基于Python实现电影推荐系统
电影推荐系统
标签:Tensorflow、矩阵分解、Surprise、PySpark
1、用Tensorflow实现矩阵分解
1.1、定义one_batch模块
import numpy as np
import pandas as pddef read_and_process(filename, sep = '::'):col_names = ['user', 'item', 'rate', 'timestamp']df = pd.read_csv(filename, sep = sep, header = None, names = col_names, engine = 'python')df['user'] -= 1df['item'] -= 1for col in ('user', 'item'):df[col] = df[col].astype(np.float32)df['rate'] = df['rate'].astype(np.float32)return dfdef get_data():df = read_and_process("./movielens/ml-1m/ratings.dat", sep = '::')rows = len(df)df = df.iloc[np.random.permutation(rows)].reset_index(drop = True)##打乱数据split_index = int(rows * 0.9)df_train = df[0: split_index]df_test = df[split_index:].reset_index(drop = True)print(df_train.shape, df_test.shape)return df_train, df_testclass ShuffleDataIterator(object):def __init__(self, inputs, batch_size = 10):##注意这里的输入self.inputs = inputsself.batch_size = batch_sizeself.num_cols = len(self.inputs)self.len = len(self.inputs[0])self.inputs = np.transpose(np.vstack([np.array(self.inputs[i]) for i in range(self.num_cols)]))def __iter__(self):return selfdef __len__(self):return self.lendef __next__(self):return self.next()def next(self):ids = np.random.randint(0, self.len, (self.batch_size,))out = self.inputs[ids, :]return [out[:, i] for i in range(self.num_cols)]class OneEpochDataIterator(ShuffleDataIterator):def __init__(self, inputs, batch_size=10):super(OneEpochDataIterator, self).__init__(inputs, batch_size=batch_size)if batch_size > 0:self.idx_group = np.array_split(np.arange(self.len), np.ceil(self.len / batch_size))else:self.idx_group = [np.arange(self.len)]self.group_id = 0##next函数不能写在__init__下面def next(self):if self.group_id >= len(self.idx_group):self.group_id = 0raise StopIterationout = self.inputs[self.idx_group[self.group_id], :]self.group_id += 1return [out[:, i] for i in range(self.num_cols)]
1.2、构建优化部分
def inference_svd(user_batch, item_batch, user_num, item_num, dim = 5, device = '/cpu:0'):with tf.device('/cpu:0'):global_bias = tf.get_variable('global_bias', shape = [])w_bias_user = tf.get_variable('embd_bias_user', shape = [user_num])w_bias_item = tf.get_variable('embd_bias_item', shape = [item_num])bias_user = tf.nn.embedding_lookup(w_bias_user, user_batch, name = 'bias_user')bias_item = tf.nn.embedding_lookup(w_bias_item, item_batch, name = 'bias_item')w_user = tf.get_variable('embd_user', shape = [user_num, dim], initializer = tf.truncated_normal_initializer(stddev = 0.02))w_item = tf.get_variable('embd_item', shape = [item_num, dim], initializer = tf.truncated_normal_initializer(stddev = 0.02))embd_user = tf.nn.embedding_lookup(w_user, user_batch, name = 'embedding_user')embd_item = tf.nn.embedding_lookup(w_item, item_batch, name = 'embedding_item')with tf.device(device):infer = tf.reduce_sum(tf.multiply(embd_user, embd_item), 1)##tf.multiply是元素点乘infer = tf.add(infer, global_bias)infer = tf.add(infer, bias_user)infer = tf.add(infer, bias_item, name = 'svd_inference')regularizer = tf.add(tf.nn.l2_loss(embd_user), tf.nn.l2_loss(embd_item), name = 'svd_regularization')return infer, regularizerdef optimizer(infer, regularizer, rate_batch, learning_rate = 0.001, reg = 0.1, device = '/cpu:0'):global_step = tf.train.get_global_step()assert global_step is not Nonewith tf.device(device):cost_l2 = tf.nn.l2_loss(tf.subtract(infer, rate_batch))penalty = tf.constant(reg, dtype = tf.float32, shape = [], name = 'l2')cost = tf.add(cost_l2, tf.multiply(regularizer, penalty))train_op = tf.train.AdamOptimizer(learning_rate).minimize(cost, global_step = global_step)return cost, train_op
1.3、定义训练函数
import time
from collections import deque
import numpy as np
import pandas as pd
from six import next
import tensorflow as tf
from tensorflow.core.framework import summary_pb2np.random.seed(12321)batch_size = 2000
user_num = 6040
item_num = 3952
dim = 15
epoch_max = 200
