址和Redis地址更改为对应的服务器的地址即可,本文即192.168.30.131。

8.5.2. 微信授权登录密钥
本文小程序的登录方式可选择微信授权登录,因此需要参考 微信小程序测试号申请 链接,申请一个测试小程序,将 AppID 和 AppSecret 配置,设置到后端项目 application-local.yaml 的 wx.miniapp 配置项中。


8.6. 运行后端程序
8.6.1. 编译项目
使用 IDEA 打开 Terminal 终端,在 根目录 下直接执行 mvn clean install package '-Dmaven.test.skip=true' 命令。如果执行报 Unknown lifecycle phase “.test.skip=true” 错误,使用 mvn clean install package -Dmaven.test.skip=true 即可。
控制台日志输出如下信息即表示成功。
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 9.139 s (Wall Clock)
[INFO] Finished at: 2024-09-20T18:56:03+08:00
[INFO] ------------------------------------------------------------------------
8.6.2. 运行项目
本文的后端程序运行在【48080】端口,此端口也是在【yudao-server/src/main/resources/application-local.yaml】中配置。运行后见到如下提示则表示运行成功。

9. 运行AI面试前端程序
从Gitee项目中拉取前端源码,AI面试前端源码传送门。用 VSCode 打开项目。本文采用的是yudao的 Vue3 + element-plus 版本。
9.1. 安装NVM
NVM是个Node多版本管理器,可以切换不同Node版本的环境,类似虚拟机的作用,
NVM安装传送门。
9.2. 安装依赖
打开 VSCode 控制台,输入如下命令安装
# 安装 pnpm,提升依赖的安装速度
npm config set registry https://registry.npmmirror.com
npm install -g pnpm
# 安装依赖
pnpm install
如果遇到如下问题:
pnpm : 无法加载文件 D:\Program Files\nvm_nodejs\pnpm.ps1,因为在此系统上禁止运行脚本。
可参考 pnpm : 无法加载文件 问题详细描述解决方案传送门
如果遇到nvm使用use命令失效的问题,可参考 NVM的use命令失效解决方案传送门
如果npm安装各种依赖包的时候,下载速度慢,可通过更换npm源的方式解决。npm源切换详解
如果出现npm install 一直sill idealTree buildDeps问题。可参考解决方案 npm install一直sill idealTree buildDeps
npm cache clear --forcenpm config set registry http://registry.npmjs.org/
9.3. 运行前端
# 启动服务
npm run dev
运行后见到如下提示则表示运行成功。

10. 运行AI面试小程序端程序
从Gitee项目中拉取小程序端源码,AI面试小程序端源码传送门。用 Hbuilder X 打开项目。
10.1. 安装依赖
打开Hbuilder X控制台,输入如下命令进行安装。如果安装过程中出现一些问题可参考步骤【9.2. 安装依赖】
# 安装依赖
npm install
10.2. 微信小程序配置
将程序中的微信小程序AppID配置为自己申请的即可。

微信小程序连接后端的相关配置在【.env】配置文件中,对应的变量名称为【CHATPRO_DEV_BASE_URL】。

10.3. OSS配置
本文中的OSS用于微信端上传面试者的视频和音频文件。OSS的配置在【neuinterview\js_sdk\x-oss-direct\】路径下的 oss.js 文件中,如图所示,更改 this.url 指向的内容即可。OSS配置详情见【13. 阿里OSS配置】。

10.4. 运行小程序
在菜单处点击【运行】-【运行到小程序模拟器】-【微信开发者工具】

运行后见到如下提示则表示运行成功。

并会自动打开对应的微信小程序开发者工具,见如下界面。

11. Coze机器人配置
本文采用的是AI是字节跳动的Coze。采用了2个AI机器人进行运行。
- 自我介绍AI生成
- 面试结果AI评分
11.1. 自我介绍AI生成工作流配置
自我介绍AI生成的工作流如下图所示。输入部分为JSON格式的字符串,大模型根据相关信息处理后生成自我介绍后输出。

第二个节点用于处理输入的JSON格式的字符串,其代码内容如下。
import json
async def main(args: Args) -> Output:params = args.paramsdata = json.loads(params['input'])ret: Output = {"name": data['name'],"good_character": data['good_character'],"awards": data['awards'],"university": data['university'],"university_motto": data['university_motto'],"major": data['major'],"subject": data['subject'],"goal": data['goal'],"position": data['position'],}return ret
11.2. 面试结果AI评分工作流配置
面试结果AI评分的工作流如下图所示。输入部分为JSON格式的字符串,大模型根据相关信息处理后生成面试结果后输出。

第二个节点用于处理输入的JSON格式的字符串,其代码内容如下。
import json
async def main(args: Args) -> Output:params = args.paramsdata = json.loads(params['input'])ret: Output = {"material": data['material'],"question": data['question'],"answer": data['answer'],}return ret
第五个节点用于处理输出的【评级】满足固定的格式,即在A-Z或a-z的范围内,其代码内容如下。
import re;
async def main(args: Args) -> Output:params = args.paramsmatch = re.search(r'[A-Za-z]',params['input'])ret: Output = {"rank": match.group(0) if match else None}return ret
11.3. 配置AI机器人
创建AI机器人,配置上一步骤配置的【自我介绍生成工作流】,并记录对应的浏览器导航栏中的botID,此botID用于后续API调用中的参数配置。同理获得面试结果AI机器人的botID。

11.4. 获得个人访问令牌
本文采用的是通过个人访问令牌的方式进行Coze鉴权。获得个人访问令牌流程传送门。此个人访问令牌用于后续API调用中的参数配置。
11.5. 服务器端配置
11.5.1. API密钥配置
进入【AI 大模型】-【控制台】-【API 密钥】,编辑【所属平台】为【扣子】的条目,填写从步骤【11.4. 获得个人访问令牌】中获得的Coze个人访问令牌。

