Lucas带你手撕机器学习——套索回归
好的,下面我将详细介绍套索回归的背景、理论基础、实现细节以及在实践中的应用,同时还会讨论其优缺点和一些常见问题。
套索回归(Lasso Regression)
1. 背景与动机
在机器学习和统计学中,模型的复杂性通常会影响其在新数据上的泛化能力。特别是当特征数量多于样本数量时,模型容易过拟合,导致性能下降。为了解决这个问题,引入了正则化技术,以限制模型的复杂性。套索回归就是一种结合了线性回归与L1正则化的回归方法,具有以下特点:
-
特征选择:由于L1正则化的特性,套索回归能够将一些特征的系数压缩为零,从而实现特征选择。这使得模型更简单、更易解释。
-
提高泛化能力:通过减少特征数量,套索回归有助于提高模型的泛化能力,尤其在高维数据中表现更好。
2. 理论基础
2.1. 损失函数
套索回归的目标是最小化以下损失函数:

其中:

是目标变量与预测值之间的均方误差。

是L1正则化项,即模型参数的绝对值之和,𝜆 是正则化强度的超参数。
L1正则化会增加较大的惩罚,使得某些特征的系数可能被完全压缩为零,从而实现特征选择。
2.2. 优化算法
由于套索回归的损失函数是非光滑的(L1范数不连续),可以使用次梯度法、坐标下降法或其他优化方法来求解最优参数。坐标下降法是套索回归中一种常用且高效的优化算法。
3. 优缺点
3.1. 优点
- 特征选择:能够自动选择重要特征,减少不必要的噪声,提高模型的可解释性。
- 简化模型:减少模型的复杂性,降低过拟合的风险。
- 适应高维数据:在特征数量远大于样本数量时,仍能有效工作。
3.2. 缺点
- 可能丢失重要信息:如果正则化参数选择不当,可能会丢失对结果有影响的特征。
- 对特征标准化敏感:套索回归对特征的尺度非常敏感,通常需要对特征进行标准化处理。
- 在特征间高度相关时的局限性:在特征高度相关的情况下,套索回归可能随机选择其中一个特征,而忽略其他重要特征。
4. 实践中的应用
套索回归广泛应用于以下场景:
- 金融风险建模:在预测信用评分或贷款违约的模型中,能够选择对结果影响最大的特征。
- 生物医学:在基因选择和疾病预测等应用中,通过特征选择来提高模型的可解释性。
- 文本分类:在文本特征提取中,通过选择重要的单词或短语来构建简化模型。
5. 使用 scikit-learn 和 PyTorch 实现套索回归
5.1. scikit-learn 实现
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Lasso
from sklearn.datasets import make_regression# 生成示例数据
X, y, coef = make_regression(n_samples=100, n_features=10, noise=0.1, coef=True, random_state=42)# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建套索回归模型
lasso_model = Lasso(alpha=1.0) # alpha是正则化强度# 训练模型
lasso_model.fit(X_train, y_train)# 进行预测
y_pred = lasso_model.predict(X_test)# 输出模型系数
print("模型系数:", lasso_model.coef_)
print("模型截距:", lasso_model.intercept_)# 可视化真实值与预测值
plt.scatter(y_test, y_pred)
plt.xlabel("真实值")
plt.ylabel("预测值")
plt.title("真实值与预测值的比较")
plt.plot([y.min(), y.max()], [y.min(), y.max()], '--', color='red') # 对角线
plt.show()
5.2. PyTorch 实现
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_regression# 生成示例数据
X, y, coef = make_regression(n_samples=100, n_features=10, noise=0.1, coef=True, random_state=42)# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 转换为PyTorch张量
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.float32).view(-1, 1)
X_test_tensor = torch.tensor(X_test, dtype=torch.float32)
y_test_tensor = torch.tensor(y_test, dtype=torch.float32).view(-1, 1)# 创建套索回归模型
class LassoRegression(nn.Module):def __init__(self, input_dim, lambda_reg):super(LassoRegression, self).__init__()self.linear = nn.Linear(input_dim, 1)self.lambda_reg = lambda_regdef forward(self, x):return self.linear(x)def loss_function(self, y_pred, y_true):mse_loss = nn.MSELoss()(y_pred, y_true)l1_reg = self.lambda_reg * torch.sum(torch.abs(self.linear.weight))return mse_loss + l1_reg# 超参数
input_dim = X_train.shape[1]
lambda_reg = 1.0
num_epochs = 1000
learning_rate = 0.01# 初始化模型和优化器
model = LassoRegression(input_dim, lambda_reg)
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)# 训练模型
for epoch in range(num_epochs):model.train()optimizer.zero_grad()y_pred = model(X_train_tensor)loss = model.loss_function(y_pred, y_train_tensor)loss.backward()optimizer.step()if epoch % 100 == 0:print(f'Epoch [{epoch}/{num_epochs}], Loss: {loss.item():.4f}')# 进行预测
model.eval()
with torch.no_grad():y_test_pred = model(X_test_tensor)# 可视化真实值与预测值
plt.scatter(y_test, y_test_pred.numpy())
plt.xlabel("真实值")
plt.ylabel("预测值")
plt.title("真实值与预测值的比较")
plt.plot([y.min(), y.max()], [y.min(), y.max()], '--', color='red') # 对角线
plt.show()# 输出模型系数和截距
print("模型权重:", model.linear.weight.data.numpy())
print("模型偏置:", model.linear.bias.data.numpy())
6. 常见问题
-
如何选择合适的正则化参数 (\lambda)?
- 通常使用交叉验证来选择合适的正则化参数。可以尝试多个值并选择在验证集上表现最佳的参数。
-
是否需要对特征进行标准化?
- 是的,特征标准化非常重要,因为套索回归对特征的尺度非常敏感。通常在训练之前对特征进行标准化处理(例如,标准化为均值为0,方差为1的分布)。
-
在特征之间高度相关时如何处理?
- 套索回归可能会随机选择相关特征中的一个,而忽略其他特征。如果特征高度相关,可以考虑使用岭回归或其他方法来处理。
总结
套索回归是一种强大的线性回归工具,通过L1正则化实现特征选择,有助于提高模型的可解释性和泛化能力。在高维数据集上,套索回归表现良好,但需要仔细选择正则化参数并进行特征标准化。通过 scikit-learn 和 PyTorch,我们可以灵活地实现套索回归,以适应不同的需求和应用场景。
如果您还有其他问题或需要更深入的讨论,请随时告诉我!
相关文章:
Lucas带你手撕机器学习——套索回归
好的,下面我将详细介绍套索回归的背景、理论基础、实现细节以及在实践中的应用,同时还会讨论其优缺点和一些常见问题。 套索回归(Lasso Regression) 1. 背景与动机 在机器学习和统计学中,模型的复杂性通常会影响其在…...

