ClickHouse在百度MEG数据中台的落地和优化
导读
百度MEG上一代大数据产品存在平台分散、质量不均和易用性差等问题,导致开发效率低下、学习成本高,业务需求响应迟缓。为了解决这些问题,百度MEG内部开发了图灵3.0生态系统,包括Turing Data Engine(TDE)计算引擎、Turing Data Studio(TDS)数据开发治理平台和Turing Data Analysis(TDA)可视化BI产品。依托图灵3.0生态,我们进而形成了一套新的开发范式——“OneData+开发范式”,其关键在于可视化分析与数据集的构建。
TDE-ClickHouse作为图灵3.0生态中重要的基础引擎之一,专注于为业务提供海量数据下的自助秒级分析能力。通过高性能的数据查询能力与高效的数据导入通路,支持业务更及时、敏捷地对海量数据进行分析;通过稳定可靠的分布式架构,在减少资源和运维成本的同时,严控引擎侧的数据质量。
01 百度MEG数据中台解决方案
1.1 背景与问题
上一期的Geek说我们分享了图灵3.0中的数据开发治理平台TDS(Turing Data Studio),这一期我们分享图灵3.0生态中的一个重要的基础引擎TDE-ClickHouse。首先我们再回顾一下图灵3.0生态的发展背景:
百度MEG上一代大数据产品存在平台多、质量参差不齐和易用性差的问题。这些问题导致开发人员面临较高的研发依赖、开发效率低下和高昂的学习成本;业务部门则感知需求支持迟缓、数据产出延迟及数据质量低的问题。
1.2 图灵3.0生态概述
为解决上述问题,我们构建了新一代大数据解决方案——“图灵3.0”,旨在覆盖数据全生命周期,支持全链路数据操作,提供高效敏捷且统一的强大数据生态系统,其中包括数据计算引擎、数据开发和数据分析三个核心部分:
(1)TDE(Turing Data Engine):图灵生态的计算引擎,包括ClickHouse和Spark;
(2)TDS(Turing Data Studio):一站式数据开发治理平台;
(3)TDA(Turing Data Analysis):新一代可视化BI分析产品。
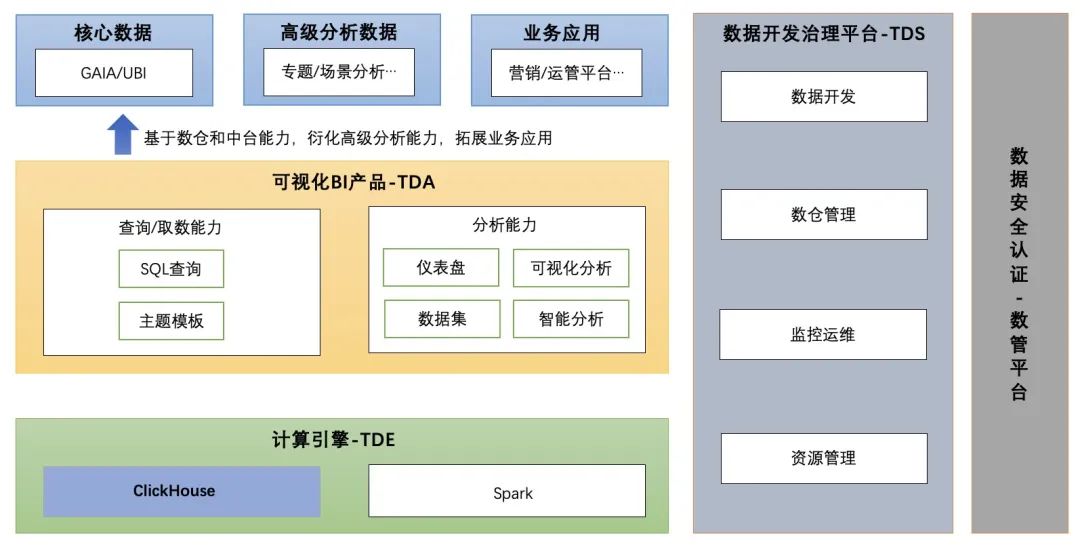
△图灵3.0生态产品
TDA以可视化分析为主的产品形态,要求底层引擎需要具备秒级响应的能力。CH凭借列式存储、数据压缩、向量化执行等特性,以及对硬件资源的极致使用,在查询性能方面表现出众。因此在可视化分析场景我们选用CH作为核心计算引擎,对于超大数据量的查询及ETL加工场景则通过Spark支持。
1.3 OneDate+开发范式
依托图灵3.0生态产品体系,我们进而形成了一套新的开发范式——“OneData+ 开发范式”,其中关键在于可视化分析与数据集的构建,为业务提供海量数据下的自助秒级分析能力。
传统的分层数仓建模方法将数据分为4层,包括ODS(Operational Data Store)、DWD(Data Warehouse Detail)、DWS(Data Warehouse Summary)和ADS(Application Data Store)。在这种建模方法中,数据开发侧作为需求的被动承接方,根据业务侧提出的数据需求进行数据开发与交付,存在需求交付周期长、人力成本高等问题。
OneData+开发范式引入"数据集"的概念,其中数据开发侧根据具化的业务主题与领域知识主动建立对应数据集,并支持数据集的后续迭代,业务侧则基于数据集进行交互式的自助拖拽分析,极大的提升了数据开发效率,降低了数据运维成本。
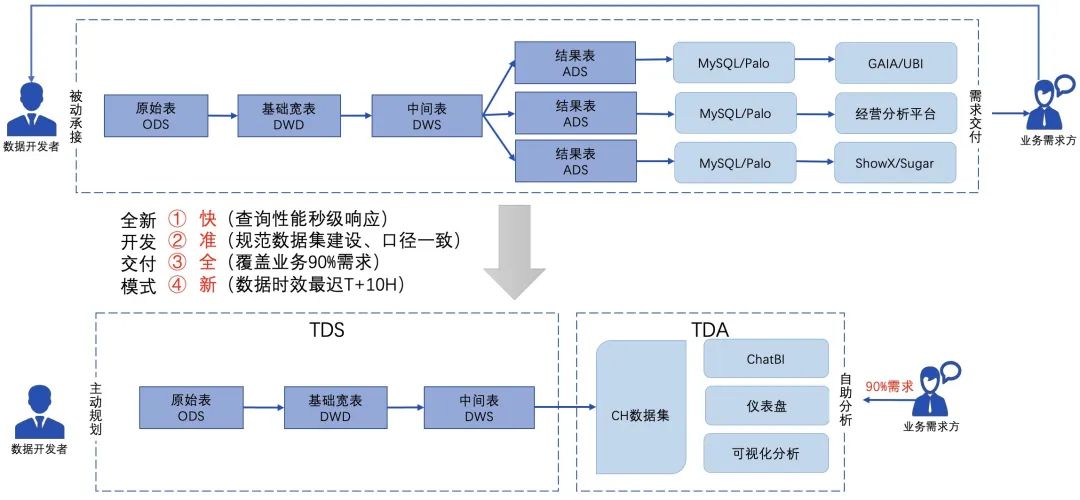
△OneData+开发范式
1.4 ClikHouse的挑战
