[项目详解][boost搜索引擎#2] 建立index | 安装分词工具cppjieba | 实现倒排索引
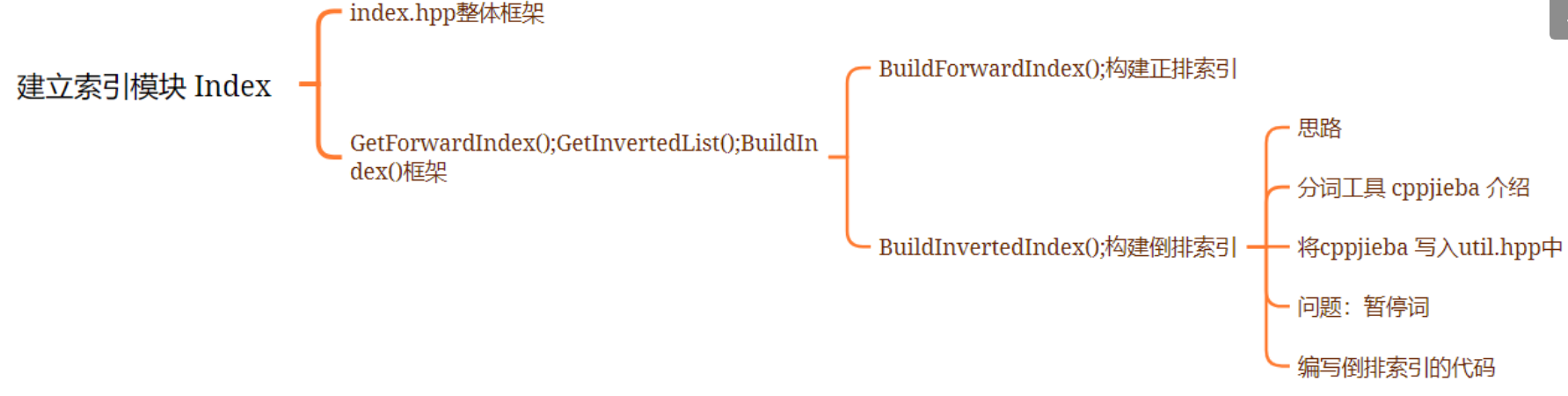
目录
编写建立索引的模块 Index
1. 设计节点
2.基本结构
3.(难点) 构建索引
1. 构建正排索引(BuildForwardIndex)
2.❗构建倒排索引
3.1 cppjieba分词工具的安装和使用
3.2 引入cppjieba到项目中
倒排索引代码
本篇文章,我们将继续项目的部分讲解,思路如下
在讲解 index 前,我们先 接着上篇文章 来看一下保存 html 文件
采用下面的方案:
- 写入文件中,一定要考虑下一次在读取的时候,也要方便操作!
- 类似:title\3 content\3url \n title\3content\3url \n title\3content\3url \n ...
- 方便我们getline(ifsream, line),直接获取文档的全部内容:title\3content\3url
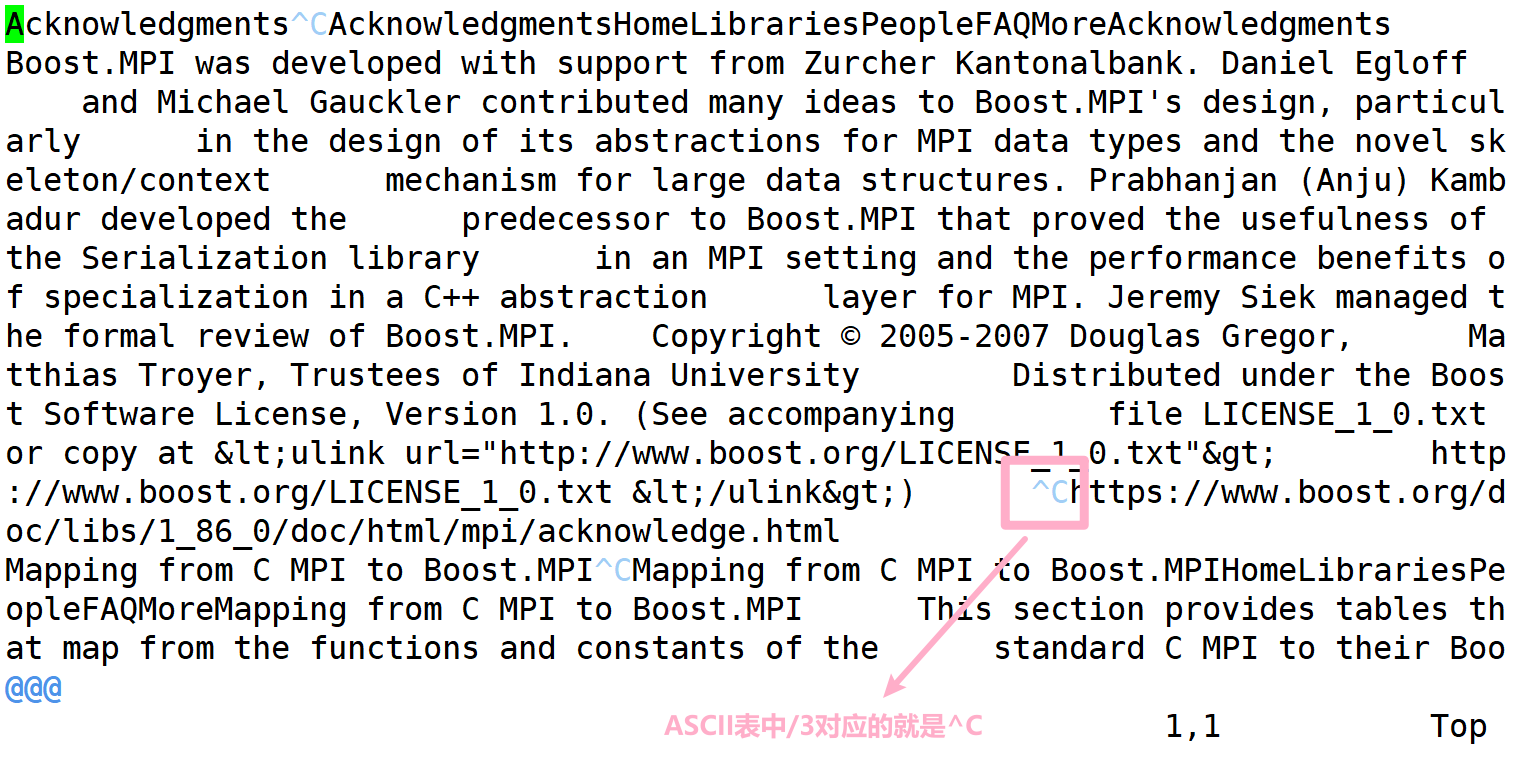
为什么使用‘\3’?
- \3 在ASSCII码表中是不可以显示的字符,我们将title、content、url用\3进行区分,不会污染我们的文档,当然你也可以使用\4等
bool SaveHtml(const std::vector<DocInfo_t> &results, const std::string &output)
{#define SEP '\3'//分割符---区分标题、内容和网址// 打开文件,在里面进行写入// 按照二进制的方式进行写入 -- 你写的是什么文档就保存什么std::ofstream out(output, std::ios::out | std::ios::binary);if(!out.is_open()){std::cerr << "open " << output << " failed!" << std::endl;return false;}// 到这里就可以进行文件内容的写入了for(auto &item : results){std::string out_string;out_string = item.title;//标题out_string += SEP;//分割符out_string += item.content;//内容out_string += SEP;//分割符out_string += item.url;//网址out_string += '\n';//换行,表示区分每一个文件// 将字符串内容写入文件中out.write(out_string.c_str(), out_string.size());}out.close();return true;
}- 接下来我们做一下测试:
/data/raw_html目录下的raw.txt就会填入所有的处理完的 html 文档。
尝试查看
至此,我们的parser(去标签+数据清)模块就完成了,为了大家能够更好的理解,下面是一张关系图:

编写建立索引的模块 Index
首先创建 一个 Index.hpp 文件,用来编写 索引模块
该文件主要负责三件事:① 构建索引 、② 正排索引 、③ 倒排索引
构建思路框图:

搜索引擎逻辑:
用户输入【关键字】搜索 → 【倒排索引】搜出 【倒排拉链】 → 倒排拉链中包含所有关键字有关的文档ID及其权重 → 【正派索引】文档ID,得到文档三元素 , 并按照权重排列呈现给用户
1. 设计节点
- 正排索引是构建倒排索引的基础
- 通过给到的关键字,去倒排索引里查找出文档ID,再根据文档ID,找到对应的文档内容
- 两个节点结构,一个是文档信息的节点,一个是倒排对应的节点;
namespace ns_index
{struct DocInfo //文档信息节点{std::string title; //文档的标题std::string content; //文档对应的去标签后的内容std::string url; //官网文档的urluint64_t doc_id; //文档的ID};struct InvertedElem //倒排对应的节点{uint64_t doc_id; //文档IDstd::string word; //关键字(通过关键字可以找到对应的ID)int weight; //权重---根据权重对文档进行排序展示};
}说明:
- 有 doc_id、word 和 weight;我们可以通过 word 关键字找到对应的文档ID
- 有文档的信息节点,通过倒排找到的文档ID,就能够在文档信息节点中找到对应的文档所有内容
- 这两个节点都有doc_id,就像MySQL中外键,相当于两张表产生了关联;
2.基本结构
索引模块最大的两个部分当然是构建正排索引和构建倒排索引,其主要接口如下:
#pragma once#include <iostream>
#include <string>
#include <vector>
#include <fstream>
#include <unordered_map>
#include <mutex>
#include "log.hpp"namespace ns_index
{struct DocInfo // 文档信息节点{std::string title; // 文档的标题std::string content; // 文档对应的去标签后的内容std::string url; // 官网文档的urluint64_t doc_id; // 文档的ID};struct InvertedElem // 倒排对应的节点{uint64_t doc_id; // 文档IDstd::string word; // 关键字(通过关键字可以找到对应的ID)int weight; // 权重---根据权重对文档进行排序展示};// 倒排拉链--一个关键字对应了一组文档typedef std::vector<InvertedElem> InvertedList;class Index{private:std::vector<DocInfo> forward_index; // 正排索引// 倒排索引std::unordered_map<std::string, InvertedList> inverted_index;public:Index() {}~Index() {}public:// 根据去标签,格式化后的文档,构建正排和倒排索引// 将数据源的路径:data/raw_html/raw.txt传给input即可,这个函数用来构建索引bool BuildIndex(const std::string &input){return true;}// 根据倒排索引的关键字word,获得倒排拉链InvertedList *GetInvertedList(const std::string &word){//...return nullptr;}// 根据doc_id找到正排索引对应doc_id的文档内容DocInfo *GetForwardIndex(uint64_t doc_id){//...return nullptr;}};
}- GetInvertedList函数:根据倒排索引的关键字word,获得倒排拉链(和上面类似)
- 返回第二个元素
//根据倒排索引的关键字word,获得倒排拉链
InvertedList* GetInvertedList(const std::string &word)
{// word关键字不是在 unordered_map 中,直接去里面找对应的倒排拉链即可auto iter = inverted_index.find(word);if(iter == inverted_index.end()) // 判断是否越界{std::cerr << " have no InvertedList" << std::endl;return nullptr;}// 返回 unordered_map 中的第二个元素--- 倒排拉链return &(iter->second);
}- GetForwardIndex函数:根据【正排索引】的 doc_id 找到文档内容
- 数组下标就是 doc_id
//根据doc_id找到正排索引对应doc_id的文档内容
DocInfo* GetForwardIndex(uint64_t doc_id)
{//如果这个doc_id已经大于正排索引的元素个数,则索引失败if(doc_id >= forward_index.size()){ std::cout << "doc_id out range, error!" << std::endl;return nullptr;}return &forward_index[doc_id];//否则返回相应doc_id的文档内容
}3.(难点) 构建索引
- 构建索引的思路正好和用户使用搜索功能的过程正好相反。
- 思路:一个一个文档正排遍历,为其每个构建先正排索引后构建倒排索引。

