240929-CGAN条件生成对抗网络
240929-CGAN条件生成对抗网络
前面我们学习了GAN(240925-GAN生成对抗网络-CSDN博客)和DCGAN(240929-DCGAN生成漫画头像-CSDN博客),接下来继续来看CGAN(Conditional GAN)条件生成对抗网络。
流程
首先我们来复习下GAN的流程。
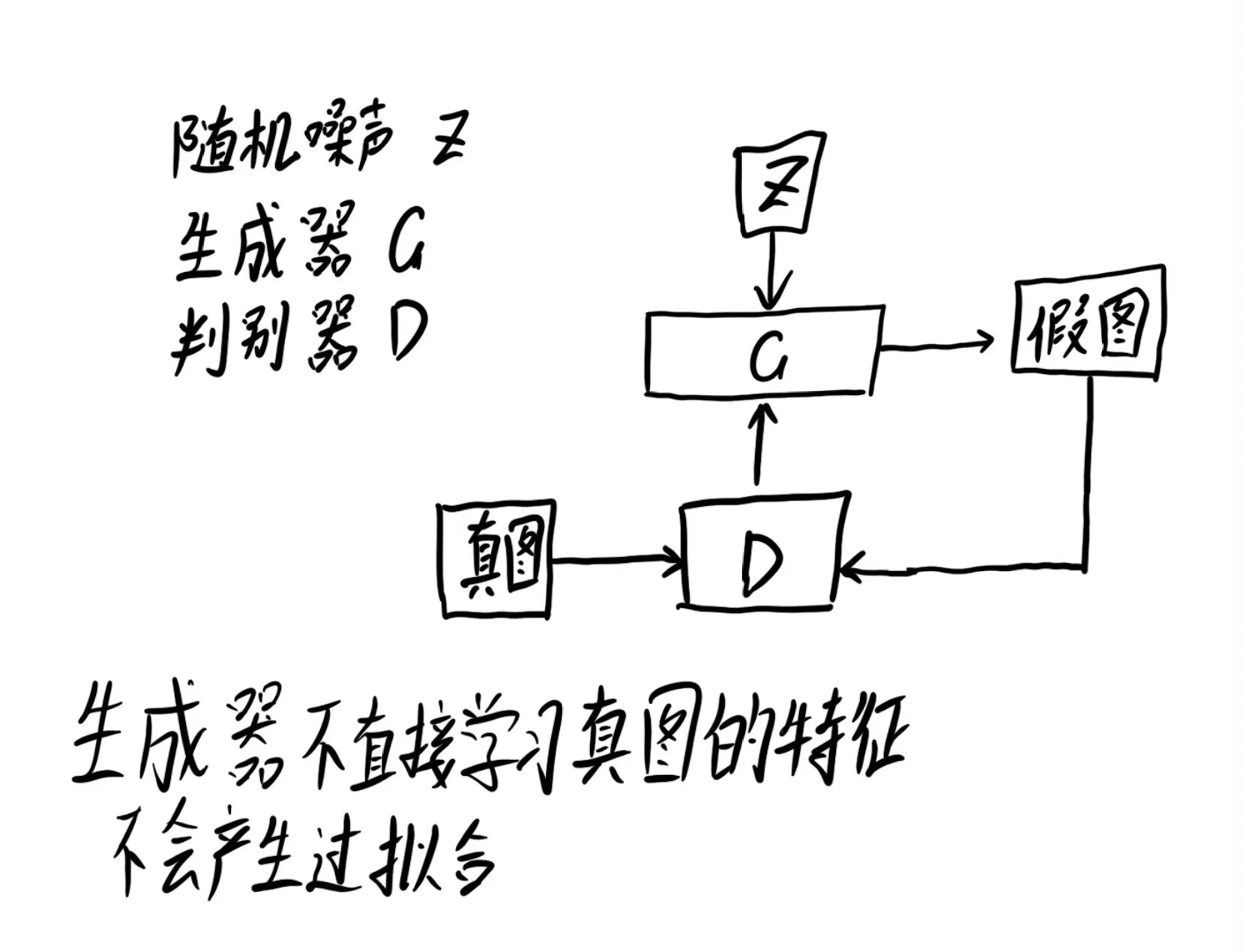
首先生成一组随机噪声,把这组随机噪声传入G,G生成一组假数据,这组假数据和真数据作为输入传入D,然后根据误差来优化判别器,判别器优化完成后,评估真假数据就变得很容易,此时就要反过来优化生成器,之后生成器水平提高了,又要反过来优化判别器,就这样循环往复竞争对抗,直到达到一个动态的均衡(纳什均衡),判别模型再也判断不出结果,准确率为50%,约等于乱猜。
而CGAN的流程与此有所区别,主要在于加入了条件标签的概念
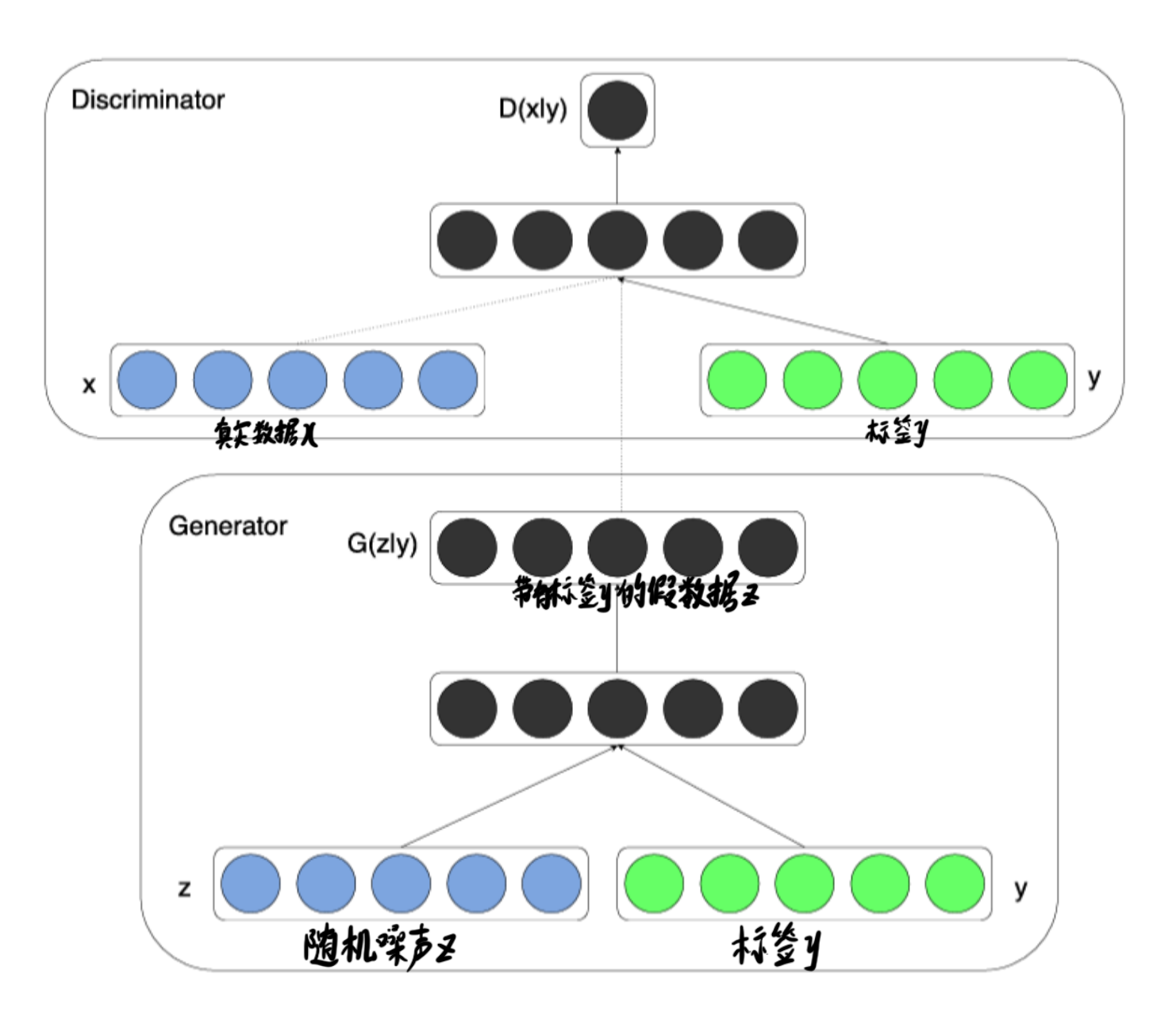
拆分开分别看生成器和判别器
生成器
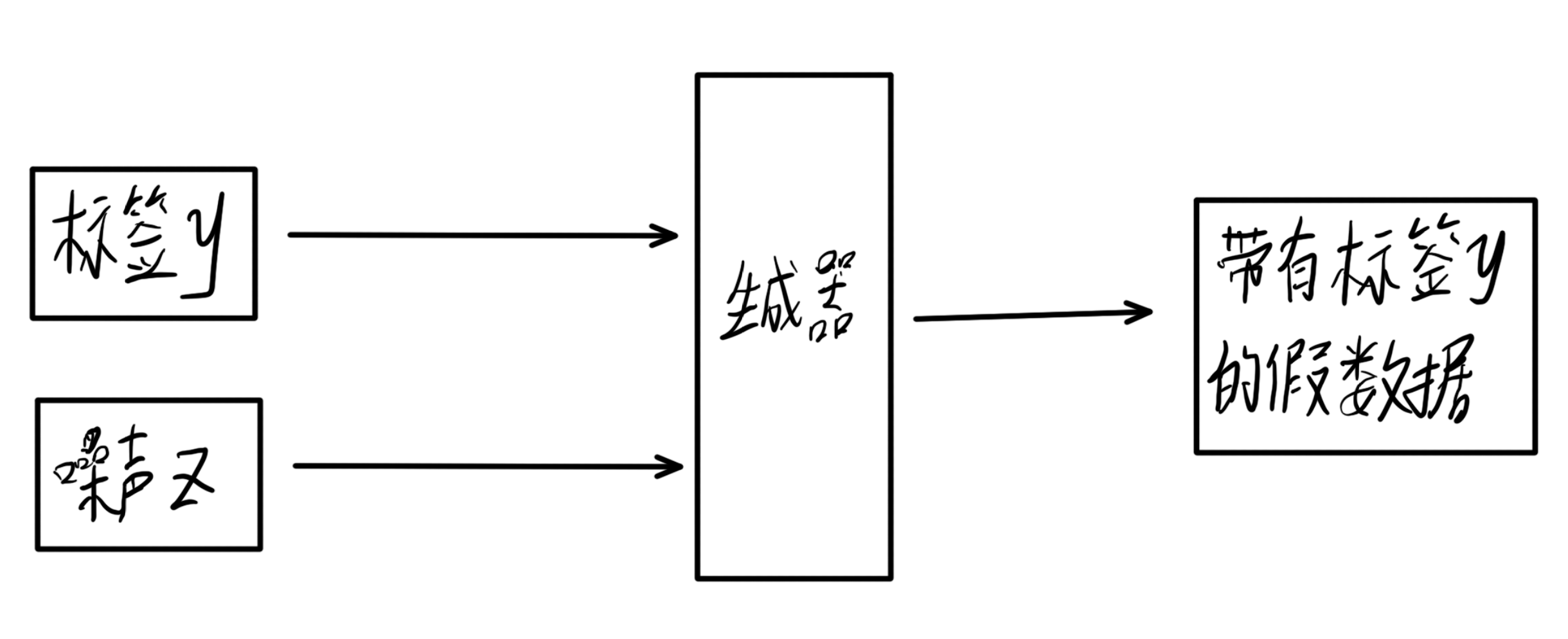
生成器接收标签y和噪声z,输出一个力求与标签相匹配的为样本,用来蒙骗判别器。
判别器
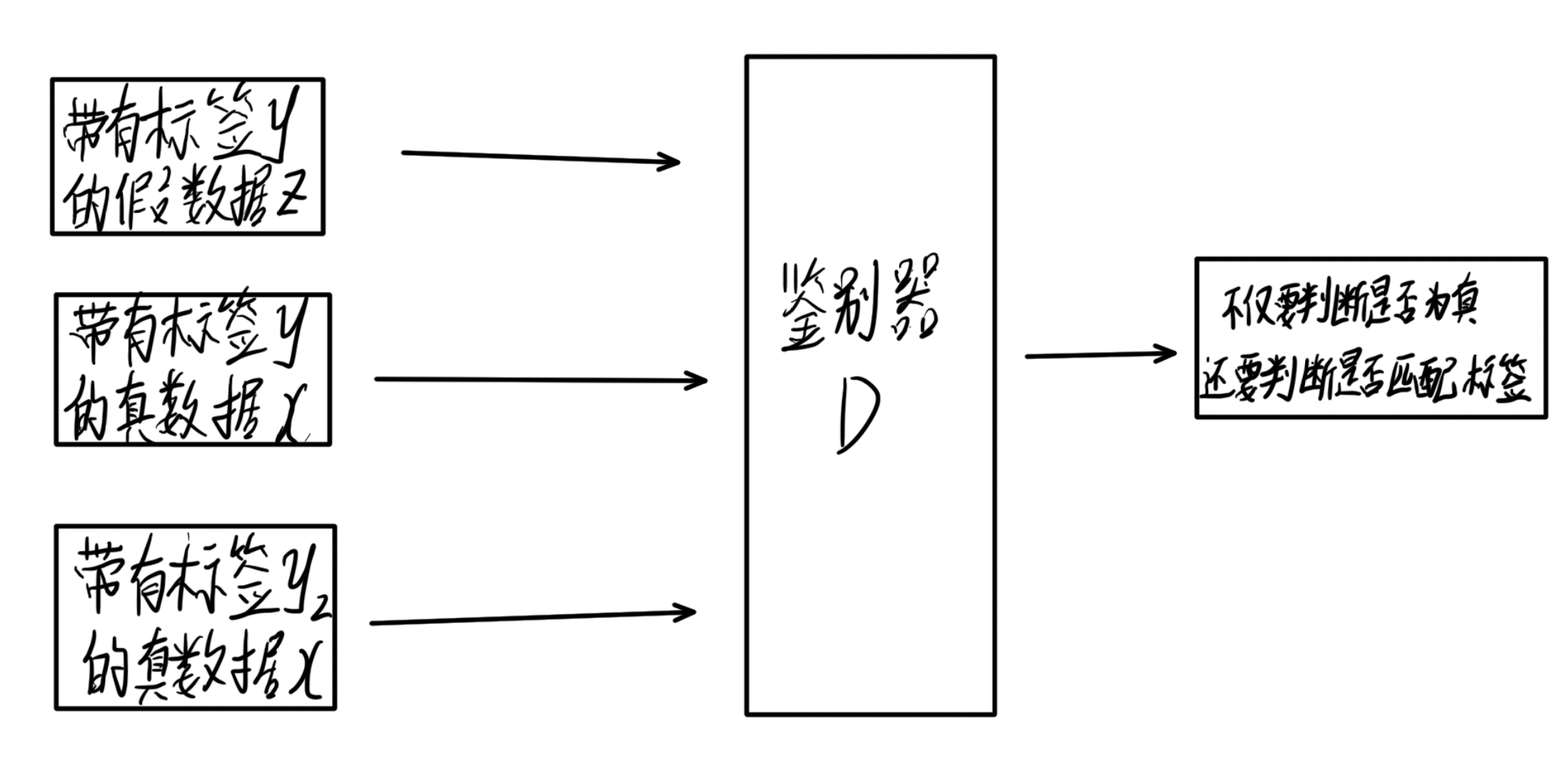
判别器接收三个数据,真实数据x,标签y,带有标签y的假数据z,此时,判别器不仅要判断数据是否为真,还要判断数据和标签是否匹配,而后接收真实且匹配的数据。
目标函数
接下来我们看目标函数的对比:
GAN:

CGAN:

实战案例(Pix2Pix实现图像转换)
下面做一个实战案例
数据处理
在本次实验中,我们使用经过处理的外墙(facades)数据集
from download import downloadurl = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/models/application/dataset_pix2pix.tar"download(url, "./dataset", kind="tar", replace=True)
下载之后我们可视化部分数据集,看看长什么样子
from mindspore import dataset as ds
import matplotlib.pyplot as pltdataset = ds.MindDataset("./dataset/dataset_pix2pix/train.mindrecord", columns_list=["input_images", "target_images"], shuffle=True)
data_iter = next(dataset.create_dict_iterator(output_numpy=True))
# 可视化部分训练数据
plt.figure(figsize=(10, 3), dpi=140)
for i, image in enumerate(data_iter['input_images'][:10], 1):plt.subplot(3, 10, i)plt.axis("off")plt.imshow((image.transpose(1, 2, 0) + 1) / 2)
plt.show()

网络结构搭建
生成器G用到的是U-Net结构,输入的轮廓图𝑥x编码再解码成真是图片,判别器D用到的是作者自己提出来的条件判别器PatchGAN,判别器D的作用是在轮廓图 𝑥x的条件下,对于生成的图片𝐺(𝑥)G(x)判断为假,对于真实判断为真。
生成器
U-Net简单结构可以参考笔者编写一个简单的UNet图像分割网络_(二)网络结构搭建_unet网络怎么简单的画出来-CSDN博客,简单参考即可。
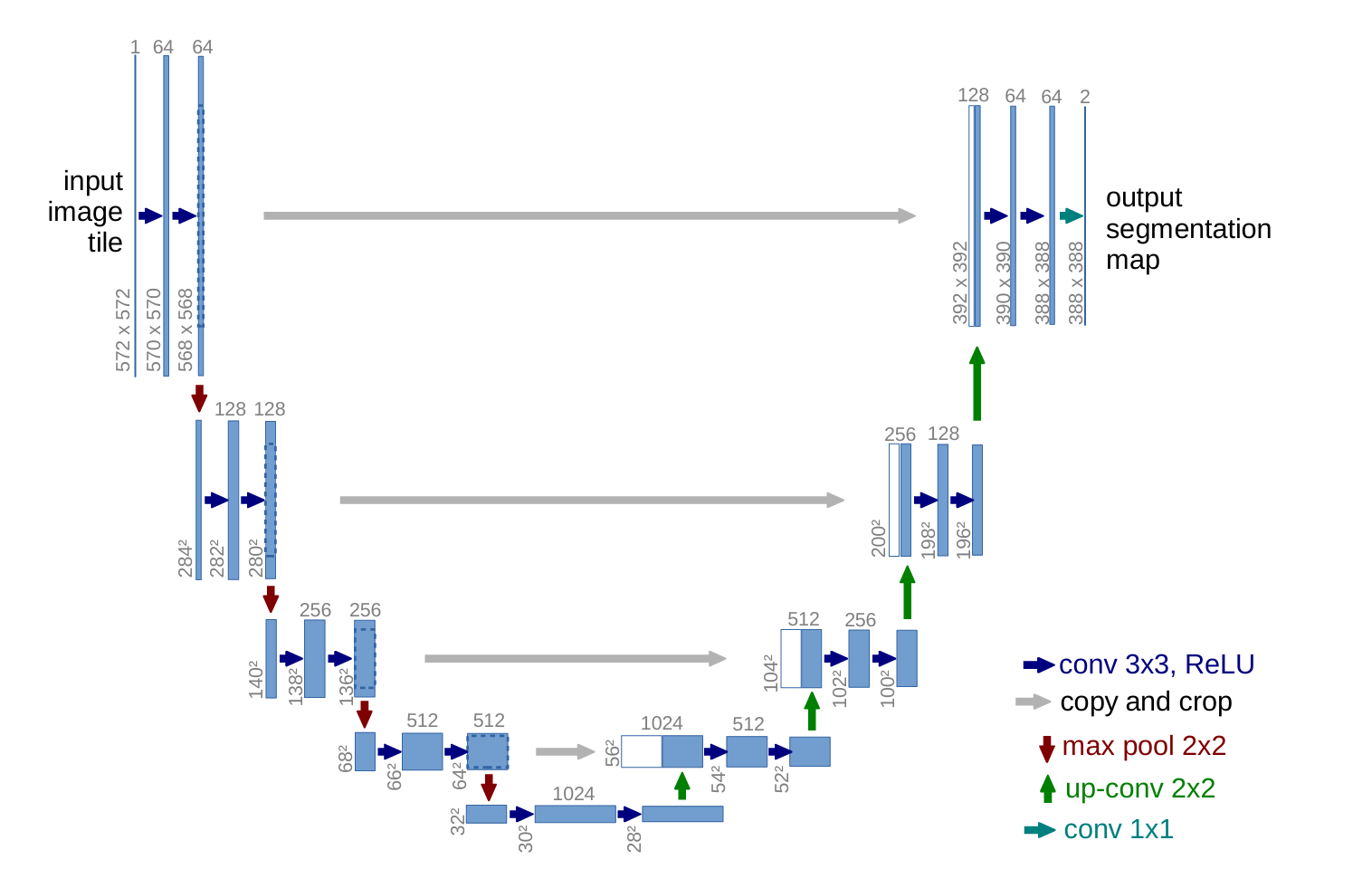
首先我们定义UNet Skip Connection Block块。这部分代码可能不太好理解,不急看懂,先继续往下看(也可能只是我太蠢没看懂,但往下看我会解释清楚结构)
import mindspore
import mindspore.nn as nn
import mindspore.ops as opsclass UNetSkipConnectionBlock(nn.Cell):"""定义UNet的跳跃连接块。参数:outer_nc (int): 输入和输出通道的数量。inner_nc (int): 内部层的通道数量。in_planes (int, optional): 输入平面的数量。默认为None,表示与outer_nc相同。dropout (bool, optional): 是否使用dropout。默认为False。submodule (nn.Cell, optional): 内部的UNet模块。outermost (bool, optional): 是否为最外层的UNet块。默认为False。innermost (bool, optional): 是否为最内层的UNet块。默认为False。alpha (float, optional): LeakyReLU的负斜率。默认为0.2。norm_mode (str, optional): 正则化模式 ('batch' 或 'instance')。默认为'batch'。返回:UNet跳跃连接块的实例。"""def __init__(self, outer_nc, inner_nc, in_planes=None, dropout=False,submodule=None, outermost=False, innermost=False, alpha=0.2, norm_mode='batch'):super(UNetSkipConnectionBlock, self).__init__()# 定义下采样和上采样的正则化层down_norm = nn.BatchNorm2d(inner_nc)up_norm = nn.BatchNorm2d(outer_nc)# 根据正则化模式判断是否需要使用偏置use_bias = Falseif norm_mode == 'instance':down_norm = nn.BatchNorm2d(inner_nc, affine=False)up_norm = nn.BatchNorm2d(outer_nc, affine=False)use_bias = True# 确定输入平面的数量if in_planes is None:in_planes = outer_nc# 定义下采样的卷积层和激活函数down_conv = nn.Conv2d(in_planes, inner_nc, kernel_size=4,stride=2, padding=1, has_bias=use_bias, pad_mode='pad')down_relu = nn.LeakyReLU(alpha)# 定义上采样的激活函数up_relu = nn.ReLU()# 根据是否为最外层、最内层或其他情况,定义上采样层和模型结构if outermost:up_conv = nn.Conv2dTranspose(inner_nc * 2, outer_nc,kernel_size=4, stride=2,padding=1, pad_mode='pad')down = [down_conv]up = [up_relu, up_conv, nn.Tanh()]model = down + [submodule] + upelif innermost:up_conv = nn.Conv2dTranspose(inner_nc, outer_nc,kernel_size=4, stride=2,padding=1, has_bias=use_bias, pad_mode='pad')down = [down_relu, down_conv]up = [up_relu, up_conv, up_norm]model = down + upelse:up_conv = nn.Conv2dTranspose(inner_nc * 2, outer_nc,kernel_size=4, stride=2,padding=1, has_bias=use_bias, pad_mode='pad')down = [down_relu, down_conv, down_norm]up = [up_relu, up_conv, up_norm]model = down + [submodule] + upif dropout:model.append(nn.Dropout(p=0.5))# 将模型结构封装为顺序序列self.model = nn.SequentialCell(model)# 记录是否为最外层,用于判断是否需要添加跳跃连接self.skip_connections = not outermostdef construct(self, x):"""执行UNet跳跃连接块的前向传播。参数:x (Tensor): 输入张量。返回:Tensor: 经过UNet块处理后的输出张量。"""out = self.model(x)# 根据是否为最外层,决定是否添加跳跃连接if self.skip_connections:out = ops.concat((out, x), axis=1)return out
接下来搭建生成器网络