在OneData+开发范式中,数据开发侧与业务侧的依赖关系从之前的"需求-交付"解耦为以数据集为中心的建设。在实践中,大部分数据集同之前DWS层的表类似,会结合业务场景建设得更加成体系,保证数据需求尽量不重不漏。ADS层则彻底消失,无需数据RD单独开发。这种情况下DWS层数据相对于ADS层数据膨胀了好几个数量级,但是要求查询性能不明显低于之前直接查询ADS层数据,这样就对CH的查询性能提出了极高的要求。
百度MEG业务实践过程中,对CH的要求是:保证百亿级的数据分析请求能秒级响应。因此,为了提升CH的查询性能,我们做了大量的优化工作。
此外,随着CH在内部的大规模使用,在数据导入和分布式架构方面也暴露出一些不足之处,比如:
(1)大规模数据导入难以保证导入任务的稳定性以及时效性,甚至产生级联的资源抢占问题;
(2)CH分布式架构存在运维成本高等问题,并且缺乏集群层面的事务支持等高级功能。
这篇文章将从查询性能、数据导入和分布式架构三个方面介绍我们对CH所做的优化工作。
02 ClickHouse查询性能优化
2.1 计算机分层解耦,聚合层硬件加速
原生CH架构主要采用单层同质的分布式架构,集群中所有数据节点的资源配置相同,数据按照分片划分并做副本冗余,存储在各个节点的本地磁盘中。
查询客户端会随机选择一个数据节点作为协调者节点,并发起查询请求。相比其他数据节点,协调者节点除了本地子查询的计算外,协调者节点额外负责:
(1)初始查询拆解成子查询后下发;
(2)合并各个子查询的结果后返回。
协调者节点需要额外的网络IO来获取其他节点的结果,以及更多的CPU来合并结果。在大数据量和复杂查询场景下,网络IO和合并结果会占用大部分时间。因此在理想状态下,协调者节点需要更高的CPU和网络配置,但在CH原生的单层同质架构下,让所有节点都具备高规格资源配置会导致成本明显上涨并出现资源浪费。
因此我们将协调者额外的职责抽离出来,独立成一层"聚合层”。聚合层节点拥有更高的CPU、内存和网络吞吐能力,其本身不存储数据。所有客户端查询都会先路由到聚合层,再由聚合层作为协调者与CH集群的数据节点交互。同时聚合层的存在让跨物理CH集群的查询(比如跨集群 Join)变为可能。
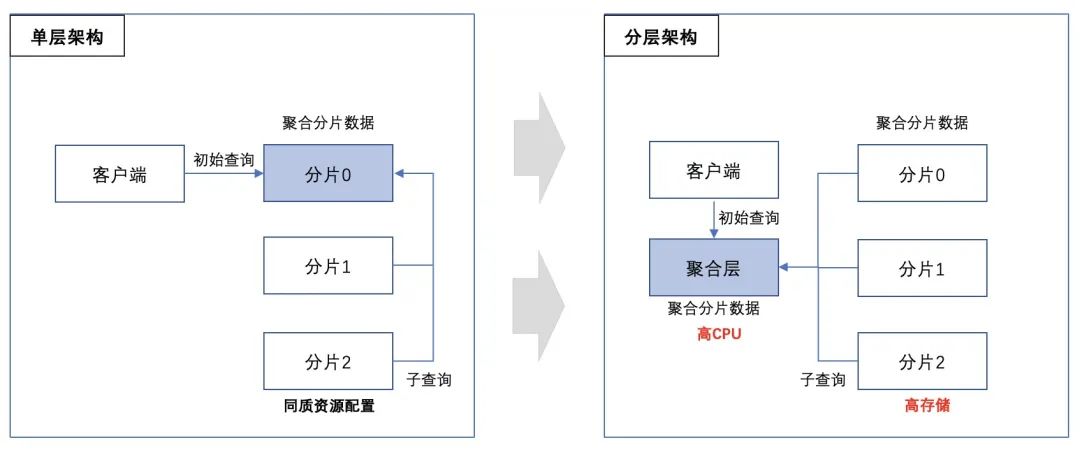
△计算分层解耦
2.2 数据多级聚合
数据开发侧首先基于OneData+开发范式在数据建模层面进行数据聚合,基于大宽表(事实表 + 维度表),并结合业务主题抽取出相应的维度聚合表作为CH数据集。为满足业务侧的拖拽式分析,CH数据集多为细粒度主题宽表(单表百+字段,单天数亿行数据)。
而在实际查询场景中,由于大部分查询请求都是报表类型的查询(单次查询涉及平均个位数字段,返回结果集数百行数据),因此需要在保证查询灵活性的同时,不能影响报表类查询的性能,此时需要在CH计算引擎层面进行透明的数据聚合。
计算引擎层我们实现了两层数据预聚合:
(1)引入聚合表:基于Projection实现对查询中间状态的预聚合,避免对原始明细数据的大量磁盘扫描;
(2)缓存查询结果:将最终查询结果缓存在外部内存,缩短查询链路,并避免重复查询带来的多余磁盘IO。
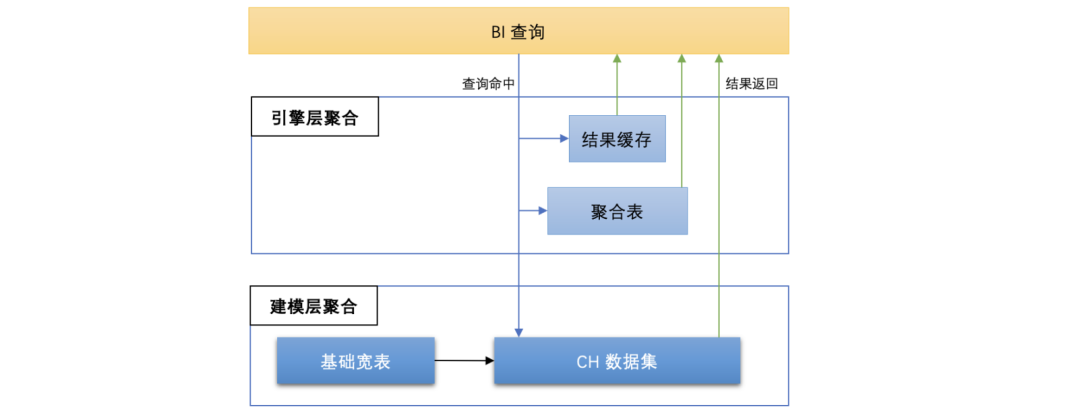
△数据多级聚合
2.2.1自动Projection
经过对各类聚合表的选型对比,我们最终选择Projection,因为和传统聚合表相比,Projection有两点优势:
(1)Projection与底表数据强一致: 如果Projection中有数据缺失,查询会自动透传到底表;
(2)对客户端完全透明:无需修改业务SQL,引擎会自动判断是否命中Projection。
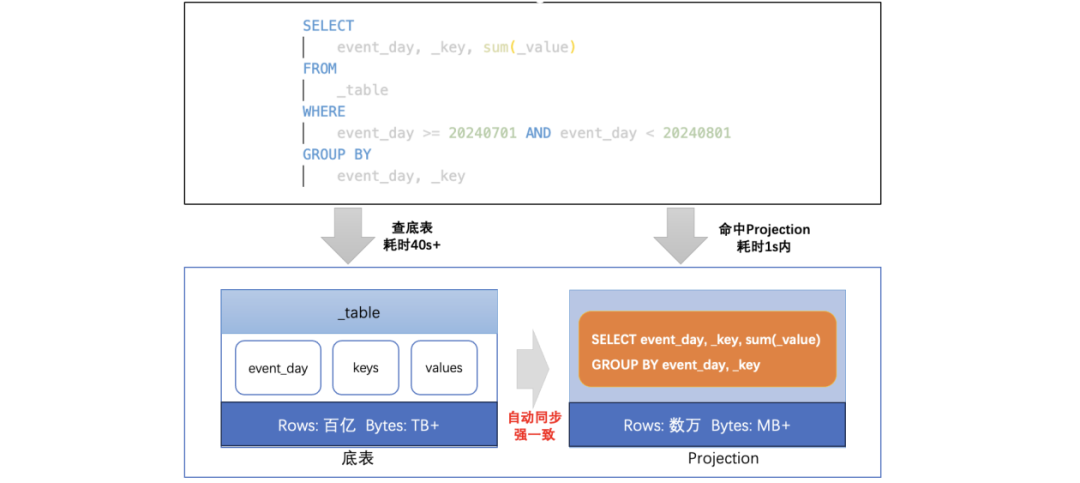
△ClickHouse Projection
同时我们与下游BI平台打通,针对BI平台中的高频查询自动创建Projection,并对Projection进行全生命周期自动化管理,具体包括:
- Projection识别
-
