G-Set(增长集合,Grow-Only Set)
一、概念
G-Set(增长集合,Grow-Only Set)是一种冲突自由复制数据类型(Conflict-Free Replicated Data Type, CRDT),用于在分布式系统中同步和合并数据,而不需要中央协调器。G-Set 支持两种操作:添加(add)和查询(query)。一旦元素被添加到 G-Set 中,它就不能被删除,这就是为什么它被称为“增长集合”。
1.1 G-Set 的特点
- 不可变性:一旦元素被添加到集合中,它就永远存在于集合中,不能被删除。
- 幂等性:多次添加同一个元素的效果和添加一次该元素的效果相同。
- 交换性:元素的添加顺序不影响最终的集合状态。
- 冲突无关:在不同节点上并行添加元素不会导致冲突,所有的更改最终都会被合并到每个节点的副本中。
1.2 G-Set 的应用场景
G-Set 非常适合于需要合并来自不同节点的数据,而这些数据不需要删除操作的场景。例如:
- 分布式计数器:计数器的每次增加可以视为向 G-Set 中添加一个元素。
- 曾在线用户集合:记录哪些用户曾经在线,即使他们后来下线了。
- 标签系统:在一个分布式系统中为对象添加标签,不需要删除标签的功能。
1.3 G-Set 的局限性
由于 G-Set 是一个只增不减的集合,它的主要局限性在于无法从集合中删除元素。这可能导致随着时间的推移,集合的大小不断增长,占用更多的存储空间。为了解决这个问题,CRDT 研究中引入了其他类型的集合,如 OR-Set(可观察移除集合),它允许元素被添加和删除,同时仍然保持冲突无关的特性。
1.4 实现示例
在 Java 中,一个简单的 G-Set 实现可以使用 HashSet 来完成:
import java.util.HashSet;
import java.util.Set;public class GSet<E> {private final Set<E> set = new HashSet<>();public void add(E element) {set.add(element);}public boolean contains(E element) {return set.contains(element);}public Set<E> getElements() {return new HashSet<>(set);}
}
这个实现提供了添加元素和查询元素是否存在的基本操作。由于使用了 HashSet,这个 G-Set 实现自然就具有了幂等性和交换性的特点。
二、示例
2.1 G-Set 的应用场景:分布式计数器
在分布式系统中,使用 G-Set 实现计数器的一个常见方法是将每次计数增加视为向集合中添加一个唯一标识符(例如,时间戳、UUID等)。这样,计数器的值就等于集合中元素的数量。下面是一个具体的示例:
2.1.1 场景描述
假设有一个在线文章阅读平台,需要统计一篇文章的阅读次数。由于平台是分布式的,文章可以同时被多个节点上的用户阅读。为了确保阅读次数的准确性,平台决定使用 G-Set 来实现分布式计数器。
2.1.2 实现步骤
- 初始化:对于每篇文章,初始化一个空的 G-Set。
- 阅读操作:当一个用户阅读文章时,系统生成一个唯一标识符(例如,
用户ID+时间戳),并将其添加到文章对应的 G-Set 中。 - 计数查询:要获取文章的阅读次数,只需计算 G-Set 中元素的数量。
2.1.3 示例代码
import java.util.HashSet;
import java.util.Set;public class ArticleReadCounter {private final Set<String> readSet = new HashSet<>();// 用户阅读文章时调用此方法public void addRead(String userId) {String uniqueId = userId + "-" + System.currentTimeMillis();readSet.add(uniqueId);}// 获取文章的阅读次数public int getReadCount() {return readSet.size();}
}
2.1.4 示例使用
public class Main {public static void main(String[] args) {ArticleReadCounter counter = new ArticleReadCounter();// 模拟用户阅读文章counter.addRead("user1");counter.addRead("user2");counter.addRead("user3");// 获取并打印阅读次数System.out.println("Article read count: " + counter.getReadCount());}
}
2.1.5 分布式环境下的合并
在分布式环境下,每个节点都可以有自己的 G-Set 实例。当需要合并两个节点的计数器时,可以将两个 G-Set 的元素合并到一个新的 G-Set 中,这个新的 G-Set 包含了所有唯一的阅读事件。由于 G-Set 是冲突无关的,这种合并操作是安全的,不会丢失数据,也不会产生冲突。
跟踪一个在线文章阅读平台的文章阅读次数,其中每次阅读都由一个唯一的事件ID表示,该ID由用户ID和时间戳组合而成。
2.1.5.1 分布式环境设置
假设我们的分布式系统有三个节点展示网页信息:Node A、Node B 和 Node C。每个节点都维护着自己的 G-Set 实例来跟踪文章的阅读事件。
- Node A 的 G-Set 包含:
{"user1-1622547600", "user2-1622547605"} - Node B 的 G-Set 包含:
{"user3-1622547610", "user4-1622547615"} - Node C 的 G-Set 包含:
{"user2-1622547605", "user5-1622547620"}
这里,"user2-1622547605" 在 Node A 和 Node C 中都出现了,展示了在分布式系统中,同一个阅读事件可能被多个节点观察到的情况。
2.1.5.2 合并过程
为了得到全局的文章阅读次数,我们需要将这三个节点的 G-Set 合并。合并操作是将所有节点的 G-Set 中的元素合并到一个新的集合中,由于 G-Set 的特性,即使某些阅读事件在多个节点中被记录,它们在合并后的集合中只会出现一次。
合并后的 G-Set 将包含:{"user1-1622547600", "user2-1622547605", "user3-1622547610", "user4-1622547615", "user5-1622547620"}
2.1.5.3 计数结果
文章的总阅读次数等于合并后的 G-Set 中元素的数量,即 5 次。
2.1.5.4 示例代码
import java.util.HashSet;
