RAG(Retrieval Augmented Generation)及衍生框架:CRAG、Self-RAG与HyDe的深入探讨
近年来,随着大型语言模型(LLMs)的迅猛发展,我们在寻求更精确、更可靠的语言生成能力上取得了显著进展。其中,检索增强生成(Retrieval-Augmented Generation)作为一种创新方法,极大地提升了语言模型在知识密集型任务中的表现。然而,RAG并非尽善尽美,其依赖检索文档的特点也带来了相关性和准确性的挑战。为了克服这些挑战,研究者们提出了多种衍生框架,包括纠错检索增强生成(CRAG)、自我反思检索增强生成(Self-RAG)以及HyDe(Hypothetical Document Embeddings)等,这些框架在提升语言模型性能上展现出了巨大潜力。
RAG:基础与挑战
RAG(Retrieval-Augmented Generation)通过引入外部信息检索来增强语言模型的生成能力。在生成文本时,RAG模型不仅依赖其内部参数知识,还会从外部数据源(如文档数据库)中检索相关信息作为输入。这种方法在回答知识密集型问题时尤为有效,因为模型可以直接利用检索到的具体事实来生成准确的答案。

然而,RAG方法也面临着几个核心挑战:
-
相关性挑战:检索到的文档可能与查询不相关,从而降低生成答案的准确性。
-
效率问题:不必要的检索和整合会增加模型的计算负担,影响生成速度。
-
泛化能力:模型在面对新的、未在训练集中出现的情况时,可能表现不佳。
为了解决这些问题,研究者们提出了多种改进方案,其中CRAG、Self-RAG和HyDe是其中的佼佼者。
CRAG:纠错检索增强生成
CRAG(Corrective Retrieval Augmented Generation)是在RAG基础上进行的一种改进,其核心思想是引入纠错机制来提高检索的准确性和相关性。
核心架构与工作原理:
- 检索评估机制(Retrieval Evaluator):
-
1、CRAG使用一个经过微调的T5-large模型作为检索评估器,用于评估针对特定用户请求所获取文档的总体品质,并计算相关性分数。
-
2、在模型微调过程中,正样本(positive samples)被标记为“1”,负样本(negative samples)被标记为“-1”。
-
3、模型推理阶段,评估器为每篇文档计算一个相关性分数,这些分数根据特定阈值被分为“正确”、“错误”和“不确定”三个类别。
- 知识精炼算法(Knowledge Refinement Algorithm):
-
1、CRAG采用“细分再整合”的策略来深度挖掘文档中的核心知识信息。
-
2、首先,使用启发式规则将文档分解为多个细粒度的知识点。
-
3、然后,计算每个知识点的相关性得分,并滤除得分较低的部分。
-
4、最后,将高相关性的知识点重组,形成内部知识库,供生成模型使用。
- 处理流程:
-
1、CRAG首先通过检索评估器评估检索文档与用户查询之间的相关性。
-
2、若检索结果被判定为“正确”,则使用知识精炼算法对文档内容进行优化。
-
3、若检索结果被判定为“错误”,则使用网络搜索引擎检索更多外部知识。
-
4、若检索结果被判定为“不确定”,则既需要运用知识精炼算法,也需要搜索引擎的辅助。
-
5、最终,经过处理的信息被转发给大语言模型(LLM),生成最终的模型响应
CRAG技术通过这种方式提高了检索结果的准确性,并减少了无关信息的干扰,从而提升了模型回答的质量。
