ChatGPT的模型训练入门级使用教程
ChatGPT 是由 OpenAI 开发的一种自然语言生成模型,基于 Transformer 架构的深度学习技术,能够流畅地进行对话并生成有意义的文本内容。它被广泛应用于聊天机器人、客户服务、内容创作、编程助手等多个领域。很多人对如何训练一个类似 ChatGPT 的语言模型感兴趣,但面对复杂的神经网络和数据处理,初学者往往觉得无从下手。本篇文章将为初学者提供一个关于如何训练类似 ChatGPT 模型的入门级使用教程,涵盖必要的背景知识、工具框架的选择、数据准备、模型训练的步骤以及调优和部署的基本流程。
一、ChatGPT的基础知识
1.1 什么是ChatGPT
ChatGPT 是基于 GPT(Generative Pre-trained Transformer)架构的一种大规模语言模型。GPT 是由 OpenAI 开发的生成式语言模型,旨在处理自然语言的生成任务。ChatGPT 采用无监督学习对海量数据进行预训练,并通过对话式数据进行微调,以生成自然的对话内容。
GPT 模型的核心技术是 Transformer,这种架构使用注意力机制来更好地理解和生成文本。通过对大量文本数据的学习,ChatGPT 学会了人类语言的各种表达方式,并能够在对话中使用这些表达方式来回答问题和生成对话。
1.2 ChatGPT的应用场景
ChatGPT 作为一种强大的对话生成模型,可以应用于很多场景,例如:
- 聊天机器人:在网站、应用中嵌入 ChatGPT 模型,为用户提供实时对话服务。
- 内容生成:为内容创作者提供写作灵感,生成广告文案、新闻稿等。
- 编程助手:为程序员提供编程建议、代码生成、调试帮助等。
- 教育助手:帮助学生解答问题,提供解释和学习资源。
1.3 模型训练的基本步骤
为了训练一个类似 ChatGPT 的模型,我们需要执行以下基本步骤:
- 数据收集与处理:收集用于训练的大量自然语言文本数据,并对数据进行预处理。
- 预训练模型:使用无监督学习对模型进行预训练,以便它能够理解语言的基本结构和语义。
- 微调模型:在特定的数据集上对预训练模型进行微调,使其能够生成特定风格或完成特定任务。
- 模型评估与优化:评估模型的表现,进行超参数调优,以提高模型的生成效果。
- 模型部署:将训练好的模型部署到生产环境中供用户使用。
二、训练环境与工具准备
2.1 Python编程语言
Python 是机器学习和深度学习的首选编程语言。它有丰富的库和工具,使得构建和训练神经网络变得简单易行。在训练类似 ChatGPT 的模型时,Python 无疑是必备工具。
2.2 深度学习框架
有几种主流的深度学习框架可以用来训练 ChatGPT 模型:
- TensorFlow:由 Google 开发,提供了强大的工具用于构建和训练神经网络。
- PyTorch:由 Facebook 开发,具有动态计算图特性,更适合模型的开发和调试。
- Transformers 库:由 Hugging Face 提供的一个高级库,包含了各种预训练的语言模型,例如 GPT-2、BERT 等,非常适合用于自然语言处理(NLP)任务。
对于初学者,建议使用 PyTorch 与 Hugging Face 的 Transformers 库,因为它们提供了很多预训练模型,并且 API 设计易于使用。
2.3 硬件资源
训练 GPT 模型需要强大的计算能力。建议使用 GPU,因为深度学习中的矩阵运算非常消耗资源,使用 GPU 可以大大加速训练过程。可以考虑使用 Google Colab 或 AWS EC2 等云服务,这些平台提供了方便的 GPU 支持。
2.4 安装必要的软件
首先,需要安装 Python 和所需的库。在终端中执行以下命令:
# 安装 PyTorch
pip install torch# 安装 Transformers 库
pip install transformers# 安装其他必备库
pip install numpy pandas tqdm
三、数据收集与预处理
3.1 数据集的选择
训练语言模型需要大量的文本数据,数据集的质量和多样性对模型的表现非常重要。以下是一些可供使用的公开数据集:
- OpenWebText:这是一个类似于 GPT-2 使用的数据集,包含了大量从互联网收集的文本。
- Wikipedia:Wikipedia 提供了丰富的百科全书类内容,适合用于训练语言模型。
- Reddit、Twitter 等对话数据:如果想要训练对话模型,可以选择一些对话数据集,例如 Reddit 评论、推文等。
3.2 数据预处理
数据预处理是训练模型前的重要步骤。需要将数据标准化,使得模型能够轻松理解输入。主要的预处理步骤包括:
- 去除无关信息:去掉 HTML 标签、表情符号等。
- 分词:将文本分为单词或词组,以便模型可以更好地理解上下文。
- 构建词汇表:需要构建词汇表来将词转换为模型可以理解的数值表示。
可以使用 Transformers 库中的 Tokenizer 来帮助完成数据的分词工作。例如:
from transformers import GPT2Tokenizertokenizer = GPT2Tokenizer.from_pretrained("gpt2")# 分词示例
text = "ChatGPT 是一个强大的 AI 模型!"
input_ids = tokenizer.encode(text, return_tensors='pt')
print(input_ids)
四、模型训练步骤
4.1 预训练语言模型
