MongoDB-aggregate流式计算:带条件的关联查询使用案例分析
在数据库的查询中,是一定会遇到表关联查询的。当两张大表关联时,时常会遇到性能和资源问题。这篇文章就是用一个例子来分享MongoDB带条件的关联查询发挥的作用。
假设工作环境中有两张MongoDB集合:SC_DATA(学生基本信息集合)、DICT_DATA(值域字典集合),集合结构如下:
| SC_DATA | |
| uniqueid | 学生唯一号 |
| sfzid | 学生身份证 |
| xsxm | 学生姓名 |
| mz | 民族 |
| xb | 性别 |
| DICT_DATA | |
| clss | 字典类别 |
| value | 字典值域 |
| map | 字典值域映射值 |
| version | 字典版本 |
现在分别给这两张表插入一些测试数据,给SC_DATA插入10条数据,给DICT_DATA插入6条数据
db.SC_DATA.insertMany([{ "uniqueid" : "10001", "sfzid" : "3715xxxx0813", "xsxm" :"张一","mz":"1","xb":"1" },{ "uniqueid" : "10002", "sfzid" : "3715xxxx0814", "xsxm" :"张二","mz":"1","xb":"1" },{ "uniqueid" : "10003", "sfzid" : "3715xxxx0815", "xsxm" :"张三","mz":"1","xb":"1" },{ "uniqueid" : "10004", "sfzid" : "3715xxxx0816", "xsxm" :"张四","mz":"1","xb":"b" },{ "uniqueid" : "10005", "sfzid" : "3715xxxx0817", "xsxm" :"张五","mz":"a","xb":"1" },{ "uniqueid" : "10006", "sfzid" : "3715xxxx0819", "xsxm" :"张六","mz":"1","xb":"b" },{ "uniqueid" : "10007", "sfzid" : "3715xxxx0823", "xsxm" :"张七","mz":"1","xb":"1" },{ "uniqueid" : "10008", "sfzid" : "3715xxxx0833", "xsxm" :"张八","mz":"1","xb":"1" },{ "uniqueid" : "10009", "sfzid" : "3715xxxx0843", "xsxm" :"张九","mz":"1","xb":"1" },{ "uniqueid" : "100010", "sfzid" : "3715xxxx0853", "xsxm" :"张十","mz":"1","xb":"1" },
])db.DICT_DATA.insertMany([{ "clss" : "民族", "value" : "汉族", "map" :"1","version":"v1.0"},{ "clss" : "民族", "value" : "壮族", "map" :"2","version":"v1.0"},{ "clss" : "民族", "value" : "满族", "map" :"3","version":"v1.0"},{ "clss" : "民族", "value" : "回族", "map" :"4","version":"v1.0"},{ "clss" : "性别", "value" : "男", "map" :"1","version":"v1.0"},{ "clss" : "性别", "value" : "女", "map" :"2","version":"v1.0"}])此时,有个需求是 “统计出SC_DATA集合中民族、性别字段在字典值域内的数据”!
一般呢,思路是利用两集合关联,过滤出能关联上的数据。MongoDB的$lookup操作符类似于关系数据库的左连接,根据当前实际情况,用大表(SC_DATA.mz、SC_DATA.xb)左连接小表(DICT_DATA.map),能关联上的数据就是SC_DATA集合中民族、性别字段在字典值域内的数据!
一般呢,就直接用了$lookup进行关联了,但是,观察下DICT_DATA字典数据,承担关联任务的字段——map,有多个相同值,必须加上clss条件过滤才能得出准确数据,代码如下。
db.SC_DATA.aggregate([{$lookup: {from: "DICT_DATA",localField: "mz",foreignField: "map",as: "DICT_DATA"}},{$unwind: {path: "$DICT_DATA",preserveNullAndEmptyArrays: true}},{$match: {"DICT_DATA.clss": "民族"}},{$group: {_id: null,count: {$sum: 1}}}])但是,诸位请看,上面的代码是先关联,再过滤。通过compass工具分阶段查看,可以更清晰的看到关联后,因为DICT_DATA.map存在重复值,所以如果SC_DATA能和DICT_DATA关联上的话,数据会翻倍。
对于我们上面的测试数据,SC_DATA有10条测试数据,和DICT_DATA关联后数据量是19条,过滤clss后是9条。大家可能觉得这种还好,但是如果SC_DATA有上千万条数据,DICT_DATA的数据更多,重复值更多,这样关联出来的数据是非常惊人的,效率也会变得奇慢无比,甚至会造成数据库卡死。