import java.util.Set;public class DistributedCounter {// 模拟合并过程public static Set<String> mergeSets(Set<String>... sets) {Set<String> mergedSet = new HashSet<>();for (Set<String> set : sets) {mergedSet.addAll(set);}return mergedSet;}public static void main(String[] args) {// 初始化节点的 G-SetsSet<String> nodeASet = new HashSet<>(Set.of("user1-1622547600", "user2-1622547605"));Set<String> nodeBSet = new HashSet<>(Set.of("user3-1622547610", "user4-1622547615"));Set<String> nodeCSet = new HashSet<>(Set.of("user2-1622547605", "user5-1622547620"));// 合并 G-SetsSet<String> mergedSet = mergeSets(nodeASet, nodeBSet, nodeCSet);// 计算并打印总阅读次数System.out.println("Total article reads: " + mergedSet.size());}
}
2.1.6 注意
这种方法的缺点是随着阅读次数的增加,G-Set 的大小也会不断增长,可能会占用大量的存储空间。在实际应用中,需要根据具体情况考虑是否适合使用 G-Set 实现分布式计数器,或者寻找其他更高效的解决方案。
2.2 G-Set 的应用场景:曾在线用户集合
在分布式系统中,使用 G-Set 来跟踪在线用户集合是一个很好的应用场景。在这个场景中,每当用户上线,系统就会将该用户的唯一标识符(如用户ID)添加到 G-Set 中。由于 G-Set 是一个只增不减的集合,这意味着一旦用户ID被添加,它就会永久保留在集合中。这对于跟踪曾经在线的用户非常有用,但请注意,这不适用于实时跟踪当前在线用户,因为用户下线后,其ID仍然保留在集合中。
2.2.1 示例代码
import java.util.HashSet;
import java.util.Set;public class OnlineUserTracker {private final Set<String> onlineUsers = new HashSet<>();// 用户上线时调用此方法public void userOnline(String userId) {onlineUsers.add(userId);}// 检查用户是否曾经上线过public boolean hasUserEverBeenOnline(String userId) {return onlineUsers.contains(userId);}// 获取曾经上线过的用户总数public int getTotalUsersEverOnline() {return onlineUsers.size();}
}
2.2.2 示例使用
public class Main {public static void main(String[] args) {OnlineUserTracker tracker = new OnlineUserTracker();// 模拟用户上线tracker.userOnline("user1");tracker.userOnline("user2");tracker.userOnline("user3");// 检查特定用户是否曾经上线过System.out.println("Has user2 ever been online? " + tracker.hasUserEverBeenOnline("user2"));// 获取并打印曾经上线过的用户总数System.out.println("Total users ever online: " + tracker.getTotalUsersEverOnline());}
}
2.2.3 分布式环境下的合并
在分布式环境下,每个节点都可以维护自己的在线用户 G-Set。当需要同步或合并两个节点的在线用户集合时,可以简单地将两个 G-Set 的元素合并到一个新的 G-Set 中。这个新的 G-Set 包含了所有唯一的用户ID,从而确保了数据的一致性和完整性。
每当用户上线时,系统就会将该用户的唯一标识符(如用户ID)添加到 G-Set 中。由于 G-Set 是一个只增不减的集合,这意味着一旦用户ID被添加,它就会永久保留在集合中,适用于跟踪曾经上线的用户。
2.2.3.1 分布式环境设置
假设我们的分布式系统有三个节点:Node A、Node B 和 Node C。每个节点都维护着自己的 G-Set 实例来跟踪在线用户。
- Node A 的 G-Set 包含在线用户:
{"user1", "user2"} - Node B 的 G-Set 包含在线用户:
{"user3", "user4"} - Node C 的 G-Set 包含在线用户:
{"user2", "user5"}
这里,"user2" 在 Node A 和 Node C 中都出现了,展示了在分布式系统中,同一个用户可能在多个节点上线的情况。
2.2.3.2 合并过程
为了得到聊天室的全局在线用户集,我们需要将这三个节点的 G-Set 合并。合并操作是将所有节点的 G-Set 中的元素合并到一个新的集合中,由于 G-Set 的特性,即使某些用户ID在多个节点中被记录,它们在合并后的集合中只会出现一次。
合并后的 G-Set 将包含在线用户:{"user1", "user2", "user3", "user4", "user5"}
2.2.3.3 示例代码
import java.util.HashSet;
import java.util.Set;public class OnlineUserTracker {// 模拟合并过程public static Set<String> mergeOnlineUsers(Set<String>... userSets) {Set<String> mergedSet = new HashSet<>();for (Set<String> set : userSets) {mergedSet.addAll(set);}return mergedSet;}public static void main(String[] args) {// 初始化节点的 G-SetsSet<String> nodeAUsers = new HashSet<>(Set.of("user1", "user2"));Set<String> nodeBUsers = new HashSet<>(Set.of("user3", "user4"));Set<String> nodeCUsers = new HashSet<>(Set.of("user2", "user5"));// 合并 G-SetsSet<String> mergedUsers = mergeOnlineUsers(nodeAUsers, nodeBUsers, nodeCUsers);// 打印合并后的在线用户集System.out.println("Merged online users: " + mergedUsers);}