class UNetGenerator(nn.Cell):def __init__(self, in_planes, out_planes, ngf=64, n_layers=8, norm_mode='bn', dropout=False):super(UNetGenerator, self).__init__()unet_block = UNetSkipConnectionBlock(ngf * 8, ngf * 8, in_planes=None, submodule=None,norm_mode=norm_mode, innermost=True)for _ in range(n_layers - 5):unet_block = UNetSkipConnectionBlock(ngf * 8, ngf * 8, in_planes=None, submodule=unet_block,norm_mode=norm_mode, dropout=dropout)unet_block = UNetSkipConnectionBlock(ngf * 4, ngf * 8, in_planes=None, submodule=unet_block,norm_mode=norm_mode)unet_block = UNetSkipConnectionBlock(ngf * 2, ngf * 4, in_planes=None, submodule=unet_block,norm_mode=norm_mode)unet_block = UNetSkipConnectionBlock(ngf, ngf * 2, in_planes=None, submodule=unet_block,norm_mode=norm_mode)self.model = UNetSkipConnectionBlock(out_planes, ngf, in_planes=in_planes, submodule=unet_block,outermost=True, norm_mode=norm_mode)def construct(self, x):return self.model(x)
对生成器U-Net架构的一些赘述
简单看代码可能有点迷,下面是解释:
首先我们执行完上面两段后,先把网络结构打印出来,进行对照查看。(该段仅方便理解,非实验所必须)
# 创建 UNetGenerator 实例
model = UNetGenerator(in_planes=3, out_planes=3, ngf=64, n_layers=8, norm_mode='bn', dropout=False)# 打印网络结构
print(model)
执行完我们可以看到这么一大堆东西,为便于阅读,此处把它粘贴到vscode里面进行查看
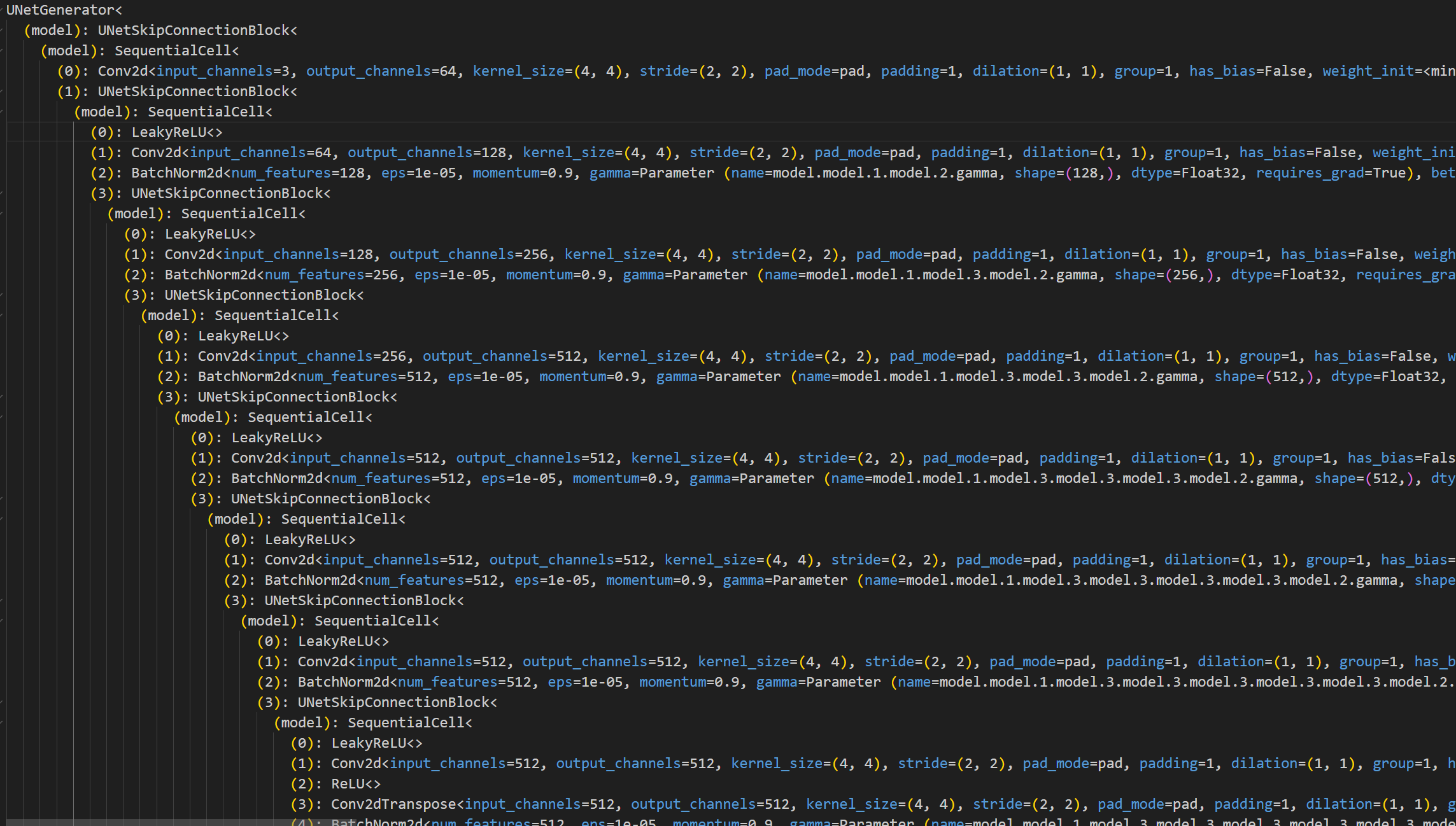
其实粘贴进来我们就大概可以看到端倪了,在notebook中没有高亮,对齐也没有那么易于阅读,所以可能不太好看。
我们定位到最里层,也就是这里
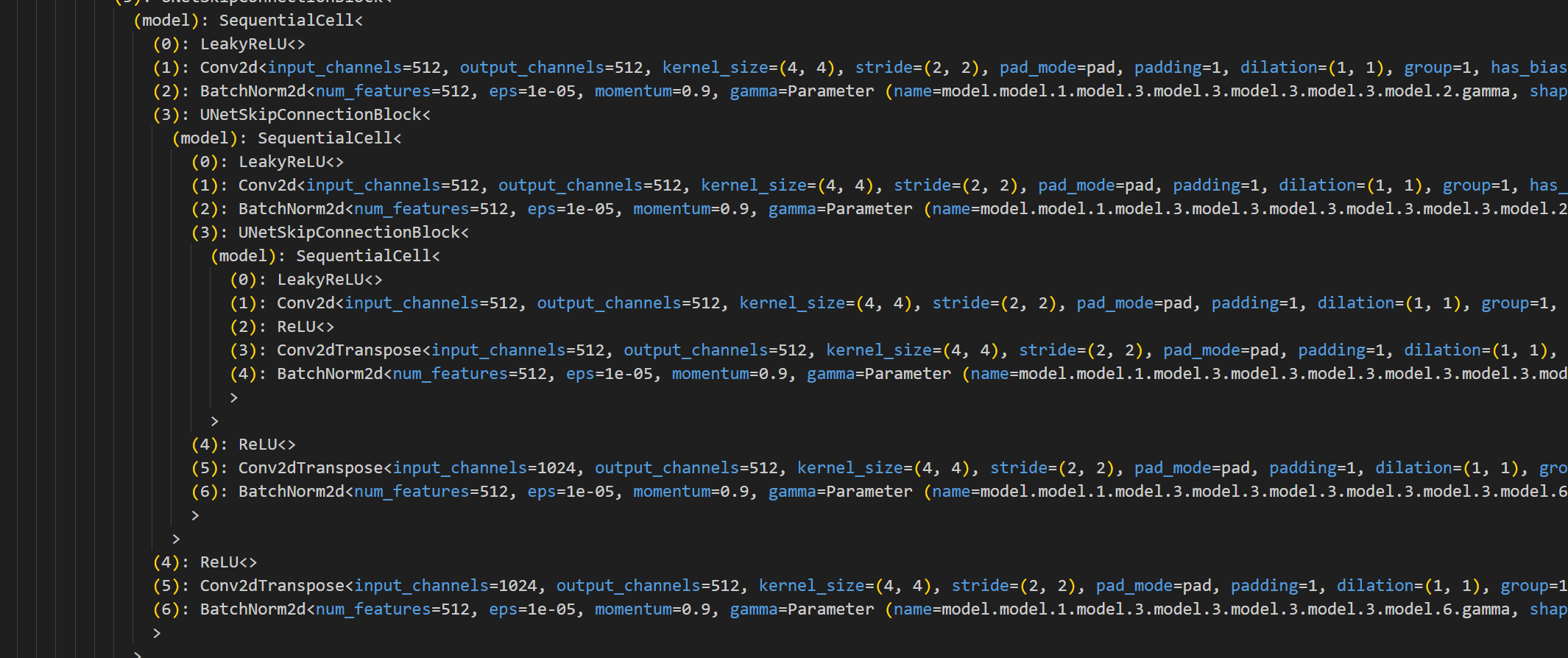
就可以大概看出来,他确实是类似于U-Net的对称结构,我们先从最里层开始对照代码查看
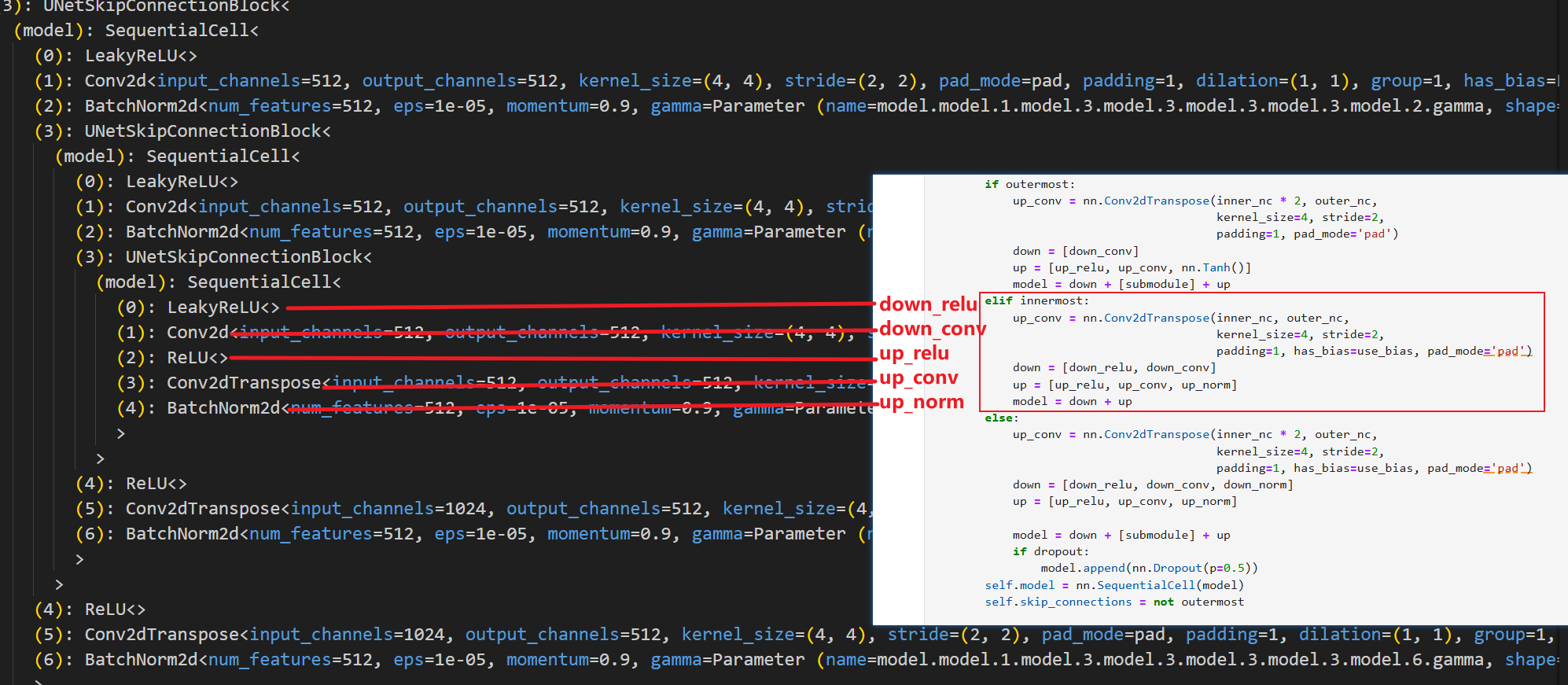
然后开始其他层(除了内层和外层之外的层,代码中也是仅做了这三种区分),我们以次里层为例
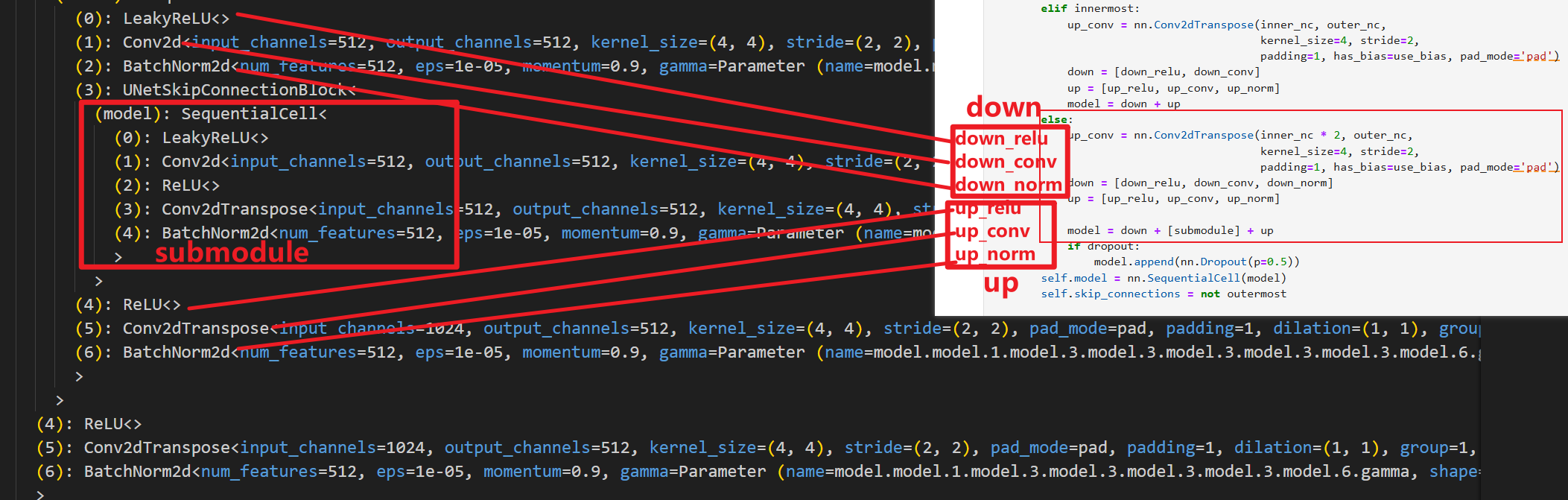
次里层就是把最里层作为子层进行嵌套,其余非最外层的层同理,都是把上一层作为子层进行嵌套(如果类比U-Net的图,可以理解为是把下一层进行嵌套,原理一样,叫法不同而已),然后看最外层
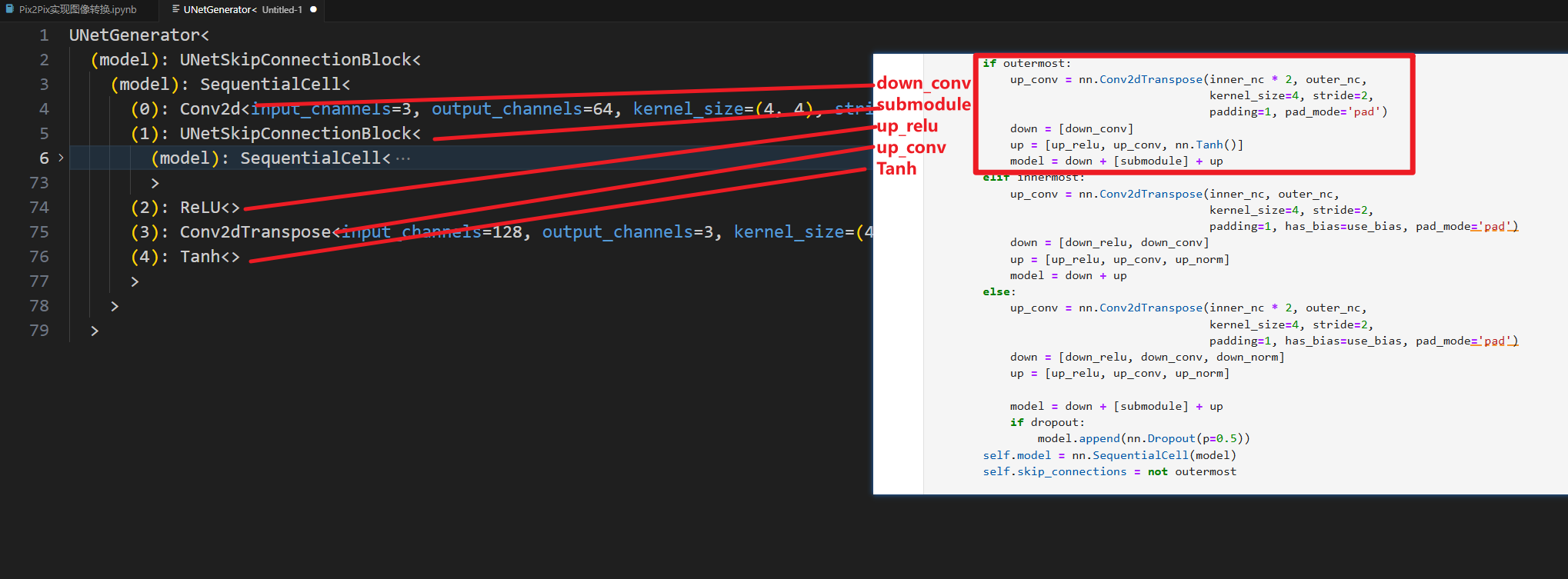
中间的层数是被我隐藏掉了。
整体看完之后就可以通透的理解了,这个U-Net结构是分层直接进行代码定义(不分左右,采用嵌套结构),不知道你们是不是哈,我入门U-Net的时候看的代码是分左右部分对每一层分别定义,所以对这部分理解有些许困难,如有大佬请直接忽略上面这部分赘述。
判别器
判别器使用的PatchGAN结构,可看做卷积。生成的矩阵中的每个点代表原图的一小块区域(patch)。通过矩阵中的各个值来判断原图中对应每个Patch的真假。
import mindspore.nn as nnclass ConvNormRelu(nn.Cell):"""一个表示卷积、归一化和ReLU层块的类。参数:in_planes (int): 输入图像的通道数。out_planes (int): 输出图像的通道数。kernel_size (int): 卷积核大小,默认为4。stride (int): 卷积步长,默认为2。alpha (float): LeakyReLU的负斜率,默认为0.2。norm_mode (str): 归一化模式,可以是'batch'或'instance',默认为'batch'。pad_mode (str): 填充模式,可以是'CONSTANT'、'reflect'等,默认为'CONSTANT'。use_relu (bool): 是否使用ReLU激活,默认为True。padding (int): 填充大小。如果为None,则使用默认填充,默认为None。"""def __init__(self,in_planes,out_planes,kernel_size=4,stride=2,alpha=0.2,norm_mode='batch',pad_mode='CONSTANT',use_relu=True,padding=None):super(ConvNormRelu, self).__init__()# 根据norm_mode选择归一化层norm = nn.BatchNorm2d(out_planes)if norm_mode == 'instance':norm = nn.BatchNorm2d(out_planes, affine=False)# 根据归一化模式确定卷积层是否有偏置has_bias = (norm_mode == 'instance')# 确定填充大小if not padding:padding = (kernel_size - 1) // 2# 构建卷积层和归一化层if pad_mode == 'CONSTANT':conv = nn.Conv2d(in_planes, out_planes, kernel_size, stride, pad_mode='pad',has_bias=has_bias, padding=padding)layers = [conv, norm]else:paddings = ((0, 0), (0, 0), (padding, padding), (padding, padding))pad = nn.Pad(paddings=paddings, mode=pad_mode)conv = nn.Conv2d(in_planes, out_planes, kernel_size, stride, pad_mode='pad', has_bias=has_bias)layers = [pad, conv, norm]# 如果需要,添加ReLU层if use_relu:relu = nn.ReLU()if alpha > 0:relu = nn.LeakyReLU(alpha)layers.append(relu)self.features = nn.SequentialCell(layers)def construct(self, x):"""ConvNormRelu块的前向计算。参数:x (Tensor): 输入张量。返回:Tensor: 经过卷积、归一化和激活后的输出张量。"""output = self.features(x)return outputclass Discriminator(nn.Cell):"""判别网络类。参数:in_planes (int): 输入图像的通道数,默认为3。ndf (int): 第一层的滤波器数量,默认为64。n_layers (int): 卷积层数,默认为3。alpha (float): LeakyReLU的负斜率,默认为0.2。norm_mode (str): 归一化模式,可以是'batch'或'instance',默认为'batch'。"""def __init__(self, in_planes=3, ndf=64, n_layers=3, alpha=0.2, norm_mode='batch'):super(Discriminator, self).__init__()kernel_size = 4# 第一层:卷积 + LeakyReLUlayers = [nn.Conv2d(in_planes, ndf, kernel_size, 2, pad_mode='pad', padding=1),nn.LeakyReLU(alpha)]# 中间层:卷积 + 归一化 + LeakyReLUnf_mult = ndffor i in range(1, n_layers):nf_mult_prev = nf_multnf_mult = min(2 ** i, 8) * ndflayers.append(ConvNormRelu(nf_mult_prev, nf_mult, kernel_size, 2, alpha, norm_mode, padding=1))# 最后一层:卷积(无激活函数)layers.append(nn.Conv2d(nf_mult, 1, kernel_size, 1, pad_mode='pad', padding=1))self.features = nn.SequentialCell(layers)def construct(self, x, y):"""判别网络的前向计算。参数:x (Tensor): 真实或生成的图像张量。y (Tensor): 条件图像张量。返回:Tensor: 经过判别网络前向计算后的输出张量。"""x_y = ops.concat((x, y), axis=1)output = self.features(x_y)return output
