从本地到云端:跨用户请求问题的完美解决方案
对于某些单个请求或响应中含有多个用户信息的服务,SDK提供了一套基于统一的UCS拆分和聚合的解决方案供开发者使用。
请求拆分
对于跨用户服务的请求,我们提供了两个处理方案:
【1】根据用户信息拆分请求: 场景:请求内含有对应多个用户的对象列表。例如批量查询,批量匹配订单进行批量操作。
Map<SwitchTag, R> split(R originalRequest, // 原始的请求RequestType。String splitItemCollectionFieldName, // 请求内含有多个用户信息的对象集合,由于契约限制必须为List类型。Function<T, K> splitKeyGetter, // 获取上述多用户对象集合内用来分割请求的key,支持的类型参照上文MappingFieldType的类型。MappingFieldType keyType) throws RequestSplitException; // 分割请求的key对应的类型
示例用法:以特殊事件强绑接口为例,EditForceMatchedOrderRequest中,forceMatchedOrderList内可能会包含多个不同用户的订单,且对象内含有订单号的信息,可以用来匹配用户的uid。代码如下:
MultiUserRequestSplitter splitter = MultiUserRequestSplitterImpl.getInstance();
EditForceMatchedOrderRequest request = new EditForceMatchedOrderRequest();
try {Map<SwitchTag, EditForceMatchedOrderRequest> splitRequests =splitter.split(request,"forceMatchedOrderList",ForceMatchedOrder::getOrderId,MappingFieldType.FLIGHT_ORDER_ID);} catch (RequestSplitException e) {// exception process
}
【2】广播请求至所有Region: 场景:请求中不含有用户信息,但是返回结果会存在多个用户的数据。例如最终行程匹单,利用规则ID查询所有匹配特殊事件规则的订单。
Map<SwitchTag, R> broadcast(R originalRequest) throws RequestSplitException;
用户只需要提供原始的请求,该方法就会将该请求复制多份到每个region。
以查询强绑订单为例,QueryForceMatchedOrderRequest中,可以只传入configId,匹配所有符合该id的订单。代码如下:
MultiUserRequestSplitter splitter = MultiUserRequestSplitterImpl.getInstance();
QueryForceMatchedOrderRequest request = new QueryForceMatchedOrderRequest();
try {Map<SwitchTag, QueryForceMatchedOrderRequest> splitRequests = splitter.split(request);
} catch (RequestSplitException e) {// exception process
}
请求执行
SDK中提供了标准的api可以让开发者方便的执行被拆分出来的请求。API列表如下:
List<RequestExecutionContext<R,P>> execRequests(Map<SwitchTag, R> requestMap,Class<P> responseClz,C serviceClient,String operationName) throws RequestExecutionException;
RequestExecutionContext<R,P> execRequest(SwitchTag switchTag,R request,Class<P> responseClz,C serviceClient,String operationName) throws RequestExecutionException;
大部分情况下,开发者只需调用execRequests方法,传入上述拆分功能返回的请求列表,以及调用客户端相关信息即可。当且仅当开发者对调用顺序有严格要求,或需要对每次请求单独做自定义异常处理,可以调用execRequest进行单个请求逐个执行。
以特殊事件强绑接口为例,使用请求拆分功能后紧接着实际发送请求的示例代码为:
MultiUserRequestExecutor executor = MultiUserRequestExecutorImpl.getInstance();
List<RequestExecutionContext<EditForceMatchedOrderRequest, EditForceMatchedOrderResponse>> execResults =executor.execRequests(// 拆分后的请求列表splitRequests,// 请求的响应契约类型EditForceMatchedOrderResponse.class,// 请求的客户端实例FlightchangeSpecialeventServiceClient.getInstance(),// 请求的对应操作名"editForceMatchedOrder");
返回值中的RequestExecutionContext对象包括了请求,响应,SwitchTag以及该次请求的异常信息,一般来说无需关心。
请求聚合
SDK中提供了一些标准的api来对拆分后不同用户的多个请求的一系列响应做聚合,最终返回客户端的只有一个响应对象,使得业务代码中除了调用部分之外的代码可以保持一致。
响应聚合的方式主要包括以下三类:根据UCS策略聚合
P aggregateByUCS(List<RequestExecutionContext<R,P>> responseContext,// 可以不传,则默认有响应都是成功,不进行过滤Predicate<P> failedRespPredictor,String itemCollectionFieldName,Function<T, K> splitKeyGetter,MappingFieldType keyType) throws Exception;
