在数据库中编程 vs 在应用程序中编程
原文地址 https://brandur.org/fragments/code-database-vs-app
数据库领域有一个长期存在的问题:你是更愿意将应用逻辑放在更接近数据库本身的存储过程和触发器中,还是置于数据库之上的应用程序代码中?
没有客观正确的答案,只有不同的观点。我浏览了 Stack Overflow 等地方的大量热门文章,并惊讶于普遍建议与常见事实的巨大差距。
可以肯定,大多数公司在应用程序代码中编写逻辑。开发者都不会想到编写存储过程,更不用说将领域逻辑放在存储过程中了。网络上很多人,却建议将逻辑放在数据库中。
先说个人观点:即使我因为类型、schema 和一致性而成为了关系数据库的拥护者,对把代码放到数据库中也还是持保留意见。将代码放入数据库,只在少数时候合适;即使合适,也要保持小规模、尽量少用。
对在数据库中编程的反对意见
数据库不适合应用程序编程的原因:
-
不透明的后果
一旦设置了触发器,如果不检查 schema,简单如插入一行的操作也可能产生严重的后果。
同样的原因,我也反对 ActiveRecord callbacks 这类东西。
-
调试、工具和测试
对数据库内函数都比较困难。
- 最多只能进行 printf 调试。
- 很难使用开发者工具,比如用 LSP 完成代码(配置的噩梦 – LSP 必须主动与数据库交互,才能知道哪些关系和字段可用);SQL 函数会成为代码其他部分跳转到定义的死胡同。
- 如果要(也应该)编写测试,就应该在应用程序代码中编写;这样…只要就地实现就可以了?
-
部署和版本管理
仍然可以对存储过程进行版本管理 – 只能通过编写新的迁移,就像数据库其他部分的版本管理一样。这就增加了更改代码的难度,毕竟部署其他应用代码肯定更容易。
更改存储过程需要创建一个 CREATE OR REPLACE 函数,其中包含函数的整个实现(包括更改),这样就无法像使用 git blame 那样查看每行的历史记录。
-
性能
数据库逻辑与数据本身同在,所以有些情况下能提供最佳性能;但一些重要方面,却使性能更差:
- 关系数据库通常是应用程序的单一阻塞点,其他应用程序代码部署在一组可以访问关系数据库的并行容器中。一个容器的应用代码容易扩展,只需部署更多的容器即可。数据库的扩展则比较困难。
- 如果还需要运行数量未知的触发器,操作速度就会更慢。例如,当每一行都有一次隐藏触发,批量操作就要花费数倍时间。当然可以暂时禁用触发器,这就会失去触发器更多明显的好处。而且由于触发器不易被发现(参见上文「不透明的后果」),你可能无法明显感觉到操作速度变慢。
-
程序化 SQL
程序化 SQL 与 BASIC 和 COBOL 1 同属于最底层的编程语言,编写体验很糟糕,即使你熟悉。当然,可以激活扩展,从而使用其他语法更好的脚本语言,但你真的想让 Python 虚拟机在你的数据库中运行吗?
对在数据库中编程的支持意见
糟糕的意见
我在 Stack Overflow 上看到这样一些糟糕的论点:
-
一致的实现:
多个应用程序访问同一个数据库时,使用存储过程是保证它们使用相同实现的唯一方法。
但出于多种原因,在应用程序之间共享数据库并不是好主意;在多个应用程序都可能向数据库写入数据的情况下共享数据库更糟(Schema 属于哪个程序?如何在 schema 变更时协调应用程序的部署?)。
-
性能:
存储过程的性能很高,因为它们与数据本身同位于数据库服务器上。
这是事实,但依赖这一点很危险,因为数据库的可扩展性有限,任何利用这种局部性的做法都会给数据库带来很大压力。如上所述,将工作外包给可轻松扩展的应用程序代码会更安全、更具可扩展性。
-
ACID 一致性:
触发器是保证 ACID 一致性的唯一方法。
在一个看起来都是数据库专家的网站上发现这一点很奇怪。——并不是唯一的方法,不然为什么有数据库事务?
更好的意见
最后,有几个更好的理由支持将代码放在数据库中:
-
非常适合一些小而受限的模块:
有一小部分常见模块非常适合触发器。例如一个很小的函数,用来触发表上的 updated_at 时间戳:
CREATE OR REPLACE FUNCTION set_updated_at() RETURNS trigger AS $$ BEGINNEW.updated_at := current_timestamp;RETURN NEW; END $$ LANGUAGE plpgsql;然后数据库中的每张表都会有这个触发器:
CREATE TRIGGER team_set_updated_atBEFORE UPDATE ON teamFOR EACH ROWEXECUTE FUNCTION set_updated_at();在应用程序代码中可以实现这一点(使用类似模型回调的方法),但会带来大量重复,一旦在某处遗漏就会造成错误。相比之下,数据库版本的运行更可靠,效果也更好。
-
实现深度一致性,避免操作错误:
举个例子:假设我们有两个独立的账户表,一个是在我们这里注册的账户,另一个是通过身份提供商的 SSO 进入的账户。它们有很大区别,因此我们要分别跟踪;但它们是相关的概念,账户可能拥有的资源(如 API 密钥)可能由其中一种类型或另一种类型拥有。
另一个名为 account_common 的表通过两个小操作增强一致性:
- 确保两个不同类型的账户不会意外共享一个 ID
- 充当通用资源(如 API 密钥)的外键目标
在添加账户或 SSO 账户时,要确保为其插入 account_common 记录。在应用程序代码中插入额外的记录不方便且容易忘记,因此我们用一个简单的触发器:
CREATE OR REPLACE FUNCTION account_common_upsert() RETURNS TRIGGER AS $$BEGININSERT INTO account_common (id, kind) VALUES (NEW.id, TG_TABLE_NAME)ON CONFLICT (id, kind)DO NOTHING;RETURN NEW;END; $$ LANGUAGE plpgsql;CREATE TRIGGER account_common_upsert BEFORE INSERT ON accountFOR EACH ROW EXECUTE FUNCTION account_common_upsert(); CREATE TRIGGER account_common_upsert BEFORE INSERT ON sso_accountFOR EACH ROW EXECUTE FUNCTION account_common_upsert();
这些情况仍然存在上述数据库代码的缺点,但也是将其放入数据库的好处大于成本的地方。
总之,应该根据具体情况评估,使用时将代码保持在较小的范围内。
💡 更多资讯,请关注 Bytebase 公号:Bytebase
相关文章:

在数据库中编程 vs 在应用程序中编程
原文地址 https://brandur.org/fragments/code-database-vs-app 数据库领域有一个长期存在的问题:你是更愿意将应用逻辑放在更接近数据库本身的存储过程和触发器中,还是置于数据库之上的应用程序代码中? 没有客观正确的答案,只有…...

【设计模式系列】装饰器模式
目录 一、什么是装饰器模式 二、装饰器模式中的角色 三、装饰器模式的典型应用场景 四、装饰器模式在BufferedReader中的应用 一、什么是装饰器模式 装饰器模式是一种结构型设计模式,用于在不修改对象自身的基础上,通过创建一个或多个装饰类来给对象…...

你真的知道TCP协议中的序列号确认、上层协议及记录标识问题吗?
引言 在前面的内容中,我们已经详细讲解了一系列与TCP相关的面试问题。然而,这些问题都是基于个别知识点进行扩展的。今天,我们将重点讨论一些场景问题,并探讨如何解决这些问题。 序列号确认问题 当A主机与B主机建立了TCP连接后…...

一家生物技术企业终止,科创属性可能不足,报告期内专利数猛增
轩凯生物九成以上营业收入来源于植物营养领域,收入来源结构单一,产品下游应用领域较为集中。报告期内公司应收账款账面价值逐年上升,回款比例显著低于前两年,遭交易所问询是否存在较大的坏账风险。 轩凯生物核心技术是否成熟以及是…...

使用 Python 的 BeautifulSoup(bs4)解析复杂 HTML
使用 Python 的 BeautifulSoup(bs4)解析复杂 HTML:详解与示例 在 Web 开发和数据分析中,解析 HTML 是一个常见的任务,尤其是当你需要从网页中提取数据时。Python 提供了多个库来处理 HTML,其中最受欢迎的就…...

Spring Cache Caffeine 高性能缓存库
Caffeine 背景 Caffeine是一个高性能的Java缓存库,它基于Guava Cache进行了增强,提供了更加出色的缓存体验。Caffeine的主要特点包括: 高性能:Caffeine使用了Java 8最新的StampedLock乐观锁技术,极大地提高了缓存…...

Python3入门--数据类型
文章目录 一、基础语法编码标识符注释单行注释以 # 开头多行注释用多个 # 号,还有 和 """ 空行行与缩进同一行显示多条语句多行语句 二、数据类型Number(数字)type和isinstance查询变量类型数值运算 String(字符串…...

开发运维警示录-20241024
开发警示录 1、作为开发,不要私自修改业务人员给的SQL语句,虽然个人感觉SQL很冗余,效率低等。 2、开发前,要明确需求,必要时通过图和文字形成文档与需求方确认、留痕。 3、开发复杂的业务逻辑代码前,先疏通…...