注: 【所属平台】需要选择的是【扣子】,【密钥】填写从步骤【11.4. 获得个人访问令牌】中获得的Coze个人访问令牌即可。

11.5.2. 聊天模型配置
进入【AI 大模型】-【控制台】-【聊天模型】,分别编辑所属平台为【扣子】且模型名称为【Coze自我介绍生成工作流】、【Coze结构面试评分工作流】的两个聊天模型。

分别配置【Coze自我介绍生成工作流】、【Coze结构面试评分工作流】中的【botID】,【botID】从步骤【11.3. 配置AI机器人】中获得。


12. Paraformer语音识别配置
语音识别的作用在于将面试者的语音转换成文字,方便后续交予大模型分析处理。本文使用的语音识别模型为阿里的Paraformer语音识别模型。
12.1. 获得阿里灵积服务API Key
阿里灵积服务API-KEY传送门

12.2. 服务器端配置
进入【控制台】-【API 密钥】后,编辑【所属平台】为【通义千问】的条目,填写步骤【12.1. 获得阿里灵积服务API Key】中获得的API Key即可。

13. 阿里OSS配置
OSS即对象存储服务,本文的OSS用于存放面试者的视频记录和音频记录,从而方便面试者回看面试的过程。本文根据OSS的访问权限分为了两种OSS。
- 通过STS临时凭证访问的私有OSS
- 公有OSS
私有的OSS用于存放面试者的视频记录和音频记录,这种私有属性的文件。公有的OSS用于存放用户的头像图片等具有公有属性的文件。
13.1. 获得STS密钥OSS
阿里OSS获得STS密钥传送门

13.1.1. 获得访问密钥
完成步骤一后,复制并保存访问密钥(AccessKey ID和AccessKey Secret),方便后续服务器端配置使用。

13.1.2. 获得ARN
完成步骤三后,复制并保存角色的ARN,方便后续服务器端配置使用。

13.1.3. 为RAM角色授予文件权限
在步骤四中的脚本编辑中授予RAM角色 文件上传 和 访问下载 的权限。可参考如下脚本。脚本中的【uniappchatinfo】为自己建立的bucket的名称。

{"Version": "1","Statement": [{"Effect": "Allow","Action": "oss:PutObject","Resource": "acs:oss:*:*:uniappchatinfo/*"},{"Effect": "Allow","Action": "oss:ListObjects","Resource": "acs:oss:*:*:uniappchatinfo/*"},{"Effect": "Allow","Action": "oss:GetObject","Resource": "acs:oss:*:*:uniappchatinfo/*"}]
}
13.2. 获得公有密钥OSS
阿里获得公有密钥传送门

13.2.1. 获得访问密钥
完成步骤一后,复制并保存访问密钥(AccessKey ID和AccessKey Secret),方便后续服务器端配置使用。

13.3. 服务器端配置
进入【基础设施】-【文件管理】-【文件配置】后,分别编辑如下两个条目。

编辑【配置名】为【阿里STS】且【存储器】为【ALISTS 对象存储】的条目。【存储 bucket】、【accessKey】、【accessSecret】、【roleArn】填写的内容可从【13.1. 获得STS密钥OSS】步骤中获得,【节点地址】、【STS节点地址】填写的内容可参考 公共云下OSS Region和Endpoint对照表 获得。

编辑【配置名】为【阿里云OSS】且【存储器】为【S3 对象存储】的条目。【存储 bucket】、【accessKey】、【accessSecret】填写的内容可从【13.2. 获得公有密钥OSS】步骤中获得,【节点地址】填写的内容可参考 公共云下OSS Region和Endpoint对照表 获得。

三、操作流程
1. 管理端
1.1. 创建素材(非必选)
素材作为面试过程中提供给面试者的阅读材料即面试题目的背景信息。现支持以文本展示的素材。进入【面试系统】-【素材管理】后,新增即可。

1.2. 创建题册
题册作为面试过程中提供给面试者的面试题目的集合。进入【面试系统】-【题册管理】后,新增即可。

1.3. 创建题目
题目作为面试者面试过程中需要回答的具体面试题目的内容。进入【面试系统】-【题册管理】后。选择对应的题册,点击对应条目的【数据】即可进入对应题册的题目集合。

进入面试题目管理界面后,点击【新增】即可进行新增面试题目。

【排序】为面试时题目出现的顺序,【问题】为面试题目对应的问题,【答案】为面试题目对应的参考答案,【素材关联】为面试题目提供给面试者的背景信息,关联的素材为步骤【1. 创建素材】中创建。

2. 小程序端
2.1. 自我介绍生成
进入【首页】后,点击【自我介绍】按钮即可进入自我介绍生成界面。

如果未登录,会弹出登录的界面,如下图所示。可选择的登录方式为 短信登录 和 微信登录,短信登录 暂走的测试通道,点击发送验证码后,填写 9999 即可。微信登录 相关配置已在【部署流程:8.5.2. 微信授权登录密钥】完成。

选择微信授权后,进行头像和昵称的同步即可。

进入【自我介绍】界面后,填写相关信息,然后点击【生成自我介绍】按钮,则会将基础信息提交给大模型,从而生成自我介绍。

生成完自我介绍后,再次从【首页】点击进入【自我介绍】界面时就会显示Coze大模型生成的内容。这个生成的内容可以进行编辑并保存,或可以进行重新生成。

2.2. AI面试
进入【首页】后,点击【开始面试】即可进入【面试题册】的列表界面,选择需要进行的【面试题册】即可开始对应的面试。

进入面试界面点击【开始回答】即可进入视频录制和音频录制。

开始回答后点击【结束回答】则会将录制的视频和音频文件上传到阿里OSS云上。

所有问题回答结束后可进入【我的】界面,从【面试记录】处进入并查看所有的历史面试记录。

根据面试题册的进度,未完成的面试题册,可继续进行面试,已完成的面试题册可查看详情。

进入已完成的面试题册,即可看到面试结果的详细情况。

在结果页面点击对应面试题目的【查看详情】,即可进入此面试题目的结果详情展示,包含音视频的回放,问答情况和AI评分情况。

四、docker部署流程
1. 后端打包
1.1. 修改配置
后端 dev 开发环境对应的 application-dev.yaml 配置文件,主要是修改 MySQL 和 Redis 的地址,关闭演示模式、微信授权信息配置,见下图所示。



