pytorh学习笔记——cifar10(四)用VGG训练
1、新建train.py,执行脚本训练模型:
import os
import timeimport torch
import torch.nn as nn
import torchvisionfrom vggNet import VGGbase, VGGNet
from load_cifar import train_loader, test_loader
import warnings
import tensorboardX# 忽略警告
warnings.filterwarnings('ignore')def main():# 定义超参数device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 使用GPU训练# device = 'cpu' # 使用CPU训练print('device:', device)batch_size = 128learning_rate = 0.1num_epoches = 100 # 训练100个epoch# 定义模型net = VGGNet().to(device) # 将模型放入GPU# 定义损失函数和优化器loss_func = nn.CrossEntropyLoss() # 交叉熵损失函数optimizer = torch.optim.Adam(net.parameters(), lr=learning_rate) # 优化器使用Adamscheduler = torch.optim.lr_scheduler.StepLR(optimizer,step_size=5,gamma=0.9) # 学习率衰减, 每5个epoch,学习率乘以0.9# 可视化log_path = 'logs/vggNet_log' # 保存日志的文件夹if not os.path.exists(log_path): # 如果log文件不存在,则创建os.makedirs(log_path)writer = tensorboardX.SummaryWriter(log_path) # 创建一个writer# 训练模型# step_n = 0 # 记录训练次数for epoch in range(num_epoches): # 训练num_epoches个epochprint('Epoch {}/{}'.format(epoch, num_epoches))begin_time = time.time() # 记录开始时间net.train() # 设置为训练模式for idx, (images, labels) in enumerate(train_loader): # 遍历训练集,共有391个batch,每个batch有128个样本images = images.to(device) # 将图片数据放入GPUlabels = labels.to(device) # 将图片标签放入GPUoutputs = net(images) # 前向传播loss = loss_func(outputs, labels) # 计算损失optimizer.zero_grad() # 梯度清零loss.backward() # 反向传播optimizer.step() # 优化器更新参数# writer.add_scalar('train_loss', loss.item(), global_step=step_n) # 将loss添加到writer中# writer.add_scalar('train correct', 100.0 * correct.item() / batch_size,# global_step=step_n) # 将正确率添加到writer中# step_n += 1 # 记录训练次数if (idx + 1) % 100 == 0: # 每100个batch打印一次训练信息,每个batch有128个样本,相当于12800个样本打印一次_, pred = torch.max(outputs, dim=1) # 获取预测结果correct = pred.eq(labels).cpu().sum() # 计算正确率# pred:神经网络的输出预测张量。# labels:通常表示真实的标签。这个张量与 pred 有相同的形状。# pred.eq(labels.data):这个调用会生成一个布尔张量,表示在 pred 中的每个元素是否等于 labels 中的相应元素。结果会是一个同形状的张量,其中的值为 True 或 False。# .cpu():方法用于将张量从 GPU 转移到 CPU。# .sum()方法对布尔张量(True 是 1,False 是 0)进行求和,返回 True 值的数量。也就是说,它返回 pred 中与 labels 相等元素的个数。这通常用于计算模型的正确预测数量。# 请注意这里的eq()和sum()是torch中的方法,与python自带的eq()、sum()方法略有不同。# 详见https://blog.csdn.net/xulibo5828/article/details/143115452print('Train Accuracy: {} %'.format(100 * correct / batch_size))scheduler.step() # 更新学习率end_time = time.time() # 记录结束时间print('Each train_epoch take time: {} s'.format(end_time - begin_time)) # 打印每个epoch的耗时# 测试模型sum_loss = 0 # 记录测试损失sum_correct = 0 # 记录测试正确率net.eval() # 设置为测试模式begin_time = time.time() # 记录开始时间for idx, (images, labels) in enumerate(test_loader): # 遍历训练集images = images.to(device) # 将图片数据放入GPUlabels = labels.to(device) # 将图片标签放入GPUoutputs = net(images) # 前向传播# loss = loss_func(outputs, labels) # 计算损失_, pred = torch.max(outputs, dim=1) # 获取预测结果if (idx + 1) % 30 == 0: # 每30个batch打印一次训练信息correct = pred.eq(labels).cpu().sum() # 计算正确率# sum_loss += loss.item() # 测试损失sum_correct += correct.item() # 测试正确率print('Test Accuracy: {} %'.format(100 * correct / batch_size))# test_loss = sum_loss * 1.0 / len(test_loader) # 计算测试损失# test_correct = sum_correct * 100.0 / len(test_loader.dataset) / batch_size # 计算测试正确率# writer.add_scalar('test_loss', test_loss, global_step=epoch + 1) # 将loss添加到writer中# writer.add_scalar('test correct', test_correct, global_step=epoch + 1) # 将正确率添加到writer中end_time = time.time() # 记录结束时间print('Each test_epoch take time: {} s'.format(end_time - begin_time)) # 打印每个epoch的耗时# 保存模型torch.save(net.state_dict(), 'vggNet.pkl') # 保存模型print('Finished Training')writer.close() # 关闭writerif __name__ == '__main__':main()
第1个epoch的准确率:
Train Accuracy: 17.96875 %第20个epoch的准确率:
Train Accuracy: 82.03125 %第50个epoch的准确率:
Train Accuracy: 87.5 %没有继续训练。
2、加入可视化的代码:
import os
import timeimport torch
import torch.nn as nn
import torchvisionfrom vggNet import VGGbase, VGGNet
from load_cifar import train_loader, test_loader
import warnings
import tensorboardX# 忽略警告
warnings.filterwarnings('ignore')def main():# 定义超参数device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 使用GPU训练# device = 'cpu' # 使用CPU训练print('device:', device)batch_size = 128learning_rate = 0.1num_epoches = 100 # 训练100个epoch# 定义模型net = VGGNet().to(device) # 将模型放入GPU# 定义损失函数和优化器loss_func = nn.CrossEntropyLoss() # 交叉熵损失函数optimizer = torch.optim.Adam(net.parameters(), lr=learning_rate) # 优化器使用Adamscheduler = torch.optim.lr_scheduler.StepLR(optimizer,step_size=5,gamma=0.9) # 学习率衰减, 每5个epoch,学习率乘以0.9# 可视化log_path = 'logs/vggNet_log' # 保存日志的文件夹if not os.path.exists(log_path): # 如果log文件不存在,则创建os.makedirs(log_path)writer = tensorboardX.SummaryWriter(log_path) # 创建一个writer# 训练模型step_n = 0 # 记录训练次数for epoch in range(num_epoches): # 训练num_epoches个epochprint('Epoch {}/{}'.format(epoch, num_epoches))begin_time = time.time() # 记录开始时间net.train() # 设置为训练模式for idx, (images, labels) in enumerate(train_loader): # 遍历训练集,共有391个batch,每个batch有128个样本images = images.to(device) # 将图片数据放入GPUlabels = labels.to(device) # 将图片标签放入GPUoutputs = net(images) # 前向传播loss = loss_func(outputs, labels) # 计算损失optimizer.zero_grad() # 梯度清零loss.backward() # 反向传播optimizer.step() # 优化器更新参数_, pred = torch.max(outputs, dim=1) # 获取预测结果correct = pred.eq(labels).cpu().sum() # 计算正确率# pred:神经网络的输出预测张量。# labels:通常表示真实的标签。这个张量与 pred 有相同的形状。# pred.eq(labels.data):这个调用会生成一个布尔张量,表示在 pred 中的每个元素是否等于 labels 中的相应元素。结果会是一个同形状的张量,其中的值为 True 或 False。# .cpu():方法用于将张量从 GPU 转移到 CPU。# .sum()方法对布尔张量(True 是 1,False 是 0)进行求和,返回 True 值的数量。也就是说,它返回 pred 中与 labels 相等元素的个数。这通常用于计算模型的正确预测数量。# 请注意这里的eq()和sum()是torch中的方法,与python自带的eq()、sum()方法略有不同。# 详见https://blog.csdn.net/xulibo5828/article/details/143115452writer.add_scalar('train_loss', loss.item(), global_step=step_n) # 将loss添加到writer中writer.add_scalar('train correct', 100.0 * correct.item() / batch_size,global_step=step_n) # 将正确率添加到writer中step_n += 1 # 记录训练次数if (idx + 1) % 100 == 0: # 每100个batch打印一次训练信息,每个batch有128个样本,相当于12800个样本打印一次print('Train Accuracy: {} %'.format(100 * correct / batch_size))scheduler.step() # 更新学习率end_time = time.time() # 记录结束时间print('Each train_epoch take time: {} s'.format(end_time - begin_time)) # 打印每个epoch的耗时# 测试模型sum_loss = 0 # 记录测试损失sum_correct = 0 # 记录测试正确率net.eval() # 设置为测试模式begin_time = time.time() # 记录开始时间for idx, (images, labels) in enumerate(test_loader): # 遍历训练集images = images.to(device) # 将图片数据放入GPUlabels = labels.to(device) # 将图片标签放入GPUoutputs = net(images) # 前向传播# loss = loss_func(outputs, labels) # 计算损失_, pred = torch.max(outputs, dim=1) # 获取预测结果if (idx + 1) % 30 == 0: # 每30个batch打印一次训练信息correct = pred.eq(labels).cpu().sum() # 计算正确率# sum_loss += loss.item() # 测试损失sum_correct += correct.item() # 测试正确率print('Test Accuracy: {} %'.format(100 * correct / batch_size))test_loss = sum_loss * 1.0 / len(test_loader) # 计算测试损失test_correct = sum_correct * 100.0 / len(test_loader.dataset) / batch_size # 计算测试正确率writer.add_scalar('test_loss', test_loss, global_step=epoch + 1) # 将loss添加到writer中writer.add_scalar('test correct', test_correct, global_step=epoch + 1) # 将正确率添加到writer中end_time = time.time() # 记录结束时间print('Each test_epoch take time: {} s'.format(end_time - begin_time)) # 打印每个epoch的耗时# 保存模型torch.save(net.state_dict(), 'vggNet.pkl') # 保存模型print('Finished Training')writer.close() # 关闭writerif __name__ == '__main__':main()
3、调用查看数据曲线:
--打开anaconda的命令行窗口,输入:conda activate torch(这里的torch是自定义的环境名称),进入pytorch所在的环境

