Merlion笔记(四):添加一个新的预测模型
文章目录
- 1 模型配置类
- 2 模型类
- 3 运行模型:一个简单的例子
- 4 可视化
- 5 定量评估
- 6 定义一个基于预测器的异常检测器
本文提供了一个示例,展示如何向 Merlion 添加一个新的预测模型,遵循 CONTRIBUTING.md 中的说明。建议在阅读本篇文章之前,先查看该 文章,了解如何使用 Merlion 的进行预测。
本文将实现一个预测模型,其预测值正好等于该时间点的前一个观测值。有关更真实的示例,请参阅对 Sarima 的实现。
1 模型配置类
创建新模型的第一步是定义一个配置类,该类继承自 ForecasterConfig:
from merlion.models.forecast.base import ForecasterConfigclass RepeatRecentConfig(ForecasterConfig):def __init__(self, max_forecast_steps=None, **kwargs):super().__init__(max_forecast_steps=max_forecast_steps, **kwargs)
2 模型类
接下来,定义模型本身,该模型必须继承自 ForecasterBase 基类,并实现所有抽象方法。
from collections import OrderedDict
from typing import List, Tupleimport numpy as np
import pandas as pdfrom merlion.models.forecast.base import ForecasterBase
from merlion.utils.time_series import to_pd_datetimeclass RepeatRecent(ForecasterBase):# RepeatRecent 的配置类是上面定义的 RepeatRecentConfigconfig_class = RepeatRecentConfig@propertydef require_even_sampling(self):"""许多预测模型假设输入的时间序列是均匀采样的。这个模型不需要这种假设,因此重写该属性。"""return Falsedef __init__(self, config):"""设置模型配置和其他局部变量。在这里,我们将 most_recent_value 初始化为 None。"""super().__init__(config)self.most_recent_value = Nonedef _train(self, train_data: pd.DataFrame, train_config=None) -> Tuple[pd.DataFrame, None]:# 训练模型。在这里,我们只是收集每个单变量的最新观察值。# 列表推导式,用来遍历 train_data 的每一列(键值对形式)。对于每一列,k 是列名,v.values[-1] # 是该列的最后一个观测值。最终生成一个列表,其中每个元素是 (列名, 最近观测值) 这样的元组。self.most_recent_value = [(k, v.values[-1]) for k, v in train_data.items()]# 模型的目标值是每个时间序列的前一个值,即每一行的预测值是上一时间点的实际值。# 将一个全 0 的数组与 train_data(去掉最后一行后的数据)拼接起来,形成一个新的数组 pred,这个数组的每一行都是前一个时间点的数值。pred = np.concatenate((np.zeros((1, self.dim)), train_data.values[:-1]))train_forecast = pd.DataFrame(pred, index=train_data.index, columns=train_data.columns)# 这个模型没有误差的概念train_stderr = None# 返回训练的预测结果和标准误差return train_forecast, train_stderrdef _forecast(self, time_stamps: List[int], time_series_prev: pd.DataFrame = None, return_prev=False) -> Tuple[pd.DataFrame, None]:# 如果提供了 time_series_prev,则使用其最近的值。否则,使用从训练数据中存储的最近值if time_series_prev is not None:most_recent_value = [(k, v.values[-1]) for k, v in time_series_prev.items()]else:most_recent_value = self.most_recent_value# 预测值只是将最近的一个值重复用于每一个未来的时间点。