【机器学习(五)】分类和回归任务-AdaBoost算法
文章目录
- 一、算法概念
- 一、算法原理
- (一)分类算法基本思路
- 1、训练集和权重初始化
- 2、弱分类器的加权误差
- 3、弱分类器的权重
- 4、Adaboost 分类损失函数
- 5、样本权重更新
- 6、AdaBoost 的强分类器
- (二)回归算法基本思路
- 1、最大误差的计算
- 2、相对误差计算
- 3、误差损失调整
- 4、权重系数计算
- 5、更新样本权重
- 6、规范化因子
- 7、强学习器
- 三、算法的优缺点
- 1、优点
- 2、缺点
- 四、Adaboost分类任务实现对比
- (一)数据加载
- 1、Python代码
- 2、Sentosa_DSML社区版
- (二)样本分区
- 1、Python代码
- 2、Sentosa_DSML社区版
- (三)模型训练
- 1、Python代码
- 2、Sentosa_DSML社区版
- (四)模型评估
- 1、Python代码
- 2、Sentosa_DSML社区版
- (四)模型可视化
- 1、Python代码
- 2、Sentosa_DSML社区版
- 四、Adaboost回归任务实现对比
- (一)数据加载、样本分区和特征标准化
- 1、Python代码
- 2、Sentosa_DSML社区版
- (二)模型训练
- 1、Python代码
- 2、Sentosa_DSML社区版
- (三)模型评估
- 1、Python代码
- 2、Sentosa_DSML社区版
- (四)模型可视化
- 1、Python代码
- 2、Sentosa_DSML社区版
- 六、总结
一、算法概念
什么是 AdaBoost?
AdaBoost 是 Adaptive Boosting 的缩写,是一种集成机器学习算法,可用于各种分类和回归任务。它是一种监督学习算法,用于通过将多个弱学习器或基学习算法(例如决策树)组合成一个强学习器来对数据进行分类。AdaBoost 的工作原理是根据先前分类的准确性对训练数据集中的实例进行加权,也就是说AdaBoost 构建了一个模型,并为所有数据点分配了相同的权重,然后,它将更大的权重应用于错误分类的点。在模型中,所有权重较大的点都会被赋予更大的权重。它将继续训练模型,直到返回较小的错误。所以,
- Boosting 是一个迭代的训练过程
- 后续模型更加关注前一个模型中错误分类的样本
- 最终预测是所有预测的加权组合
如下图所示:

以下是 AdaBoost 工作原理的步骤:
- 弱学习器:AdaBoost从弱分类器开始,弱分类器是一种相对简单的机器学习模型,其准确率仅略高于随机猜测率。弱分类器通常使用一个浅层决策树。
- 权重初始化:训练集中的每个实例最初被分配一个相等的权重。这些权重用于在训练期间赋予更困难的实例更多的重要性。
- 迭代(Boosting):AdaBoost执行迭代来训练一组弱分类器。在每次迭代中,模型都会尝试纠正组合模型到目前为止所犯的错误。在每次迭代中,模型都会为前几次迭代中被错误分类的实例分配更高的权重。
- 分类器权重计算:训练较弱的分类器的权重根据其产生的加权误差计算。误差较大的分类器获得较低的权重。
- 更新实例权重:错误分类的示例获得更高的权重,而正确分类的示例获得更低的权重。这导致模型在后续迭代中专注于更困难的示例。
- 加权组合弱分类器:AdaBoost将加权弱分类器组合生成一个强分类器。这个过程的关键在于,每个弱分类器的权重取决于它在训练过程中的表现,表现好的分类器会得到更高的权重,而表现不佳的分类器会得到较低的权重。
- 最终输出:最终输出是所有弱分类器组合而成的强分类器,该最终模型比单个弱分类器准确率更高。
AdaBoost 的重点在于,通过这个迭代过程,模型能够聚焦于难以分类的样本,从而提升系统的整体性能。AdaBoost 具有很强的鲁棒性,能够适应各种弱模型,是一种强大的集成学习工具。算法流程如下所示:

一、算法原理
(一)分类算法基本思路
1、训练集和权重初始化
这一节会详细解释AdaBoost 算法中的公式和推导过程,有助于理解每一步的逻辑及其含义。
训练集和权重初始化
首先,是训练集和权重初始化部分,
设训练集为:
T = { ( x , y 1 ) , ( x 2 , y 2 ) , … ( x m , y m ) } T=\left\{\left(x, y_1\right),\left(x_2, y_2\right), \ldots\left(x_m, y_m\right)\right\} T={(x,y1),(x2,y2),…(xm,ym)}
其中,每个样本 x i ∈ R n x_i∈R^n xi∈Rn。
AdaBoost 算法从样本权重初始化开始。最开始,每个样本被赋予相等的权重:
D ( t ) = ( w t 1 , w t 2 , … w t m ) ; w 1 , i = 1 m ; i = 1 , 2 … m D(t)=\left(w_{t 1}, w_{t 2}, \ldots w_{t m}\right) ; \quad w_{1,i}=\frac{1}{m} ; \quad i=1,2 \ldots m D(t)=(wt1,wt2,…wtm);w1,i=m1;i=1,2…m
其中,这里,所有权重 w 1 , i w_{1,i} w1,i的总和为1,表示每个样本的初始重要性是相等的。
2、弱分类器的加权误差
这里假设我们是二元分类问题,在第 t 轮的迭代中,输出为 { − 1 , 1 } , \{-1 , 1\} , {−1,1}, 则第t个弱分类器 G t ( x ) G_t(x) Gt(x) 在训统集上的加权误差率为
ϵ t = P ( G t ( x i ) ≠ y i ) = ∑ i = 1 m w t i I ( G t ( x i ) ≠ y i ) \epsilon_t=P\left(G_t\left(x_i\right) \neq y_i\right)=\sum_{i=1}^m w_{t i} I\left(G_t\left(x_i\right) \neq y_i\right) ϵt=P(Gt(xi)=yi)=i=1∑mwtiI(Gt(xi)=yi)
这里的 ϵ t \epsilon_t ϵt是第 t个弱分类器的加权误差率。 w t i w_{t i} wti是样本i在第t轮的权重,反映了在这一轮中该样本的重要性。加权误差表示的是分类错误的样本的权重总和,如果 ϵ t \epsilon_t ϵt接近 0,说明分类器表现良好,错误率很低;如果 ϵ t \epsilon_t ϵt接近 0.5,说明分类器的表现几乎是随机猜测。
3、弱分类器的权重
对于每一轮的弱分类器,权重系数的表达公式为:
α t = 1 2 log 1 − ϵ t ϵ t \alpha_t=\frac{1}{2} \log \frac{1-\epsilon_t}{\epsilon_t} αt=21logϵt1−ϵt
这个公式表明了弱分类器的表现与其权重之间的关系:
如果 ϵ t \epsilon_t ϵt很小,表示弱分类器表现好,那么 α t \alpha_t αt会很大,表示这个分类器在最终组合中有较大的权重。
ϵ t \epsilon_t ϵt越接近 0.5,表示分类器效果接近随机猜测,那么 α t \alpha_t αt越接近 0,表示该分类器在最终组合中权重很小。
如果 ϵ t \epsilon_t ϵt大于 0.5,理论上这个分类器的效果是反向的,意味着它的分类错误率超过 50%。因此 AdaBoost 会停止训练。
4、Adaboost 分类损失函数
Adaboost是一种基于加法模型和前向分步算法的分类方法。它通过一系列弱分类器的组合来构建一个强分类器,核心思想是根据分类错误率动态调整样本的权重,使得分类器能更好地处理难以分类的样本。
在Adaboost中,最终的强分类器 H t ( x ) H_t(x) Ht(x) 是若干个弱分类器的加权组合:
H ( x ) = sign ( ∑ t = 1 T α t G t ( x ) ) H(x) = \text{sign}\left(\sum_{t=1}^T \alpha_t G_t(x)\right) H(x)=sign(∑t=1TαtGt(x))
α i \alpha_i αi 表示第 i i i 个弱分类器的权重。其中, G i ( x ) G_i(x) Gi(x) 是第 i i i 个弱分类器对输入 x x x 的预测结果。
通过前向分步学习方法,强分类器逐步构建为:
H t ( x ) = H t − 1 ( x ) + α t G t ( x ) H_t(x)=H_{t-1}(x)+\alpha_t G_t(x) Ht(x)=Ht−1(x)+αtGt(x)
Adaboost的损失函数定义为指数损失函数,其公式为:
arg min α , T ∑ i = 1 m exp ( − y i h t ( x i ) ) \arg\min_{\alpha,T}\sum_{i=1}^m\exp\left(-y_ih_t(x_i)\right) argα,Tmini=1∑mexp(−yiht(xi))
其中:
∙ \bullet ∙ y i y_i yi为样本 i i i的真实标签,取值 { − 1 , 1 } \{-1,1\} {−1,1}。
∙ \bullet ∙ h t ( x i ) h_t( x_i) ht(xi)为分类器 h t h_t ht对样本 x i x_i xi的预测结果。
利用前向分步学习的递推公式 h t ( x ) = h t − 1 ( x ) + α t G t ( x ) h_t(x)=h_{t-1}(x)+\alpha_tG_t(x) ht(x)=ht−1(x)+αtGt(x),损失函数可以改写为:
( α t , G t ( x ) ) = arg min α , G ∑ i = 1 m exp [ − y i ( h t − 1 ( x i ) + α G ( x i ) ) ] (\alpha_t,G_t(x))=\arg\min_{\alpha,G}\sum_{i=1}^m\exp\left[-y_i\left(h_{t-1}(x_i)+\alpha G(x_i)\right)\right] (αt,Gt(x))=argα,Gmini=1∑mexp[−yi(ht−1(xi)+αG(xi))]
定义样本权重 w t , i ′ w_{t,i}^{\prime} wt,i′为:
w t , i ′ = exp ( − y i h t − 1 ( x i ) ) w_{t,i}'=\exp{(-y_ih_{t-1}(x_i))} wt,i′=exp(−yiht−1(xi))