--输入:tensorboard --logdir=E:\AI_tset\cifar10_demo\logs\vggNet_log,“E:\AI_tset\cifar10_demo\logs\vggNet_log”是训练脚本中定义的日志文件所在的目录。

出现了:TensorBoard 2.18.0 at http://localhost:6006/,打开浏览器,输入http://localhost:6006/或者127.0.0.1:6006/,就会显示出数据曲线:

相关文章:
pytorh学习笔记——cifar10(四)用VGG训练
1、新建train.py,执行脚本训练模型: import os import timeimport torch import torch.nn as nn import torchvisionfrom vggNet import VGGbase, VGGNet from load_cifar import train_loader, test_loader import warnings import tensorboardX# 忽略…...

CRLF、UTF-8这些编辑器右下角的选项的意思
经常使用编辑器的小伙伴应该经常能看到右下角会有这么两个选项,下图是VScode中的示例,那么这两个到底是啥作用呢? 目录 字符编码ASCII 字符集GBK 字符集Unicode 字符集UTF-8 编码 换行 字符编码 此部分参考博文 在计算机中,所有…...

【C++干货篇】——类和对象的魅力(四)
【C干货篇】——类和对象的魅力(四) 1.取地址运算符的重载 1.1const 成员函数 将const修饰的成员函数称之为const成员函数,const修饰成员函数放到成员函数参数列表的后面。const实际修饰该成员函数隐含的this指针(this指向的对…...

基于java的诊所管理系统源码,SaaS门诊信息系统,二次开发的不二选择
门诊管理系统源码,诊所系统源码,saas服务模式 医疗信息化的新时代已经到来,诊所管理系统作为诊所管理和运营的核心工具,不仅提升了医疗服务的质量和效率,也为患者提供了更加便捷和舒适的就医体验,同时还推动…...

