Elasticsearch深度攻略:核心概念与实践应用
目录
- 一、Elasticsearch简介
- 1、Elasticsearch是什么
- 2、Elasticsearch的应用场景
- 3、Elasticsearch的核心概念
- 二、Elasticsearch安装与配置
- 1、安装Elasticsearch
- (1)系统要求
- (2)下载Elasticsearch
- (3)解压安装包
- (4)配置环境变量(可选)
- (5)运行Elasticsearch
- (6)配置Elasticsearch
- (7)设置Java虚拟机参数
- (8)设置文件描述符和线程数
- (9)启动和停止服务
- (10)确保防火墙和Selinux设置正确
- 2、配置Elasticsearch
- (1)配置文件概述
- (2)集群和节点配置
- 集群名称(cluster.name)
- 节点名称(node.name)
- (3)网络配置
- 绑定主机(network.host)
- HTTP端口(http.port)
- 发现和通信(discovery.seed_hosts)
- (4)数据和日志存储
- 数据路径(path.data)
- 日志路径(path.logs)
- (5)内存和垃圾回收
- 堆内存大小(heap.size)
- 垃圾回收策略(gc策略)
- (6)文件描述符和线程数
- 文件描述符限制
- 线程数限制
- (7)安全和认证
- 开启X-Pack安全功能
- 用户认证和角色授权
- (8)监控和性能调优
- 监控设置
- 性能调优
- 3、运行和监控Elasticsearch
- (1)启动和停止Elasticsearch
- 启动Elasticsearch
- 停止Elasticsearch
- (2)监控Elasticsearch
- 使用Elasticsearch-head插件
- 使用Kibana
- 使用Elasticsearch API
- X-Pack监控
- (3)性能监控和故障排除
- 监控JVM性能
- 监控磁盘I/O
- 故障排除
- 三、Elasticsearch索引操作
- 1、创建索引
- 创建索引的基本步骤
- 索引配置
- 设置分片和副本
- 设置索引映射
- 索引模板
- 注意事项
- 2、索引文档
- 索引文档的基本步骤
- 3、索引管理
- 索引的创建与更新
- 索引的删除
- 索引的模板
- 索引的监控
- 索引的优化
- 索引的快照与恢复
- 四、Elasticsearch搜索功能
- 1、基本搜索
- 查询字符串语法
- 常用的查询类型
- 执行搜索操作
- 搜索结果解析
- 2、高级搜索
- (1)查询表达式(Query DSL)
- (2)全文搜索与短语搜索
- (3)模糊匹配与正则表达式
- (4)嵌套文档搜索
- (5)脚本查询
- (6)搜索建议
- 3、聚合分析
- (1)聚合分析概述
- (2)桶聚合
- (3)度量聚合
- (4)复合聚合
- (5)聚合分析的最佳实践
- 五、Elasticsearch集群管理
- 1、集群架构
- 集群的基本组成
- 节点角色
- 分片和副本
- 集群发现和选举
- 集群健康
- 集群扩展
- 2、集群监控
- (1)集群健康检查
- (2)节点监控
- (3)分片和副本监控
- (4)性能监控
- (5)日志和错误报告
- (6)监控工具和插件
- (7)集群监控实践
- 3、集群扩展
- (1)垂直扩展
- (2)水平扩展
- (3)集群扩展实践
- (4)扩展工具和策略
- (5)扩展的挑战和解决方案
一、Elasticsearch简介
1、Elasticsearch是什么
Elasticsearch(简称ES)是一个基于Lucene构建的开源搜索引擎,它提供了一个分布式、RESTful的搜索和分析引擎,适用于处理大量的数据。Elasticsearch以其高性能、可扩展性和易于使用而著称,被广泛应用于全文搜索、日志分析、实时监控等领域。
以下是关于Elasticsearch的几个关键特性:
(1)全文搜索
Elasticsearch的核心功能之一是全文搜索。全文搜索是指对文本数据进行索引,并能够根据用户的查询需求快速返回匹配的结果。它支持复杂的查询语法,包括布尔运算、模糊匹配、短语搜索等,使得用户能够轻松地检索到相关信息。
(2)分布式架构
Elasticsearch是一个分布式系统,这意味着它可以横向扩展,支持大规模的数据处理。它将数据分布在多个节点上,通过集群的方式提供高可用性和容错能力。当一个新的节点加入集群时,Elasticsearch会自动重新平衡数据,确保数据均匀分布在所有节点上。
(3)RESTful API
Elasticsearch提供了一个简单易用的RESTful API,用户可以通过HTTP请求与Elasticsearch进行交互。这些API包括索引、搜索、更新、删除等操作,使得用户能够轻松地管理和操作数据。
(4)可扩展性
Elasticsearch支持数据的实时索引和搜索,同时也能够处理大量的数据。它支持水平扩展,即通过增加更多的节点来提高性能和存储容量。此外,Elasticsearch还支持多种类型的数据,包括文本、数字、日期等。
(5)丰富的功能
除了基本的搜索功能,Elasticsearch还提供了许多高级功能,如:
- 聚合分析:Elasticsearch能够对数据进行聚合分析,提供数据的统计信息,如总和、平均值、最大值、最小值等。
- 映射和索引模式:Elasticsearch允许用户定义映射,以控制如何索引和存储数据。同时,它支持索引模式,允许用户对多个索引执行相同的操作。
- 动态映射:Elasticsearch可以根据数据类型自动创建映射,简化了数据索引的过程。
- 安全性:Elasticsearch提供了内置的安全功能,包括用户认证、角色授权和加密通信等。
(6)生态系统
Elasticsearch拥有一个庞大的生态系统,包括Kibana、Beats、Logstash等工具。这些工具与Elasticsearch紧密集成,提供了更加丰富的功能和更好的用户体验。
Kibana是一个开源的分析和可视化工具,它允许用户轻松地创建和管理Elasticsearch索引,并对数据进行可视化展示。Beats是一组轻量级的数据收集器,用于收集和发送数据到Elasticsearch。Logstash是一个强大的数据处理管道,它能够同时从多个来源采集数据,转换数据,然后将数据发送到Elasticsearch。
总之,Elasticsearch是一个功能强大、易于使用且高度可扩展的搜索引擎,它为用户提供了快速、高效的数据检索和分析能力。无论是在企业级应用还是个人项目中,Elasticsearch都展现出了其强大的价值和潜力。
2、Elasticsearch的应用场景
Elasticsearch作为一种强大的搜索引擎,其应用场景广泛,涵盖了大数据处理、日志分析、实时监控、搜索引擎等多个领域。以下是Elasticsearch的一些主要应用场景:
- 全文搜索引擎
Elasticsearch最初的设计目的是作为一个全文搜索引擎,它可以快速地检索文本数据,并支持复杂的查询语法。以下是一些具体的应用案例:
- 网站搜索:Elasticsearch可以用于构建网站内部的搜索功能,如电商平台的商品搜索、新闻网站的新闻搜索等,提供快速、准确的搜索结果。
- 文档搜索:对于文档管理系统,Elasticsearch能够帮助用户快速定位到所需的文档支持关键词搜索、短语搜索等多种查询方式。
- 日志数据分析
Elasticsearch经常与Logstash和Kibana结合使用形成ELK栈,用于日志数据的收集、处理和可视化。以下是一些应用案例:
- 系统监控:通过收集系统日志,Elasticsearch可以实时监控系统的运行状态,如CPU使用率、内存使用情况、磁盘I/O等。
- 应用监控:对于应用程序的日志,Elasticsearch可以帮助开发者快速定位问题,分析错误日志,提高应用的稳定性。
- 安全分析:通过分析网络日志,Elasticsearch可以检测异常行为,如入侵尝试、恶意攻击等,从而提高系统的安全性。
- 实时数据分析
Elasticsearch支持数据的实时索引和搜索,这使得它非常适合处理实时数据流。以下是一些应用案例:
- 股票市场分析:Elasticsearch可以实时分析股票市场的数据,提供即时的股票价格趋势、交易量等信息。
- 社交媒体监控:通过实时分析社交媒体上的数据,Elasticsearch可以帮助企业了解用户的情绪、偏好和趋势,从而做出更有效的营销决策。
- 时间序列数据分析
Elasticsearch支持时间序列数据的索引和查询,这使得它成为处理时间敏感数据的有力工具。以下是一些应用案例:
- 物联网(IoT):在物联网领域,Elasticsearch可以处理大量的传感器数据,如温度、湿度、位置等,并支持实时监控和分析。
- 性能监控:对于服务器的性能数据,Elasticsearch可以提供历史的性能趋势分析,帮助管理员优化资源分配。
- 地理信息服务
Elasticsearch支持地理信息数据的索引和搜索,这使得它在地理信息服务领域有着广泛的应用。以下是一些案例:
- 位置搜索:Elasticsearch可以用于搜索附近的餐馆、商店等地理位置信息。
- 地图服务:在地图服务中,Elasticsearch可以提供基于地理位置的,如查找特定区域内的兴趣点。
- 推荐系统
Elasticsearch的聚合分析功能可以用于构建推荐系统,通过分析用户的行为数据,提供个性化的推荐内容。以下是一些应用:
- 电商推荐:基于用户的购买历史和搜索行为,Elasticsearch可以推荐商品。
- 内容推荐:对于新闻或视频平台,Elasticsearch可以根据用户的阅读或观看习惯,推荐相关的文章或视频。
总之,Elasticsearch的应用场景非常多样化,无论是处理文本数据、日志数据,还是实时数据、地理信息数据,它都能够提供高效、灵活的解决方案。随着大数据和实时分析需求的不断增长,Elasticsearch的应用范围将会更加广泛。
3、Elasticsearch的核心概念
Elasticsearch作为一个分布式、RESTful搜索和分析引擎,拥有一系列核心概念,这些概念是理解和运用Elasticsearch的基础。以下是Elasticsearch的几个核心概念:
-
节点(Node)和集群(Cluster)
- 节点:Elasticsearch集群中的单个服务器称为节点,每个节点都可以存储数据并且参与集群的索引和搜索功能。
- 集群:由一个或多个节点组成的集合,它们共同工作,共享数据并通过配置文件连接在一起。集群中的节点通过相互通信来保持数据的一致性。
-
索引(Index)
- 索引:在Elasticsearch中,索引是数据的集合,类似于关系型数据库中的数据库表。每个索引都有自己的映射(mapping)和设置(settings),这些定义了索引中数据的结构和索引的行为。