场景:广播请求后返回了多个区域的多个用户的请求,需要筛选出Region中灰度范围内用户的数据,保证数据新鲜度。
其中,responseContext为上述请求执行后返回的包装结果,failedRespPredictor为判断单个响应是否成功的函数,其余参数和请求拆分中的定义保持一致(用户信息对象为响应中的对象)。
注意:返回的响应集合中,如果有一个响应经过failedRespPredictor判断为失败,则默认情况下,会认为整个请求失败,返回该失败的响应。该行为可以通过配置ignoreFailureAndExceptions改变,后续配置项介绍会详细说明。
示例代码:以用规则ID查询所有匹配的强绑规则订单为例,该场景下请求内仅含有需要查询的规则ID无用户信息,所以被广播到了SHA和SIN两个Region同时进行查询。现在需要对查询结果做聚合:
MultiUserResponseAggregator aggregator = MultiUserResponseAggregatorImpl.getInstance();
QueryForceMatchedOrderResponse aggregated = aggregator.aggregateByUCS(execResults,response -> response.getResponseStatus().getAck() != AckCodeType.Success,"forceMatchedOrderList",ForceMatchedOrder::getOrderId,MappingFieldType.FLIGHT_ORDER_ID);
// handle response as used to be
聚合全量不同的结果
P aggregateAllDistinct(List<RequestExecutionContext<R,P>> responseContext,String itemCollectionFieldName,// 判断两个含有用户信息的对象是否属于同一个业务记录的函数,默认为Object.equalsBiPredicate<T, T> itemEqualPredictor,// 可以不传,则默认有响应都是成功,不进行过滤Predicate<P> failedRespPredictor) throws Exception;
场景:批量操作请求按照用户被拆分成多个后,需要获取所有响应进行展示,或数据完全隔离后单边进行查询。
示例场景:以特殊事件强绑接口为例,请求按照用户被拆分成多个请求后,返回的响应是操作失败的订单列表,此时只需要聚合所有失败的订单返回给客户端即可。示例代码如下:
MultiUserResponseAggregator aggregator = MultiUserResponseAggregatorImpl.getInstance();
EditForceMatchedOrderResponse response = aggregator.aggregateAllDistinct(execResults,"updateFailedList",// 返回的itemCollection为Long,直接使用默认的Object.equals比较即可null,// 无特别的响应状态码,默认即可null);
返回任意结果(任意成功/任意失败/失败优先)
// 任意成功
P getAnySuccessResponse(List<RequestExecutionContext<R,P>> responseContext, Predicate<P> successRespPredictor);
// 失败优先
<R extends SpecificRecord, P extends SpecificRecord>
P getAnyResponseWithFailFast(List<RequestExecutionContext<R,P>> responseContext,Predicate<P> failedRespPredictor) throws Exception;
// 所有失败
<R extends SpecificRecord, P extends SpecificRecord>
List<RequestExecutionContext<R,P>> getAllFailedResponseContext(List<RequestExecutionContext<R,P>> responseContext, Predicate<P> failedRespPredictor);
场景:批量操作请求按照用户被拆分成多个后,响应中不含有用户信息,仅存在成功/失败/状态码的字段
典型场景示例代码:综合以上的用法,我们针对典型的场景给出两套标准的示例代码:
【1】批量编辑强绑订单,请求中含有多个待编辑的订单信息,响应为编辑失败的订单号集合
private EditForceMatchedOrderResponse editForceMatchedOrder(EditForceMatchedOrderRequest request) {
MultiUserRequestSplitter splitter = MultiUserRequestSplitterImpl.getInstance();MultiUserRequestExecutor executor = MultiUserRequestExecutorImpl.getInstance();MultiUserResponseAggregator aggregator = MultiUserResponseAggregatorImpl.getInstance();
try {Map<SwitchTag, EditForceMatchedOrderRequest> splitRequests =splitter.split(request,"forceMatchedOrderList",ForceMatchedOrder::getOrderId,MappingFieldType.FLIGHT_ORDER_ID);