步骤:
- 先把处理干净的文档读取上来,是按行读取,这样就能读到每个html文档
- 按行读上来每个html文档后,我们就可以开始构建正排索引和倒排索引,此时就要提供两个函数,
- 分别为BuildForwardIndex(构建正排索引)和 BuildInvertedIndex(构建倒排索引)
基本代码如下:
//根据去标签,格式化后的文档,构建正排和倒排索引
//将数据源的路径:data/raw_html/raw.txt传给input即可,这个函数用来构建索引
bool BuildIndex(const std::string &input)
{//在上面SaveHtml函数中,我们是以二进制的方式进行保存的,那么读取的时候也要按照二进制的方式读取,读取失败给出提示std::ifstream in(input, std::ios::in | std::ios::binary);if(!in.is_open()){std::cerr << "sory, " << input << " open error" << std::endl;return false;}std::string line;int count = 0;while(std::getline(in, line)){DocInfo* doc = BuildForwardIndex(line);//构建正排索引if(nullptr == doc){std::cerr << "build " << line << " error" << std::endl;continue;}BuildInvertedIndex(*doc);//有了正排索引才能构建倒排索引count++; if(count % 50 == 0) { std::cout << "当前已经建立的索引文档:" << count << "个" << std::endl; }}return true;
}- vscode 下的搜索,ctrl+f
1. 构建正排索引(BuildForwardIndex)
- 在编写构建正排索引的代码前,我们要知道,在构建索引的函数中,我们是按行读取了每个html文件的(每个文件都是这种格式:title\3content\3url...)构建正排索引,就是将DocInfo结构体内的字段进行填充,
- 这里我们就需要给一个字符串切分的函数,我们写到util.hpp中,
- 这里我们又要引入一个新的方法——boost库当中的切分字符串函数split;
代码如下:
class StringUtil{public://切分字符串static void Splist(const std::string &target, std::vector<std::string> *out, const std::string &sep){//boost库中的split函数boost::split(*out, target, boost::is_any_of(sep), boost::token_compress_on);}
};boost::split(*out, target, boost::is_any_of(sep), boost::token_compress_on);
- 第一个参数:表示你要将切分的字符串放到哪里
- 第二个参数:表示你要切分的字符串
- 第三个参数:表示分割符是什么,不管是多个还是一个
- 第四个参数:它是默认可以不传,即切分的时候不压缩,不压缩就是保留空格
如:字符串为aaaa\3\3bbbb\3\3cccc\3\3d
- 如果不传第四个参数 结果为aaaa bbbb cccc d
- 如果传第四个参数为boost::token_compress_on 结果为aaaabbbbccccd
- 如果传第四个参数为boost::token_compress_off 结果为aaaa bbbb cccc d
构建正排索引的编写:
//构建正排索引
DocInfo* BuildForwardIndex(const std::string &line)
{// 1.解析line,字符串切分// 将line中的内容且分为3段:原始为title\3content\3url\3// 切分后:title content urlstd::vector<std::string> results;std::string sep = "\3"; //行内分隔符ns_util::StringUtil::Splist(line, &results, sep);//字符串切分 if(results.size() != 3) { return nullptr; } // 2.字符串进行填充到DocInfo DocInfo doc; doc.title = results[0]; doc.content = results[1]; doc.url = results[2]; doc.doc_id = forward_index.size(); //先进行保存id,在插入,对应的id就是当前doc在vector中的下标// 3.插入到正排索引的vector forward_index.push_back(std::move(doc)); //使用move可以减少拷贝带来的效率降低return &forward_index.back();
}2.❗构建倒排索引
原理图:

总的思路:
- 对 title 和 content 进行分词(使用cppjieba)
- 在分词的时候,必然会有某些词在 title 和 content 中出现过;我们这里还需要做一个处理,就是对每个词进行词频统计(你可想一下,你在搜索某个关键字的时候,为什么有些文档排在前面,而有些文档排在最后)这主要是词和文档的相关性
- 自定义相关性:我们有了词和文档的相关性的认识后,就要来自己设计这个相关性;我们把出现在title中的词,其权重更高,在content中,其权重低一些(如:让出现在title中的词的词频x10,出现在content中的词的词频x1,两者相加的结果称之为该词在整个文档中的权重)
- 根据这个权重,我们就可以对所有文档进行权重排序,进行展示,权重高的排在前面展示,权重低的排在后面展示
我们之前的基本结构代码:
//倒排拉链节点
struct InvertedElem{uint64_t doc_id; //文档的IDstd::string word; //关键词int weight; //权重
};//倒排拉链
typedef std::vector<InvertedElem> InvertedList;//倒排索引一定是一个关键字和一组(个)InvertedElem对应[关键字和倒排拉链的映射关系]
std::unordered_map<std::string, InvertedList> inverted_index;//文档信息节点
struct DocInfo{std::string title; //文档的标题std::string content; //文档对应的去标签之后的内容std::string url; //官网文档urluint64_t doc_id; //文档的ID
};- 需要对 title && content都要先分词 -- 使用jieba分词
- title: 吃/葡萄/吃葡萄(title_word)
content:吃/葡萄/不吐/葡萄皮(content_word)
- 词频统计 它是包含标题和内容的,我们就需要有一个结构体,来存储每一篇文档中每个词出现在title和content中的次数,伪代码如下:
//词频统计的结点
struct word_cnt
{int title_cnt; //词在标题中出现的次数int content_cnt;//词在内容中出现的次数
}- 统计这些次数之后
- 我们还需要将词频和关键词进行关联,文档中的每个词都要对应一个词频结构体,
- 这样我们通过关键字就能找到其对应的词频结构体,
- 通过这个结构体就能知道该关键字在文档中的title和content中分别出现了多少次,
- 下一步就可以进行权重的计算。
- 这里我们就可以使用数据结构unordered_map来进行存储。
伪代码如下:
//关键字和词频结构体的映射
std::unordered_map<std::string, word_cnt> word_map;
//关键字就能找到其对应的词频结构体
for(auto& word : title_word)
{// 一个关键词 对应 标题 中出现的次数word_map[word].title_cnt++; //吃(1)/葡萄(1)/吃葡萄(1)
}//范围for进行遍历,对content中的词进行词频统计
for(auto& word : content_word)
{// 一个关键词 对应 内容 中出现的次数word_map[word].content_cnt++; //吃(1)/葡萄(1)/不吐(1)/葡萄皮(1)
}- 自定义相关性
知道了在文档中,标题 和 内容 每个词出现的次数,接下来就需要我们自己来设计相关性了,伪代码如下:
//遍历刚才那个unordered_map<std::string, word_cnt> word_map;
for(auto& word : word_map)
{struct InvertedElem elem;//定义一个倒排拉链节点,然后填写相应的字段elem.doc_id = 123;elem.word = word.first; // word.first-> 关键字elem.weight = 10*word.second.title_cnt + word.second.content_cnt ;//权重计算// 将关键字 对应的 倒排拉链节点 保存到 对应的倒排拉链这个 数组中inverted_index[word.first].push_back(elem);//最后保存到倒排索引的数据结构中
}//倒排索引结构如下: 一个关键字 对应的 倒排拉链(一个或一组倒排节点)
//std::unordered_map<std::string, InvertedList> inverted_index;//倒排索引结构体 -- 一个倒排拉链节点
struct InvertedElem
{uint64_t doc_id; // 文档IDstd::string word; // 文档相关关键字int weight; // 文档权重
};//倒排拉链
typedef std::vector<InvertedElem> InvertedList;至此就是倒排索引比较完善的原理介绍和代码思路
3.1 cppjieba分词工具的安装和使用
获取链接:cppjieba 下载链接 里面有详细的教程
- 我们这里可以使用 git clone,如下
- git clone https://github.com/yanyiwu/cppjieba
- 查看 cppjieba 目录,里面包含如下:

这是别人的写好的一个开源项目,我们来测试一下~
要注意头文件的路径,我们先来修改一下头文件的路径,它本身是要使用cppjieba/Jieba.hpp的,我们看一下这个头文件的具体路径:
路径是:cppjieba/include/cppjieba/Jieba.hpp
我们发现
我们可以找到开源项目中的测试文件来进行 test
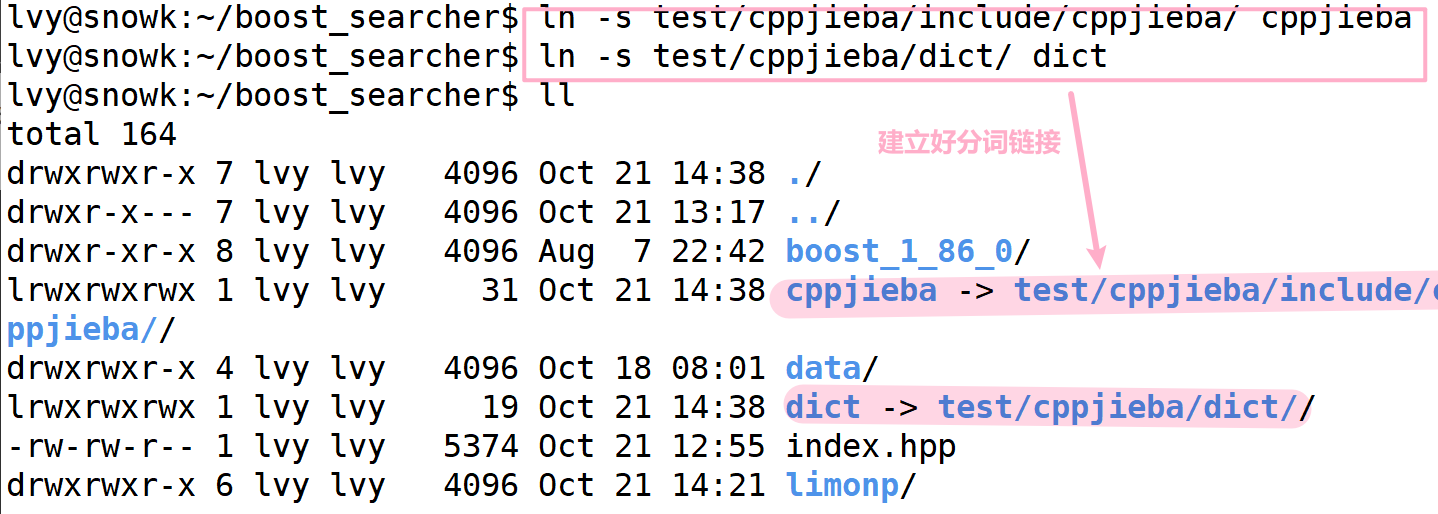
引入这个头文件,我们不能直接引入,需要使用软连接:
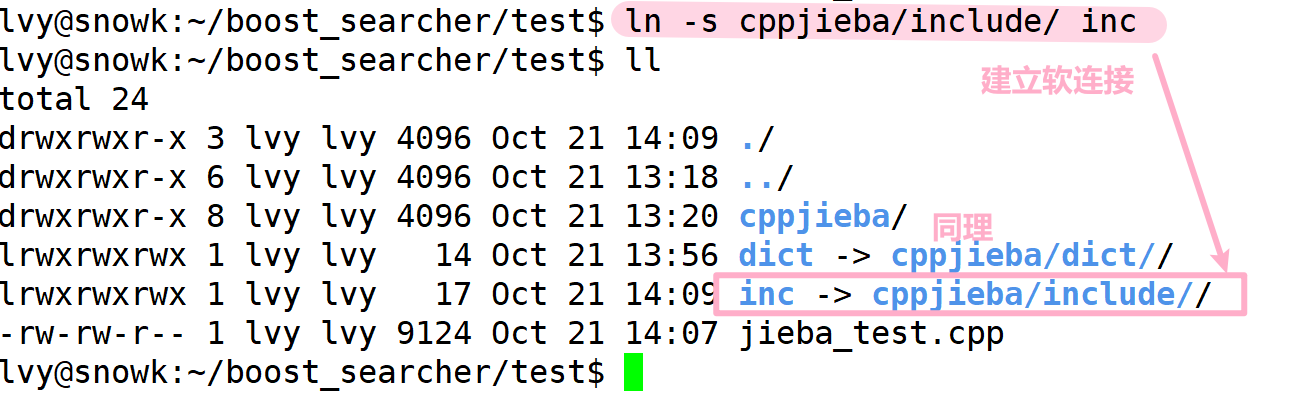
尝试编译后发现
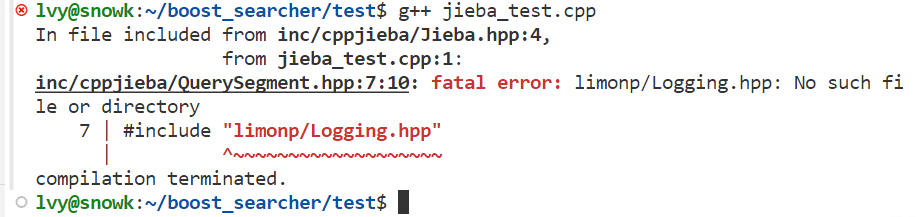
此时,我们还是需要对这个头文件进行软连接,我们通过查找,发现有这么一个路径:

但是里面什么东西都没有,这是我在联系项目中出现的问题,经过我去GitHub查找一番后,发现它在另外一个压缩包里:
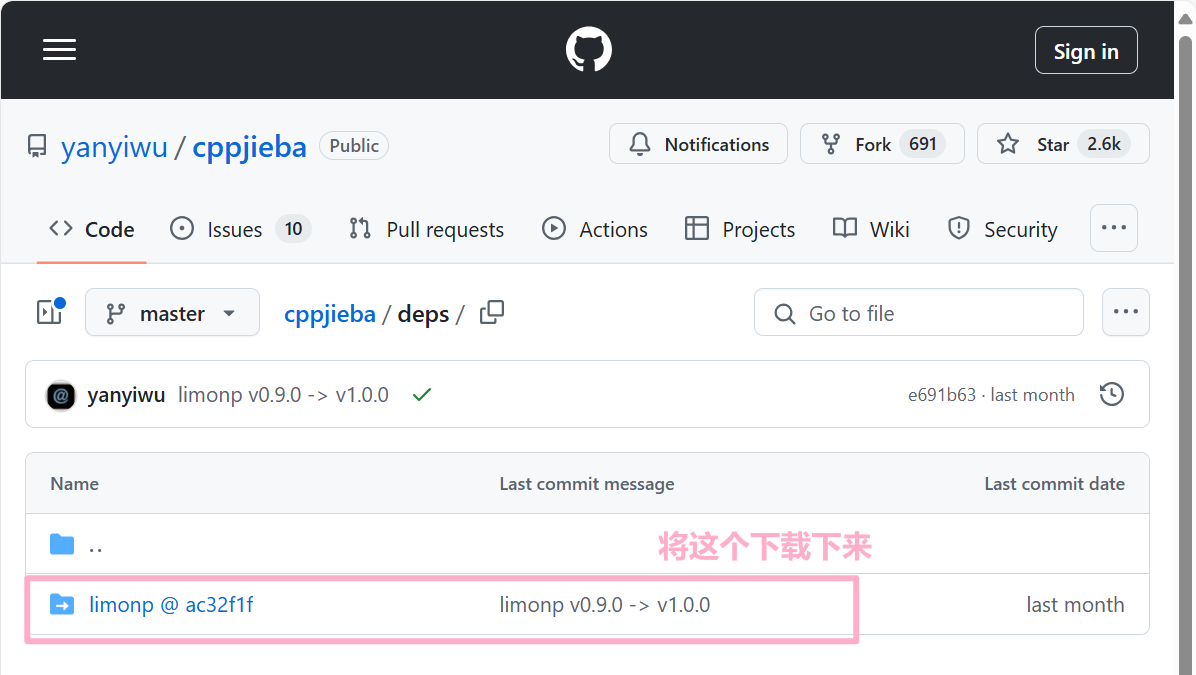
下载好如下:
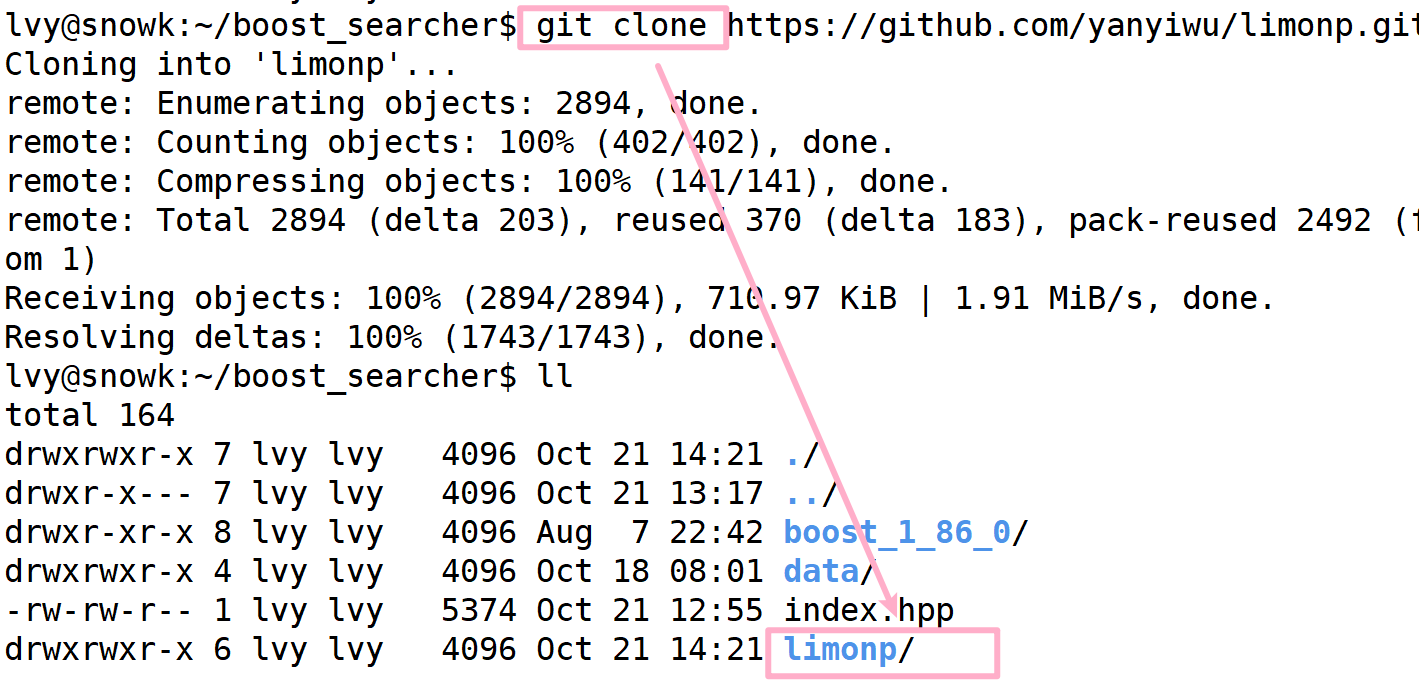
进入它里面,看是否有我们需要的内容
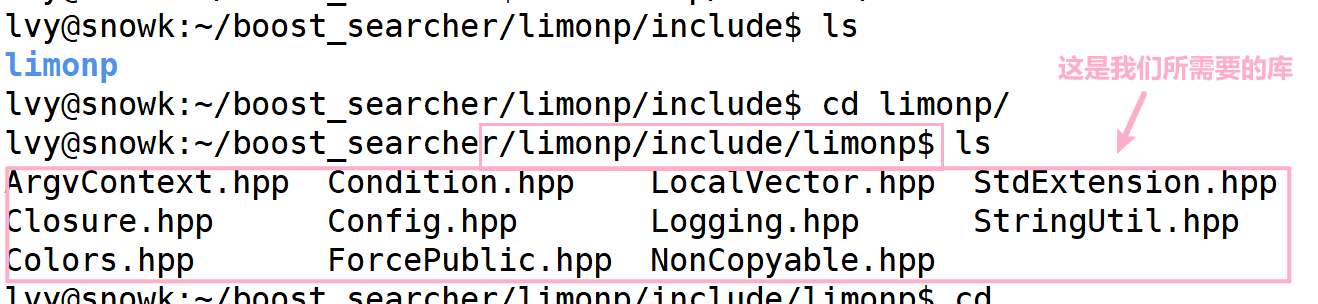
此时我们只需要将它 拷贝到 include/cppjieba/ 下即可
cp -r limonp/include/limonp/ test/cppjieba/include/cppjieba/我们将路径都完善之后,接下来,我们 选取局部测试代码 编译运行一下
int main(int argc, char** argv)
{cppjieba::Jieba jieba(DICT_PATH, HMM_PATH, USER_DICT_PATH, IDF_PATH, STOP_WORD_PATH); vector<string> words; // 接收切分的词string s;s = "小明硕士毕业于中国科学院计算所";cout << "原句:" << s << endl;jieba.CutForSearch(s, words);cout << "分词后:";for (auto& word : words){cout << word << " | ";}cout << endl;
}
熟悉完上面的操作后,就可以在我们的项目中引入头文件,来使用cppjieba分词工具啦~
3.2 引入cppjieba到项目中
将软链接建立好之后,我们在util.hpp中编写一个jieba分词的类,主要是为了方便后期其他地方需要使用的时候,可以直接调用。
首先我们先看一下之前的测试代码: 可以发现分词用到的 词库和函数
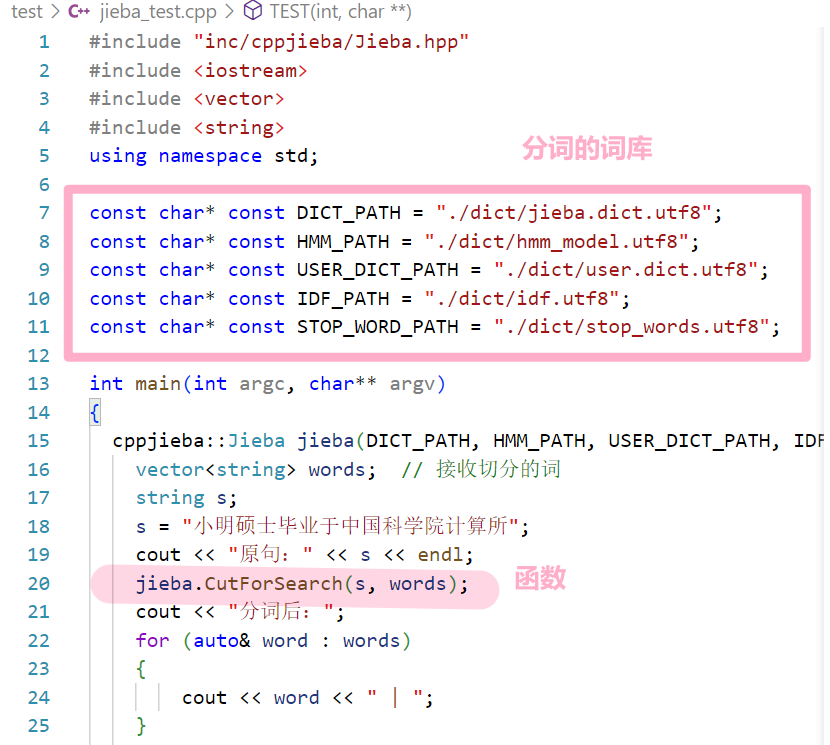
我们在util.hpp中创建一个 JiebaUtil的分词工具类,建立软连接
util.hpp代码如下:
#pragma once
#include <iostream>
#include <string>
#include <fstream>
#include <vector>#include <boost/algorithm/string.hpp>
#include "cppjieba/Jieba.hpp" namespace ns_util
{class FileUtil{ public://输入文件名,将文件内容读取到out中static bool ReadFile(const std::string &file_path, std::string *out){// 读取 file_path(一个.html文件) 中的内容 -- 打开文件std::ifstream in(file_path, std::ios::in);//文件打开失败检查if(!in.is_open()){std::cerr << "open file " << file_path << " error" << std::endl;return false;}//读取文件内容std::string line;//while(bool),getline的返回值istream会重载操作符bool,读到文件尾eofset被设置并返回false//如何理解getline读取到文件结束呢??getline的返回值是一个&,while(bool), 本质是因为重载了强制类型转化while(std::getline(in, line)) // 每循环一次,读取的是文件的一行内容{*out += line; // 将文件内容保存在 *out 里面}in.close(); // 关掉文件return true;}};class StringUtil{public://切分字符串static void Splist(const std::string &target, std::vector<std::string> *out, const std::string &sep){//boost库中的split函数boost::split(*out, target, boost::is_any_of(sep), boost::token_compress_on);}};//下面这5个是分词时所需要的词库路径const