1.2. 编译后端
在项目的根目录下,执行 mvn clean package '-Dmaven.test.skip=true' 命令,编译后端项目,构建出它的 Jar 包,如下图所示。

1.3. 上传 Jar 包
在 Linux 服务器上创建 /work/projects/yudao-server 目录,使用 scp 命令或者 FTP 工具,将 yudao-server.jar 上传到该目录下,如下图所示。

1.4. 构建镜像
将 yudao-server 目录下的 Dockerfile 文件上传到 /work/projects/yudao-server 目录下,用于制作后端项目的 Docker 镜像。Dockerfile 内容如下。

## AdoptOpenJDK 停止发布 OpenJDK 二进制,而 Eclipse Temurin 是它的延伸,提供更好的稳定性
## 感谢复旦核博士的建议!灰子哥,牛皮!
FROM eclipse-temurin:21-jre## 创建目录,并使用它作为工作目录
RUN mkdir -p /yudao-server
WORKDIR /yudao-server
## 将后端项目的 Jar 文件,复制到镜像中
COPY yudao-server.jar app.jar## 设置 TZ 时区
ENV TZ=Asia/Shanghai
## 设置 JAVA_OPTS 环境变量,可通过 docker run -e "JAVA_OPTS=" 进行覆盖
ENV JAVA_OPTS="-Xms512m -Xmx512m -Djava.security.egd=file:/dev/./urandom"## 应用参数
ENV ARGS=""## 暴露后端项目的 48080 端口
EXPOSE 48080## 启动后端项目
CMD java ${JAVA_OPTS} -jar app.jar $ARGS
执行如下命令,构建名字为 yudao-server 的 Docker 镜像。
cd /work/projects/yudao-server
docker build -t yudao-server .
如果出现 eclipse-temurin:21-jre 下载不下来的异常情况,可参考 从零开始之Dify二次开发篇 中的 【将dify组件镜像转移到阿里云(可选)】部分 或 【Docker镜像库失效应对策略】教你两种方式快速下载镜像 。
1.5. 编写docker服务启动脚本
在 /work/projects/yudao-server 目录下,新建 shell 脚本 deploy.sh 使用 Docker 启动后端项目。编写内容如下。
#!/bin/bash
set -e## 第一步:删除可能启动的老 yudao-server 容器
echo "开始删除 yudao-server 容器"
docker stop yudao-server || true
docker rm yudao-server || true
echo "完成删除 yudao-server 容器"## 第二步:启动新的 yudao-server 容器 \
echo "开始启动 yudao-server 容器"
docker run -d \
--name yudao-server \
-p 48080:48080 \
-e "SPRING_PROFILES_ACTIVE=dev" \
-v /work/projects/yudao-server:/root/logs/ \
yudao-server
echo "正在启动 yudao-server 容器中,需要等待 60 秒左右"
应用日志文件,挂载到服务器的 /work/projects/yudao-server 目录下,通过SPRING_PROFILES_ACTIVE 设置为 dev 开发环境。
1.6. 启动后端
执行 sh deploy.sh 命令,使用 Docker 启动后端项目。通过执行 docker logs yudao-server --tail=100 -f 命令查看服务的启动情况。当出现如下内容时则表示启动成功。

2. 前端打包
2.1. 修改配置
前端 dev 开发环境对应的是 .env.dev 配置文件,主要是修改 VUE_APP_BASE_API 为后端项目的访问地址。