判别器的代码相对来说没有生成器那么绕,但是变量名稍微有点混,我们也可以把结构打印出来对照查看,这里自行对照。笔者仅提供代码。
# 创建 UNetGenerator 实例
model = Discriminator(in_planes=3, ndf=64, n_layers=3, norm_mode='batch')# 打印网络结构
print(model)
Pix2Pix的生成器和判别器初始化
# 导入MindSpore的神经网络模块和初始化方法
import mindspore.nn as nn
from mindspore.common import initializer as init# 定义生成器的输入和输出通道数
g_in_planes = 3
g_out_planes = 3
# 定义生成器的特征数和卷积层数
g_ngf = 64
g_layers = 8
# 定义判别器的输入通道数和特征数
d_in_planes = 6
d_ndf = 64
# 定义判别器的卷积层数和LeakyReLU的负斜率系数
d_layers = 3
alpha = 0.2
# 定义模型参数的初始化方法和增益值
init_gain = 0.02
init_type = 'normal'# 初始化生成器网络,并根据指定的初始化类型对生成器的参数进行初始化
net_generator = UNetGenerator(in_planes=g_in_planes, out_planes=g_out_planes,ngf=g_ngf, n_layers=g_layers)
# 遍历生成器网络的所有可训练的块及其名称
for _, cell in net_generator.cells_and_names():# 判断当前单元是否为卷积层或卷积转置层if isinstance(cell, (nn.Conv2d, nn.Conv2dTranspose)):# 根据指定的初始化类型对卷积层的权重进行初始化if init_type == 'normal':cell.weight.set_data(init.initializer(init.Normal(init_gain), cell.weight.shape))elif init_type == 'xavier':cell.weight.set_data(init.initializer(init.XavierUniform(init_gain), cell.weight.shape))elif init_type == 'constant':cell.weight.set_data(init.initializer(0.001, cell.weight.shape))else:raise NotImplementedError('initialization method [%s] is not implemented' % init_type)# 判断当前单元是否为批归一化层elif isinstance(cell, nn.BatchNorm2d):# 对批归一化层的gamma参数和beta参数进行初始化cell.gamma.set_data(init.initializer('ones', cell.gamma.shape))cell.beta.set_data(init.initializer('zeros', cell.beta.shape))
# 初始化判别器网络,并根据指定的初始化类型对判别器的参数进行初始化
net_discriminator = Discriminator(in_planes=d_in_planes, ndf=d_ndf,alpha=alpha, n_layers=d_layers)
for _, cell in net_discriminator.cells_and_names():if isinstance(cell, (nn.Conv2d, nn.Conv2dTranspose)):if init_type == 'normal':cell.weight.set_data(init.initializer(init.Normal(init_gain), cell.weight.shape))elif init_type == 'xavier':cell.weight.set_data(init.initializer(init.XavierUniform(init_gain), cell.weight.shape))elif init_type == 'constant':cell.weight.set_data(init.initializer(0.001, cell.weight.shape))else:raise NotImplementedError('initialization method [%s] is not implemented' % init_type)elif isinstance(cell, nn.BatchNorm2d):cell.gamma.set_data(init.initializer('ones', cell.gamma.shape))cell.beta.set_data(init.initializer('zeros', cell.beta.shape))# 定义Pix2Pix模型类,整合生成器和判别器
class Pix2Pix(nn.Cell):"""Pix2Pix模型网络"""def __init__(self, discriminator, generator):super(Pix2Pix, self).__init__(auto_prefix=True)# 初始化判别器和生成器网络self.net_discriminator = discriminatorself.net_generator = generatordef construct(self, reala):# 通过生成器网络生成假的输出fakeb = self.net_generator(reala)return fakeb
训练
训练分为两个主要部分:训练判别器和训练生成器。训练判别器的目的是最大程度地提高判别图像真伪的概率。训练生成器是希望能产生更好的虚假图像。在这两个部分中,分别获取训练过程中的损失,并在每个周期结束时进行统计。
# 使用%%time魔术命令来测量代码块的执行时间
import numpy as np # 引入numpy库用于数值计算
import os # 引入os库用于操作系统相关功能
import datetime # 引入datetime库用于处理日期和时间
from mindspore import value_and_grad, Tensor # 从mindspore库中引入梯度计算和Tensor对象# 定义训练轮次、检查点目录、数据集大小、验证图片大小、学习率、训练和衰减周期等超参数
epoch_num = 3
ckpt_dir = "results/ckpt"
dataset_size = 400
val_pic_size = 256
lr = 0.0002
n_epochs = 100
n_epochs_decay = 100# 定义函数以获取学习率列表
def get_lr():# 初始化学习率列表lrs = [lr] * dataset_size * n_epochslr_epoch = 0# 逐步衰减学习率for epoch in range(n_epochs_decay):lr_epoch = lr * (n_epochs_decay - epoch) / n_epochs_decaylrs += [lr_epoch] * dataset_sizelrs += [lr_epoch] * dataset_size * (epoch_num - n_epochs_decay - n_epochs)return Tensor(np.array(lrs).astype(np.float32)) # 返回学习率Tensor# 加载数据集