List<RequestExecutionContext<EditForceMatchedOrderRequest, EditForceMatchedOrderResponse>> execResults = executor.execRequests(splitRequests,EditForceMatchedOrderResponse.class,FlightchangeSpecialeventServiceClient.getInstance(),"editForceMatchedOrder");
return aggregator.aggregateAllDistinct(execResults, "updateFailedList", null, null);} catch (Exception e) {// exception process}
}
【2】根据强绑规则ID查询所有匹配的订单信息,请求中只含有规则ID,响应为所有匹配的订单信息的集合
private QueryForceMatchedOrderResponse queryForceMatchedOrder(QueryForceMatchedOrderRequest request) {MultiUserRequestSplitter splitter = MultiUserRequestSplitterImpl.getInstance();MultiUserRequestExecutor executor = MultiUserRequestExecutorImpl.getInstance();MultiUserResponseAggregator aggregator = MultiUserResponseAggregatorImpl.getInstance();
try {Map<SwitchTag, QueryForceMatchedOrderRequest> splitRequests = splitter.broadcast(request);
List<RequestExecutionContext<QueryForceMatchedOrderRequest, QueryForceMatchedOrderResponse>> execResults = executor.execRequests(splitRequests,QueryForceMatchedOrderResponse.class,FlightchangeSpecialeventServiceClient.getInstance(),"queryForceMatchedOrder");
return aggregator.aggregateByUCS(execResults,"forceMatchedOrderList",ForceMatchedOrder::getOrderId,MappingFieldType.FLIGHT_ORDER_ID);} catch (Exception e) {// exception process}
}
配置项列表
为了启用SDK中的多用户请求处理功能,开发者必须在客户端的QConfig上新建名为requestprocessorconfig.json的配置文件, 并按照目标操作的维度配置必要的信息。示例的配置文件如下:
[{"requestTypeFullName" : "com.huwei.soa.flight.flightchange.specialevent.v1.EditForceMatchedOrderRequest", // 要调用的操作的请求契约全类名"targetServiceCode" : "24249", // 要调用的服务对应的serviceCode,用于关联UCS策略以及路由规则"splitterSettings" : {"enableRequestSplit" : true, // 是否打开请求拆分功能,默认不打开,即原样转发请求"splitMode" : "BY_UID", // 拆分的模式"interruptOnUDLError" : false, // 查询UDL信息出现异常如超时时,是否直接中断当前请求。默认或设置为false时,查询UDL出错,请求会继续被执行,但是不会带上UDL信息,所以都会被路由到SHA。设置为true时,查询UDL出错,方法直接抛错中断执行"allowNullSplitKey": false // 默认情况下,split key为空的时候走SHA。设置为true后,split key为空的时候,该key会拆分为广播的请求。场景为某些特殊的批量查询下,查询的key即可能是订单号也有可能是规则ID。},"executorSettings" : {"enableConcurrentExecute" : false, // 是否启用并发请求。当拆分后的用户数量很多,或客户端对响应时间比较敏感的情况下,该选项设置为true可以开启并发执行。默认为不开启。"concurrentExecThreshold" : 10, // 并发执行的请求个数阈值。默认为0。当并发请求开启后,可以通过设置该值,来达到仅当拆分后请求数量大于该阈值才并发执行的效果。"maxConcurrentThreads" : 16, // 最大并发线程数,仅对当前操作生效。"interruptOnRemoteCallError" : false, // 是否在远程调用发生异常时立即中断。默认为不中断。"execTimeoutMillis" : 3000, // 并发执行时,总体的超时时间(单位ms)。默认为10秒。"requestFormat" : "json" // 调用服务端时的请求格式,针对服务端只接受特定的格式的场景。默认即跟随baiji框架设置。},"aggregatorSettings" : {"ignoreFailureAndExceptions" : false, // 是否在聚合时忽略异常和失败的请求,默认为不忽略。设置为true时,异常或失败的请求会被跳过,系统只会聚合合法的响应并返回客户端。"dataInconsistentErrorLogLevel" : "INFO", // 当Region之间数据不一致时,log信息的级别。可选有INFO, ERROR, DISABLE"disableUCSFiltering" : false // 在数据完全隔离后,跳过UCS过滤的步骤,直接聚合全量数据。}},...
]
splitMode:拆分的模式
【1】BY_UID:默认的每个用户拆分一个请求,适用于绝大部分情况;
【2】BY_UDL:(使用前请联系上云组评估)仅当单个批量请求的用户可能非常多导致性能问题时使用;
【3】BROADCAST: 广播模式,同一个请求复制到所有Region;
相关文章:

从本地到云端:跨用户请求问题的完美解决方案
对于某些单个请求或响应中含有多个用户信息的服务,SDK提供了一套基于统一的UCS拆分和聚合的解决方案供开发者使用。 请求拆分 对于跨用户服务的请求,我们提供了两个处理方案: 【1】根据用户信息拆分请求: 场景:请求内…...

leetcode day4 409+5
409 最长回文串 给定一个包含大写字母和小写字母的字符串 s ,返回 通过这些字母构造成的 最长的 回文串 的长度。 在构造过程中,请注意 区分大小写 。比如 "Aa" 不能当做一个回文字符串。 示例 1: 输入:s "abccccdd" 输出:7 解…...

英语语法学习框架(考研)
一、简单句 英语都是由简单句构成,简单句共有五种基本句型:①主谓;②主谓宾;③主谓宾宾补;④主谓宾间宾(间接宾语);⑤主系表; 其中谓语是句子最重要的部分,谓…...

基于neo4j的学术论文关系管理系统
正在为毕业设计头疼?又或者在学术研究中总是找不到像样的工具来管理浩瀚的文献资料?今天给大家介绍一款超实用的工具——基于Neo4j的学术论文关系管理系统,让你轻松搞定学术文献的管理与展示!🎉 系统的核心是什么呢&a…...

C#中的委托、匿名方法、Lambda、Action和Func
委托 委托概述 委托是存有对某个方法的引用的一种引用类型变量。定义方法的类型,可以把一个方法当作另一方法的参数。所有的委托(Delegate)都派生自 System.Delegate 类。委托声明决定了可由该委托引用的方法。 # 声明委托类型 委托类型声…...

IDEA关联Tomcat——最新版本IDEA 2024
1.链接Tomcat到IDEA上 添加Tomcat到IDEA上有两种方式: 第一种: (1)首先,来到欢迎界面,找到左侧的Customize选项 (2)然后找到Build、Execution、Deployment选项 (3&am…...

【如何获取股票数据18】Python、Java等多种主流语言实例演示获取股票行情api接口之沪深A股解禁限售数据获取实例演示及接口API说明文档
最近一两年内,股票量化分析逐渐成为热门话题。而从事这一领域工作的第一步,就是获取全面且准确的股票数据。因为无论是实时交易数据、历史交易记录、财务数据还是基本面信息,这些数据都是我们进行量化分析时不可或缺的宝贵资源。我们的主要任…...

NVR小程序接入平台/设备EasyNVR多品牌NVR管理工具/设备的多维拓展与灵活应用
在数字化安防时代,NVR批量管理软件/平台EasyNVR作为一种先进的视频监控系统设备,正逐步成为各个领域监控解决方案的首选。NVR批量管理软件/平台EasyNVR作为一款基于端-边-云一体化架构的国标视频融合云平台,凭借其部署简单轻量、功能多样、兼…...
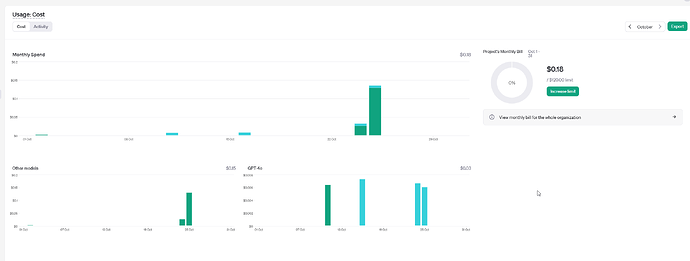
GPT-4o 和 GPT-4 Turbo 模型之间的对比
GPT-4o 和 GPT-4 Turbo 之间的对比 备注 要弄 AI ,不同模型之间的对比就比较重要。 GPT-4o 是 GPT-4 Turbo 的升级版本,能够提供比 GPT-4 Turbo 更多的内容和信息,但成功相对来说更高一些。 第三方引用 在 2024 年 5 月 13 日࿰…...