面试中的一个基本问题:如何在数据库中存储密码?
面试中的一个基本问题:如何在数据库中存储密码? 在安全面试中,“如何在数据库中存储密码?”是一个基础问题,但反映了应聘者对安全最佳实践的理解。以下是安全存储密码的最佳实践概述。 了解风险 存储密码必须安全&am…...

XML HTTP Request
XML HTTP Request 简介 XMLHttpRequest(XHR)是一个JavaScript对象,它最初由微软设计,并在IE5中引入,用于在后台与服务器交换数据。它允许网页在不重新加载整个页面的情况下更新部分内容,这使得网页能够实现动态更新,大大提高了用户体验。虽然名字中包含“XML”,但XML…...

TLS协议基本原理与Wireshark分析
01背 景 随着车联网的迅猛发展,汽车已经不再是传统的机械交通工具,而是智能化、互联化的移动终端。然而,随之而来的是对车辆通信安全的日益严峻的威胁。在车联网生态系统中,车辆通过无线网络与其他车辆、基础设施以及云端服务进行…...
怎么办)
当遇到 502 错误(Bad Gateway)怎么办
很多安装雷池社区版的时候,配置完成,访问的时候可能会遇到当前问题,如何解决呢? 客户端,浏览器排查 1.刷新页面和清除缓存 首先尝试刷新页面,因为有时候 502 错误可能是由于网络临时波动导致服务器无法连…...
: 加油站)
学习记录:js算法(七十五): 加油站
文章目录 加油站思路一思路二思路三思路四思路五 加油站 在一条环路上有 n 个加油站,其中第 i 个加油站有汽油 gas[i] 升。 你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发…...