char* const DICT_PATH = "./dict/jieba.dict.utf8"; const char* const HMM_PATH = "./dict/hmm_model.utf8"; const char* const USER_DICT_PATH = "./dict/user.dict.utf8"; const char* const IDF_PATH = "./dict/idf.utf8"; const char* const STOP_WORD_PATH = "./dict/stop_words.utf8"; class JiebaUtil { private: static cppjieba::Jieba jieba; //定义静态的成员变量(需要在类外初始化) public: static void CutString(const std::string &src, std::vector<std::string> *out) { //调用CutForSearch函数,第一个参数就是你要对谁进行分词,第二个参数就是分词后的结果存放到哪里jieba.CutForSearch(src, *out); } };//类外初始化,就是将上面的路径传进去,具体和它的构造函数是相关的,具体可以去看一下源代码cppjieba::Jieba JiebaUtil::jieba(DICT_PATH, HMM_PATH, USER_DICT_PATH, IDF_PATH, STOP_WORD_PATH);
}倒排索引代码
构建倒排索引相对复杂一些,只要将上面倒排索引的原理和伪代码的思路;理解到位后,下面的代码就比较简单了。
//构建倒排索引
bool BuildInvertedIndex(const DocInfo &doc)
{ //词频统计结构体 struct word_cnt { int title_cnt; int content_cnt; word_cnt():title_cnt(0), content_cnt(0){} }; std::unordered_map<std::string, word_cnt> word_map; //用来暂存词频的映射表 //对标题进行分词 std::vector<std::string> title_words; ns_util::JiebaUtil::CutString(doc.title, &title_words); //对标题进行词频统计 for(auto s : title_words) { boost::to_lower(s); // 将我们的分词进行统一转化成为小写的 word_map[s].title_cnt++;//如果存在就获取,不存在就新建 } //对文档内容进行分词 std::vector<std::string> content_words; ns_util::JiebaUtil::CutString(doc.content, &content_words); //对文档内容进行词频统计 for(auto s : content_words) { boost::to_lower(s); // 将我们的分词进行统一转化成为小写的 word_map[s].content_cnt++; } #define X 10
#define Y 1 //最终构建倒排 for(auto &word_pair : word_map) { InvertedElem item; item.doc_id = doc.doc_id; //倒排索引的id即文档id item.word = word_pair.first; item.weight = X * word_pair.second.title_cnt + Y * word_pair.second.content_cnt; InvertedList& inverted_list = inverted_index[word_pair.first]; inverted_list.push_back(std::move(item)); } return true;
} 下篇文章将继续对项目进行讲解~
补充:
写项目突然想到一个有意思的点~