在训练 ChatGPT 之前,我们需要对语言模型进行预训练。这部分通常是无监督的,即使用大量文本数据来学习语言的基本模式和结构。可以选择使用 GPT-2 这种已经预训练的模型作为基础。
from transformers import GPT2LMHeadModel# 加载预训练的 GPT-2 模型
model = GPT2LMHeadModel.from_pretrained("gpt2")
预训练模型的参数已经经过大量互联网数据的学习,因此它对语言结构有一定的理解。接下来,我们会对模型进行微调,使其适应特定任务。
4.2 微调模型
微调是指在特定任务上进一步训练模型,以提高它在特定场景下的表现。例如,如果你想训练一个客服机器人,你可以使用客服对话数据对模型进行微调。
from transformers import Trainer, TrainingArguments# 设置训练参数
training_args = TrainingArguments(output_dir='./results', # 输出目录num_train_epochs=3, # 训练周期数per_device_train_batch_size=4, # 每个设备的批量大小save_steps=10_000, # 保存模型的步数save_total_limit=2, # 最多保存模型的数量
)trainer = Trainer(model=model, # 训练的模型args=training_args, # 训练参数train_dataset=your_dataset, # 训练数据集(需提前准备好)
)# 开始训练
trainer.train()
4.3 模型评估与调优
模型训练完成后,需要对其进行评估和优化。评估的指标通常包括 损失函数(Loss)、困惑度(Perplexity) 等。较低的困惑度表示模型对数据有较好的理解。
如果模型的表现不理想,可以通过以下方式进行优化:
- 调整学习率:过高的学习率可能导致模型发散,过低的学习率则可能导致训练时间过长。
- 增加训练数据:如果数据量不足,模型可能无法很好地学习。
- 使用更复杂的模型架构:可以尝试增加模型的层数或宽度,以提高模型的学习能力。
4.4 模型推理
训练完成后,可以使用模型进行文本生成。下面是一个简单的示例,展示如何使用训练好的模型来生成文本:
# 设置模型为评估模式
model.eval()# 输入提示词
prompt = "人工智能的未来是"
input_ids = tokenizer.encode(prompt, return_tensors='pt')# 生成文本
output = model.generate(input_ids, max_length=50, num_return_sequences=1)# 解码输出
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)
五、模型部署与应用
5.1 使用API部署模型
要将训练好的模型部署到生产环境,可以使用一些 API 框架,如 Flask 或 FastAPI,来为模型提供服务。
from flask import Flask, request, jsonifyapp = Flask(__name__)@app.route('/generate', methods=['POST'])
def generate():prompt = request.json.get('prompt')input_ids = tokenizer.encode(prompt, return_tensors='pt')output = model.generate(input_ids, max_length=50, num_return_sequences=1)response_text = tokenizer.decode(output[0], skip_special_tokens=True)return jsonify({'generated_text': response_text})if __name__ == '__main__':app.run(debug=True)
5.2 部署到云端
可以将服务部署到 云平台(如 AWS、GCP 或 Azure),以提供更高的可用性和扩展性。例如,可以使用 Docker 容器化模型并部署到 Kubernetes 集群中,以便更好地管理资源和应对高并发请求。
六、常见问题与解决方案
6.1 数据不足怎么办?
如果训练数据不足,可以尝试:
- 数据增强:通过对原始数据进行变换来增加数据量,例如句子重排、同义词替换等。
- 迁移学习:使用一个已经在大量数据上训练好的模型,然后在少量数据上进行微调。
6.2 训练时间过长
训练大型语言模型非常耗时。可以通过以下方式加速训练:
- 使用 GPU 或 TPU 加速训练过程。
- 调整 批量大小 以提高硬件的利用率。
- 使用 分布式训练 来在多个 GPU 上并行训练模型。
七、结语
训练一个类似 ChatGPT 的模型是一项挑战性很大的工作,但也是非常有趣的过程。通过使用现有的工具和框架,即使是入门级的开发者也可以成功地训练一个对话模型。希望本篇文章能够帮助初学者了解 ChatGPT 模型训练的基础知识,并提供一个简单可行的实践路径。
无论是初学者还是有经验的开发者,在这条探索 AI 模型的道路上,保持好奇心和持续学习的态度是最为重要的。随着技术的不断发展,AI 模型的能力将变得越来越强大,而掌握这些工具和技术将为我们的生活和工作带来更多的可能性。
相关文章:

ChatGPT的模型训练入门级使用教程
ChatGPT 是由 OpenAI 开发的一种自然语言生成模型,基于 Transformer 架构的深度学习技术,能够流畅地进行对话并生成有意义的文本内容。它被广泛应用于聊天机器人、客户服务、内容创作、编程助手等多个领域。很多人对如何训练一个类似 ChatGPT 的语言模型…...

【OS】2.1.2 进程的状态与转换_进程的组织
✨ Blog’s 主页: 白乐天_ξ( ✿>◡❛) 🌈 个人Motto:他强任他强,清风拂山冈! 🔥 所属专栏:C深入学习笔记 💫 欢迎来到我的学习笔记! 一、进程的状态 1.1.创建态 ……的…...

和为 n 的完全平方数的最少数量
给你一个整数 n ,返回 和为 n 的完全平方数的最少数量 。 完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而 3 和 11 不是。 示…...

Hallo2 长视频和高分辨率的音频驱动的肖像图像动画 (数字人技术)
HALLO2: LONG-DURATION AND HIGH-RESOLUTION AUDIO-DRIVEN PORTRAIT IMAGE ANIMATION 论文:https://arxiv.org/abs/2410.07718 代码:https://github.com/fudan-generative-vision/hallo2 模型:https://huggingface.co/fudan-generative-ai/h…...

如何在Debian 8上使用Let‘s Encrypt保护Apache
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 简介 本教程将向您展示如何在运行 Apache 作为 Web 服务器的 Debian 8 服务器上设置来自 Let’s Encrypt 的 TLS/SSL 证书。我们还将介…...

百科知识|选购指南
百科知识||选购指南 百科知识选购指南茶叶分类茶叶的味道来源茶叶制作步骤名茶其他一些茶叶的知识 百科知识 选购指南 茶叶 分类 茶叶种类: 六大茶类完美分析介绍!茶友推荐收藏 (aboxtik.com) 1.绿茶(发酵率0%) 2.白茶(发酵率…...

Go 语言基础教程:4.常量的使用
在这篇教程中,我们将通过一个简单的 Go 语言程序来学习常量的声明和使用。以下是我们要分析的代码: package mainimport ("fmt""math" )const s string "constant"func main() {fmt.Println(s)const n 500000000const …...

centos服务器重启后,jar包自启动
第一种方法: systemctl服务自启动 在/usr/lib/systemd/system目录下,创建service:start_jar.servie [Unit] DescriptionYour Java Application as a Service Afternetwork.target[Service] Userroot Typesimple ExecStart/usr/bin/java -j…...