O2OA如何实现文件跨服务器的备份
O2OA可以外接存储服务器,但是一个存储服务器上怕磁盘损坏等问题导致文件丢失,所以需要实现文件跨服务器备份。 整体过程: 1、SSH免密登录配置 2、增加一个同步推送文件的.sh文件 3、编辑crontab 增加定时任务执行上一步的.sh文件 一、配…...
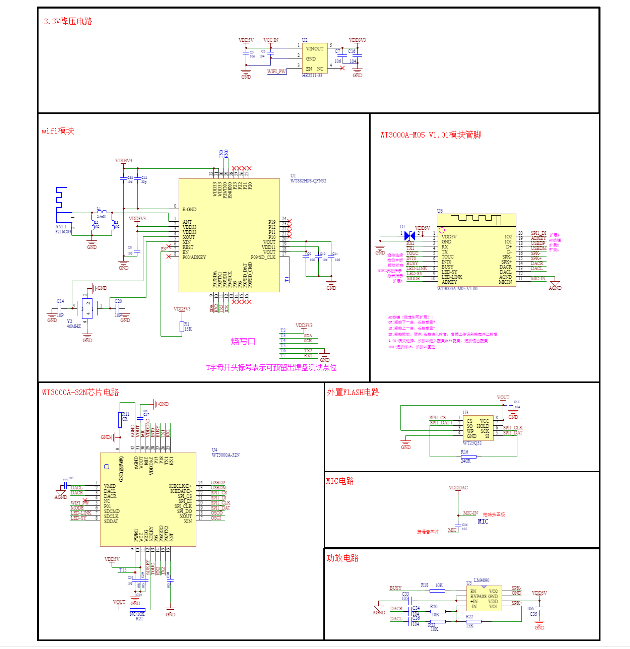
语音提示器-WT3000A离在线TTS方案-打破语种限制/AI对话多功能支持
前言: TTS(Text To Speech )技术作为智能语音领域的重要组成部分,能够将文本信息转化为逼真的语音输出,为各类硬件设备提供便捷的语音提示服务。本方案正是基于唯创知音的离在线TTS(离线本地音乐播放与在线…...

使用HAL库的STM32工程,实现DMA传输USART发送接收数据
以串口3为例,初始化部分为STM32CubeMX生成代码 串口初始化 UART_HandleTypeDef huart3; DMA_HandleTypeDef hdma_usart3_rx; DMA_HandleTypeDef hdma_usart3_tx;/* USART3 init function */ void MX_USART3_UART_Init(void) {/* USER CODE BEGIN USART3_Init 0 */…...

常用排序算法总结
内容目录 1. 选择类排序 1.1 直接选择排序1.2 堆排序 2. 交换类排序 2.1 冒泡排序2.2 快速排序 3. 插入类排序 3.1 直接插入排序3.2 希尔排序 4. 其它排序 4.1 归并排序4.2 基数排序/桶排序 排序 1. 选择类排序 选择类排序的特征是每次从待排序集合中选择出一个最大值或者最…...

[项目详解][boost搜索引擎#2] 建立index | 安装分词工具cppjieba | 实现倒排索引
目录 编写建立索引的模块 Index 1. 设计节点 2.基本结构 3.(难点) 构建索引 1. 构建正排索引(BuildForwardIndex) 2.❗构建倒排索引 3.1 cppjieba分词工具的安装和使用 3.2 引入cppjieba到项目中 倒排索引代码 本篇文章,我们将继续项…...

R语言编程
一、R语言在机器学习中的优势 R语言是一种广泛用于统计分析和数据可视化的编程语言,在机器学习领域也有诸多优势。 丰富的包:R拥有大量专门用于机器学习的包。例如,caret包是一个功能强大的机器学习工具包,它提供了统一的接口来训练和评估多种机器学习模型,如线性回归、决…...

Mysql主主互备配置
在现有运行的mysql环境下,修改相关配置项,完成主主互备模式的部署。 下面的配置说明中设置的mysql互备对应服务器IP为: 192.168.1.6 192.168.1.7 先检查UUID 在mysql的数据目录下,检查主备mysql的uuid(如下的server-…...
)
如何预防数据打架?数据仓库如何保持指标数据一致性开发指南(持续更新)
大数据开发人员最经常遇到尴尬和麻烦的事是,指标开发好了,以为万事大吉了。被业务和运营发现这个指标在不同地方数据打架,显示不同的数值。为了保证指标数据一致性,要从整个开发流程做好。 目录 一、数据仓库架构规划 二、数据抽取与转换 三、数据存储管理 四、指标管…...

我谈Canny算子
在Canny算子的论文中,提出了好的边缘检测算子应满足三点:①检测错误率低——尽可能多地查找出图像中的实际边缘,边缘的误检率(将边缘识别为非边缘)低,且避免噪声产生虚假边缘(将非边缘识别为边缘…...

算法的学习笔记—平衡二叉树(牛客JZ79)
😀前言 在数据结构中,二叉树是一种重要的树形结构。平衡二叉树是一种特殊的二叉树,其特性是任何节点的左右子树高度差的绝对值不超过1。本文将介绍如何判断一棵给定的二叉树是否为平衡二叉树,重点关注算法的时间复杂度和空间复杂度…...

