钉钉录播抓取视频
爬取钉钉视频
免责声明
此脚本仅供学习参考,切勿违法使用下载他人资源进行售卖,本人不但任何责任!
仓库地址:
- GItee 源码仓库
执行顺序
- poxyM3u8开启代理
- getM3u8url用于获取m3u8文件
- userAgent随机请求头
- downVideo|downVideoThreadTqdm单线程下载和多线程下载,二选一即可
启动顺序:poxyM3u8开启代理 -> getM3u8url获取文件->downVideo遍历文件进行下载
像这样别人给的钉钉链接我想要它的视频, 但是又没有下载按钮,我该怎么办呢?

我想到了用爬虫爬取
方案一
检查了一下网络请求发现它是采用m3u8文件格式保存的,所以找m3u8的文件。找到了

-
对它写代码进行保存:
with open("4f8122f4-f8fb-43d5-b8c8-7c1c9a4a70f7_normal.m3u8", "r", encoding="utf-8") as f:centen = f.read() print(centen) pattern = r'([0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{12}\/[\d]+\.ts\?auth_key=[\d\w-]+)' matches = re.findall(pattern, centen) print(matches) # urls = [] for match in matches:url = "https://dtliving-bj.dingtalk.com/live_hp/" + matchurls.append(url) # print(len(urls)) # for i in urls: # print(i)for item in tqdm(urls,disable="下载"):response = requests.get(item)with open("E:/a.mp4", "ab", ) as f:f.write(response.content)下载是下载下来了, 可是我有很多很多集,我自己下载是不是太麻烦了,也累。所以我就分析了一下这个地址
发现:
m3u8:https://dtliving-sz.dingtalk.com/live_hp/8618428f-dc2e-419e-bc6b-b93a6ee6b28c_normal.m3u8?auth_key=1730544823-fb9347e4a68a456b8b265afa36700f15-0-f24f0b45c72dd6547dadf77466f68ce4url:https://n.dingtalk.com/dingding/live-room/index.html?roomId=ZxaInSr3io8j9iZf&liveUuid=8618428f-dc2e-419e-bc6b-b93a6ee6b28c8618428f-dc2e-419e-bc6b-b93a6ee6b28c_normal.m3u8,其中8618428f-dc2e-419e-bc6b-b93a6ee6b28c是Uuid既然:
8618428f-dc2e-419e-bc6b-b93a6ee6b28c是房间号的话那我把好多集的房间号爬下来然后拼接到dtliving-sz.dingtalk.com/live_hp/房间号_normal.m3u8这样不就行了?然后拼接好我就发了一个请求发现并不能下载下来

原因是`auth_key`的原因, 然后我尝试寻找`auth_key`

emmm, 找了许久,打扰了。还是能力不够, 所以打算换一个方式。
方案二
我发现浏览器是可以获取到auth_key的那我不如我去拿浏览器的响应值。
相当于做了一件中间人的方式把我想要的东西抓取出来。
我使用了mitmproxy当我的代理
pip install mitmproxy
然后写一段代码来捕捉我想要抓取的url的响应
from mitmproxy import ctx,http
# http://mitm.it/ 证书
# mitmdump.exe -s .\test5.py
# mitmweb
import re
import requestsdef request(flow):# 获取请求对象request = flow.request# 实例化输出类math = re.match("^(.*?)_normal.m3u8", request.url)if math:info = ctx.log.info# 打印请求的urlinfo("请求地址: " + request.url + "\n")string = request.urlstart_index = string.find("auth_key=") + len("auth_key=")end_index = len(string)result = string[start_index:end_index]print(result)info("请求体: " + request.text + "\n")# # 打印请求方法info("请求方法: " + request.method)def response(flow):m3u8math = re.match("^(.*?)_normal.m3u8", flow.request.url)if m3u8math:print("===============这是m3u8格式的文件响应============================")centen = flow.response.get_text()with open("./m3u8s/{0}.m3u8".format(title), "w") as f:f.write(centen)print("===============结束============================")代码写好了,然后打开本机代理改成mitmproxy的代理然后安装证书,之后就可以愉快的抓请求了
1、代码启动

2、代理设置:

3、证书安装:
- 设置好系统代理后,浏览器输入
http://mitm.it/, 然后选择对应系统的证书安装就行。

4、抓取
- 当我使用浏览器打开
https://n.dingtalk.com/dingding/live-room/index.html?roomId=AAToXdFAVGArvaQx&liveUuid=9aac3549-698f-46b9-9bb0-f2f44d4faaca的时候它就会帮我把特定m3u8的请求响应做文件保存
from mitmproxy import ctx,http
# http://mitm.it/ 证书
# mitmdump.exe -s .\xiaoyuan.py
# mitmweb
import re
import requests
def response(flow):titlesearch = re.search(r"roomId=(.*?)&liveUuid=(.*)", flow.request.url)if titlesearch:global roomIdAndUidroomIdAndUid = titlesearchcentent = flow.response.get_content().decode('utf-8')titleRe = re.search(r'<meta property="og:title" content="(.*?)">',centent)global titletitle = titleRe.group(1)print(title)else:m3u8math = re.match(r"^(.*)/(.*?)_normal.m3u8", flow.request.url)if m3u8math:print("===============这是m3u8格式的文件响应============================")print("房间号:", roomIdAndUid.group(2), "========", roomIdAndUid.group(1))centen = flow.response.get_text()try:with open("./杰哥数学m3u8/{0}.m3u8".format(title), "w") as f:f.write(centen)except OSError:with open("./log.txt".format(title), "a") as f:f.write("标题: {0}, roomId:{1}, UuId: {2}, url:https://n.dingtalk.com/dingding/live-room/index.html?roomId={3}&liveUuid={4}\n".format(title,roomIdAndUid.group(1),roomIdAndUid.group(2),roomIdAndUid.group(1),roomIdAndUid.group(2),))print("===============结束============================")
可是我有很多个链接

所以我打算使用webdriver帮我做批量的链接请求, 而且这个必须要登录才能播放而webdriver会打断我的登录状态,为了保存我的登录状态所以我直接调试本机的chrome。
1、关闭chrome浏览器
2、终端输入
chrome.exe --remote-debugging-port=9222
3、确认是登录状态后,执行代码
import time
from selenium import webdriver
from selenium import webdriveroptions = webdriver.ChromeOptions()
options.set_headless()
options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
driver = webdriver.Chrome("chromedriver-win64/chromedriver-win64/chromedriver.exe",chrome_options=options)
driver.get('https://n.dingtalk.com/dingding/live-room/index.html?roomId=AAToXdFAVGArvaQx&liveUuid=9aac3549-698f-46b9-9bb0-f2f44d4faaca')这段代码一执行马上就把这个m3u8文件下载下来了