i = self.target_seq_index # 目标序列的索引datetimes = to_pd_datetime(time_stamps) # 测试序列的时间戳name, val = most_recent_value[i]forecast = pd.DataFrame([val] * len(datetimes), index=datetimes, columns=[name])# 如果需要,给 time_series_prev 的 target_seq_index 预加上“预测”值。if return_prev and time_series_prev is not None:pred = np.concatenate(([0], time_series_prev.values[:-1, i]))prev_forecast = pd.DataFrame(pred, index=time_series_prev.index, columns=[name])forecast = pd.concat((prev_forecast, forecast))return forecast, None3 运行模型:一个简单的例子
尝试在一些实际数据上运行这个模型!我们将首先从 M4 数据集中获取时间序列并将其可视化。
import matplotlib.pyplot as plt
import pandas as pdfrom merlion.utils import TimeSeries, UnivariateTimeSeries
from ts_datasets.forecast import M4time_series, metadata = M4(subset="Hourly")[0]# Visualize the full time series
fig = plt.figure(figsize=(12, 6))
ax = fig.add_subplot(111)
ax.plot(time_series)# Label the train/test split with a dashed line
ax.axvline(time_series[metadata["trainval"]].index[-1], ls="--", lw=2, c="k")plt.show()
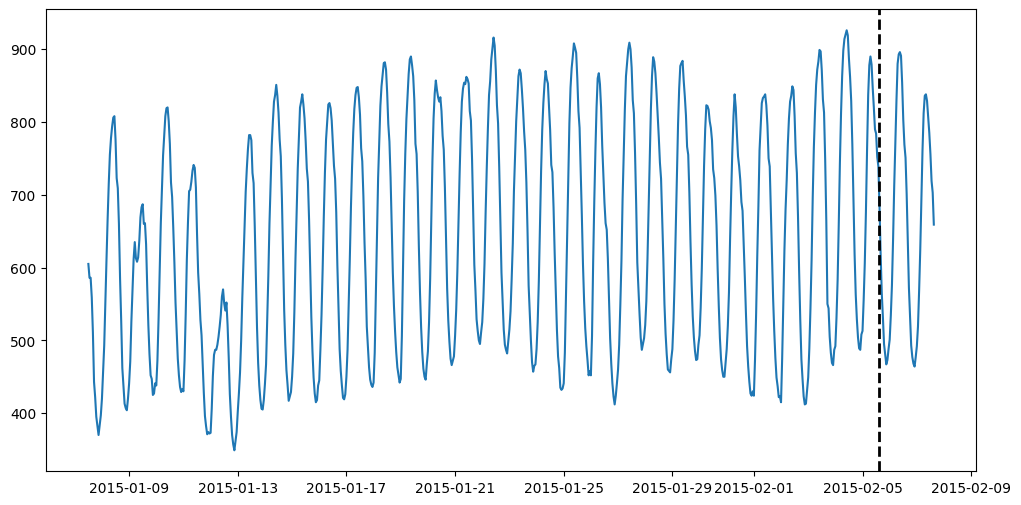
现在,将数据分成训练和测试部分,并在其上运行我们的预测模型。
train_data = TimeSeries.from_pd(time_series[metadata["trainval"]])
test_data = TimeSeries.from_pd(time_series[~metadata["trainval"]])# Initialize a model & train it. The dataframe returned & printed
# below is the model's "forecast" on the training data. None is
# the uncertainty estimate.
model = RepeatRecent(RepeatRecentConfig())
model.train(train_data=train_data)
( H1time 2015-01-07 12:00:00 0.02015-01-07 13:00:00 605.02015-01-07 14:00:00 586.02015-01-07 15:00:00 586.02015-01-07 16:00:00 559.0... ...2015-02-05 11:00:00 820.02015-02-05 12:00:00 790.02015-02-05 13:00:00 784.02015-02-05 14:00:00 752.02015-02-05 15:00:00 739.0[700 rows x 1 columns],None)
# Let's run our model on the test data now
forecast, err = model.forecast(test_data.to_pd().index)
print("Forecast")
print(forecast)
print()
print("Error")
print(err)
ForecastH1
time
2015-02-05 16:00:00 684.0
2015-02-05 17:00:00 684.0
2015-02-05 18:00:00 684.0
2015-02-05 19:00:00 684.0
2015-02-05 20:00:00 684.0
2015-02-05 21:00:00 684.0
2015-02-05 22:00:00 684.0
2015-02-05 23:00:00 684.0
2015-02-06 00:00:00 684.0
2015-02-06 01:00:00 684.0
2015-02-06 02:00:00 684.0
2015-02-06 03:00:00 684.0
2015-02-06 04:00:00 684.0
2015-02-06 05:00:00 684.0
2015-02-06 06:00:00 684.0
2015-02-06 07:00:00 684.0
2015-02-06 08:00:00 684.0
2015-02-06 09:00:00 684.0
