初识TCP/IP协议
回顾上文
来回顾一下TCP协议的特性,有一道比较经典的题:如何使用UDP实现可靠传输,通过应用程序的代码,完成可靠传输的过程?
原则,TCO有啥就吹啥,引入滑动窗口,引入流量控制,引入拥塞控制,引入1确认应答(ack),引入序号+确认序号,引入超时重传
2 Question:
在TCP报文格式里有16位紧急指针,这个指针的作用是什么?
在TCP报文格式中RST中还有一个PSH是什么作用?
Answer:
TCP带外数据传输,正常的TCP传输的数据,可以认为是“业务数据”,除了业务数据之外,还有一些特殊的,用来控制TCP自身工作机制,特殊的数据包
PSH是催促对方尽快给自己返回回应

网络层的主要协议为IP协议,当前协议叫做
TCP/IP协议

IP协议与“交换机开发”可能会密切联系,所以这里我们不像TCP那么详细介绍
网络层主要做的事情
- 路径规划(路由选择)
- 地址管理,IP地址的规则和特点
其中4位版本,指的是IPv4,如果是6位版本则指的是IPv6,上述结构是IPv4的结构,下图为IPv6结构

其他的IP版本,可能是存在于实验室中,但是没有真正大规模商用
4位首部长度:0-0xf,0-15,也是以4字节位单位的,IP报头最长就是60字节,最短是20字节
8位服务类型(TOS):type of service,其实只有4位有效,这四位是互斥的,只有其中以为为1
由AI可知:
在IPv4协议中,服务类型(Type of Service,ToS)字段是8位长,用于指示数据包的服务质量要求。这个字段在IPv4头部中,用于指导网络设备如何处理数据包,例如优先级、延迟、吞吐量和可靠性等。
IPv4头部中的服务类型字段在RFC 1349中被定义为一个3位的优先级字段和4位的ToS字段的组合。后来,这个字段在RFC 2474中被重新定义为区分服务(Differentiated Services,DS)字段。
在RFC 1349中,服务类型字段被分为两个主要部分:
- 前3位:优先级(Precedence)
- 用于确定数据包的优先级,值从000到111,数值越小优先级越高。
- 后5位:ToS字段
- 用于指定数据包的服务质量要求,包括:
- - 延迟(Delay)
- - 吞吐量(Throughput)
- - 可靠性(Reliability)
- - 代价(Cost)
RFC 1349定义了几种ToS值,用于不同的服务类型:
- - 00000:正常服务(Normal Service)
- - 00001:最小延迟(Minimize Delay)
- - 00010:最大吞吐量(Maximize Throughput)
- - 00011:最大可靠性(Maximize Reliability)
- - 00100:最小代价(Minimize Cost)
- - 00101:到网络控制流(Network Control)
- - 00110: 无改变(Unspecified)
- - 00111: 到网络控制流,但优先级更高(Network Control, but higher priority)
在RFC 2474中,ToS字段被重新定义为区分服务字段,用于实现更细粒度的服务质量控制。这个字段被分为两个子字段:
- 6位:区分服务代码点(DSCP)
- - 用于定义不同的流量类别和服务等级。
- 2位:拥塞控制(ECN)
- - 用于指示数据包是否可以被网络设备标记为遇到拥塞。
DSCP字段定义了多种服务代码点,用于不同的服务类别,如AF(Assured Forwarding)和EF(Expedited Forwarding)等。
请注意,实际的服务质量还取决于网络设备和服务提供商的配置和支持。
16位总长度(字节数):整个IP数据包的长度,报头 + 载荷,总长度,去掉IP首部长度,剩下的就是TCP数据包的总长度,去掉TCP报头长度,剩下的就是载荷长度了,64KB,如果携带的载荷,超出长度上限,超出长度上限,IP就会自动拆分成多个数据包,每个数据包携带一部分发送到对方之后,再拼接好


16位标识:用来区分哪些数据包要进行合并
3位标志:只有两个有效,其中一个用来表示,该数据包是否触发了拆包的效果(是否需要组包),另一个标志位,结束标记,当前包就是最后一个需要租包的部分;上述组包过程,完全是IP本身负责的,和载荷中保存啥东西没有任何关系,也不需要关心
Question:IP都能组包了,UDP为啥还有64KB的限制,借助IP组包能力不能突破UDP的限制吗?
Answer:直观上看起来,把上述数据,拆成多分,分多个IP数据包发送,好像也是OK
传输过去之后,上述数据也能合并还原成原始的模样
这里还原出来的数据,要交给UDP进一步的进行使用,在UDP这一层,要对上述数据进行解析,取出8个字节,作为报头,剩下的作为载荷,剩下的载荷到底多长?就会尝试从报头中,报文长度字段来读取,读出来的数字,最多还是64KB



