高并发内存池(五):ThreadCache、CentralCache和PageCache的内存回收机制、阶段性代码展示和释放内存过程的调试
目录
ThreadCache的内存回收机制
补充内容1
补充内容2
补充内容3
补充内容4
ListTooLong函数的实现
CentralCache的内存回收机制
MapObjectToSpan函数的实现
ReleaseListToSpans函数的实现
PageCache的内存回收机制
补充内容1
补充内容2
ReleaseSpanToPageCache函数的实现
阶段性代码展示
Common.h
ObjectPool.h
ConcurrentAlloc.h
PageCache.h
CentralCache.h
ThreadCache.h
PageCache.cpp
CentralCache.cpp
ThreadCache.cpp
unitTest.cpp
调试过程
新增函数TestConcurrentAlloc2
内存释放流程图
ThreadCache的内存回收机制
补充内容1
在FreeList类中新增PopRange函数,用于一次性删除_maxsize个内存结点
//头删n个内存结点(或者叫剔除,因为这些内存结点只不过是从freelist中拿出来了并未消失)
void PopRange(void*& start, void*& end, size_t n)
{assert(n <= _size);//要剔除的结点个数不能大于当前链表中结点的个数start = end = _freeList;for (size_t i = 0; i < n - 1; ++i){end = NextObj(end);}_freeList = NextObj(end);NextObj(end) = nullptr;_size -= n;
}
补充内容2
在FreeList类中新增记录当前链表中内存结点个数的变量_size
同时在Pop、Push、PushRange、PopRange函数中增加计数操作

//管理切分好的小对象的自由链表
class FreeList
{
public:...//返回当前链表中结点的个数size_t Size(){return _size;}private:void* _freeList = nullptr;size_t _maxSize = 1;//记录当前freelist一次性最多向CentralCache申请多少个内存结点size_t _size = 0;//当前链表中结点的个数
};
补充内容3
在Deallocate函数中新增是否向CentralCache返回内存结点的判断
//释放ThreadCache中的内存
void ThreadCache::Deallocate(void* ptr, size_t size)
{assert(ptr);assert(size <= MAX_BYTES);//找对映射的自由链表桶,并将用完的对象插入进去size_t index = SizeClass::Index(size);_freeLists[index].Push(ptr);//当还回来后当前自由链表的内存结点个数大于当前链表一次性可以向CentralCache申请的内存结点个数_maxsize,就将当前自由链表中_maxsize个内存结点归还给CentralCache//如果只归还多出的那一小部分内存结点(_size-_maxsize)会导致ThreadCache和CentralCache进行频繁的交互,增加系统调用和锁竞争的次数,从而降低整体性能if (_freeLists[index].Size() >= _freeLists[index].MaxSize()){ListTooLong(_freeLists[index], size);}
}
补充内容4
在FetchFromCentralCache函数中调用PushRange函数时新增表示插入结点个数的参数
(actualNum - 1是因为此时有一个已经被申请者使用了,添加是为了_size的计数)

ListTooLong函数的实现
注意事项:记得在ThreadCache类中新增ListTooLong函数的声明
//释放内存结点导致自由链表结点个数过多时,依据当前自由链表一次性最多向CentralCache申请的内存结点的个数,向CentralCache归还这么多的内存结点
void ListTooLong(FreeList& list, size_t size);//链表结点过多
void ThreadCache::ListTooLong(FreeList& list, size_t size)
{//输出型参数void* start = nullptr;void* end = nullptr;list.PopRange(start, end, list.MaxSize());CentralCache::GetInstance()->ReleaseListToSpans(start,size);
}CentralCache的内存回收机制
MapObjectToSpan函数的实现
功能:确定从ThreadCache归还回的内存结点都属于哪个span
注意事项:记得在PageCache类中新增MapObjectToSpan函数的声明
//内存结点的地址->页号->span的映射
Span* PageCache::MapObjectToSpan(void* obj)
{size_t id = ((size_t)obj >> PAGE_SHIFT);//页号 = 内存结点的地址 / 页大小 auto ret = _idSpanMap.find(id);//在_idSpanMap中寻找对应的span地址if (ret != _idSpanMap.end()){return ret->second;//找到了就返回该span的地址}else{assert(false);//找不到就报错return nullptr;}
}ReleaseListToSpans函数的实现
注意事项:归还内存结点前先将当前的SpanList上锁,在归还完成后再解锁,每向某个span归还一个内存结点就将该span的_useCount--,再判断该span的_useCount == 0时将该span归还给PageCache,最后记得在CentralCache类中新增ReleaseListToSpans函数的声明
//将从ThreadCache获得内存结点归还给它们所属的span,因为这些内存结点可能是由CentralCache同一桶中的不同span分配的
//前一个span用完了,从后一个span中获取,同时前一个span可能还会接收从ThreadCache归还回来的内存结点,下次分配时可能又可以从前面的span分配了,多线程考虑的有点多
void CentralCache::ReleaseListToSpans(void* start, size_t size)
{size_t index = SizeClass::Index(size);_spanLists[index]._mtx.lock();//start指向的是一串内存结点的头结点while (start){void* next = NextObj(start);//归还的内存结点可能隶属于不同的span,所以每次插入时需要判断Span* span = PageCache::GetInstance()->MapObjectToSpan(start);//确定要归还的span//头插内存结点到span中NextObj(start) = span->_freelist;span->_freelist = start;span->_useCount--;//_useCount--表示有一个分配出去的小块内存回到当前span//当前span的_useCount为0表示当前span切分出去的所有小块内存都回来了,直接将整个span还给PageCache,PageCache再尝试进行前后页的合并if (span->_useCount == 0){_spanLists[index].Erase(span);//将当前的span从CentralCache的某个桶处的SpanList上取下//参与到PageCache中进行合并的span不需要自由链表等内容,置空即可span->_freelist = nullptr;span->_next = nullptr;span->_prev = nullptr;_spanLists[index]._mtx.unlock();//不用了就解锁,避免对CentralCache中同一桶的锁竞争PageCache::GetInstance()->_pageMtx.lock();//为PageCache上锁PageCache::GetInstance()->ReleaseSpanToPageCache(span);//尝试合并前后页PageCache::GetInstance()->_pageMtx.unlock();//为PageCache解锁_spanLists[index]._mtx.lock();//合并完后还要再上锁,为了让当前线程走完ReleaseListToSpans函数 }start = next;}_spanLists[index]._mtx.unlock();//当前线程走完ReleaseListToSpans函数,解锁
}
PageCache的内存回收机制
补充内容1
在PageCache类中新增unordered_map类型的成员变量_idSpanMap
在NewSpan分裂span以及从PageCache直接返回span时,填写页号和span的映射关系
解释:我们无法直接通过从Thread Cache中归还的内存结点的地址确定该内存结点要被归还给CentralCache中的哪个span,需要先将该内存结点的地址转换为页号(内存结点都是从页中分配的),再通过页号和span的映射关系确定要归还的span是哪个
//建立页号和span间得映射关系
std::unordered_map<size_t, Span*> _idSpanMap;

