从调用NCCL到深入NCCL源码
本小白目前研究GPU多卡互连的方案,主要参考NCCL和RCCL进行学习,如有错误,请及时指正!
内容还在整理中,近期不断更新!!
背景介绍
在大模型高性能计算时会需要用到多卡(GPU)进行并行加速。其中分为单机多卡和多机多卡。

rank:用于表示在整个分布式任务中进程的序号,每一个进程对应了一个rank进程,整个分布式训练由许多的rank进程完成。rank,我个人理解就相当于进程的index,通过这个index找到对应的进程。
node:物理节点,一般来说指一台机器,机器内部可以有多个GPU
local_rank:local_rank不同于进程rank的地方在于,他是相对于node而言的编号,每个node之间的local_rank相对独立。如果是一台机器,rank一般就等于local_rank。
调用案例
直接进入主题首先例程为:单线程/单进程 调用 单个GPU设备代码:
#include <stdio.h>
#include "cuda_runtime.h"
#include "nccl.h"
#include "mpi.h"
#include <unistd.h>
#include <stdint.h>
#include <stdlib.h>#define MPICHECK(cmd) do { \int e = cmd; \if( e != MPI_SUCCESS ) { \printf("Failed: MPI error %s:%d '%d'\n", \__FILE__,__LINE__, e); \exit(EXIT_FAILURE); \} \
} while(0)#define CUDACHECK(cmd) do { \cudaError_t e = cmd; \if( e != cudaSuccess ) { \printf("Failed: Cuda error %s:%d '%s'\n", \__FILE__,__LINE__,cudaGetErrorString(e)); \exit(EXIT_FAILURE); \} \
} while(0)#define NCCLCHECK(cmd) do { \ncclResult_t r = cmd; \if (r!= ncclSuccess) { \printf("Failed, NCCL error %s:%d '%s'\n", \__FILE__,__LINE__,ncclGetErrorString(r)); \exit(EXIT_FAILURE); \} \
} while(0)static uint64_t getHostHash(const char* string) {// Based on DJB2a, result = result * 33 ^ charuint64_t result = 5381;for (int c = 0; string[c] != '\0'; c++){result = ((result << 5) + result) ^ string[c];}return result;
}static void getHostName(char* hostname, int maxlen) {gethostname(hostname, maxlen);for (int i=0; i< maxlen; i++) {if (hostname[i] == '.') {hostname[i] = '\0';return;}}
}int main(int argc, char* argv[])
{int size = 32*1024*1024;int myRank, nRanks, localRank = 0;//initializing MPIMPICHECK(MPI_Init(&argc, &argv));MPICHECK(MPI_Comm_rank(MPI_COMM_WORLD, &myRank));MPICHECK(MPI_Comm_size(MPI_COMM_WORLD, &nRanks));//calculating localRank based on hostname which is used in selecting a GPUuint64_t hostHashs[nRanks];char hostname[1024];getHostName(hostname, 1024);hostHashs[myRank] = getHostHash(hostname);MPICHECK(MPI_Allgather(MPI_IN_PLACE, 0, MPI_DATATYPE_NULL, hostHashs, sizeof(uint64_t), MPI_BYTE, MPI_COMM_WORLD));for (int p=0; p<nRanks; p++) {if (p == myRank) break;if (hostHashs[p] == hostHashs[myRank]) localRank++;}ncclUniqueId id;ncclComm_t comm;float *sendbuff, *recvbuff;cudaStream_t s;//get NCCL unique ID at rank 0 and broadcast it to all othersif (myRank == 0) ncclGetUniqueId(&id);MPICHECK(MPI_Bcast((void *)&id, sizeof(id), MPI_BYTE, 0, MPI_COMM_WORLD));//picking a GPU based on localRank, allocate device buffersCUDACHECK(cudaSetDevice(localRank));CUDACHECK(cudaMalloc(&sendbuff, size * sizeof(float)));CUDACHECK(cudaMalloc(&recvbuff, size * sizeof(float)));CUDACHECK(cudaStreamCreate(&s));//initializing NCCLNCCLCHECK(ncclCommInitRank(&comm, nRanks, id, myRank));//communicating using NCCLNCCLCHECK(ncclAllReduce((const void*)sendbuff, (void*)recvbuff, size, ncclFloat, ncclSum,comm, s));//completing NCCL operation by synchronizing on the CUDA streamCUDACHECK(cudaStreamSynchronize(s));//free device buffersCUDACHECK(cudaFree(sendbuff));CUDACHECK(cudaFree(recvbuff));//finalizing NCCLncclCommDestroy(comm);//finalizing MPIMPICHECK(MPI_Finalize());printf("[MPI Rank %d] Success \n", myRank);return 0;
}其中关于NCCL的API的主要是以下这三个:
1. ncclGetUniqueId(&id)
2. ncclCommInitRank(&comm, nRanks, id, myRank)
3. ncclAllReduce((const void*)sendbuff, (void*)recvbuff, size, ncclFloat, ncclSum,comm, s)
首先明白前两个API,其中ncclGetUniqueId的作用,再多卡互连的环境中,所有参与的GPU共用此id,用来标识这个(一个)通信域。
来看一下这个id是怎么获得的, if (myRank == 0) ncclGetUniqueId(&id);
ncclResult_t ncclGetUniqueId(ncclUniqueId* out) { // 1 NCCL库初始化 NCCLCHECK(ncclInit()); // 检查传入的out指针是否为非空。NCCLCHECK(PtrCheck(out, "GetUniqueId", "out")); //2 调用bootstrapGetUniqueId函数来获取一个唯一的ID,并将这个ID存储在传入的out指针所指向的内存位置。 ncclResult_t res = bootstrapGetUniqueId((struct ncclBootstrapHandle*)out); // TRACE_CALL是一个用于日志记录或跟踪的宏。TRACE_CALL("ncclGetUniqueId(0x%llx)", (unsigned long long)hashUniqueId(*out)); // 返回bootstrapGetUniqueId函数的结果。表示操作是否成功 return res;
}一、ncclInit()核心逻辑:源码位置:nccl-master\src\init.cc
1、initEnv(); //初始化环境设置
2、initGdrCopy() //初始化 GPU Direct RDMA (GDR)
3、bootstrapNetInit() //初始化引导网络
4、ncclNetPluginInit() //NCCL网络插件初始化,抽象和封装底层网络细节,方便NCCL灵活应用
备注:“A、setEnvFile(confFilePath);//根据配置文件初始化设置” 的首行缩进表示initEnv()调用了setEnvFile(confFilePath)函数。缩进表示调用,或者该代码片段中使用。
备注:bootstrap引导网络主要在初始化时完成一些小数据量的信息交换,例如ip地址。
二、bootstrapGetUniqueId()核心逻辑:源码位置nccl-master\src\bootstrap.cc
1、生成一个随机数,填充ncclUniqueId的前半部分。
2、如果环境变量中有NCCL_COMM_ID的值,将环境变量解析为网络地址,赋值给ncclUniqueId的后半部分。
3、如果环境变量中没有NCCL_COMM_ID的值,将bootstrap网络地址,赋值给ncclUniqueId的后半部分。
注意,标识通信组的唯一ID ncclUniqueId本质上由两部分组成,前半部分是随机数,后半部分是网络地址。(2/3这部分不确定)
总结:
1.nccl网络初始化:一、bootstrap网络,二、数据通信网络,bootstrap网络主要用于初始化时交换一些简单的信息,比如每个机器的ip和端口,由于数据量很小,而且主要是在初始化阶段执行一次,因此bootstrap使用的是tcp;而通信网络是用于实际数据的传输,因此会优先使用rdma(支持gdr的话会优先使用gdr)
2.生成UniqueID,主进程通常为Rank0 调用ncclGetUniqueId生成一个UniqueID,并且共享给所有参与通信的进程。
源码内容
上面讲了网络初始化和UniqueID生成,以下总结以下源码整体的内容:

一、初始化、Get UniqueID
上述已经讲解完这个部分
初始化:获取当前机器上所有可用的IB网卡和普通以太网卡然后保存
UniqueID:包括随机数+IP PORT(RANK0)
二、Bootstrap网络建立
核心逻辑:
1、rank0执行完ncclGetUniqueId,生产ncclUniqueId,包含rank0的ip port,通过mpi传播到所有节点。每个rank上都有rank0的网络地址;
2、所有rank根据rank0的网络地址,建立socket并向rank0发送自己的网络地址,rank0上现在就有所有rank的网络地址了;
3、rank0告诉每个rank它的下一个节点网络地址,完成环形网络建立;
4、AllGather全局收集所有节点的网络地址,每个rank就都有了全局所有rank的ip port;
源码位置:nccl-master\src\bootstrap.cc
///
//1、函数的输入handle就是UniqueID,被强制转化欸ncclBootstrapHandle,包含rank0的网络地址
ncclResult_t bootstrapInit(struct ncclBootstrapHandle* handle, struct ncclComm* comm) {// 获取当前节点的排名int rank = comm->rank;// 获取参与节点的数量int nranks = comm->nRanks;// 分配内存并初始化bootstrapState结构体,用于管理启动阶段的状态struct bootstrapState* state;NCCLCHECK(ncclCalloc(&state, 1));state->rank = rank; // 设置当前节点的排名state->nranks = nranks; // 设置参与节点的数量state->abortFlag = comm->abortFlag; // 设置是否应中止通信的标志// 将bootstrapState指针赋予comm结构体comm->bootstrap = state;// 设置魔术数字,用于校验comm->magic = state->magic = handle->magic;// 记录日志,显示当前节点的排名和参与节点的数量TRACE(NCCL_INIT, "rank %d nranks %d", rank, nranks);// 为当前节点准备发送给其他节点的信息struct extInfo info = { 0 };info.rank = rank; // 设置当前节点的排名info.nranks = nranks; // 设置参与节点的数量// 创建一个监听套接字,允许其他节点联系当前节点NCCLCHECK(ncclSocketInit(&state->listenSock, &bootstrapNetIfAddr, comm->magic, ncclSocketTypeBootstrap, comm->abortFlag)); // 初始化监听套接字NCCLCHECK(ncclSocketListen(&state->listenSock)); // 设置监听状态NCCLCHECK(ncclSocketGetAddr(&state->listenSock, &info.extAddressListen)); // 获取监听套接字的地址// 创建另一个监听套接字,允许根节点联系当前节点NCCLCHECK(ncclSocketInit(&listenSockRoot, &bootstrapNetIfAddr, comm->magic, ncclSocketTypeBootstrap, comm->abortFlag)); // 初始化监听套接字NCCLCHECK(ncclSocketListen(&listenSockRoot)); // 设置监听状态NCCLCHECK(ncclSocketGetAddr(&listenSockRoot, &info.extAddressListenRoot)); // 获取监听套接字的地址// 如果参与节点的数量大于128,则延迟连接到根节点,以减轻根节点的负载if (nranks > 128) {long msec = rank; // 计算延迟时间struct timespec tv; // 定义时间戳结构体tv.tv_sec = msec / 1000; // 秒部分tv.tv_nsec = 1000000 * (msec % 1000); // 毫秒部分TRACE(NCCL_INIT, "rank %d delaying connection to root by %ld msec", rank, msec); // 记录日志,显示延迟时间(void) nanosleep(&tv, NULL); // 延迟指定时间}//2、所有根据rank0的网络地址,建立socket并向rank0发送自己的网络地址;// 发送当前节点的信息给根节点NCCLCHECK(ncclSocketInit(&sock, &handle->addr, comm->magic, ncclSocketTypeBootstrap, comm->abortFlag)); // 初始化套接字NCCLCHECK(ncclSocketConnect(&sock)); // 连接到根节点NCCLCHECK(bootstrapNetSend(&sock, &info, sizeof(info))); // 发送信息NCCLCHECK(ncclSocketClose(&sock)); // 关闭套接字/////3、rank0告诉每个rank它的下一个节点网络地址,完成环形网络建立;// 从根节点接收下一个节点在启动环中的信息NCCLCHECK(ncclSocketInit(&sock)); // 初始化套接字NCCLCHECK(ncclSocketAccept(&sock, &listenSockRoot)); // 接受来自根节点的连接请求NCCLCHECK(bootstrapNetRecv(&sock, &nextAddr, sizeof(union ncclSocketAddress))); // 接收信息NCCLCHECK(ncclSocketClose(&sock)); // 关闭套接字NCCLCHECK(ncclSocketClose(&listenSockRoot)); // 关闭根节点的监听套接字// 初始化与下一个节点的发送套接字NCCLCHECK(ncclSocketInit(&state->ringSendSocket, &nextAddr, comm->magic, ncclSocketTypeBootstrap, comm->abortFlag)); // 初始化套接字NCCLCHECK(ncclSocketConnect(&state->ringSendSocket)); // 连接到下一个节点// 接受来自前一个节点的环连接请求NCCLCHECK(ncclSocketInit(&state->ringRecvSocket)); // 初始化套接字NCCLCHECK(ncclSocketAccept(&state->ringRecvSocket, &state->listenSock)); // 接受连接请求///4、AllGather全局收集所有节点的网络地址;// 全局收集所有节点的监听器地址NCCLCHECK(ncclCalloc(&state->peerCommAddresses, nranks)); // 分配内存NCCLCHECK(ncclSocketGetAddr(&state->listenSock, state->peerCommAddresses+rank)); // 获取当前节点的监听器地址NCCLCHECK(bootstrapAllGather(state, state->peerCommAddresses, sizeof(union ncclSocketAddress))); // 全局收集监听器地址// 创建服务代理套接字NCCLCHECK(ncclCalloc(&state->peerProxyAddresses, nranks)); // 分配内存NCCLCHECK(ncclCalloc(&state->peerProxyAddressesUDS, nranks)); // 分配内存// 初始化服务代理NCCLCHECK(ncclCalloc(&proxySocket, 1)); // 分配内存NCCLCHECK(ncclSocketInit(proxySocket, &bootstrapNetIfAddr, comm->magic, ncclSocketTypeProxy, comm->abortFlag)); // 初始化套接字NCCLCHECK(ncclSocketListen(proxySocket)); // 设置监听状态NCCLCHECK(ncclSocketGetAddr(proxySocket, state->peerProxyAddresses+rank)); // 获取当前节点的代理地址NCCLCHECK(bootstrapAllGather(state, state->peerProxyAddresses, sizeof(union ncclSocketAddress))); // 全局收集代理地址uint64_t randId; // 随机IDNCCLCHECK(getRandomData(&randId, sizeof(randId))); // 生成随机数据state->peerProxyAddressesUDS[rank] = getPidHash()+randId; // 生成唯一的UDS名称NCCLCHECK(bootstrapAllGather(state, state->peerProxyAddressesUDS, sizeof(*state->peerProxyAddressesUDS))); // 全局收集UDS名称NCCLCHECK(ncclProxyInit(comm, proxySocket, state->peerProxyAddresses, state->peerProxyAddressesUDS)); // 初始化代理// 记录完成初始化的消息TRACE(NCCL_INIT, "rank %d nranks %d - DONE", rank, nranks);// 返回成功状态return ncclSuccess;
}初始化通信,所有进程使用相同的UniqueID调用ncclCommInitRank函数初始化通信,一般每个GPU都有一个独立的ncclComm,NCCL根据UniqueID和各自的网络配置(IP地址+端口号)建立Socket连接构建通信拓扑。
三、机器拓扑
NCCL拓扑识别的整体思路:
1、物理拓扑构建
2、通信路径计算(每个GPU/网卡到其它GPU,网卡的最优路径。)
3、逻辑拓扑构建(通信通道检索)
先获取物理拓扑图,然后计算通信路径(方便逻辑拓扑构建),根据通信路径构建逻辑拓扑,例如ring,tree逻辑拓扑,指明哪个GPU和哪个GPU通信。
源码位置:nccl-master\src\init.cc
总:initTransportsRank()
static ncclResult_t initTransportsRank(struct ncclComm* comm, struct ncclComm* parent = NULL) {// 其它代码// 获取系统的拓扑信息,并存储在comm的topo成员中
NCCLCHECKGOTO(ncclTopoGetSystem(comm, &comm->topo), ret, fail); // 在已获取的拓扑中,计算GPU和NIC之间的路径
NCCLCHECKGOTO(ncclTopoComputePaths(comm->topo, comm), ret, fail); // 根据计算结果,移除不可访问的GPU和未使用的NIC
NCCLCHECKGOTO(ncclTopoTrimSystem(comm->topo, comm), ret, fail); // 在移除不可访问的组件后,重新计算路径