8位生存时间(ttl):IP数据包要在网络上转发,限制一个1数据包在网络上转发的最大次数,一个IP数据包,初识情况下,有一个TTL的值(32/64这样的整数),这个次数每次经过一个路由器的转发就要-1,减到0了这个数据包就要丢弃掉,这个初识值是可配置的(系统内核的参数),关键问题,64这样的数值是否够用呢?通常情况下,64其实够用了,这里背后,有一个”六度空间“理论
六度空间理论,也被称为小世界理论(Six Degrees of Separation),是一个社会学理论,它认为世界上任何两个互不相识的人,最多只需要通过六个中间人就能建立起联系。这个理论最早由匈牙利作家弗里吉什·卡林西(Frigyes Karinthy)在1929年的短篇小说《链》中提出。
理论背后的基本思想是,虽然世界上有数十亿人口,但人们通过社交网络相互连接,形成了一个巨大的、相互关联的网络。在这个网络中,人与人之间的联系可以通过朋友、家人、同事、同学等社会关系进行传递。
这个理论在20世纪60年代由美国社会学家斯坦利·米尔格拉姆(Stanley Milgram)通过一系列实验得到了进一步的推广和验证。米尔格拉姆的实验通常被称为“小世界实验”,他通过邮寄包裹的方式,试图证明普通人之间平均只需要通过几个中间人就能建立起联系。
六度空间理论在社会学、心理学、网络科学等领域都有广泛的应用,它揭示了人类社会网络的紧密性和复杂性。随着互联网和社交媒体的兴起,这个理论也被用来解释信息如何在网络中快速传播。
此外,六度空间理论也启发了许多文化作品,包括电影、电视剧、书籍和游戏等,它们通常以探索人与人之间的联系和关系为主题。
值得注意的是,虽然六度空间理论在理论上是有趣的,但它并不意味着每个人都能够轻易地通过六个人与世界上的任何其他人建立联系。实际上,能否建立起这样的联系还取决于许多因素,如社会地位、文化背景、地理位置等。
路由器转发IP数据包的时候,每个路由器,其实不了解整个网络的全貌,但是能够知道他相邻的设备有哪些,所以,即使通过少数的几次跳转,也可以涵盖到大量的设备,通常来说,64这样的数值就够用的,64也不一定就非得是这个数字,都是可配置的,32/128
8位协议:这里就描述了在和部分是哪种协议的数据包,交给TCP还是UDP还是其他的协议,一个数据包在分用的时候,要交给上层的哪个协议,都是有明确的声明的,传输层->应用层:端口号来区分,网络层->传输层:报头里,类型字段,区分是IP数据包,还是其他的数据包
16位首部校验和:校验和,只是针对IP首部进行校验,载荷部分不关心,载荷部分UDP/TCP,都有各自的校验和,IP只需要管好自己即可
32位源IP地址:0-42亿9千万
32位目的IP地址:原则上说,不同的设备IP地址应该是唯一的,不重复的,上述这个数字,在今天是不太够用的,尤其是移动互联网
一个IP地址,是一个32位整数,为了能够让人更方便的观察,把32位的整数通常表示成"点分十进制"的形式
Question:IP地址不够用,咋办
Answer:
动态分配IP地址,某个设备上网就分配,不上网就不分配,这样的机制,只能缓解,没法从根本上解决问题,IP地址没有变多
NAT机制,网络地址映射,首先把IP地址,分成两个大类:私网IP(局域网内部使用),通常有10.*,172,16-172.31.*,192.168.*,公网IP(广域网使用的),此时约定,公网IP唯一,私网IP允许在不同的局域网重复,当前虽然能上网的设备非常多,但是绝大部分都是在局域网中的,局域网1中的设备ip可以和局域网2中的设备ip重复
Question:如果引入上述私网IP,如何进行通信呢?
Answer:
- 同一个局域网内部,设备之间进行通信,由于一个局域网内部的设备之间的IP是不能重复的,此时这些设备都能正常相互交互
- 广域网设备和广域网设备之间通信,要求广域网中的设备IP本身就是唯一的,也能正常交互
- 局域网1中的设备A尝试局域网2中的设备2,这种情况认为不允许进行访问
- 局域网中的设备主动访问广域网设备(NAT技术)
- 广域网设备主动访问局域网设备,这种情况认为不允许进行访问
因此,如果需要进行上述的局域网设备和局域网设备之间的通信,往往需要搭配广域网中的服务器进行数据转发

我的电脑要发送一个数据给csdn服务器,此时我的电脑就会构造出一个IP数据包
运营商路由器,也可以把它当作一个NAT设备,它就会对中间经过的数据包,经过网络地址转换,当内网设备经过运营商路由器访问外网的时候,它就会把IP数据包中的源IP,替换成它自己的IP,运营商路由器进行上述替换,目的就是为了让自己的外网ip取代之前的内网ip