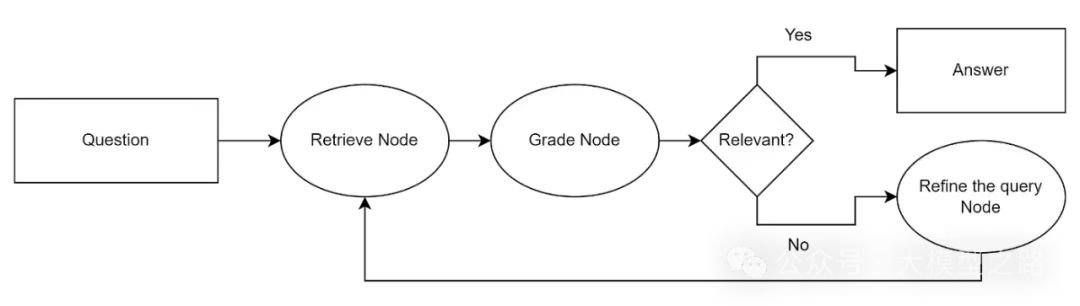
CRAG的优势在于其能够自动识别和纠正检索过程中的错误,减少不相关文档对生成答案的负面影响。同时,通过引入纠错机制,CRAG还能够提升模型在处理复杂查询时的鲁棒性。
Self-RAG:自我反思检索增强生成
Self-RAG(Self-Reflective Retrieval-Augmented Generation)则更进一步,通过引入自我反思机制来提升语言模型的生成质量。Self-RAG不仅关注检索的准确性,还关注模型生成过程的可控性和反思能力。具体而言,Self-RAG通过以下方式实现:
-
反思Token生成:在生成过程中,模型会生成特殊的反思Token,如Retrieve、ISREL、ISSUP和ISUSE等,这些Token分别用于指示是否需要检索、评估检索文档的相关性、支持度和整体效用。
-
按需检索:根据反思Token的指示,模型决定是否需要进一步检索相关文档,并并行处理多个检索到的段落。
-
生成与评估:在生成答案后,模型利用反思Token进行自我评估,选择最佳输出。
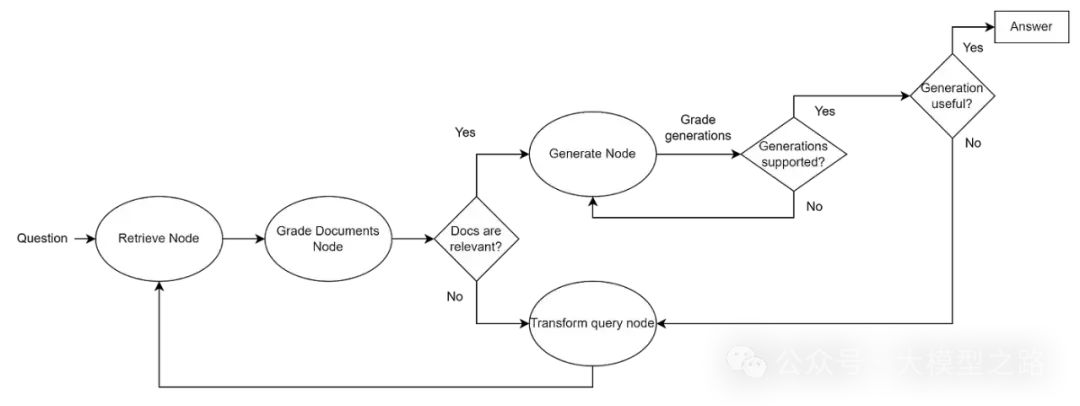
Self-RAG的优势在于其能够按需检索,减少不必要的检索操作,并通过自我反思提高生成答案的事实准确性和整体质量。此外,Self-RAG还通过引入反思Token增强了模型的可控性,使其能够根据不同任务需求调整生成行为。
HyDe:假设文档嵌入
HyDe(Hypothetical Document Embeddings)是一种创新的检索增强方法,它不同于传统的基于用户查询的检索方式,而是利用语言模型生成一个假设性的响应(即虚拟文档),然后利用这个响应进行检索。
HyDE的核心架构和工作原理如下:
-
生成假设文档:HyDE利用语言学习模型(如GPT)根据用户的查询生成一个假设性的答案或文档。这个文档虽然不是真实存在的,但它旨在模拟相关文档的内容,从而捕获查询的相关性模式。
-
文档编码:生成的假设文档随后被一个无监督对比学习的编码器(如Contriever)转换成一个嵌入向量。这个向量在语料库的嵌入空间中确定了一个邻域,基于向量相似性从中检索出相似的真实文档。
-
相似性检索:使用生成的文档向量在本地知识库中进行相似性检索,寻找最终结果。HyDE通过这种方式能够以零样本的方式工作,即不依赖于具体的相关性标签进行训练,从而适应多种语言和任务,即使在没有明确训练数据的情况下也能进行有效的文档检索。
HyDE的工作原理可以概括为:
-
输入指令和查询:HyDE接收一个查询指令,例如“写一个段落来回答这个问题”。
-
生成文档:基于GPT的语言模型生成一个假设的文档。
-
文档编码与检索:生成的文档被送入对比学习的编码器,该编码器将文档转换成嵌入向量,然后这个向量被用来在语料库中查找最相似的真实文档。
-
返回结果:模型根据生成的文档与真实文档之间的语义相似性返回查询结果。
HyDE的优势在于它能够处理更复杂和多样化的查询,特别适用于需要高度解释性和语义理解的领域,如医疗、法律和科研文献检索。它通过创造性地解释和拓展查询内容,提供更深层次的匹配和理解,从而提高了检索的相关性和准确性
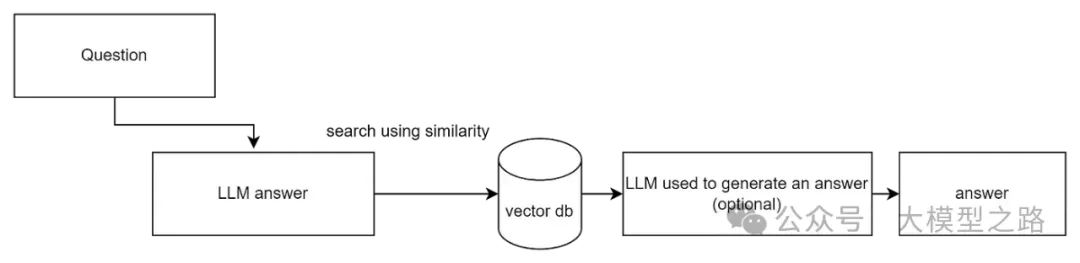
HyDe的优势在于其能够处理那些过于抽象或缺乏具体上下文的用户查询。通过生成假设文档,HyDe为检索过程提供了更多的上下文信息,从而提高了检索的准确性和相关性。