device = '/cpu:0'def make_scalar_summary(name, val):return summary_pb2.Summary(value = [summary_pb2.Summary.Value(tag = name, simple_value = val)])def svd(train, test):samples_per_batch = len(train) // batch_sizeiter_train = ShuffleDataIterator([train['user'], train['item'], train['rate']], batch_size = batch_size)##注意iuputsiter_test = OneEpochDataIterator([test['user'], test['item'], test['rate']], batch_size = -1)user_batch = tf.placeholder(tf.int32, shape = [None], name = 'id_user')item_batch = tf.placeholder(tf.int32, shape = [None], name = 'id_item')rate_batch = tf.placeholder(tf.float32, shape = [None])infer, regularizer = inference_svd(user_batch, item_batch, user_num = user_num, item_num = item_num, dim = dim, device = device)global_step = tf.train.get_or_create_global_step()cost, train_op = optimizer(infer, regularizer, rate_batch, learning_rate = 0.001, reg = 0.05, device = device)init_op = tf.global_variables_initializer()with tf.Session() as sess:sess.run(init_op)summary_writer = tf.summary.FileWriter(logdir = './data', graph = sess.graph)print('{} {} {} {}'.format('epoch', 'train_error', 'val_error', 'elapsed_time'))errors = deque(maxlen = samples_per_batch)start = time.time()for i in range(epoch_max * samples_per_batch):users, items, rates = next(iter_train)_, pred_batch = sess.run([train_op, infer], feed_dict = {user_batch: users, item_batch: items, rate_batch: rates})pred_batch = np.clip(pred_batch, 1.0, 5.0)errors.append(np.power(pred_batch - rates, 2))if i % samples_per_batch == 0:train_err = np.sqrt(np.mean(errors))test_err2 = np.array([])for users, items, rates in iter_test:pred_batch = sess.run(infer, feed_dict = {user_batch: users, item_batch: items})pred_batch = np.clip(pred_batch, 1.0, 5.0)test_err2 = np.append(test_err2, np.power((pred_batch - rates), 2))end = time.time()test_err = np.sqrt(np.mean(test_err2))print('{:3d} {:f} {:f} {:f}(s)'.format(i // samples_per_batch, train_err, test_err, end - start))train_err_summary = make_scalar_summary('training_error', train_err)test_err_summary = make_scalar_summary('testing_error', test_err)summary_writer.add_summary(train_err_summary, i)summary_writer.add_summary(test_err_summary, i)start = end
2、使用surprise库实现电影推荐
from surprise import KNNBaseline
from surprise import Dataset, Reader
from surprise.model_selection import cross_validatereader = Reader(line_format = 'user item rating timestamp', sep = '::')
data = Dataset.load_from_file('./movielens/ml-1m/ratings.dat', reader = reader)
algo = KNNBaseline()
perf = cross_validate(algo, data, measures = ['RMSE', 'MAE'], cv = 3, verbose = True)with open('./movielens/ml-1m/movies.dat', 'r', encoding = 'ISO-8859-1') as f:movies_id_dic = {}id_movies_dic = {}for line in f.readlines():movies = line.strip().split('::')id_movies_dic[int(movies[0]) - 1] = movies[1]movies_id_dic[movies[1]] = int(movies[0]) - 1toy_story_neighbors = algo.get_neighbors(movie_id, k = 5)
print('最接近《Toy Story (1995)》的5部电影是:')
for i in toy_story_neighbors:print(id_movies_dic[i])
3、用pyspark实现矩阵分解与预测
3.1、配置spark的运行环境
from pyspark import SparkConf, SparkContext
from pyspark.mllib.recommendation import ALS, MatrixFactorizationModelconf = SparkConf().setMaster('local').setAppName('movielenALS').set('spark.excutor.memory', '2g')
sc = SparkContext.getOrCreate(conf)
3.2、将数据转换为RDD格式
from pyspark.mllib.recommendation import Ratingratings_data = sc.textFile('./movielens/ml-1m/ratings.dat')
ratings_int = ratings_data.map(lambda x: x.split('::')[0:3])
rates_data = ratings_int.map(lambda x: Rating(int(x[0]), int(x[1]), int(x[2])))
3.3、预测
sc.setCheckpointDir('checkpoint/')
ALS.checkpointInterval = 2
model = ALS.train(ratings = rates_data, rank = 20, iterations = 5, lambda_ = 0.02)
预测user14对item25的评分
print(model.predict(14, 25))
预测item25的最值得推荐的10个user
print(model.recommendUsers(25, 10))
预测user14的最值得推荐的10个item
print(model.recommendProducts(14, 10))
预测出每个user最值得被推荐的3个item
print(model.recommendProductsForUsers(3).collect())
相关文章:

基于Python实现电影推荐系统
电影推荐系统 标签:Tensorflow、矩阵分解、Surprise、PySpark 1、用Tensorflow实现矩阵分解 1.1、定义one_batch模块 import numpy as np import pandas as pddef read_and_process(filename, sep ::):col_names [user, item, rate, timestamp]df pd.read_cs…...
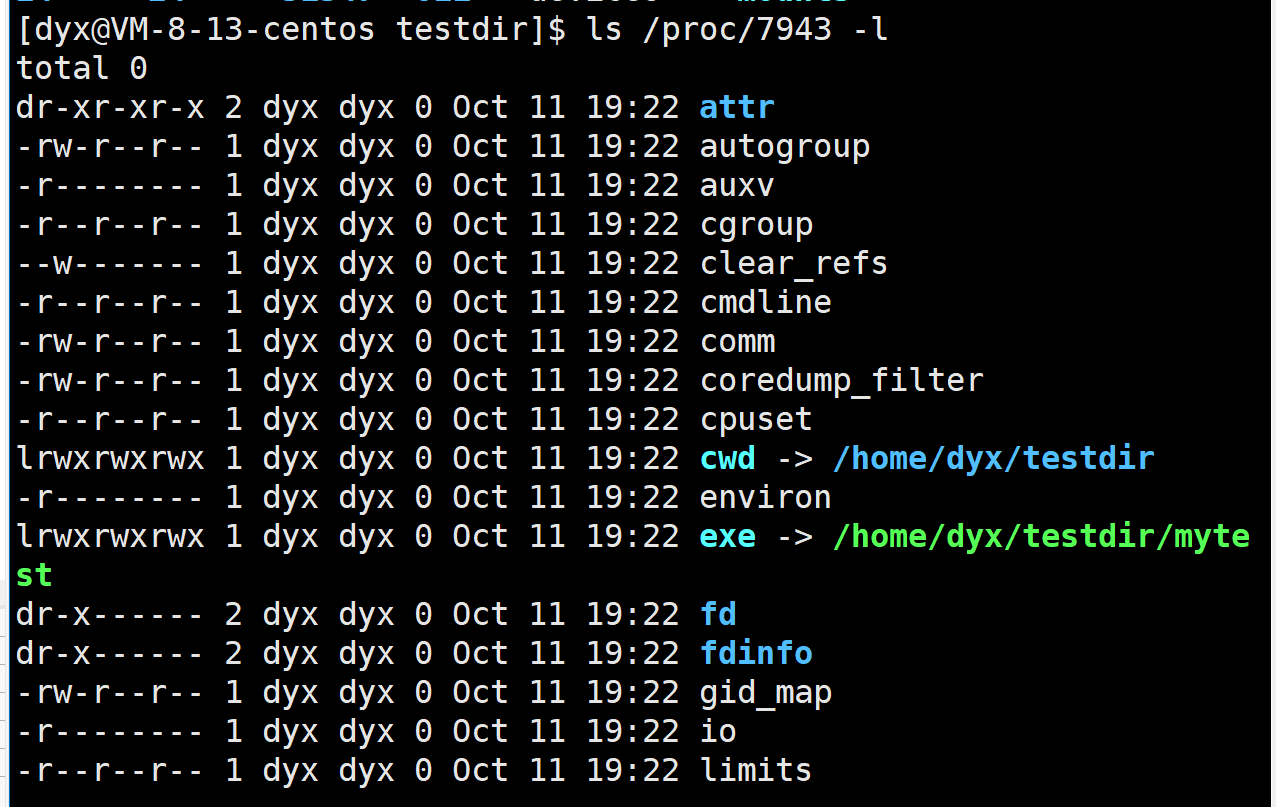
【linux】进程理解
🔥个人主页:Quitecoder 🔥专栏:linux笔记仓 目录 01.进程的基本概念进程的组成部分进程的特性进程的状态 02.PCBPCB的组成部分task_structtask_struct 的主要组成部分 03.进程属性查看进程 04.通过系统调用创建进程-fork初识工作…...