解析查询SQL,识别其中的查询字段(包括维度与指标字段)与计算函数;
-
基于成本评估聚合效果,过滤低效的Projection,并结合其他拦截策略(比如集群负载等)做服务降级;
-
生成待创建的Projection语句。
- Projection生命周期管理
-
Projection创建主要基于生成的Projection语句并在CH集群创建;
-
Projection删除主要关注命中率较低的Projection的挖掘以及回收;
-
Projection物化主要关注数据上卷在历史存量数据中生效。
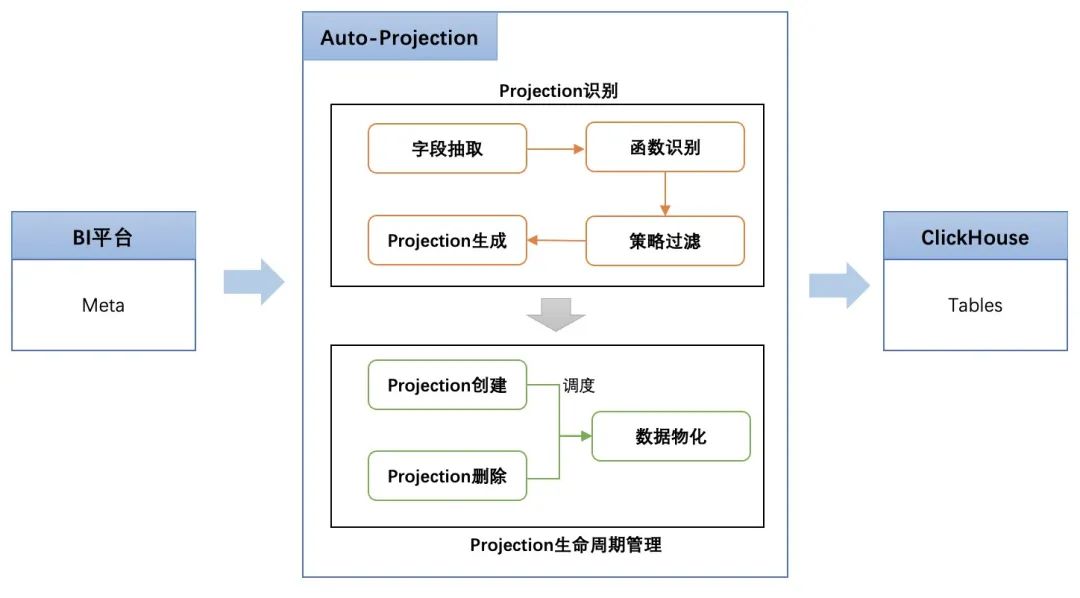
△自动Projection建设
2.2.2 查询结果Cache
对于查询结果的缓存,原生CH的QueryCache存在如下问题:
(1)单机Cache,多个“聚合层”实例的Cache无法共享;
(2)只有基于时间的过期机制,无一致性保证,底层数据更新后可能查到错误数据。
因此我们在CH的查询入口层(CHProxy)添加了QueryCache机制,通过缓存最终查询结果以缩短查询链路,并保证了查询结果的全局可见性;同时在数据导入过程中引入版本机制,版本变更时触发存量Cache的自动失效,以保证结果缓存与底层数据的一致性。上线后各个CH集群查询平响最多下降50%。
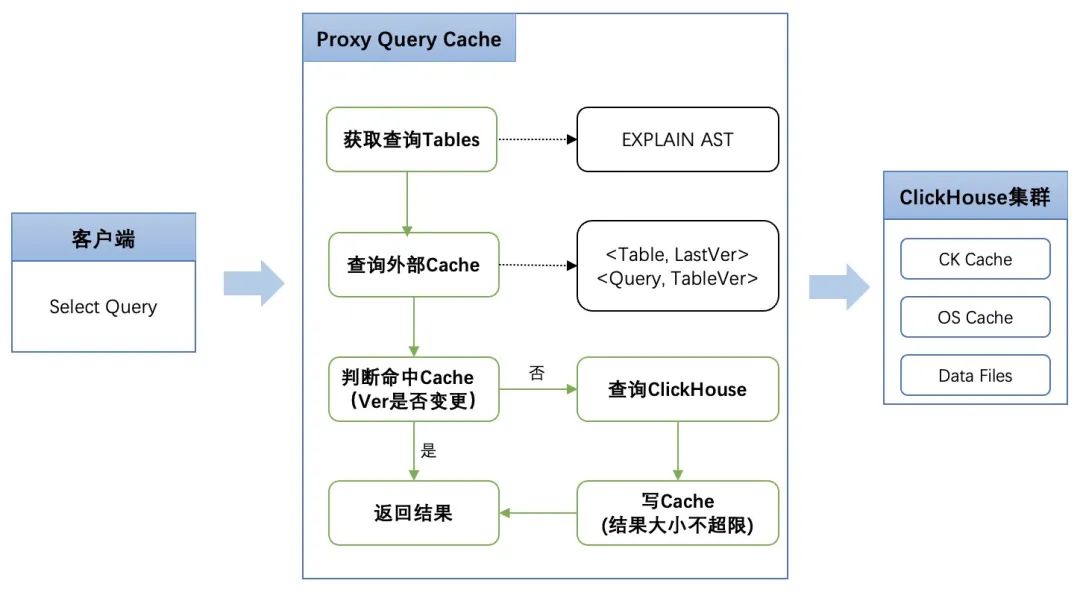
△Proxy QueryCache建设
2.3 高基数精准UV查询
基于以上一系列的通用性查询性能优化后,虽然查询平响得到较好的优化,但是P90、P99指标改善却不明显。为此我们对CH集群的查询SQL进行挖掘与分析,发现大部分长尾SQL来自高基数的精准UV查询,SQL查询格式如下:
SELECT keys, COUNT(DISTINCT cuid) FROM xxx GROUP BY keys该类查询的特点是底表数据量大、字段基数高,为了对结果去重,需要维护高成本的HashSet。业界常见的解决思路包括:
(1)近似算法,如HyperLogLog预估基数,存在1%左右的误差,大多数业务无法接受;
(2)在数据入库前预聚合,但由于UV的不可加和特性,在动态维度场景下不满足需求。
对查询耗时进行拆解分析,发现由于数据随机分布在各个分片上,需要在聚合层进行二次去重才能得到正确结果,聚合层成为计算热点。在整个查询过程中,子查询结果的网络传输和聚合层的二次去重耗时占到整个查询耗时的90+%。
基于以上问题,为了在不影响查询结果准确性的前提下降低聚合层的计算负载,我们进行了两阶段的优化:
(1)NoMerge查询:在数据入库时根据cuid预划分数据,查询时将聚合层的去重计算下推到各个CH分片,聚合层只需要执行轻量级的NoMerge计算;
(2)Projection+RoaringBitMap:使用Projection优化磁盘扫描数据量;使用BitMap优化Set计算,进一步减少中间状态大小。
2.3.1 NoMerge查询
第一阶段我们基于数据预划分,引入了NoMerge查询的优化方案:
(1)在数据入库时,对数据进行预划分,保证相同cuid的数据落在同一个分片上,实现数据正交;
(2)改写CH原生的COUNT(DISTINCT)实现逻辑:分片节点不再返回去重后的结果集,而是只上报子结果集的大小;
(3)聚合层只需要对子查询返回的结果集大小求和,即可得到最终的UV值。
通过这种方法,在高基数去重计数的查询场景下,可以获得5-10倍的性能收益。
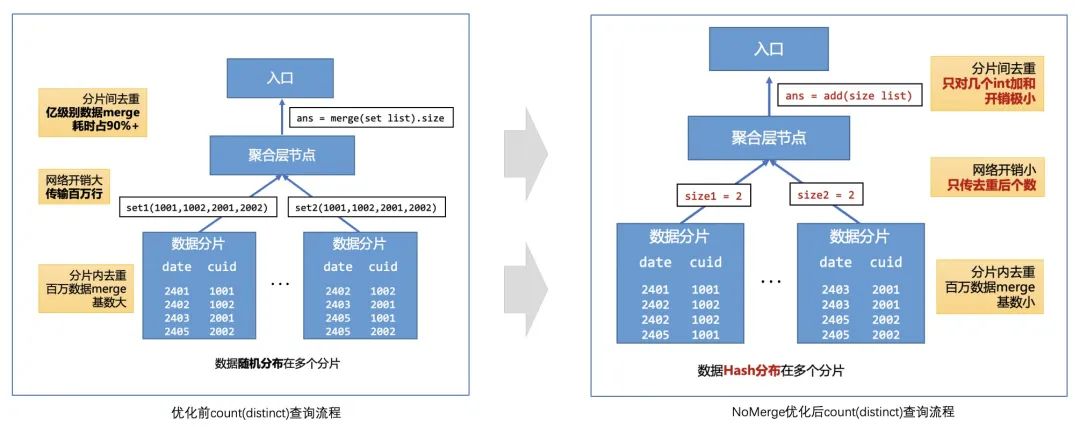
△NoMerge优化COUNT(DISTINCT)
2.3.2 Projection+RoaringBitMap
第二阶段我们尝试用Projection结合RoaringBitMap进一步优化UV查询的性能。传统UV计算通过HashSet保存中间状态,而在高基数场景下,由于数据压缩比效果较差,预计算带来的收益不明显,因此我们引入RoaringBitmap数据结构替换Hashset,减少中间状态大小,提升数据的压缩与传输效果。