RAG及其衍生技术(CRAG、Self-RAG、HyDe)在提升语言模型准确性和适用性方面发挥了重要作用。这些技术通过引入纠正机制、自我反思和假设性文档嵌入等方法,解决了RAG在相关性和准确性方面的不足,提高了语言模型在处理知识密集型任务时的性能。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
相关文章:
RAG(Retrieval Augmented Generation)及衍生框架:CRAG、Self-RAG与HyDe的深入探讨
近年来,随着大型语言模型(LLMs)的迅猛发展,我们在寻求更精确、更可靠的语言生成能力上取得了显著进展。其中,检索增强生成(Retrieval-Augmented Generation)作为一种创新方法,极大地…...

C语言介绍
什么是C语言 C programing language 能干什么 Hello world? 如何学C语言 no reading no learning...

损失函数篇 | YOLOv10 更换损失函数之 MPDIoU | 《2023 一种用于高效准确的边界框回归的损失函数》
论文地址:https://arxiv.org/pdf/2307.07662v1.pdf 边界框回归(Bounding Box Regression,BBR)在目标检测和实例分割中得到了广泛应用,是目标定位的重要步骤。然而,对于边界框回归的大多数现有损失函数来说,当预测的边界框与真值边界框具有相同的长宽比,但宽度和高度的…...

WMware安装WMware Tools(Linux~Ubuntu)
1、这里终端里面输入sudo apt upgrade用于更新最新的包 sudo apt upgrade 2、安装 open-vm-tools-desktop 包, Ps:这里是以为我已经安装好了。 udo apt install open-vm-tools-desktop -y3、最后重启就大功告成了 reboot 4、测试是否成功:…...
关键帧跟踪)
SLAM ORB-SLAM2(30)关键帧跟踪
SLAM ORB-SLAM2(30)关键帧跟踪 1. 关键帧跟踪2. TrackReferenceKeyFrame2.1. 将当前普通帧的描述子转化为BoW向量2.2. 通过词袋BoW加速当前帧与参考帧之间的特征点匹配2.3. 将上一帧的位姿态作为当前帧位姿的初始值2.4. 通过优化3D-2D的重投影误差来获得位姿2.5. 剔除优化后的…...

