Spring Cache Caffeine 高性能缓存库

Caffeine 背景
Caffeine是一个高性能的Java缓存库,它基于Guava Cache进行了增强,提供了更加出色的缓存体验。Caffeine的主要特点包括:
高性能:Caffeine使用了Java 8最新的StampedLock乐观锁技术,极大地提高了缓存的并发吞吐量,使其成为一个高性能的Java缓存库。
内存友好:Caffeine支持自动驱逐缓存中的元素,以限制其内存占用。它还提供了灵活的构造器,可以创建具有不同特性的缓存,如自动加载元素、基于容量的驱逐、基于过期时间的驱逐等。
可扩展性强:Caffeine支持 JSR-107 - JCache_(Java临时缓存API (JSR-107),也称为JCache,是定义javax.cache API的规范。 该规范是在Java社区流程下开发的,其目的是为Java应用程序提供标准化的缓存概念和机制。 API使用简单,它被设计为缓存标准,是供应商中立的。)_和Guava适配器,提高了与其他缓存库和框架的集成度。
事件监听和多种过期策略:Caffeine提供了事件监听和多种过期策略,可以更好地优化和管理数据的缓存。这些功能不仅可以提升系统的性能表现,也能够有效地降低对底层资源的压力。
本地缓存:Caffeine是一个基于Java 8开发的提供了近乎最佳命中率的高性能缓存库。可以说是目前最优秀的本地缓存。
总之,Caffeine是一个功能强大、性能卓越的Java缓存库,适用于各种需要缓存的应用场景。
Caffeine 主要特点
Caffeine 是一个高性能的 Java 缓存库,它的主要特点包括:
- 速度:Caffeine 的性能非常高,它的速度通常比 ConcurrentHashMap 快很多。Caffeine 使用了高效的数据结构和并发算法,以及一些优化手段,如无锁操作、缓存行填充等,来提高性能。
- 自动垃圾回收:Caffeine 支持基于访问时间和写入时间的自动垃圾回收。当缓存中的数据超过了设定的过期时间,Caffeine 会自动将其从缓存中移除。
- 基于大小的回收:Caffeine 支持基于缓存大小的回收策略。当缓存中的数据量超过了设定的最大值,Caffeine 会自动回收最近最少使用的数据。
- 定时回收:Caffeine 支持定时回收策略,可以设置缓存中的数据在一定时间后被强制回收。
- 缓存统计:Caffeine 提供了丰富的缓存统计信息,如命中率、缓存大小等,帮助开发者了解缓存的使用情况。
- 灵活的配置:Caffeine 提供了丰富的配置选项,允许开发者根据需要定制缓存的行为。例如,可以设置缓存的最大大小、过期时间、回收策略等。
- 扩展性:Caffeine 支持自定义缓存实现,开发者可以根据需要扩展 Caffeine 的功能。
- 与 Spring Cache 集成:Caffeine 可以很容易地与 Spring Cache 集成,使得在 Spring 项目中使用缓存变得更加简单。
- 无阻塞操作:Caffeine 的大部分操作都是无阻塞的,这意味着它可以在高并发环境下提供更好的性能。
- 轻量级:Caffeine 是一个轻量级的库,它的依赖非常少,不会给项目带来额外的负担。
这些特点使得 Caffeine 成为了一个非常受欢迎的 Java 缓存库,尤其是在需要高性能和灵活配置的场景中。如果你正在寻找一个高性能的 Java 缓存库,Caffeine 值得一试。
更多关于 Caffeine 和 Spring Cache 的信息,可以查阅官方文档:
- Caffeine: https://github.com/ben-manes/caffeine/wiki
- Spring Cache: https://docs.spring.io/spring-framework/docs/current/reference/html/integration.html__#cache
Caffeine 使用
Spring Cache 是 Spring 框架提供的一个缓存抽象,它允许开发者通过注解的方式轻松地使用缓存。Caffeine 是一个高性能的 Java 缓存库,它提供了诸如自动垃圾回收、基于大小的回收、定时回收等功能。
要在 Spring 中使用 Caffeine 作为缓存实现,需执行以下步骤:
添加依赖
在你的项目中,添加 Caffeine 和 Spring Cache 的依赖。可以在 pom.xml 文件中添加以下依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId>
</dependency>
配置 Caffeine
在你的 Spring Boot 配置类中,配置 Caffeine 缓存管理器:
创建了一个 CaffeineCacheManager Bean,并设置了 Caffeine 的一些基本属性,如过期时间和最大缓存大小。
import com.github.benmanes.caffeine.cache.Caffeine;
import org.springframework.cache.CacheManager;
import org.springframework.cache.caffeine.CaffeineCacheManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.concurrent.TimeUnit;@Configuration
public class CaffeineConfig {@Beanpublic CacheManager cacheManager() {CaffeineCacheManager cacheManager = new CaffeineCacheManager();cacheManager.setCaffeine(Caffeine.newBuilder().expireAfterWrite(60, TimeUnit.SECONDS).maximumSize(100));return cacheManager;}
}
可以在你的服务类中使用 Spring Cache 的注解来缓存数据。
我们使用了 @Cacheable 注解来缓存 getUserById 方法的结果。当方法被调用时,Spring 会先检查缓存中是否存在该用户,如果存在则直接返回缓存中的数据,否则才会调用方法并将结果存入缓存。例如:
import org.springframework.cache.annotation.Cacheable;
import org.springframework.stereotype.Service;@Service
public class UserService {@Cacheable(value = "users", key = "#id")public User getUserById(Long id) {// 模拟从数据库中获取用户数据return new User(id, "User " + id);}
}
多个缓存区域
在 Caffeine 中,你可以配置多个缓存区域,每个区域都有自己的配置和缓存数据。要配置多个缓存区域,你需要为每个区域创建一个 Cache 实例,并为它们分别配置。
以下是一个使用 Spring Boot 和 Caffeine 配置多个缓存区域的例子:
配置缓存区域
在你的 Spring Boot 配置类中,配置多个缓存区域:我们创建了一个 SimpleCacheManager Bean,并为其配置了两个缓存区域。每个缓存区域都有自己的名称、过期时间和最大缓存大小。
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import org.springframework.cache.CacheManager;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.cache.caffeine.CaffeineCache;
import org.springframework.cache.support.SimpleCacheManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;@Configuration
@EnableCaching
public class CaffeineConfig {@Beanpublic CacheManager cacheManager() {SimpleCacheManager cacheManager = new SimpleCacheManager();List<CaffeineCache> caches = new ArrayList<>();// 配置第一个缓存区域Cache<Object, Object> cache1 = Caffeine.newBuilder().expireAfterWrite(60, TimeUnit.SECONDS).maximumSize(100).build();caches.add(new CaffeineCache("cache1", cache1));// 配置第二个缓存区域Cache<Object, Object> cache2 = Caffeine.newBuilder().expireAfterWrite(30, TimeUnit.SECONDS).maximumSize(50).build();caches.add(new CaffeineCache("cache2", cache2));cacheManager.setCaches(caches);return cacheManager;}
}
使用缓存区域
在你的服务类中使用 Spring Cache 的注解来缓存数据,并指定要使用的缓存区域:我们使用了 @Cacheable 注解来缓存 getUserByIdFromCache1 和 getUserByIdFromCache2 方法的结果,并分别指定了不同的缓存区域。
import org.springframework.cache.annotation.Cacheable;
import org.springframework.stereotype.Service;@Service
public class UserService {@Cacheable(value = "cache1", key = "#id")public User getUserByIdFromCache1(Long id) {// 模拟从数据库中获取用户数据return new User(id, "User " + id);}@Cacheable(value = "cache2", key = "#id")public User getUserByIdFromCache2(Long id) {// 模拟从数据库中获取用户数据return new User(id, "User " + id);}
}
Caffeine 常见机制
Notification on Eviction
Caffeine 提供了一种机制,允许你在缓存项被回收时接收通知,这被称为 “Notification on Eviction”。使用 removalListener 方法注册一个回调函数。当缓存项被回收时,这个回调函数会被调用。
以下是一个使用 Caffeine 的 “Notification on Eviction” 的例子:我们创建了一个 Caffeine 缓存,并使用 removalListener 方法注册了一个回调函数。当缓存项被回收时,这个回调函数会被调用,并打印出被回收的缓存项的键、值和回收原因。
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.RemovalCause;
import com.github.benmanes.caffeine.cache.RemovalListener;import java.util.concurrent.TimeUnit;public class CaffeineNotificationOnEvictionExample {public static void main(String[] args) throws InterruptedException {RemovalListener<String, String> removalListener = (key, value, cause) -> {System.out.println("Key: " + key + ", Value: " + value + ", Cause: " + cause);};Cache<String, String> cache = Caffeine.newBuilder().expireAfterWrite(1, TimeUnit.MINUTES).maximumSize(100).removalListener(removalListener).build();cache.put("key1", "value1");cache.put("key2", "value2");// 等待一段时间,让缓存项过期Thread.sleep(60 * 1000);// 清理缓存cache.cleanUp();}