接下来执行多个url把他们m3u8都下载下来,我只需要把它们都打开然后进行代理检测到就会帮我们下载m3u8文件
import timefrom selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as ECoptions = webdriver.ChromeOptions()
options.set_headless()
options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
driver = webdriver.Chrome("chromedriver-win64/chromedriver-win64/chromedriver.exe",chrome_options=options)
driver.implicitly_wait(10)def newTable(urls, i):if len(urls) > i:window_handles = driver.window_handles# 切换到新标签页print(window_handles)new_tab = window_handles[-1]driver.switch_to.window(new_tab)driver.get(urls[i])login_btn = WebDriverWait(driver, 10, 0.5).until(EC.visibility_of_element_located((By.ID, "live-room")))if login_btn:time.sleep(5)i += 1print(i)newTable(urls, i)with open("钉钉1.txt", "r", encoding="utf-8") as f:urls = f.readlines()driver.get(urls[0])time.sleep(5)newTable(urls, 1)然后再对m3u8文件进行遍历下载
import re
import requests
import os
import tqdm
requests.packages.urllib3.disable_warnings()with open("m3u8/af941a57-92ad-487f-a2a1-a4682f07afc4_normal.m3u8", "r", encoding="utf-8") as file:content = file.read()# fileName = os.path.basename(file_path).split(".")[0]
# print(f"文件 {os.path.basename(file_path)} 的内容为:{content}")
pattern = r'([0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{12}\/[\d]+\.ts\?auth_key=[\d\w-]+)'
matches = re.findall(pattern, content)m3u8Url = ["https://dtliving-sz.dingtalk.com/live_hp/", "https://dtliving-sh.dingtalk.com/live_hp/"]def getStatusUrl():for status in m3u8Url:url = status + matches[0]responseStatus = requests.get(url, verify=False)print(status, responseStatus.status_code)if responseStatus.status_code == 200:return status
def getMp4Url():urls = []status = getStatusUrl()for match in matches:url = status+matchurls.append(url)return urlsdef run():urls = getMp4Url()for item in tqdm.tqdm(urls):response = requests.get(item, verify=False)if response.status_code == 200:# with open("/disk/data/杰哥数学/{0}.mp4".format("习题课1"), "ab", ) as f:with open(r"E:\杰哥数学\{0}.mp4".format("习题课1"), "ab", ) as f:f.write(response.content)run()
这样就可以下载文件了
总结
流程分析
由于解密困难,所以采用mitmproxy进行代理实现直接抓取视频需要请求的m3u8格式的文件,然后进行保存
- 启动代理
- 模拟浏览器访问视频地址
- 下载所有m3u8的文件
- 对m3u8文件进行清洗
- 拼装ts片段视频的地址
- 保存视频
完整代码
1、启动代理
poxyM3u8.py
from mitmproxy import ctx,http
# http://mitm.it/ 证书
# mitmdump.exe -s .\xiaoyuan.py
# mitmweb
import re
import requestsdef setM3u8Status():"""1 表示下载好了 """with open("m3u8Status.txt", "w") as f:f.write("0")def response(flow):titlesearch = re.search(r"roomId=(.*?)&liveUuid=(.*)", flow.request.url)if titlesearch:global roomIdAndUidroomIdAndUid = titlesearchcentent = flow.response.get_content().decode('utf-8')titleRe = re.search(r'<meta property="og:title" content="(.*?)">',centent)global titletitle = titleRe.group(1)print(title)else:m3u8math = re.match(r"^(.*)/(.*?)_normal.m3u8", flow.request.url)if m3u8math:print("===============这是m3u8格式的文件响应============================")print("房间号:", roomIdAndUid.group(2), "========", roomIdAndUid.group(1))centen = flow.response.get_text()try:with open(r"./m3u8/{0}.m3u8".format(title.replace("/", "-")).replace("\t", " "), "w") as f:f.write(centen)setM3u8Status()except OSError as e:print("==================================错误====================================")print(e)print("==================================错误====================================")with open("./log.txt".format(title), "a") as f:f.write("标题: {0}, roomId:{1}, UuId: {2}, url:https://n.dingtalk.com/dingding/live-room/index.html?roomId={3}&liveUuid={4}\n".format(title,roomIdAndUid.group(1),roomIdAndUid.group(2),roomIdAndUid.group(1),roomIdAndUid.group(2),))print("===============结束============================")2、模拟浏览器进行请求
getM3u8.py
import time
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as ECoptions = webdriver.ChromeOptions()
options.set_headless()
options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
driver = webdriver.Chrome("../chromedriver-win64/chromedriver-win64/chromedriver.exe", chrome_options=options)
driver.implicitly_wait(10)def newTable(urls, i):if len(urls) > i:window_handles = driver.window_handles# 切换到新标签页print(window_handles)new_tab = window_handles[-1]driver.switch_to.window(new_tab)setM3u8Status()driver.get(urls[i])while getM3u8FileStatus():time.sleep(5)i += 1print(i)newTable(urls, i)# login_btn = WebDriverWait(driver, 10, 0.5).until(EC.visibility_of_element_located((By.ID, "live-room")))# if login_btn:# time.sleep(5)# i += 1# print(i)# newTable(urls, i)def getM3u8FileStatus():with open("m3u8Status.txt", "r", encoding="utf-8") as f:status = f.read()time.sleep(2)return "1" == statusdef setM3u8Status():"""0 表示新的请求等待 """with open("m3u8Status.txt", "w") as f:f.write("1")time.sleep(2)with open("钉钉1.txt", "r", encoding="utf-8") as f:urls = f.readlines()driver.get(urls[0])while getM3u8FileStatus():time.sleep(5)newTable(urls, 1)3、最后下载文件
我发现m3u8里面的ts请求不止一个域名
有两个,用错了域名会报404状态码
m3u8Url = ["https://dtliving-sz.dingtalk.com/live_hp/", "https://dtliving-sh.dingtalk.com/live_hp/"]
userAgent 随机请求头
import random
import stringbrowsers = ["Chrome", "Firefox", "Safari", "Edge", "Opera"]
operating_systems = ["Windows NT", "Macintosh", "Linux", "iPhone", "iPad", "Android"]