强心剂!EEMD-MPE-KPCA-LSTM、EEMD-MPE-LSTM、EEMD-PE-LSTM故障识别、诊断
强心剂!EEMD-MPE-KPCA-LSTM、EEMD-MPE-LSTM、EEMD-PE-LSTM故障识别、诊断 目录 强心剂!EEMD-MPE-KPCA-LSTM、EEMD-MPE-LSTM、EEMD-PE-LSTM故障识别、诊断效果一览基本介绍程序设计参考资料 效果一览 基本介绍 EEMD-MPE-KPCA-LSTM(集合经验模态分解-多尺…...

yarn的安装与使用以及与npm的区别(安装过程中可能会遇到的问题)
一、yarn的安装 使用npm就可以进行安装 但是需要注意的一点是yarn的使用和node版本是有关系的必须是16.0以上的版本。 输入以下代码就可以实现yarn的安装 npm install -g yarn 再通过版本号的检查来确定,yarn是否安装成功 yarn -v二、遇到的问题 1、问题描述…...

大数据行业预测
大数据行业预测 编译 李升伟 和所有预测一样,我们必须谨慎对待这些预测,因为其中一些预测可能成不了事实。当然,真正改变游戏规则的创新往往出乎意料,甚至让最警惕的预言家也措手不及。所以,如果在来年发生了一些惊天…...
打包成桌面端(nextron、electron、tauri)的最佳解决方式)
可能是NextJs(使用ssr、api route)打包成桌面端(nextron、electron、tauri)的最佳解决方式
可能是NextJs(使用ssr、api route)打包成桌面端(nextron、electron、tauri)的最佳解决方式 前言 在我使用nextron(nextelectron)写了一个项目后打包发现nextron等一系列桌面端框架在生产环境是不支持next的ssr也就是api route功能的这就导致我非常难受&…...

二百七十、Kettle——ClickHouse中增量导入清洗数据错误表
一、目的 比如原始数据100条,清洗后,90条正确数据在DWD层清洗表,10条错误数据在DWD层清洗数据错误表,所以清洗数据错误表任务一定要放在清洗表任务之后。 更关键的是,Hive中原本的SQL语句,放在ClickHouse…...

CentOS6升级OpenSSH9.2和OpenSSL3
文章目录 1.说明2.下载地址3.升级OpenSSL4.安装telnet 服务4.1.安装 telnet 服务4.2 关闭防火墙4.2.使用 telnet 连接 5.升级OpenSSH5.1.安装相关命令依赖5.2.备份原 ssh 配置5.3.卸载原有的 OpenSSH5.4.安装 OpenSSH5.5.修改 ssh 配置文件5.6关闭 selinux5.7.重启 OpenSSH 1.说…...
2024 年 MathorCup 数学应用挑战赛——大数据竞赛-赛道 A:台风的分类与预测
2024年MathorCup大数据挑战赛-赛道A初赛--思路https://download.csdn.net/download/qq_52590045/89922904↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓…...