华为云实战杂记
配置nginx服务器 首先我们拿到一台服务器时,并不知道系统是否存在Nginx我们可以在Linux命令行执行如下命令查看 find / -name nginx* find / -name nginx* 查找所有名字以nginx开头的文件或者目录,我们看看系统里面都有哪些文件先,这样可以快…...
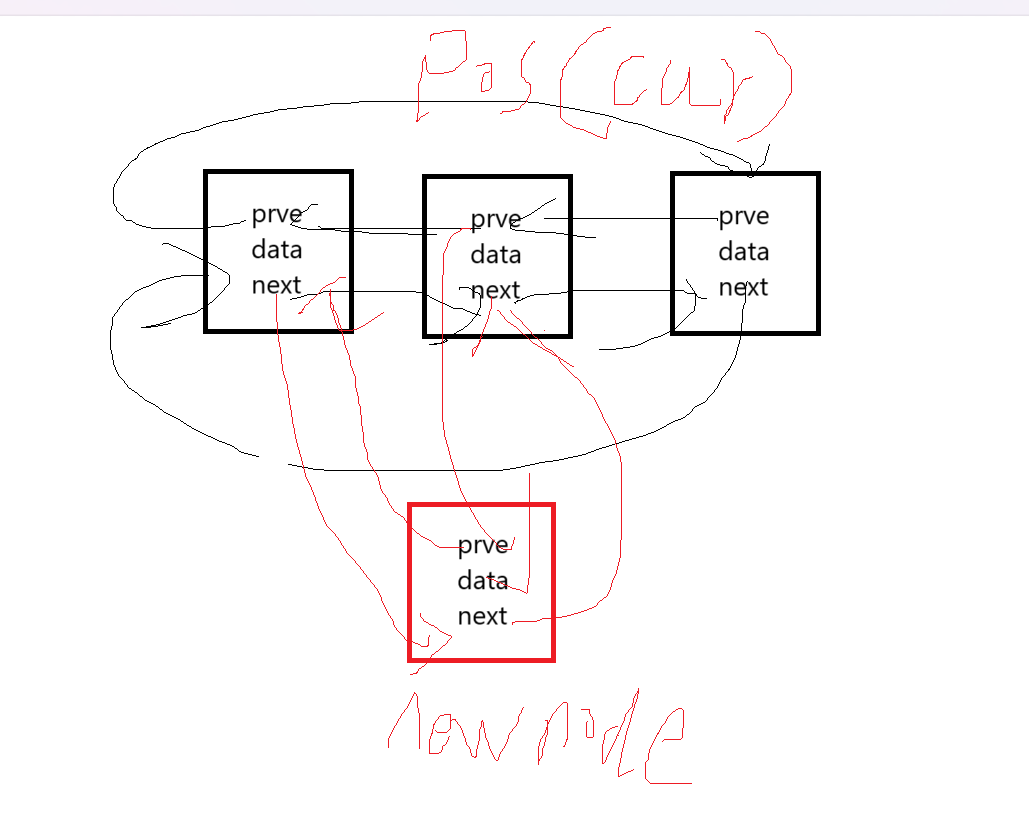
Lesson10---list
Lesson10—list 第10章 c的list的使用和实现 文章目录 Lesson10---list前言一、list的初始化二、list的遍历1.迭代器2.范围for 三、list常用的内置函数1.sort(慎用)2.unique3.reverse4.merge5.splice 四、模拟实现1.基本框架2.构造函数3.push_back4. 遍…...
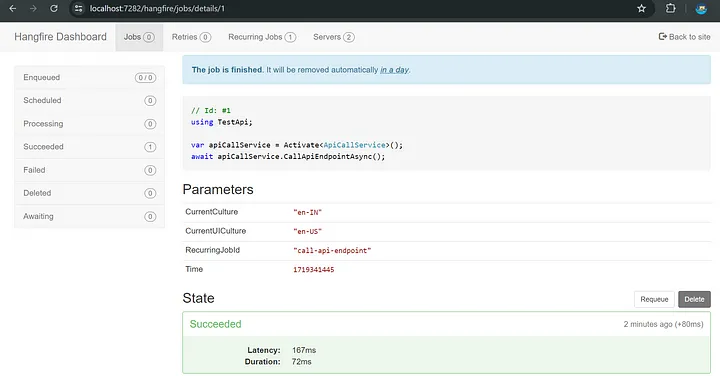
ASP.NET Core 8.0 中使用 Hangfire 调度 API
在这篇博文中,我们将引导您完成将 Hangfire 集成到 ASP.NET Core NET Core 项目中以安排 API 每天运行的步骤。Hangfire 是一个功能强大的库,可简化 .NET 应用程序中的后台作业处理,使其成为调度任务的绝佳选择。继续阅读以了解如何设置 Hang…...