}
2.2.4 注意
- G-Set 适用于跟踪用户的在线状态,但由于其只增不减的特性,它不适合用于实时监控当前在线用户。
- 随着时间的推移,G-Set 的大小可能会不断增长,这可能会导致存储空间的问题。在实际应用中,需要考虑这一点,并根据具体需求选择合适的数据结构。
2.3 G-Set 的应用场景:标签系统
在分布式系统中,使用 G-Set 实现标签系统是一个很好的应用场景。在这个场景中,每当需要给一个对象(如文章、图片等)添加标签时,系统就会将该标签的唯一标识符(如标签名)添加到与该对象关联的 G-Set 中。由于 G-Set 是一个只增不减的集合,这意味着一旦标签被添加,它就会永久保留在集合中,适用于标签的累积和历史记录。
2.3.1 示例代码
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;public class TagSystem {// 使用 Map 来存储每个对象及其关联的 G-Setprivate final Map<String, Set<String>> objectTags = new HashMap<>();// 给对象添加标签public void addTagToObject(String objectId, String tag) {// 获取或创建与对象关联的 G-SetSet<String> tags = objectTags.computeIfAbsent(objectId, k -> new HashSet<>());// 将标签添加到 G-Set 中tags.add(tag);}// 获取对象的所有标签public Set<String> getTagsForObject(String objectId) {return objectTags.getOrDefault(objectId, new HashSet<>());}
}
2.3.2 示例使用
public class Main {public static void main(String[] args) {TagSystem tagSystem = new TagSystem();// 给对象添加标签tagSystem.addTagToObject("article1", "Technology");tagSystem.addTagToObject("article1", "Innovation");tagSystem.addTagToObject("article2", "Travel");tagSystem.addTagToObject("article1", "2023");// 获取并打印对象的标签System.out.println("Tags for article1: " + tagSystem.getTagsForObject("article1"));System.out.println("Tags for article2: " + tagSystem.getTagsForObject("article2"));}
}
2.3.3 分布式环境下的合并
在分布式环境下,每个节点都可以维护自己的标签 G-Set。当需要同步或合并两个节点的标签集合时,可以简单地将两个 G-Set 的元素合并到一个新的 G-Set 中。这个新的 G-Set 包含了所有唯一的标签,从而确保了数据的一致性和完整性。
在这个场景中,每当需要给一个对象(如文章、图片等)添加标签时,系统就会将该标签的唯一标识符(如标签名)添加到与该对象关联的 G-Set 中。由于 G-Set 是一个只增不减的集合,这意味着一旦标签被添加,它就会永久保留在集合中。
2.3.3.1 分布式环境设置
假设我们的分布式系统有三个节点:Node A、Node B 和 Node C。每个节点都维护着自己的 G-Set 实例来跟踪对象的标签。
- Node A 的 G-Set 包含对象 “Article1” 的标签:
{"Tech", "Innovation"} - Node B 的 G-Set 包含对象 “Article1” 的标签:
{"2023", "Tech"} - Node C 的 G-Set 包含对象 “Article1” 的标签:
{"Innovation", "Environment"}
这里,标签 “Tech” 和 “Innovation” 在多个节点中出现了,展示了在分布式系统中,同一个标签可能被多个节点添加的情况。
2.3.3.2 合并过程
为了得到对象 “Article1” 的全局标签集,我们需要将这三个节点的 G-Set 合并。合并操作是将所有节点的 G-Set 中的元素合并到一个新的集合中,由于 G-Set 的特性,即使某些标签在多个节点中被记录,它们在合并后的集合中只会出现一次。
合并后的 G-Set 将包含对象 “Article1” 的标签:{"Tech", "Innovation", "2023", "Environment"}
2.3.3.3 示例代码
import java.util.HashSet;
import java.util.Set;public class TagSystem {// 模拟合并过程public static Set<String> mergeTags(Set<String>... tagSets) {Set<String> mergedSet = new HashSet<>();for (Set<String> set : tagSets) {mergedSet.addAll(set);}return mergedSet;}public static void main(String[] args) {// 初始化节点的 G-SetsSet<String> nodeATags = new HashSet<>(Set.of("Tech", "Innovation"));Set<String> nodeBTags = new HashSet<>(Set.of("2023", "Tech"));Set<String> nodeCTags = new HashSet<>(Set.of("Innovation", "Environment"));// 合并 G-SetsSet<String> mergedTags = mergeTags(nodeATags, nodeBTags, nodeCTags);// 打印合并后的标签集System.out.println("Merged tags for Article1: " + mergedTags);}
}
2.3.4 注意
- G-Set 适用于累积对象的标签,但由于其只增不减的特性,它不适合用于需要频繁删除标签的场景。
- 随着时间的推移,每个对象关联的 G-Set 的大小可能会不断增长,这可能会导致存储空间的问题。在实际应用中,需要考虑这一点,并根据具体需求选择合适的数据结构。
相关文章:
)
G-Set(增长集合,Grow-Only Set)
一、概念 G-Set(增长集合,Grow-Only Set)是一种冲突自由复制数据类型(Conflict-Free Replicated Data Type, CRDT),用于在分布式系统中同步和合并数据,而不需要中央协调器。G-Set 支持两种操作…...