NCCLCHECKGOTO(ncclTopoComputePaths(comm->topo, comm), ret, fail); // 初始化拓扑搜索
NCCLCHECKGOTO(ncclTopoSearchInit(comm->topo), ret, fail); // 打印最终的拓扑结构,用于调试或信息展示
NCCLCHECKGOTO(ncclTopoPrint(comm->topo), ret, fail); // 获取与当前GPU本地化的CPU亲和性,即哪些CPU与当前GPU通信效率最高
NCCLCHECKGOTO(ncclTopoGetCpuAffinity(comm->topo, comm->rank, &comm->cpuAffinity), ret, fail); // 如果找到了与GPU匹配的CPU亲和性(即找到了可用的CPU集合)
if (CPU_COUNT(&comm->cpuAffinity)) { // 保存当前线程的CPU亲和性设置(可能是为了之后恢复) sched_getaffinity(0, sizeof(cpu_set_t), &affinitySave); // 将当前线程的CPU亲和性设置为与GPU匹配的CPU集合 sched_setaffinity(0, sizeof(cpu_set_t), &comm->cpuAffinity);
} // 检查本地是否支持CollNet(NCCL的一种优化)
if (collNetSupport(comm)) { // 获取环境变量NCCL_COLLNET_ENABLE的值,决定是否启用CollNet const char *collNetEnable = ncclGetEnv("NCCL_COLLNET_ENABLE"); if (collNetEnable != NULL) { // 如果环境变量已设置,打印信息到日志或控制台 INFO(NCCL_ALL, "NCCL_COLLNET_ENABLE set by environment to %s.", collNetEnable); // 如果环境变量值为"1",则启用CollNet支持 if (strcmp(collNetEnable, "1") == 0) { comm->collNetSupport = 1; } }
} // 初始化Nvls支持第三代NVSwitch系统(NVLink4)
NCCLCHECK(ncclNvlsInit(comm)); // 初始化环图结构,用于表示环形的通信模式
memset(&ringGraph, 0, sizeof(struct ncclTopoGraph));
ringGraph.id = 0;
ringGraph.pattern = NCCL_TOPO_PATTERN_RING;
ringGraph.minChannels = 1;
ringGraph.maxChannels = MAXCHANNELS/2; // 在已获取的拓扑中,计算环图的通信信息
NCCLCHECKGOTO(ncclTopoCompute(comm->topo, &ringGraph), ret, fail); // 打印环图的拓扑结构,用于调试或信息展示
NCCLCHECKGOTO(ncclTopoPrintGraph(comm->topo, &ringGraph), ret, fail); // 其它代码} 1、物理拓扑构建:ncclTopoGetSystem()
2、通信路径计算:ncclTopoComputePaths()
3、逻辑拓扑构建(通信通道检索):ncclTopoCompute()
ncclTopoGetSystem()源码速递:
源码位置:nccl-master\src\graph\topo.cc
ncclResult_t ncclTopoGetSystem(struct ncclComm* comm, struct ncclTopoSystem** system) { // 分配一个XML结构,用于存储拓扑信息 struct ncclXml* xml; NCCLCHECK(xmlAlloc(&xml, NCCL_TOPO_XML_MAX_NODES)); ///1、 尝试从文件加载已有拓扑信息。// 尝试从环境变量中获取XML拓扑文件的路径 const char* xmlTopoFile = ncclGetEnv("NCCL_TOPO_FILE"); if (xmlTopoFile) { // 如果环境变量设置了,则打印信息并加载该文件到xml结构中 INFO(NCCL_ENV, "NCCL_TOPO_FILE set by environment to %s", xmlTopoFile); NCCLCHECK(ncclTopoGetXmlFromFile(xmlTopoFile, xml, 1)); } else { // 如果没有设置环境变量,则尝试从默认位置加载XML拓扑文件 // Try default XML topology location NCCLCHECK(ncclTopoGetXmlFromFile("/var/run/nvidia-topologyd/virtualTopology.xml", xml, 0)); } /2、如果没有已有拓扑信息,创建一个名为"system"的根节点;//// 如果xml结构中没有任何节点(即没有加载到任何拓扑信息) if (xml->maxIndex == 0) { // 创建一个名为"system"的根节点,并设置其版本属性 // Create top tag struct ncclXmlNode* top; NCCLCHECK(xmlAddNode(xml, NULL, "system", &top)); NCCLCHECK(xmlSetAttrInt(top, "version", NCCL_TOPO_XML_VERSION)); } /3、遍历本服务器所有GPU,拓扑树中添加GPU节点和NVlink;// 如果需要,自动检测GPU设备 // Auto-detect GPUs if needed for (int r=0; r<comm->nRanks; r++) { // 如果当前排名r对应的hostHash与当前rank的hostHash相同(可能是同一台机器上的不同GPU) if (comm->peerInfo[r].hostHash == comm->peerInfo[comm->rank].hostHash) { // 将busId转换为可读的PCI总线ID格式 char busId[NVML_DEVICE_PCI_BUS_ID_BUFFER_SIZE]; NCCLCHECK(int64ToBusId(comm->peerInfo[r].busId, busId)); // 填充一个表示GPU的XML节点 struct ncclXmlNode* node; NCCLCHECK(ncclTopoFillGpu(xml, busId, &node)); // 如果没有成功创建节点,则继续下一次循环 if (node == NULL) continue; // 设置该GPU节点的"keep"属性为1,表示需要保留这个节点 NCCLCHECK(xmlSetAttrInt(node, "keep", 1)); // 设置该GPU节点的"rank"属性为当前排名r NCCLCHECK(xmlSetAttrInt(node, "rank", r)); // 设置该GPU节点的"gdr"属性,表示是否支持GPU Direct RDMA NCCLCHECK(xmlInitAttrInt(node, "gdr", comm->peerInfo[r].gdrSupport)); } } /
4、遍历所有网络设备,拓扑树中添加网络拓扑节点;/
// 如果需要的话,自动检测NICs(网络接口卡)。net和collnet共享相同的xml/graph节点,
// 所以我们先从collnet开始,以便它有更高的优先级。
// Auto-detect NICs if needed. net/collnet share the same xml/graph nodes,
// so we start with collnet so that it has precedence.
int netDevCount = 0; // 初始化网络设备计数为0
// 如果comm支持collNet
if (collNetSupport(comm)) { // 获取comm支持的网络设备数量 NCCLCHECK(collNetDevices(comm, &netDevCount)); // 遍历每个网络设备 for (int n=0; n<netDevCount; n++) { ncclNetProperties_t props; // 定义一个ncclNetProperties_t类型的变量props,用于存储设备属性 // 获取第n个网络设备的属性 NCCLCHECK(collNetGetProperties(comm, n, &props)); // 创建一个XML节点来表示这个网络设备 struct ncclXmlNode* netNode; // 使用设备的pci路径和名称来填充XML节点 NCCLCHECK(ncclTopoFillNet(xml, props.pciPath, props.name, &netNode)); // 将"keep"属性设置为1,可能表示这个节点需要被保留 NCCLCHECK(xmlSetAttrInt(netNode, "keep", 1)); // 将"dev"属性设置为n,表示这是第n个设备 NCCLCHECK(xmlSetAttrInt(netNode, "dev", n)); // 将速度、端口、GUID等属性添加到XML节点中 NCCLCHECK(xmlInitAttrInt(netNode, "speed", props.speed)); NCCLCHECK(xmlInitAttrInt(netNode, "port", props.port)); NCCLCHECK(xmlInitAttrUint64(netNode, "guid", props.guid)); NCCLCHECK(xmlInitAttrInt(netNode, "maxconn", props.maxComms)); // 检查是否支持GPU Direct RDMA(GDR) bool gdrSupport = (props.ptrSupport & NCCL_PTR_CUDA) || (comm->dmaBufSupport && (props.ptrSupport & NCCL_PTR_DMABUF)); // 打印GDR支持状态和设备信息 INFO(NCCL_NET,"NET/%s : GPU Direct RDMA %s for HCA %d '%s'", comm->ncclNet->name, gdrSupport ? "Enabled" : "Disabled", n, props.name); // 将GDR支持状态添加到XML节点中 NCCLCHECK(xmlInitAttrInt(netNode, "gdr", gdrSupport)); // 将"coll"属性设置为1,可能表示这是一个集合通信网络接口 NCCLCHECK(xmlInitAttrInt(netNode, "coll", 1)); }
} // 循环遍历所有的网络设备,其中 netDevCount 是网络设备的总数