dataset = ds.MindDataset("./dataset/dataset_pix2pix/train.mindrecord", columns_list=["input_images", "target_images"], shuffle=True, num_parallel_workers=1)
steps_per_epoch = dataset.get_dataset_size() # 获取每个epoch的步骤数
loss_f = nn.BCEWithLogitsLoss() # 定义二分类损失函数
l1_loss = nn.L1Loss() # 定义L1损失函数# 定义判别器前向计算函数
def forword_dis(reala, realb):lambda_dis = 0.5 # 判别器损失权重fakeb = net_generator(reala) # 生成假图像pred0 = net_discriminator(reala, fakeb) # 判别器对假图像的预测pred1 = net_discriminator(reala, realb) # 判别器对真图像的预测loss_d = loss_f(pred1, ops.ones_like(pred1)) + loss_f(pred0, ops.zeros_like(pred0)) # 计算判别器损失loss_dis = loss_d * lambda_dis # 加权判别器损失return loss_dis# 定义生成器前向计算函数
def forword_gan(reala, realb):lambda_gan = 0.5 # 生成对抗损失权重lambda_l1 = 100 # L1损失权重fakeb = net_generator(reala) # 生成假图像pred0 = net_discriminator(reala, fakeb) # 判别器对假图像的预测loss_1 = loss_f(pred0, ops.ones_like(pred0)) # 计算对抗损失loss_2 = l1_loss(fakeb, realb) # 计算L1损失loss_gan = loss_1 * lambda_gan + loss_2 * lambda_l1 # 总生成器损失return loss_gan# 初始化优化器
d_opt = nn.Adam(net_discriminator.trainable_params(), learning_rate=get_lr(), beta1=0.5, beta2=0.999, loss_scale=1)
g_opt = nn.Adam(net_generator.trainable_params(), learning_rate=get_lr(), beta1=0.5, beta2=0.999, loss_scale=1)# 准备梯度计算函数
grad_d = value_and_grad(forword_dis, None, net_discriminator.trainable_params())
grad_g = value_and_grad(forword_gan, None, net_generator.trainable_params())# 定义训练步函数
def train_step(reala, realb):loss_dis, d_grads = grad_d(reala, realb) # 计算判别器损失和梯度loss_gan, g_grads = grad_g(reala, realb) # 计算生成器损失和梯度d_opt(d_grads) # 更新判别器参数g_opt(g_grads) # 更新生成器参数return loss_dis, loss_gan # 返回损失值# 确保检查点目录存在
if not os.path.isdir(ckpt_dir):os.makedirs(ckpt_dir)# 初始化损失列表
g_losses = []
d_losses = []
data_loader = dataset.create_dict_iterator(output_numpy=True, num_epochs=epoch_num) # 创建数据加载器# 开始训练循环
for epoch in range(epoch_num):for i, data in enumerate(data_loader):start_time = datetime.datetime.now() # 记录开始时间input_image = Tensor(data["input_images"]) # 输入图像target_image = Tensor(data["target_images"]) # 目标图像dis_loss, gen_loss = train_step(input_image, target_image) # 执行训练步end_time = datetime.datetime.now() # 记录结束时间delta = (end_time - start_time).microseconds # 计算步骤时间# 打印训练进度和损失信息if i % 2 == 0:print("ms per step:{:.2f} epoch:{}/{} step:{}/{} Dloss:{:.4f} Gloss:{:.4f} ".format((delta / 1000), (epoch + 1), (epoch_num), i, steps_per_epoch, float(dis_loss), float(gen_loss)))d_losses.append(dis_loss.asnumpy()) # 记录判别器损失g_losses.append(gen_loss.asnumpy()) # 记录生成器损失# 保存检查点if (epoch + 1) == epoch_num:mindspore.save_checkpoint(net_generator, ckpt_dir + "Generator.ckpt")
推理
获取上述训练过程完成后的ckpt文件,通过load_checkpoint和load_param_into_net将ckpt中的权重参数导入到模型中,获取数据进行推理并对推理的效果图进行演示(由于时间问题,训练过程只进行了3个epoch,可根据需求调整epoch)。
# 导入MindSpore的checkpoint加载函数
from mindspore import load_checkpoint, load_param_into_net# 加载生成器的参数
param_g = load_checkpoint(ckpt_dir + "Generator.ckpt")
# 将加载的参数应用到生成器网络中
load_param_into_net(net_generator, param_g)# 加载训练数据集,包括输入图像和目标图像,并开启数据混洗以增强模型泛化能力
dataset = ds.MindDataset("./dataset/dataset_pix2pix/train.mindrecord", columns_list=["input_images", "target_images"], shuffle=True)
# 获取数据迭代器中的第一个批次的数据
data_iter = next(dataset.create_dict_iterator())# 使用生成器网络对输入图像进行前向传播,得到预测结果
predict_show = net_generator(data_iter["input_images"])# 初始化一个图形界面用于展示输入图像和生成的图像
plt.figure(figsize=(10, 3), dpi=140)
for i in range(10):# 绘制输入图像plt.subplot(2, 10, i + 1)plt.imshow((data_iter["input_images"][i].asnumpy().transpose(1, 2, 0) + 1) / 2)plt.axis("off")plt.subplots_adjust(wspace=0.05, hspace=0.02)# 绘制生成的图像plt.subplot(2, 10, i + 11)plt.imshow((predict_show[i].asnumpy().transpose(1, 2, 0) + 1) / 2)plt.axis("off")plt.subplots_adjust(wspace=0.05, hspace=0.02)
# 显示所有图像
plt.show()