查看linux的版本
在 Linux 系统中,有多种方法可以查看当前系统的版本信息。以下是一些常用的方法: 1. 使用 uname 命令 uname 命令可以显示系统的内核版本和其他相关信息。 uname -a这个命令会输出类似如下的信息: Linux hostname 5.4.0-88-generic #99-U…...

Mysql补充
单例 双重检查锁 class Singleton {private static volatile Singleton instance ;private Singleton() {}public static Singleton getInstance(){if(instance null) {synchronized (Singleto.class) {if(instance null){instance new Singleton() ;}} return instance;} …...

com.baomidou.mybatisplus.extension.service.IService用法详解及使用例子
IService 是 MyBatis-Plus 中的一个接口,提供了通用的 CRUD 操作,简化了数据库操作的代码。下面是 IService 的用法详解及示例代码。 1. 引入依赖 确保在你的 pom.xml 中添加了 MyBatis-Plus 的依赖: <dependency><groupId>co…...
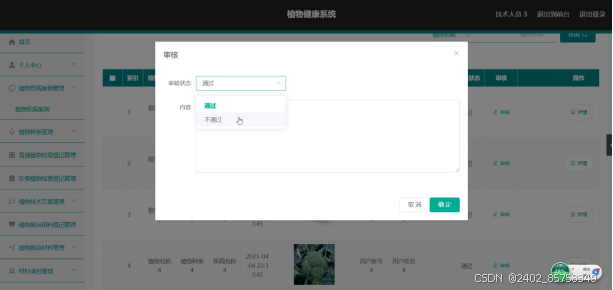
植物健康,Spring Boot来保障
5系统详细实现 5.1 系统首页 植物健康系统需要登录才可以看到首页。具体界面的展示如图5.1所示。 图5.1 系统首页界面 5.2 咨询专家 可以在咨询专家栏目发布消息。具体界面如图5.2所示。 图5.2 咨询专家界面 5.3 普通植物检查登记 普通员工可以对普通植物检查登记信息进行添…...

mac-chrome提示您的连接不是私密连接
一、现象介绍 关闭代理之后就ok打开代理,就会提示您的连接不是私密连接 二、原因 由于代理部分的问题,无法找到正确的网站ip地址 三、解决方法 1、键盘直接输入thisisunsafe,可以继续访问网站,如果还是不对的话,那…...
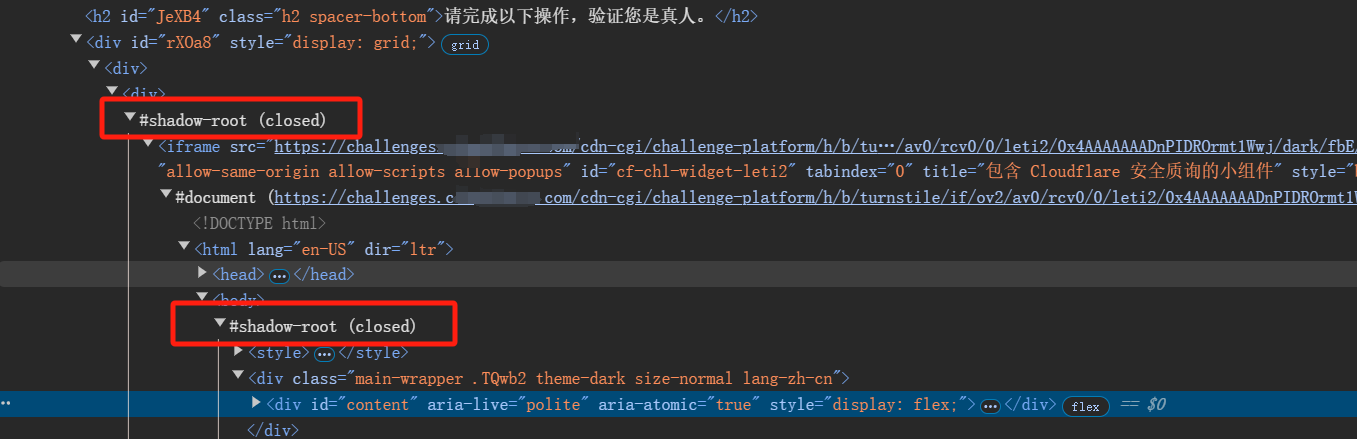
028.爬虫专用浏览器-抓取#shadowRoot(closed)下的内容
一、什么是Shadow DOM Shadow DOM是一种在web开发中用于封装HTML标记、样式和行为的技术,以避免组件间的样式和脚本冲突。它允许开发者将网页的一部分隐藏在一个独立的作用域内,从而实现更加模块化和可维护的代码结构 二、js操作Shadow DOM // 获取宿…...
Serv00 免费虚拟主机 零成本搭建 PHP / Node.js 网站
本文首发于只抄博客,欢迎点击原文链接了解更多内容。 前言 Serv00 是一个提供免费虚拟主机的平台,包含了 3GB 的存储空间和 512MB 的内存空间,足够我们搭建一个 1IP 的小网站了。同时他还不限制每月的流量,并提供了 16 个数据库&…...