2.2. 编译前端
在项目根目录下,执行 npm run build:dev 命令,编译前端项目,构建出它的 dist 文件。

如果想要打包其他的环境,可使用如下命令。
npm run build:prod ## 打包 prod 生产环境
npm run build:stage ## 打包 stage 预发布环境
其它高级参数说明【可暂时不看】:
① PUBLIC_PATH:静态资源地址,可用于七牛等 CDN 服务回源读取前端的静态文件,提升访问速度,建议 prod 生产环境使用。
② VUE_APP_APP_NAME:二级部署路径,默认为 / 根目录,一般不用修改。
③ mode:前端路由的模式,默认采用 history 路由,一般不用修改。可以通过修改 router/index.js 来设置为 hash 路由,示例如下:
2.3. 安装 Nginx
Nginx 挂载到服务器的目录:
/work/nginx/conf.d用于存放配置文件/work/nginx/html用于存放网页文件/work/nginx/logs用于存放日志/work/nginx/cert用于存放 HTTPS 证书
创建 /work/nginx 目录,并在该目录下新建 nginx.conf 文件,避免稍后安装 Nginx 报错,内容如下。
user nginx;
worker_processes 1;events {worker_connections 1024;
}error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;http {include /etc/nginx/mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;log_format main '$remote_addr - $remote_user [$time_local] "$request" ''$status $body_bytes_sent "$http_referer" ''"$http_user_agent" "$http_x_forwarded_for"';
# access_log /var/log/nginx/access.log main;gzip on;gzip_min_length 1k; # 设置允许压缩的页面最小字节数gzip_buffers 4 16k; # 用来存储 gzip 的压缩结果gzip_http_version 1.1; # 识别 HTTP 协议版本gzip_comp_level 2; # 设置 gzip 的压缩比 1-9。1 压缩比最小但最快,而 9 相反gzip_types text/plain application/x-javascript text/css application/xml application/javascript; # 指定压缩类型gzip_proxied any; # 无论后端服务器的 headers 头返回什么信息,都无条件启用压缩include /etc/nginx/conf.d/*.conf; ## 加载该目录下的其它 Nginx 配置文件
}
拉取 Nginx 镜像,执行如下命令即可。
docker pull nginx:latest
下载不下来,可参考 从零开始之Dify二次开发篇 中的 【将dify组件镜像转移到阿里云(可选)】部分 或 【Docker镜像库失效应对策略】教你两种方式快速下载镜像 。
镜像拉取下来后执行如下命令即可启动 Nginx。
docker run -d \
--name nginx --restart always \
-p 80:80 -p 443:443 \
-e "TZ=Asia/Shanghai" \
-v /work/nginx/nginx.conf:/etc/nginx/nginx.conf \
-v /work/nginx/conf.d:/etc/nginx/conf.d \
-v /work/nginx/logs:/var/log/nginx \
-v /work/nginx/cert:/etc/nginx/cert \
-v /work/nginx/html:/usr/share/nginx/html \
nginx:latest
执行 docker ps 命令,查看到 Nginx 容器状态为 up 即可。
2.4. 配置 Nginx
在 /work/nginx/conf.d 目录下,创建 ruoyi-vue-pro.conf ,内容如下。
server {listen 80;server_name 192.168.30.131; ## 重要!!!修改成你的外网 IP/域名location / { ## 前端项目root /usr/share/nginx/html/yudao-admin-ui;index index.html index.htm;try_files $uri $uri/ /index.html;}location /admin-api/ { ## 后端项目 - 管理后台proxy_pass http://192.168.30.131:48080/admin-api/; ## 重要!!!proxy_pass 需要设置为后端项目所在服务器的 IPproxy_set_header Host $http_host;proxy_set_header X-Real-IP $remote_addr;proxy_set_header REMOTE-HOST $remote_addr;proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;}location /app-api/ { ## 后端项目 - 用户 Appproxy_pass http://192.168.30.131:48080/app-api/; ## 重要!!!proxy_pass 需要设置为后端项目所在服务器的 IPproxy_set_header Host $http_host;proxy_set_header X-Real-IP $remote_addr;proxy_set_header REMOTE-HOST $remote_addr;proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;}location /infra/ws/ { ## websocket接口proxy_pass http://192.168.30.131:48080/infra/ws/;proxy_http_version 1.1;proxy_set_header Upgrade $http_upgrade;proxy_set_header Connection "Upgrade";}
}
执行 docker exec nginx nginx -s reload 命令,重新记载 Nginx 配置。
注:如果担心 Nginx 配置不正确,可以先执行 docker exec nginx nginx -t 命令。
2.5. 上传 dist 文件
使用 scp 命令或者 FTP 工具,将 dist 上传到 /work/nginx/html 目录下。并将其更改为 yudao-admin-ui

2.6. 检验连通性
执行 curl http://192.168.30.131:48080/admin-api/ 命令,成功访问后端项目的内网地址,返回结果如下所示即可。
{"code":401,"data":null,"msg":"账号未登录"}
五、技术框架图

六、数据结构图

七、参考
- 芋道源码(ruoyi-vue-pro)
- 芋道源码商城(yudao-mall-uniapp)
- chatgpt微信小程序智能AI聊天免费开源-后台管理页面
相关文章:
从零开始之AI面试小程序
从零开始之AI面试小程序 文章目录 从零开始之AI面试小程序前言一、工具列表二、开发部署流程1. VMWare安装2. Centos安装3. Centos环境配置3.1. 更改子网IP3.2. 配置静态IP地址 4. Docker和Docker Compose安装5. Docker镜像加速源配置6. 部署中间件6.1. MySQL部署6.2. Redis部署…...
Html2OpenXml:HTML转化为OpenXml的.Net库,轻松实现Html转为Word。
推荐一个开源库,轻松实现HTML转化为OpenXml。 01 项目简介 Html2OpenXml 是一个开源.Net库,旨在将简单或复杂的HTML内容转换为OpenXml组件。 该项目始于2009年,最初是为了将用户评论转换为Word文档而设计的 随着时间的推移,Ht…...

HumanNeRF:Free-viewpoint Rendering of Moving People from Monocular Video 精读
1. 姿态估计和骨架变换模块 人体姿态估计:HumanNeRF 通过已知的单目视频对视频中人物的姿态进行估计。常见的方法是通过人体姿态估计器(如 OpenPose 或 SMPL 模型)提取人物的骨架信息,获取 3D 关节的位置信息。这些关节信息可以帮…...
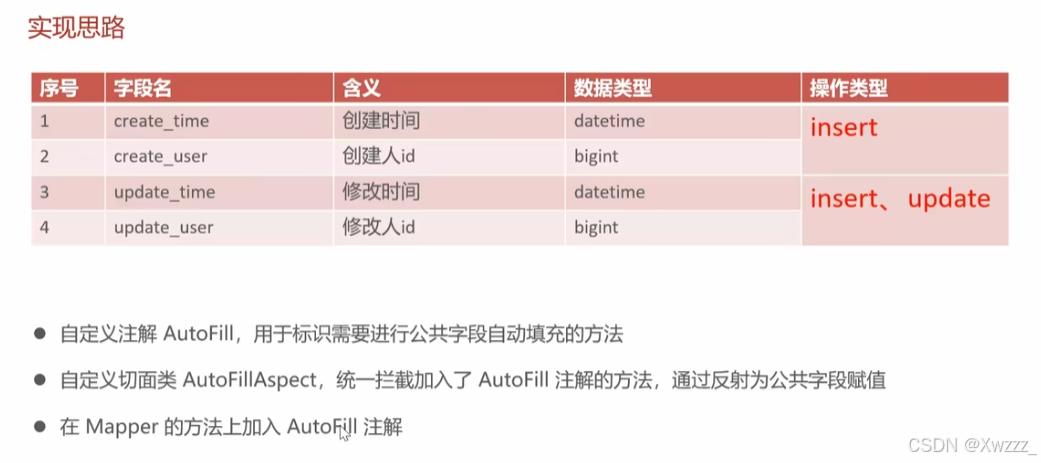
Springboot中基于注解实现公共字段自动填充
1.使用场景 当我们有大量的表需要管理公共字段,并且希望提高开发效率和确保数据一致性时,使用这种自动填充方式是很有必要的。它可以达到一下作用 统一管理数据库表中的公共字段:如创建时间、修改时间、创建人ID、修改人ID等,这些…...