}
需要注意,“Notification on Eviction” 只在缓存项被主动回收时触发,而不是在缓存项被读取或写入时触发。
此外,“Notification on Eviction” 并不保证在所有情况下都能接收到通知,例如在缓存关闭或应用程序退出时,可能无法接收到通知。因此,在使用 “Notification on Eviction” 时,需要考虑到这些因素。
Cleanup
Caffeine 提供了一种机制,允许你手动触发缓存的清理操作,这被称为 “Cleanup”。使用 cleanUp 方法注册一个回调函数。当需要清理缓存时,可以调用 cleanUp 方法来触发回调函数。
以下是一个使用 Caffeine 的 “Cleanup” 的例子:我们创建了一个 Caffeine 缓存,并使用 removalListener 方法注册了一个回调函数。当缓存项被回收时,这个回调函数会被调用,并打印出被回收的缓存项的键、值和回收原因。
在这个例子中,我们使用 cleanUp 方法手动触发了缓存的清理操作。这会导致所有过期的缓存项被回收,并触发回调函数。
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.RemovalCause;
import com.github.benmanes.caffeine.cache.RemovalListener;import java.util.concurrent.TimeUnit;public class CaffeineCleanupExample {public static void main(String[] args) throws InterruptedException {RemovalListener<String, String> removalListener = (key, value, cause) -> {System.out.println("Key: " + key + ", Value: " + value + ", Cause: " + cause);};Cache<String, String> cache = Caffeine.newBuilder().expireAfterWrite(1, TimeUnit.MINUTES).maximumSize(100).removalListener(removalListener).build();cache.put("key1", "value1");cache.put("key2", "value2");// 等待一段时间,让缓存项过期Thread.sleep(60 * 1000);// 手动触发缓存清理cache.cleanUp();}
}
需要注意,“Cleanup” 并不保证在所有情况下都能清理缓存。例如,在缓存关闭或应用程序退出时,可能无法清理缓存。因此,在使用 “Cleanup” 时,需要考虑到这些因素。
Enable Statistics
Caffeine 提供了一种机制,允许你启用缓存的统计信息收集功能,这被称为 “Enable Statistics”。在创建 Caffeine 缓存时,使用 recordStats 方法启用统计信息收集功能。启用统计信息收集功能后,使用 stats 方法获取缓存的统计信息。
以下是一个使用 Caffeine 的 “Enable Statistics” 的例子:我们创建了一个 Caffeine 缓存,并使用 recordStats 方法启用了统计信息收集功能。在缓存中添加了两个缓存项后,我们等待了一段时间,让缓存项过期。然后,我们使用 stats 方法获取了缓存的统计信息,并将其打印出来。
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.stats.CacheStats;import java.util.concurrent.TimeUnit;public class CaffeineEnableStatisticsExample {public static void main(String[] args) throws InterruptedException {Cache<String, String> cache = Caffeine.newBuilder().expireAfterWrite(1, TimeUnit.MINUTES).maximumSize(100).recordStats().build();cache.put("key1", "value1");cache.put("key2", "value2");// 等待一段时间,让缓存项过期Thread.sleep(60 * 1000);// 获取缓存的统计信息CacheStats stats = cache.stats();System.out.println("Cache Stats: " + stats);}
}
需要注意,启用统计信息收集功能会增加缓存的开销,因此在生产环境中使用时需要谨慎。在开发和测试环境中,启用统计信息收集功能可以帮助你更好地了解缓存的使用情况,从而优化缓存的配置和使用。
相关文章:
Spring Cache Caffeine 高性能缓存库
Caffeine 背景 Caffeine是一个高性能的Java缓存库,它基于Guava Cache进行了增强,提供了更加出色的缓存体验。Caffeine的主要特点包括: 高性能:Caffeine使用了Java 8最新的StampedLock乐观锁技术,极大地提高了缓存…...