for (int n=0; n<netDevCount; n++) { // 定义一个 ncclNetProperties_t 类型的变量 props,用于存储网络设备的属性 ncclNetProperties_t props; // 调用 getProperties 函数获取网络设备的属性,并检查调用是否成功 // 参数 n 是当前网络设备的索引,&props 是用于存储属性的指针 NCCLCHECK(comm->ncclNet->getProperties(n, &props)); // 定义一个指向 ncclXmlNode 结构的指针 netNode,该结构将用于表示 XML 中的节点 struct ncclXmlNode* netNode; // 调用 ncclTopoFillNet 函数在 XML 结构中创建一个新的节点,并检查调用是否成功 // 参数 xml 是 XML 结构的指针,props.pciPath 和 props.name 是网络设备的 PCI 路径和名称 // &netNode 是用于存储新节点指针的指针 NCCLCHECK(ncclTopoFillNet(xml, props.pciPath, props.name, &netNode)); // 设置新节点的 keep 属性为 1,表示该节点应该被保留 NCCLCHECK(xmlSetAttrInt(netNode, "keep", 1)); // 设置新节点的 dev 属性为当前网络设备的索引 n NCCLCHECK(xmlSetAttrInt(netNode, "dev", n)); // 设置新节点的 speed 属性为网络设备的速度 NCCLCHECK(xmlInitAttrInt(netNode, "speed", props.speed)); // 设置新节点的 port 属性为网络设备的端口号 // 并检查设置属性是否成功 NCCLCHECK(xmlInitAttrInt(netNode, "port", props.port)); // 设置新节点的 latency 属性为网络设备的延迟 NCCLCHECK(xmlInitAttrFloat(netNode, "latency", props.latency)); // 设置新节点的 guid 属性为网络设备的全局唯一标识符 NCCLCHECK(xmlInitAttrUint64(netNode, "guid", props.guid)); // 设置新节点的 maxconn 属性为网络设备支持的最大并发通信数 NCCLCHECK(xmlInitAttrInt(netNode, "maxconn", props.maxComms)); // 检查网络设备是否支持 GPU Direct RDMA // 如果 props.ptrSupport 包含 NCCL_PTR_CUDA 或者如果 comm->dmaBufSupport 为真且 props.ptrSupport 包含 NCCL_PTR_DMABUF,则 gdrSupport 为真 bool gdrSupport = (props.ptrSupport & NCCL_PTR_CUDA) || (comm->dmaBufSupport && (props.ptrSupport & NCCL_PTR_DMABUF)); // 打印日志信息,显示网络设备是否支持 GPU Direct RDMA // 其中 comm->ncclNet->name 是网络设备的名称,n 是设备的索引,props.name 是设备的名字 INFO(NCCL_NET,"NET/%s : GPU Direct RDMA %s for HCA %d '%s'", comm->ncclNet->name, gdrSupport ? "Enabled" : "Disabled", n, props.name); // 设置新节点的 gdr 属性,表示是否支持 GPU Direct RDMA NCCLCHECK(xmlInitAttrInt(netNode, "gdr", gdrSupport));
} 5、移除不可用的节点;/
// 移除 XML 中不包含 keep="1" 节点的分支
NCCLCHECK(ncclTopoTrimXml(xml)); /
6、Multi-Node NVLink (MNNVL) 跨服务器NVLink支持;
// 如果 MNNVL被启用
if (comm->MNNVL) { // MNNVL 集群支持 // 分配内存来存储所有集群成员的网络拓扑数据 char* mem; // 为每个集群成员分配足够的内存空间来存储 XML 数据 // 假设每个成员的 XML 数据不超过 NCCL_TOPO_XML_MAX_NODES 大小 NCCLCHECK(ncclCalloc(&mem, comm->clique.size * xmlMemSize(NCCL_TOPO_XML_MAX_NODES))); // 获取当前集群成员的 XML 数据区域 struct ncclXml* rankXml = (struct ncclXml*)(mem + xmlMemSize(NCCL_TOPO_XML_MAX_NODES) * comm->cliqueRank); // 复制当前集群成员的 XML 数据 memcpy(rankXml, xml, xmlMemSize(NCCL_TOPO_XML_MAX_NODES)); // 将当前集群成员的 XML 数据转换为内部表示形式(可能是为了更高效的通信) NCCLCHECK(ncclTopoConvertXml(rankXml, (uintptr_t)xml->nodes, 1)); // 在集群内所有成员间收集各自的 XML 数据 // bootstrapIntraNodeAllGather 可能是某种集群内收集数据的函数 NCCLCHECK(bootstrapIntraNodeAllGather(comm->bootstrap, comm->clique.ranks, comm->cliqueRank, comm->clique.size, mem, xmlMemSize(NCCL_TOPO_XML_MAX_NODES))); // 分配一个新的 XML 结构来存储融合后的集群拓扑数据 struct ncclXml* cliqueXml; NCCLCHECK(xmlAlloc(&cliqueXml, comm->clique.size * NCCL_TOPO_XML_MAX_NODES)); // 融合集群内所有成员的 XML 数据 for (int i = 0; i < comm->clique.size; i++) { // 获取集群中每个成员的 XML 数据 struct ncclXml* peerXml = (struct ncclXml*)(mem + xmlMemSize(NCCL_TOPO_XML_MAX_NODES) * i); // 将 XML 数据转换为内部表示形式(这次可能为了融合做准备) NCCLCHECK(ncclTopoConvertXml(peerXml, (uintptr_t)peerXml->nodes, 0)); // 将当前成员的 XML 数据融合到 cliqueXml 中 NCCLCHECK(ncclTopoFuseXml(cliqueXml, peerXml)); } // 释放原来的 XML 数据 free(xml); // 更新 xml 指针以指向融合后的集群 XML 数据 xml = cliqueXml;
} //
7、保持拓扑文件;/
// 获取环境变量 NCCL_TOPO_DUMP_FILE 的值,用于存储 XML 拓扑数据
xmlTopoFile = ncclGetEnv("NCCL_TOPO_DUMP_FILE");
// 如果环境变量被设置,并且当前进程是负责输出拓扑数据的进程(由 ncclParamTopoDumpFileRank() 确定)
if (xmlTopoFile && comm->rank == ncclParamTopoDumpFileRank()) { // 输出环境变量 NCCL_TOPO_DUMP_FILE 的值 INFO(NCCL_ENV, "NCCL_TOPO_DUMP_FILE set by environment to %s", xmlTopoFile); // 将融合后的 XML 拓扑数据写入到指定的文件中 NCCLCHECK(ncclTopoDumpXmlToFile(xmlTopoFile, xml));
}
// 从 XML 数据中提取系统信息,并存储在 system 中
// comm->peerInfo[comm->rank].hostHash 可能用于区分不同主机的哈希值
NCCLCHECK(ncclTopoGetSystemFromXml(xml, system, comm->peerInfo[comm->rank].hostHash)); // 释放 XML 数据的内存
free(xml);
// 返回成功状态
return ncclSuccess;}1.ncclTopoGetSystem() 的过程:
1.1 加载拓扑信息(查看有/无)
1.2(无):创建根节点system
1.3 ncclTopoFillGpu 拓扑树遍历添加GPU NVLink
1.4 遍历添加网络设备节点
1.5 移除不可用点
1.6 Multi-Node NVLink (MNNVL)跨节点NVLink是否支持
1.7 Save Topo
最核心的就下面这三步:一、创建根节点,二、遍历并插入GPU节点和NVlink,三、遍历并插入网卡节点
看看关键的插入GPU节点:ncclTopoFillGpu()
源码速递:
源码位置:nccl-master\src\graph\xml.cc
1.3 ncclTopoFillGpu核心逻辑:
1.3.1:ncclTopoGetPciNode()确定当前GPU卡是否已创建xml node,没有就创建。
1.3.2:ncclTopoGetXmlFromSys()获取GPU到cpu的路径,路径信息获取,生成xml树。
1.3.3:GPU相关信息获取,设置NVlink信息。
1.3.1 ncclTopoGetPciNode()确定当前GPU卡是否已创建xml node,没有就创建。
源码位置:nccl-master\src\graph\xml.cc
// 定义一个函数ncclTopoGetPciNode,它接受一个ncclXml结构体指针xml,一个字符串指针busId用于指定PCI节点的busid,
// 以及一个指向ncclXmlNode指针的指针pciNode,用于返回找到的或新创建的PCI节点的地址。
ncclResult_t ncclTopoGetPciNode(struct ncclXml* xml, const char* busId, struct ncclXmlNode** pciNode) { // 调用xmlFindTagKv函数在xml中查找标签为"pci"且属性"busid"等于busId的节点。 // 如果找到,将找到的节点的地址存储在*pciNode中。 NCCLCHECK(xmlFindTagKv(xml, "pci", pciNode, "busid", busId)); // 如果*pciNode是NULL,表示没有找到与busId相对应的PCI节点。 if (*pciNode == NULL) { // 调用xmlAddNode函数在xml中添加一个新的"pci"节点,并将其地址存储在*pciNode中。 // 这里的NULL作为父节点参数,意味着新节点将被添加到XML树的根目录下。 NCCLCHECK(xmlAddNode(xml, NULL, "pci", pciNode)); // 调用xmlSetAttr函数设置新创建的PCI节点的"busid"属性为busId。 NCCLCHECK(xmlSetAttr(*pciNode, "busid", busId)); } // 函数成功完成,返回ncclSuccess表示操作成功。 return ncclSuccess;
}1.3.2 ncclTopoGetXmlFromSys(),是ncclTopoFillGpu中调用中最核心的
核心逻辑
1、getPciPath()获取GPU到cpu的路径;
2、获取link_width,link_speed等属性;
3、根据路径查找父节点,查找不到就创建父节点,继续查找父节点的父节点(爷爷节点),就这样循环查找和创建,构建xml树,直到找到父节点;
4、插入节点GPU节点。
XML文件