SSM学习day01 JS基础语法
一、JS基础语法 跟java有点像,但是不用注明数据类型 使用var去声明变量 特点1:var关键字声明变量,是为全局变量,作用域很大。在一个代码块中定义的变量,在其他代码块里也能使用 特点2:可以重复定义&#…...

kubeadm快速自动化部署k8s集群
目录 一、准备环境 二、安装docker--三台机器都操作 三、使用kubeadm部署Kubernetes 在所有节点安装kubeadm和kubelet、kubectl 配置启动kubelet(所有主机) master节点初始化 Mater重新完成初始化 执行Master初始化后的提示配置 配置使用网络插件 创建flannel网络 …...

解决JAVA使用@JsonProperty序列化出现字段重复问题(大写开头的字段重复序列化)
文章目录 引言I 解决方案方案1:使用JsonAutoDetect注解方案2:手动编写get方法,JsonProperty注解加到方法上。方案3:首字母改成小写的II 知识扩展:对象默认是怎样被序列化?引言 需求: JSON序列化时,使用@JsonProperty注解,将字段名序列化为首字母大写,兼容前端和第三方…...

分布式理论基础
文章目录 1、理论基础2、CAP定理1_一致性2_可用性3_分区容错性4_总结 3、BASE理论1_Basically Available(基本可用)2_Soft State(软状态)3_Eventually Consistent(最终一致性)4_总结 1、理论基础 在计算机…...
-- jacoco agent)
Java应用程序的测试覆盖率之设计与实现(二)-- jacoco agent
说在前面的话 要想获得测试覆盖率报告,第一步要做的是,采集覆盖率数据,并输入到tcp。 而本文便是介绍一种java应用程序部署下的推荐方式。 作为一种通用方案,首先不想对应用程序有所侵入,其次运维和管理方便。 正好,jacoco agent就是类似于pinpoint agent一样,都使用…...

【机器学习】13. 决策树
决策树的构造 策略:从上往下学习通过recursive divide-and-conquer process(递归分治过程) 首先选择最好的变量作为根节点,给每一个可能的变量值创造分支。然后将样本放进子集之中,从每个分支的节点拓展一个。最后&a…...
:手搓截屏和帧率控制)
Python|GIF 解析与构建(5):手搓截屏和帧率控制
目录 Python|GIF 解析与构建(5):手搓截屏和帧率控制 一、引言 二、技术实现:手搓截屏模块 2.1 核心原理 2.2 代码解析:ScreenshotData类 2.2.1 截图函数:capture_screen 三、技术实现&…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...

【HarmonyOS 5.0】DevEco Testing:鸿蒙应用质量保障的终极武器
——全方位测试解决方案与代码实战 一、工具定位与核心能力 DevEco Testing是HarmonyOS官方推出的一体化测试平台,覆盖应用全生命周期测试需求,主要提供五大核心能力: 测试类型检测目标关键指标功能体验基…...

centos 7 部署awstats 网站访问检测
一、基础环境准备(两种安装方式都要做) bash # 安装必要依赖 yum install -y httpd perl mod_perl perl-Time-HiRes perl-DateTime systemctl enable httpd # 设置 Apache 开机自启 systemctl start httpd # 启动 Apache二、安装 AWStats࿰…...