versions = [str(i) for i in range(80, 130)]def generate_random_string(length):return ''.join(random.choices(string.ascii_letters + string.digits, k=length))def generate_user_agents(num):user_agents = []for _ in range(num):browser = random.choice(browsers)os = random.choice(operating_systems)version = random.choice(versions)if os == "Windows NT":ua = f"Mozilla/5.0 ({os}; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) {browser}/{version} Safari/537.36"elif os == "Macintosh":ua = f"Mozilla/5.0 ({os}; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) {browser}/{version} Safari/537.36"elif os == "Linux":ua = f"Mozilla/5.0 ({os}; x86_64) AppleWebKit/537.36 (KHTML, like Gecko) {browser}/{version} Safari/537.36"elif os == "iPhone":ua = f"Mozilla/5.0 (iPhone; CPU iPhone OS {generate_random_string(2)}_0 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/{version} Mobile/15E148 Safari/604.1"elif os == "iPad":ua = f"Mozilla/5.0 (iPad; CPU OS {generate_random_string(2)}_0 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/{version} Mobile/15E148 Safari/604.1"elif os == "Android":ua = f"Mozilla/5.0 (Linux; Android {generate_random_string(2)}; {generate_random_string(10)}) AppleWebKit/537.36 (KHTML, like Gecko) {browser}/{version} Mobile Safari/537.36"user_agents.append(ua)return user_agents# print(random.choice(generate_user_agents(100)))
downVideo.py
import os
import random
import time
import requests
import re
from tqdm import tqdm
requests.packages.urllib3.disable_warnings()
import glob
from userAgent import generate_user_agentsheaders = {'User-Agent': random.choice(generate_user_agents(100))}
folder_path = 'm3u8'
# 获取文件列表并添加进度条
file_paths = list(tqdm(glob.glob(folder_path + '/**/*', recursive=True), desc="获取文件列表进度"))m3u8Url = ["https://dtliving-sz.dingtalk.com/live_hp/", "https://dtliving-sh.dingtalk.com/live_hp/", "https://dtliving-bj.dingtalk.com/live_hp/"]def getStatusUrl(fileName, m3u8, i):url = m3u8Url[i] + m3u8print(f"第{i}次,正在检测{url}....")response = requests.get(url, headers=headers, verify=False)if response.status_code == 200:print(f"域名检测成功{m3u8}的域名是{m3u8Url[i]}")return m3u8Url[i]else:i+=1if len(m3u8Url) > i:print(f"第{i},次检测{url}....")getStatusUrl(fileName, m3u8, i)else:print(f"错误")with open("./errorUrl.txt", "a", encoding="utf-8") as f:f.write(f"{m3u8}没有找到合适的域名, 文件名称是: {fileName}")def getMp4Url(matches,fileName, m3u8, i):urls = []status = getStatusUrl(fileName, m3u8, i)for match in matches:url = status+matchurls.append(url)return urlsfor file_path in file_paths:if os.path.isfile(file_path):with open(file_path, 'r', encoding="utf-8") as file:content = file.read()fileName = os.path.basename(file_path).split(".")[0]# print(f"文件 {os.path.basename(file_path)} 的内容为:{content}")pattern = r'([0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{12}\/[\d]+\.ts\?auth_key=[\d\w-]+)'matches = re.findall(pattern, content)urls = getMp4Url(matches, fileName, matches[0], 0)# 处理每个文件中的链接列表并添加进度条for item in tqdm(urls, desc=f"处理 {fileName} 文件内链接进度"):response = requests.get(item, verify=False)time.sleep(2)# with open("/disk/data/杰哥数学/{0}.mp4".format(fileName), "ab", ) as f:with open(r"E:\杰哥数学\{0}.mp4".format(fileName), "ab", ) as f:f.write(response.content)也可以是多线程这样下载更快
import os
import random
import time
import requests
import re
from tqdm import tqdm
import glob
from userAgent import generate_user_agents
import threadingrequests.packages.urllib3.disable_warnings()# 设置请求头
headers = {'User-Agent': random.choice(generate_user_agents(100))}# 设置文件夹路径
folder_path = 'm3u8'# 获取文件列表并添加进度条
file_paths = list(tqdm(glob.glob(folder_path + '/**/*', recursive=True), desc="获取文件列表进度"))# 定义m3u8的URL列表
m3u8Url = ["https://dtliving-sz.dingtalk.com/live_hp/", "https://dtliving-sh.dingtalk.com/live_hp/", "https://dtliving-bj.dingtalk.com/live_hp/"]def getStatusUrl(fileName, m3u8, i):url = m3u8Url[i] + m3u8print(f"第{i}次,正在检测{url}....")log.write(f"第{i}次,正在检测{url}....")response = requests.get(url, headers=headers, verify=False)if response.status_code == 200:print(f"域名检测成功{m3u8}的域名是{m3u8Url[i]}")log.write(f"域名检测成功{m3u8}的域名是{m3u8Url[i]}")return m3u8Url[i]else:i += 1if len(m3u8Url) > i:print(f"第{i},次检测{url}....")log.write(f"第{i},次检测{url}....")return getStatusUrl(fileName, m3u8, i)else:log.write(f"第{i},{url}域名匹配失败....")with open("./errorUrl.txt", "a", encoding="utf-8") as f:f.write(f"{m3u8}没有找到合适的域名, 文件名称是: {fileName}")def getMp4Url(matches, fileName, m3u8, i):urls = []status = getStatusUrl(fileName, m3u8, i)for match in matches:url = status+matchurls.append(url)return urlsdef process_file(file_path):global loglog = open("log.txt", "a", encoding="utf-8")if os.path.isfile(file_path):with open(file_path, 'r', encoding="utf-8") as file:content = file.read()fileName = os.path.basename(file_path).split(".")[0]pattern = r'([0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{12}\/[\d]+\.ts\?auth_key=[\d\w-]+)'matches = re.findall(pattern, content)urls = getMp4Url(matches, fileName, matches[0], 0)# 处理每个文件中的链接列表并添加进度条for item in tqdm(urls, desc=f"处理 {fileName} 文件内链接进度"):response = requests.get(item, verify=False)time.sleep(2)# with open(r"E:\杰哥数学\{0}.mp4".format(fileName), "ab", ) as f:with open("/disk/data/杰哥数学/{0}.mp4".format(fileName), "ab", ) as f:f.write(response.content)log.close()# 创建线程列表
threads = []# 遍历文件路径列表,为每个文件创建一个线程进行处理
for file_path in file_paths:thread = threading.Thread(target=process_file, args=(file_path,))threads.append(thread)thread.start()# 等待所有线程完成
for thread in threads:thread.join()效果