Android 已经过时的方法用什么新方法替代?
过时修正举例 (Kotlin): getColor(): resources.getColor(R.color.white) //已过时// 修正后:ContextCompat.getColor(this, R.color.white) getDrawable(): resources.getDrawable(R.mipmap.test) //已过时//修正后:ContextCompat.getDrawable(this, R.mipmap.test) //…...

【RocketMQ】MQ与RocketMQ介绍
🎯 导读:本文介绍了消息队列(MQ)的基本概念及其在分布式系统中的作用,包括实现异步通信、削峰限流和应用解耦等方面的优势,并对ActiveMQ、RabbitMQ、RocketMQ及Kafka四种MQ产品进行了对比分析,涵…...
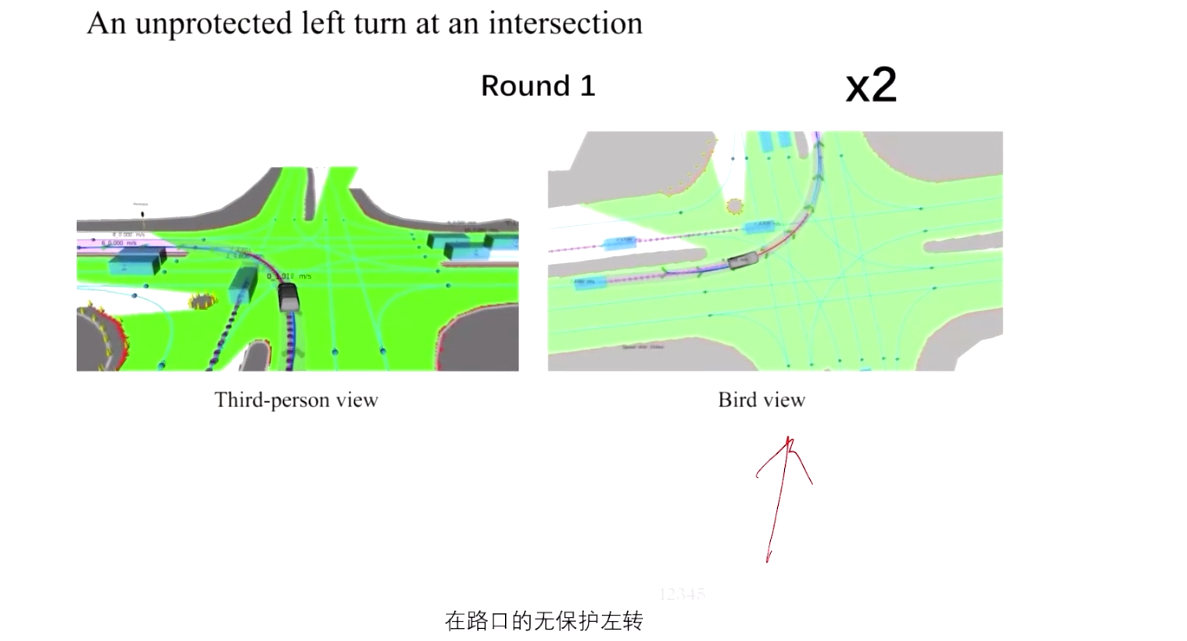
【笔记】自动驾驶预测与决策规划_Part4_时空联合规划
文章目录 0. 前言1. 时空联合规划的基本概念1.1 时空分离方法1.2 时空联合方法 2.基于搜索的时空联合规划 (Hybrid A* )2.1 基于Hybrid A* 的时空联合规划建模2.2 构建三维时空联合地图2.3 基于Hybrid A*的时空节点扩展2.4 Hybrid A* :时空节…...