上述一些表示含义
busid:唯一标识每个设备在PCIe总线中的位置。
在 Linux 中,PCI 设备的设备名称(Device Name)通常以 "domain:bus:slot:function" 的形式来表示,其中冒号分隔开的各个数字具有以下含义:
domain:表示 PCI 设备所在的 PCI 域(Domain),通常为一个 16 位的十六进制数,用于区分不同的 PCI 域。在大多数情况下,这个值为 0000。
bus:表示 PCI 设备所在的总线(Bus),通常为一个 8 位的十六进制数,用于区分不同的总线。一个系统可以具有多个总线。
slot:表示 PCI 设备所在的插槽(Slot),通常为一个 5 位的十六进制数,用于区分不同的插槽。一个总线上可以有多个插槽。
function:表示 PCI 设备的功能(Function),通常为一个 3 位的十六进制数,用于区分同一插槽上的不同功能。一个插槽上可以有多个功能。
通过这种编号方式,可以唯一标识一个 PCI 设备的位置信息。在上述示例中,"0000:03:00.0" 表示该设备位于 PCI 域 0000,总线 03,插槽 00,功能 0。
请注意,这些数字可能会因系统配置而有所不同,具体取决于你的系统和相应的 PCI 设备。
四、XML转无向图
nccl对机器PCI系统拓扑分析后产生XML格式结果,
nccl对XML进行建图,为了之后进行路径搜索。
其中 ncclTopoGetSystem() 最后执行 ncclTopoGetSystemFromXml()
ncclTopoGetSystemFromXml()分为以下几个过程:
1.分配内存
2.XML中找 “ System ”
3.遍历子节点找到 CPU,调用ncclTopoAddCpu
4.ncclTopoAddNvLinks()
5.ncclTopoConnectCpus()
6.ncclTopoSortSystem()对TopoSystem中的组件排序,方便优化数据传输路径
只能搜索到当前节点(Node)内的拓扑
以下是一个无向图示例:

节点的类型: 节点的类型分为 GPU、PCI、NVS(nv switch)、CPU、NIC、NET
节点的信息: 节点的信息最主要的是 nlinks, 表示与该节点相连的设备数量,包括自己,比如与GPU0相连的设备数量有5个
边的信息: 边的信息则要关注以下内容:1. Link.type每条连接的类型,2.Link.remNode连接的对端节点。3. Link.bw 累计连接到带宽。4. Links,是一个数组,保存到其他设备的所有边
# definePATH_LOC 0 本身
PATH_NVL 1 NVLink
PATH_PIX 2 最多经过一个PCIe switch
PATH_PXB 3 经过多个PCIe switch
PATH_PHB 4 经过CPU
PATH_SYS 5
PATH_NET 6 通过网络五、路径计算
目标:计算所有设备到GPU、NIC、NVSwitch的通路,统计相应信息
上面 三、四源码都在 1. ncclTopoGetSystem()中
本节 五 源码为:
2. ncclTopoComputePaths
3. ncclTopoTrimSystem
4. ncclTopoComputePaths(comm->topo, comm->peerInfo)
最终得到的路径结果信息:1. Count,2.bw,3.Type
示例:如下图找出所有设备到GPU0的路径

结果:

过程:
- 计算的原则是使用广度优先搜索
- 最优的路径是路径最短且带宽最大
- 按照带宽大小遍历对端节点
1.从GPU0 开始遍历节点,GPU0 到GPU0,自己跟自己带宽最大,计算一遍,就不会再更新了。
2.假设遍历到GPU3

3. 针对GPU3,遍历与GPU3相连的节点,分别有五个:GPU3、GPU0、GPU1、GPU2、PCI89:00.
4.遍历GPU3到对端点GPU2。这里也就是比较GPU0----到----GPU2的最优路径。
一、GPU2 到 GPU0 ,bw:20
二、GPU2 到 GPU3 到GPU0 , bw=40
三、GPU2 到GPU1 到GPU0 , bw=20
这里会选择直连作为最优路径,因为虽然带宽小,但是路径短,即边的数量只有1,比其他两个的2条边少。
5.通过第四步,可以更新GPU2到GPU0 的路径了。通过暴力搜索,所有的节点都能计算出来。
GPU0的路径结果如下,包括连接类型,设备类型,带宽

六、Channel搜索
目标:
搜索channel,为了更好的利用带宽和网卡,以及同一块数据可以通过多个channel并发通信,多通道通信利用多个独立的通信路径同时传输数据,从而提高了通信带宽和吞吐量。
- 使用的是递归暴力搜索
- 根据设置的条件,最严格到一步一步放松,条件包括路径类型和带宽
- 满足的要求,即怎么才算成功搜索到一个channel:
- 1. 路径要通
- 2. path 路径类型要满足
- 3. 链路带宽 > 要求的条件带宽
- 4. channel * bw 要尽量大
例程:
1.为了方便起见,以以下拓扑链接为例,搜索 ring channel, 链接路径类型都是 nvlink, 相应贷款也列出来

2.根据GPU的SM计算能力,设置带宽条件,先从60开始,路径类型也从nvlink开始,从设备GPU0开始暴力搜索,判断GPU0到GPU1或者GPU3的路径类型满足,但是带宽不满足60,那么就失败了;先降低路径类型,从nvlink 一步一步降低路径类型要求,但是无论如何带宽60是不满足的,所以,恢复路径类型的要求到nvlink, 将带宽要求降低到40,40也不满足,因为GPU0开始,到GPU3是通的,但是转一圈回来,GPU2、GPU1到GPU0的带宽都是小于40的,所以成不了环。
3. 下一个节点的选择有两种策略,一个是按照PCI顺序,即GPU0的下一个节点是GPU1,GPU2,GPU3,这些都是要遍历的,针对GPU1, 下一个几点就是GPU2, GPU3,这样递归遍历;另一个策略是按照带宽大小寻找下一个节点;
4.当路径类型要求为nvlink, 路径带宽条件为20的时候,就有路可以通了。下一个节点是按照带宽大小寻找的,即GPU0下一个节点是GPU3, GPU3到GPU2,GPU2到GPU1。两个条件都满足,可以构成 0->1->2->3,也可以构成channel, 0->3->2->1, 这是一个循环。 同时,链路上的带宽是减掉当前遍历的带宽的,如下图,好理解一点,本来是40的变为20,本来是20的变为0。

5.还要在上面的基础上进行遍历,要充分利用带宽。流程还是一样的,就不细讲了,我们可以直接看图,按照上面的思路直接选,会花圈就行,以下的信息可以画出2个 channel 来,即 0->3->1->2, 0->2->1->3.