原论文:1411.1784 (arxiv.org)
参考代码:Pix2Pix实现图像转… - JupyterLab (mindspore.cn)
参考资料:
ConditionalGAN(CGAN)介绍及实现图像转图像生成应用_conditional gan-CSDN博客
GAN学习记录(四)——条件生成对抗网络CGAN_条件生成对抗网络gancsdn-CSDN博客
相关文章:
240929-CGAN条件生成对抗网络
240929-CGAN条件生成对抗网络 前面我们学习了GAN(240925-GAN生成对抗网络-CSDN博客)和DCGAN(240929-DCGAN生成漫画头像-CSDN博客),接下来继续来看CGAN(Conditional GAN)条件生成对抗网络。 流…...

springboot第74集:设计模式
解析 核心线程数与CPU核数相同:避免线程过多导致的上下文切换,提高CPU利用率。无界队列:适合任务量大且任务执行时间短的场景,避免因队列满而拒绝任务。 IO密集型任务 场景描述 适用于执行大量IO操作的任务,如文件读写…...

数字化采购管理革新:全过程数字化采购管理平台的架构与实施
摘要:在数字化转型的浪潮中,采购管理正逐步迈向全流程的数字化。本文将详细解析全过程数字化采购管理平台的技术架构和实施策略,探讨如何通过Spring Cloud、Spring Boot2、Mybatis等先进技术和服务框架,实现从供应商管理到采购招投…...