Linux指令收集
文件和目录操作 ls: 列出目录内容。 -l 显示详细信息。-a 显示隐藏文件(以.开头的文件)。cd: 改变当前工作目录。 cd ~ 返回主目录。cd .. 上移一级目录。pwd: 显示当前工作目录。mkdir: 创建目录。 mkdir -p path/to/directory 创建多级目录。rmdir: 删…...
)
《C++并发编程实战》笔记(五)
五、内存模型和原子操作 5.1 C中的标准原子类型 原子操作是不可分割的操作,它或者完全做好,或者完全没做。 标准原子类型的定义在头文件<atomic>中,类模板std::atomic<T>接受各种类型的模板实参,从而创建该类型对应…...
)
在Python中实现多目标优化问题(5)
在Python中实现多目标优化问题 在Python中实现多目标优化,除了传统的进化算法(如NSGA-II、MOEA/D)和机器学习辅助的方法之外,还有一些新的方法和技术。以下是一些较新的或较少被提及的方法: 1. 基于梯度的多目标优化…...
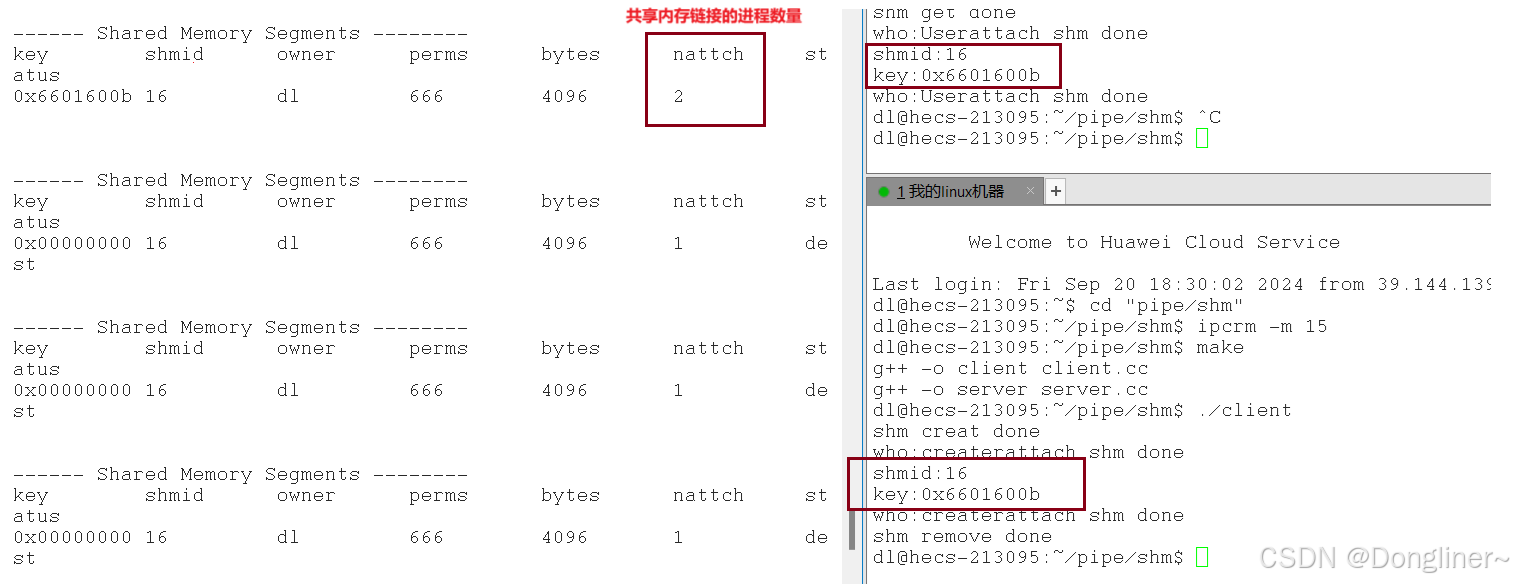
【Linux:共享内存】
共享内存的概念: 操作系统通过页表将共享内存的起始虚拟地址映射到当前进程的地址空间中共享内存是由需要通信的双方进程之一来创建但该资源并不属于创建它的进程,而属于操作系统 共享内存可以在系统中存在多份,供不同个数,不同进…...

今年Java回暖了吗
今年回暖了吗 仅结合师兄和同学的情况 BG 大多双非本 少部分211本 985硕 去年十月一之前 基本转正都失败 十月一之前0 offer 只有很少的人拿到美团 今年十月一之前 有HC的基本都转正了(美团、字节等),目前没有HC的说也有机会(…...

a = Sw,其中a和w是向量,S是矩阵,求w等于什么?w可以写成关于a和S的什么样子的公式
给定公式: a S w a S w aSw 其中: a a a 是已知向量, S S S 是已知矩阵, w w w 是未知向量。 我们的目标是求解 w w w,即将 w w w 表示为 a a a 和 S S S 的函数。 情况 1:矩阵 S S S 可逆 如果矩…...

多线程事务管理:Spring Boot 实现全局事务回滚
多线程事务管理:Spring Boot 实现全局事务回滚 在日常开发中,我们常常会遇到需要在多线程环境下进行数据库操作的场景。这类操作的挑战在于如何保证多个线程中的数据库操作要么一起成功,要么一起失败,即 事务的原子性。尤其是在多个线程并发执行的情况下,确保事务的一致性…...
Vue3 中集成海康 H5 监控视频播放功能
🌈个人主页:前端青山 🔥系列专栏:Vue篇 🔖人终将被年少不可得之物困其一生 依旧青山,本期给大家带来Vuet篇专栏内容:Vue-集成海康 H5 监控视频播放功能 目录 一、引言 二、环境搭建 三、代码解析 子组件部分 1.…...