6. 所以,最终,搜索出4个channel。还可以从另一个角度去看 channel, 站在GPU3的角度,带宽为20的话,有两条nvlink到GPU0, 这个四个channel里只看GPU3的下一个节点,就会看到2个0, 1个1,1个2。这是最终的一个效果,即充分利用了所有的带宽。

七、数据通信链路的建立
目标:每个Rank都知道从哪个Rank接收数据并且发送数据给哪个Rank。

P2P和SHM是机内通信,NET是机间通信
首先介绍P2P通信。
完整过程:
1. 判断P2P是否可用,p2pCanConnect()
2. 接收端 执行recv setup,建立buffer,相关信息记录到 ncclConnInfo中,启动监听socket,ip和port记录到connectInfo,通过bootstrap将connectInfo 发送到发送端。
3. 发送端 执行send setup,建立buffer,相关信息记录到 ncclConnInfo中,启动监听socket,ip和port记录到connectInfo,通过bootstrap将connectInfo 发送到接收端。
4. 发送端接收 过程2 的信息,建立 发送 到 接收之间的链接。
5. 接收端接收 过程3 的信息, 建立 接收 到 发送之间的连接。
假设有两台机器,双机16卡
第一台机器环:
graph->intra: GPU/0 GPU/7 GPU/6 GPU/3 GPU/2 GPU/5 GPU/4 GPU/1
graph->inter: NET/0 NET/0第二台机器环:
graph->intra: GPU/10 GPU/9 GPU/8 GPU/13 GPU/12 GPU/15 GPU/14 GPU/11
graph->inter: NET/0 NET/0首先每个Rank都有一个ncclPeer,ncclPeer保存了两个connector,对于rank 10,send负责和rank 9通信,recv负责和rank 1通信。后续为了方便表述,假设rank 10叫接收端,rank 1叫发送端。
struct ncclPeer {struct ncclConnector send;struct ncclConnector recv;
};ncclConnector中connected表示是否完成连接的建立,transportResources为通信过程中用到的buffer,
struct ncclConnector {int connected;struct ncclProxyArgs *proxyAppend;struct ncclTransportComm* transportComm;void* transportResources; // Host-side resourcesstruct ncclConnInfo conn;struct ncclComm *comm;
};ncclConnInfo记录了通信过程上下文信息,本节只需要关注buffs,即通信过程中的buffer,实际位于transportResources,这里只是指针指过去。
struct ncclConnInfo {// Regular comm mechanismchar *buffs[NCCL_NUM_PROTOCOLS]; // Local for recv, remote for senduint64_t *tail; // Local for recv, remote for senduint64_t *head; // Local for send, remote for recvint direct; // Direct communicationvoid **ptrExchange; // Pointer exchange for direct communicationint *fifo; // Size fifo for proxyuint64_t step; // Keep where we areuint64_t llLastCleaning;
};相关文章:
从调用NCCL到深入NCCL源码
本小白目前研究GPU多卡互连的方案,主要参考NCCL和RCCL进行学习,如有错误,请及时指正! 内容还在整理中,近期不断更新!! 背景介绍 在大模型高性能计算时会需要用到多卡(GPU…...

深入理解Transformer的笔记记录(精简版本)NNLM → Word2Vec
文章的整体介绍顺序为: NNLM → Word2Vec → Seq2Seq → Seq2Seq with Attention → Transformer → Elmo → GPT → BERT 自然语言处理相关任务中要将自然语言交给机器学习中的算法来处理,通常需要将语言数学化,因为计算机机器只认数学符号…...

优选算法第一讲:双指针模块
优选算法第一讲:双指针模块 1.移动零2.复写零3.快乐数4.盛最多水的容器5.有效三角形的个数6.查找总价格为目标值的两个商品7.三数之和8.四数之和 1.移动零 链接: 移动零 下面是一个画图,其中,绿色部分标出的是重点: 代码实现&am…...

智能优化算法-水循环优化算法(WCA)(附源码)
目录 1.内容介绍 2.部分代码 3.实验结果 4.内容获取 1.内容介绍 水循环优化算法 (Water Cycle Algorithm, WCA) 是一种基于自然界水循环过程的元启发式优化算法,由Shah-Hosseini于2012年提出。WCA通过模拟水滴在河流、湖泊和海洋中的流动过程,以及蒸发…...

基于SpringBoot的个性化健康建议平台
1系统概述 1.1 研究背景 随着计算机技术的发展以及计算机网络的逐渐普及,互联网成为人们查找信息的重要场所,二十一世纪是信息的时代,所以信息的管理显得特别重要。因此,使用计算机来管理基于智能推荐的卫生健康系统的相关信息成为…...

Mapsui绘制WKT的示例
步骤 创建.NET Framework4.8的WPF应用在NuGet中安装Mapsui.Wpf 4.1.7添加命名空间和组件 <Window x:Class"TestMapsui.MainWindow"xmlns"http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x"http://schemas.microsoft.com/winf…...

Modbus TCP 西门子PLC指令以太口地址配置以及 Poll Slave调试软件地址配置
1前言 本篇文章讲了 Modbus TCP通讯中的一些以太网端口配置和遇到的一些问题, 都是肝货自己测试的QAQ。 2西门子 SERVER 指令 该指令是让外界设备主动连接此PLC被动连接, 所以这里应该填 外界设备的IP地址。 这边 我因为是电脑的Modbus Poll 主机来…...

MySQL表的基本查询上
1,创建表 前面基础的文章已经讲了很多啦,直接上操作: 非常简单!下一个! 2,插入数据 1,全列插入 前面也说很多了,直接上操作: 以上插入和全列插入类似,全列…...

MySQL中什么情况下类型转换会导致索引失效
文章目录 1. 问题引入2. 准备工作3. 案例分析3.1 正常情况3.2 发生了隐式类型转换的情况 4. MySQL隐式类型转换的规则4.1 案例引入4.2 MySQL 中隐式类型转换的规则4.3 验证 MySQL 隐式类型转换的规则 5. 总结 如果对 MySQL 索引不了解,可以看一下我的另一篇博文&…...

数据治理的意义
数据治理是一套管理数据资产的流程、策略、规则和控制措施,旨在确保数据的质量、安全性、可用性和合规性。数据治理的目标通常包括但不限于以下几点: 1. **提高数据质量**:确保数据的准确性、一致性、完整性和可靠性。 2. **确保数据安全**…...