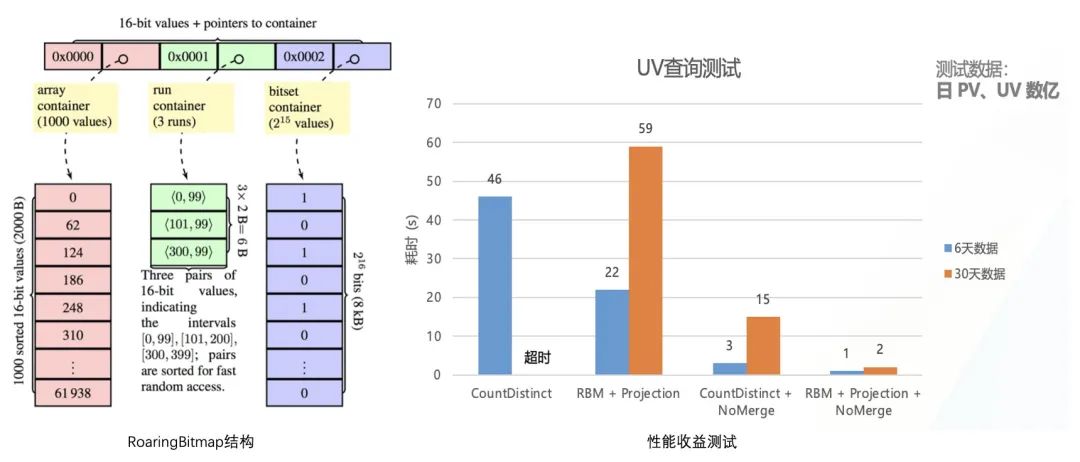
△RBM优化COUNT(DISTINCT)
2.4 RBO优化
参考对UV查询的性能优化,我们继续推进对特定类型查询的优化,以降低对应类型复杂查询的耗时。由于下游BI平台对常用的查询SQL按模板进行封装,并提供给用户直接拖拽使用,因此大量查询SQL具备相同的范式。对这些相同类型的查询SQL进行性能分析并采取针对性优化,可以以少量成本换取较大的查询性能收益,其中RBO (基于规则的优化器) 是一种比较合适的优化选择,下面以Case-When查询优化为例进行说明。
Case-When查询具体包含如下几类形式:
# case 1,等价于 col_a = 'A'
CASE WHEN col_a = 'A' THEN 'X' WHEN col_a IN ('B', 'C') THEN 'Y' ELSE 'Z'
END IN ('X')# case 2,等价于 col_b = 'A'
CASE col_b WHEN 'A' THEN 'X' WHEN 'B' THEN 'Y' ELSE 'Z' END
IN ('X')# case3,等价于 col_c = 'A'
IF(col_c = 'A', 'X', 'Y') = 'X'完整的Case-When查询示例如下:
SELECT _key, _value
FROM_table
WHERE CASE WHEN col_a = 'A' THEN 'X' WHEN col_a IN ('B', 'C') THEN 'Y' ELSE 'Z' END IN ('X')该Case-When查询可能存在如下问题:1)无法命中索引;2)存在冗余计算。我们对此使用RBO规则对Case-When查询进行改写优化,AST改写过程可以参考下图。上线后命中规则的SQL查询耗时降低20% - 40%。
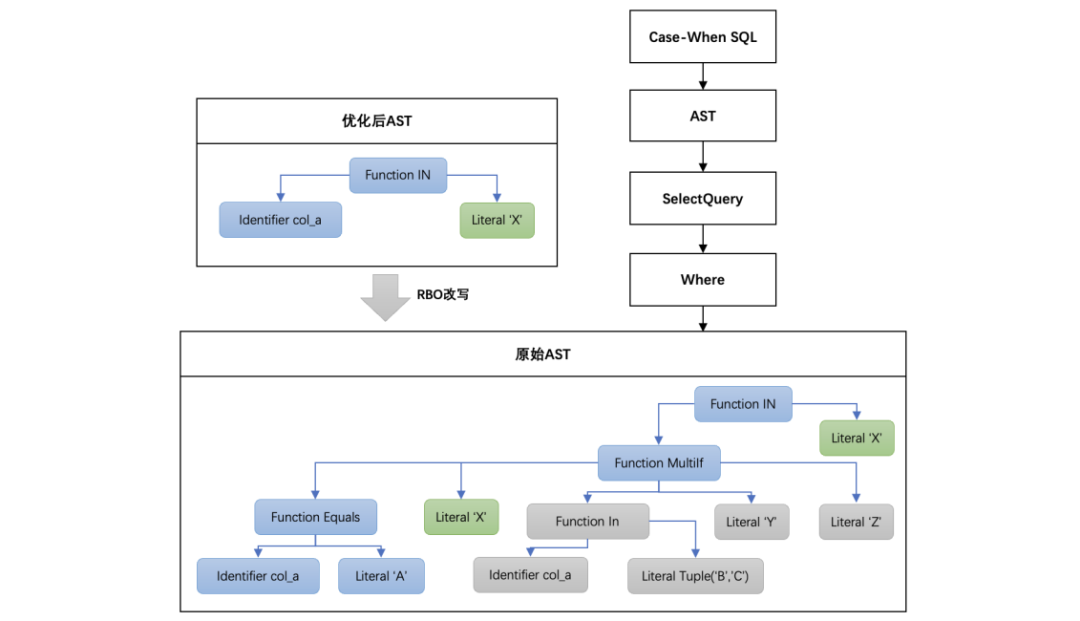
△Case-When查询流程改写
03 ClickHouse数据导入优化
除查询性能外,数据导入也是衡量数仓引擎性能以及易用性的关键标准之一,高效快捷的数据导入可以很大程度提升业务的数据开发与分析效率。
MEG数据中台的导入场景以周期性离线导入为主,大部分数据为天级例行导入。我们前期主要使用原生CH的Min-Batch数据Insert实现数据导入,但是随着业务的覆盖以及接入数据量的增大,该导入方式暴露出以下问题:
(1)入口节点热点:类似于原生查询,原生导入首先会在集群内选择一个入口节点写数,然后入口节点根据策略将数据分发到其他分片,导入速度可能受限于入口节点的带宽;
(2)写放大:CH底层数据采用LSM-Tree组织,原生导入首先在CH本地内存组织数据,积累到一定量后以Part文件形式落盘,CH会定期对磁盘上的多个Part进行合并,Part合并会带来额外的写开销。
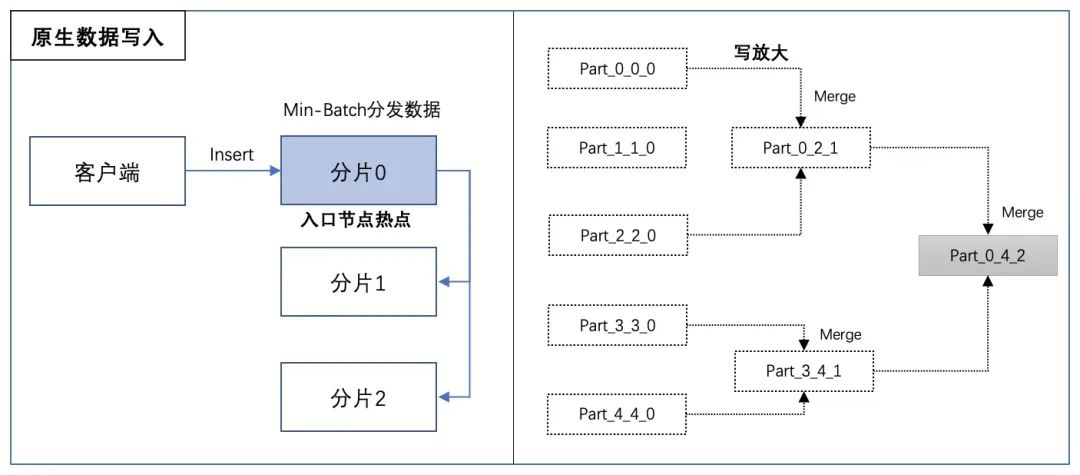
△原生数据写入
基于以上描述可以看出CH Min-Batch Insert在离线导入的背景下对业务的意义不大,反而额外的数据合并会抢占一定的机器资源,影响业务查询的稳定性。因此我们建设了一套BulkLoad的导入机制,尽量保证"读写分离",避免读写间的资源抢占。
BulkLoad导入整体分为两个阶段:
(1)数据构建:离线任务从数据源摄取数据,构建为CH内部数据结构,而后将多个 Part合并为一个Part,最后将数据打包推送到分布式文件存储(后称AFS);
(2)数据配送:通过两阶段提交的方式对构建好的数据进行校验,并按路由规则配送到CH对应节点。
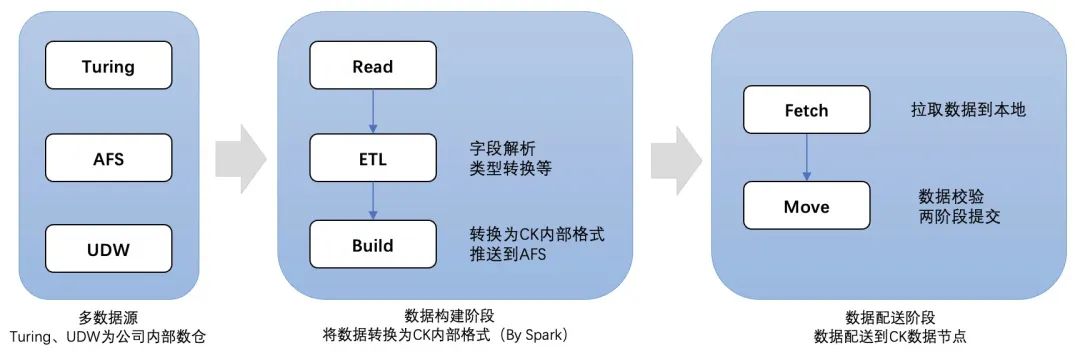