2015-02-06 10:00:00 684.0
2015-02-06 11:00:00 684.0
2015-02-06 12:00:00 684.0
2015-02-06 13:00:00 684.0
2015-02-06 14:00:00 684.0
2015-02-06 15:00:00 684.0
2015-02-06 16:00:00 684.0
2015-02-06 17:00:00 684.0
2015-02-06 18:00:00 684.0
2015-02-06 19:00:00 684.0
2015-02-06 20:00:00 684.0
2015-02-06 21:00:00 684.0
2015-02-06 22:00:00 684.0
2015-02-06 23:00:00 684.0
2015-02-07 00:00:00 684.0
2015-02-07 01:00:00 684.0
2015-02-07 02:00:00 684.0
2015-02-07 03:00:00 684.0
2015-02-07 04:00:00 684.0
2015-02-07 05:00:00 684.0
2015-02-07 06:00:00 684.0
2015-02-07 07:00:00 684.0
2015-02-07 08:00:00 684.0
2015-02-07 09:00:00 684.0
2015-02-07 10:00:00 684.0
2015-02-07 11:00:00 684.0
2015-02-07 12:00:00 684.0
2015-02-07 13:00:00 684.0
2015-02-07 14:00:00 684.0
2015-02-07 15:00:00 684.0Error
None
4 可视化
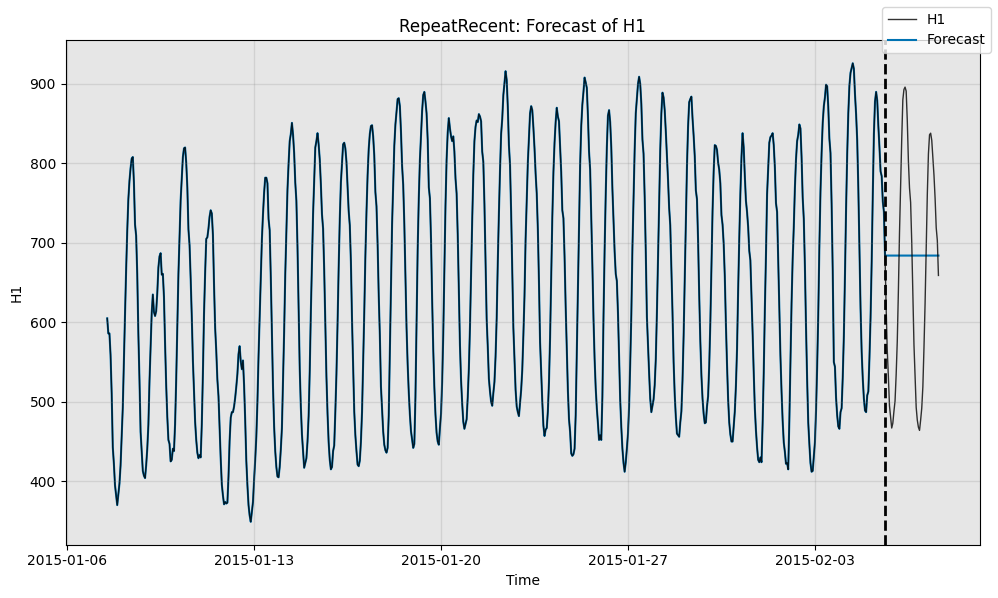
# Qualitatively, we can see what the forecaster is doing by plotting
print("Forecast w/ ground truth time series")
fig, ax = model.plot_forecast(time_series=test_data,time_series_prev=train_data,plot_time_series_prev=True)
plt.show()print()
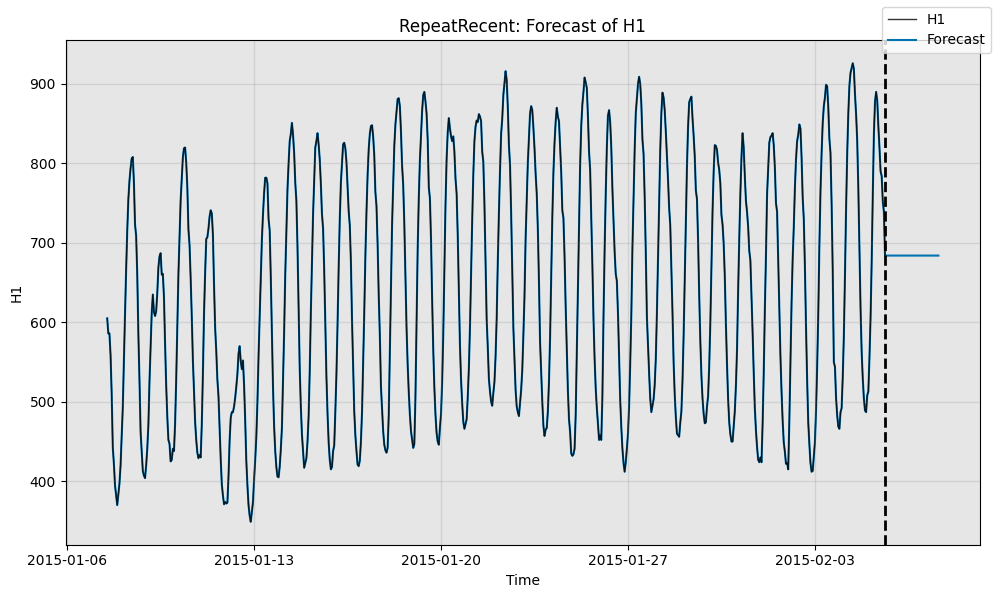
print("Forecast without ground truth time series")
fig, ax = model.plot_forecast(time_stamps=test_data.to_pd().index,time_series_prev=train_data,plot_time_series_prev=True)
Forecast w/ ground truth time series
Forecast without ground truth time series
5 定量评估
也可以对模型进行定量评估。计算模型预测结果与真实数据的对称平均百分比误差(sMAPE,symmetric Mean Average Percent Error)。
from merlion.evaluate.forecast import ForecastMetric
smape = ForecastMetric.sMAPE.value(ground_truth=test_data, predict=forecast)
print(f"sMAPE = {smape:.3f}")sMAPE = 20.166
6 定义一个基于预测器的异常检测器
将一个预测模型转换为异常检测模型是非常简单的。只需要在合适的目录下创建一个新文件,并定义包含一些基本头部的类结构。通过多重继承 ForecastingDetectorBase 类,大部分繁重的工作都可以自动处理。
任何基于预测的异常检测器返回的异常评分,都是基于预测值与真实时间序列值之间的残差。
from merlion.evaluate.anomaly import TSADMetric
from merlion.models.anomaly.forecast_based.base import ForecastingDetectorBase
from merlion.models.anomaly.base import DetectorConfig
from merlion.post_process.threshold import AggregateAlarms
from merlion.transform.normalize import MeanVarNormalize# 定义一个配置类,该类按顺序继承自 RepeatRecentConfig 和 DetectorConfig