- 类型(Type):虽然Elasticsearch 7.x之后已经废弃了类型的概念,但在早期版本中,类型用于索引内部的不同数据类别。例如,一个博客索引可能包含文章和评论两种类型。
- 文档(Document):索引中的数据以JSON文档的形式存储,每个文档都有一个唯一的ID。文档是Elasticsearch中数据的基本单位。
-
分片(Shard)和副本(Replica)
- 分片:为了支持大数据量,Elasticsearch会将索引分成多个分片,每个分片是一个独立的、可搜索的数据子集。分片可以分布在不同的节点上,从而实现数据的分布式存储和查询。
- 副本:每个分片可以有零个或多个副本,副本是分片的一个或多个拷贝。副本用于提供数据的冗余和高可用性,同时可以增加搜索的并发能力。
-
映射(Mapping)和设置(Settings)
- 映射:映射定义了索引中字段的名称、类型和属性。它类似于关系型数据库中的列定义。映射确保了数据的一致性和正确性。
- 设置:设置定义了索引的配置参数,如分片和副本的数量、索引的更新策略等。这些设置在索引创建时指定,并且在索引的生命周期内很少更改。
-
RESTful API
- RESTful API:Elasticsearch通过HTTP协议和JSON格式提供RESTful API,用户可以通过这些API进行索引的创建、文档的索引和搜索等操作。这些API是Elasticsearch与外界交互的主要方式。
-
倒排索引(Inverted Index)
- 倒排索引:Elasticsearch使用倒排索引来加速搜索操作。倒排索引是一种数据结构,它将文档中的单词映射到包含这些单词的文档列表。这种索引方式使得搜索变得非常快速。
-
分布式搜索
- 分布式搜索:Elasticsearch的搜索操作是分布式的,这意味着一个搜索请求会同时在多个分片上并行执行。Elasticsearch会合并这些分片的结果,并返回最终的搜索结果。
-
聚合(Aggregations)
- 聚合:聚合是Elasticsearch提供的一种强大的数据分析工具,它可以在搜索结果之上提供额外的信息,如总数、平均值、最大值、最小值等。聚合可以看作是SQL中的GROUP BY和聚合函数。
-
管道(Pipeline)
- 管道:Elasticsearch的管道用于在数据被索引之前或之后进行数据处理。例如,可以使用管道来预处理数据、转换数据格式或执行数据清洗。
-
监控和管理工具
- 监控和管理工具:Elasticsearch提供了丰富的监控和管理工具,如Elasticsearch-head、Kibana、Elasticsearch-py等,这些工具可以帮助用户更轻松地管理集群、监控性能和执行日常任务。
通过理解这些核心概念,用户可以更好地利用Elasticsearch的强大功能,构建高效、可扩展的搜索和数据分析解决方案。掌握这些概念是深入学习Elasticsearch和进行实际应用的基础。
二、Elasticsearch安装与配置
1、安装Elasticsearch
Elasticsearch是一款功能强大的开源搜索引擎,它基于Lucene构建,为用户提供了一个快速、稳定、可扩展的搜索解决方案。下面将详细介绍Elasticsearch的安装过程。
(1)系统要求
在安装Elasticsearch之前,需要确保操作系统满足以下要求:
- 操作系统:建议使用Linux操作系统,尤其是Ubuntu、Debian、CentOS等主流发行版。
- Java环境:Elasticsearch是基于Java编写的,因此需要安装Java环境。推荐使用JDK 1.8或更高版本。
- 内存:至少需要2GB的内存,但为了获得更好的性能,建议使用更多的内存。
- 文件系统:推荐使用ext4或XFS文件系统。
(2)下载Elasticsearch
Elasticsearch可以从其官方网站(https://www.elastic.co/cn/elasticsearch)下载。选择适合操作系统的版本,这里以Linux版本为例:
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.10.1-linux-x86_64.tar.gz
(3)解压安装包
下载完成后,tar命令解压安装包:
tar -xvf elasticsearch-7.10.1-linux-x86_64.tar.gz
解压后,会得到一个名为elasticsearch-7.10.1的文件夹。
(4)配置环境变量(可选)
为了方便后续操作,Elasticsearch的安装路径添加到环境变量中:
echo \export ES_HOME=/path/to/elasticsearch-7.10.1\ >> /etc/profile
echo \export PATH=$PATH:$ES_HOME/bin\ >> /etc/profile
source /etc/profile
(5)运行Elasticsearch
在Elasticsearch的根目录下,运行以下命令启动Elasticsearch:
./bin/elasticsearch
启动后,可以通过访问http://localhost:9200/来检查Elasticsearch是否成功启动。
(6)配置Elasticsearch
Elasticsearch的配置文件位于config/elasticsearch.yml。以下是一些常见的配置项:
- cluster.name:设置集群名称,默认为\elasticsearch\。
- node.name:设置节点名称,默认为随机生成的名称。
- path.data:设置数据存储路径,默认为
/usr/share/elasticsearch/data。 - path.logs:设置日志存储路径,默认为/usr/share/elasticsearch/logs`。
- network.host:设置节点绑定的主机地址,默认为
localhost。 - http.port:设置HTTP服务的端口,默认为9200。
根据实际需求,可以修改这些配置项。
(7)设置Java虚拟机参数
为了确保Elasticsearch能够高效运行,需要设置合适的Java虚拟机参数。在config/jvm.options文件中,可以调整以下参数:
- -Xms:设置堆内存的初始大小。
- -Xmx:设置堆内存的最大。
建议将这两个参数设置为与物理内存一致。
(8)设置文件描述符和线程数
为了提高Elasticsearch的性能,可能需要调整操作系统的文件描述符和线程数限制。这可以通过编辑/etc/security/limits.conf文件来实现:
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096
(9)启动和停止服务
Elasticsearch可以通过以下命令启动和停止:
./bin/elasticsearch -d # 后台启动
./bin/elasticsearch # 前台启动
./bin/elasticsearch -X stop # 停止服务
(10)确保防火墙和Selinux设置正确
如果服务器开启了防火墙或Selinux,需要确保相应的端口(如9200和9300)被允许,并且Selinux处于允许状态。
通过以上步骤,Elasticsearch就可以成功并运行了。接下来,您可以根据实际需求进行进一步的配置和优化。
2、配置Elasticsearch
在成功安装Elasticsearch之后,对其进行适当的配置是确保系统稳定、高效运行的关键步骤。以下是详细讲解Elasticsearch配置的各个方面。
(1)配置文件概述
Elasticsearch的主要配置文件是位于config目录下的elasticsearch.yml。这个文件包含了Elasticsearch运行所需的各种设置,包括集群名称、节点名称、网络设置、索引存储路径等。
(2)集群和节点配置
集群名称(cluster.name)
集群名称用于识别Elasticsearch集群。默认情况下,集群名称为elasticsearch。如果您的环境中存在多个Elasticsearch集群,建议为每个集群设置不同的名称,以避免混淆:
cluster.name: my-elasticsearch-cluster
节点名称(node.name)
节点名称是Elasticsearch集群中每个节点的唯一标识。如果不指定,Elasticsearch会自动生成一个名称。在生产环境中,建议明确指定节点名称:
node.name: node-1
(3)网络配置
绑定主机(network.host)
指定Elasticsearch节点应该绑定到哪个主机地址。默认情况下,它绑定到localhost,这意味着它只能在本地机器上访问。在生产环境中,您需要将其设置为可访问的IP地址或主机名:
network.host: 192.168.1.10
HTTP端口(http.port)
Elasticsearch通过HTTP端口提供REST API服务。默认端口是9200,可以根据需要修改:
http.port: 9200
发现和通信(discovery.seed_hosts)
在集群环境中,节点需要知道其他节点的主机地址以进行通信。可以通过指定一组主机地址来实现:
discovery.seed_hosts:- 192.168.1.10:9300- 192.168.1.11:9300- 192.168.1.12:9300
(4)数据和日志存储
数据路径(path.data)
指定Elasticsearch存储索引数据的路径。可以设置多个路径,以实现数据分片存储:
path.data: /var/data/elasticsearch
日志路径(path.logs)
指定Elasticsearch存储日志文件的路径:
path.logs: /var/log/elasticsearch
(5)内存和垃圾回收
堆内存大小(heap.size)
Elasticsearch是基于Java的,因此需要设置堆内存大小。建议将堆内存大小设置为物理内存的一半:
heap.size: 16g
垃圾回收策略(gc策略)
为了减少垃圾回收对性能的影响,可以设置垃圾回收策略。Elasticsearch推荐使用G1垃圾回收器:
ES_JAVA_OPTS=\Xms16g -Xmx16g -XX:+UseG1GC\`
(6)文件描述符和线程数
文件描述符限制
Elasticsearch在处理大量并发请求时,可能会消耗大量的文件描述符。为了防止系统限制导致的问题,需要调整文件描述符的限制:
* soft nofile 65536
* hard nofile 65536
线程数限制
同样,Elasticsearch可能会使用大量的线程。确保系统线程数限制足够高:
* soft nproc 4096
* hard nproc 4096
(7)安全和认证
开启X-Pack安全功能
X-Pack是Elasticsearch的安全框架,提供了加密通信、用户认证、角色授权等功能。在生产环境中,建议启用X-Pack安全功能:
xpack.security.enabled: true