如果能够在关联出结果前,就进行过滤,就会让更少量的数据进入到下一个MongoDB聚合管道,就会消耗更少量的资源。
这里也就引出了这篇文章的主角:带条件的$lookup,语法格式如下:
{$lookup:{from: <joined collection>,let: { <var_1>: <expression>, …, <var_n>: <expression> },pipeline: [ <pipeline to run on joined collection> ],as: <output array field>}
}参数说明如下:
| 参数 | 说明 |
| from | 指定待执行连接操作的集合,是当前集合【可以看下面的例子理解】 |
| let | 指定各个管道阶段使用的变量,这里的变量可以放到pipeline中使用; 这里指定的都是自身当前集合中的字段变量; 这里指定变量的时候以 col_name:$col_name的形式,在pipeline中使用的时候以 $$col_name形式 使用; |
| pipeline | 1、pipeline中,可以使用let中指定的变量,也可以使用当前集合中的字段; 2、pipeline中,$match阶段需要使用$expr操作符来访问变量,$expr允许在$match中使用聚合表达式; 3、pipeline中,放置在$expr上的$eq、$lt、$lte、$gt、$gte比较操作符,可以使用$lookup阶段引用的 from集合上的索引; 3.1、使用索引的限制一:不使用多键索引; 3.2、使用索引的限制二:当操作的数量比较大,或者操作数据类型没有定义时,不使用索引; 3.3、使用索引的限制三:索引只能用于字段和常量之间的比较,变量和变量之间的比较不能使用索引; 4、pipeline中,非$match阶段,不需要使用$expr操作符来访问变量 |
| as | 指定要添加到已连接文档的新数量字段的名称。新的大量字段包含来自加入的收集的匹配文档。如果指定的名称已存在于所连接的文档中,则现有字段将被覆盖。 |
针对 “统计出SC_DATA集合中民族、性别字段在字典值域内的数据”!这个需求,我们就可以将其写为如下代码!
db.SC_DATA.aggregate([{$lookup: {from: "DICT_DATA",let: {mz: "$mz"},pipeline: [{$match: {$expr: {$and: [{$eq: ["$map", "$$mz"]},{$eq: ["$clss", "民族"]}]}}}],as: "DICT_DATA"}},{$unwind: {path: "$DICT_DATA",preserveNullAndEmptyArrays: true}},{$match: {"DICT_DATA.map": {$ne: null}}},{$group: {_id: null,count: {$sum: 1}}}])从compass工具中,可以更清晰的看到数据量变化。此时,因为在输出关联数据前,先进行了过滤。这种写法可以消耗更少的数据库及系统资源,但在索引使用上和正常关联略有区别需要注意。

相关文章:
MongoDB-aggregate流式计算:带条件的关联查询使用案例分析
在数据库的查询中,是一定会遇到表关联查询的。当两张大表关联时,时常会遇到性能和资源问题。这篇文章就是用一个例子来分享MongoDB带条件的关联查询发挥的作用。 假设工作环境中有两张MongoDB集合:SC_DATA(学生基本信息集合&…...

Redis数据库与GO(一):安装,string,hash
安装包地址:https://github.com/tporadowski/redis/releases 建议下载zip版本,解压即可使用。解压后,依次打开目录下的redis-server.exe和redis-cli.exe,redis-cli.exe用于输入指令。 一、基本结构 如图,redis对外有个…...

expressjs,实现上传图片,返回图片链接
在 Express.js 中实现图片上传并返回图片链接,你通常需要使用一个中间件来处理文件上传,比如 multer。multer 是一个 node.js 的中间件,用于处理 multipart/form-data 类型的表单数据,主要用于上传文件。 以下是一个简单的示例&a…...

爬虫——XPath基本用法
第一章XML 一、xml简介 1.什么是XML? 1,XML指可扩展标记语言 2,XML是一种标记语言,类似于HTML 3,XML的设计宗旨是传输数据,而非显示数据 4,XML标签需要我们自己自定义 5,XML被…...

常见排序算法汇总
排序算法汇总 这篇文章说明下排序算法,直接开始。 1.冒泡排序 最简单直观的排序算法了,新手入门的第一个排序算法,也非常直观,最大的数字像泡泡一样一个个的“冒”到数组的最后面。 算法思想:反复遍历要排序的序列…...

Golang | Leetcode Golang题解之第459题重复的子字符串
题目: 题解: func repeatedSubstringPattern(s string) bool {return kmp(s s, s) }func kmp(query, pattern string) bool {n, m : len(query), len(pattern)fail : make([]int, m)for i : 0; i < m; i {fail[i] -1}for i : 1; i < m; i {j : …...