《Vue.js 组件开发秘籍:从基础到高级》
Vue.js 组件开发是构建 Vue 应用程序的核心方法之一。以下是对 Vue.js 组件开发的介绍: 一、什么是 Vue.js 组件? 在 Vue.js 中,组件是可复用的 Vue 实例,它们封装了特定的功能和用户界面。每个组件都有自己独立的模板、逻辑和样…...
【Next.js 项目实战系列】03-查看 Issue
原文链接 CSDN 的排版/样式可能有问题,去我的博客查看原文系列吧,觉得有用的话,给我的库点个star,关注一下吧 上一篇【Next.js 项目实战系列】02-创建 Issue 查看 Issue 展示 Issue 本节代码链接 首先使用 prisma 获取所有…...

Android Settings 设置项修改
Settings 设置项 在 Android 系统上,WRITE_SETTINGS 这个权限从 API 1 就已经开始有了。 通过在 app 中设置权限 android.permission.WRITE_SETTINGS 允许 app 读/写 系统设置。 在官方文档的描述中,还有一段注意事项: Note: If the app targets API level 23 or higher,…...

Windows远程桌面到Ubuntu
在Ubuntu系统中,默认情况下root账户是被禁用的,为了安全起见,建议不要直接使用root账户登录图形界面。但是,如果出于特定的管理或维护需求,您可以按照以下步骤启用和使用root账户登录图形界面: 启用root账户…...
)
解释 RESTful API,以及如何使用它构建 web 应用程序(AI)
RESTful API(Representational State Transfer)是一种基于HTTP协议的软件架构风格,用于构建可扩展、可维护和可重用的网络服务。 RESTful API的特点包括: 1. 基于资源:每个API都代表一个或多个资源,这些资…...