kotlin实现viewpager
说明:kotlin tablayout viewpager adapter实现滑动界面 效果图 step1: package com.example.flushfragmentdemoimport androidx.appcompat.app.AppCompatActivity import android.os.Bundle import androidx.fragment.app.Fragment import androidx.viewpager2.adapter.…...
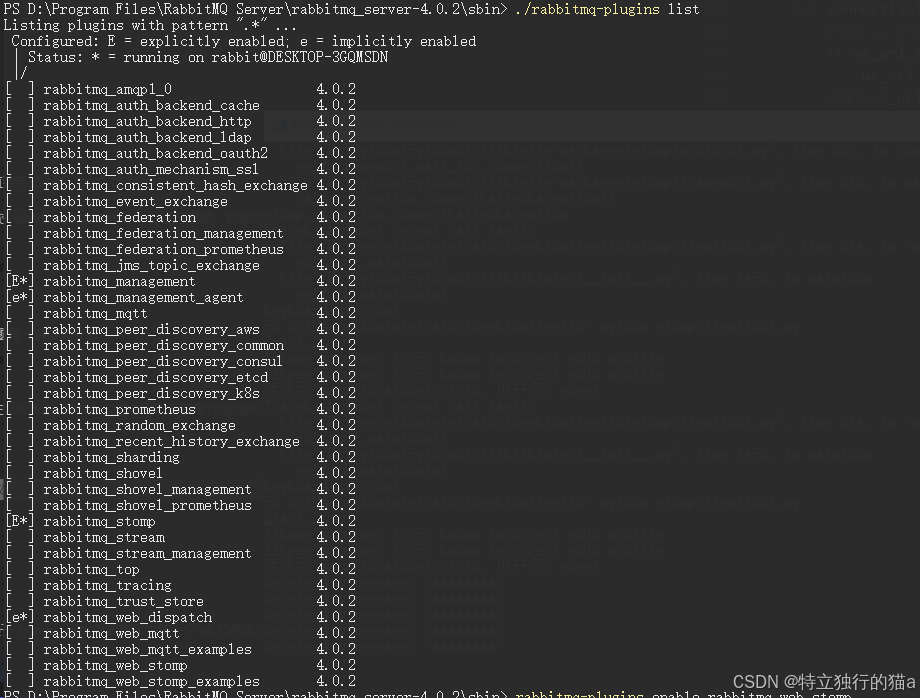
RabbitMQ最新版本4.0.2在Windows下的安装及使用
RabbitMQ 是一个开源的消息代理和队列服务器,提供可靠的消息传递和队列服务。它支持多种消息协议,包括 AMQP、STOMP、MQTT 等。本文将详细介绍如何在 Windows 系统上安装和使用最新版本的 RabbitMQ 4.0.2。 前言 RabbitMQ 是用 Erlang 语言开发的 AMQP&…...

东方博宜1180 - 数字出现次数
问题描述 有 50 个数( 0∼19),求这 50个数中相同数字出现的最多次数为几次? 输入 50 个数字。 输出 1 个数字(即相同数字出现的最多次数)。 样例 输入 1 10 2 0 15 8 12 7 0 3 15 0 15 18 16 7 17 16 9 …...

LeetCode: 3274. 检查棋盘方格颜色是否相同
一、题目 给你两个字符串 coordinate1 和 coordinate2,代表 8 x 8 国际象棋棋盘上的两个方格的坐标。 以下是棋盘的参考图。 如果这两个方格颜色相同,返回 true,否则返回 false。 坐标总是表示有效的棋盘方格。坐标的格式总是先…...

datax编译并测试
mvn -U clean package assembly:assembly -Dmaven.test.skiptrue 参看:DataX导数的坑_datax插件初始化错误, 该问题通常是由于datax安装错误引起,请联系您的运维解决-CSDN博客 两边表结构先创建好: (base) [rootlnpg bin]# pwd /db/DataX-datax_v20230…...

2-133 基于matlab的粒子群算法PSO优化BP神经网络
基于matlab的粒子群算法PSO优化BP神经网络,BP神经网络算法采用梯度下降算法,以输出误差平方最小为目标,采用误差反向传播,训练网络节点权值和偏置值,得到训练模型。BP神经网络的结构(层数、每层节点个数)较复杂时&…...
形势重新评估与后续措施)
复盘秋招22场面试(四)形势重新评估与后续措施
连续好多天睡不着觉,经常晚上起来好几次,到现在还是没offer。之前有个校友在抖音留言说我能收到这么多面试说明简历没问题,这么多一面挂,说明我技术面有问题。确实有一些是kpi面,但是我复盘之后我发现也没有那么多kpi面…...

XML Group端口详解
在XML数据映射过程中,经常需要对数据进行分组聚合操作。例如,当处理包含多个物料明细的XML文件时,可能需要将相同物料号的明细归为一组,或对相同物料号的数量进行求和计算。传统实现方式通常需要编写脚本代码,增加了开…...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...