注意事项
- 不要忘记开系统代理
- chrome浏览器需要全部关闭才可以
chrome.exe --remote-debugging-port=9222这个命令,不然selenium会没反应 - 不要忘记安装证书
- 要是下载请求失败的话,请注意访问的频率、更换请求头和IP
相关文章:
钉钉录播抓取视频
爬取钉钉视频 免责声明 此脚本仅供学习参考,切勿违法使用下载他人资源进行售卖,本人不但任何责任! 仓库地址: GItee 源码仓库 执行顺序 poxyM3u8开启代理getM3u8url用于获取m3u8文件userAgent随机请求头downVideo|downVideoThreadTqdm单线程下载和…...

centos下面的jdk17的安装配置
文章目录 1.基本指令回顾2.jdk17的安装到这个centos上面2.1首先切换到这个root下面去2.2查看系统jdk版本2.3首先到官网找到进行下载2.4安装包的上传2.5jdk17的安装包的解压过程2.6配置环境变量2.7是否设置成功,查看版本 1.基本指令回顾 ls:list也就是列出来这个目录…...

【操作系统】——调度
🌹😊🌹博客主页:【Hello_shuoCSDN博客】 ✨操作系统详见 【操作系统专项】 ✨C语言知识详见:【C语言专项】 目录 处理机调度的概念、层次 进程调度的时机、切换与过程、方式 调度器和闲逛进程 处理机调度的概念、层…...

基于Aspose依赖添加自定义文本水印——Word、Pdf、Cell
基于Aspose依赖添加自定义文本水印——Word、Pdf、Cell 所需依赖Word水印Pdf水印——( 注意 pdf 存在找不到字体的问题)Excel水印 所需依赖 <dependency><groupId>com.aspose</groupId><artifactId>aspose-pdf</artifactId&g…...

【C++】—掌握STL string类:字符串操作的得力助手
#1024程序员节|征文# 文章目录 繁星点点映夜空,晨曦微露照前程1.string的基本概念2.标准库中的string类2.1 string类2.2 auto和范围for2.3 string类常用的接口2.4 string类对象的容量操作2.5 string类对象的访问及遍历操作2.6 string类对象的修改操作2…...