//获取一个非空span
Span* PageCache::NewSpan(size_t k)
{assert(k > 0 && k < NPAGES);//先检查PageCache的第k个桶中有没有span,有就直接头删并返回if (!_spanLists[k].Empty()){Span* kSpan = _spanLists[k].PopFront();//保存页号和span的映射关系//因为留在PacgeCache中的span只存放了其首尾页号和其的对应关系,而此时该span要被分配给CentralCache了,在CentralCache要被切分成小内存块,小内存块从ThreadCache归还时需要依据小内存块的地址确定所属span,故要简历该span中所有页号和该span的对应关系for (size_t i = 0; i < kSpan->_n; ++i){_idSpanMap[kSpan->_PageId + i] = kSpan;}return kSpan;}//走到这儿代表k号桶为空,检查后面的桶有没有大的span,分裂一下for (size_t i = k + 1; i < NPAGES; ++i)//因为第一个要询问的肯定是k桶的下一个桶所以i = k + 1{//k页的span返回给CentralCache,i-k页的span挂到i-k号桶中,均需要存储页号和span的映射关系if (!_spanLists[i].Empty()){Span* nSpan = _spanLists[i].PopFront();Span* kSpan = _spanPool.New();//在nSpan头部切一个k页的span下来kSpan->_PageId = nSpan->_PageId;kSpan->_n = k;nSpan->_PageId += k;//nSpan管理的首页页号变为了i + knSpan->_n -= k;//nSpan管理的页数变为了i - k_spanLists[nSpan->_n].PushFront(nSpan);//将nSpan重新挂到PageCache中的第nSpan->_n号桶中,即第i - k号桶//存储nSpan的首尾页号跟nSpan的映射关系,便于PageCache回收内存时的合并查找_idSpanMap[nSpan->_PageId] = nSpan;_idSpanMap[nSpan->_PageId + nSpan->_n - 1] = nSpan;//在span分裂后就建立页号和span得映射关系,便于CentralCahe在回收来自ThreadCache的小块内存时,找到那些小内存块所属的spanfor (size_t i = 0; i < kSpan->_n; ++i){_idSpanMap[kSpan->_PageId + i] = kSpan;}return kSpan;}}//走到这里就说明PageCache中没有合适的span了,此时就去找堆申请一个管理128页的spanSpan* bigSpan = _spanPool.New();void* ptr = SystemAlloc(NPAGES - 1);//ptr指向从堆分配的内存空间的起始地址//计算新span的页号,管理的页数等bigSpan->_PageId = (size_t)ptr >> PAGE_SHIFT;//页号 = 起始地址 / 页大小bigSpan->_n = NPAGES - 1;_spanLists[bigSpan->_n].PushFront(bigSpan);return NewSpan(k);//重新调用一次自己,那么此时PageCache中就有一个管理k页的span了,可以从PageCache中直接分配了,在for循环中就会return//可以代码复用,且循环只有128次的递归消耗的资源很小
}补充内容2
在Span类中新增变量_isUse,用于标记当前span的状态
(为true表示在被使用,为false表示未被使用)
在PageCache为CentralCache分配span时将_isUse设为true
(在GetOneSpan函数执行完NewSpan函数后)
CentralCache归还的span在PageCache中挂起后将_isUse设为false(ReleaseSpanToPageCache函数的末尾)
struct Span
{...bool _isUse = false;//初始时设为false,因为所有span都是从PageCache中得到的
}