到达csdn服务器之后,csdn就会看到一个有5.6.7.8这样的设备给它发了一个请求,csdn服务器对于我自己电脑真实的内网IP是一无所知的
我自己电脑局域网内的其他电脑也是通过运营商路由器访问公网的,所以这个局域网中的几百台/几千台设备,都是通过一个外网IP,在公网上进行传输的,运营商路由器,一个外网IP,就能表示几千台甚至几万台这样的内网中的设备

这实际上对应的是运营商的公网IP,这个公网IP不仅仅代表我电脑的,还代表我手机的公网IP,只有运营商的路由器设备才有公网IP,你自己买的路由器,是没有公网IP的
Question:手机热点代表什么?
Answer:让手机变成路由器
- 从csdn服务器开始说起,csdn要返回相应数据,此时csdn只能看到5.6.7.8,于是csdn构造的IP数据如下图

- 这个数据包就会返回给运营商路由器
- 运营商路由器内部维护了一个”映射关系“,就会记录说当前这个相应对应的
- 查询到结果之后,就可以把IP和端口替换回来了

- 随后,这个数据包就会传输回我自己的电脑了
- 假设我的电脑和手机同时访问csdn,此时


- 源端口是系统分配的一个随机的空闲端口,这俩端口大概率是不同的,端口号碰巧一样,小概率事件,为了防止端口不够,所以才会分区
- 此时这两台设备同时构造IP数据包发送给运营商路由器


NAT机制

通过AI可知:
NAT(Network Address Translation,网络地址转换)是一种在IP数据包通过设备如路由器时,将数据包中的源IP或目的IP地址转换为另一个IP地址的技术。NAT允许一个整体机构以一个公用IP地址出现在Internet上,同时内部网络可以使用私有IP地址。这样不仅可以有效利用公网IP地址,还可以隐藏内部网络结构,提高安全性。
NAT的基本原理包括静态NAT、动态NAT和端口地址转换(PAT,也称为NAPT或端口复用):
- 静态NAT:为内部网络中的每个主机永久映射一个外部网络中的合法地址,多用于服务器。
- 动态NAT:使用一个地址池,动态地将内部网络中的主机映射到外部网络的地址池中的地址。
- NAPT/PAT:允许多个内部地址映射到一个外部地址的不同端口上,实现多个私有IP地址共享一个公共IP地址上网。
NAT的工作原理是:
- 内部主机发送数据包时,NAT设备(如路由器)将源私有IP地址转换为公共IP地址。
- 数据包在互联网中传输时,其他设备看到的是转换后的公共IP地址。
- 当外部服务器响应数据包时,NAT设备将目标公共IP地址转换回内部的私有IP地址,确保数据可以正确返回到原始请求的主机。
NAT技术的优点包括:
- - 节省公网IP地址:多个私有IP地址可以共享一个公共IP地址。
- - 增强安全性:内部网络的真实结构被隐藏,减少了外部攻击的风险。
- - 支持负载均衡:可以通过转换不同的源IP地址和端口来实现。
NAT技术的缺点包括:
- - 外部访问限制:外部网络无法直接访问内部网络的特定设备。
- - 影响某些服务:基于IP地址的安全策略和服务可能无法正常工作。
- - 对称性限制:需要考虑到对称性,即同一个内部主机的请求在转换后的IP地址和端口号要保持一致。
此外,还有几种特殊的NAT类型,如限制锥型NAT、端口限制锥型NAT和对称NAT,它们在映射时对端口和IP地址有不同的限制和要求。
NAT技术广泛应用于家庭、学校和企业网络中,使得多个设备可以共享一个公网IP地址上网,同时也为内部网络提供了一定程度的安全保护。随着IPv6的推广,NAT技术的重要性可能会逐渐降低,因为IPv6提供了几乎无限的地址空间。
从IP地址看不出来如何进行中转的,得看网线是如何接的,需要看网络拓扑结构,路由器负责分配IP地址,也可以手动设置

这代表路由器自动给你分配,路由器有一个功能DHCP,配置错了,就上不了网了
现实世界就是通过动态分配和NAT解决的IP不够用的问题:虽然能解决,但是这样的方案就给网络复杂程度增加了不少,而且也没有从根本上解决问题,如果随着设备进一步的增多(一个外网NAT设备上面最多只能有6w多个表项)
IPv6是终极方案:引入了更长的字节数来表示IP地址,IPv6拿16个字节来表示IP地址,128位,这是一个天文数字,足以给地球上每一粒沙子分配一个唯一的IP
为啥现在世界上还是以IPv4为主呢?IPv4和IPv6不兼容,最开始使用IPv4的时候,大家用的路由器,交换机,网卡,各种设备,都是支持IPv4的设备,如果要升级成IPv6就得更换成支持IPv6的路由器/交换机/网卡,为啥NAT技术能火,NAT是纯软件的方案,不需要换设备,只要更新一下路由器上面的程序(固件),成本很低
IP地址基本规则
网段划分
同一个局域网的主机,要按照一定的规则分配IP地址,把一个IP地址(IPv4)分成两个部分,前半部分,网络号->标识局域网,后半部分,主机号->区分同一个局域网中的不同主机,同一个局域网内部,主机之间的IP,网络号相同,主机号要不同,局域网之间,网络号可以相同,但是两个相邻的局域网(同一个路由器,wan口和lan处于两个不同局域网),路由器就是连接两个局域网之间的桥梁,一旦相邻的局域网网络号相同,没法上网了
一个IP地址是32位,那些是网络号,哪些是主机号呢?这里引入概念:’
子网掩码(Mask)
也是32位整数,左半部分都是1,右半部分都是0,不会01交替出现,