Java多线程实现之Callable接口深度解析
Java多线程实现之Callable接口深度解析 一、Callable接口概述1.1 接口定义1.2 与Runnable接口的对比1.3 Future接口与FutureTask类 二、Callable接口的基本使用方法2.1 传统方式实现Callable接口2.2 使用Lambda表达式简化Callable实现2.3 使用FutureTask类执行Callable任务 三、…...
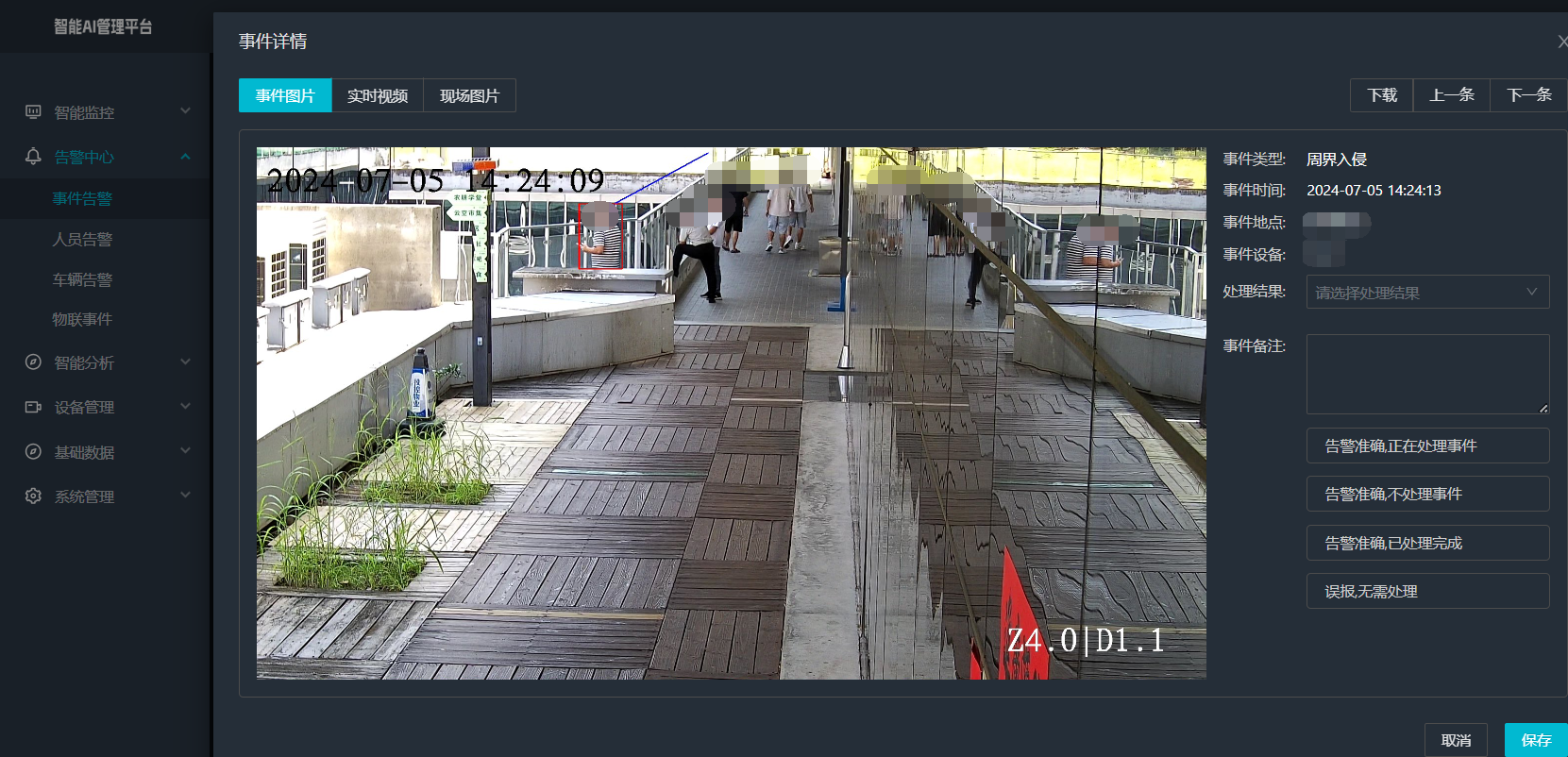
打手机检测算法AI智能分析网关V4守护公共/工业/医疗等多场景安全应用
一、方案背景 在现代生产与生活场景中,如工厂高危作业区、医院手术室、公共场景等,人员违规打手机的行为潜藏着巨大风险。传统依靠人工巡查的监管方式,存在效率低、覆盖面不足、判断主观性强等问题,难以满足对人员打手机行为精…...