它的值不依赖于 α \alpha α和 G G G,只与 h t − 1 ( x ) h_{t-1}(x) ht−1(x)相关。因此,损失函数可以改写为:
( α t , G t ( x ) ) = arg min α , G ∑ i = 1 m w t , i ′ exp [ − y i α G ( x i ) ] (\alpha_t,G_t(x))=\arg\min_{\alpha,G}\sum_{i=1}^mw_{t,i}'\exp\left[-y_i\alpha G(x_i)\right] (αt,Gt(x))=argα,Gmini=1∑mwt,i′exp[−yiαG(xi)]
为了找到最优的弱分类器 G t ( x ) G_t(x) Gt(x),可以将损失函数展开为:
∑ i = 1 m w t , i ′ exp ( − y i α G ( x i ) ) = ∑ y i = G t ( x i ) w t , i ′ e − α + ∑ y i ≠ G t ( x i ) w t , i ′ e α \sum_{i=1}^mw_{t,i}'\exp\left(-y_i\alpha G(x_i)\right)=\sum_{y_i=G_t(x_i)}w_{t,i}'e^{-\alpha}+\sum_{y_i\neq G_t(x_i)}w_{t,i}'e^{\alpha} i=1∑mwt,i′exp(−yiαG(xi))=yi=Gt(xi)∑wt,i′e−α+yi=Gt(xi)∑wt,i′eα
由此,可以得到最优弱分类器 G t ( x ) G_t(x) Gt(x)的选择:
G t ( x ) = arg min G ∑ i = 1 m w t , i ′ I ( y i ≠ G ( x i ) ) G_t(x)=\arg\min_G\sum_{i=1}^mw_{t,i}'I(y_i\neq G(x_i)) Gt(x)=argGmini=1∑mwt,i′I(yi=G(xi))
将 G t ( x ) G_t(x) Gt(x) 带入损失函数后,对 α \alpha α 求导并令其等于0,可以得到:
α t = 1 2 log 1 − e t e t \alpha_t=\dfrac{1}{2}\log\dfrac{1-e_t}{e_t} αt=21loget1−et
其中, e t e_t et为第 t t t轮的加权分类误差率:
e t = ∑ i = 1 m w t , i ′ I ( y i ≠ G ( x i ) ) ∑ i = 1 m w t , i ′ = ∑ i = 1 m w t , i I ( y i ≠ G ( x i ) ) e_t=\frac{\sum_{i=1}^mw_{t,i}'I(y_i\neq G(x_i))}{\sum_{i=1}^mw_{t,i}'}=\sum_{i=1}^mw_{t,i}I(y_i\neq G(x_i)) et=∑i=1mwt,i′∑i=1mwt,i′I(yi=G(xi))=i=1∑mwt,iI(yi=G(xi))
在第t+1轮中,样本权重会根据弱分类器的表现进行更新。对于分类错误的样本,其权重会增大,从而在下一轮中对这些样本给予更多的关注。通过以上推导,可以得到Adaboost的弱分类器样本权重更新公式。
5、样本权重更新
接下来,计算AdaBoost 更新样本的权重,以便在下一轮训练中更加关注那些被当前弱分类器错误分类的样本。利用 h t ( x ) = h t − 1 ( x ) + α t G t ( x ) h_t(x)=h_{t-1}(x)+\alpha_tG_t(x) ht(x)=ht−1(x)+αtGt(x)和 w t , i ′ = exp ( − y i h t − 1 ( x ) ) w_{t,i}^{\prime}=\exp(-y_ih_{t-1}(x)) wt,i′=exp(−yiht−1(x)),可以得到样本权重的更新公式为:
w t + 1 , i = w t i Z T exp ( − α t y i G t ( x i ) ) w_{t+1, i}=\frac{w_{t i}}{Z_T} \exp \left(-\alpha_t y_i G_t\left(x_i\right)\right) wt+1,i=ZTwtiexp(−αtyiGt(xi))
其中, α t \alpha_t αt 是第 t t t 个弱分类器的权重, y i y_i yi 是样本 i i i 的真实标签, G t ( x i ) G_t\left(x_i\right) Gt(xi) 是第 t t t 个弱分类器对样本 x i x_i xi 的预测结果。
这个公式的作用是通过调整权重来强化难以分类的样本:
- 如果分类器 G t ( x i ) G_t\left(x_i\right) Gt(xi) 对样本 x i x_i xi 分类错误,即 y i G t ( x i ) < 0 y_i G_t\left(x_i\right)<0 yiGt(xi)<0 会导致 w t + 1 , i w_{t+1, i} wt+1,i 增大,表示这个样本在下一轮中会被赋予更大的权重,模型会更关注它。
- 如果分类器 G t ( x i ) G_t\left(x_i\right) Gt(xi) 对样本 x i x_i xi 分类正确,即 y i G t ( x i ) > 0 y_i G_t\left(x_i\right)>0 yiGt(xi)>0 会导致 w t + 1 , i w_{t+1, i} wt+1,i 减小,表示模型认为这个样本已经很好分类了,下轮可以降低它的重要性。
6、AdaBoost 的强分类器
这里 Z t Z_t Zt 是规范化因子,保证更新后的权重仍然是一个概率分布。其计算公式为:
Z t = ∑ i = 1 m w t i exp ( − α t y i G t ( x i ) ) Z_t=\sum_{i=1}^m w_{t i} \exp \left(-\alpha_t y_i G_t\left(x_i\right)\right) Zt=i=1∑mwtiexp(−αtyiGt(xi))
通过这个规范化因子,所有的权重从 w t + 1 , i w_{t+1, i} wt+1,i 被重新调整,使得它们的总和依然为 1。从样本权重更新公式可以看出,分类错误的样本会得到更高的权重,这让下一轮的弱分类器更加关注这些难以分类的样本。这种机制逐步强化了对弱分类器表现不好的部分样本的关注,最终通过多次迭代形成一个强分类器:
H ( x ) = sign ( ∑ t = 1 T α t G t ( x ) ) H(x) = \text{sign}\left(\sum_{t=1}^T \alpha_t G_t(x)\right) H(x)=sign(t=1∑TαtGt(x))
(二)回归算法基本思路
我们先从回归问题中的误差率定义开始解释,逐步详细分析每个公式和步骤。
1、最大误差的计算
给定第t个弱学习器 G t ( x ) G_t(x) Gt(x),其在训练集上的最大误差定义为:
E t = max ∣ y i − G t ( x i ) ∣ i = 1 , 2 … m E_t=\max \left|y_i-G_t\left(x_i\right)\right| i=1,2 \ldots m Et=max∣yi−Gt(xi)∣i=1,2…m
通过计算每个样本上预测值和真实值之间的绝对差值,找到这个差值的最大值。这个最大误差为后续计算每个样本的相对误差提供了一个标准化的尺度,使得每个样本的误差相对该最大误差进行比较。
2、相对误差计算
然后计算毎个样本i的相对误差
e t i = ∣ y i − G t ( x i ) ∣ E t e_{t i}=\frac{\left|y_i-G_t\left(x_i\right)\right|}{E_t} eti=Et∣yi−Gt(xi)∣
通过相对误差,我们可以统一衡量所有样本的误差,而不受特定样本的绝对误差影响。
3、误差损失调整
误差损失可以根据不同的度量方式进行调整。
如果是线性误差的情况,即直接比较绝对误差:
e t i = ( y i − G t ( x i ) ) 2 E t e_{t i}=\frac{\left(y_i-G_t\left(x_i\right)\right)^2}{E_t} eti=Et(yi−Gt(xi))2
如果使用平方误差,则相对误差为:
e t i = ( y i − G t ( x i ) ) 2 E t 2 e_{t i}=\frac{\left(y_i-G_t\left(x_i\right)\right)^2}{E_t^2} eti=Et2(yi−Gt(xi))2
如果我们用的是指数误差,则
e t i = 1 − exp ( − ∣ y i − G t ( x i ) ∣ ) E t ) e_{t i}=1-\exp \left(\frac{\left.-\left|y_i-G_t\left(x_i\right)\right|\right)}{E_t}\right) eti=1−exp(Et−∣yi−Gt(xi)∣))
指数误差对较大的误差进行了压缩,使其影响变得非线性。
最终得到第t个弱学习器的误差率
e t = ∑ i = 1 m w t i e t i e_t=\sum_{i=1}^m w_{t i} e_{t i} et=i=1∑mwtieti
反映了第t个弱学习器在整个训练集上的整体表现
4、权重系数计算
对于第t个弱学习器,权重系数 α t \alpha_t αt的计算公式为:
α t = e t 1 − e t \alpha_t=\frac{e_t}{1-e_t} αt=1−etet
这里,权重 α t \alpha_t αt反映了第 t个弱学习器的重要性。如果误差率 e t e_t et小,则 α t \alpha_t αt会较大,表明该弱学习器的重要性较高;反之,误差率大的弱学习器权重较小,这种权重系数分配方法确保了表现更好的弱学习器在组合中获得更大的影响力。
5、更新样本权重
对于更新样本权重D,第t+1个弱学习器的样本集权重系数为:
w t + 1 , i = w t i Z t α t 1 − e t i w_{t+1, i}=\frac{w_{t i}}{Z_t} \alpha_t^{1-e_{t i}} wt+1,i=Ztwtiαt1−eti
样本权重更新的核心思想是,将更多的关注放在那些难以分类的样本上,以便在后续的训练中重点处理这些样本。
6、规范化因子
这里 Z t Z_t Zt 是规范化因子,规范化因子的计算公式为:
Z t = ∑ i = 1 m w t i α t 1 − e t i Z_t=\sum_{i=1}^m w_{t i} \alpha_t^{1-e_{t i}} Zt=i=1∑mwtiαt1−eti
通过这个规范化步骤,保持了样本权重的标准化,使得权重在每一轮迭代中不会无穷增大或减小。
7、强学习器
回归问题与分类问题略有不同,最终的强回归器 f(x)不是简单的加权和,而是通过选择若干弱学习器中的一个,最终的强回归器为:
f ( x ) = G t ∗ ( x ) f(x)=G_{t^*}(x) f(x)=Gt∗(x)
其中, G t ∗ ( x ) G_{t^*}(x) Gt∗(x) 是所有 ln 1 α t , t = 1 , 2 , … T \ln \frac{1}{\alpha_t}, t=1,2, \ldots T lnαt1,t=1,2,…T 的中位数值对应序号 t ∗ t^* t∗ 对应的弱学习器。这种方法能够在一定程度上避免极端弱学习器的影响,从而更稳定地进行回归预测。
三、算法的优缺点
1、优点
Adaboost算法的主要优点有:
- 分类精度高:作为分类器时,Adaboost可以显著提高分类精度。
- 灵活性强:Adaboost框架下可以使用各种回归或分类模型作为弱学习器,应用广泛。
- 简单易理解:尤其是用于二元分类时,算法构造简单且结果容易解释。
- 不易过拟合:相较于其他算法,Adaboost不容易过拟合。
2、缺点
Adaboost的主要缺点有:
- 对异常样本敏感:在迭代过程中,异常样本可能获得过高的权重,影响最终模型的预测效果。
此外,虽然理论上任何学习器都可以作为弱学习器,但实践中最常用的弱学习器是决策树和神经网络。在分类任务中,Adaboost通常使用CART分类树;在回归任务中,则使用CART回归树。
四、Adaboost分类任务实现对比
主要根据模型搭建的流程,对比传统代码方式和利用Sentosa_DSML社区版完成机器学习算法时的区别。
(一)数据加载
1、Python代码
#导入库
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris#加载数据集
iris = load_iris()
X = iris.data
y = iris.target
在此步骤中,我们导入必要的库。AdaBoostClassifier 是用于实现 AdaBoost 的 scikit-learn 类,DecisionTreeClassifier 是基本的弱分类器(在本例中为浅层决策树),其他库用于数据管理和性能评估。
2、Sentosa_DSML社区版
利用文本算子读入数据。