此处子网掩码就是1111.1111.1111.0000,此处前三个字节,24位是网络号,后8位是主机号,如果让路由器自动分配,生成IP肯定是符合要求的,如果你自己设置,就需要遵守上述规则
前面说的搭配子网掩码的网段划分,是现在的方法,上古时期,还流传一种划分方式,ABCDE五类
这种做法会浪费大量的IP
特殊的IP地址
- 主机号全0:这样的IP表示网段,不应该分配给具体的主机,192.168.100.0,这样的ip不能设置到主机上,设置上去也上不了网
- 主机号全1(二进制):这样的IP表示广播IP,往广播IP上发送数据,此时就会发送给局域网中的所有设备(TCP不支持广播,UDP才能支持)
- 127.*:这样的地址,环回IP(loopback),127.0.0.1,往这个ip发送数据,就是自己来接受,微信,可以自己给自己发消息,即使你的电脑不联网,也是能使用的,即使你的电脑不联网,也是能使用的,mysql/tcp服务器/udp服务器,客户端和服务器在同一个主机上,此时就可以使用环回IP来进行访问
- 你的电脑上会有一个虚拟的网卡,环回网卡,这个网卡的IP就是127.0.0.1,但凡是往127.0.0.1上发送的数据,都是通过这个网卡来转发的,转发效果就是发给自己,接下来自己就能收到
路由选择
找路,例如高德地图的导航,地图软件的导航是立足于全局的数据,给你得到一个”最优解“,地图厂商会有一些渠道,把地理数据给收集好,最优解不是说只有一种,按照不同的角度,得到最优解(路线最短,时间最短,少换乘,只做地铁)
网络中,路由器的寻路,则无法做到”最优解“,只能做到”较优解“,每一台路由器,无法知道整个网络的全貌,但是可以知道它附近的网络设备情况是咋样的,对于路由器来说,在进行转发数据的时候,很可能是无法一下就知道,目的IP所对应的设备该如何达到,只能通过"启发式"”探索式“,逐渐找到最终的目标
路由的过程, 是⼀跳⼀跳(Hop by Hop) "问路" 的过程. 所谓 "⼀跳" 就是数据链路层中的⼀个区间. 具体在以太⽹中指从源MAC地址到⽬的MAC地址之间的帧 传输区间.
- IP数据包的传输过程也和问路⼀样
- 当IP数据包, 到达路由器时, 路由器会先查看⽬的IP
- 路由器决定这个数据包是能直接发送给⽬标主机, 还是需要发送给下⼀个路由器
- 依次反复, ⼀直到达⽬标IP地址
- 那么如何判定当前这个数据包该发送到哪⾥呢? 这个就依靠每个节点内部维护⼀个路由表

- 路由表可以使⽤route命令查看
- 如果⽬的IP命中了路由表, 就直接转发即可
- 路由表中的最后⼀⾏,主要由下⼀跳地址和发送接⼝两部分组成,当⽬的地址与路由表中其它⾏都不 匹配时,就按缺省路由条⽬规定的接⼝发送到下⼀跳地址
启发式的过程:走着瞧~
每个路由器,虽然无法感知到整个网络结构的全貌,但是可以认识到它周围的网络设备,路由器中会维护一个数据结构,路由表,记录了周围的朋友都是啥样的
当路由器收到数据的时候,就会根据目的IP,查询路由表,看看在路由表中是否存在,如果存在,好办,直接按照目标的位置继续转发即可,如果不存在,就会从朋友中,挑选一个最”神通广大“的朋友,把这个数据交给这个最神通广大的朋友,让它来帮忙想办法(路由器的”下一跳表项“)
相关文章:
初识TCP/IP协议
回顾上文 来回顾一下TCP协议的特性,有一道比较经典的题:如何使用UDP实现可靠传输,通过应用程序的代码,完成可靠传输的过程? 原则,TCO有啥就吹啥,引入滑动窗口,引入流量控制&#x…...