△数据BulkLoad写入
BulkLoad导入在大规模数据导入的场景下表现出良好的吞吐,百亿行级数据导入耗时小于两小时。此外采用预计算的方式剥离数据导入需要的资源,可以更好保证稳定的查询性能。最后,我们将构建得到的数据同时作为CH的冷备数据,提升整体容灾能力。
此外,针对增长、反作弊等数据实时性要求较高的业务场景,我们还提供了不重不丢、秒级延迟的流式导入,目前线上单流最高导入并发超过百万QPS。同时针对部分小数据量的临时分析场景,为复用CH的查询能力,我们打通了CH与AFS数据的即时查询通路。
04 ClickHouse分布式架构升级
4.1 云原生化
MEG数据中台前期主要基于物理机搭建CH集群,随着接入业务的增多以及数据规模的持续增加,集群扩容与运维效率明显满足不了规模的增长速度,具体体现如下:
(1)弹性化部署效率低:需要人工维护CH集群拓扑,比如人工配置集群拓扑以满足分片反亲和;
(2)大规模部署运维成本高:物理机需要自运维,并且集群扩缩容需要人工同步业务表结构。
为提升CH集群部署效率以及降低集群运维成本,我们将CH集群进行云原生化改造。与一般的无状态服务(如 Web Server 等)不同CH作为有状态数据库服务,云原生化改造需要解决以下问题:
(1)为追求CH极致性能,CH数据存放在本地磁盘,需要保证容器重建后本地数据不丢;
(2)公司内部PaaS平台不支持Kubernetes(后称K8s)Service,需要使用其他服务发现方式, 并维护集群拓扑关系;
(3)保证分片可用性和反亲和部署。
Operator in K8s是一个可以简化应用配置、管理和监控的K8s扩展方法,CH也发起开源项目 ClickHouse-Operator,用于在K8s上部署和管理CH。结合公司内现有的PaaS平台:Pandora、Opera、EKS等,综合考虑接入成本、服务完整性、成熟度等因素,最终选择基于ClickHouse-Operator实现CH集群部署在EKS。
主要实施路径为:
首先在EKS集群中声明CH的CRD(CustomResourceDefinition)资源,然后将Operator部署到EKS集群中。当有CH集群创建、扩/缩容、修改CH配置需求时,通过Operator调和能力(reconcile),完成有状态的工作负载(StatefulSet)、配置管理组件(ConfigMap)和 命名服务(BNS)等资源的创建、更新。
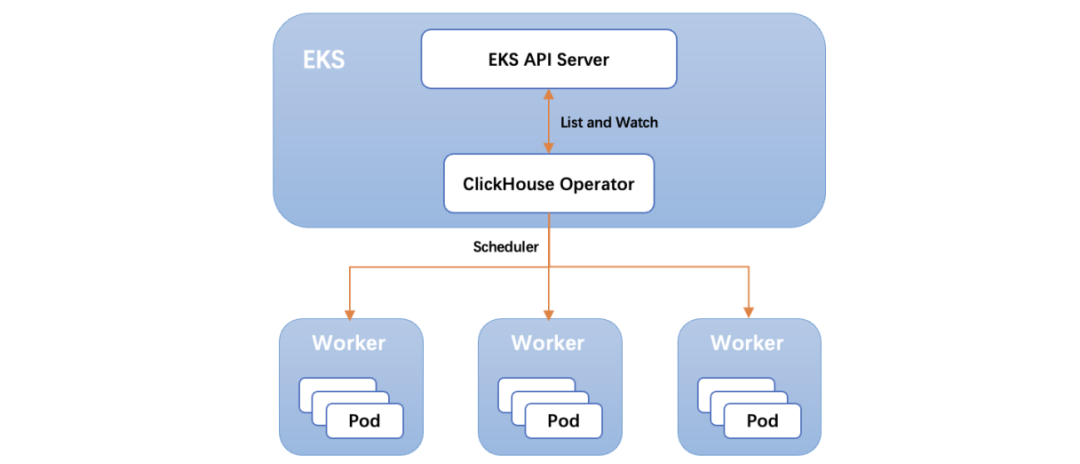
△ClickHouse云原生架构
针对容器重建后本地数据丢失的问题,我们采用两套数据自动恢复机制:从正常副本拷贝数据,或从AFS备份数据重建本地数据。业务可视自身情况权衡成本和服务稳定性,选择适合业务场景的数据透明恢复方案。
对于集群的服务发现功能,我们引入厂内经过高并发验证的BNS以提供相应能力。对于集群拓扑关系的维护,首先通过StatefulSet创建出来的Pod自带固定编号,以此就有了对应的分片、副本顺序;然后通过ConfigMap维护集群的拓扑关系,集群变更时通过自定义Controller监听Pod状态,并及时同步最新的拓扑关系。
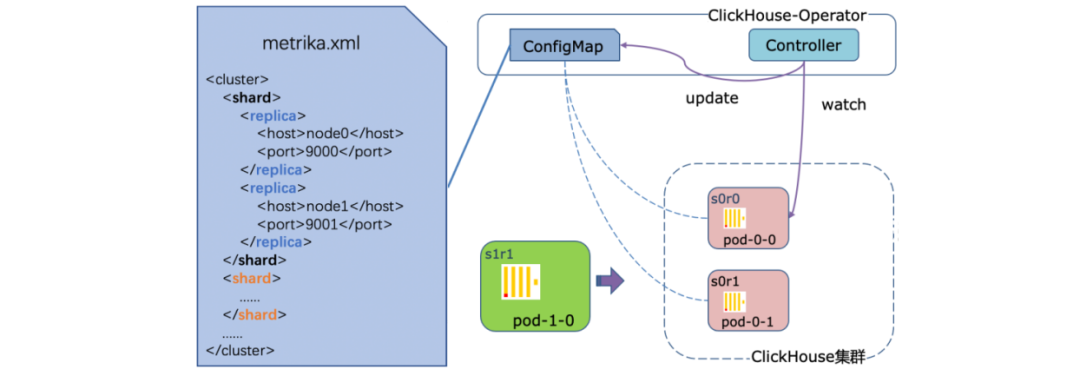
△ClickHouse集群拓扑关系
最后我们通过Pod Availability机制,结合Readiness Gates保障集群可用性,并通过给Node打标签的方式实现Shard反亲和部署。
目前我们已实现全量集群虚拟化部署,总规模3000+节点,在资源成本、部署周期、维护成本都有明显的收益。
4.2 集群协调服务
虽然CH云原生化极大降低了集群的部署与运维成本,使得CH集群的规模增长速度能够满足业务的接入需求,但是规模的持续增长也对CH的架构稳定性和数据质量保证提出了更高的要求。在原生CH集群的一致性方案中,副本间日志和数据的同步主要通过 ZooKeeper(后称ZK) 实现;分片间元数据的一致性则通过串行化执行DDL语句来实现。原生一致性方案在CH规模增长过程中暴露出以下问题:
(1)架构稳定性:基于ZK实现的主从架构稳定性差,ZK容易成为集群热点;
(2)数据正确性:缺乏集群层面的事务支持,脏读、脏写导致的错误数据不如没有数据。
为解决以上问题,我们对原生CH架构进行了改造,其核心思路为:
(1)构建轻量级集群元信息服务(Meta),将依赖ZK的主从架构切换为以Meta为底座的无主架构,提升CH集群稳定性的同时消除ZK运维压力;
(2)基于全局Meta服务,结合Quorum协议、MVCC机制重构数据导入、恢复、DDL等流程,同时实现原子导入等高级功能,解决数据正确性问题。
首先是集群协调者服务的升级。集群Meta服务将元数据的存储和访问服务进行分层解耦,其中无状态的服务层可根据集群负载按需扩缩容,存储层保存CH集群的库表以及数据文件等元信息,保证Meta服务的全局一致性。
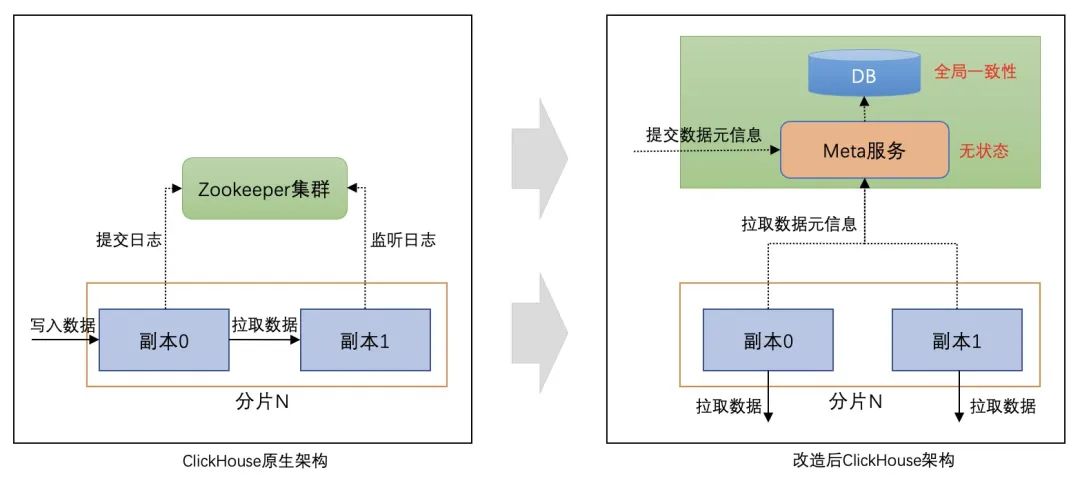
△ClickHouse协调服务升级
然后是数据同步机制的升级。ZK主要保证CH副本间的数据一致性,无法提供集群分片间的全局事务性,失败的数据导入任务引入的不完整数据可能导致查询时出现脏读以及数据恢复时出现脏写。为此我们引入全局的轻量级版本机制,查询、写入、数据恢复等流程根据特定版本读写数据,以提供全流程数据服务的强一致性。
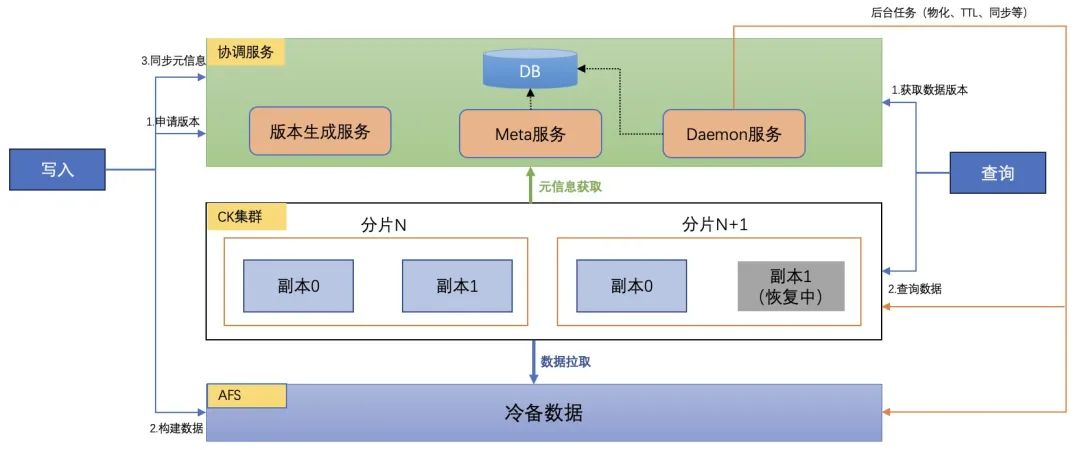
△ClickHouse数据同步机制升级
05 总结与展望
TDE-ClickHouse作为图灵3.0生态中重要的基础引擎之一,凭借其强大的计算性能,为业务提供海量数据下的自助秒级分析能力。其中高性能的数据查询能力与高效的数据导入通路,可以支持下游业务更及时、敏捷地对海量数据进行分析,提供数据驱动的洞察能力,辅助业务决策;稳定可靠的分布式架构在减少资源成本与运维成本的同时,严格保障了CH侧的数据质量,为下游业务提供准确无误的数据反馈。
目前百度MEG数据中台的CH资源规模已超过35万核计算、10PB存储;覆盖30+业务线,单日BI分析查询PV超过15万,查询平响小于3秒,P90小于7秒。
此外我们也在不断完善MEG数据中台CH的各项能力,包括存算分离减少资源与运维成本,提升规模弹性;湖仓融合降低数据迁移与探索成本;以及特定场景与类型的查询性能优化等。
随着AI等领域的发展,数据规模定会进一步激增,数据的重要性也会愈发明显,未来数据使用需求的变更、新硬件的出现、以及数据库相关技术理论的发展也会不断推动数据产品形态的更迭,我们也会持续关注与跟进。
————END————
推荐阅读
用增结算数仓化改造:在/离线调度系统的构建与应用
百度视觉搜索架构演进实践
智算基石全栈加速,百度百舸 4.0 的技术探索和创新
HelixFold 3 全球首个完整复现 AlphaFold 3,百度智能云 CHPC 为人类生命探索提供算力平台支撑
百度搜索结果波动的极致治理
相关文章:
ClickHouse在百度MEG数据中台的落地和优化
导读 百度MEG上一代大数据产品存在平台分散、质量不均和易用性差等问题,导致开发效率低下、学习成本高,业务需求响应迟缓。为了解决这些问题,百度MEG内部开发了图灵3.0生态系统,包括Turing Data Engine(TDE)计算引擎、Turing Dat…...
与C/S架构(Client/Server))
B/S架构(Browser/Server)与C/S架构(Client/Server)
基本概念 B/S架构(Browser/Server):即浏览器/服务器架构。在这种架构中,用户通过浏览器(如Chrome、Firefox、Safari等)访问服务器上的应用程序。服务器端负责处理业务逻辑、存储数据等核心功能,…...