文件IO练习1
题目一: 1、使用fread和fwrite完成两个文件的拷贝,要求源文件和目标文件由外界输入 实现代码: #define LEN_BUF 256int main(int argc, const char *argv[]) {if(argc ! 3){fprintf(stderr,"程序入参输入有误\n");return -1;}FILE…...

c++ std::future 和 std::promise 的实现工作原理简介
为了便于理解 std::future 和 std::promise 的实现工作原理,我们可以创建一个简化的版本。这包括共享状态、Promise 设置值、Future 获取值的核心机制。我们的示例代码将实现 SimplePromise 和 SimpleFuture 两个类,二者通过一个共享状态实现线程间的通信…...

MATLAB(Octave)混电动力能耗评估
🎯要点 处理电动和混动汽车能耗的后向和前向算法模型(simulink),以及图形函数、后处理函数等实现。构建储能元数据信息:电池标称特性、电池标识符等以及静止、恒定电流和恒定电压等特征阶段。使用电流脉冲或要识别的等效电路模型类型配置阻抗…...

opencv学习:人脸识别器特征提取BPHFaceRecognizer_create算法的使用
BPHFaceRecognizer_create算法 在OpenCV中,cv2.face.LBPHFaceRecognizer_create()函数用于创建一个局部二值模式直方图(Local Binary Patterns Histograms,简称LBPH)人脸识别器。LBPH是一种用于人脸识别的特征提取方法࿰…...

HTML+CSS总结【量大管饱】
文章目录 前言HTML总结语义化标签常用标签H5新的语义元素H5的媒体标签\<embed> 元素(少用)\<object>元素(少用)\<audio>\<video> 元素包含关系iframe元素嵌入flash内容常用表单inputselect CSS总结权重样…...
其实开发如此简单)
Android开发之Broadcast Receive(广播机制)其实开发如此简单
什么是BroadcastReceiver BroadcastReceiver(广播接收器)用于响应来自其他应用程序或者系统的广播消息。这些消息有时被称为事件或者意图。本质上来讲BroadcastReceiver是一个全局的监听器,隶属于Android四大组件之一。 使用场景 1、 不同…...

Chromium 中chrome.cookies扩展接口c++实现分析
chrome.cookies 使用 chrome.cookies API 查询和修改 Cookie,并在 Cookie 发生更改时收到通知。 更多参考官网定义:chrome.cookies | API | Chrome for Developers (google.cn) 本文以加载一个清理cookies功能扩展为例 https://github.com/Google…...

excel筛选多个单元格内容
通常情况下,excel单元格筛选时,只筛选一个条件,如果要筛选多个条件,可以如下操作: 字符串中间用空格分隔就行。...
)
Instant 和 Duration 类(进行时间处理)
Instant Instant 类是 Java 8 中引入的,用于表示一个具体的时间点,它基于 UTC(协调世界时)时区。以下是 Instant 类的一些常用方法及其简要说明: now():获取当前的 Instant 对象,表示当前时间…...

Java每日面试题(Spring)(day19)
目录 Spring的优点什么是Spring AOP?AOP有哪些实现方式?JDK动态代理和CGLIB动态代理的区别?Spring AOP相关术语Spring通知有哪些类型?什么是Spring IOC?Spring中Bean的作用域有哪些?Spring中的Bean什么时候…...

【多线程】线程池(上)
文章目录 线程池基本概念线程池的优点线程池的特点 创建线程池自定义线程池线程池的工作原理线程池源码分析内置线程池newFixedThreadPoolSingleThreadExecutornewCachedThreadPoolScheduledThreadPool 线程池的核心线程是否会被回收?拒绝策略ThreadPoolExecutor.AbortPolicyT…...

ansible 语句+jinjia2+roles
文章目录 1、when语句1、判断表达式1、比较运算符2、逻辑运算符3、根据rc的返回值判断task任务是否执行成功5、通过条件判断路径是否存在6、in 2、when和其他关键字1、block关键字2、rescue关键字3、always关键字 3、ansible循环语句1、基于列表循环(whith_items)2、基于字典循…...