用户认证和角色授权
配置用户认证和角色授权,确保只有授权用户才能访问Elasticsearch:
xpack.security.user:elastic:password: \your_password\ kibana:password: \your_password\`
(8)监控和性能调优
监控设置
Elasticsearch提供了丰富的监控指标,可以通过以下设置启用监控:
xpack.monitoring.enabled: true
性能调优
根据具体的使用场景和硬件资源,可以对Elasticsearch进行性能调优。这可能包括调整缓存大小、合并策略、索引刷新间隔等。
通过以上配置,可以确保Elasticsearch在您的环境中以最佳状态运行。不过,需要注意的是,每个环境都是独特的,因此建议根据实际情况调整配置,并在生产环境中进行充分的测试。
3、运行和监控Elasticsearch
在成功安装并配置了Elasticsearch之后,下一步是确保其正常运行并进行有效监控。以下是关于如何运行Elasticsearch以及如何监控其性能和健康状况的详细指南。
(1)启动和停止Elasticsearch
首先,让我们了解如何启动和停止Elasticsearch服务。
启动Elasticsearch
在命令行中,进入Elasticsearch的安装目录,然后执行以下命令:
./bin/elasticsearch
如果一切正常,Elasticsearch将启动,并在控制台输出启动日志。您也可以通过以下命令检查服务状态:
./bin/elasticsearch -p
停止Elasticsearch
要停止Elasticsearch服务,您可以找到Elasticsearch的进程ID,并使用kill命令来终止它:
kill -9 `cat pid`
或者,如果您使用的是服务管理器(如systemd),可以使用以下命令:
sudo systemctl stop elasticsearch
(2)监控Elasticsearch
监控Elasticsearch是确保其稳定运行的关键。以下是一些常用的监控工具和方法。
使用Elasticsearch-head插件
elasticsearch-head是一个用于监控Elasticsearch集群状态和索引的Web界面插件。您可以通过以下命令安装它:
./bin/elasticsearch-plugin install file:///path/to/elasticsearch-head.zip
安装后,您可以通过浏览器访问http://localhost:9100来查看集群状态。
使用Kibana
Kibana是Elastic Stack的一部分,提供了一个强大的用户界面来监控和管理Elasticsearch集群。您可以通过以下步骤在Kibana中设置监控:
- 打开Kibana。
- 转到“管理”页面。
- 选择“Elasticsearch”部分。
- 在“监控”选项卡中,您可以查看集群的健康状况、性能指标、节点信息等。
使用Elasticsearch API
Elasticsearch提供了丰富的REST API,可以用来监控集群状态、节点状态、索引性能等。以下是一些常用的API:
- 集群健康:
GET /_cluster/health - 节点信息:
GET /_nodes - 索引性能:
GET /_cat/indices?v&h=i,tm,mx,md
您可以使用curl或任何支持HTTP请求的工具来访问这些API。
X-Pack监控
X-Pack是Elastic Stack的一部分,提供了监控功能。要启用X-Pack监控,您需要在elasticsearch.yml配置文件中设置以下参数:
xpack.monitoring.enabled: true
然后,您可以在Kibana的监控页面中查看详细的监控数据。
(3)性能监控和故障排除
监控Elasticsearch的性能对于确保其高效运行至关重要。以下是一些性能监控和故障排除的技巧。
监控JVM性能
Elasticsearch是基于Java的,因此监控JVM性能非常重要。您可以使用以下工具来监控JVM:
jconsole:一个Java GUI监控工具,可以查看JVM的堆内存使用情况、垃圾回收情况等。jstack:一个命令行工具,可以打印出给定Java进程的堆栈跟踪。
监控磁盘I/O
Elasticsearch在处理大量数据时,磁盘I/O可能会成为瓶颈。您可以使用操作系统工具(如iostat)来监控磁盘性能。
故障排除
如果遇到性能问题服务中断,以下是一些故障排除的步骤:
- 检查日志文件:Elasticsearch的日志文件位于
logs目录下。检查elasticsearch.log文件以查找错误和警告信息。 - 分析堆转储:如果Elasticsearch发生堆溢出错误,您可以使用
jstack和heapdump工具来分析堆转储文件。 - 使用Elasticsearch-head或Kibana来检查集群状态和索引健康状况。
通过以上方法,您可以确保Elasticsearch在您的环境中以最佳状态运行,并及时发现并解决潜在的问题。监控和故障排除是维护Elasticsearch集群健康和性能的关键环节。
三、Elasticsearch索引操作
1、创建索引
在Elasticsearch中,索引是数据存储和检索的基础。创建索引是使用Elasticsearch进行数据操作的第一步。下面我们将详细介绍如何创建索引,以及创建索引时需要考虑的各个方面。
创建索引的基本步骤
创建索引的基本步骤非常简单,您可以通过REST API来完成。以下是一个使用curl命令创建索引的例子:
curl -X PUT \localhost:9200/your_index\ -H 'Content-Type: application/json' -d'
{\settings\ {\number_of_shards\ 1,umber_of_replicas\ 0},\mappings\ {\properties\ {\field1\ { \type\ \text\ },\field2\ { \type\ \date\ }}}
}'
在这个例子中,your_index是您要创建的索引的名称。以下是该命令中各个部分的解释:
-X PUT:指定HTTP方法为PUT,因为创建索引相当于在服务器上创建资源。localhost:9200/your_index:指定Elasticsearch服务器的地址和索引名称。-H 'Content-Type: application/json':设置请求头,告诉服务器我们发送的是JSON格式的数据。-d'...%':包含创建索引时需要的JSON数据体。
索引配置
在创建索引时,您可以对索引进行配置,这些配置将影响索引的性能和存储。
设置分片和副本
每个索引由一个或多个分片组成,分片是数据分布和负载均衡的基本单元。副本是分片的副本,用于提供数据冗余和增加读取能力。
number_of_shards:指定索引的分片数量。默认值为5,但您可以根据数据量和硬件资源进行调整。number_of_replicas:指定每个分片的副本数量。默认值为1,但在生产环境中,通常会设置为更高的值以提高数据的可用性。
设置索引映射
索引映射定义了索引中字段的名称、类型和属性。映射对于确保数据的一致性和正确索引非常重要。
properties:映射中的属性定义了字段的数据类型,如text、date、integer等。- 字段类型:每个字段都需要指定一个类型,例如,文本数据通常使用
text类型,日期数据使用date类型。
索引模板
如果您经常需要创建具有相似配置的索引,可以使用索引模板来自动化这一过程。索引模板包含索引配置和映射,当您创建新索引时,Elasticsearch会自动应用这些模板。
以下是一个创建索引模板的例子:
curl -X PUT \localhost:9200/_template/template_1\ -H 'Content-Type: application/json' -d'
{\index_patterns\ [\your_index*\ \settings\ {umber_of_shards\ 1,umber_of_replicas\ 0},\mappings\ {\properties\ {\field1\ { \type\ \text\ },\field2\ { \type\ \date\ }}}
}'
在这个例子中,template_1是模板的名称,your_index*是匹配索引名称的模式。当您创建以your_index开头的索引时,Elasticsearch将自动应用这个模板。
注意事项
在创建索引时,以下是一些需要注意的事项:
- 一旦索引创建,其配置和映射通常不可更改。如果需要修改,可能需要重新创建索引。
- 索引名称必须全部小写,不能包含空格、逗号、冒号等特殊字符。
- 考虑索引的存储和性能需求,合理配置分片和副本数量。
通过正确创建和配置索引,您可以为Elasticsearch中的数据存储和检索打下坚实的基础。创建索引是Elasticsearch数据管理的关键步骤,理解其原理和最佳实践对于构建高效、可扩展的搜索解决方案至关重要。
2、索引文档
在Elasticsearch中,索引文档是构建搜索功能的核心步骤之一。文档是Elasticsearch中的基本数据单位,它通常代表了一个实体或对象。下面我们将详细介绍如何索引文档,以及在这个过程中需要注意的关键点。
索引文档的基本步骤
索引文档通常涉及步骤:
- 创建文档:将数据以JSON格式发送到Elasticsearch。
- 指定文档ID:可选地指定文档的唯一标识符。
- 发送请求:使用HTTP请求将文档发送到Elasticsearch集群。
以下是一个使用curl命令索引文档的:
curl -X POST \\localhost9200/your_index/_doc/1\\ -H 'Content-Type: application/json' -d'
{\field1\value1\ \field2\ \value2\ \field3\ \value3\`在这个例子中,`your_index`是索引名称,`1`是文档ID,`field1`、`field2`和`field3`是文档的字段,而`value1`、`value2`和`value3`是对应的值。#### 指定ID当您索引文档时,可以指定一个唯一的文档ID。未指定ID,Elasticsearch会自动生成一个。指定ID的好处是您可以确保文档的唯一性,并可以在后续操作中通过该ID检索或更新文档。- 如果指定了ID且该ID已存在,Elasticsearch将更新该文档。