ReleaseSpanToPageCache函数的实现
注意事项: 记得在PageCache类中新增ReleaseSpanToPageCache函数的声明
//接收CentralCache中归还的span,并尝试合并该span的相邻空闲页,使得该span变成一个管理更多页的span
void ReleaseSpanToPageCache(Span* span);停止合并原则:
- 前/后页不存在:通过页号查找不到span,表示该span未在PageCache中出现过
- 前/后页所属的span被占用:该span在PageCache中出现过,但此时被分给了CentralCache
- 合并后的总页数大于128:查找的span在PageCache中,但和当前span合并后页数大于128
//合并页
void PageCache::ReleaseSpanToPageCache(Span* span)
{ //向前合并while (1){size_t prevId = span->_PageId - 1;//获取前页的页号auto ret = _idSpanMap.find(prevId);//由页号确定在哈希表中的位置//通过页号查找不到span,表示该span未在PageCache中出现过,不合并if (ret == _idSpanMap.end()){break;}//该span在PageCache中出现过,但此时被分给了CentralCache,不合并Span* prevSpan = ret->second;if (prevSpan->_isUse == true){break;}//查找的span在PageCache中,但和当前span合并后页数大于128,不合并if (prevSpan->_n + span->_n > NPAGES - 1){break;}_spanLists[prevSpan->_n].Erase(prevSpan);//将PageCache中prevSpan->_n桶处的span进行删除span->_PageId = prevSpan->_PageId;span->_n += prevSpan->_n;delete prevSpan;}//向后合并while (1){size_t nextId = span->_PageId + span->_n;//当前span管理的页的后一个span的首页页号auto ret = _idSpanMap.find(nextId);//获取页号对应的桶位置//通过页号查找不到span,表示该span未在PageCache中出现过,不合并if (ret == _idSpanMap.end()){break;}//该span在PageCache中出现过,但此时被分给了CentralCache,不合并Span* nextSpan = ret->second;if (nextSpan->_isUse == true){break;}//查找的span在PageCache中,但和当前span合并后页数大于128,不合并if (nextSpan->_n + span->_n > NPAGES - 1){break;}span->_n += nextSpan->_n;_spanLists[nextSpan->_n].Erase(nextSpan);delete nextSpan;}_spanLists[span->_n].PushFront(span);//将合并后的span在PageCache中挂起//重新存放首尾页的映射关系_idSpanMap[span->_PageId] = span;_idSpanMap[span->_PageId + span->_n - 1] = span;span->_isUse = false;//将当前span的_isUse设为false
}阶段性代码展示
Common.h
#pragma once
#include <iostream>
#include <vector>
#include <thread>
#include <unordered_map>
#include <time.h>
#include <assert.h>
#include <Windows.h>
#include <mutex>using std::cout;
using std::endl;//static const 和 const static 效果相同,表示当前变量仅会在当前文件中出现static const size_t MAX_BYTES = 256 * 1024;//规定单次向ThreadCache中申请的内存不超过256KB
static const size_t NFREELIST = 208; //规定ThreadCache和CentralCache中哈希桶的数量为208
static const size_t NPAGES = 129; //规定PageCache中span存放的最大页数为129
static const size_t PAGE_SHIFT = 13; //规定一个页的大小为2的13次方字节,即8KB//Windows环境下通过封装Windows提供的VirtualAlloc函数,直接向堆申请以页为单位的内存,而不使用malloc/new
inline static void* SystemAlloc(size_t kpage)//kpage表示页数
{
#ifdef _WIN32void* ptr = VirtualAlloc(0, kpage << PAGE_SHIFT, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
#endifif (ptr == nullptr)throw std::bad_alloc();//申请失败的抛异常return ptr;
}//调用Winodws提供的VirtualFree函数释放从堆申请的内存,而不使用free/delete
inline static void SystemFree(void* ptr)
{VirtualFree(ptr, 0 ,MEM_RELEASE);
}//获取下一个结点的地址
//static限制NextObj的作用域,防止其它文件使用extern访问NextObj函数,传引用返回减少拷贝消耗
static void*& NextObj(void* obj)
{return *(void**)obj;
}//管理切分好的小对象的自由链表
class FreeList
{
public://头插void Push(void* obj){assert(obj);NextObj(obj) = _freeList;_freeList = obj;++_size;}//一次性插入n个结点void PushRange(void* start, void* end,size_t n){NextObj(end) = _freeList;_freeList = start;_size += n;}//头删void* Pop(){assert(_freeList);//当前负责释放内存结点的自由链表不能为空void* obj = _freeList;_freeList = NextObj(obj);--_size;return obj;}//头删n个内存结点(或者叫剔除,因为这些内存结点只不过是从freelist中拿出来了并未消失)void PopRange(void*& start, void*& end, size_t n){assert(n <= _size);//要剔除的结点个数不能大于当前链表中结点的个数start = end = _freeList;for (size_t i = 0; i < n - 1; ++i){end = NextObj(end);}_freeList = NextObj(end);NextObj(end) = nullptr;_size -= n;}//判空,当前自由链表是否为空bool Empty(){return _freeList == nullptr;}//返回当前freelist一次性最多向CentralCache申请多少个内存结点size_t& MaxSize(){return _maxSize;}//返回当前链表中结点的个数size_t Size(){return _size;}private:void* _freeList = nullptr;size_t _maxSize = 1;//记录当前freelist一次性最多向CentralCache申请多少个内存结点size_t _size = 0;//当前链表中结点的个数
};//存放常用计算函数的类
class SizeClass
{
public://基本原则:申请的内存越大,所需要的对齐数越大,整体控制在最多10%左右的内碎片浪费(如果要的内存是15byte,那么在1,128范围内按8byte对齐后的内碎片应该为1,1/16=0.0625四舍五入就是百分之十)//[1,128] 按8byte对齐 freelist[0,16) 128 / 8 = 16//[128+1.1024] 按16byte对齐 freelist[16,72) 896 / 16 = 56//[1024+1,8*1024] 按128byte对齐 freelist[72,128) ...//[8*1024+1,64*1024] 按1024byte对齐 freelist[128,184) ...//[64*1024+1,256*1024] 按8*1024byte对齐 freelist[184,208) ...//内联函数在程序的编译期间在使用位置展开,一般是简短且频繁使用的函数,减少函数调用产生的消耗,增加代码执行效率static inline size_t _RoundUp(size_t bytes, size_t alignNum)//(申请的内存大小,规定的对齐数){size_t alignSize = 0;//对齐后的内存大小if (bytes % alignNum != 0)//不能按与之配对的对齐数进行对齐的,就按照与其一起传入的对齐数进行对齐计算{alignSize = (bytes / alignNum + 1) * alignNum;//bytes = 50 alignNum = 8,对齐后大小就为56}else//能按与其配对的对齐数进行对齐的,对齐后大小就是传入的申请内存大小{alignSize = bytes;//bytes = 16 alignNum = 8,对齐后大小就为16}return alignSize;}//内存对齐static inline size_t RoundUp(size_t size){if (size <= 128){return _RoundUp(size, 8);}else if (size <= 1024){return _RoundUp(size, 16);}else if (size <= 8 * 1024){return _RoundUp(size, 128);}else if (size <= 64 * 1024){return _RoundUp(size, 1024);}else if (size <= 256 * 1024){return _RoundUp(size, 8 * 1024);}else{assert(false);return -1;}}static inline size_t _Index(size_t bytes, size_t align_shift){return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;}//寻找桶位置static inline size_t Index(size_t bytes){assert(bytes <= MAX_BYTES);static int group_array[4] = { 16,56,56,56 };//提前写出计算好的每个链表的个数if (bytes <= 128){return _Index(bytes, 3);}else if (bytes <= 1024){return _Index(bytes - 128, 4) + group_array[0];//加上上一个范围内的桶的个数}else if (bytes <= 8 * 1024){return _Index(bytes - 1024, 7) + group_array[0] + group_array[1];}else if (bytes <= 64 * 1024){return _Index(bytes - 8 * 1024, 10) + group_array[0] + group_array[1] + group_array[2];}else if (bytes <= 256 * 1024){return _Index(bytes - 64 * 1024, 13) + group_array[0] + group_array[1] + group_array[2] + group_array[3];}else{assert(false);return -1;}}//理论上当前自由链表一次性要向CentralCache申请的结点个数static size_t NumMoveSize(size_t size){assert(size > 0);//num∈[2,512]int num = MAX_BYTES / size;if (num < 2)//最少要給2个{//num = 256KB / 512KB = 0.5 ≈ 1 个//num越小表示单次申请所需的内存越大,而给太少不合适num = 2;}if (num > 512)//最多能给512个{//num = 256KB / 50Byte ≈ 5242个//num越大表示单次申请所需的内存越小,而给太多不合适,会导致分配耗时太大num = 512;}return num;}//一次性要向堆申请多少个页static size_t NumMovePage(size_t size){size_t batchnum = NumMoveSize(size);size_t npage = (batchnum * size) >> PAGE_SHIFT;//(最多可以分配的内存结点个数 * 单个内存结点的大小) / 每个页的大小if (npage == 0)//所需页数小于1,就主动给分配一个npage = 1;return npage;}
};struct Span
{size_t _PageId = 0;//当前span管理的连续页的起始页的页号size_t _n = 0;//当前span管理的页的数量Span* _next = nullptr;Span* _prev = nullptr;size_t _useCount = 0;//当前span中切好小块内存,被分配给thread cache的数量void* _freelist = nullptr; //管理当前span切分好的小块内存的自由链表bool _isUse = false;//判断当前span是否在被使用,如果没有则可以在PageCache中合成更大页
};//管理某个桶下所有span的数据结构(带头双向循环链表)
class SpanList
{
public://构造初始的SpanListSpanList(){_head = new Span;_head->_next = _head;_head->_prev = _head;}//返回指向链表头结点的指针Span* Begin(){return _head->_next;}//返回指向链表尾结点的指针Span* End(){return _head;}//头插void PushFront(Span* span){Insert(Begin(), span);}//在pos位置前插入//位置描述:prev newspan posvoid Insert(Span* pos, Span* newSpan){assert(pos && newSpan);Span* prev = pos->_prev;prev->_next = newSpan;newSpan->_prev = prev;newSpan->_next = pos;pos->_prev = newSpan;}//头删Span* PopFront(){Span* front = _head->_next;//_head->_next指向的是那个有用的第一个结点而不是哨兵位Erase(front);return front;//删掉后就要用,所以要返回删掉的那块内存的地址 }//删除pos位置的span//位置描述:prev pos nextvoid Erase(Span* pos){assert(pos && pos != _head);//指定位置不能为空且删除位置不能是头节点//暂存一下位置Span* prev = pos->_prev;Span* next = pos->_next;prev->_next = next;next->_prev = prev;}//判断是否为空bool Empty(){return _head->_next == _head;}std::mutex _mtx; //桶锁
private:Span* _head = nullptr;
};ObjectPool.h
#include "Common.h"
template<class T>//模板参数T
class ObjectPool
{
public: //为T类型的对象构造一大块内存空间T* New(){T* obj = nullptr;if (_freelist != nullptr){//头删void* next = *((void**)_freelist);obj = _freelist;_freelist = next;return obj;}else//自由链表没东西才会去用大块内存{//剩余内存不够一个T对象大小时,重新开大块空间if (_remainBytes < sizeof(T)){_remainBytes = 128 * 1024;_memory = (char*)SystemAlloc(_remainBytes >> 13);//SystemAlloc替换了原来这里的mallocif (_memory == nullptr){throw std::bad_alloc();}}obj = (T*)_memory;size_t objsize = sizeof(T) < sizeof(void*) ? sizeof(void*) : sizeof(T);_memory += objsize;_remainBytes -= objsize;}//定位new,显示调用T的构造函数初始化new(obj)T;return obj;}//回收内存void Delete(T* obj)//obj指向要回收的对象的指针{//显示调用析构函数清理对象obj->~T();//头插*(void**)obj = _freelist;_freelist = obj;}private:char *_memory = nullptr;//指向申请的大块内存的指针size_t _remainBytes = 0;//大块内存中剩余可分配字节数void* _freelist = nullptr;//指向存放归还回来内存结点的自由链表
};ConcurrentAlloc.h
#pragma once
#include "ThreadCache.h"
#include "PageCache.h"//线程局部存储TLS:是一种变量的存储方法,这个变量在它所在的线程内是安全可访问的,但是不能被其它线程访问,这样就保持了数据的线程独立性。//后续代码完成后线程会通过调用本函数进行内存申请,类似于malloc
static void* ConcurrentAlloc(size_t size)
{//通过TLS方法,每个线程可以无锁的获取自己专属的ThreadCache对象if (pTLSThreadCache == nullptr){pTLSThreadCache = new ThreadCache;}//获取线程id(检测两个线程是否分到两个不同的pTLSThreadCache)cout << std::this_thread::get_id() << ":" << pTLSThreadCache << endl;//Allocate函数执行时可能会经历很多文件才能返回,返回的结果就是申请到的内存的地址return pTLSThreadCache->Allocate(size);
}//线程会调用本函数释放内存,类似于free
static void ConcurrentAlloc(void* ptr,size_t size)
{assert(pTLSThreadCache);//理论上释放时pTLSThreadCache不会为空pTLSThreadCache->Deallocate(ptr,size);//释放内存结点给ThreadCache
}PageCache.h
#pragma once
#include "Common.h"
#include "ObjectPool.h"class PageCache
{
public:static PageCache* GetInstance(){return &_sInst;}//获取一个管理k页的span,也许获取的是PageCache现存的span,也许是向堆新申请的spanSpan* NewSpan(size_t k);//获取从内存结点的地址到span的映射Span* MapObjectToSpan(void* obj);//接收CentralCache中归还的span,并尝试合并该span的相邻空闲页,使得该span变成一个管理更多页的spanvoid ReleaseSpanToPageCache(Span* span);std::mutex _pageMtx;//pagecache不能用桶锁,只能用全局锁,因为后面可能会有span的合并和分裂
private:SpanList _spanLists[NPAGES];std::unordered_map<size_t, Span*> _idSpanMap;//存放页号和span的映射关系PageCache() {}PageCache(const PageCache&) = delete;static PageCache _sInst;
};CentralCache.h
#pragma once
#include "Common.h"class CentralCache
{
public://获取实例化好的CnetralCache类型的静态成员对象的地址static CentralCache* GetInstance(){return &_sInst;}//为ThreadCache分配一定数量的内存结点size_t FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size);//从SpanList中获取一个非空的span,如果SpanList没有则会去问PageCache申请Span* GetOneSpan(SpanList& list, size_t size);//将ThreadCache归还的重新挂在CentralCache中的某个span上void ReleaseListToSpans(void* start, size_t size);private:SpanList _spanLists[NFREELIST];//单例模式的实现方式是构造函数和拷贝构造函数私有化CentralCache() {}CentralCache(const CentralCache&) = delete;static CentralCache _sInst;//静态成员变量在编译时就会被分配内存
};ThreadCache.h
#pragma once
#include "Common.h"class ThreadCache
{
public://分配ThreadCache中的内存void* Allocate(size_t bytes);//释放ThreadCache中的内存void Deallocate(void* ptr, size_t size);//从CentralCache中获取内存结点void* FetchFromCentralCache(size_t index, size_t size);//释放内存结点导致自由链表结点个数过多时,依据当前自由链表一次性最多向CentralCache申请的内存结点的个数,向CentralCache归还这么多的内存结点void ListTooLong(FreeList& list, size_t size);
private:FreeList _freeLists[NFREELIST];//ThreadCache的208个桶下都是自由链表
};//TLS无锁技术