相关文章:
[项目详解][boost搜索引擎#2] 建立index | 安装分词工具cppjieba | 实现倒排索引
目录 编写建立索引的模块 Index 1. 设计节点 2.基本结构 3.(难点) 构建索引 1. 构建正排索引(BuildForwardIndex) 2.❗构建倒排索引 3.1 cppjieba分词工具的安装和使用 3.2 引入cppjieba到项目中 倒排索引代码 本篇文章,我们将继续项…...

R语言编程
一、R语言在机器学习中的优势 R语言是一种广泛用于统计分析和数据可视化的编程语言,在机器学习领域也有诸多优势。 丰富的包:R拥有大量专门用于机器学习的包。例如,caret包是一个功能强大的机器学习工具包,它提供了统一的接口来训练和评估多种机器学习模型,如线性回归、决…...

Mysql主主互备配置
在现有运行的mysql环境下,修改相关配置项,完成主主互备模式的部署。 下面的配置说明中设置的mysql互备对应服务器IP为: 192.168.1.6 192.168.1.7 先检查UUID 在mysql的数据目录下,检查主备mysql的uuid(如下的server-…...
)
如何预防数据打架?数据仓库如何保持指标数据一致性开发指南(持续更新)
大数据开发人员最经常遇到尴尬和麻烦的事是,指标开发好了,以为万事大吉了。被业务和运营发现这个指标在不同地方数据打架,显示不同的数值。为了保证指标数据一致性,要从整个开发流程做好。 目录 一、数据仓库架构规划 二、数据抽取与转换 三、数据存储管理 四、指标管…...

我谈Canny算子
在Canny算子的论文中,提出了好的边缘检测算子应满足三点:①检测错误率低——尽可能多地查找出图像中的实际边缘,边缘的误检率(将边缘识别为非边缘)低,且避免噪声产生虚假边缘(将非边缘识别为边缘…...

算法的学习笔记—平衡二叉树(牛客JZ79)
😀前言 在数据结构中,二叉树是一种重要的树形结构。平衡二叉树是一种特殊的二叉树,其特性是任何节点的左右子树高度差的绝对值不超过1。本文将介绍如何判断一棵给定的二叉树是否为平衡二叉树,重点关注算法的时间复杂度和空间复杂度…...

SSM学习day01 JS基础语法
一、JS基础语法 跟java有点像,但是不用注明数据类型 使用var去声明变量 特点1:var关键字声明变量,是为全局变量,作用域很大。在一个代码块中定义的变量,在其他代码块里也能使用 特点2:可以重复定义&#…...

kubeadm快速自动化部署k8s集群
目录 一、准备环境 二、安装docker--三台机器都操作 三、使用kubeadm部署Kubernetes 在所有节点安装kubeadm和kubelet、kubectl 配置启动kubelet(所有主机) master节点初始化 Mater重新完成初始化 执行Master初始化后的提示配置 配置使用网络插件 创建flannel网络 …...

解决JAVA使用@JsonProperty序列化出现字段重复问题(大写开头的字段重复序列化)
文章目录 引言I 解决方案方案1:使用JsonAutoDetect注解方案2:手动编写get方法,JsonProperty注解加到方法上。方案3:首字母改成小写的II 知识扩展:对象默认是怎样被序列化?引言 需求: JSON序列化时,使用@JsonProperty注解,将字段名序列化为首字母大写,兼容前端和第三方…...