NestJs:处理身份验证和授权
使用 Nest.js 开发项目时,处理身份验证和授权是常见的需求,可以采用以下架构和实现方式。 架构 用户认证模块 (Auth Module): 服务 (Service): 处理用户登录逻辑,生成 JWT(JSON Web Token),以及验证 token…...
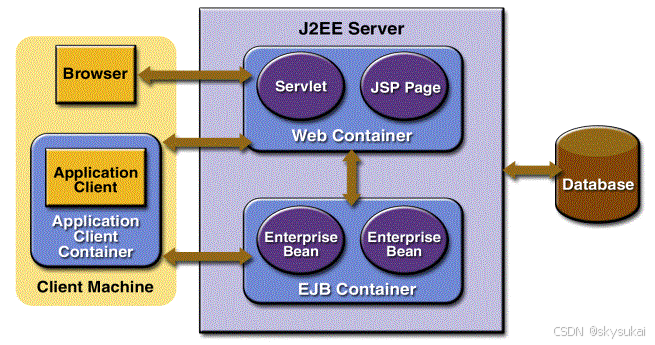
Java EE规范
1、简介 Java EE的全称是Java Platform, Enterprise Edition。早期Java EE也被称为J2EE,即Java 2 Platform Enterprise Edition的缩写。从J2EE1.5以后,就改名成为Java EE。一般来说,企业级应用具备这些特征:1、数据量特别大&…...