快手游戏服务端C++开发一面-面经总结
1、tcp的重传机制有哪几种?具体描述一下 最基本的超时重传 超过时间就会重传 三个重复ACK 快速重传 减少等待超时、 接收方可以发送选择性确认 不用重传整段 乱序到达 可以通知哪些丢失 重复数据重传 2、override和final? override可写可不写 写出来就…...

git的学习使用(认识工作区,暂存区,版本区。添加文件的方法)
学习目标: 学习使用git,并且熟悉git的使用 学习内容: 必备环境:xshell,Ubuntu云服务器 如下: 搭建 git 环境认识工作区、暂存区、版本区git基本操作之添加文件(1):gi…...
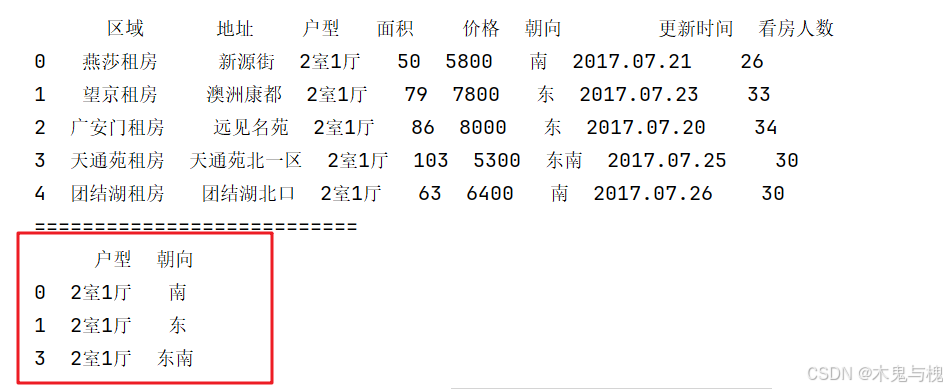
Series数据去重
目录 准备数据 Series数据去重 DataFrame数据和Series数据去重对比 在pandas中,Series.drop_duplicates(keep, inplace)方法用于删除Series对象中的重复值。 keep: 决定保留哪些重复值。可以取以下三个值之一: first(默认值&…...

Python语言核心12个必知语法细节
1. 变量和数据类型 Python是动态类型的,变量不需要声明类型。 python复制代码 a 10 # 整数 b 3.14 # 浮点数 c "Hello" # 字符串 d [1, 2, 3] # 列表 2. 条件语句 使用if, elif, else进行条件判断。 python复制代码 x 10 if x > 5: print(&q…...

解决ImageIO无法读取部分JPEG格式图片问题
解决ImageIO无法读取部分JPEG格式图片问题 问题描述 我最近对在线聊天功能进行了一些内存优化,结果在回归测试时,突然发现有张图片总是发送失败。测试同事把问题转到我这儿来看,我仔细检查了一下,发现是上传文件的接口报错&#…...

使用three.js 实现蜡烛效果
使用three.js 实现蜡烛效果 import * as THREE from "three" import { OrbitControls } from "three/examples/jsm/controls/OrbitControls.js"var scene new THREE.Scene(); var camera new THREE.PerspectiveCamera(60, window.innerWidth / window.in…...

手动在Linux服务器上部署并运行SpringBoot项目(新手向)
背景 当我们在本地开发完应用并且测试通过后,接着就要部署在服务器上启动。 步骤 1.先用maven将SpringBoot应用当成jar包 2.生成jar文件并复制此文件 3.xshell远程连接linux服务器,在xftp将文件粘贴到linux服务器,这里我放在/usr/local…...

自媒体短视频如何制作?
从0到1打造爆款短视频!300条视频创作经验分享,助你玩转自媒体! 想用短视频玩转自媒体却不知道从何下手?别担心!从21年开始接触短视频的我,断断续续创作了300多条视频,踩过不少坑,也收获了一些心得,核心秘诀就是:账号内容垂直化 + 明确受众群体! 我将从主题确定、脚本…...

2024年河南省职业技能竞赛(网络建设与运维赛项)
模块二:网络建设与调试 说明: 1.所网络设备在创建之后都可以直接通过 SecureCRT 软件 telnet 远程连接操作。 2.要求在全员化竞赛平台中保留竞赛生成的所有虚拟主机。 3.题目中所有所有的密码均为 Pass-1234,若未按照要求设置,涉 …...

git--git reset
HEAD 单独一个HEAD eg:git diff HEAD 表示当前结点。 HEAD~ HEAD~只处理当前分支。 注意:master分支的上一个结点是tmp分支的所在的结点fc11b74, 79f109e才是master的第二个父节点。 HEAD~ 当前结点的父节点。 HEAD~1 当前结点的父节点。 HEAD~n 当前结点索…...
: K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?)
云原生核心技术 (7/12): K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?
大家好,欢迎来到《云原生核心技术》系列的第七篇! 在上一篇,我们成功地使用 Minikube 或 kind 在自己的电脑上搭建起了一个迷你但功能完备的 Kubernetes 集群。现在,我们就像一个拥有了一块崭新数字土地的农场主,是时…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

基于uniapp+WebSocket实现聊天对话、消息监听、消息推送、聊天室等功能,多端兼容
基于 UniApp + WebSocket实现多端兼容的实时通讯系统,涵盖WebSocket连接建立、消息收发机制、多端兼容性配置、消息实时监听等功能,适配微信小程序、H5、Android、iOS等终端 目录 技术选型分析WebSocket协议优势UniApp跨平台特性WebSocket 基础实现连接管理消息收发连接…...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...

《基于Apache Flink的流处理》笔记
思维导图 1-3 章 4-7章 8-11 章 参考资料 源码: https://github.com/streaming-with-flink 博客 https://flink.apache.org/bloghttps://www.ververica.com/blog 聚会及会议 https://flink-forward.orghttps://www.meetup.com/topics/apache-flink https://n…...

微信小程序云开发平台MySQL的连接方式
注:微信小程序云开发平台指的是腾讯云开发 先给结论:微信小程序云开发平台的MySQL,无法通过获取数据库连接信息的方式进行连接,连接只能通过云开发的SDK连接,具体要参考官方文档: 为什么? 因为…...

【学习笔记】深入理解Java虚拟机学习笔记——第4章 虚拟机性能监控,故障处理工具
第2章 虚拟机性能监控,故障处理工具 4.1 概述 略 4.2 基础故障处理工具 4.2.1 jps:虚拟机进程状况工具 命令:jps [options] [hostid] 功能:本地虚拟机进程显示进程ID(与ps相同),可同时显示主类&#x…...

Hive 存储格式深度解析:从 TextFile 到 ORC,如何选对数据存储方案?
在大数据处理领域,Hive 作为 Hadoop 生态中重要的数据仓库工具,其存储格式的选择直接影响数据存储成本、查询效率和计算资源消耗。面对 TextFile、SequenceFile、Parquet、RCFile、ORC 等多种存储格式,很多开发者常常陷入选择困境。本文将从底…...

服务器--宝塔命令
一、宝塔面板安装命令 ⚠️ 必须使用 root 用户 或 sudo 权限执行! sudo su - 1. CentOS 系统: yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh2. Ubuntu / Debian 系统…...