//static保证该指针只在当前文件可见防止因为多个头文件包含导致的链接时出现多个相同名称的指针
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;PageCache.cpp
#include "PageCache.h"PageCache PageCache::_sInst;//int i = 0;//内存申请的测试代码//从PageCache中获取一个新的非空span
Span* PageCache::NewSpan(size_t k)
{assert(k > 0 && k < NPAGES);//++i;//if (i == 3)//{// cout << "获取一个新的span" << endl;//}//先检查PageCache的第k个桶中有没有span,有就头删if (!_spanLists[k].Empty()){return _spanLists[k].PopFront();}//检查该桶后面的大桶中是否有span,如果有就进行span分裂for (size_t i = k + 1; i < NPAGES; ++i)//因为第一个要询问的肯定是k桶的下一个桶所以i = k + 1{//后续大桶有span,执行span的分裂if (!_spanLists[i].Empty()){Span* nSpan = _spanLists[i].PopFront();Span* kSpan = new Span;//在nSpan头部切一个k页的span下来kSpan->_PageId = nSpan->_PageId;kSpan->_n = k;nSpan->_PageId += k;nSpan->_n -= k;_spanLists[nSpan->_n].PushFront(nSpan);//存储nSpan的首尾页号跟nSpan的映射关系,便于PageCache回收内存时的合并查找_idSpanMap[nSpan->_PageId] = nSpan;_idSpanMap[nSpan->_PageId + nSpan->_n - 1] = nSpan;//在span分裂后就建立页号和span得映射关系,便于CentralCahe在回收来自ThreadCache的小块内存时,找到对应的spanfor (size_t i = 0; i < kSpan->_n; ++i){_idSpanMap[kSpan->_PageId + i] = kSpan;}return kSpan;}}//走到这里就说明PageCache中没有合适的span了,此时就去找堆申请一个管理128页的spanSpan* bigSpan = new Span;void* ptr = SystemAlloc(NPAGES - 1);//ptr存放堆分配的span的起始地址bigSpan->_PageId = (size_t)ptr >> PAGE_SHIFT;//由地址计算页号,页号 = 起始地址 / 页大小,使用位运算更快bigSpan->_n = NPAGES - 1;//新的大span中管理的页的数量为128个_spanLists[bigSpan->_n].PushFront(bigSpan);return NewSpan(k);//重新调用一次自己,那么此时PageCache中就有一个管理k页的span了,可以从PageCache中直接分配了,不需要再考虑该返回什么//可以代码复用,递归消耗的资源很小
}//内存结点的地址->页号->span的映射
Span* PageCache::MapObjectToSpan(void* obj)
{size_t id = ((size_t)obj >> PAGE_SHIFT);//页号 = 内存结点的地址 / 页大小 auto ret = _idSpanMap.find(id);//在_idSpanMap中寻找对应的span地址if (ret != _idSpanMap.end()){return ret->second;//找到了就返回该span的地址}else{assert(false);//找不到就报错return nullptr;}
}//合并页
void PageCache::ReleaseSpanToPageCache(Span* span)
{ //向前合并while (1){size_t prevId = span->_PageId - 1;//获取前页的页号auto ret = _idSpanMap.find(prevId);//由页号确定在哈希表中的位置//通过页号查找不到span,表示该span未在PageCache中出现过,不合并if (ret == _idSpanMap.end()){break;}//该span在PageCache中出现过,但此时被分给了CentralCache,不合并Span* prevSpan = ret->second;if (prevSpan->_isUse == true){break;}//查找的span在PageCache中,但和当前span合并后页数大于128,不合并if (prevSpan->_n + span->_n > NPAGES - 1){break;}_spanLists[prevSpan->_n].Erase(prevSpan);//将PageCache中prevSpan->_n桶处的span进行删除span->_PageId = prevSpan->_PageId;span->_n += prevSpan->_n;delete prevSpan;}//向后合并while (1){size_t nextId = span->_PageId + span->_n;//当前span管理的页的后一个span的首页页号auto ret = _idSpanMap.find(nextId);//获取页号对应的桶位置//通过页号查找不到span,表示该span未在PageCache中出现过,不合并if (ret == _idSpanMap.end()){break;}//该span在PageCache中出现过,但此时被分给了CentralCache,不合并Span* nextSpan = ret->second;if (nextSpan->_isUse == true){break;}//查找的span在PageCache中,但和当前span合并后页数大于128,不合并if (nextSpan->_n + span->_n > NPAGES - 1){break;}span->_n += nextSpan->_n;_spanLists[nextSpan->_n].Erase(nextSpan);delete nextSpan;}_spanLists[span->_n].PushFront(span);//将合并后的span在PageCache中挂起//重新存放首尾页的映射关系_idSpanMap[span->_PageId] = span;_idSpanMap[span->_PageId + span->_n - 1] = span;span->_isUse = false;//将当前span的_isUse设为false
}CentralCache.cpp
#include "CentralCache.h"
#include "PageCache.h"//定义
CentralCache CentralCache::_sInst;//实际可以从CentralCache中获取到的内存结点的个数
size_t CentralCache::FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size)
{size_t index = SizeClass::Index(size);_spanLists[index]._mtx.lock();//上桶锁Span* span = GetOneSpan(_spanLists[index], size);//获取一个非空span//span为空或者span管理的空间为空均不行assert(span);assert(span->_freelist);//尝试从span中获取batchNum个对象,若没有这么多对象的话,有多少就给多少start = end = span->_freelist;size_t actualNum = 1;//已经判断过的自由链表不为空,所以肯定有一个size_t i = 0;//NextObj(end) != nullptr用于防止actualNum小于bathcNum,循环次数过多时NexeObj(end)中的end为nullptr,导致的报错while (i < batchNum - 1 && NextObj(end) != nullptr){end = NextObj(end);++i;++actualNum;}//更新当前span的自由链表中span->_freelist = NextObj(end);NextObj(end) = nullptr;span->_useCount += actualNum;//当前span中有actualNum个内存结点被分配给ThreadCache_spanLists[index]._mtx.unlock();//解桶锁return actualNum;
}//获取非空span
Span* CentralCache::GetOneSpan(SpanList& list, size_t size)
{//遍历CentralCache当前桶中的SpanList寻找一个非空的spanSpan* it = list.Begin();while (it != list.End()){if (it->_freelist != nullptr) {return it;}else{ it = it->_next;}}//先把进来GetOneSpan前设置的桶锁解除,避免其它线程释放内存时被阻塞list._mtx.unlock();size_t k = SizeClass::NumMovePage(size);//SizeClass::NumMovePage(size)计算要向PageCache申请管理多少页的span,即k//走到这里证明CentralCache当前桶中的SpanList中没有非空的span对象了,需要向PageCache申请PageCache::GetInstance()->_pageMtx.lock();//为PageCache整体上锁Span* span = PageCache::GetInstance()->NewSpan(k);PageCache::GetInstance()->_pageMtx.unlock();//为PageCache整体解锁span->_isUse = true;//修改从PageCache获取到的span的状态为正在使用//从PageCache中获取的span是没有进行内存切分的,需要进行切分并挂在其自由链表下//1、计算span管理下的大块内存的起始和结尾地址//起始地址 = 页号 * 页的大小char* start = (char*)(span->_PageId << PAGE_SHIFT);//选择char*而不是void*,为了后续+=size的时移动size个字节//假设span->_PageId = 5,PAGE_SHIFT = 13,5 >> 13 = 40960(字节)//整数值 40960 表示内存中的一个地址位置,通过 (char*) 显示类型转换后,start 就指向了这个内存地址,即span的起始地址char* end = (char*)(start + (span->_n << PAGE_SHIFT));//end指向span的结束地址,span管理的内存大小 = span中页的个数 * 页大小 //2、将start和end指向的大块内存切成多个小块内存,并尾插至自由链表中(采用尾插,使得即使被切割但在物理上仍为连续空间,加快访问速度)//①先切下来一块作为头结点,便于尾插span->_freelist = start;void* tail = start;start += size;//循环尾插while(start < end){NextObj(tail) = start;//当前tail指向的内存块的前4/8个字节存放下一个结点的起始地址,即start指向的结点的地址start += size;//更新starttail = NextObj(tail);//更新tail}NextObj(tail) = nullptr;//及时置空//向CentralCache中当前的SpanList头插前要上锁,防止其它线程同时访问当前的SpanListlist._mtx.lock();list.PushFront(span);//将获取到的span插入当前桶中的SpanListreturn span;//此时该span已经放在了CentralCache的某个桶的SpanList中了,返回该span的地址即可
}//将从ThreadCache获得内存结点归还给它们所属的span,因为这些内存结点可能是由CentralCache同一桶中的不同span分配的
//前一个span用完了,从后一个span中获取,同时前一个span可能还会接收从ThreadCache归还回来的内存结点,下次分配时可能又可以从前面的span分配了,多线程考虑的有点多
void CentralCache::ReleaseListToSpans(void* start, size_t size)
{size_t index = SizeClass::Index(size);_spanLists[index]._mtx.lock();//start指向的是一串内存结点的头结点while (start){void* next = NextObj(start);Span* span = PageCache::GetInstance()->MapObjectToSpan(start);//确定要归还的span//头插内存结点到span中NextObj(start) = span->_freelist;span->_freelist = start;span->_useCount--;//_useCount--表示有一个分配出去的小块内存回到当前span//当前span的_useCount为0表示当前span切分出去的所有小块内存都回来了,直接将整个span还给PageCache,PageCache再尝试进行前后页的合并if (span->_useCount == 0){_spanLists[index].Erase(span);//将当前的span从CentralCache的某个桶处的SpanList上取下//参与到PageCache中进行合并的span不需要自由链表等内容,置空即可span->_freelist = nullptr;span->_next = nullptr;span->_prev = nullptr;_spanLists[index]._mtx.unlock();//不用了就解锁,避免对CentralCache中同一桶的锁竞争PageCache::GetInstance()->_pageMtx.lock();//为PageCache上锁PageCache::GetInstance()->ReleaseSpanToPageCache(span);//尝试合并前后页PageCache::GetInstance()->_pageMtx.unlock();//为PageCache解锁_spanLists[index]._mtx.lock();//合并完后还要再上锁,为了让当前线程走完ReleaseListToSpans函数 }start = next;}_spanLists[index]._mtx.unlock();//当前线程走完ReleaseListToSpans函数,解锁
}ThreadCache.cpp
#include "ThreadCache.h"
#include "CentralCache.h"//分配ThreadCache中的内存
void* ThreadCache::Allocate(size_t size)
{assert(size <= MAX_BYTES);size_t allignSize = SizeClass::RoundUp(size);//获取对齐后的大小size_t index = SizeClass::Index(size);//确认桶的位置if (!_freeLists[index].Empty()){return _freeLists[index].Pop();//头删符合位置的桶的内存块,表示释放出去一块可以使用的内存}else//ThreadCache中没有合适的内存空间{return FetchFromCentralCache(index, allignSize);//向CentralCache的相同位置处申请内存空间}
}//向CentralCache申请内存空间
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{//慢调节算法size_t batchNum = min(_freeLists[index].MaxSize(), SizeClass::NumMoveSize(size));//bathcNum ∈ [2,512]if (_freeLists[index].MaxSize() == batchNum){_freeLists[index].MaxSize() += 1;}//上述部分是满调节算法得到的当前理论上一次性要向CentralCache申请的结点个数//下面是计算实际一次性可从CentralCache中申请到的结点个数//输出型参数,传入FetchRangeObj函数的是它们的引用,会对start和end进行填充void* start = nullptr;void* end = nullptr;//actualNum表示实际上可以从CentralCache中获取到的内存结点的个数size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, batchNum, size);assert(actualNum >= 1);//actualNum必定会大于等于1,不可能为0,因为FetchRangeObj还有GetOneSpan函数if (actualNum == 1){assert(start == end);//此时start和end应该都指向该结点return start;//直接返回start指向的结点即可}else{//如果从CentralCache中获取了多个内存结点,则将第一个返回给ThreadCache,然后再将剩余的内存挂在ThreadCache的自由链表中_freeLists[index].PushRange(NextObj(start), end,actualNum - 1);return start;}
}//释放ThreadCache中的内存
void ThreadCache::Deallocate(void* ptr, size_t size)
{assert(ptr);assert(size <= MAX_BYTES);//找对映射的自由链表桶,并将用完的对象插入进去size_t index = SizeClass::Index(size);_freeLists[index].Push(ptr);//当还回来后当前自由链表的内存结点个数大于当前链表一次性可以向CentralCache申请的内存结点个数_maxsize,就将当前自由链表中_maxsize个内存结点归还给CentralCache//如果只归还多出的那一小部分内存结点(_size-_maxsize)会导致ThreadCache和CentralCache进行频繁的交互,增加系统调用和锁竞争的次数,从而降低整体性能if (_freeLists[index].Size() >= _freeLists[index].MaxSize()){ListTooLong(_freeLists[index], size);}}//链表结点过多
void ThreadCache::ListTooLong(FreeList& list, size_t size)
{//输出型参数void* start = nullptr;void* end = nullptr;list.PopRange(start, end, list.MaxSize());CentralCache::GetInstance()->ReleaseListToSpans(start,size);
}unitTest.cpp
#include "ObjectPool.h"
#include "ConcurrentAlloc.h"void Alloc1()
{for (size_t i = 0; i < 5; ++i){void* ptr = ConcurrentAlloc(6);}
}void Alloc2()
{for (size_t i = 0; i < 5; ++i){void* ptr = ConcurrentAlloc(7);}
}void TLSTest()
{std::thread t1(Alloc1);//创建一个新的线程 t1,并且在这个线程中执行 Alloc1 函数std::thread t2(Alloc2);//创建一个新的线程 t2,并且在这个线程中执行 Alloc2 函数t1.join();t2.join();
}//申请内存过程的调试
void TestConcurrentAlloc()
{//void* p1 = ConcurrentAlloc(6);//void* p2 = ConcurrentAlloc(8);//void* p3 = ConcurrentAlloc(1);//void* p4 = ConcurrentAlloc(7);//void* p5 = ConcurrentAlloc(8);//cout << p1 << endl;//cout << p2 << endl;//cout << p3 << endl;//cout << p4 << endl;//cout << p5 << endl;//尝试用完一整个spanfor (size_t i = 0; i < 1024; i++){void* p1 = ConcurrentAlloc(6);}//如果用完了一个新的span那么p2指向的地址应该是上一个用完的span的结尾地址void* p2 = ConcurrentAlloc(8);cout << p2 <<endl;
}int main()
{//TLSTest();//TestConcurrentAlloc()TestConcurrentAlloc2();return 0;
}调试过程
新增函数TestConcurrentAlloc2
//释放内存过程的调试(单线程)
void TestConcurrentAlloc2()
{//比内存申请时的用例多加两个申请,//因为只有这样才能成功使得某个span的_useCount == 0进入PageCache中//初始_maxsize = 1void* p1 = ConcurrentAlloc(6);//分配一个,_maxsize++ == 2void* p2 = ConcurrentAlloc(8);//不够再申请时因为_maxsize == 2,所以分配2个,用一剩一,++_maxsize == 3void* p3 = ConcurrentAlloc(1);//用了剩的那个,不用++_maxsizevoid* p4 = ConcurrentAlloc(7);//不够再申请时因为_maxsize == 3,所以分配三个,用一剩二,++_maxsize == 4void* p5 = ConcurrentAlloc(8);//用剩余的那两个,不用++_maxsizevoid* p6 = ConcurrentAlloc(6);//用剩余的那两个,不用++_maxsizevoid* p7 = ConcurrentAlloc(8);//不够再申请时因为_maxsize == 4,所以分配4个,用一剩三,++_maxsize == 5void* p8 = ConcurrentAlloc(6);//用剩余的三个,不用++_maxsize//此时_maxsize == 5,_freeLists[0].size == 2,此时负责分配这10个8字节大小内存结点的span的_useCount == 10,后续调试时可以以此为标准//最终代码时不需要传入释放的大小,这里我们先传入ConcurrentFree(p1, 6);ConcurrentFree(p2, 8);ConcurrentFree(p3, 1);ConcurrentFree(p4, 7);ConcurrentFree(p5, 8);ConcurrentFree(p6, 8);ConcurrentFree(p7, 8);ConcurrentFree(p8, 8);
}
内存释放流程图