Python3入门--数据类型
文章目录 一、基础语法编码标识符注释单行注释以 # 开头多行注释用多个 # 号,还有 和 """ 空行行与缩进同一行显示多条语句多行语句 二、数据类型Number(数字)type和isinstance查询变量类型数值运算 String(字符串…...

开发运维警示录-20241024
开发警示录 1、作为开发,不要私自修改业务人员给的SQL语句,虽然个人感觉SQL很冗余,效率低等。 2、开发前,要明确需求,必要时通过图和文字形成文档与需求方确认、留痕。 3、开发复杂的业务逻辑代码前,先疏通…...

Linux运维_搭建smb服务
Samba(SMB)是一个开源软件,允许Linux和Unix系统与Windows系统共享文件和打印机。以下是一些关于Samba和SMB的基本信息和操作步骤: Samba 和 SMB 基本概念 Samba:实现了SMB(Server Message Blockÿ…...
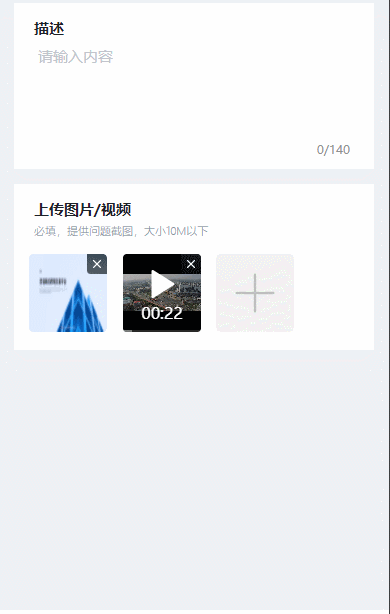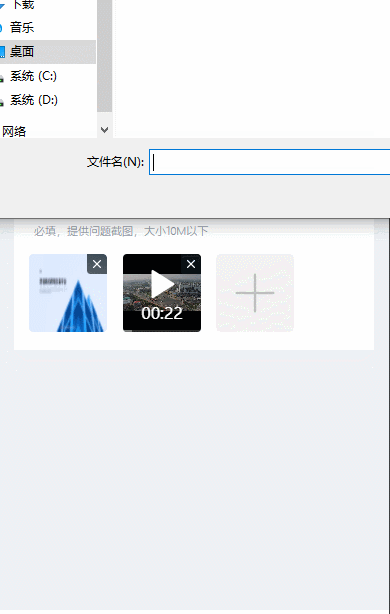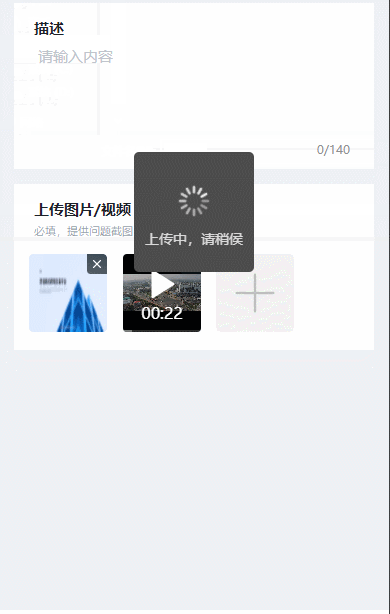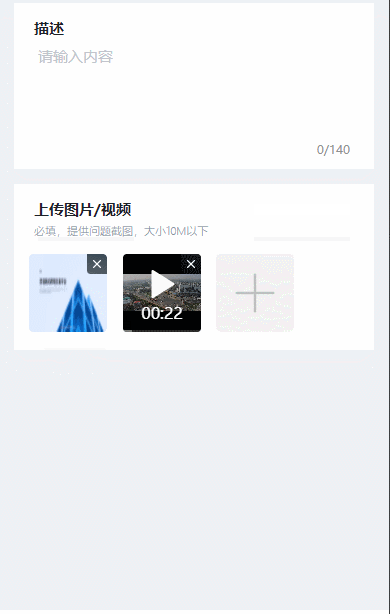
vue3移动端可同时上传照片和视频的组件
uni-app中的uni-file-picker可单独上传照片或视频,但不支持同时上传照片和视频。本篇博客使用image标签和video标签实现移动端(H5app小程序)中照片和视频的同时上传。 本篇博客采用的是照片和视频的单独上传,但可同时展示…...