k8s 部署 prometheus
创建namespace prometheus-namespace.yaml apiVersion: v1 kind: Namespace metadata:name: ns-prometheus拉取镜像 docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/quay.io/prometheus/prometheus:v2.54.0prometheus配置文件configmap prometheus-configmap.yaml …...
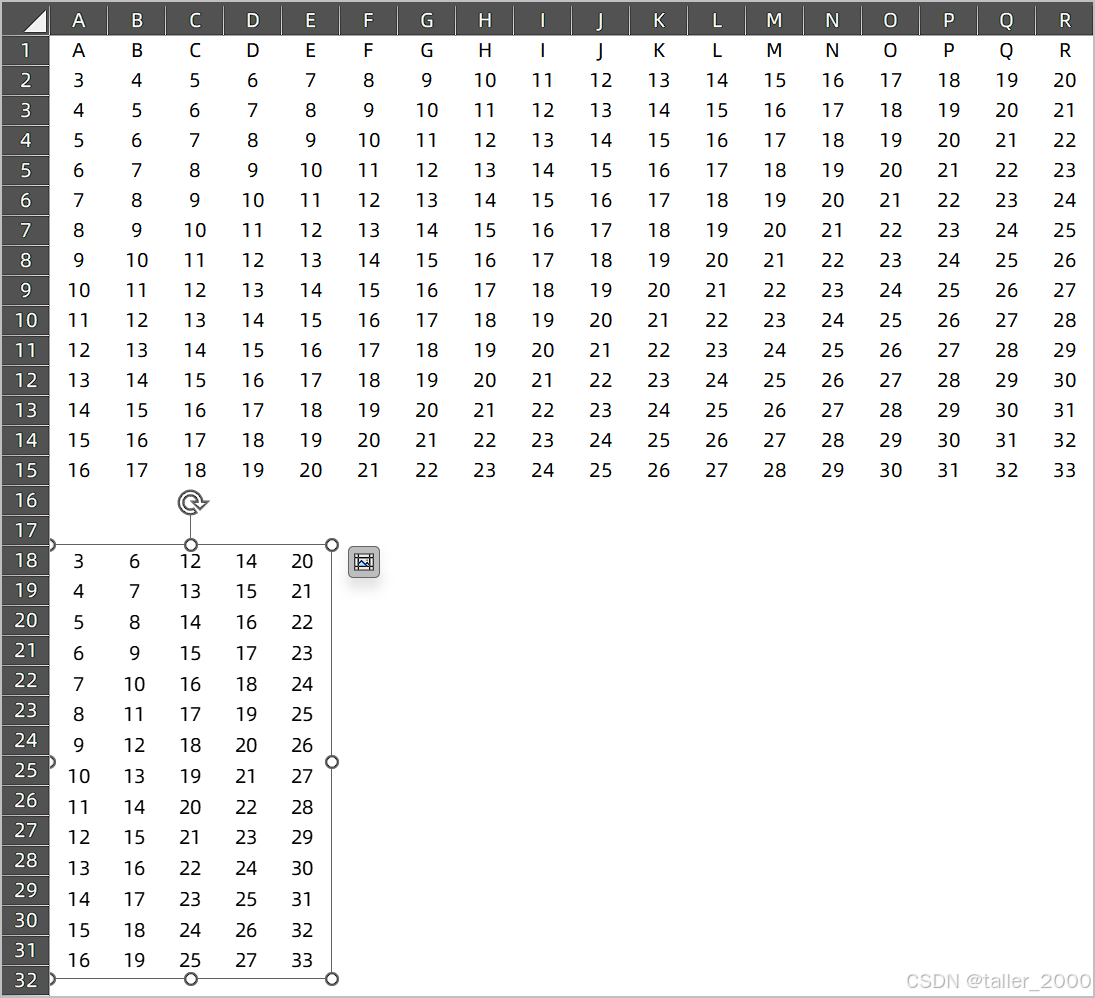
使用VBA快速生成Excel工作表非连续列图片快照
Excel中示例数据如下图所示。 现在需要拷贝A2:A15,D2:D15,J2:J15,L2:L15,R2:R15为图片,然后粘贴到A18单元格,如下图所示。 大家都知道VBA中Range对象有CopyPicture方法可以拷贝为图片,但是如果Range对象为非连续区域,那么将产生10…...

解决GitHub下载速度慢
解决GitHub下载速度慢 方法一:使用git clone 地址 --depth 1来下载 depth 1 表示只科隆最新的一次提交,也就是默认主分支,而不是完整地克隆整个代码仓库,这样可以减少下载地数据,加快克隆操作 可以用git clone 地址 …...

【机器学习(五)】分类和回归任务-AdaBoost算法
文章目录 一、算法概念一、算法原理(一)分类算法基本思路1、训练集和权重初始化2、弱分类器的加权误差3、弱分类器的权重4、Adaboost 分类损失函数5、样本权重更新6、AdaBoost 的强分类器 (二)回归算法基本思路1、最大误差的计算2…...