(二)样本分区
此步骤将数据集分为训练集和测试集。20%的数据用作测试集,而80%用于训练模型。
1、Python代码
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
2、Sentosa_DSML社区版
利用样本分区算子划分训练集和测试集

利用类型算子设置数据的标签列和特征列

(三)模型训练
1、Python代码
#配置弱分类器和AdaBoost分类器。n_estimators指定要训练的迭代次数(弱分类器)weak_classifier = DecisionTreeClassifier(max_depth=5, max_leaf_nodes=None, random_state=42)# 设置 AdaBoostClassifier 的参数
n_estimators = 50
learning_rate = 1.0# 创建 AdaBoost 分类器
adaboost_classifier = AdaBoostClassifier(estimator=weak_classifier,n_estimators=n_estimators,learning_rate=learning_rate,random_state=42)
#训练 AdaBoost 模型
adaboost_classifier.fit(X_train, y_train)
2、Sentosa_DSML社区版
使用AdaBoost分类算子进行模型训练。

执行完成后得到训练结果

(四)模型评估
1、Python代码
#对测试集进行预测,并通过将预测与真实标签进行比较来计算模型的准确性等指标
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import confusion_matrix
# 评估模型
accuracy = accuracy_score(y_test, predictions)
precision = precision_score(y_test, predictions, average='weighted')
recall = recall_score(y_test, predictions, average='weighted')
f1 = f1_score(y_test, predictions, average='weighted')
# 打印评估结果
print(f"AdaBoost 模型的准确率: {accuracy:.2f}")
print(f"加权精度 (Weighted Precision): {precision:.2f}")
print(f"加权召回率 (Weighted Recall): {recall:.2f}")
print(f"F1 值 (Weighted F1 Score): {f1:.2f}")# 计算混淆矩阵cm = confusion_matrix(y_test, predictions)plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=iris.target_names, yticklabels=iris.target_names)
plt.title('Confusion Matrix')
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.show()
2、Sentosa_DSML社区版
利用评估算子对模型进行评估

评估完成后得到模型训练集和验证集上的的评估结果。


利用混淆矩阵算子可以计算模型在训练集和测试集上的混淆矩阵

结果如下:


(四)模型可视化
1、Python代码
# 计算特征重要性并进行排序
importances = adaboost_classifier.feature_importances_
indices = np.argsort(importances)[::-1]# 绘制特征重要性柱状图
plt.figure(figsize=(10, 6))
plt.title("Feature Importances")
plt.bar(range(X.shape[1]), importances[indices], align="center")
plt.xticks(range(X.shape[1]), [iris.feature_names[i] for i in indices], rotation=45)
plt.tight_layout()
plt.show()

2、Sentosa_DSML社区版
右键查看模型信息即可得到特征重要性排序图和模型可视化结果等信息,模型信息如下图所示:



四、Adaboost回归任务实现对比
主要根据回归模型搭建的流程,对比传统代码方式和利用Sentosa_DSML社区版完成机器学习算法时的区别。
(一)数据加载、样本分区和特征标准化
1、Python代码
#导入库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import AdaBoostRegressor
from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_error# 读取数据集
df = pd.read_csv("D:/sentosa_ML/Sentosa_DSML/mlServer/TestData/winequality.csv")# 将数据集划分为特征和标签
X = df.drop("quality", axis=1) # 假设标签是 "quality"
Y = df["quality"]# 划分训练集和测试集
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=42)# 标准化特征
sc_x = StandardScaler()
X_train = sc_x.fit_transform(X_train)
X_test = sc_x.transform(X_test)2、Sentosa_DSML社区版
与上一节数据处理和样本分区操作类似,首先,利用文本算子读入数据,然后,连接样本分区算子划分训练集和测试集,其次,使用类型算子设置数据的标签列和特征列。

接下来,连接标准化算子对数据集进行标准化处理

执行得到标准化模型

(二)模型训练
1、Python代码
base_regressor = DecisionTreeRegressor(max_depth=8, # 树的最大深度min_samples_split=1, # 最小实例数min_impurity_decrease=0.0, # 最小信息增益max_features=None, # 不限制最大分桶数random_state=42
)# 设置 AdaBoost 回归器的参数
adaboost_regressor = AdaBoostRegressor(estimator=base_regressor,n_estimators=100, # 最大迭代次数为100learning_rate=0.1, # 步长为0.1loss='square', # 最小化的损失函数为 squared errorrandom_state=42
)# 训练模型
adaboost_regressor.fit(X_train, Y_train)# 预测测试集上的标签
y_pred = adaboost_regressor.predict(X_test)
2、Sentosa_DSML社区版
连接AdaBoost回归算子