0.计网和操作系统
0.计网和操作系统 熟悉计算机网络和操作系统知识,包括 TCP/IP、UDP、HTTP、DNS 协议等。 常见的页面置换算法: 先进先出(FIFO)算法:将最早进入内存的页面替换出去。最近最少使用(LRU)算法&am…...

探索Prompt Engineering:开启大型语言模型潜力的钥匙
前言 什么是Prompt?Prompt Engineering? Prompt可以理解为向语言模型提出的问题或者指令,它是激发模型产生特定类型响应的“触发器”。 Prompt Engineering,即提示工程,是近年来随着大型语言模型(LLM,Larg…...
)
滚雪球学Oracle[3.3讲]:数据定义语言(DDL)
全文目录: 前言一、约束的高级使用1.1 主键(Primary Key)案例演示:定义主键 1.2 唯一性约束(Unique)案例演示:定义唯一性约束 1.3 外键(Foreign Key)案例演示:…...

ssrf学习(ctfhub靶场)
ssrf练习 目录 ssrf类型 漏洞形成原理(来自网络) 靶场题目 第一题(url探测网站下文件) 第二关(使用伪协议) 关于http和file协议的理解 file协议 http协议 第三关(端口扫描)…...

ElasticSearch之网络配置
对官方文档Networking的阅读笔记。 ES集群中的节点,支持处理两类通信平面 集群内节点之间的通信,官方文档称之为transport layer。集群外的通信,处理客户端下发的请求,比如数据的CRUD,检索等,官方文档称之…...

【C语言进阶】系统测试与调试
1. 引言 在开始本教程的深度学习之前,我们需要了解整个教程的目标及其结构,以及为何进阶学习是提升C语言技能的关键。 目标和结构: 教程目标:本教程旨在通过系统化的学习,从单元测试、系统集成测试到调试技巧…...

多个单链表的合成
建立两个非递减有序单链表,然后合并成一个非递增有序的单链表。 注意:建立非递减有序的单链表,需要采用创建单链表的算法 输入格式: 1 9 5 7 3 0 2 8 4 6 0 输出格式: 9 8 7 6 5 4 3 2 1 输入样例: 在这里给出一组输入。例如…...

『建议收藏』ChatGPT Canvas功能进阶使用指南!
大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,专注于分享AI全维度知识,包括但不限于AI科普,AI工…...

Ollama 运行视觉语言模型LLaVA
Ollama的LLaVA(大型语言和视觉助手)模型集已更新至 1.6 版,支持: 更高的图像分辨率:支持高达 4 倍的像素,使模型能够掌握更多细节。改进的文本识别和推理能力:在附加文档、图表和图表数据集上进…...

gdb 调试 linux 应用程序的技巧介绍
使用 gdb 来调试 Linux 应用程序时,可以显著提高开发和调试的效率。gdb(GNU 调试器)是一款功能强大的调试工具,适用于调试各类 C、C 程序。它允许我们在运行程序时检查其状态,设置断点,跟踪变量值的变化&am…...

Java项目实战II基于Java+Spring Boot+MySQL的房产销售系统(源码+数据库+文档)
目录 一、前言 二、技术介绍 三、系统实现 四、文档参考 五、核心代码 六、源码获取 全栈码农以及毕业设计实战开发,CSDN平台Java领域新星创作者 一、前言 随着房地产市场的蓬勃发展,房产销售业务日益复杂,传统的手工管理方式已难以满…...

aws(学习笔记第一课) AWS CLI,创建ec2 server以及drawio进行aws画图
aws(学习笔记第一课) 使用AWS CLI 学习内容: 使用AWS CLI配置密钥对创建ec2 server使用drawio(vscode插件)进行AWS的画图 1. 使用AWS CLI 注册AWS账号 AWS是通用的云计算平台,可以提供ec2,vpc,SNS以及clo…...