PyQt入门指南二十七 QTableView表格视图组件
# 创建一个QStandardItemModel实例,用于存储表格数据model QStandardItemModel(4, 2) # 4行2列# 填充模型数据for row in range(4):for column in range(2):item QStandardItem(fRow {row}, Column {column})model.setItem(row, column, item)# 创建一个QTableVi…...
)
AI学习指南深度学习篇-自注意力机制(Self-Attention Mechanism)
AI学习指南深度学习篇—自注意力机制(Self-Attention Mechanism) 在深度学习的研究领域,自注意力机制(Self-Attention Mechanism)作为一种创新的模型结构,已成为了神经网络领域的一个重要组成部分…...

【JAVA毕业设计】基于Vue和SpringBoot的校园管理系统
本文项目编号 T 026 ,文末自助获取源码 \color{red}{T026,文末自助获取源码} T026,文末自助获取源码 目录 一、系统介绍二、演示录屏三、启动教程四、功能截图五、文案资料5.1 选题背景5.2 国内外研究现状5.3 可行性分析 六、核心代码6.1 管…...

你对MySQL的having关键字了解多少?
在MySQL中,HAVING子句用于在数据分组并计算聚合函数之后,对结果进行进一步的过滤。它通常与GROUP BY子句一起使用,以根据指定的条件过滤分组。HAVING子句的作用类似于WHERE子句,但WHERE子句是在数据被聚合之前进行过滤,…...

【STM32编码器】【STM32】
提示:一般情况下我们会设计一个硬件电路模块来自动完成简单重复而高频的计算 文章目录 一、为什么通常情况下不使用外部中断来对编码器的脉冲进行计数?二、编码器速度测量程序设计思路三、正交编码器四、初始化流程五、STM32正交编码器输入捕获模式配置示…...

Python轴承故障诊断 (13)基于故障信号特征提取的超强机器学习识别模型
往期精彩内容: Python-凯斯西储大学(CWRU)轴承数据解读与分类处理 Pytorch-LSTM轴承故障一维信号分类(一)-CSDN博客 Pytorch-CNN轴承故障一维信号分类(二)-CSDN博客 Pytorch-Transformer轴承故障一维信号分类(三)-CSDN博客 三十多个开源…...

VScode分文件编写C++报错 | 如何进行VScode分文件编写C++ | 不懂也能轻松解决版
分文件编写遇到的问题 分文件编写例子如下所示: 但是直接使用 Run Code 或者 调试C/C文件 会报错如下: 正在执行任务: C/C: g.exe 生成活动文件 正在启动生成… cmd /c chcp 65001>nul && D:\Librarys\mingw64\bin\g.exe -fdiagnostics-col…...

洞察前沿趋势!2024深圳国际金融科技大赛——西丽湖金融科技大学生挑战赛技术公开课指南
在当前信息技术与“互联网”深度融合的背景下,金融行业的转型升级是热门话题,创新与发展成为金融科技主旋律。随着区块链技术、人工智能技术、5G通信技术、大数据技术等前沿科技的飞速发展,它们与金融领域的深度融合,正引领着新型…...

Unity3D学习FPS游戏(4)重力模拟和角色跳跃
前言:前面两篇文章,已经实现了角色的移动和视角转动,但是角色并没有办法跳跃,有时候还会随着视角移动跑到天上。这是因为缺少重力系统,本篇将实现重力和角色跳跃功能。觉得有帮助的话可以点赞收藏支持一下!…...

C#基础知识-枚举
目录 枚举 1.分类 1.1普通枚举 1)默认情况 2)指定起始值 1.2标志枚举(Flag Enum) 位运算符与标志枚举 1)组合标志 2)检查标志 2.枚举与不同类型之间的转换 1)枚举->整型 2&#…...

系统架构设计师教程 第2章 2.1-2计算机系统及硬件 笔记
2.1计算机系统概述 ★☆☆☆☆ 计算机系统 (Computer System) 是指用于数据管理的计算机硬件、软件及网络组成的系统。 一般指由硬件子系统和软件子系统组成的系统,简称为计算机。 将连接多个计算机以实现计算机间数据交换能力的网络设备,称为计算机网…...