- 如果ID不存在,Elasticsearch将创建一个新文档。#### 自动生成文档ID如果不指定文档ID,Elasticsearch会自动生成一个UUID作为文档ID。这适用于大多数场景,尤其是当您不需要手动管理文档ID时。#### 文档类型在Elasticsearch 7.x及之前的版本,文档类型是一个重要的概念,但自Elasticsearch 7.x之后,文档类型被弃用,并在8.x中被移除。现在,所有的文档都存储在同一个类型中,即默认的`_doc`类型。#### 文档元数据每个索引的文档都包含一些元数据,这些元数据对Elasticsearch的操作至关重要:- `_index`:文档所属的索引名称。
- `_type`:文档类型,现在默认为`_doc`。
- `_id`:文档的唯一标识符。
- `_source`:原始JSON文档内容。
- `_version`:文档的版本号,每次更新文档时都会增加。#### 索引文档的注意事项在索引文档时,以下是一些需要注意的关键点:1. **文档结构**:确保文档中的字段和类型与索引的映射相匹配,否则可能导致索引失败或数据不一致。2. **批量操作**:如果需要索引大量文档,可以使用`_bulk` API进行批量操作,效率和性能。```bash
curl -X POST \\localhost:9200/your_index/_\\ -H 'Content-Type: application/json' -d'
{ \index\ : { \id\ : \1\ } }
{ \field1\ \value1\ \field2\ \value2\ }
{ \index\ : { \id\ : \2\ } }
{ \field1\ \value3\ \field2\ \value4\ }'
-
错误处理:在索引文档时,应该检查响应以确保操作成功。如果发生错误,应该记录错误信息并进行相应的处理。
-
性能优化:对于高吞吐量的场景,考虑使用索引优化策略,如调整刷新间隔、增加缓存等。
-
数据一致性:在分布式环境中,确保索引操作的一致性和原子性非常重要。
通过正确地索引文档,您可以确保数据在Elasticsearch中高效、一致地存储,从而为后续的搜索和聚合操作打下坚实的基础。理解和掌握索引文档的细节对于构建高效、可靠的Elasticsearch应用程序至关重要。
3、索引管理
在Elasticsearch中,索引管理是确保数据高效存储和的关键环节。一个良好的索引管理策略可以提升性能、优化资源使用,并确保数据的安全性和一致性。以下是关于Elasticsearch索引管理的详细探讨。
索引的创建与更新
在Elasticsearch中,创建索引通常涉及到定义索引的名称、映射(mapping)和设置(settings)。映射定义了索引中字段的名称和类型,而设置则包括诸如分片数、副本数等配置。
- 创建索引:使用以下命令创建一个新索引:
curl -X PUT \localhost:9200/your_index\ -H 'Content-Type: application/json' -d'
{\settings\ {\number_of_shards\ 3,\number_of_replicas\ 1},\mappings\ {\properties\ {\field1\ { \type\ \text\ },\field2\ { \type\ \date\ },\field3\ { \\ \integer\ }}}
}'
- 更新索引:一旦索引创建,其设置和映射通常是不可变的。但如果确实需要更新,可以使用
_updateAPI进行部分更新。
索引的删除
当索引不再需要时,可以将其删除以释放资源。删除索引是一个简单的操作,但需要谨慎进行,因为删除后数据将无法恢复。
curl -X DELETE \localhost:9200/your_index\`#### 索引的别名使用别名可以为索引提供一个简化的名称,或者将多个索引聚合为一个逻辑名称。别名对于切换索引、无缝升级等操作非常有用。- **创建别名**:```bash
curl -X POST \localhost:9200/_aliases\ -H 'Content-Type: application/json' -d'
{\actions\ [{ \add\ { \index\ \your_index\ \alias\ \your_alias\ } }]
}'
- 删除别名:
curl -X POST \localhost:9200/_aliases\ -H 'Content-Type: application/json' -d'
{\actions\ [{ \remove\ { \index\ \your_index\ \alias\ \your_alias\ } }]
}'
索引的模板
索引模板允许您为自动创建的索引预定义设置和映射。当您创建一个新的索引时,Elasticsearch会查找匹配的模板并应用其设置和映射。
- 创建索引模板:
curl -X PUT \localhost:9200/_template/template_1\ -H 'Content-Type: application/json' -d'
{\index_patterns\ [\your_index*\ \settings\ {umber_of_shards\ 1},\m\ {\properties\ {\field1\ { \type\ \text\ }}}
}'
索引的监控
监控索引的健康状况和性能对于维护Elasticsearch集群至关重要。以下是一些监控索引的方法:
- 查看索引信息:
curl -X GET \localhost:9200/_cat/indices?v&h=i,health,status,docs.count,docs.deleted,store.size\`
- 分析索引性能:
curl -X GET \localhost:9200/_stats store,search?pretty\`
索引的优化
索引优化是一个减少索引大小、提高搜索效率的过程。优化操作通常包括合并分段和清除不必要的分段。
- 优化索引:
curl -X POST \localhost:9200/your_index/_optimize\`在进行优化时,需要注意以下几点:- 优化可能会消耗大量资源,因此最好在低峰时段进行。
- 优化操作会触发刷新,这可能会导致短暂的搜索延迟。
- 优化后的索引可能需要一些时间来恢复性能。
索引的快照与恢复
为了防止数据丢失,建议定期创建索引的快照。快照可以存储在远程存储服务上,如AWS S3或Google Cloud Storage。
- 创建快照:
curl -X PUT \localhost:9200/_snapshot/your_snapshot_repository/your_snapshot\`
- 恢复快照:
curl -X POST \localhost:9200/_snapshot/your_snapshot_repository/your_snapshot/_restore\`
通过有效的索引管理,您可以确保Elasticsearch集群的稳定性和高效性。正确的索引策略不仅可以提升搜索性能,还可以降低维护成本,并数据的可靠性和安全性。
四、Elasticsearch搜索功能
1、基本搜索
Elasticsearch的核心功能之一是其强大的搜索能力。在本节中,我们将深入探讨Elasticsearch的基本搜索功能,包括查询字符串语法、常用的查询类型以及如何执行搜索操作。
查询字符串语法
Elasticsearch使用一种称为查询字符串(Query String)语法的特殊语法来执行搜索。这种语法允许用户使用简单的文本字符串进行复杂搜索,包括布尔运算符、括号和字段限定符。
- 布尔运算符:AND、OR和NOT用于组合多个查询条件。例如,`\Elasticsearch AND Kibana\将返回包含这两个词的文档。
- 括号:用于定义查询条件的优先级。例如,
\Elasticsearch AND (Kibana OR Logstash)\将返回包含\lasticsearch\和\Kibana\或\Logstash\的文档。 - 字段限定符:允许您指定查询应该针对特定字段进行。例如,`\title:Elasticsearch\将只在\字段中搜索\lasticsearch\。
常用的查询类型
Elasticsearch提供了多种查询类型,以满足不同的搜索需求。以下是一些常用的查询类型:
- Match查询:最常用的查询类型之一,它会在指定的字段中查找与提供的查询字符串匹配的文档。
{\query\ {\match\ {\field_name\ \query_string\ }}
}
- Term查询:与Match查询类似,但Term查询不会分析查询字符串。它适用于精确值搜索,如ID或关键字。
{\query\ {\term\ {\field_name\ \exact_value\ }}
}
- Range查询:用于查找字段值在指定范围内的文档。
{\query\ {\range\ {\field_name\ {\gte\ 10,\lte\ 20}}}
}
- Boolean查询:允许组合多个查询条件,并定义它们之间的关系(如must、should、must_not)。
{\query\ {\bool\ {\must\ [{ \match\ { \field1\ \value1\ } },{ \match\ { \field2\ \value2\ } }],\should\ [{ \match\ { \field3\ \value3\ } }],\minimum_should_match\ 1}}
}
执行搜索操作
在Elasticsearch中执行搜索操作通常涉及到发送一个HTTP GET请求到/index_name/_search端点,并传递查询参数。以下是一个基本的搜索请求示例:
curl -X GET \localhost:9200/your_index/_search?pretty\ -H 'Content-Type: application/json' -d'
{\query\ {\match\ {\field_name\ \query_string\ }}
}'
在这个例子中,your_index是索引的名称,field_name是您想要搜索的字段,而query_string是您想要搜索的文本。
搜索结果解析
执行搜索操作后,Elasticsearch会返回一个JSON格式的响应,其中包含以下关键信息:
- 命中数(hits):匹配查询条件的文档总数。
- 最大得分(max_score):所有匹配文档中得分最高的文档的得分。
- 文档列表:匹配查询条件的文档列表,每个文档包含其字段值和元数据。
{\hits\ {\total\ {\value\ 10,\relation\ \eq\ },\max_score\ 1.0,\hits\ [{\index\ \your_index\ \type\ \doc\ \id\ \1\ \score\ 1.0,\source\ {\field1\ \value1\ \field2\ \value2\ }},// ... 其他匹配的文档]}
}