使用 classification_report 评估 scikit-learn 中的分类模型
介绍 在机器学习领域,评估分类模型的性能至关重要。scikit-learn 是一个功能强大的 Python 机器学习工具,提供了多种模型评估工具。其中最有用的函数之一是 classification_report,它可以全面概述分类模型的关键指标。在这篇文章中ÿ…...

高翔【自动驾驶与机器人中的SLAM技术】学习笔记(十)高翔书中的细节:参考链接;卫星导航;ESKF
一、 参考链接 我认真查找了好多地方:结果在最后一页。 作者GITHUB链接如下: https://github.com/gaoxiang12/slam_in_autonomous_driving 全书所有参考链接 :如下 1 https://www.sae.org/standards/content/j3016_202104 2 http://www.evinchina.com/articleshow-217.htm…...

【在Python中爬取网页信息并存储】
在Python中爬取网页信息并存储的过程通常涉及几个关键步骤:发送HTTP请求、解析HTML内容、提取所需数据,以及将数据存储到适当的格式中(如文本文件、CSV文件、数据库等)。以下是一个更详细的指南,包括示例代码ÿ…...

ESP32 Bluedroid 篇(1)—— ibeacon 广播
前言 前面我们已经了解了 ESP32 的 BLE 整体架构,现在我们开始实际学习一下Bluedroid 从机篇的广播和扫描。本文将会以 ble_ibeacon demo 为例子进行讲解,需要注意的一点是。ibeacon 分为两个部分,一个是作为广播者,一个是作为观…...

【通配符】粗浅学习
1 背景说明 首先要注意,通配符中的符号和正则表达式中的特殊符号具备不同的匹配意义,例如:*在正则表达式中表示里面是指匹配前面的子表达式0次或者多次,而在通配符领域则是表示代表0个到无穷个任意字符。 此外,要注意…...

Spring MVC 常用注解
目录 基础概念 常用注解介绍 基础概念 1、MVC :代表一种软件架构设计思想,通俗的理解:客户端发送请求到后台服务器的Controller(C),控制器调用Model(M)来处理业务逻辑,处理完成后,返回处理后的数据到Vie…...

水泵模块(5V STM32)
目录 一、介绍 二、传感器原理 1.尺寸介绍 2.继电器控制水泵电路原理图 三、程序设计 main.c文件 bump.h文件 bump.c文件 四、实验效果 五、资料获取 项目分享 一、介绍 水泵模块(bump)通常是指用于液体输送系统的组件,它负责将水或其他流体从低处提…...

需求6:如何写一个后端接口?
这两天一直在对之前做的工作做梳理总结,不过前两天我都是在总结一些bug的问题。尽管有些bug问题我还没写文章,但是,我今天不得不先停下对bug的总结了。因为在国庆之后,我需要自己开发一个IT资产管理的功能,这个功能需要…...
:文件权限控制及文件操作相关的命令)
《Linux从小白到高手》理论篇(五):文件权限控制及文件操作相关的命令
本篇介绍Linux文件权限控制及文件操作相关的命令,看完本文,有关Linux文件权限控制及文件操作相关的常用命令你就掌握了99%了。 文件权限 在介绍文件权限之前先来复习下Linux的文件类型,始终记住那句话:Linux系统下,一…...
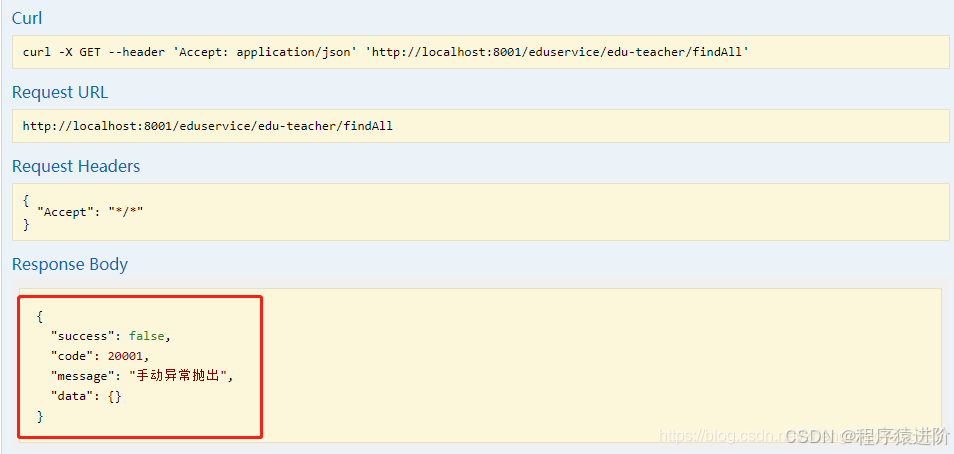
异常场景分析
优质博文:IT-BLOG-CN 为了防止黑客从前台异常信息,对系统进行攻击。同时,为了提高用户体验,我们都会都抛出的异常进行拦截处理。 一、异常处理类 Java把异常当做是破坏正常流程的一个事件,当事件发生后,…...