【Java笔记】第十四章:异常
一、概念【理解即可】 1. 异常:程序运行过程中,出现的非正常情况。 2. 异常的处理:当异常出现时,执行一段预先准备好的代码。 3. 异常的处理的必要性:减少用户的损失、同时减小给用户带来麻烦,也可以对用…...
Python游戏开发超详细(基础理论知识篇)
一、引导: Python游戏开发是一个非常有趣且富有挑战性的领域。通过Python,你可以利用其强大的库和框架来创建各种类型的游戏,从简单的2D游戏到复杂的3D游戏。以下是第一课的基础理论知识,帮助你入门Python游戏开发。 二、理论知识…...

Python开发日记 -- 实现bin文件的签名
目录 1.数据的不同表现形式签名值不一样? 2.Binascii模块简介 3.问题定位 4.问题总结 1.数据的不同表现形式签名值不一样? Happy Muscle试运行了一段时间,组内同事再一次提出了新的需求:需要对bin文件签名。 PS:服…...

微软运用欺骗性策略大规模打击网络钓鱼活动
微软正在利用欺骗性策略来打击网络钓鱼行为者,方法是通过访问 Azure 生成外形逼真的蜜罐租户,引诱网络犯罪分子进入以收集有关他们的情报。 利用收集到的数据,微软可以绘制恶意基础设施地图,深入了解复杂的网络钓鱼操作ÿ…...

小程序无法获取头像昵称以及手机号码的深度剖析与解决方案
在当今数字化时代,小程序以其便捷、高效的特点,成为了人们生活和工作中不可或缺的一部分。然而,有时候开发者会遇到小程序无法获取头像昵称以及手机号码的问题,这给用户体验和业务流程带来了极大的困扰。本文将深入探讨这个问题的原因,并提供相应的解决方案。 一、引言 小…...
从0到1,搭建vue3项目
一 Vite创建Vue3项目 1.1.创建Vue3项目 1.1.1.运行创建项目命令 # 使用 npm npm create vitelatest 1.1.2、填写项目名称 1.1.3、选择前端框架 1.1.4、选择语法类型 1.1.5、按提示运行代码 1.1.6浏览器问 localhost:5173 预览 1.2项目结构 1.2.1vite.config.ts 1.2.2 pac…...

Mybatis mapper文件 resultType和resultMap的区别
在 MyBatis 中,resultType 和 resultMap 都用于定义从数据库查询结果到 Java 对象的映射规则,但它们之间存在着一些关键的区别。以下是对这两者的详细说明和区别: 1. resultType 定义 resultType 是 MyBatis 查询语句中的一个属性…...

文件下载漏洞
文件安全 文件下载 常见敏感信息路径 Windows C:\boot.ini //查看系统版本 C:\Windows\System32\inetsrv\MetaBase.xml //IIS配置文件 C:\Windows\repair\sam //存储系统初次安装的密码 C:\Program Files\mysql\my.ini //Mysql配置 C:\Program Files\mysql\data\mysql\user.…...

【Flutter】状态管理:Provider状态管理
在 Flutter 开发中,状态管理是一个至关重要的部分。随着应用的规模和复杂性增加,简单的局部状态管理(如 setState() 和 InheritedWidget)可能变得难以维护和扩展。Provider 是一种推荐的、广泛使用的 Flutter 状态管理工具&#x…...

来个Oracle一键检查
启停、切换、升级、网络改造等场景下,需要对数据库有些基本检查操作,确认当前是否运行正常,主打一个简单和一键搞定。 #!/bin/bash## 实例个数 告警日志 实例状态 会话 活动会话 锁 集群状态 服务状态 磁盘空间 侦听日志 ## linux vmstat 2 …...

C语言中的分支与循环(中 1)
关系操作符 C语言用于比较的表达式,称为"关系表达式",里面使用的运算符称为关系运算符,关系运算符主要有以下6类。 > 大于运算符< 小于运算符>大于等于运算符< 小于等于运算符 相等运算符! 不相等运算符 下面是例子:…...

Git_GitLab
Git_GitLab 安装 服务器准备 安装包准备 编写安装脚本 初始化 GitLab 服务 启动 GitLab 服务 浏览器访问 GitLab GitLab 创建远程库 IDEA 集成 GitLab 安装 GitLab 插件 设置 GitLab 插件 安装 服务器准备 准备一个系统为 CentOS7 以上版本的服务器,使…...
)
如何自定义一个自己的 Spring Boot Starter 组件(从入门到实践)
文章目录 一、什么是 Spring Boot Starter?二、为什么要自定义 Starter?三、自定义 Starter 的基本步骤1. 创建 Maven 项目2. 配置 pom.xml3. 创建自动配置类4. 创建业务逻辑类5. 创建 spring.factories 四、使用自定义 Starter五、总结推荐阅读文章 在使…...