通过理解这些基本搜索概念和操作,您可以开始使用Elasticsearch进行有效的数据检索。这些基本搜索功能是构建更复杂查询和实现高级搜索策略的基础。随着对Elasticsearch搜索机制的深入理解,您将能够为各种应用场景定制搜索解决方案。
2、高级搜索
在了解了Elasticsearch的基本搜索功能之后,我们将进一步探讨其高级搜索特性。这些特性允许我们执行更为复杂和精细的搜索操作,以满足各种高级查询需求。
(1)查询表达式(Query DSL)
Elasticsearch的高级搜索基于查询表达式(Query DSL,Domain Specific Language),这是一种灵活且强大的查询语言,它允许用户构建复杂的查询。
- Query Clause:查询子句,用于指定搜索条件。
- Filter Clause:过滤子句,用于排除不相关的文档,但不会影响文档的得分。
- Sort Clause:排序子句,用于指定搜索结果的排序方式。
以下是一个使用Query DSL的示例:
{\\query\\ {\\bool\\ {\\must\\ { \\match\\ { \\field1\\ \\value1\\ } },\\filter\\ { \\range\\ { \\field2\\ { \\gte\\ 10, \\lte\\ 20\\ } } },\\sort\\ [{ \\field3\\ \\{ \\order\\ desc\\ } },{ \\_score\\ \\{ \\order\\ desc\\ } }]}}
}
在这个例子中,我们使用了布尔查询来组合多个查询和过滤条件,并指定了排序规则。
(2)全文搜索与短语搜索
Elasticsearch的全文搜索能力是其最强大的特性之一。它不仅能够搜索单个单词,还能够理解单词之间的关系,执行短语搜索和近义词处理。
- 全文搜索:默认情况下,Elasticsearch会对字段进行分词(Tokenization),然后搜索这些分词。
{\\query\\ {\\match\\ {\\content\\ \Elasticsearch is a search engine\ }}
}
- 短语搜索:使用
match_phrase查询来搜索精确的短语。
{\\query\\ {\\match_phrase\\ {\\content\\ \Elasticsearch search engine\ }}
}
(3)模糊匹配与正则表达式
Elasticsearch支持模糊匹配和正则表达式,这使得搜索更加灵活。
- 模糊匹配:使用
fuzzy查询来搜索接近但不完全相同的词。
{\\query\\ {\\fuzzy\\ {\\name\\ {\\value\\ \Elasticseaarch\ \\fuzziness\\ 2}}}
}
在这里,fuzziness参数定义了允许的模糊度。
- 正则表达式:使用
regexp查询来匹配正则表达式。
{\\query\\ {\\regexp\\ {\\username\\ \elasticsearch.*\ }}
}
(4)嵌套文档搜索
在复杂的文档结构中,Elasticsearch支持对嵌套文档的搜索。这在处理如JSON对象数组等复杂数据结构时非常有用。
{\\query\\ {\\bool\\ {\\must\\ {\\nested\\ {\\path\\ \object_field\ \\query\\ {\\match\\ {\\nested_field\\ \\value\\ }}}}}}
}
在这个例子中,我们搜索了嵌套在object_field中的nested_field。
(5)脚本查询
Elasticsearch允许使用脚本查询来执行复杂的逻辑。这可以通过script查询来实现。
{\\query\\ {\\script\\ {\\script\\ {\\source\\ \doc['field'].value > params.threshold\ \\params\\ {\\threshold\\ 100}}}}
}
在这个例子中,我们使用脚本检查field的值是否大于100。
(6)搜索建议
Elasticsearch还提供了搜索建议功能,这可以帮助用户在输入搜索词时获得提示。
{\\suggest\\ {\\text\\ \elast\ \\term\\ {\\field\\
ame\ \\suggest_mode\\ \missing\ }}
}
在这个例子中,如果用户输入\elast\Elasticsearch将提供包含该前缀的单词的建议。
通过这些高级搜索功能,Elasticsearch能够满足各种复杂的搜索需求,无论是全文搜索、短语匹配、模糊查询还是嵌套文档搜索,都为开发者提供了强大的工具来构建高效、灵活的搜索系统。
3、聚合分析
在Elasticsearch中,除了强大的搜索功能外,聚合分析(Aggregations)是另一个令人兴奋的特性。聚合分析允许我们对数据进行分组、统计和计算,从而获得数据的深层洞察。在本节中,我们将详细介绍Elasticsearch的聚合分析功能。
(1)聚合分析概述
聚合分析是Elasticsearch对数据进行统计分析的一种方式,它能够对搜索结果进行分组,并提供关于这些分组的统计信息。聚合分析可以看作是SQL中的GROUP BY和聚合函数的对应功能。
Elasticsearch中的聚合分为两种类型:
- 桶聚合(Bucket Aggregations):用于将文档分组到多个“桶”中,每个桶代表一个分组。
- 度量聚合(Metric Aggregations):用于计算每个桶的统计数据,如平均值、最大值、最小值等。
(2)桶聚合
桶聚合是Elasticsearch中最常见的聚合类型,它允许我们根据特定的字段将文档分组。以下是一些常见的桶聚合类型:
- Terms Aggregation:根据字段中的术语进行分组。
{\size\ 0, // 不返回原始文档\aggs\ {\group_by_state\ {\terms\ {\field\ \state\ \size\ 10 // 返回前10个最常见的状态}}}
}
- Range Aggregation:根据数值范围进行分组。
{\size\ 0,\aggs\ {\group_by_age\ {\range\ {\field\ \age\ \ranges\ [{ \to\ 20 },{ \from\ 20, \to\ 30 },{ \from\ 30, \to\ 40 }]}}}
}
- Histogram Aggregation:基于数值字段的间隔进行分组。
{\size\ 0,\aggs\ {\group_by_price\ {\histogram\ {\field\ \price\ \interval\ 10 // 每10个单位的价格为一个桶}}}
}
- Date Histogram Aggregation:基于日期字段的间隔进行分组。
{\size\ 0,\aggs\ {\group_by_date\ {\date_histogram\ {\field\ \date\ \interval\ \1d\ // 每天为一个桶}}}
}
(3)度量聚合
度量聚合用于计算每个桶的统计数据。以下是一些常见的度量聚合类型:
- Sum Aggregation:计算每个桶的总和。
{\size\ 0,\aggs\ {\group_by_state\ {\terms\ {\field\ \state\ },\aggs\ {\total_price\ {\sum\ {\field\ \price\ }}}}}
}
- Avg Aggregation:计算每个桶的平均值。
{\size\ 0,\aggs\ {\group_by_state\ {\terms\ {\field\ \state\ },\aggs\ {\average_price\ {\avg\ {\field\ \price\ }}}}}
}
- Max/Min Aggregation:计算每个桶的最大值或最小值。
{\size\ 0,\aggs\ {\group_by_state\ {\terms\ {\field\ \state\ },\aggs\ {\max_price\ {\max\ {\field\ \price\ }},\min_price\ {\min\ {\field\ \price\ }}}}}
}
- Stats Aggregation:计算每个桶的统计信息,包括计数、总和、平均值、最大值和最小值。
{\size\ 0,\aggs\ {\group_by_state\ {\terms\ {\field\ \state\ },\aggs\ {\stats_price\ {\stats\ {\field\ \price\ }}}}}
}
(4)复合聚合
Elasticsearch还支持复合聚合,这是一种将多个聚合嵌套在一起以执行更复杂分析的方法。例如,我们可以在一个terms聚合内部嵌套一个date_histogram聚合,以分析每个状态下每天的销售情况。
{\size\ 0,\aggs\ {\group_by_state\ {\terms\ {\field\ \state\ },\aggs\ {\sales_over_time\ {\date_histogram\ {\field\ \date\ \interval\ \1d\ },\aggs\ {\total_sales\ {\sum\ {\field\ \sales\ }}}}}}}
}
通过这种方式,我们可以对数据进行多维度的分析,从而获得更深入的洞察。
(5)聚合分析的最佳实践
在使用Elasticsearch进行聚合分析时,以下是一些最佳实践:
- 限制桶的数量:避免返回过多的桶,因为这可能会导致性能问题。使用
size参数来限制返回的桶的数量。 - 优化查询:在执行聚合分析之前,尽量减少搜索结果的大小,可以通过设置
size参数为0来实现。 - 避免深度嵌套:尽量减少聚合的嵌套深度,因为这可能会影响性能。
- 监控性能:使用Elasticsearch的监控工具来跟踪聚合查询的性能,以便及时发现和解决问题。
通过掌握Elasticsearch的聚合分析功能,我们可以对数据进行深入的分析,从而支持更复杂的业务决策和策略制定。聚合分析是Elasticsearch作为一个企业级搜索引擎不可或缺的一部分,它为用户提供了强大的数据分析能力。
五、Elasticsearch集群管理
1、集群架构
Elasticsearch是一个分布式搜索引擎,其核心在于集群的架构设计。集群架构确保了Elasticsearch的高可用性、可扩展性和容错性。在本节中,我们将深入探讨Elasticsearch集群的架构及其关键组成部分。
集群的基本组成
Elasticsearch集群由多个节点组成,这些节点通过网络相互连接。每个节点都是集群的一部分,并且可以承担不同的角色。以下是集群的基本组成:
- 节点(Node):集群中的每个服务器实例都是一个节点。节点可以存储数据、参与集群的索引和搜索操作。
- 集群(Cluster):由一个或多个节点组成的集合,它们共同工作以提供索引和搜索功能。