Leetcode: 0001-0010题速览
Leetcode: 0001-0010题速览 本文材料来自于LeetCode solutions in any programming language | 多种编程语言实现 LeetCode、《剑指 Offer(第 2 版)》、《程序员面试金典(第 6 版)》题解 遵从开源协议为知识共享 版权归属-相同方式…...
计算机的错误计算(一百一十二)
摘要 计算机的错误计算(六十三)与(六十八)以及(六十九)分别探讨了大数与 附近数以及 附近数 的余切函数的计算精度问题。本节讨论余切序列(即迭代 )的计算精度问题。 余切序列是指…...
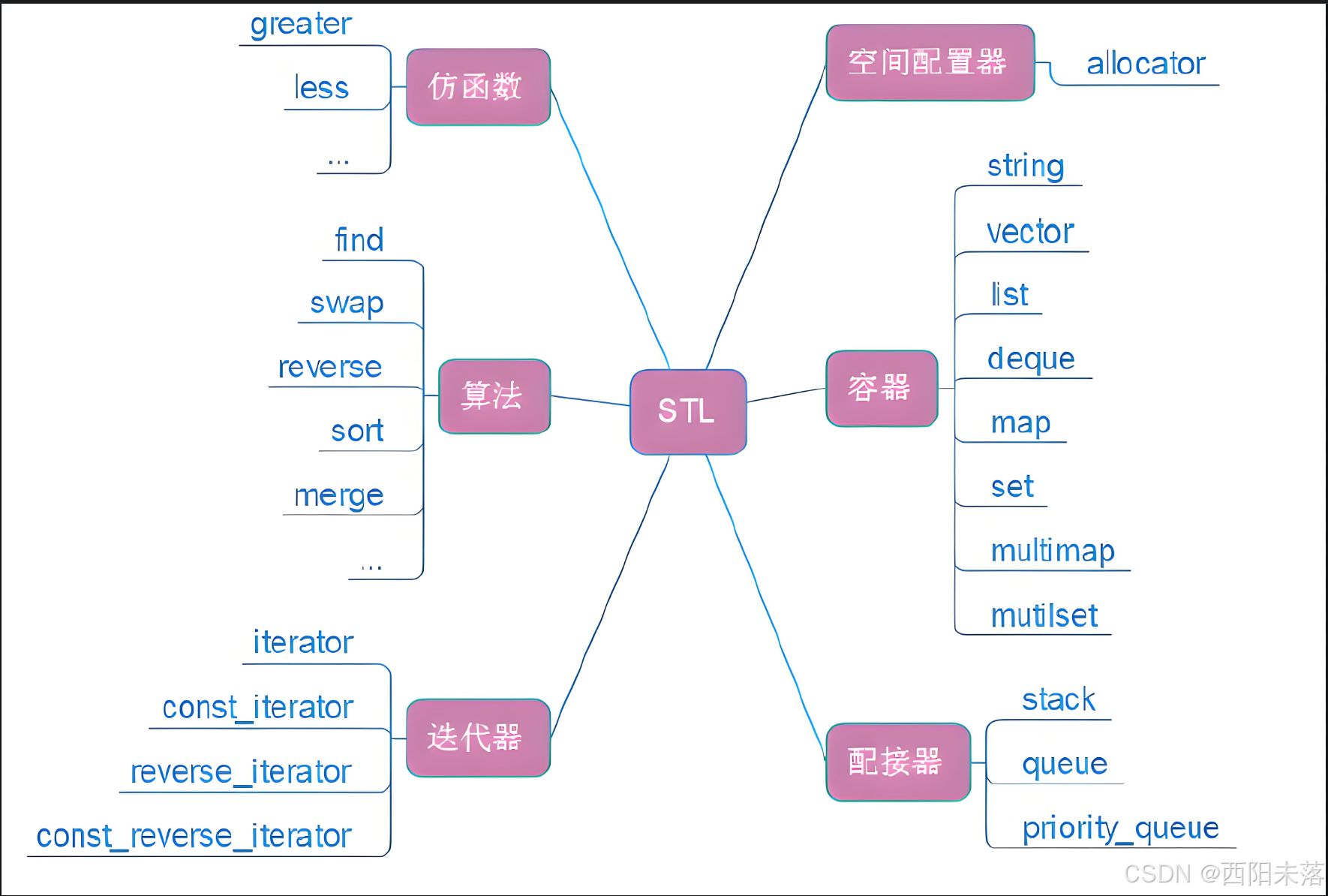
C++基础(7)——STL简介及string类
目录 1.STL简介 1.1什么是 1.2STL的历史版本 1.3STL的六大组件 编辑 1.4有用的网址 2.string类 2.1string的多种定义方式 2.2string的插入 2.2.1尾插(push_back) 2.2.2insert插入 2.3拼接(append) 2.4删除 2.4.1尾…...