gin入门教程(10):实现jwt认证
使用 github.com/golang-jwt/jwt 实现 JWT(JSON Web Token)可以有效地进行用户身份验证,这个功能往往在接口前后端分离的应用中经常用到。以下是一个基本的示例,演示如何在 Gin 框架中实现 JWT 认证。 目录结构 /hello-gin │ ├── cmd/ …...

Python 基础语法 - 数据类型
顾名思义,计算机就是用来做数学计算的机器,因此,计算机程序理所当然的可以处理各种数值。但是,计算机能处理的远远不止数值,还可以处理文本,图形,音频,视频,网页等各种各…...
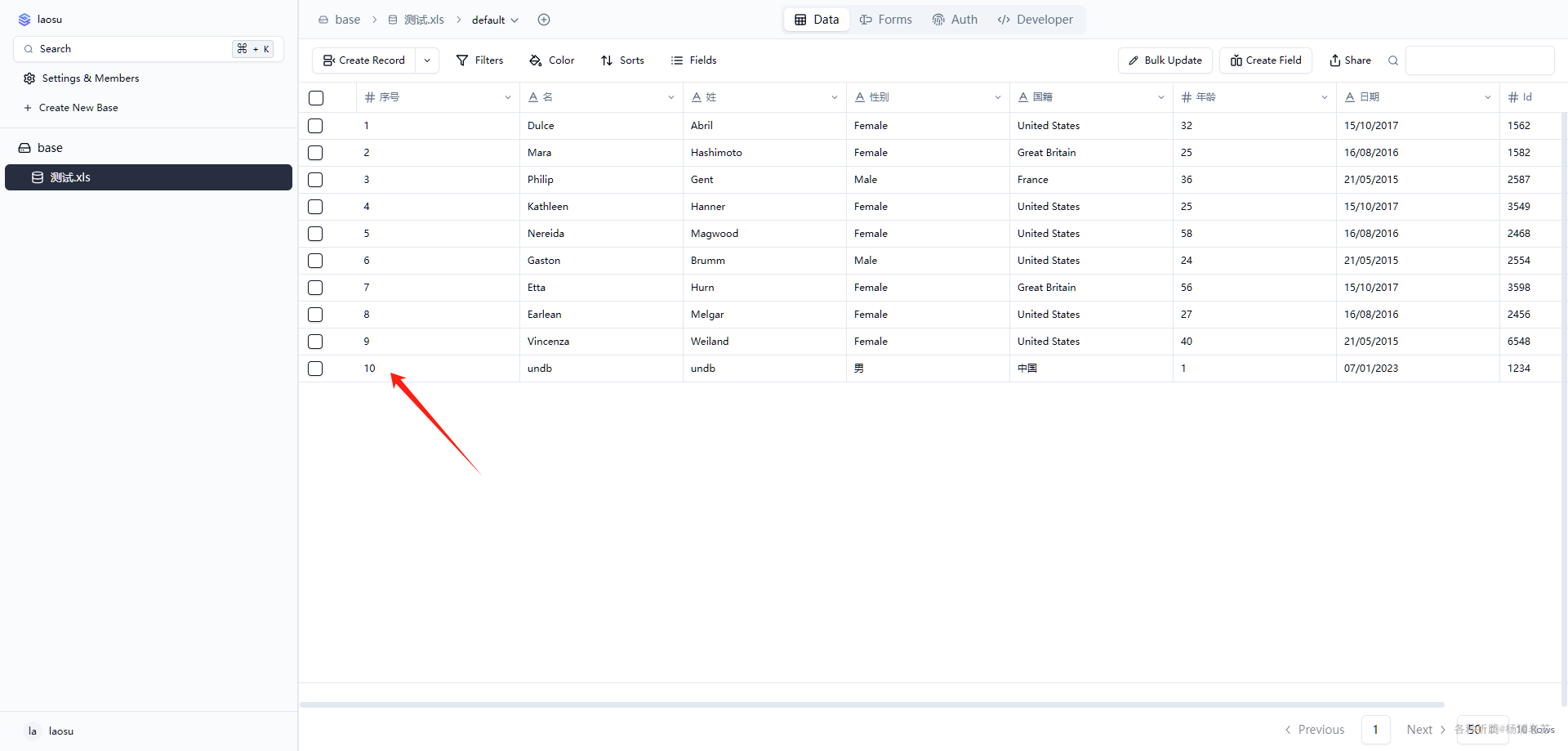
自托管无代码数据库Undb
什么是 Undb ? Undb 是一个无代码平台,也可以作为后端即服务 (BaaS)。它基于 SQLite,可以使用 Bun 打包成二进制文件用于后端服务。此外,它可以通过 Docker 部署为服务,提供表管理的 UI。 软件特点: ⚡ 无…...