Linux运维_搭建smb服务
Samba(SMB)是一个开源软件,允许Linux和Unix系统与Windows系统共享文件和打印机。以下是一些关于Samba和SMB的基本信息和操作步骤: Samba 和 SMB 基本概念 Samba:实现了SMB(Server Message Blockÿ…...
vue3移动端可同时上传照片和视频的组件
uni-app中的uni-file-picker可单独上传照片或视频,但不支持同时上传照片和视频。本篇博客使用image标签和video标签实现移动端(H5app小程序)中照片和视频的同时上传。 本篇博客采用的是照片和视频的单独上传,但可同时展示…...

PyQt入门指南二十七 QTableView表格视图组件
# 创建一个QStandardItemModel实例,用于存储表格数据model QStandardItemModel(4, 2) # 4行2列# 填充模型数据for row in range(4):for column in range(2):item QStandardItem(fRow {row}, Column {column})model.setItem(row, column, item)# 创建一个QTableVi…...
)
AI学习指南深度学习篇-自注意力机制(Self-Attention Mechanism)
AI学习指南深度学习篇—自注意力机制(Self-Attention Mechanism) 在深度学习的研究领域,自注意力机制(Self-Attention Mechanism)作为一种创新的模型结构,已成为了神经网络领域的一个重要组成部分…...

【JAVA毕业设计】基于Vue和SpringBoot的校园管理系统
本文项目编号 T 026 ,文末自助获取源码 \color{red}{T026,文末自助获取源码} T026,文末自助获取源码 目录 一、系统介绍二、演示录屏三、启动教程四、功能截图五、文案资料5.1 选题背景5.2 国内外研究现状5.3 可行性分析 六、核心代码6.1 管…...

你对MySQL的having关键字了解多少?
在MySQL中,HAVING子句用于在数据分组并计算聚合函数之后,对结果进行进一步的过滤。它通常与GROUP BY子句一起使用,以根据指定的条件过滤分组。HAVING子句的作用类似于WHERE子句,但WHERE子句是在数据被聚合之前进行过滤,…...

【STM32编码器】【STM32】
提示:一般情况下我们会设计一个硬件电路模块来自动完成简单重复而高频的计算 文章目录 一、为什么通常情况下不使用外部中断来对编码器的脉冲进行计数?二、编码器速度测量程序设计思路三、正交编码器四、初始化流程五、STM32正交编码器输入捕获模式配置示…...

Python轴承故障诊断 (13)基于故障信号特征提取的超强机器学习识别模型
往期精彩内容: Python-凯斯西储大学(CWRU)轴承数据解读与分类处理 Pytorch-LSTM轴承故障一维信号分类(一)-CSDN博客 Pytorch-CNN轴承故障一维信号分类(二)-CSDN博客 Pytorch-Transformer轴承故障一维信号分类(三)-CSDN博客 三十多个开源…...

VScode分文件编写C++报错 | 如何进行VScode分文件编写C++ | 不懂也能轻松解决版
分文件编写遇到的问题 分文件编写例子如下所示: 但是直接使用 Run Code 或者 调试C/C文件 会报错如下: 正在执行任务: C/C: g.exe 生成活动文件 正在启动生成… cmd /c chcp 65001>nul && D:\Librarys\mingw64\bin\g.exe -fdiagnostics-col…...

洞察前沿趋势!2024深圳国际金融科技大赛——西丽湖金融科技大学生挑战赛技术公开课指南
在当前信息技术与“互联网”深度融合的背景下,金融行业的转型升级是热门话题,创新与发展成为金融科技主旋律。随着区块链技术、人工智能技术、5G通信技术、大数据技术等前沿科技的飞速发展,它们与金融领域的深度融合,正引领着新型…...

Unity3D学习FPS游戏(4)重力模拟和角色跳跃
前言:前面两篇文章,已经实现了角色的移动和视角转动,但是角色并没有办法跳跃,有时候还会随着视角移动跑到天上。这是因为缺少重力系统,本篇将实现重力和角色跳跃功能。觉得有帮助的话可以点赞收藏支持一下!…...