配置Nginx以支持通过HTTPS回源到CDN
要配置Nginx以支持通过HTTPS回源到CDN,你需要确保Nginx已正确配置SSL,并且能够处理来自CDN的HTTPS请求。以下是一个简化的Nginx配置示例,它配置了SSL并设置了代理服务器参数以回源到CDN: server {listen 443 ssl;server_name you…...
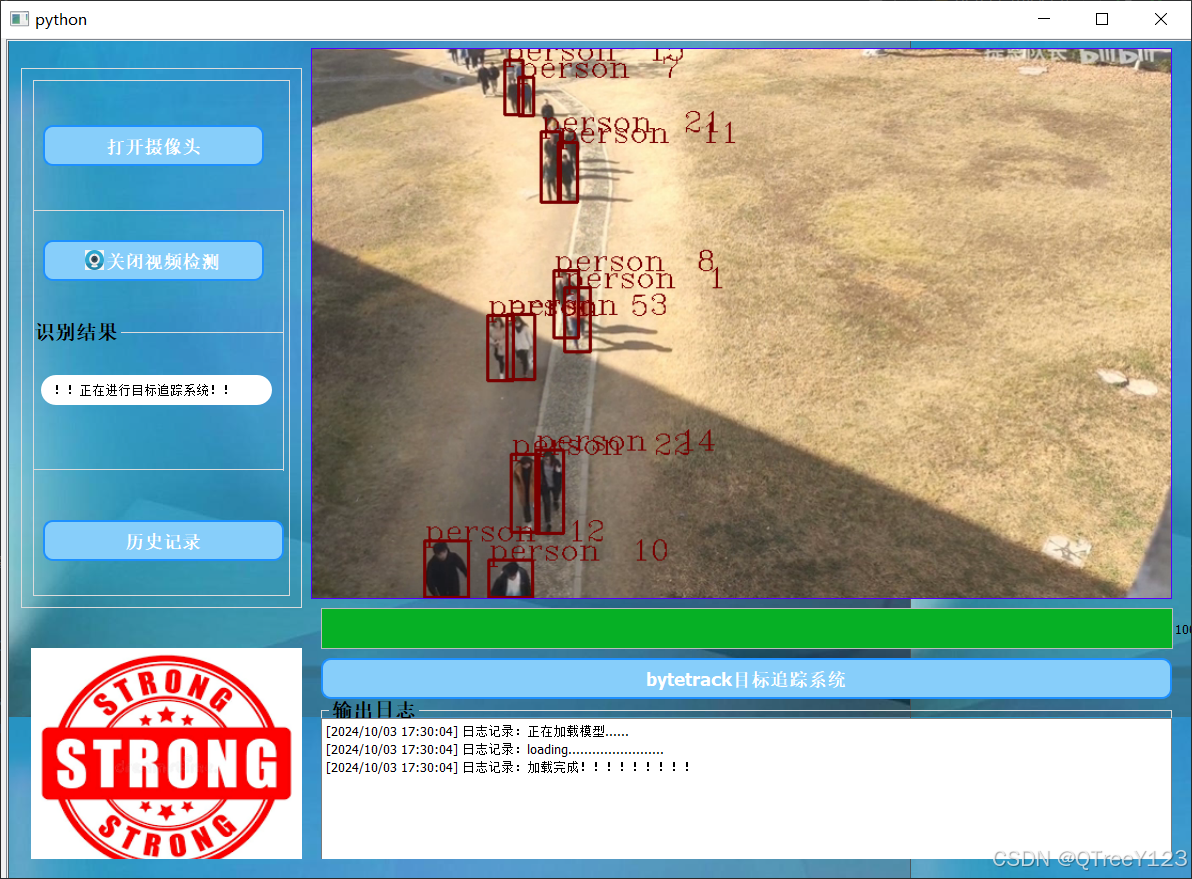
yolov10+strongsort的目标跟踪实现
此次yolov10deepsort不论是准确率还是稳定性,再次超越了之前的yolodeepsort系列。 yolov10介绍——实时端到端物体检测 YOLOv10 是清华大学研究人员在 UltralyticsPython 清华大学的研究人员在 YOLOv10软件包的基础上,引入了一种新的实时目标检测…...
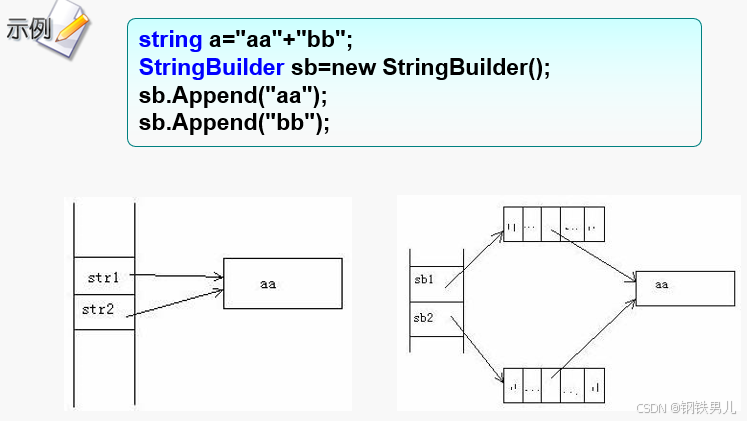
C# 字符与字符串
本课要点: 1、字符类Char的使用 2、字符串类String的使用 3、可变字符串****StringBuilder 4、常见错误 一 何时用到字符与字符串 问题: 输出C#**课考试最高分:**98.5 输出最高分学生姓名:张三 输出最高分学生性别&#x…...