Webpack 特性探讨:CDN、分包、Tree Shaking 与热更新
文章目录 前言包准备CDN 集成代码分包Tree Shaking原理实现条件:解决 treeShaking 无效方案:示例代码: 热更新(HMR) 前言 Webpack 作为现代前端开发中的核心构建工具,提供了丰富的特性来帮助开发者优化和打…...
)
Robot Operating System——一组三维空间中的位姿(位置和方向)
大纲 应用场景1. 机器人导航场景描述具体应用 2. 运动规划场景描述具体应用 3. 物体识别和跟踪场景描述具体应用 4. 环境建模场景描述具体应用 5. 仿真环境场景描述具体应用 定义字段解释 案例 geometry_msgs::msg::PoseArray 是 ROS 2 中的一个消息类型,用于表示一…...

mycat读写分离中间件
5、部署Mycat读写分离中间件服务 5.1安装Mycat服务 将Mycat服务的二进制软件包Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz上传到Mycat虚拟机的/root目录下,并将软件包解压到/use/local目录中 5.2赋予解压后的mycat目录权限 5.3向/etc/profile系统变量…...
Growthly Quest 增长工具:助力 Web3 项目实现数据驱动的增长
作者:Stella L (stellafootprint.network) 在瞬息万变的 Web3 领域,众多项目在用户吸引、参与和留存方面遭遇重重难关。Footprint Analytics 推出 Growthly,作为应对这些挑战的全方位解决方案,其中创新性的 Quest(任务…...