Linux: eBPF: libbpf-bootstrap-master 编译
文章目录 简介编译运行展示输出展示:简介 这个是使用libbpf的一个例子; 编译 如果是一个可以联网的机器,这个libbpf-bootstrap的编译就方便了,完全是自动化的下载依赖文件;如果没有,就只能自己准备这些个软件。 需要:libbpf-static; [root@RH8-LCP c]# makeLIB …...
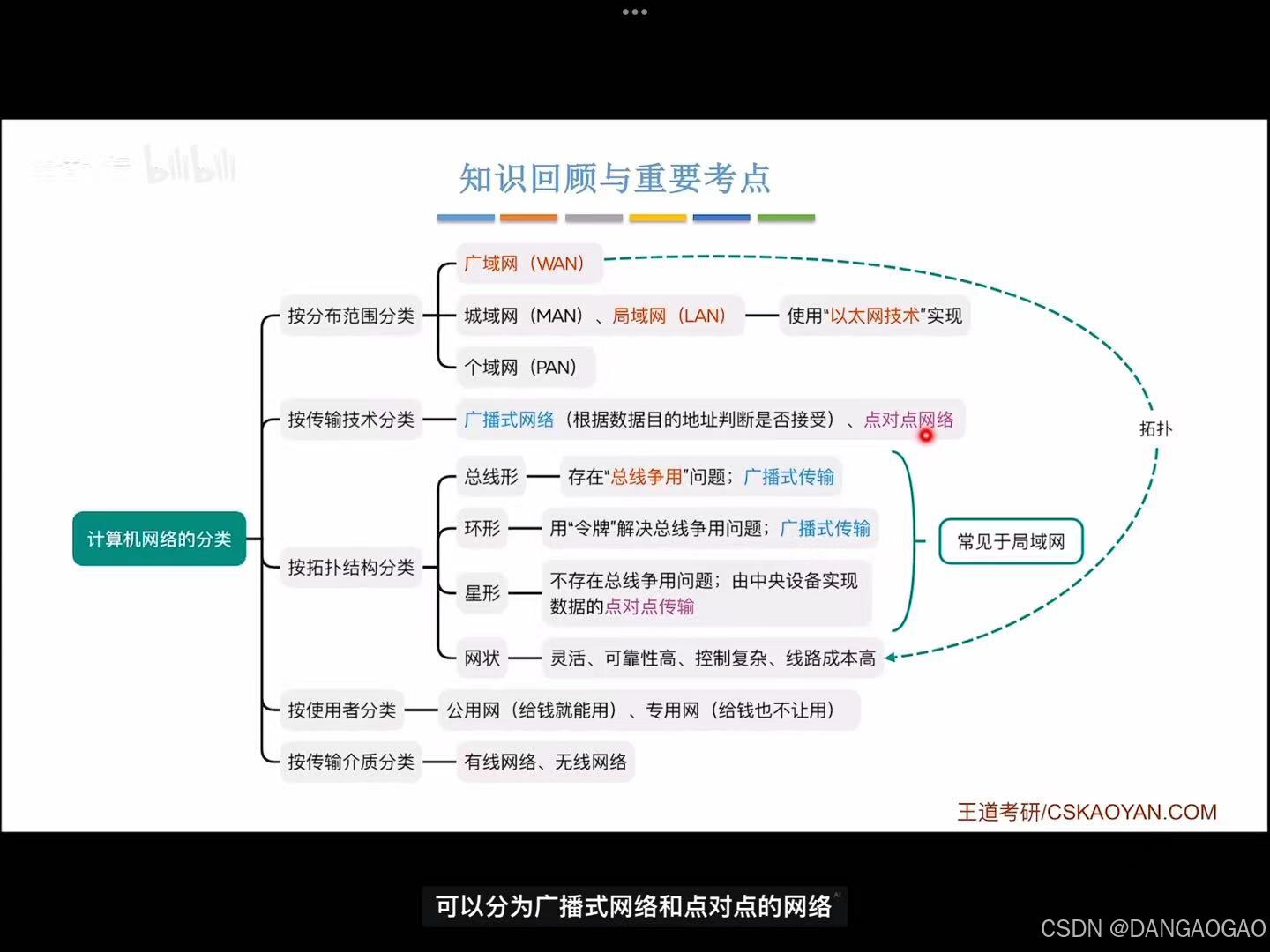
1.1.4 计算机网络的分类
按分布范围分类: 广域网(wan) 城域网(man) 局域网(lan) 个域网(pan) 注意:如今局域网几乎采用“以太网技术实现”,因此“以太网”几乎成了“局域…...

周家庄智慧旅游小程序
项目概述 周家庄智慧旅游小程序将通过数字化手段提升游客的旅游体验,依托周家庄的自然与文化资源,打造智慧旅游新模式。该小程序将结合虚拟现实(VR)、增强现实(AR)和人工智能等技术,提供丰富的…...

【在Linux世界中追寻伟大的One Piece】命名管道
目录 1 -> 命名管道 1.1 -> 创建一个命名管道 1.2 -> 匿名管道与命名管道的区别 1.3 -> 命名管道的打开规则 1.4 -> 例子 1 -> 命名管道 管道应用的一个限制就是只能在具有共同祖先(具有亲缘关系)的进程间通信。如果我们想在不相关的进程之间交换数据&…...
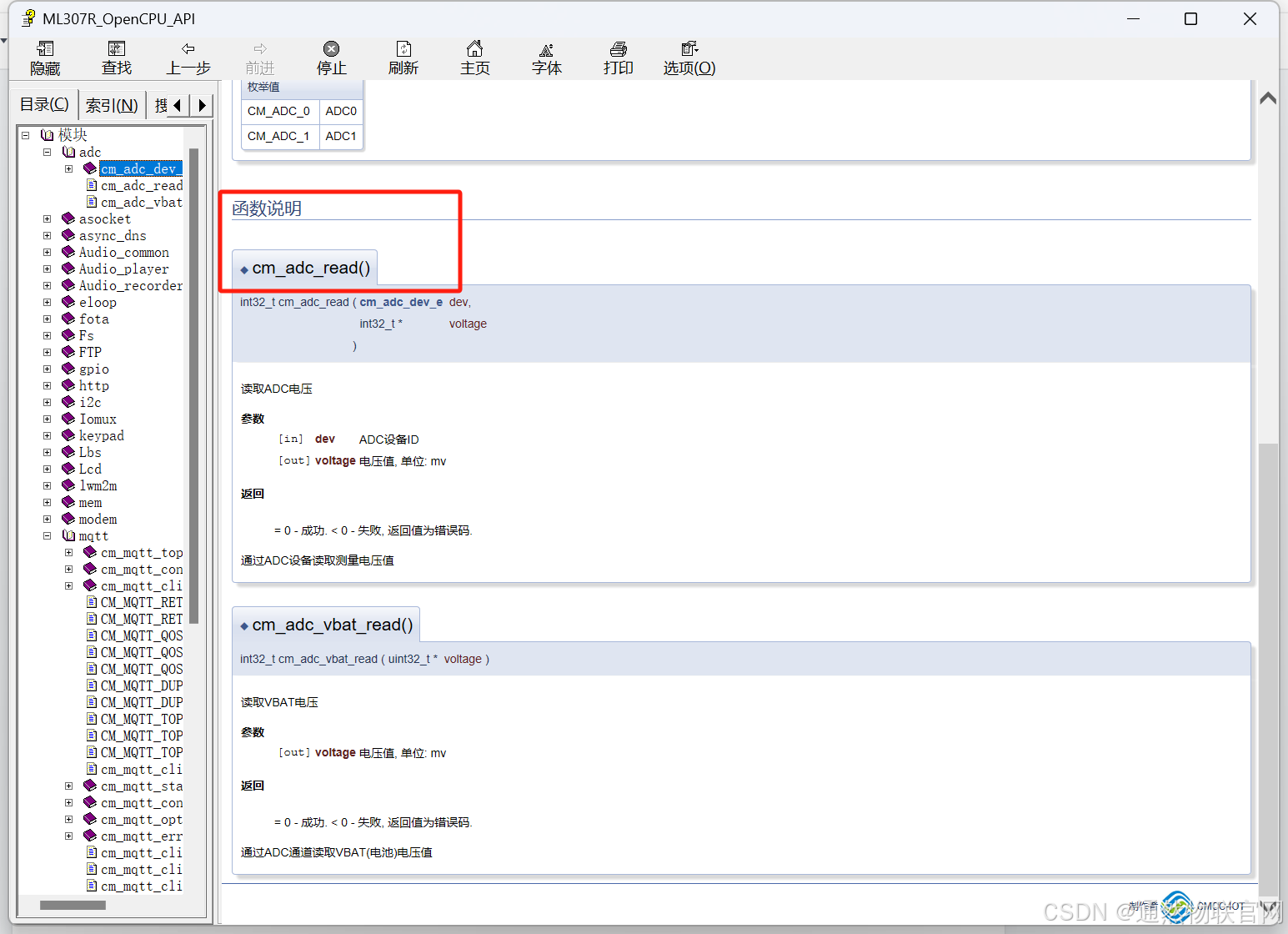
如意控物联网项目-ML307R模组软件及硬件调试环境搭建
软件及硬件调试环境搭建 1、 软件环境搭建及编译 a) 打开官方SDK,内涵APP-DEMO,通过vscode打开程序, 软件程序编写及编译参考下边说明文档链接 OneMO线上服务平台 编译需预安装python3.7以上版本,安装完python后,打开…...