Ollama及其Open-WebUI部署更新
目录 1 安装ollama 2 安装Open-WebUI 2.1 不使用容器安装open-webui 2.2 使用Docker安装open-webui 2.3 基于docker升级open-webui 1 安装ollama curl -fsSL https://ollama.com/install.sh | sh启动、关闭ollama systemctl start ollama systemctl stop ollama sys…...

手写 | 设计模式
这里写目录标题 观察者 vs 发布订阅 观察者 vs 发布订阅 参考代码 观察者模式,一对多,两个角色:观察者observer和被观察者/主题Subject。 Subject维护一个数组,记录有哪些Observer;通过调自身的noticefy方法…...

基于深度学习的地形分类与变化检测
基于深度学习的地形分类与变化检测是遥感领域的一个关键应用,利用深度学习技术从卫星、无人机等地球观测平台获取的遥感数据中自动分析地表特征,并识别地形的变化。这一技术被广泛应用于城市规划、环境监测、灾害预警、土地利用变化分析等领域。 1. 地形…...

进程、线程、协程
文章目录 前言一、易混概念1.1 同步vs异步1.2 并发vs并行 二、进程(Process)2.1进程概念2.2 进程三个基本状态2.3多进程方式编程 三、线程(Thread)3.1 线程的引入3.2 线程概念3.3 多线程编程3.4 GIL对多线程的影响3.5 GIL是否意味…...
——元件基础(完整版))
嵌入式工程师成长之路(1)——元件基础(完整版)
系列文章目录 1.元件基础 2.电路设计 3.PCB设计 4.元件焊接 5.板子调试 6.程序设计 7.算法学习 8.编写exe 9.检测标准 10.项目举例 11.职业规划 文章目录 前言一、认识元件①、认识元件②、认识封装二、电阻1.上拉电阻与下拉电阻①、定义②、应用③、阻值选择④、因上下拉电…...

在Ubuntu 20.04 上安装 CoppeliaSim
在 Ubuntu 20.04 上安装 CoppeliaSim Edu V4.6.0 rev18 的步骤如下: 1. 下载安装文件: 首先,确保您已经下载了 CoppeliaSim_Edu_V4_6_0_rev18_Ubuntu20_04.tar.xz 文件。您可以从 Coppelia Robotics 的官方网站下载。 2. 解压缩文件: 打开终端&#…...
)
pulseaudio的相关操作(二)
这篇文章主要介绍pulseaudio playback的相关API,pulseaudio playback的具体实例可以参考[2]。如果用pulseaudio实现playback,简单地说就是创建一个playback stream,然后指定这个stream的sink,再定期的向这个stream中写数据。 mai…...

Selenium自动化测试工具
一 .Selenium简介 是一个用于Web应用程序测试的工具 Selenium的核心功能之一是测试软件在不同浏览器和操作系统上的兼容性,确保软件功能与用户需求的一致性,提升用户体验。 自动化脚本生成与执行 Selenium支持自动录制用户操作并生成多种编程语言的测…...
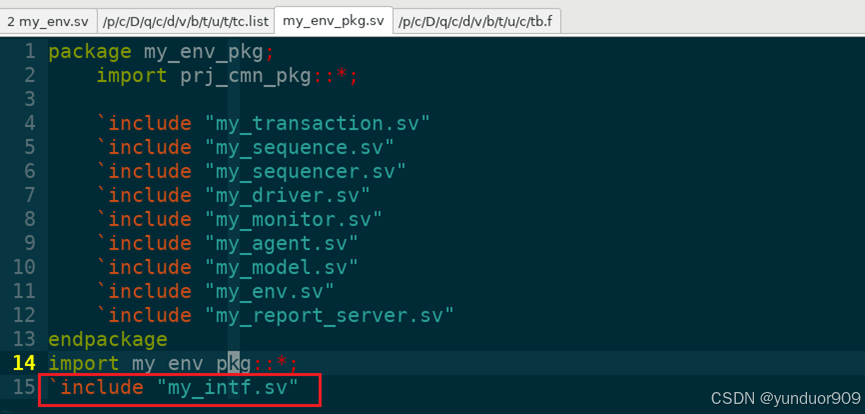
优化UVM环境(九)-将interface文件放在env pkg外面
书接上回: 优化UVM环境(八)-整理project_common_pkg文件 My_env_pkg.sv里不能包含interface,需要将my_intf.sv文件放在pkg之外...