CSS伪元素以及伪类和CSS特性
伪元素:可以理解为假标签。 有2个伪元素 (1)::before (2)::after ::before <!DOCTYPE html> <html> <head><title></title><style type"text/css">body::before{con…...

【论文笔记】Instantaneous Perception of Moving Objects in 3D
原文链接:https://arxiv.org/abs/2405.02781 简介:本文主张自动驾驶中细微运动的瞬时检测和量化与一般的大型运动同等重要。具体来说,由于激光雷达点云缺乏帧间对应关系,静态物体可能看起来在运动(称为游泳效应&#x…...

Docker 离线安装指南
参考文章 1、确认操作系统类型及内核版本 Docker依赖于Linux内核的一些特性,不同版本的Docker对内核版本有不同要求。例如,Docker 17.06及之后的版本通常需要Linux内核3.10及以上版本,Docker17.09及更高版本对应Linux内核4.9.x及更高版本。…...

2024年赣州旅游投资集团社会招聘笔试真
2024年赣州旅游投资集团社会招聘笔试真 题 ( 满 分 1 0 0 分 时 间 1 2 0 分 钟 ) 一、单选题(每题只有一个正确答案,答错、不答或多答均不得分) 1.纪要的特点不包括()。 A.概括重点 B.指导传达 C. 客观纪实 D.有言必录 【答案】: D 2.1864年,()预言了电磁波的存在,并指出…...

苍穹外卖--缓存菜品
1.问题说明 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大 2.实现思路 通过Redis来缓存菜品数据,减少数据库查询操作。 缓存逻辑分析: ①每个分类下的菜品保持一份缓存数据…...
相比,优缺点是什么?适用于哪些场景?)
Redis的发布订阅模式与专业的 MQ(如 Kafka, RabbitMQ)相比,优缺点是什么?适用于哪些场景?
Redis 的发布订阅(Pub/Sub)模式与专业的 MQ(Message Queue)如 Kafka、RabbitMQ 进行比较,核心的权衡点在于:简单与速度 vs. 可靠与功能。 下面我们详细展开对比。 Redis Pub/Sub 的核心特点 它是一个发后…...

排序算法总结(C++)
目录 一、稳定性二、排序算法选择、冒泡、插入排序归并排序随机快速排序堆排序基数排序计数排序 三、总结 一、稳定性 排序算法的稳定性是指:同样大小的样本 **(同样大小的数据)**在排序之后不会改变原始的相对次序。 稳定性对基础类型对象…...

如何更改默认 Crontab 编辑器 ?
在 Linux 领域中,crontab 是您可能经常遇到的一个术语。这个实用程序在类 unix 操作系统上可用,用于调度在预定义时间和间隔自动执行的任务。这对管理员和高级用户非常有益,允许他们自动执行各种系统任务。 编辑 Crontab 文件通常使用文本编…...
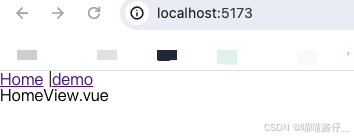
打手机检测算法AI智能分析网关V4守护公共/工业/医疗等多场景安全应用
一、方案背景 在现代生产与生活场景中,如工厂高危作业区、医院手术室、公共场景等,人员违规打手机的行为潜藏着巨大风险。传统依靠人工巡查的监管方式,存在效率低、覆盖面不足、判断主观性强等问题,难以满足对人员打手机行为精…...

STM32---外部32.768K晶振(LSE)无法起振问题
晶振是否起振主要就检查两个1、晶振与MCU是否兼容;2、晶振的负载电容是否匹配 目录 一、判断晶振与MCU是否兼容 二、判断负载电容是否匹配 1. 晶振负载电容(CL)与匹配电容(CL1、CL2)的关系 2. 如何选择 CL1 和 CL…...