5G网络架构深度解析:从核心网到接入网的组网实战
1. 5G网络架构全景解析 5G网络架构可以想象成一座现代化城市的交通系统。核心网相当于城市交通指挥中心,负责全局调度;接入网则是遍布城市的道路和红绿灯系统,直接管理车辆(数据)的流动。与传统4G网络相比,…...

Linux服务器内存不足?宝塔面板轻量级GitLab部署方案实测
Linux服务器内存不足?宝塔面板轻量级GitLab部署方案实测 当你在1-2GB内存的轻量级服务器上尝试部署GitLab时,是否经常遇到内存爆满、服务崩溃的情况?作为个人开发者或初创团队,如何在资源有限的情况下搭建稳定的代码管理平台&…...

DeerFlow惊艳案例:AI研究助手生成的报告有多专业
DeerFlow惊艳案例:AI研究助手生成的报告有多专业 1. DeerFlow研究助手核心能力展示 1.1 多源信息整合能力 DeerFlow最令人印象深刻的能力之一是它能从多个高质量信息源获取数据并整合成连贯的报告。在实际测试中,我们让它分析"2024年全球人工智能…...

手把手教你调试Linux下的lt8619c.c驱动:从设备树解析到V4L2控件初始化
手把手教你调试Linux下的lt8619c.c驱动:从设备树解析到V4L2控件初始化 在嵌入式Linux开发中,显示接口驱动调试往往是项目推进的关键环节。LT8619C作为一款高性能HDMI接收芯片,其驱动开发涉及设备树配置、V4L2框架集成、中断处理等多个技术要点…...
)
LSV实战:5分钟搞定倾斜摄影+BIM场景搭建(附模型快速复制技巧)
LSV高效场景搭建:倾斜摄影与BIM模型融合实战指南 在数字化设计与城市规划领域,将倾斜摄影模型与BIM人工模型结合已成为行业标配工作流。这种融合技术能快速构建高精度三维场景,大幅提升规划展示效果与方案沟通效率。对于经常需要处理大型场景…...

Doris性能调优必看:FE查询优化器与BE执行引擎的7个黄金配合法则
Doris性能调优实战:FE优化器与BE执行引擎的深度协同策略 当Doris集群处理千万级数据查询时,一个原本应该毫秒级返回的聚合操作突然陷入长达数分钟的等待——这不是简单的硬件资源问题,而是FE生成的执行计划与BE实际执行能力之间出现了认知偏差…...

我把 VS Code 里看依赖版本的插件,做了一个更快的版本
我把 VS Code 里看依赖版本的插件,做了一个更快的版本 平时写 Node.js 项目时,我经常会在 package.json 里看看依赖有没有更新。 之前我一直在用 Version Lens 这类插件,它的体验本身是不错的:打开 package.json,就能直…...
)
基于Linux中的数据库操作——用户密码找回(2)
1.首先需要停止MySQLsystemctl stop mysqld2、跳过权限验证启动MySQLmysqld --usermysql --skip-grant-tables &如果mysqld_safw文件已经存在,则可用:/usr/local/mysql/bin/mysqld_safe --skip-grant-tables &3.现在则可无密码登录MySQLmysql -…...

tao-8k Embedding模型实战教程:本地化部署+WebUI交互+API集成
tao-8k Embedding模型实战教程:本地化部署WebUI交互API集成 1. 环境准备与快速部署 在开始使用tao-8k模型之前,我们需要先准备好基础环境。tao-8k是一个专门处理文本嵌入的开源模型,能够将文本转换成高维向量,特别适合处理长文本…...

【统信UOS实战】离线部署MySQL 5.7:从依赖缺失到服务自启的完整避坑指南
1. 离线环境下的MySQL 5.7部署挑战 在国产统信UOS桌面操作系统上部署MySQL 5.7,最大的难点在于软件源闭源导致的依赖缺失问题。我最近在一个政府项目中就遇到了这个场景——内网服务器无法连接外网,但业务系统又急需MySQL数据库支持。经过多次尝试和踩坑…...