mysql 主从安装
登录看第二篇 WINDOWS系统搭建MYSQL 8.0主从模式_windows mysql8.0.34主从配置-CSDN博客 Windows下MySQL8.0最新版本超详细安装教程_windowsserver安装mysql8.0-CSDN博客 启动两个服务 可执行文件路径一致问题解决: windows,同一台机器安装两个mysq…...

【C++刷题】力扣-#121-买卖股票的最佳时机
题目描述 给定一个数组 prices,其中 prices[i] 表示第 i 天的股票价格。假设你可以在第 i 天买入并在第 j 天卖出股票(i ≤ j),设计一个算法来计算你所能获取的最大利润。注意你只能持有一股股票,并且你不能同时参与多…...

Python量化交易(二):金融市场的基础概念
引言 大家好,我是GISer Liu😁,一名热爱AI技术的GIS开发者。本系列文章是我跟随DataWhale 2024年10月学习赛的Python量化交易学习总结文档;在现代社会中,投资已成为个人、机构和政府追求财富增长和资源配置的重要方式。…...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

解决Ubuntu22.04 VMware失败的问题 ubuntu入门之二十八
现象1 打开VMware失败 Ubuntu升级之后打开VMware上报需要安装vmmon和vmnet,点击确认后如下提示 最终上报fail 解决方法 内核升级导致,需要在新内核下重新下载编译安装 查看版本 $ vmware -v VMware Workstation 17.5.1 build-23298084$ lsb_release…...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...

Matlab | matlab常用命令总结
常用命令 一、 基础操作与环境二、 矩阵与数组操作(核心)三、 绘图与可视化四、 编程与控制流五、 符号计算 (Symbolic Math Toolbox)六、 文件与数据 I/O七、 常用函数类别重要提示这是一份 MATLAB 常用命令和功能的总结,涵盖了基础操作、矩阵运算、绘图、编程和文件处理等…...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...

深入解析C++中的extern关键字:跨文件共享变量与函数的终极指南
🚀 C extern 关键字深度解析:跨文件编程的终极指南 📅 更新时间:2025年6月5日 🏷️ 标签:C | extern关键字 | 多文件编程 | 链接与声明 | 现代C 文章目录 前言🔥一、extern 是什么?&…...
中关于正整数输入的校验规则)
Element Plus 表单(el-form)中关于正整数输入的校验规则
目录 1 单个正整数输入1.1 模板1.2 校验规则 2 两个正整数输入(联动)2.1 模板2.2 校验规则2.3 CSS 1 单个正整数输入 1.1 模板 <el-formref"formRef":model"formData":rules"formRules"label-width"150px"…...
-HIve数据分析)
大数据学习(132)-HIve数据分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言Ǵ…...

2023赣州旅游投资集团
单选题 1.“不登高山,不知天之高也;不临深溪,不知地之厚也。”这句话说明_____。 A、人的意识具有创造性 B、人的认识是独立于实践之外的 C、实践在认识过程中具有决定作用 D、人的一切知识都是从直接经验中获得的 参考答案: C 本题解…...

android13 app的触摸问题定位分析流程
一、知识点 一般来说,触摸问题都是app层面出问题,我们可以在ViewRootImpl.java添加log的方式定位;如果是touchableRegion的计算问题,就会相对比较麻烦了,需要通过adb shell dumpsys input > input.log指令,且通过打印堆栈的方式,逐步定位问题,并找到修改方案。 问题…...