- 分片(Shard):索引可以被分割成多个分片,每个分片是一个独立的、可搜索的数据单元。
- 副本(Replica):每个分片的副本,用于提高数据的可用性和容错性。
节点角色
在Elasticsearch集群中,节点可以承担以下角色:
- 主节点(Master Node):负责集群级别的管理任务,如创建索引、分配分片、监控集群健康等。一个集群只能有一个主节点。
- 数据节点(Data Node):负责存储数据、执行数据相关的操作,如索引和搜索。
- 协调节点(Coordinating Node):不存储数据,但负责接收客户端请求,将请求分发到数据节点,并将结果汇总返回给客户端。
- 机器学习节点(Machine Learning Node):专门用于执行机器学习任务,如异常检测和分类。
分片和副本
Elasticsearch的索引由一个或多个分片组成,每个分片是一个独立的Lucene索引。分片可以分布在不同的节点上,以实现负载均衡和数据冗余。
- 主分片(Primary Shard):每个索引创建时都会有一个主分片,负责处理写操作和保证数据的完整性。
- 副本分片(Replica Shard):主分片的副本,用于提高读取性能和数据可用性。副本分片可以处理搜索请求,并在主分片不可用时接管写操作。
Elasticsearch默认为主分片创建一个副本分片,但这个数量可以根据需要进行配置。副本分片的数量通常取决于集群的大小和性能需求。
集群发现和选举
Elasticsearch集群使用一种称为“Zen Discovery”的机制来发现和选举主节点。当一个新的节点加入集群时,它会尝试与其他节点通信,以确定当前的主节点。如果当前没有主节点或者主节点不可用,节点会触发一个选举过程,选出一个新的主节点。
选举过程基于节点的配置信息和集群状态,以确保选举出最合适的节点作为主节点。这个过程是自动的,无需人工干预。
集群健康
Elasticsearch集群的健康状态是集群管理中的一个重要方面。集群健康分为三个级别:绿色(健康)、黄色(警告)和红色(不健康)。
- 绿色:所有主分片和副本分片都正常。
- 黄色:所有主分片正常,但至少有一个副本分片缺失。
- 红色:至少有一个主分片缺失,集群无法保证数据的完整性。
集群管理员可以通过Elasticsearch的REST API来监控集群的健康状态,并采取相应的措施来维护或恢复集群的健康。
集群扩展
Elasticsearch集群可以通过添加更多的节点来进行水平扩展。随着集群规模的增加,管理员需要考虑如何合理分配分片和副本,以保持集群的性能和稳定性。
- 分片分配:Elasticsearch自动管理分片的分配,但管理员可以手动调整分片的分配策略,以优化性能。
- 节点池:通过创建不同角色的节点池,可以更精细地控制节点的工作负载,例如,将数据节点和机器学习节点分开。
通过深入理解Elasticsearch集群的架构,管理员可以更好地管理和优化集群,确保其能够高效、稳定地服务于各种搜索和数据分析任务。集群架构的设计不仅影响了集群的性能,还直接关系到数据的可靠性和安全性。因此,掌握集群架构的细节对于构建和维护一个高效的Elasticsearch环境至关重要。
2、集群监控
在Elasticsearch中,集群监控是确保系统稳定运行和性能优化的关键环节。通过对集群状态的持续监控,管理员可以及时发现并解决潜在的问题,从而保持集群的健康和高效。以下是Elasticsearch集群监控的几个重要方面。
(1)集群健康检查
集群健康是监控的核心内容,它反映了集群的整体运行状况。Elasticsearch提供了一个简单而直观的健康检查机制,通过REST API可以轻松获取集群的健康状态。
- 健康状态指标:集群健康状态分为绿色、黄色和红色三个级别。绿色表示集群完全健康,黄色表示集群有警告,红色则表示集群有问题需要立即解决。
- 健康检查API:通过访问
_cluster/healthAPI,可以获取集群的健康状态信息,包括节点数量、分片状态、副本状态等。
(2)节点监控
集群由多个节点组成,每个节点的状态都会影响集群的整体表现。以下是一些关键的节点监控指标:
- CPU使用率:监控每个节点的CPU使用率,确保没有节点过载。
- 内存使用情况:监控节点内存使用,避免内存溢出或交换空间的使用。
- 磁盘空间:监控数据节点上的磁盘空间,确保有足够的空间存储数据。
- JVM性能:监控JVM性能,包括垃圾回收、堆内存使用等。
Elasticsearch的_nodes API提供了详细的节点状态信息,管理员可以通过这个API来监控节点的实时状态。
(3)分片和副本监控
分片和副本是Elasticsearch集群的核心组成部分,它们的健康状态直接关系到数据的可用性和搜索性能。
- 分片状态:通过
_cat/shardsAPI可以查看所有分片的状态,包括分片的主副情况、分片大小、分片所在节点等。 - 副本状态:副本分片的健康状态尤其重要,因为它们在主分片不可用时可以接管工作。监控副本分片的状态,确保副本数量符合预期。
(4)性能监控
性能监控是集群监控中不可或缺的一环。以下是一些关键的性能监控指标:
- 查询延迟:监控查询的响应时间,确保搜索性能满足需求。
- 吞吐量:监控索引和搜索操作的吞吐量,了解集群的处理能力。
- 并发连接数:监控并发连接数,避免过多并发请求导致资源紧张。
Elasticsearch的_monitoring API可以提供关于集群性能的详细信息。
(5)日志和错误报告
日志是监控集群运行状况的重要资源。Elasticsearch的日志记录了集群的运行信息、错误和警告。以下是一些日志监控的要点:
- 日志级别:Elasticsearch支持不同级别的日志记录,包括DEBUG、INFO、WARN和ERROR。根据需要调整日志级别,以获取适当的日志信息。
- 错误报告:监控错误日志,及时发现并解决潜在的问题。
(6)监控工具和插件
Elasticsearch社区提供了一系列监控工具和插件,以帮助管理员更有效地监控集群:
- Elasticsearch-head:一个浏览器插件,用于可视化集群状态和执行简单的管理任务。
- Elasticsearch-kibana:一个强大的可视化工具,可以与Elasticsearch集群集成,提供更详细的监控数据。
- Elasticsearch-py:一个Python客户端,可以用于编写自定义的监控脚本。
(7)集群监控实践
在实际操作中,管理员应该定期执行以下监控任务:
- 定期检查集群健康:通过
_cluster/healthAPI定期检查集群健康状态。 - 设置告警:使用Elasticsearch的X-Pack或第三方工具设置告警,当集群状态异常时及时收到通知。
- 性能分析:定期分析集群的性能数据,找出瓶颈并优化配置。
- 日志审计:定期审查日志文件,发现并解决潜在的问题。
通过这些监控措施,管理员可以确保Elasticsearch集群的稳定性和高效性,从而为用户提供可靠的数据存储和搜索服务。集群监控不仅是一种被动的问题解决手段,更是一种主动的性能优化策略。通过持续监控和优化,Elasticsearch集群可以更好地适应不断变化的工作负载和业务需求。
3、集群扩展
随着业务的发展,数据量的增长是不可避免的。为了保持Elasticsearch集群的性能和稳定性,集群扩展成为了一个重要的议题。Elasticsearch集群的扩展分为垂直扩展和水平扩展两种方式,下面将详细介绍这两种扩展方法以及如何在实践中进行集群扩展。
(1)垂直扩展
垂直扩展,也称为向上扩展,指的是增加单个节点的资源,如CPU、内存和存储空间。这种扩展方式通常适用于集群规模较小,且资源瓶颈主要集中在单个节点上的情况。
- 内存扩展:增加节点的内存可以提升Elasticsearch的缓存能力,从而提高搜索性能。
- CPU扩展:增加CPU核心数可以提升集群的处理能力,尤其是在处理大量并发请求时。
- 存储扩展:增加存储空间可以容纳更多的数据,但也要注意磁盘I/O性能,避免成为瓶颈。
进行垂直扩展时,需要注意以下几点:
- 兼容性:确保新增的资源与现有硬件兼容。
- 容量规划:合理规划资源容量,避免过度扩展导致资源浪费。
- 性能测试:扩展后进行性能测试,确保新的配置能够满足性能要求。
(2)水平扩展
水平扩展,也称为向外扩展,指的是增加集群中的节点数量。这种扩展方式是Elasticsearch集群扩展的首选,因为它可以线性地增加集群的处理能力和存储容量。
- 节点添加:通过向集群中添加新的节点,可以增加集群的总体资源。
- 分片和副本:Elasticsearch会自动将分片和副本分配到新节点上,从而提高数据可用性和搜索性能。
- 负载均衡:水平扩展有助于分散负载,减少单个节点的压力。
进行水平扩展时,以下是一些关键步骤和注意事项:
- 节点规划:根据业务需求规划新节点的硬件配置和角色(如主节点、数据节点、协调节点等)。
- 网络配置:确保新节点能够与集群中的其他节点进行通信,网络延迟和带宽都会影响集群性能。
- 集群再平衡:添加新节点后,Elasticsearch会自动进行再平衡操作,将分片和副本重新分配到新节点上。
- 监控和调整:扩展后要密切监控集群状态,根据实际情况调整配置。
(3)集群扩展实践
以下是一个集群扩展的实践案例:
- 需求分析:假设我们的业务需求导致数据量每月增长10%,需要增加集群的存储和处理能力。
- 资源评估:评估现有集群的资源使用情况,确定是进行垂直扩展还是水平扩展。
- 扩展计划:制定扩展计划,包括新节点的采购、配置和部署。
- 执行扩展:按照计划执行扩展操作,包括添加新节点、调整分片和副本策略。
- 性能测试:扩展完成后进行性能测试,确保集群能够满足新的业务需求。
- 监控和优化:持续监控集群状态,根据监控结果对集群进行优化。
(4)扩展工具和策略
Elasticsearch提供了一些工具和策略来帮助管理员进行集群扩展:
- Elasticsearch-head:通过Elasticsearch-head插件可以直观地管理集群节点。
- Shard Allocation Awareness:通过配置分片分配感知,可以确保数据在物理位置上更加均匀地分布。
- Index Aliases:使用索引别名可以在不中断服务的情况下无缝地扩展索引。
(5)扩展的挑战和解决方案
集群扩展虽然能够提高性能和容量,但也带来了一些挑战:
- 复杂度增加:随着集群规模的扩大,管理和维护的复杂度也会增加。
- 成本上升:更多的节点意味着更高的硬件和运营成本。
- 数据迁移:在扩展过程中可能需要迁移数据,这可能会影响服务。
针对这些挑战,以下是一些解决方案:
- 自动化管理:使用自动化工具和脚本简化集群管理。
- 成本优化:通过使用更高效的硬件或云服务来优化成本。
- 无停机迁移:使用Elasticsearch的内置功能进行无停机数据迁移。
通过合理规划和实施集群扩展策略,Elasticsearch集群可以有效地应对业务增长带来的挑战,保持高性能和稳定性。集群扩展是一个持续的过程,需要管理员不断地监控、评估和调整,以确保集群能够适应不断变化的业务需求。
相关文章:

Elasticsearch深度攻略:核心概念与实践应用
目录 一、Elasticsearch简介1、Elasticsearch是什么2、Elasticsearch的应用场景3、Elasticsearch的核心概念 二、Elasticsearch安装与配置1、安装Elasticsearch(1)系统要求(2)下载Elasticsearch(3)解压安装…...

TLS详解
什么是TLS TLS(Transport Layer Security)传输层安全性协议 ,它的前身是SSL(Secure Sockets Layer)安全套接层,是一个被应用程序用来在网络中安全的通讯协议, 防止电子邮件、网页、消息以及其他协议被篡改或是窃听。是用来替代SSL的…...

正则表达式中的特殊字符
正则表达式中的特殊字符 字符类预定义字符类量词锚点分组和捕获选择、分支和条件反义和否定转义字符示例 这是我在这个网站整理的笔记,有错误的地方请指出,关注我,接下来还会持续更新。 作者:神的孩子都在歌唱 在正则表达式中,有许…...

EP42 公告详情页
文件路径: E:/homework/uniappv3tswallpaper/api/apis.js 先添加相应的api。 import {request } from "/utils/requset.js"export function apiGetBanner() {return request({url: "/homeBanner"}) } export function apiGetDayRandom() {ret…...

游戏找不到xinput1_3.dll的原因及解决方法
1. xinput1_3.dll 基本信息 1.1 文件名 xinput1_3.dll 是一个动态链接库(DLL)文件,它属于 Microsoft DirectX for Windows 的一部分。这个文件主要负责处理与 Xbox 360 控制器和其他兼容 XInput 标准的游戏手柄相关的输入信号,确…...