流程图有问题的话留下言,我改一下😋
~over~
相关文章:
高并发内存池(五):ThreadCache、CentralCache和PageCache的内存回收机制、阶段性代码展示和释放内存过程的调试
目录 ThreadCache的内存回收机制 补充内容1 补充内容2 补充内容3 补充内容4 ListTooLong函数的实现 CentralCache的内存回收机制 MapObjectToSpan函数的实现 ReleaseListToSpans函数的实现 PageCache的内存回收机制 补充内容1 补充内容2 ReleaseSpanToPageCache函…...
探索C++ STL中的Queue与Stack——构建数据处理的基础框架)
STL之stackqueue篇(上)探索C++ STL中的Queue与Stack——构建数据处理的基础框架
文章目录 前言一、stack1.1 定义与基本概念1.2 底层容器1.3 成员函数1.4 使用示例1.5 注意事项1.6 应用场景 二、queue2.1 定义与基本概念2.2 底层容器2.3 成员函数2.4 使用示例2.5 注意事项2.6 应用场景 前言 本文旨在深入探讨C STL中的queue与stack容器,从它们的…...

代码随想录算法训练营Day13
110.平衡二叉树 力扣题目链接:. - 力扣(LeetCode) 后序迭代 class Solution {public boolean isBalanced(TreeNode root) {return getHeight(root)!-1;}public int getHeight(TreeNode root){if(rootnull){return 0;}int leftheightgetHei…...