执行得到回归模型

(三)模型评估
1、Python代码
# 计算评估指标
r2 = r2_score(Y_test, y_pred)
mae = mean_absolute_error(Y_test, y_pred)
mse = mean_squared_error(Y_test, y_pred)
rmse = np.sqrt(mse)
mape = np.mean(np.abs((Y_test - y_pred) / Y_test)) * 100
smape = 100 / len(Y_test) * np.sum(2 * np.abs(Y_test - y_pred) / (np.abs(Y_test) + np.abs(y_pred)))# 打印评估结果
print(f"R²: {r2}")
print(f"MAE: {mae}")
print(f"MSE: {mse}")
print(f"RMSE: {rmse}")
print(f"MAPE: {mape}%")
print(f"SMAPE: {smape}%")
2、Sentosa_DSML社区版
连接评估算子对模型进行评估

训练集和测试集的评估结果如下图所示:


(四)模型可视化
1、Python代码
# 可视化特征重要性
importances = adaboost_regressor.feature_importances_
indices = np.argsort(importances)[::-1]plt.figure(figsize=(10, 6))
plt.title("Feature Importances")
plt.bar(range(X.shape[1]), importances[indices], align="center")
plt.xticks(range(X.shape[1]), X.columns[indices], rotation=45)
plt.tight_layout()
plt.show()

2、Sentosa_DSML社区版
右键即可查看模型信息,下图为模型特征重要性和残差直方图:


六、总结
相比传统代码方式,利用Sentosa_DSML社区版完成机器学习算法的流程更加高效和自动化,传统方式需要手动编写大量代码来处理数据清洗、特征工程、模型训练与评估,而在Sentosa_DSML社区版中,这些步骤可以通过可视化界面、预构建模块和自动化流程来简化,有效的降低了技术门槛,非专业开发者也能通过拖拽和配置的方式开发应用,减少了对专业开发人员的依赖。
Sentosa_DSML社区版提供了易于配置的算子流,减少了编写和调试代码的时间,并提升了模型开发和部署的效率,由于应用的结构更清晰,维护和更新变得更加容易,且平台通常会提供版本控制和更新功能,使得应用的持续改进更为便捷。
为了非商业用途的科研学者、研究人员及开发者提供学习、交流及实践机器学习技术,推出了一款轻量化且完全免费的Sentosa_DSML社区版。以轻量化一键安装、平台免费使用、视频教学和社区论坛服务为主要特点,能够与其他数据科学家和机器学习爱好者交流心得,分享经验和解决问题。文章最后附上官网链接,感兴趣工具的可以直接下载使用
https://sentosa.znv.com/

相关文章:
【机器学习(五)】分类和回归任务-AdaBoost算法
文章目录 一、算法概念一、算法原理(一)分类算法基本思路1、训练集和权重初始化2、弱分类器的加权误差3、弱分类器的权重4、Adaboost 分类损失函数5、样本权重更新6、AdaBoost 的强分类器 (二)回归算法基本思路1、最大误差的计算2…...

【设计模式-模板】
定义 模板方法模式是一种行为设计模式,它在一个方法中定义了一个算法的骨架,并将一些步骤延迟到子类中实现。通过这种方式,模板方法允许子类在不改变算法结构的情况下重新定义算法中的某些特定步骤。 UML图 组成角色 AbstractClass&#x…...

小程序原生-列表渲染
1. 列表渲染的基础用法 <!--渲染数组列表--> <view wx:for"{{numList}}" wx:key"*this" > 序号:{{index}} - 元素:{{item}}</view> <!--渲染对象属性--> <view wx:for"{{userInfo}}" wx:key&q…...

JAVA认识异常
目录 1. 异常的概念与体系结构 1.1 异常的概念 1. 算术异常 2. 数组越界异常 3. 空指针异常 1.2 异常的分类 1. 编译时异常 2. 运行时异常 2.1 异常的处理 防御式编程 2.2 异常的捕获 2.3.1 异常声明throws 2.3.2 try-catch捕获并处理 2.3.3 finally 总结 1. 异常…...
)
2024年10月计划(工作为主,Ue5独立游戏为辅,)
我发现一点,就是工作很忙,比如中秋也在远程加班,周末有时也远程加班,国庆节甚至也差点去甲方工作。甚至有可能驻场。可见,小公司确实不能去。 好在,9月份时,通过渲染 除了上班时间外࿰…...

并发、并行和异步设计
译者个人领悟,一家之言: 并发和并行确实可以明确区分出来,因为cpu的速度非常快,在执行一个任务时经常要等其他组件,比如网络,磁盘等,如果一直串行等待这样就会造成很大的浪费. (就类似于烧水的同时,可以切菜,不用等烧水完成了才去切菜,我可以烧一会水,火生起来了水壶放上了,随…...