C#里使用ORM访问mariadb数据库
数据库,对于开发人员来说,是必须掌握的内容。 曾经我的老板对我说,只要会数据库的增删查改,就不会没有饭吃。 经过了20年多的工作经历,说明这个是铁的事实,毕竟计算机就是加工数据处理的而设计的。 数据就是信息,信息就是金钱,有了钱就可以有饭吃。 管理数据,就是…...

电商揭秘:商城积分体系简析
引言 商城积分体系划分是一个复杂而细致的过程,它旨在通过积分这一虚拟货币来激励用户行为、提升用户粘性,并促进商城的销售和用户活跃度。以下是对商城积分体系划分的详细解析: 一、积分获取方式 消费积分: 基础积分:…...

【Python】 -- 趣味代码 - 小恐龙游戏
文章目录 文章目录 00 小恐龙游戏程序设计框架代码结构和功能游戏流程总结01 小恐龙游戏程序设计02 百度网盘地址00 小恐龙游戏程序设计框架 这段代码是一个基于 Pygame 的简易跑酷游戏的完整实现,玩家控制一个角色(龙)躲避障碍物(仙人掌和乌鸦)。以下是代码的详细介绍:…...

Prompt Tuning、P-Tuning、Prefix Tuning的区别
一、Prompt Tuning、P-Tuning、Prefix Tuning的区别 1. Prompt Tuning(提示调优) 核心思想:固定预训练模型参数,仅学习额外的连续提示向量(通常是嵌入层的一部分)。实现方式:在输入文本前添加可训练的连续向量(软提示),模型只更新这些提示参数。优势:参数量少(仅提…...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...

3.3.1_1 检错编码(奇偶校验码)
从这节课开始,我们会探讨数据链路层的差错控制功能,差错控制功能的主要目标是要发现并且解决一个帧内部的位错误,我们需要使用特殊的编码技术去发现帧内部的位错误,当我们发现位错误之后,通常来说有两种解决方案。第一…...

什么是库存周转?如何用进销存系统提高库存周转率?
你可能听说过这样一句话: “利润不是赚出来的,是管出来的。” 尤其是在制造业、批发零售、电商这类“货堆成山”的行业,很多企业看着销售不错,账上却没钱、利润也不见了,一翻库存才发现: 一堆卖不动的旧货…...

MVC 数据库
MVC 数据库 引言 在软件开发领域,Model-View-Controller(MVC)是一种流行的软件架构模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种模式有助于提高代码的可维护性和可扩展性。本文将深入探讨MVC架构与数据库之间的关系,以…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...

智能仓储的未来:自动化、AI与数据分析如何重塑物流中心
当仓库学会“思考”,物流的终极形态正在诞生 想象这样的场景: 凌晨3点,某物流中心灯火通明却空无一人。AGV机器人集群根据实时订单动态规划路径;AI视觉系统在0.1秒内扫描包裹信息;数字孪生平台正模拟次日峰值流量压力…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...