idea中自定义注释模板语法
文章目录 idea 自定义模板语法1.自定义模板语法是什么?2.如何在idea中设置呢? idea 自定义模板语法 1.自定义模板语法是什么? 打开我的idea,创建一个测试类: 这里看到我的 test 测试类里面会有注释,这是怎…...
基于SSM的儿童教育网站【附源码】
基于SpringBoot的课程作业管理系统(源码L文说明文档) 目录 4 系统设计 4.1 系统概述 4.2 系统模块设计 4.3.3 数据库表设计 5 系统实现 5.1 管理员功能模块的实现 5.1.1 视频列表 5.1.2 文章信息管理 5.1.3 文章类…...

深挖自闭症病因与孩子表现的关联
自闭症,亦称为孤独症,乃是一种对儿童发展有着严重影响的神经发育障碍性疾病。深入探寻自闭症的病因与孩子表现之间的联系,对于更深刻地理解并助力自闭症儿童而言,可谓至关重要。 当前,自闭症的病因尚未完全明晰&#x…...

[网络协议篇] UDP协议
文章目录 1. 简介2. 特点3. UDP数据报结构4. 基于UDP的应用层协议5. UDP安全性问题6. 使用udp传输数据的系统就一定不可靠吗?7. 基于UDP的主机探活 python实现 1. 简介 User Datagram Protocol,用户数据报协议,基于IP协议提供面向无连接的网…...
----MySQL(初阶))
关系型数据库(1)----MySQL(初阶)
目录 1.mysql 2.mysqld 3.mysql架构 1.连接层 2.核心服务层 3.存储引擎层 4.数据存储层 4.SQL分类 5.MySQL操作库 6.MySQL数据类型 1. 数值类型 2. 日期和时间类型 3. 字符串类型 4. 空间类型 5. JSON数据类型 7.MySQL表的约束 1. 主键约束(PRIMARY…...