基于STM32的智能门禁系统
目录 引言项目背景环境准备 硬件准备软件安装与配置系统设计 系统架构关键技术代码示例 RFID数据采集与处理门禁控制实现显示与报警功能应用场景结论 1. 引言 智能门禁系统在现代安防中占据重要地位,通常用于控制进入和离开特定区域的权限。通过基于STM32微控制器…...
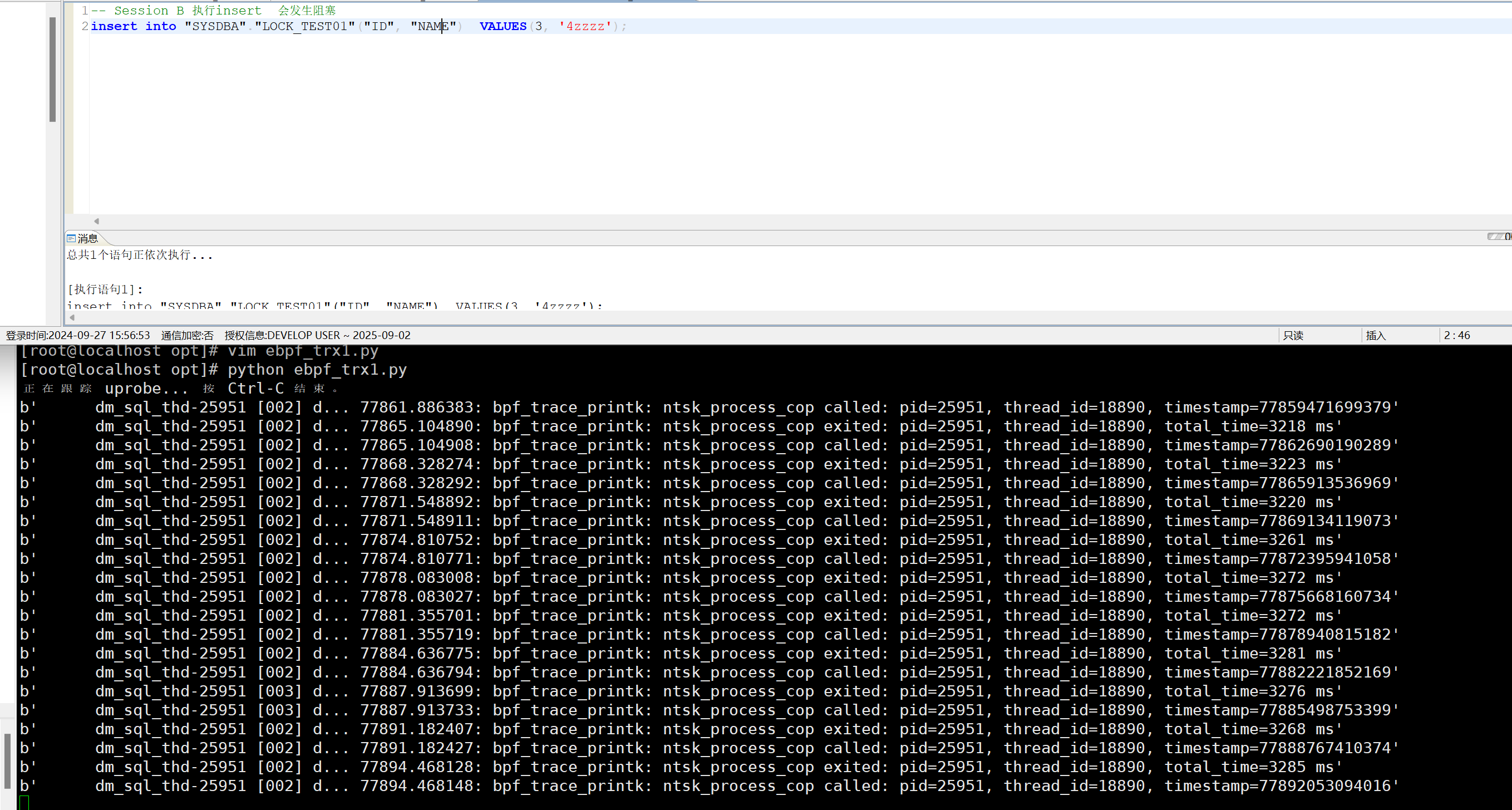
[EBPF] 实时捕获DM数据库是否存在SQL阻塞
1. 介绍 eBPF(extened Berkeley Packet Filter)是一种内核技术,它允许开发人员在不修改内核代码的情况下运行特定的功能。eBPF 的概念源自于 Berkeley Packet Filter(BPF),后者是由贝尔实验室开发的一种网…...