AI编程--插件对比分析:CodeRider、GitHub Copilot及其他
AI编程插件对比分析:CodeRider、GitHub Copilot及其他 随着人工智能技术的快速发展,AI编程插件已成为提升开发者生产力的重要工具。CodeRider和GitHub Copilot作为市场上的领先者,分别以其独特的特性和生态系统吸引了大量开发者。本文将从功…...

JVM虚拟机:内存结构、垃圾回收、性能优化
1、JVM虚拟机的简介 Java 虚拟机(Java Virtual Machine 简称:JVM)是运行所有 Java 程序的抽象计算机,是 Java 语言的运行环境,实现了 Java 程序的跨平台特性。JVM 屏蔽了与具体操作系统平台相关的信息,使得 Java 程序只需生成在 JVM 上运行的目标代码(字节码),就可以…...

android13 app的触摸问题定位分析流程
一、知识点 一般来说,触摸问题都是app层面出问题,我们可以在ViewRootImpl.java添加log的方式定位;如果是touchableRegion的计算问题,就会相对比较麻烦了,需要通过adb shell dumpsys input > input.log指令,且通过打印堆栈的方式,逐步定位问题,并找到修改方案。 问题…...

面试高频问题
文章目录 🚀 消息队列核心技术揭秘:从入门到秒杀面试官1️⃣ Kafka为何能"吞云吐雾"?性能背后的秘密1.1 顺序写入与零拷贝:性能的双引擎1.2 分区并行:数据的"八车道高速公路"1.3 页缓存与批量处理…...
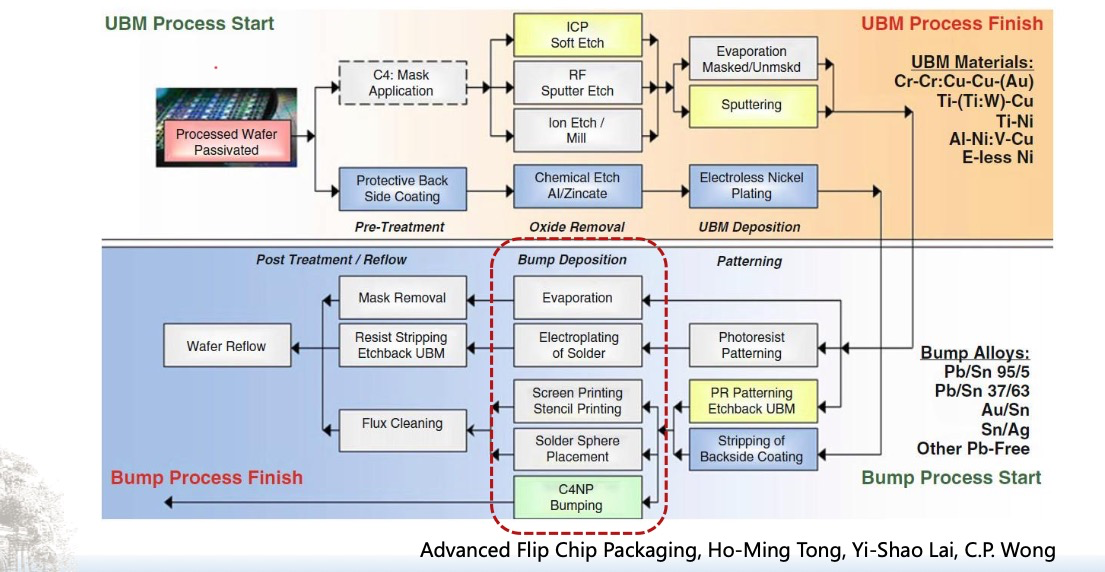
倒装芯片凸点成型工艺
UBM(Under Bump Metallization)与Bump(焊球)形成工艺流程。我们可以将整张流程图分为三大阶段来理解: 🔧 一、UBM(Under Bump Metallization)工艺流程(黄色区域ÿ…...