计算机毕业设计Python+大模型租房推荐系统 租房大屏可视化 租房爬虫 hadoop spark 58同城租房爬虫 房源推荐系统
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 用到的技术: 1. python…...

深度学习技术演进:从 CNN、RNN 到 Transformer 的发展与原理解析
深度学习的技术演进经历了从卷积神经网络(CNN)到循环神经网络(RNN)再到 Transformer 的重要发展。这三个架构分别擅长处理图像、序列数据和多种任务的特征,标志着深度学习在不同领域取得的进步。 1. 卷积神经网络&…...

Lua中的goto语句
软考鸭微信小程序 过软考,来软考鸭! 提供软考免费软考讲解视频、题库、软考试题、软考模考、软考查分、软考咨询等服务 在Lua编程语言中,goto语句是一种跳转语句,用于将程序的执行流程无条件地转移到程序中的另一个位置。这个位置由一个标签(…...

【rust实战】rust博客系统2_使用wrap启动rust项目服务
如何创建一个使用warp框架的rust项目1.使用cargo 创建项目 cargo new blog 2.添加warp依赖 1.cd blog 2.编辑Cargo.toml文件 添加warp 和 tokio 作为依赖项 在[dependencies]中添加 [package] name "blog" version "0.1.0" …...

【实战案例】Django框架使用模板渲染视图页面及异常处理
本文基于之前内容列表如下: 【图文指引】5分钟搭建Django轻量级框架服务 【实战案例】Django框架基础之上编写第一个Django应用之基本请求和响应 【实战案例】Django框架连接并操作数据库MySQL相关API 视图概述 Django中的视图的概念是一类具有相同功能和模板的网…...

设置K8s管理节点异常容忍时间
说明 每个节点上的 kubelet 需要定时向 apiserver 上报当前节点状态,如果两者间网络异常导致心跳终端,kube-controller-manager 中的 NodeController 会将该节点标记为 Unknown 或 Unhealthy,持续一段时间异常状态后 kube-controller-manage…...

什么样的JSON编辑器才好用
简介 JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也便于机器解析和生成。随着互联网和应用程序的快速发展,JSON已经成为数据传输和存储的主要格式之一。在处理和编辑JSON数据…...

ArkUI自定义TabBar组件
在ArkUI中的Tabs,通过页签进行内容视图切换的容器组件,每个页签对应一个内容视图。其中内容是图TabContent作为Tabs的自组件,通过给TabContent设置tabBar属性来自定义导航栏样式。现在我们就根据UI设计的效果图来实现下图效果: 根…...

pair类型应用举例
在main.cpp里输入程序如下: #include <iostream> //使能cin(),cout(); #include <utility> //使能pair数据类型; #include <string> //使能string字符串; #include <stdlib.h> //使能exit(); //pair类型可以将两个相同的或不同类…...

数字 图像处理算法的形式
一 基本功能形式 按图像处理的输出形式,图像处理的基本功能可分为三种形式。 1)单幅图像 单幅图像 2)多幅图像 单幅图像 3)单(或多)幅图像 数字或符号等 二 几种具体算法形式 1.局部处理邻域对于任一…...

安徽对口高考Python试题选:输入一个正整数,然后输出该整数的3的幂数相加形式。
第一步:求出3的最高次幂是多少 guoint(input("请输入一个正整数:")) iguo a0 while i>0: if 3**i<guo: ai break ii-1print(a)#此语句为了看懂题目,题目中不需要打印出最高幂数 第二步…...

Node.js是什么? 能做什么?
Node.js是一个基于Chrome V8引擎的JavaScript运行环境,它使用事件驱动、非阻塞式I/O模型,使得JavaScript能够在服务器端运行。Node.js允许JavaScript脱离浏览器,直接在服务器和计算机上使用,极大地扩展了JavaScript的应用范围。…...

JVM快速入门
1、 JVM探究 面试问题 :谈谈对JVM的理解? java8虚拟机和之前的变化更新?什么是OOM,什么是栈溢出StackOverFlowError?怎么分析?JVM的常用调优参数有哪些?内存快照如何抓取,怎么分析Dump文件?知道吗?谈谈JVM中,类加载器你的认识?2、JVM的位置 3、JVM的体系结构 3.1…...

wordpress后台更新后 前端没变化的解决方法
使用siteground主机的wordpress网站,会出现更新了网站内容和修改了php模板文件、js文件、css文件、图片文件后,网站没有变化的情况。 不熟悉siteground主机的新手,遇到这个问题,就很抓狂,明明是哪都没操作错误&#x…...

云启出海,智联未来|阿里云网络「企业出海」系列客户沙龙上海站圆满落地
借阿里云中企出海大会的东风,以**「云启出海,智联未来|打造安全可靠的出海云网络引擎」为主题的阿里云企业出海客户沙龙云网络&安全专场于5.28日下午在上海顺利举办,现场吸引了来自携程、小红书、米哈游、哔哩哔哩、波克城市、…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

SpringCloudGateway 自定义局部过滤器
场景: 将所有请求转化为同一路径请求(方便穿网配置)在请求头内标识原来路径,然后在将请求分发给不同服务 AllToOneGatewayFilterFactory import lombok.Getter; import lombok.Setter; import lombok.extern.slf4j.Slf4j; impor…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...
基于Springboot+Vue的办公管理系统
角色: 管理员、员工 技术: 后端: SpringBoot, Vue2, MySQL, Mybatis-Plus 前端: Vue2, Element-UI, Axios, Echarts, Vue-Router 核心功能: 该办公管理系统是一个综合性的企业内部管理平台,旨在提升企业运营效率和员工管理水…...

python爬虫——气象数据爬取
一、导入库与全局配置 python 运行 import json import datetime import time import requests from sqlalchemy import create_engine import csv import pandas as pd作用: 引入数据解析、网络请求、时间处理、数据库操作等所需库。requests:发送 …...
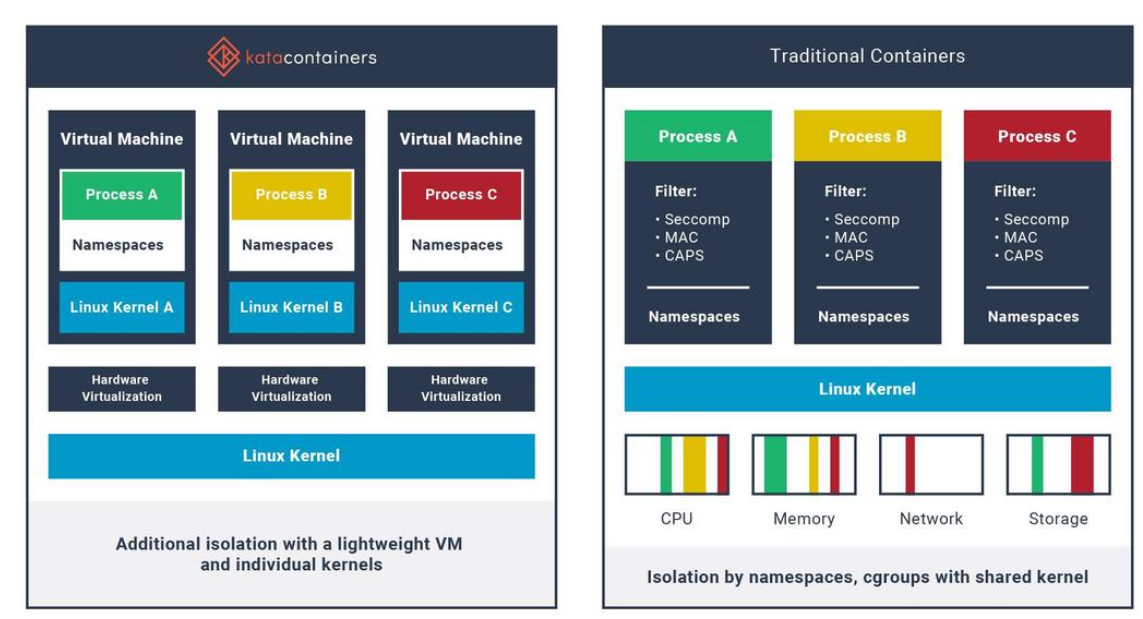
沙箱虚拟化技术虚拟机容器之间的关系详解
问题 沙箱、虚拟化、容器三者分开一一介绍的话我知道他们各自都是什么东西,但是如果把三者放在一起,它们之间到底什么关系?又有什么联系呢?我不是很明白!!! 就比如说: 沙箱&#…...