秋招内推--招联金融2025
【投递方式】 直接扫下方二维码,或点击内推官网https://wecruit.hotjob.cn/SU61025e262f9d247b98e0a2c2/mc/position/campus,使用内推码 igcefb 投递) 【招聘岗位】 后台开发 前端开发 数据开发 数据运营 算法开发 技术运维 软件测试 产品策…...

Unity2022.3.x各个版本bug集合及推荐稳定版本
最近升级到Unity2022,发现以下问题,仅作参考 2022.3.0f1 - 2022.3.6f1 粒子渲染到RenderTexture闪屏 https://issuetracker.unity3d.com/issues/android-vulkan-visualisation-corruption-occurs-when-rendering-particles-to-render-texture 2022.3.…...

SparkSQL-性能调优
祝福 在这个举国同庆的时刻,我们首先献上对祖国的祝福: 第一,我们感谢您给我们和平的环境,让我们能快乐生活 第二,祝福我们国家未来的路越走越宽广,科技更发达,人民更幸福 第三,…...
leetcode-链表篇
leetcode-707 你可以选择使用单链表或者双链表,设计并实现自己的链表。 单链表中的节点应该具备两个属性:val 和 next 。val 是当前节点的值,next 是指向下一个节点的指针/引用。 如果是双向链表,则还需要属性 prev 以指示链表中的…...