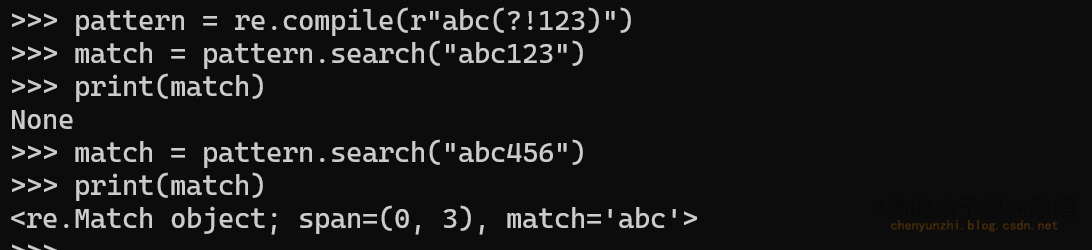
正则的正向前瞻断言和负向前瞻断言
正则的正向前瞻断言和负向前瞻断言 一. 正向前瞻断言二. 负向前瞻断言三. 总结 这是我在这个网站整理的笔记,有错误的地方请指出,关注我,接下来还会持续更新。 作者:神的孩子都在歌唱 正向前瞻断言和负向前瞻断言是正则表达式中用于检查后续字…...
高频面试题及参考答案)
大厂物联网(IoT)高频面试题及参考答案
目录 解释物联网 (IoT) 的基本概念 物联网的主要组成部分有哪些? 描述物联网的基本架构。 IoT 与传统网络有什么区别? 物联网中常用的传感器类型有哪些? 描述物联网的三个主要层次。 简述物联网中数据安全的重要性 描述物联网安全的主要威胁 解释端到端加密在 IoT 中…...