C#基础知识-枚举
目录 枚举 1.分类 1.1普通枚举 1)默认情况 2)指定起始值 1.2标志枚举(Flag Enum) 位运算符与标志枚举 1)组合标志 2)检查标志 2.枚举与不同类型之间的转换 1)枚举->整型 2&#…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

Go 语言接口详解
Go 语言接口详解 核心概念 接口定义 在 Go 语言中,接口是一种抽象类型,它定义了一组方法的集合: // 定义接口 type Shape interface {Area() float64Perimeter() float64 } 接口实现 Go 接口的实现是隐式的: // 矩形结构体…...

dify打造数据可视化图表
一、概述 在日常工作和学习中,我们经常需要和数据打交道。无论是分析报告、项目展示,还是简单的数据洞察,一个清晰直观的图表,往往能胜过千言万语。 一款能让数据可视化变得超级简单的 MCP Server,由蚂蚁集团 AntV 团队…...

使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台
🎯 使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台 📌 项目背景 随着大语言模型(LLM)的广泛应用,开发者常面临多个挑战: 各大模型(OpenAI、Claude、Gemini、Ollama)接口风格不统一;缺乏一个统一平台进行模型调用与测试;本地模型 Ollama 的集成与前…...

深入浅出深度学习基础:从感知机到全连接神经网络的核心原理与应用
文章目录 前言一、感知机 (Perceptron)1.1 基础介绍1.1.1 感知机是什么?1.1.2 感知机的工作原理 1.2 感知机的简单应用:基本逻辑门1.2.1 逻辑与 (Logic AND)1.2.2 逻辑或 (Logic OR)1.2.3 逻辑与非 (Logic NAND) 1.3 感知机的实现1.3.1 简单实现 (基于阈…...

Linux系统部署KES
1、安装准备 1.版本说明V008R006C009B0014 V008:是version产品的大版本。 R006:是release产品特性版本。 C009:是通用版 B0014:是build开发过程中的构建版本2.硬件要求 #安全版和企业版 内存:1GB 以上 硬盘…...

Spring Security 认证流程——补充
一、认证流程概述 Spring Security 的认证流程基于 过滤器链(Filter Chain),核心组件包括 UsernamePasswordAuthenticationFilter、AuthenticationManager、UserDetailsService 等。整个流程可分为以下步骤: 用户提交登录请求拦…...
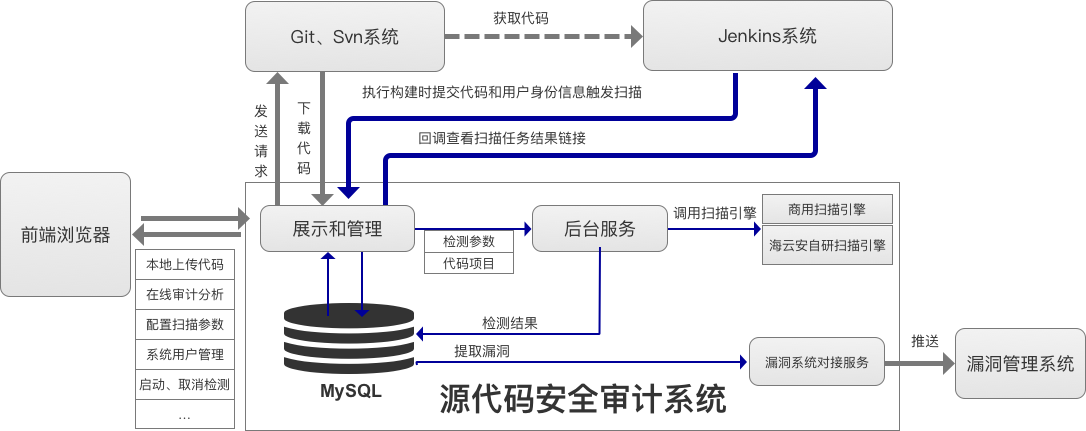
海云安高敏捷信创白盒SCAP入选《中国网络安全细分领域产品名录》
近日,嘶吼安全产业研究院发布《中国网络安全细分领域产品名录》,海云安高敏捷信创白盒(SCAP)成功入选软件供应链安全领域产品名录。 在数字化转型加速的今天,网络安全已成为企业生存与发展的核心基石,为了解…...

用 Rust 重写 Linux 内核模块实战:迈向安全内核的新篇章
用 Rust 重写 Linux 内核模块实战:迈向安全内核的新篇章 摘要: 操作系统内核的安全性、稳定性至关重要。传统 Linux 内核模块开发长期依赖于 C 语言,受限于 C 语言本身的内存安全和并发安全问题,开发复杂模块极易引入难以…...

MeshGPT 笔记
[2311.15475] MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers https://library.scholarcy.com/try 真正意义上的AI生成三维模型MESHGPT来袭!_哔哩哔哩_bilibili GitHub - lucidrains/meshgpt-pytorch: Implementation of MeshGPT, SOTA Me…...