Pytorch 学习手册
零 相关资料 官方网址 官方网址下的API搜索网站 一 定义 深度学习框架是用于设计、训练和部署深度学习模型的软件工具包。这些框架提供了一系列预定义的组件,如神经网络层(卷积层、全连接层等)、损失函数、优化器以及数据处理工具…...
——Vite 环境变量)
第十一章 【前端】调用接口(11.1)——Vite 环境变量
第十一章 【前端】调用接口 11.1 Vite 环境变量 参考:https://cn.vitejs.dev/guide/env-and-mode.html Vite 在一个特殊的 import.meta.env 对象上暴露环境变量。为了防止意外地将一些环境变量泄漏到客户端,只有以 VITE_ 为前缀的变量才会暴露给经过 …...

MySQL添加时间戳字段并且判断插入或更新时间
文章目录 步骤 1: 修改表结构步骤 2: 插入或更新数据步骤 3: 查询数据并判断时间完整示例 在MySQL中,可以在表中添加一个时间戳字段来记录每条数据的最后插入或更新时间。然后,在插入或更新数据时,自动更新这个时间戳字段。最后,在…...
)
SOA(面相服务架构)
目录 SOA的基本概念 SOA的关键特性 SOA的实现步骤 SOA的技术实现 SOA的应用场景 面向服务的架构(Service-Oriented Architecture, SOA)是一种软件设计理念和架构模式,旨在通过网络协议将不同的服务相互连接和集成,以构建灵活、可扩展和可重用的应用系统。SOA的…...
关联场景中,如何从模型(一)关联到模型(多)的某个字段)
One2many(一对多)关联场景中,如何从模型(一)关联到模型(多)的某个字段
好的,我们用一个更通俗的例子来解释不同模块之间的模型关联,场景是“学校和学生”的例子。 1. 场景介绍 假设我们有两个模块: 学校模块 (school):用于管理学校信息。学生模块 (student):用于管理学生信息。 每个学…...

LLaMA 3 和 OpenAI有哪些相同点和不同点?
LLaMA 3(Meta 的 LLaMA 系列)和 OpenAI 的模型(如 GPT 系列)都是先进的 大语言模型(LLMs),它们在训练、应用场景和能力上有很多相似之处,但也存在显著的不同点。以下是一些关键相同点…...

Spring 事务管理及失效总结
所谓事务管理,其实就是“按照给定的事务规则来执行提交或者回滚操作”。 Spring 并不直接管理事务,而是提供了多种事务管理器,他们将事务管理的职责委托给 Hibernate 或者 JTA 等持久化机制所提供的相关平台框架的事务来实现。 Spring 事务…...

全局思维下的联合创新:华为携手ISV伙伴助推银行核心平稳升级
文 | 螳螂观察 作者 | 李永华 随着数字金融快速发展,对核心系统提出了“海量、高效、弹性、扩展、敏捷”等新需求,区域性银行面临核心系统升级的迫切需要,对金融科技厂商而言也催生了庞大的机遇和空间。 只是,银行核心系统是金…...

深度估计任务中的有监督和无监督训练
在计算机视觉领域,深度估计任务一直是研究的热点之一。它旨在通过图像或视频数据来推断场景中物体与相机之间的距离,为许多应用提供关键信息,如自动驾驶、机器人导航、增强现实等。在深度估计任务中,有监督训练和无监督训练是两种…...

扩散模型DDPM代码实践
安装diffusers pip install diffusers 按照diffusers官方代码 from diffusers import DDPMPipelinepipe DDPMPipeline.from_pretrained("google/ddpm-cat-256")image pipe().images[0]image.save("/data/zhz/projects/diffusion/output/ddpm_generated_imag…...

关于GPIO输入模式的配置选择
GPIO(通用输入输出)口是嵌入式系统中的重要组成部分,输入模式使得微控制器能够与外部世界进行交互。本文将探讨GPIO输入模式中的浮空输入、上拉输入和下拉输入的配置、使用场景及注意事项,并提供一些决策指导,帮助读者…...

【Kubernetes】日志平台EFK+Logstash+Kafka【实战】
一,环境准备 (1)下载镜像包(共3个): elasticsearch-7-12-1.tar.gz fluentd-containerd.tar.gz kibana-7-12-1.tar.gz (2)在node节点导入镜像: ctr -nk8s.io images i…...

今天推荐一个文档管理系统 Dorisoy.Pan
Dorisoy.Pan 是一个基于 .NET 8 和 WebAPI 构建的文档管理系统,它集成了 Autofac、MediatR、JWT、EF Core、MySQL 8.0 和 SQL Server 等技术,以实现一个简单、高性能、稳定且安全的解决方案。 这个系统支持多种客户端,包括网站、Android、iO…...

[智能体-42]:深度解读:Python 免编译 + 动态执行,支撑智能体落地大模型决策
一、先厘清核心概念无需编译执行:Python 属于解释型语言,区别于 C/C、Java 编译型语言。编译型语言必须先将源码整体编译成机器码 / 字节码文件,才能运行;Python 无需手动编译,源码可逐行边解析边执行,即时…...

SMGI框架:通用人工智能的结构元模型与实现路径解析
1. 项目概述:从“智能拼图”到“统一蓝图”最近几年,AI领域的热词层出不穷,从大语言模型到多模态,再到通用人工智能(AGI),大家似乎都在朝着同一个方向狂奔,但脚下的路却千差万别。这…...

PXE安装麒麟Kylin后,我用这个脚本搞定了软件源、远程桌面和sudo免密
PXE安装麒麟Kylin后的高效配置脚本实战指南当你通过PXE完成麒麟Kylin系统的无人值守安装后,系统往往处于"毛坯房"状态——基础框架有了,但离真正的生产环境还有距离。本文将分享一个名为.kylin-post-actions的神奇脚本,它能帮你一键…...

遥感因果分析:多尺度表征拼接技术解析与工程实践
1. 项目概述:从“看”到“理解”的遥感因果分析新思路在遥感图像分析领域,我们早已不满足于仅仅“看到”地物。从土地利用分类到灾害评估,核心目标正从“是什么”转向“为什么”和“会怎样”。比如,我们不仅想知道某片区域是农田&…...

BL51链接器段名通配符使用技巧与工程实践
1. BL51链接器中段名通配符使用指南作为一名从事8051嵌入式开发十余年的老工程师,我经常需要处理代码段的精细布局问题。今天要分享的是BL51链接器中一个非常实用但容易被忽视的功能——段名通配符匹配。这个功能在项目代码量较大时尤其有用,能显著提升链…...

FlexHEG:AI硬件加速器的自动化保障验证框架
1. FlexHEG技术体系概述FlexHEG(Flexible Hardware-Enabled Guarantees)是一套为AI硬件加速器设计的自动化保障验证框架。这个技术体系的核心目标是通过硬件和软件的协同设计,实现对AI计算工作负载的实时监控和策略合规性验证。在当前AI技术快…...

Godot PCK文件解包:原理、工具与工程化实践指南
1. 为什么“解包PCK”不是技术炫技,而是实际工作刚需在Godot引擎生态里,“PCK文件”这三个字母背后藏着的不是冷冰板的二进制容器,而是一整套游戏交付逻辑的终点与逆向理解的起点。我第一次真正意识到这点,是在接手一个外包美术团…...
)
别再只盯着MSE了!用Python实战对比5大回归评估指标(附避坑指南)
别再只盯着MSE了!用Python实战对比5大回归评估指标(附避坑指南)当你的回归模型在测试集上表现不佳时,第一个浮现在脑海的问题往往是:"该用哪个指标来评估才最合理?"这个问题远比想象中复杂——我…...
)
告别双系统!用WSL2+Ubuntu20.04+ROS Noetic,在Windows上丝滑运行AirSim仿真(保姆级避坑指南)
在Windows上构建WSL2ROSAirSim一体化仿真环境:从零避坑到实战 对于机器人开发者而言,跨平台仿真环境的搭建往往意味着无尽的配置噩梦。当我在研究生课题中首次尝试将AirSim与ROS联调时,经历了整整两周的黑暗时期——双系统切换导致工作流断裂…...

荣耀出征官方下载地址|装备绑定与非绑定决策分析
认准奇迹mu:荣耀出征官方直营官网主站与认证入口体验正版游戏(资质可查,安全合规)《奇迹mu:荣耀出征》是合规申报的移动类型经典复刻怀旧奇迹mu手游,已经在《奇迹mu:荣耀出征》官网主站首发上线。游戏高度还…...