react hook
react hook 最近实习有点忙,所以学习记录没来得及写。 HOC higher order components(HOC) 高阶组件是一个组件,接受一个参数作为组件,返回值也是一个组件的函数。高阶组件作用域强化组件,服用逻辑,提升渲染性能等。…...

Jetpack架构组件_LiveData组件
1.LiveData初识 LiveData:ViewModel管理要展示的数据(VM层类似于原MVP中的P层),处理业务逻辑,比如调用服务器的登陆接口业务。通过LiveData观察者模式,只要数据的值发生了改变,就会自动通知VIEW层…...
Etcd 可观测最佳实践
简介 Etcd 是一个高可用的分布式键值存储系统,它提供了一个可靠的、强一致性的存储服务,用于配置管理和服务发现。它最初由 CoreOS 开发,现在由 Cloud Native Computing Foundation (CNCF) 维护。Etcd 使用 Raft 算法来实现数据的一致性&…...

钉钉录播抓取视频
爬取钉钉视频 免责声明 此脚本仅供学习参考,切勿违法使用下载他人资源进行售卖,本人不但任何责任! 仓库地址: GItee 源码仓库 执行顺序 poxyM3u8开启代理getM3u8url用于获取m3u8文件userAgent随机请求头downVideo|downVideoThreadTqdm单线程下载和…...

centos下面的jdk17的安装配置
文章目录 1.基本指令回顾2.jdk17的安装到这个centos上面2.1首先切换到这个root下面去2.2查看系统jdk版本2.3首先到官网找到进行下载2.4安装包的上传2.5jdk17的安装包的解压过程2.6配置环境变量2.7是否设置成功,查看版本 1.基本指令回顾 ls:list也就是列出来这个目录…...

【操作系统】——调度
🌹😊🌹博客主页:【Hello_shuoCSDN博客】 ✨操作系统详见 【操作系统专项】 ✨C语言知识详见:【C语言专项】 目录 处理机调度的概念、层次 进程调度的时机、切换与过程、方式 调度器和闲逛进程 处理机调度的概念、层…...
)
保姆级教程:用Docker Compose一键部署带中文界面的n8n(附汉化包下载)
企业级自动化神器n8n的Docker Compose全栈部署指南 在当今数字化转型浪潮中,自动化工作流工具已成为企业提升效率的刚需。n8n作为一款开源的节点式工作流自动化平台,凭借其强大的集成能力和可视化操作界面,正在技术圈掀起一场效率革命。本文将…...

React-Grid-Layout终极指南:三步构建专业级可拖拽网格布局
React-Grid-Layout终极指南:三步构建专业级可拖拽网格布局 【免费下载链接】react-grid-layout A draggable and resizable grid layout with responsive breakpoints, for React. 项目地址: https://gitcode.com/gh_mirrors/re/react-grid-layout React-Gri…...

终极指南:如何实时监控Slonik连接池状态与性能指标
终极指南:如何实时监控Slonik连接池状态与性能指标 【免费下载链接】slonik A Node.js PostgreSQL client with runtime and build time type safety, and composable SQL. 项目地址: https://gitcode.com/gh_mirrors/sl/slonik Slonik作为一款为Node.js打造…...

AI编程助手Trae使用详解
Trae是字节跳动推出的AI原生集成开发环境,支持macOS和Windows双平台,内置Claude-3.5、GPT-4o、DeepSeek等顶级AI模型,具备代码补全、智能问答等核心功能。相比传统编辑器,Trae的最大特点是深度集成了AI协作能力,可以实…...

揭秘C++多态:动态行为的核心奥秘
C 多态:面向对象的动态行为核心机制多态性是面向对象编程(OOP)的核心概念之一,它允许对象在运行时根据其实际类型表现出不同的行为。在C中,多态性主要通过虚函数(virtual functions)和继承机制实…...

终极Cursor Pro解锁指南:免费体验AI编程助手的完整解决方案
终极Cursor Pro解锁指南:免费体验AI编程助手的完整解决方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached you…...

微信H5支付v3版Java实战:从零构建移动端支付解决方案
1. 微信H5支付的应用场景与优势 移动端支付已经成为现代商业不可或缺的一部分。微信H5支付作为微信支付生态中的重要一环,特别适合那些需要在非微信客户端浏览器中实现支付功能的场景。想象一下这样的画面:用户在手机浏览器中浏览你的电商网站ÿ…...

全能视频下载工具:Video-Downloader让在线视频轻松保存
全能视频下载工具:Video-Downloader让在线视频轻松保存 【免费下载链接】Video-Downloader 下载youku,letv,sohu,tudou,bilibili,acfun,iqiyi等网站分段视频文件,提供mac&win独立App。 项目地址: https://gitcode.com/gh_mirrors/vi/Video-Downloa…...

华为云AI开发认证HCCDA通关指南:从试题解析到实战应用
1. 华为云HCCDA认证:AI开发者的黄金敲门砖 最近两年,AI技术在各行各业的应用越来越广泛,很多开发者都在寻找能够系统学习AI开发的途径。华为云推出的HCCDA(Huawei Cloud Certified Developer Associate)认证࿰…...

资源处理效率工具RePKG:从问题解决到场景创新的实战指南
资源处理效率工具RePKG:从问题解决到场景创新的实战指南 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 在数字创意和开发工作中,我们经常遇到各种专用格式的…...