学习一下用鸿蒙DevEco Studio HarmonyOS5实现百度地图
在鸿蒙(HarmonyOS5)中集成百度地图,可以通过以下步骤和技术方案实现。结合鸿蒙的分布式能力和百度地图的API,可以构建跨设备的定位、导航和地图展示功能。 1. 鸿蒙环境准备 开发工具:下载安装 De…...
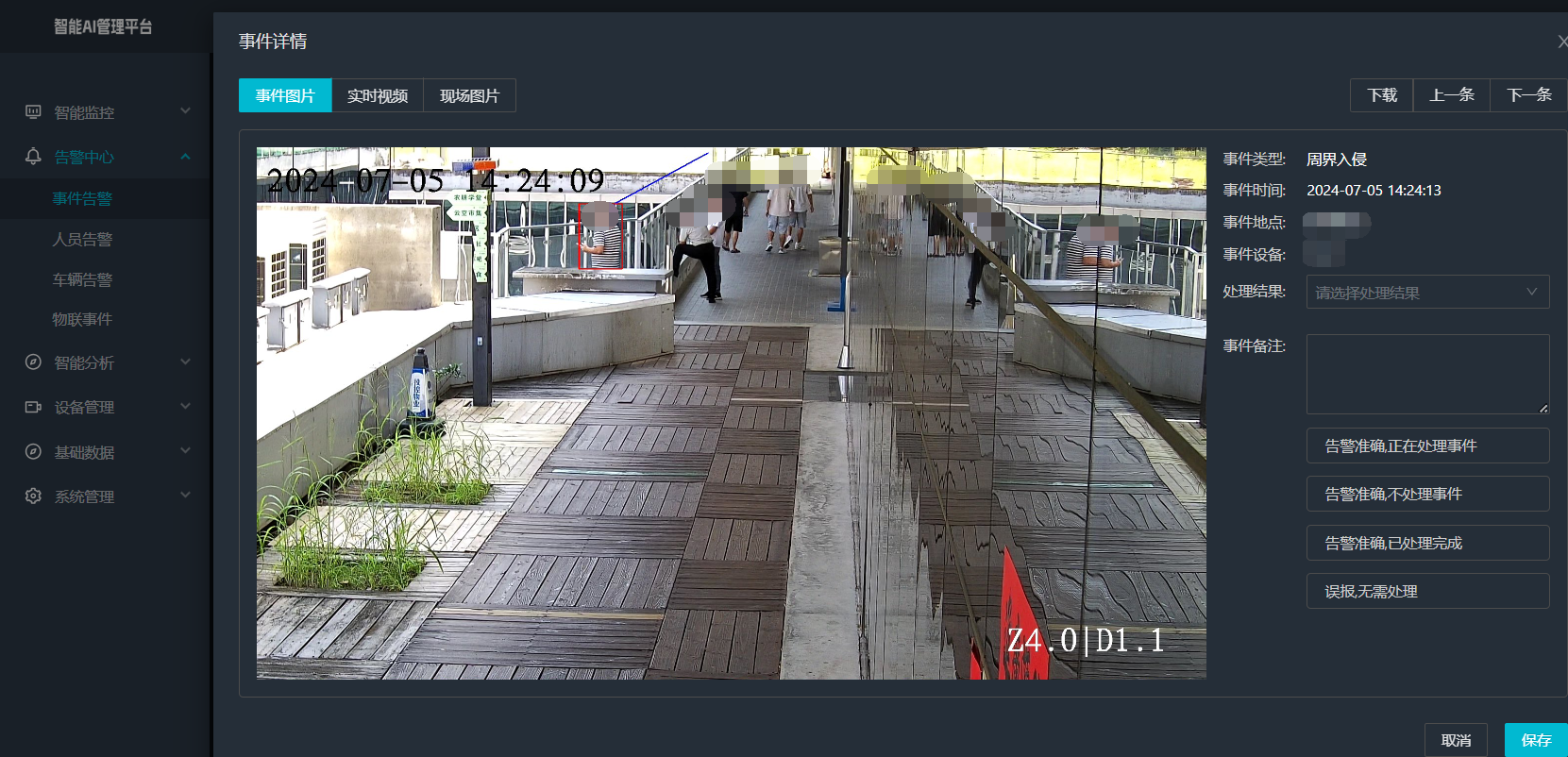
Java数组Arrays操作全攻略
Arrays类的概述 Java中的Arrays类位于java.util包中,提供了一系列静态方法用于操作数组(如排序、搜索、填充、比较等)。这些方法适用于基本类型数组和对象数组。 常用成员方法及代码示例 排序(sort) 对数组进行升序…...