防反接电路设计
方案1 串联二极管, 优点:成本低、设计简单 缺点:损耗大,P ui 方案2 串联自恢复保险丝 当电源反接的时候,D4导通,F2超过跳闸带你留,就会断开,从而保护了后级电路 方案3 H桥电路…...

SpringMVC源码-AbstractHandlerMethodMapping处理器映射器将@Controller修饰类方法存储到处理器映射器
SpringMVC九大内置组件之HandlerMapping处理器映射器-AbstractHandlerMethodMapping类以及子类RequestMappingHandlerMapping如何将Controller修饰的注解类以及类下被注解RequestMapping修饰的方法存储到处理器映射器中。 从RequestMappingHandlerMapping寻找: AbstractHandle…...

毕业设计选题:基于ssm+vue+uniapp的购物系统小程序
开发语言:Java框架:ssmuniappJDK版本:JDK1.8服务器:tomcat7数据库:mysql 5.7(一定要5.7版本)数据库工具:Navicat11开发软件:eclipse/myeclipse/ideaMaven包:M…...
】力扣583. 两个字符串的删除操作)
【动态规划-最长公共子序列(LCS)】力扣583. 两个字符串的删除操作
给定两个单词 word1 和 word2 ,返回使得 word1 和 word2 相同所需的最小步数。 每步 可以删除任意一个字符串中的一个字符。 示例 1: 输入: word1 “sea”, word2 “eat” 输出: 2 解释: 第一步将 “sea” 变为 “ea” ,第二步将 "e…...

【分布式微服务云原生】8分钟探索RPC:远程过程调用的奥秘与技术实现
摘要 在分布式系统中,RPC(Remote Procedure Call,远程过程调用)技术是连接各个组件的桥梁。本文将深入探讨RPC的概念、技术实现原理、以及请求处理的详细过程。通过清晰的结构、流程图、代码片段和图表,我们将一起揭开…...

Linux操作系统中Redis
1、什么是Redis Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSIC语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。 可以理解成一个大容量的map。…...

每日论文5—06TCAS2锁相环电流匹配的gain-boosting电荷泵
《Gain-Boosting Charge Pump for Current Matching in Phase-Locked Loop》 06TCAS2 本质上和cascode来增加输出电阻,从而减小电流变化的思路是一样的。这里用了放大器来增加输出电阻。具体做法如下图: 如图1(a),A3把Vb和Vx拉平࿰…...
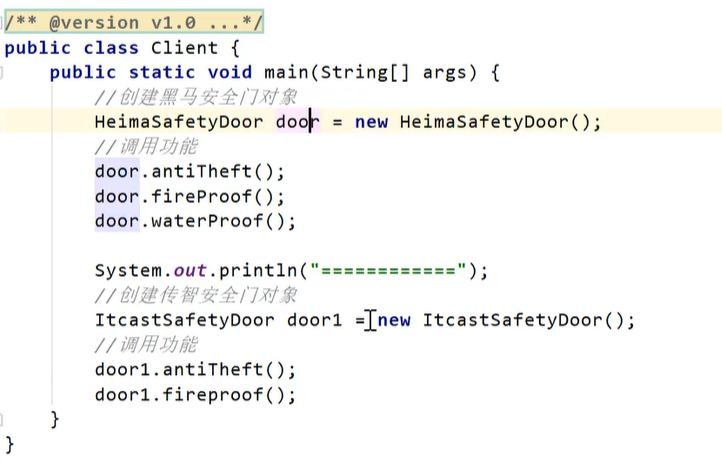
接口隔离原则(学习笔记)
客户端不应该被迫依赖于它不使用的方法:一个类对另一个类的依赖应该建立在最小的接口上。 上面的设计我们发现他存在的问题,黑马品牌的安全门具有防盗,防水,防火的功能。现在如果我们还需要再创建一盒传智品牌的安全门,…...

基于ESP8266—AT指令连接阿里云+MQTT透传数据(1)
在阿里云创建MQTT产品的过程涉及几个关键步骤,主要包括注册阿里云账号、实名认证、开通MQTT服务实例、创建产品与设备等。以下是详细的步骤说明: 一、准备工作 访问阿里云官网,点击注册按钮,填写相关信息(如账号、密码、手机号等)完成注册。注册完成后,需要对账号进行实…...

强化学习-python案例
强化学习是一种机器学习方法,旨在通过与环境的交互来学习最优策略。它的核心概念是智能体(agent)在环境中采取动作,从而获得奖励或惩罚。智能体的目标是最大化长期奖励,通过试错的方式不断改进其决策策略。 在强化学习…...

Element UI教程:如何将Radio单选框的圆框改为方框
大家好,今天给大家带来一篇关于Element UI的使用技巧。在项目中,我们经常会用到Radio单选框组件,默认情况下,Radio单选框的样式是圆框。但有时候,为了满足设计需求,我们需要将圆框改为方框,如下…...

vue3结合 vue-router和keepalive实现路由跳转保持滚动位置不改变(超级简易清晰)
1.首先我们在路由跳转页面设置keepalive(Seeall是我想实现结果的页面) 2. 想实现结果的页面中如果不是全屏实现滚动而是有单独的标签实现滚动效果...

PostgreSQL 字段使用pglz压缩测试
PostgreSQL 字段使用pglz压缩测试 测试一: 创建测试表 yewu1.test1,并插入1000w行数据 创建测试表 yewu1.test2,使用 pglz压缩字段,并插入1000w行数据–创建测试表1,并插入1000w行数据 white# create table yewu1.t…...

基于大数据的学生体质健康信息系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、Vue项目源码、SSM项目源码、微信小程序源码 精品专栏:…...

【STM32】 TCP/IP通信协议(1)--LwIP介绍
一、前言 TCP/IP是干啥的?它跟SPI、IIC、CAN有什么区别?它如何实现stm32的通讯?如何去配置?为了搞懂这些问题,查询资料可解决如下疑问: 1.为什么要用以太网通信? 以太网(Ethernet) 是指遵守 IEEE 802.3 …...

利用最小二乘法找圆心和半径
#include <iostream> #include <vector> #include <cmath> #include <Eigen/Dense> // 需安装Eigen库用于矩阵运算 // 定义点结构 struct Point { double x, y; Point(double x_, double y_) : x(x_), y(y_) {} }; // 最小二乘法求圆心和半径 …...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

MySQL 隔离级别:脏读、幻读及不可重复读的原理与示例
一、MySQL 隔离级别 MySQL 提供了四种隔离级别,用于控制事务之间的并发访问以及数据的可见性,不同隔离级别对脏读、幻读、不可重复读这几种并发数据问题有着不同的处理方式,具体如下: 隔离级别脏读不可重复读幻读性能特点及锁机制读未提交(READ UNCOMMITTED)允许出现允许…...

【力扣数据库知识手册笔记】索引
索引 索引的优缺点 优点1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。2. 可以加快数据的检索速度(创建索引的主要原因)。3. 可以加速表和表之间的连接,实现数据的参考完整性。4. 可以在查询过程中,…...

QMC5883L的驱动
简介 本篇文章的代码已经上传到了github上面,开源代码 作为一个电子罗盘模块,我们可以通过I2C从中获取偏航角yaw,相对于六轴陀螺仪的yaw,qmc5883l几乎不会零飘并且成本较低。 参考资料 QMC5883L磁场传感器驱动 QMC5883L磁力计…...

Vue2 第一节_Vue2上手_插值表达式{{}}_访问数据和修改数据_Vue开发者工具
文章目录 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染2. 插值表达式{{}}3. 访问数据和修改数据4. vue响应式5. Vue开发者工具--方便调试 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染 准备容器引包创建Vue实例 new Vue()指定配置项 ->渲染数据 准备一个容器,例如: …...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...