破解路内监管盲区:免布线低位视频桩重塑停车管理新标准
城市路内停车管理常因行道树遮挡、高位设备盲区等问题,导致车牌识别率低、逃费率高,传统模式在复杂路段束手无策。免布线低位视频桩凭借超低视角部署与智能算法,正成为破局关键。该设备安装于车位侧方0.5-0.7米高度,直接规避树枝遮…...
)
uniapp 集成腾讯云 IM 富媒体消息(地理位置/文件)
UniApp 集成腾讯云 IM 富媒体消息全攻略(地理位置/文件) 一、功能实现原理 腾讯云 IM 通过 消息扩展机制 支持富媒体类型,核心实现方式: 标准消息类型:直接使用 SDK 内置类型(文件、图片等)自…...
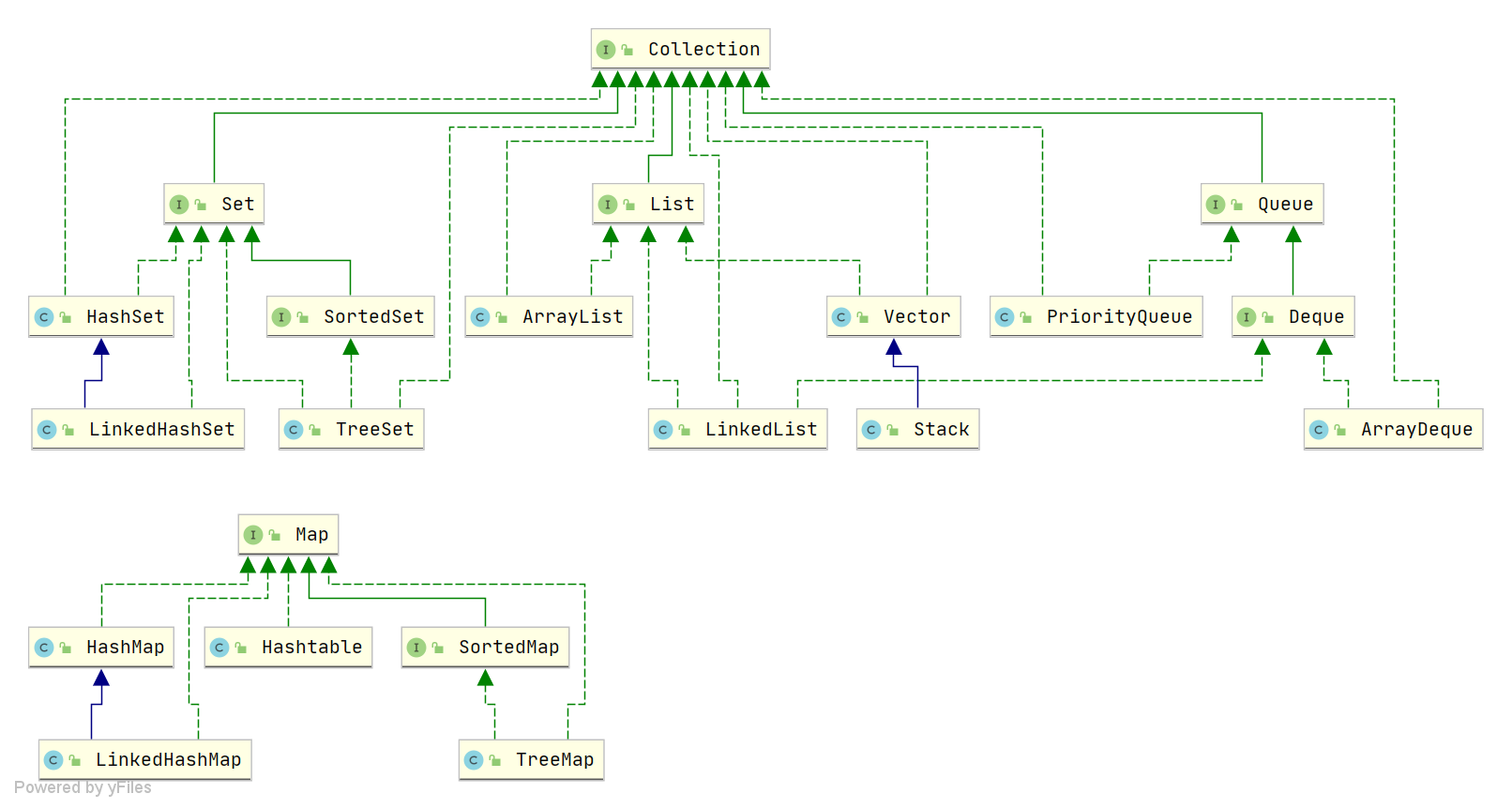
Java中HashMap底层原理深度解析:从数据结构到红黑树优化
一、HashMap概述与核心特性 HashMap作为Java集合框架中最常用的数据结构之一,是基于哈希表的Map接口非同步实现。它允许使用null键和null值(但只能有一个null键),并且不保证映射顺序的恒久不变。与Hashtable相比,Hash…...