分布式理论基础
文章目录 1、理论基础2、CAP定理1_一致性2_可用性3_分区容错性4_总结 3、BASE理论1_Basically Available(基本可用)2_Soft State(软状态)3_Eventually Consistent(最终一致性)4_总结 1、理论基础 在计算机…...
-- jacoco agent)
Java应用程序的测试覆盖率之设计与实现(二)-- jacoco agent
说在前面的话 要想获得测试覆盖率报告,第一步要做的是,采集覆盖率数据,并输入到tcp。 而本文便是介绍一种java应用程序部署下的推荐方式。 作为一种通用方案,首先不想对应用程序有所侵入,其次运维和管理方便。 正好,jacoco agent就是类似于pinpoint agent一样,都使用…...

【机器学习】13. 决策树
决策树的构造 策略:从上往下学习通过recursive divide-and-conquer process(递归分治过程) 首先选择最好的变量作为根节点,给每一个可能的变量值创造分支。然后将样本放进子集之中,从每个分支的节点拓展一个。最后&a…...
《a16z : 2024 年加密货币现状报告》解析
加密社 原文链接:State of Crypto 2024 - a16z crypto译者:AI翻译官,校对:翻译小组 当我们两年前第一次发布年度加密状态报告的时候,情况跟现在很不一样。那时候,加密货币还没成为政策制定者关心的大事。 比…...

Laravel 使用Simple QrCode 生成PNG遇到问题
最近因项目需求,需要对qrcode 进行一些简单修改,发现一些问题,顺便记录一下 目前最新的版本是4.2,在环境是 PHP8 ,laravel11 的版本默认下载基本是4.0以上的 如下列代码 QrCode::format(png)->generate(test);这样…...

一站式学习 Shell 脚本语法与编程技巧,踏出自动化的第一步
文章目录 1. 初识 Shell 解释器1.1 Shell 类型1.2 Shell 的父子关系 2. 编写第一个 Shell 脚本3. Shell 脚本语法3.1 脚本格式3.2 注释3.2.1 单行注释3.2.2 多行注释 3.3 Shell 变量3.3.1 系统预定义变量(环境变量)printenv 查看所有环境变量set 查看所有…...
批处理操作的优化
原来的代码 Override Transactional(rollbackFor Exception.class) public void batchAddQuestionsToBank(List<Long> questionIdList, Long questionBankId, User loginUser) {// 参数校验ThrowUtils.throwIf(CollUtil.isEmpty(questionIdList), ErrorCode.PARAMS_ERR…...

机器视觉运动控制一体机在DELTA并联机械手视觉上下料应用
市场应用背景 DELTA并联机械手是由三个相同的支链所组成,每个支链包含一个转动关节和一个移动关节,具有结构紧凑、占地面积小、高速高灵活性等特点,可在有限的空间内进行高效的作业,广泛应用于柔性上下料、包装、分拣、装配等需要…...

RHCE-web篇
一.web服务器 Web 服务器是一种软件或硬件系统,用于接收、处理和响应来自客户端(通常是浏览器)的 HTTP 请求。它的主要功能是存储和提供网站内容,比如 HTML 页面、图像、视频等。 Web 服务器的主要功能 处理请求…...

Java - 人工智能;SpringAI
一、人工智能(Artificial Intelligence,缩写为AI) 人工智能(Artificial Intelligence,缩写为AI)是一门新的技术科学,旨在开发、研究用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统…...
MFC开发,给对话框添加定时器
定时器简介 定时器的主要功能是设置以毫秒为单位的定时周期,然后进行连续定时或单次定时。 定时器是用于设置有规律的去触发某种动作所用的,这种场景也是软件中经常可以用到的,比如用户设置规定时间推送提示的功能,又比如程序定…...

基于服务器使用 apt 安装、配置 Nginx
🧾 一、查看可安装的 Nginx 版本 首先,你可以运行以下命令查看可用版本: apt-cache madison nginx-core输出示例: nginx-core | 1.18.0-6ubuntu14.6 | http://archive.ubuntu.com/ubuntu focal-updates/main amd64 Packages ng…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

Springcloud:Eureka 高可用集群搭建实战(服务注册与发现的底层原理与避坑指南)
引言:为什么 Eureka 依然是存量系统的核心? 尽管 Nacos 等新注册中心崛起,但金融、电力等保守行业仍有大量系统运行在 Eureka 上。理解其高可用设计与自我保护机制,是保障分布式系统稳定的必修课。本文将手把手带你搭建生产级 Eur…...

Rust 异步编程
Rust 异步编程 引言 Rust 是一种系统编程语言,以其高性能、安全性以及零成本抽象而著称。在多核处理器成为主流的今天,异步编程成为了一种提高应用性能、优化资源利用的有效手段。本文将深入探讨 Rust 异步编程的核心概念、常用库以及最佳实践。 异步编程基础 什么是异步…...

Java 二维码
Java 二维码 **技术:**谷歌 ZXing 实现 首先添加依赖 <!-- 二维码依赖 --><dependency><groupId>com.google.zxing</groupId><artifactId>core</artifactId><version>3.5.1</version></dependency><de…...

LeetCode - 199. 二叉树的右视图
题目 199. 二叉树的右视图 - 力扣(LeetCode) 思路 右视图是指从树的右侧看,对于每一层,只能看到该层最右边的节点。实现思路是: 使用深度优先搜索(DFS)按照"根-右-左"的顺序遍历树记录每个节点的深度对于…...

JS手写代码篇----使用Promise封装AJAX请求
15、使用Promise封装AJAX请求 promise就有reject和resolve了,就不必写成功和失败的回调函数了 const BASEURL ./手写ajax/test.jsonfunction promiseAjax() {return new Promise((resolve, reject) > {const xhr new XMLHttpRequest();xhr.open("get&quo…...

Razor编程中@Html的方法使用大全
文章目录 1. 基础HTML辅助方法1.1 Html.ActionLink()1.2 Html.RouteLink()1.3 Html.Display() / Html.DisplayFor()1.4 Html.Editor() / Html.EditorFor()1.5 Html.Label() / Html.LabelFor()1.6 Html.TextBox() / Html.TextBoxFor() 2. 表单相关辅助方法2.1 Html.BeginForm() …...
Golang——7、包与接口详解
包与接口详解 1、Golang包详解1.1、Golang中包的定义和介绍1.2、Golang包管理工具go mod1.3、Golang中自定义包1.4、Golang中使用第三包1.5、init函数 2、接口详解2.1、接口的定义2.2、空接口2.3、类型断言2.4、结构体值接收者和指针接收者实现接口的区别2.5、一个结构体实现多…...