JetLinks物联网平台微服务化系列文章介绍
橙蜂智能公司致力于提供先进的人工智能和物联网解决方案,帮助企业优化运营并实现技术潜能。公司主要服务包括AI数字人、AI翻译、AI知识库、大模型服务等。其核心价值观为创新、客户至上、质量、合作和可持续发展。 橙蜂智农的智慧农业产品涵盖了多方面的功能&#x…...

【QT Quick】基础语法:导入外部QML文件
在实际项目中,代码通常分为多个文件进行模块化管理,这样可以方便代码重用,例如统一风格或共享功能模块。我们将在此部分学习如何创建 QML 项目,并演示如何访问外部代码,包括其他 QML 文件、库文件以及 JS 代码。 准备…...

Llama 系列简介与 Llama3 预训练模型推理
1. Llama 系列简介 1.1 Llama1 由 Meta AI 发布,包含 7B、13B、33B 和 65B 四种参数规模的开源基座语言模型 数据集:模型训练数据集使用的都是开源的数据集,总共 1.4T token 模型结构:原始的 Transformer 由编码器(…...

【AIGC】ChatGPT提示词助力自媒体内容创作升级
博客主页: [小ᶻZ࿆] 本文专栏: AIGC | ChatGPT 文章目录 💯前言💯高效仿写专家级文章提示词使用方法 💯CSDN博主账号分析提示词使用方法 💯自媒体爆款文案优化助手提示词使用方法 💯小结 💯…...

SSTI基础
<aside> 💡 简介 </aside> 原理 又名:Flask模版注入 模版种类 **Twig{{7*7}}结果49 jinja2{{7*7}}结果为7777777 //jinja2的常见参数是name smarty7{*comment*}7为77**<aside> 💡 flask实例 </aside> **from …...

10.1软件工程知识详解上
软件工程概述 软件开发生命周期 软件定义时期:包括可行性研究和详细需求分析过程,任务是确定软件开发工程必须完成的总目标,具体可分成问题定义、可行性研究、需求分析等。软件开发时期:就是软件的设计与实现,可分成…...
)
03Frenet与Cardesian坐标系(Frenet转Cardesian公式推导)
Frenet转Cardesian 1 明确目标 已知车辆质点在Frenet坐标系下的状态: Frenet 坐标系下的纵向坐标: s s s纵向速度: s ˙ \dot{s} s˙纵向加速度: s \ddot{s} s横向坐标: l l l横向速度: l ˙ \dot{l} l…...

knowLedge-Vue I18n 是 Vue.js 的国际化插件
1.简介 Vue I18n 是 Vue.js 的国际化插件,它允许开发者根据不同的语言环境显示不同的文本,支持多语言。 Vue I18n主要有两个版本:v8和v9。v8版本适用于Vue2框架。v9版本适用于Vue3框架。 2. 翻译实现原理 Vue I18n 插件通过在 Vue 实例中注…...

【开源免费】基于SpringBoot+Vue.JS微服务在线教育系统(JAVA毕业设计)
本文项目编号 T 060 ,文末自助获取源码 \color{red}{T060,文末自助获取源码} T060,文末自助获取源码 目录 一、系统介绍二、演示录屏三、启动教程四、功能截图五、文案资料5.1 选题背景5.2 国内外研究现状5.3 可行性分析 六、核心代码6.1 查…...

expressjs 中的mysql.createConnection,execute 怎么使用
在 Express.js 应用中使用 MySQL 数据库,你通常会使用 mysql 或 mysql2 这样的库来创建和管理数据库连接,并执行查询。然而,mysql.createConnection 并不直接提供 execute 方法。相反,你可以使用 query 方法来执行 SQL 语句。 以…...

每日一题|983. 最低票价|动态规划、记忆化递归
本题求解最小值,思路是动态规划,但是遇到的问题是:动态规划更新的顺序和步长,以及可能存在的递归溢出问题。 1、确定dp数组含义 dp[i]表示第i天到最后一天(可能不在需要出行的天数里),需要花费…...

Frida+Fart实战:在ART Dex加载临界点精准dump二代壳内存Dex
1. 这不是“又一个脱壳教程”,而是对Android加固演进逻辑的现场解剖你打开一个市面上主流的金融类App,用adb shell pm list packages | grep bank随手一搜,发现它被某知名商业加固厂商打了“二代壳”——启动慢、内存占用高、关键so文件加密、…...

BilibiliDown音频提取终极指南:3种方法从B站视频提取高质量音乐
BilibiliDown音频提取终极指南:3种方法从B站视频提取高质量音乐 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_…...

Windows HEIC缩略图预览:告别iPhone照片在Windows的“盲盒“时代
Windows HEIC缩略图预览:告别iPhone照片在Windows的"盲盒"时代 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails …...

从零开始构建FPGA项目:ADI HDL开发实战经验分享
从零开始构建FPGA项目:ADI HDL开发实战经验分享 【免费下载链接】hdl HDL libraries and projects 项目地址: https://gitcode.com/gh_mirrors/hd/hdl ADI HDL(Analog Devices HDL)是一套功能强大的硬件描述语言库,专为FPG…...
)
VMware虚拟机突然断网?别慌,试试这个NAT模式一键重置法(附主机WiFi适配器设置)
VMware虚拟机断网急救指南:NAT模式重置与主机适配器深度解析 从一次紧急调试说起 深夜11点23分,程序员老张正在虚拟机里调试一个即将上线的微服务接口。突然,git pull命令卡住不动,ping测试显示"Destination Host Unreachabl…...

XXMI启动器:6款热门二次元游戏模组一站式管理终极指南
XXMI启动器:6款热门二次元游戏模组一站式管理终极指南 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher XXMI启动器是一款专为二次元游戏爱好者设计的开源模组管理平台…...

Ccursor安装使用
首先进入官文 https://cursor.com/下载,然后按照步骤进行安装,一般都是直接默认安装(修改软件位置的话可以修改下去,默认是在c盘,可能会后面用的多了造成卡顿),直到安装完成, 点击使…...
)
告别丢包!手把手教你用Vivado/PLL调优RTL8211的RXC时钟相位(FPGA千兆以太网篇)
FPGA千兆以太网时序优化实战:用PLL驯服RTL8211的RXC时钟相位 当你在调试FPGA与RTL8211千兆以太网PHY芯片的RGMII接口时,是否遇到过这样的场景:硬件连接一切正常,链路也能正常建立,但就是会随机出现数据包丢失或CRC校验…...
深入RT-DETR混合编码器:我是如何把Transformer计算瓶颈‘砍掉’一半的
深入RT-DETR混合编码器:我是如何把Transformer计算瓶颈‘砍掉’一半的 在目标检测领域,实时性能一直是工业界和学术界共同追求的圣杯。当传统YOLO系列通过精心设计的卷积网络不断刷新速度记录时,Transformer架构的DETR家族却因沉重的计算负担…...

从零到一:AI 3D建模革命,5分钟让图片“活“起来的完整实战指南
从零到一:AI 3D建模革命,5分钟让图片"活"起来的完整实战指南 【免费下载链接】TripoSR TripoSR: Fast 3D Object Reconstruction from a Single Image 项目地址: https://gitcode.com/GitHub_Trending/tr/TripoSR 你是否曾梦想过&#…...