【设计模式-模板】
定义 模板方法模式是一种行为设计模式,它在一个方法中定义了一个算法的骨架,并将一些步骤延迟到子类中实现。通过这种方式,模板方法允许子类在不改变算法结构的情况下重新定义算法中的某些特定步骤。 UML图 组成角色 AbstractClass&#x…...

小程序原生-列表渲染
1. 列表渲染的基础用法 <!--渲染数组列表--> <view wx:for"{{numList}}" wx:key"*this" > 序号:{{index}} - 元素:{{item}}</view> <!--渲染对象属性--> <view wx:for"{{userInfo}}" wx:key&q…...

JAVA认识异常
目录 1. 异常的概念与体系结构 1.1 异常的概念 1. 算术异常 2. 数组越界异常 3. 空指针异常 1.2 异常的分类 1. 编译时异常 2. 运行时异常 2.1 异常的处理 防御式编程 2.2 异常的捕获 2.3.1 异常声明throws 2.3.2 try-catch捕获并处理 2.3.3 finally 总结 1. 异常…...
)
2024年10月计划(工作为主,Ue5独立游戏为辅,)
我发现一点,就是工作很忙,比如中秋也在远程加班,周末有时也远程加班,国庆节甚至也差点去甲方工作。甚至有可能驻场。可见,小公司确实不能去。 好在,9月份时,通过渲染 除了上班时间外࿰…...

并发、并行和异步设计
译者个人领悟,一家之言: 并发和并行确实可以明确区分出来,因为cpu的速度非常快,在执行一个任务时经常要等其他组件,比如网络,磁盘等,如果一直串行等待这样就会造成很大的浪费. (就类似于烧水的同时,可以切菜,不用等烧水完成了才去切菜,我可以烧一会水,火生起来了水壶放上了,随…...

求职Leetcode题目(12)
1.只出现一次的数字 异或运算满足交换律 a⊕bb⊕a ,即以上运算结果与 nums 的元素顺序无关。代码如下: class Solution {public int singleNumber(int[] nums) {int ans 0;for(int num:nums){ans^num;}return ans;} } 2.只出现一次的数字II 这是今天滴…...
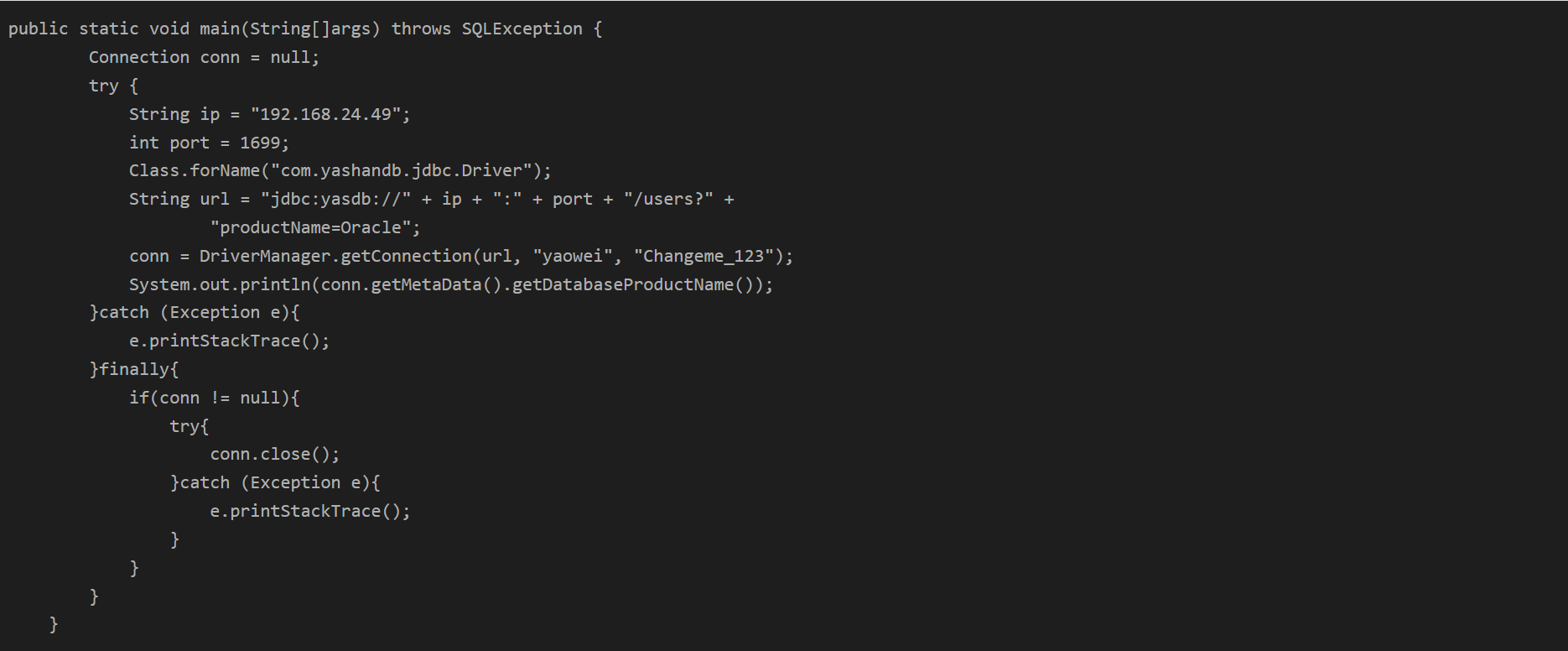
【YashanDB知识库】如何配置jdbc驱动使getDatabaseProductName()返回Oracle
本文转自YashanDB官网,具体内容请见https://www.yashandb.com/newsinfo/7352676.html?templateId1718516 问题现象 某些三方件,例如 工作流引擎activiti,暂未适配yashandb,使用中会出现如下异常: 问题的风险及影响 …...