初级程序员入门指南
初级程序员入门指南 在数字化浪潮中,编程已然成为极具价值的技能。对于渴望踏入程序员行列的新手而言,明晰入门路径与必备知识是开启征程的关键。本文将为初级程序员提供全面的入门指引。 一、明确学习方向 (一)编程语言抉择 编…...
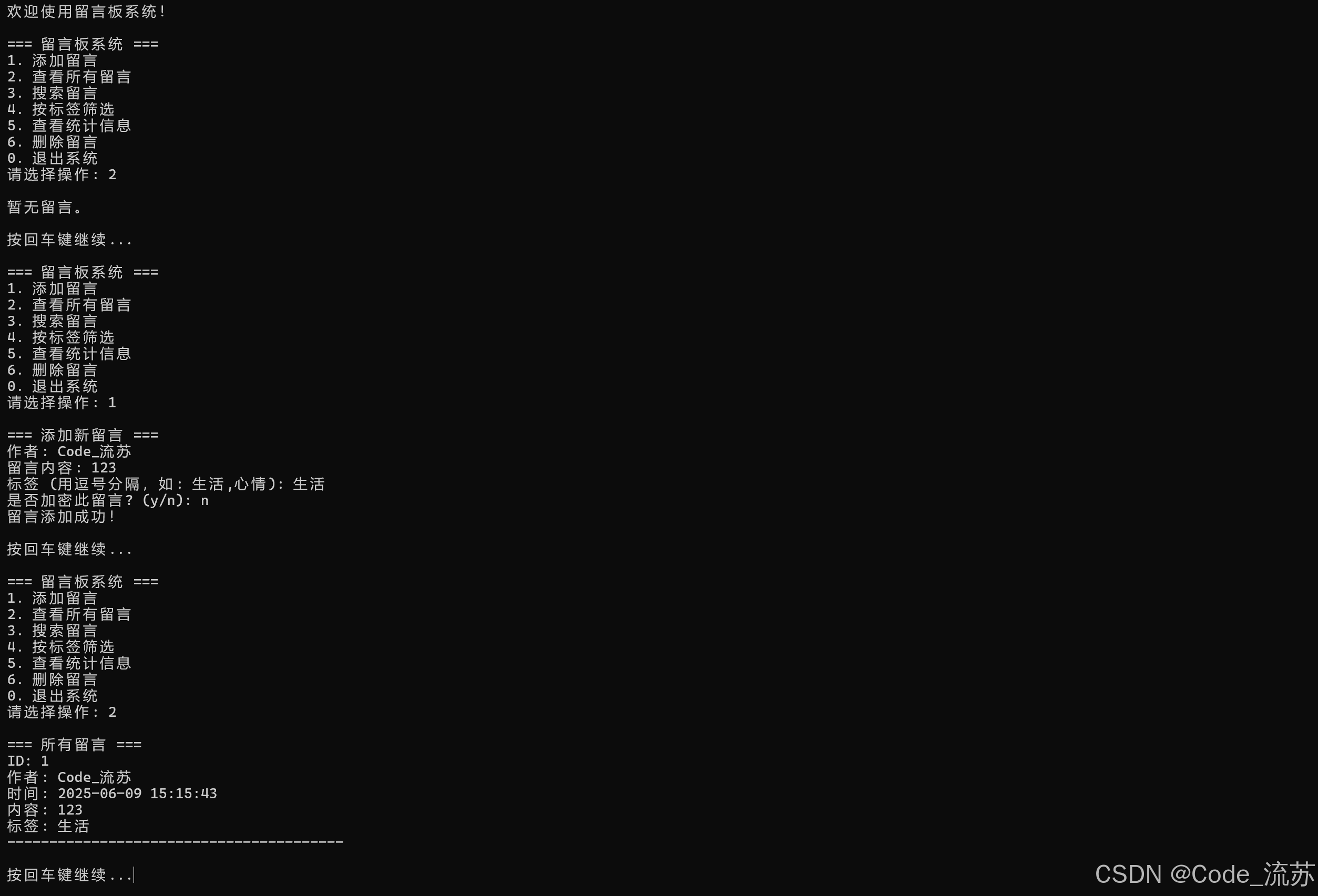
C++课设:实现本地留言板系统(支持留言、搜索、标签、加密等)
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏介绍:《编程项目实战》 目录 一、项目功能概览与亮点分析1. 核心功能…...