在Ubuntu 16.04上使用LEMP安装WordPress的方法
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 简介 WordPress 是互联网上最流行的 CMS(内容管理系统)。它允许您在 MySQL 后端和 PHP 处理的基础上轻松设置灵…...

显示器放大后,大漠识图识色坐标偏移解决方法
原因分析: 显示器分辨率较高,DPI设置放大125% or 150% or 200%,游戏打开时也会默认会根据显示器的放大比例自行放大,但是大漠综合管理工具抓图不会放大; 解决方法: 1、大漠综合管理…...

C++容器之list基本使用
目录 前言 一、list的介绍? 二、使用 1.list的构造 2.list iterator的使用 3.list capacity 🥇 empty 🥇size 4.list element access 🥇 front 🥇 back 5.list modifiers 🥇 push_front 🥇 po…...

3个维度重构你的Windows体验:Win11Debloat系统深度优化解码
3个维度重构你的Windows体验:Win11Debloat系统深度优化解码 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter a…...

如何实现XState状态机日志记录:完整的变更追踪与审计指南
如何实现XState状态机日志记录:完整的变更追踪与审计指南 【免费下载链接】xstate State machines, statecharts, and actors for complex logic 项目地址: https://gitcode.com/gh_mirrors/xs/xstate XState是一个强大的状态管理库,用于构建复杂…...

SAP FI实操笔记:中日会计科目对照表,手把手教你配置GL主数据
SAP FI中日会计科目智能配置实战:从对照表到系统落地的全流程解析 当东京证券交易所的上市公司需要合并其在华子公司报表时,财务团队总会在会计科目转换环节遭遇"术语迷阵"。某日企财务总监曾向我展示过他们手工维护的Excel对照表——超过2000…...

Win11Debloat终极指南:如何简单快速优化Windows系统性能
Win11Debloat终极指南:如何简单快速优化Windows系统性能 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and …...

BiliTools:2026年最全能的哔哩哔哩资源管理工具箱完整指南
BiliTools:2026年最全能的哔哩哔哩资源管理工具箱完整指南 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliTools …...

从Python小白到全栈:聊聊PyCharm专业版里那些社区版没有的‘生产力神器’
从Python小白到全栈:聊聊PyCharm专业版里那些社区版没有的‘生产力神器’ 第一次用PyCharm社区版调试Django项目时,我在控制台输出了整整三页的SQL查询日志——这些本该在Database Tools面板里直观展示的关系数据,最终以密密麻麻的文本形式淹…...

3分钟掌握城通网盘高速下载:开源工具ctfileGet完全指南
3分钟掌握城通网盘高速下载:开源工具ctfileGet完全指南 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否曾经面对城通网盘的下载进度条感到绝望?当网络带宽被限制在每秒几十…...

揭秘一条现代化PCBA产线:5G+AI如何实现‘零缺陷’智能检测?
5GAI驱动的PCBA智能检测革命:从传统目检到零缺陷的跨越 走进这家位于华南的电子制造示范工厂,第一眼看到的不是戴着放大镜的质检员,而是一排闪烁着蓝光的机械臂正以每秒3块板卡的速度进行高精度扫描。每块PCBA经过时,头顶的工业相…...

NoFences:免费开源的Windows桌面分区管理神器,打造高效整洁的工作空间
NoFences:免费开源的Windows桌面分区管理神器,打造高效整洁的工作空间 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 还在为杂乱无章的Windows桌面而…...

旅行拼团信用程序,团员爽约记录上链,降低组团风险,方便筛选靠谱伙伴。
旅行拼团信用上链系统设计方案一、实际应用场景描述户外徒步俱乐部“山野行者”定期组织跨省长线徒步(如川西环线、冈仁波齐转山),需提前30天统计人数并预订包车、高山协作及住宿。近一年出现多次“临出发前48小时内无故退团”事件࿰…...