【Python】Eventlet 异步网络库简介
Eventlet 是一个 Python 的异步网络库,它使用协程(green threads)来简化并发编程。通过非阻塞的 I/O 操作,Eventlet 使得你可以轻松编写高性能的网络应用程序,而无需处理复杂的回调逻辑或编写多线程代码。它广泛应用于…...
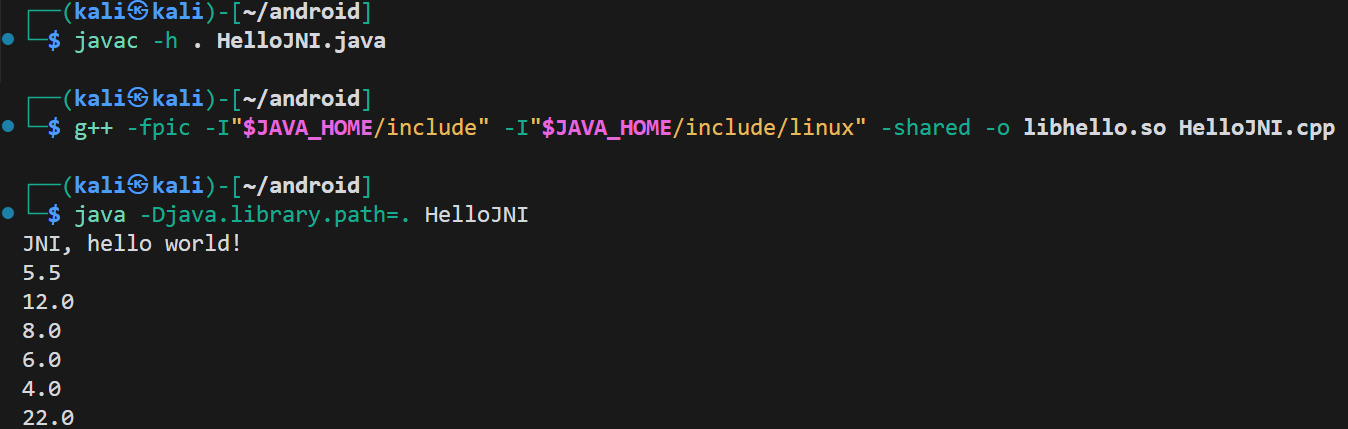
【JNI】数组的基本使用
在上一期讲了基本类型的基本使用,这期来说一说数组的基本使用 HelloJNI.java:实现myArray函数,把一个整型数组转换为双精度型数组 public class HelloJNI { static {System.loadLibrary("hello"); }private native String HelloW…...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...
)
React Native 开发环境搭建(全平台详解)
React Native 开发环境搭建(全平台详解) 在开始使用 React Native 开发移动应用之前,正确设置开发环境是至关重要的一步。本文将为你提供一份全面的指南,涵盖 macOS 和 Windows 平台的配置步骤,如何在 Android 和 iOS…...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

【CSS position 属性】static、relative、fixed、absolute 、sticky详细介绍,多层嵌套定位示例
文章目录 ★ position 的五种类型及基本用法 ★ 一、position 属性概述 二、position 的五种类型详解(初学者版) 1. static(默认值) 2. relative(相对定位) 3. absolute(绝对定位) 4. fixed(固定定位) 5. sticky(粘性定位) 三、定位元素的层级关系(z-i…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

【2025年】解决Burpsuite抓不到https包的问题
环境:windows11 burpsuite:2025.5 在抓取https网站时,burpsuite抓取不到https数据包,只显示: 解决该问题只需如下三个步骤: 1、浏览器中访问 http://burp 2、下载 CA certificate 证书 3、在设置--隐私与安全--…...

Java面试专项一-准备篇
一、企业简历筛选规则 一般企业的简历筛选流程:首先由HR先筛选一部分简历后,在将简历给到对应的项目负责人后再进行下一步的操作。 HR如何筛选简历 例如:Boss直聘(招聘方平台) 直接按照条件进行筛选 例如:…...

Selenium常用函数介绍
目录 一,元素定位 1.1 cssSeector 1.2 xpath 二,操作测试对象 三,窗口 3.1 案例 3.2 窗口切换 3.3 窗口大小 3.4 屏幕截图 3.5 关闭窗口 四,弹窗 五,等待 六,导航 七,文件上传 …...

解析奥地利 XARION激光超声检测系统:无膜光学麦克风 + 无耦合剂的技术协同优势及多元应用
在工业制造领域,无损检测(NDT)的精度与效率直接影响产品质量与生产安全。奥地利 XARION开发的激光超声精密检测系统,以非接触式光学麦克风技术为核心,打破传统检测瓶颈,为半导体、航空航天、汽车制造等行业提供了高灵敏…...

wpf在image控件上快速显示内存图像
wpf在image控件上快速显示内存图像https://www.cnblogs.com/haodafeng/p/10431387.html 如果你在寻找能够快速在image控件刷新大图像(比如分辨率3000*3000的图像)的办法,尤其是想把内存中的裸数据(只有图像的数据,不包…...