求职Leetcode题目(12)
1.只出现一次的数字 异或运算满足交换律 a⊕bb⊕a ,即以上运算结果与 nums 的元素顺序无关。代码如下: class Solution {public int singleNumber(int[] nums) {int ans 0;for(int num:nums){ans^num;}return ans;} } 2.只出现一次的数字II 这是今天滴…...
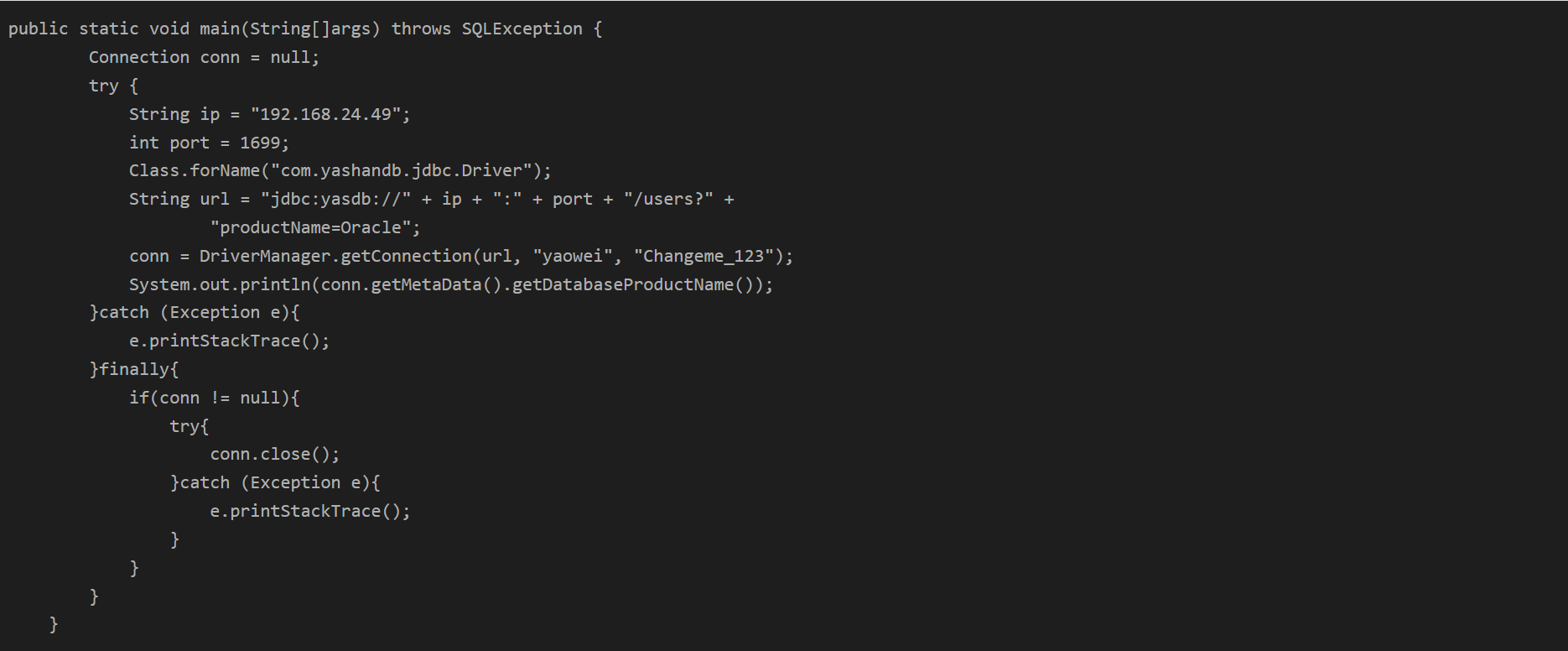
【YashanDB知识库】如何配置jdbc驱动使getDatabaseProductName()返回Oracle
本文转自YashanDB官网,具体内容请见https://www.yashandb.com/newsinfo/7352676.html?templateId1718516 问题现象 某些三方件,例如 工作流引擎activiti,暂未适配yashandb,使用中会出现如下异常: 问题的风险及影响 …...

Hadoop三大组件之MapReduce(一)
Hadoop之MapReduce 1. MapReduce是什么 MapReduce是一个分布式运算程序的编程框架,旨在帮助用户开发基于Hadoop的数据分析应用。它的核心功能是将用户编写的业务逻辑代码与自带的默认组件整合,形成一个完整的分布式运算程序,并并发运行在一…...

SQL Server 分页查询的学习文章
SQL Server 分页查询的学习文章 一、SQL Server 分页查询1. 什么是分页查询?2. SQL Server 的分页查询方法2.1 使用 OFFSET 和 FETCH NEXT语法:示例: 2.2 使用 ROW_NUMBER() 方法语法:示例: 2.3 性能考虑3. 总结 一、S…...

告别PDF大文件困扰!4款PDF在线压缩工具助你轻松优化!
嘿,档案员小伙伴们,今天咱们来聊聊那些让咱们在档案堆里游刃有余的神器。这些工具啊,简直就是咱们档案员的得力助手,特别是在PDF压缩这块儿,简直就是神器中的神器! 1、福昕转换大师 网址:http…...

Find My汽车钥匙|苹果Find My技术与钥匙结合,智能防丢,全球定位
随着科技的发展,传统汽车钥匙向智能车钥匙发展,智能车钥匙是一种采用先进技术打造的汽车钥匙,它通过无线控制技术来实现对车门、后备箱和油箱盖等部件的远程控制。智能车钥匙的出现,不仅提升了汽车的安全性能,同时也让…...
)
mysql学习教程,从入门到精通,SQL UNION 运算符(27)
1、SQL UNION 运算符 UNION 运算符在 SQL 中用于合并两个或多个 SELECT 语句的结果集,并默认去除重复的行。如果你想要包含所有重复行,可以使用 UNION ALL。下面是一个使用 UNION 运算符的示例,假设我们有两个表:employees_2020 …...
)
PKCE3-PKCE实现(SpringBoot3.0)
在 Spring Boot 3.0 JDK 17 的环境下,实现 PKCE 认证的核心步骤包括: 1)引入依赖:使用 Spring Security OAuth 2.0 客户端进行授权码流程。 2)配置 OAuth 2.0 客户端:在 Spring Boot 中配置 OAuth 2.0 客…...