通过使用Visual Studio将你的程序一键发布到Docker
通过使用Visual Studio将你的程序一键发布到Docker 代码 阿里云容器镜像服务 https://www.aliyun.com/product/acr 添加Docker CE阿里云镜像仓库 sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo 安装Docker CE、Doc…...

vue2和vue3动态引入路由,权限控制
后端返回的路由结构(具体路由可以本地模拟) // 此路由自己本地模拟即可 const menus [{"title": "动态路由","meta": "{\"title\":\"动态路由\",\"noCache\":true}","component": "/t…...

Spring Boot:植物健康的智能守护者
2相关技术 2.1 MYSQL数据库 MySQL是一个真正的多用户、多线程SQL数据库服务器。 是基于SQL的客户/服务器模式的关系数据库管理系统,它的有点有有功能强大、使用简单、管理方便、安全可靠性高、运行速度快、多线程、跨平台性、完全网络化、稳定性等,非常…...
红黑树 学习笔记
目录 1.红黑树的概念 1.1红黑树的规则 1.2红黑树的效率 2.红黑树的实现 2.1红黑树的大致结构 2.2红黑树的插入 2.2.1红黑树插入的大致过程 2.2.2情况1:变色 2.2.3情况2:单旋+变色 2.2.4情况3:双旋变色 2.3红黑树的查找…...

Linux应用开发之网络套接字编程(实例篇)
服务端与客户端单连接 服务端代码 #include <sys/socket.h> #include <sys/types.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <arpa/inet.h> #include <pthread.h> …...

linux之kylin系统nginx的安装
一、nginx的作用 1.可做高性能的web服务器 直接处理静态资源(HTML/CSS/图片等),响应速度远超传统服务器类似apache支持高并发连接 2.反向代理服务器 隐藏后端服务器IP地址,提高安全性 3.负载均衡服务器 支持多种策略分发流量…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

Cinnamon修改面板小工具图标
Cinnamon开始菜单-CSDN博客 设置模块都是做好的,比GNOME简单得多! 在 applet.js 里增加 const Settings imports.ui.settings;this.settings new Settings.AppletSettings(this, HTYMenusonichy, instance_id); this.settings.bind(menu-icon, menu…...

MySQL 8.0 OCP 英文题库解析(十三)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题111~120 试题1…...

vue3+vite项目中使用.env文件环境变量方法
vue3vite项目中使用.env文件环境变量方法 .env文件作用命名规则常用的配置项示例使用方法注意事项在vite.config.js文件中读取环境变量方法 .env文件作用 .env 文件用于定义环境变量,这些变量可以在项目中通过 import.meta.env 进行访问。Vite 会自动加载这些环境变…...

docker 部署发现spring.profiles.active 问题
报错: org.springframework.boot.context.config.InvalidConfigDataPropertyException: Property spring.profiles.active imported from location class path resource [application-test.yml] is invalid in a profile specific resource [origin: class path re…...

Python+ZeroMQ实战:智能车辆状态监控与模拟模式自动切换
目录 关键点 技术实现1 技术实现2 摘要: 本文将介绍如何利用Python和ZeroMQ消息队列构建一个智能车辆状态监控系统。系统能够根据时间策略自动切换驾驶模式(自动驾驶、人工驾驶、远程驾驶、主动安全),并通过实时消息推送更新车…...

Bean 作用域有哪些?如何答出技术深度?
导语: Spring 面试绕不开 Bean 的作用域问题,这是面试官考察候选人对 Spring 框架理解深度的常见方式。本文将围绕“Spring 中的 Bean 作用域”展开,结合典型面试题及实战场景,帮你厘清重点,打破模板式回答,…...

根目录0xa0属性对应的Ntfs!_SCB中的FileObject是什么时候被建立的----NTFS源代码分析--重要
根目录0xa0属性对应的Ntfs!_SCB中的FileObject是什么时候被建立的 第一部分: 0: kd> g Breakpoint 9 hit Ntfs!ReadIndexBuffer: f7173886 55 push ebp 0: kd> kc # 00 Ntfs!ReadIndexBuffer 01 Ntfs!FindFirstIndexEntry 02 Ntfs!NtfsUpda…...