Hadoop三大组件之MapReduce(一)
Hadoop之MapReduce 1. MapReduce是什么 MapReduce是一个分布式运算程序的编程框架,旨在帮助用户开发基于Hadoop的数据分析应用。它的核心功能是将用户编写的业务逻辑代码与自带的默认组件整合,形成一个完整的分布式运算程序,并并发运行在一…...

SQL Server 分页查询的学习文章
SQL Server 分页查询的学习文章 一、SQL Server 分页查询1. 什么是分页查询?2. SQL Server 的分页查询方法2.1 使用 OFFSET 和 FETCH NEXT语法:示例: 2.2 使用 ROW_NUMBER() 方法语法:示例: 2.3 性能考虑3. 总结 一、S…...

告别PDF大文件困扰!4款PDF在线压缩工具助你轻松优化!
嘿,档案员小伙伴们,今天咱们来聊聊那些让咱们在档案堆里游刃有余的神器。这些工具啊,简直就是咱们档案员的得力助手,特别是在PDF压缩这块儿,简直就是神器中的神器! 1、福昕转换大师 网址:http…...

Find My汽车钥匙|苹果Find My技术与钥匙结合,智能防丢,全球定位
随着科技的发展,传统汽车钥匙向智能车钥匙发展,智能车钥匙是一种采用先进技术打造的汽车钥匙,它通过无线控制技术来实现对车门、后备箱和油箱盖等部件的远程控制。智能车钥匙的出现,不仅提升了汽车的安全性能,同时也让…...

利用最小二乘法找圆心和半径
#include <iostream> #include <vector> #include <cmath> #include <Eigen/Dense> // 需安装Eigen库用于矩阵运算 // 定义点结构 struct Point { double x, y; Point(double x_, double y_) : x(x_), y(y_) {} }; // 最小二乘法求圆心和半径 …...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...
)
进程地址空间(比特课总结)
一、进程地址空间 1. 环境变量 1 )⽤户级环境变量与系统级环境变量 全局属性:环境变量具有全局属性,会被⼦进程继承。例如当bash启动⼦进程时,环 境变量会⾃动传递给⼦进程。 本地变量限制:本地变量只在当前进程(ba…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

Vue3 + Element Plus + TypeScript中el-transfer穿梭框组件使用详解及示例
使用详解 Element Plus 的 el-transfer 组件是一个强大的穿梭框组件,常用于在两个集合之间进行数据转移,如权限分配、数据选择等场景。下面我将详细介绍其用法并提供一个完整示例。 核心特性与用法 基本属性 v-model:绑定右侧列表的值&…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...
 自用)
css3笔记 (1) 自用
outline: none 用于移除元素获得焦点时默认的轮廓线 broder:0 用于移除边框 font-size:0 用于设置字体不显示 list-style: none 消除<li> 标签默认样式 margin: xx auto 版心居中 width:100% 通栏 vertical-align 作用于行内元素 / 表格单元格ÿ…...