【Docker项目实战】使用Docker部署HumHub社交网络平台
【Docker项目实战】使用Docker部署HumHub社交网络平台 一、HumHub介绍1.1 HumHub简介1.2 HumHub特点1.3 主要使用场景二、本次实践规划2.1 本地环境规划2.2 本次实践介绍三、本地环境检查3.1 检查Docker服务状态3.2 检查Docker版本3.3 检查docker compose 版本四、下载HumHub镜…...

“医者仁术”再进化,AI让乳腺癌筛查迎难而上
世卫组织最新数据显示,我国肿瘤疾病仍然呈上升趋势,肿瘤防控形势依然比较严峻。尤其是像乳腺癌等发病率较高的疾病,早诊断和早治疗意义重大,能够有效降低病死率。 另一方面,中国地域广阔且发展不平衡,各地…...

安卓流式布局实现记录
效果图: 1、导入第三方控件 implementation com.google.android:flexbox:1.1.0 2、布局中使用 <com.google.android.flexbox.FlexboxLayoutandroid:id"id/baggageFl"android:layout_width"match_parent"android:layout_height"wrap_co…...
)
-bash gcc command not found解决方案(CentOS操作系统)
以 CentOS7 为例,执行以下语句 : yum install gcc如果下载不成功,并且网络没有问题。 执行以下语句 : cp -r /etc/yum.repos.d /etc/yum.repos.d.bakrm -f /etc/yum.repos.d/*.repocurl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.…...

(二)Python输入输出函数
一、输入函数 input函数:用户输入的数据,以字符串形式返回;若需数值类型,则进行类型转换。 xinput("请入你喜欢的蔬菜:") print(x) 二、输出函数 print函数 输出单一数值 x666 print(x) 输出混合类型…...

从调用NCCL到深入NCCL源码
本小白目前研究GPU多卡互连的方案,主要参考NCCL和RCCL进行学习,如有错误,请及时指正! 内容还在整理中,近期不断更新!! 背景介绍 在大模型高性能计算时会需要用到多卡(GPU…...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...

从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...

蓝牙 BLE 扫描面试题大全(2):进阶面试题与实战演练
前文覆盖了 BLE 扫描的基础概念与经典问题蓝牙 BLE 扫描面试题大全(1):从基础到实战的深度解析-CSDN博客,但实际面试中,企业更关注候选人对复杂场景的应对能力(如多设备并发扫描、低功耗与高发现率的平衡)和前沿技术的…...
:滤镜命令)
ffmpeg(四):滤镜命令
FFmpeg 的滤镜命令是用于音视频处理中的强大工具,可以完成剪裁、缩放、加水印、调色、合成、旋转、模糊、叠加字幕等复杂的操作。其核心语法格式一般如下: ffmpeg -i input.mp4 -vf "滤镜参数" output.mp4或者带音频滤镜: ffmpeg…...

SpringCloudGateway 自定义局部过滤器
场景: 将所有请求转化为同一路径请求(方便穿网配置)在请求头内标识原来路径,然后在将请求分发给不同服务 AllToOneGatewayFilterFactory import lombok.Getter; import lombok.Setter; import lombok.extern.slf4j.Slf4j; impor…...

Bean 作用域有哪些?如何答出技术深度?
导语: Spring 面试绕不开 Bean 的作用域问题,这是面试官考察候选人对 Spring 框架理解深度的常见方式。本文将围绕“Spring 中的 Bean 作用域”展开,结合典型面试题及实战场景,帮你厘清重点,打破模板式回答,…...

LOOI机器人的技术实现解析:从手势识别到边缘检测
LOOI机器人作为一款创新的AI硬件产品,通过将智能手机转变为具有情感交互能力的桌面机器人,展示了前沿AI技术与传统硬件设计的完美结合。作为AI与玩具领域的专家,我将全面解析LOOI的技术实现架构,特别是其手势识别、物体识别和环境…...
ubuntu22.04有线网络无法连接,图标也没了
今天突然无法有线网络无法连接任何设备,并且图标都没了 错误案例 往上一顿搜索,试了很多博客都不行,比如 Ubuntu22.04右上角网络图标消失 最后解决的办法 下载网卡驱动,重新安装 操作步骤 查看自己网卡的型号 lspci | gre…...
基础)
6个月Python学习计划 Day 16 - 面向对象编程(OOP)基础
第三周 Day 3 🎯 今日目标 理解类(class)和对象(object)的关系学会定义类的属性、方法和构造函数(init)掌握对象的创建与使用初识封装、继承和多态的基本概念(预告) &a…...