C++详解vector
目录 构造和拷贝构造 赋值运算符重载: vector的编辑函数: assign函数: push_back和pop_back函数: insert函数: erase函数: swap函数: clear函数: begin函数: e…...

Redis实战--Redis的数据持久化与搭建Redis主从复制模式和搭建Redis的哨兵模式
Redis作为一个高性能的key-value数据库,广泛应用于缓存、消息队列、排行榜等场景。然而,Redis是基于内存的数据库,这意味着一旦服务器宕机,内存中的数据就会丢失。为了解决这个问题,Redis提供了数据持久化的机制&#…...

World of Warcraft [CLASSIC] Engineering 421-440
工程学421-440 World of Warcraft [CLASSIC] Engineering 335-420_魔兽世界宗师级工程学需要多少点-CSDN博客 【萨隆邪铁锭】421-425 学习新技能,其他都不划算,只能做太阳瞄准镜 【太阳瞄准镜】426、427、428、429 【随身邮箱】430 这个基本要做的&am…...

VUE3.5版本解读
官网:Announcing Vue 3.5 | The Vue Point 2024年9月1日,宣布 Vue 3.5“天元突破:红莲螺岩”发布! 反应系统优化 在 3.5 中,Vue 的反应系统经历了另一次重大重构,在行为没有变化的情况下实现了更好的性能…...

spark计算引擎-架构和应用
一Spark 定义:Spark 是一个开源的分布式计算系统,它提供了一个快速且通用的集群计算平台。Spark 被设计用来处理大规模数据集,并且支持多种数据处理任务,包括批处理、交互式查询、机器学习、图形处理和流处理。 核心架构&#x…...
)
VUE 开发——AJAX学习(二)
一、Bootstrap弹框 功能:不离开当前页面,显示单独内容,供用户操作 步骤: 引入bootstrap.css和bootstrap.js准备弹框标签,确认结构通过自定义属性,控制弹框显示和隐藏 在<head>部分添加:…...

使用docker在3台服务器上搭建基于redis 6.x的一主两从三台均是哨兵模式
一、环境及版本说明 如果服务器已经安装了docker,则忽略此步骤,如果没有安装,则可以按照一下方式安装: 1. 在线安装(有互联网环境): 请看我这篇文章 传送阵>> 点我查看 2. 离线安装(内网环境):请看我这篇文章 传送阵>> 点我查看 说明:假设每台服务器已…...

【Python】 -- 趣味代码 - 小恐龙游戏
文章目录 文章目录 00 小恐龙游戏程序设计框架代码结构和功能游戏流程总结01 小恐龙游戏程序设计02 百度网盘地址00 小恐龙游戏程序设计框架 这段代码是一个基于 Pygame 的简易跑酷游戏的完整实现,玩家控制一个角色(龙)躲避障碍物(仙人掌和乌鸦)。以下是代码的详细介绍:…...

C++:std::is_convertible
C++标志库中提供is_convertible,可以测试一种类型是否可以转换为另一只类型: template <class From, class To> struct is_convertible; 使用举例: #include <iostream> #include <string>using namespace std;struct A { }; struct B : A { };int main…...

MVC 数据库
MVC 数据库 引言 在软件开发领域,Model-View-Controller(MVC)是一种流行的软件架构模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种模式有助于提高代码的可维护性和可扩展性。本文将深入探讨MVC架构与数据库之间的关系,以…...

在四层代理中还原真实客户端ngx_stream_realip_module
一、模块原理与价值 PROXY Protocol 回溯 第三方负载均衡(如 HAProxy、AWS NLB、阿里 SLB)发起上游连接时,将真实客户端 IP/Port 写入 PROXY Protocol v1/v2 头。Stream 层接收到头部后,ngx_stream_realip_module 从中提取原始信息…...

如何在看板中有效管理突发紧急任务
在看板中有效管理突发紧急任务需要:设立专门的紧急任务通道、重新调整任务优先级、保持适度的WIP(Work-in-Progress)弹性、优化任务处理流程、提高团队应对突发情况的敏捷性。其中,设立专门的紧急任务通道尤为重要,这能…...

unix/linux,sudo,其发展历程详细时间线、由来、历史背景
sudo 的诞生和演化,本身就是一部 Unix/Linux 系统管理哲学变迁的微缩史。来,让我们拨开时间的迷雾,一同探寻 sudo 那波澜壮阔(也颇为实用主义)的发展历程。 历史背景:su的时代与困境 ( 20 世纪 70 年代 - 80 年代初) 在 sudo 出现之前,Unix 系统管理员和需要特权操作的…...
中关于正整数输入的校验规则)
Element Plus 表单(el-form)中关于正整数输入的校验规则
目录 1 单个正整数输入1.1 模板1.2 校验规则 2 两个正整数输入(联动)2.1 模板2.2 校验规则2.3 CSS 1 单个正整数输入 1.1 模板 <el-formref"formRef":model"formData":rules"formRules"label-width"150px"…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

ip子接口配置及删除
配置永久生效的子接口,2个IP 都可以登录你这一台服务器。重启不失效。 永久的 [应用] vi /etc/sysconfig/network-scripts/ifcfg-eth0修改文件内内容 TYPE"Ethernet" BOOTPROTO"none" NAME"eth0" DEVICE"eth0" ONBOOT&q…...