class RepeatRecentDetectorConfig(RepeatRecentConfig, DetectorConfig):# 设置一个默认的异常评分后处理规则_default_post_rule = AggregateAlarms(alm_threshold=3.0)# 默认的数据预处理变换是均值-方差归一化,# 这样异常评分大致与 z-score 对齐_default_transform = MeanVarNormalize()# 定义一个模型类,该类按顺序继承自 ForecastingDetectorBase 和 RepeatRecent
class RepeatRecentDetector(ForecastingDetectorBase, RepeatRecent):# 我们只需要设置配置类config_class = RepeatRecentDetectorConfig# Train the anomaly detection variant
model2 = RepeatRecentDetector(RepeatRecentDetectorConfig())
model2.train(train_data) anom_score
time
2015-01-07 12:00:00 -0.212986
2015-01-07 13:00:00 -0.120839
2015-01-07 14:00:00 0.000000
2015-01-07 15:00:00 -0.171719
2015-01-07 16:00:00 -0.305278
... ...
2015-02-05 11:00:00 -0.190799
2015-02-05 12:00:00 -0.038160
2015-02-05 13:00:00 -0.203519
2015-02-05 14:00:00 -0.082679
2015-02-05 15:00:00 -0.349798[700 rows x 1 columns]
# Obtain the anomaly detection variant's predictions on the test data
model2.get_anomaly_score(test_data) anom_score
time
2015-02-05 16:00:00 -0.413397
2015-02-05 17:00:00 -0.756835
2015-02-05 18:00:00 -0.966714
2015-02-05 19:00:00 -1.202032
2015-02-05 20:00:00 -1.291072
2015-02-05 21:00:00 -1.380111
2015-02-05 22:00:00 -1.341952
2015-02-05 23:00:00 -1.246552
2015-02-06 00:00:00 -1.163873
2015-02-06 01:00:00 -0.953994
2015-02-06 02:00:00 -0.686876
2015-02-06 03:00:00 -0.286198
2015-02-06 04:00:00 0.178079
2015-02-06 05:00:00 0.559676
2015-02-06 06:00:00 0.928554
2015-02-06 07:00:00 1.246552
2015-02-06 08:00:00 1.329232
2015-02-06 09:00:00 1.348311
2015-02-06 10:00:00 1.316512
2015-02-06 11:00:00 1.081193
2015-02-06 12:00:00 0.756835
2015-02-06 13:00:00 0.540597
2015-02-06 14:00:00 0.426117
2015-02-06 15:00:00 0.108119
2015-02-06 16:00:00 -0.311638
2015-02-06 17:00:00 -0.712316
2015-02-06 18:00:00 -0.966714
2015-02-06 19:00:00 -1.214752
2015-02-06 20:00:00 -1.316512
2015-02-06 21:00:00 -1.373751
2015-02-06 22:00:00 -1.399191
2015-02-06 23:00:00 -1.316512
2015-02-07 00:00:00 -1.221112
2015-02-07 01:00:00 -1.049393
2015-02-07 02:00:00 -0.737755
2015-02-07 03:00:00 -0.381598
2015-02-07 04:00:00 0.076320
2015-02-07 05:00:00 0.489717
2015-02-07 06:00:00 0.814075
2015-02-07 07:00:00 0.966714
2015-02-07 08:00:00 0.979434
2015-02-07 09:00:00 0.922194
2015-02-07 10:00:00 0.782275
2015-02-07 11:00:00 0.642356
2015-02-07 12:00:00 0.457917
2015-02-07 13:00:00 0.222599
2015-02-07 14:00:00 0.120839
2015-02-07 15:00:00 -0.158999
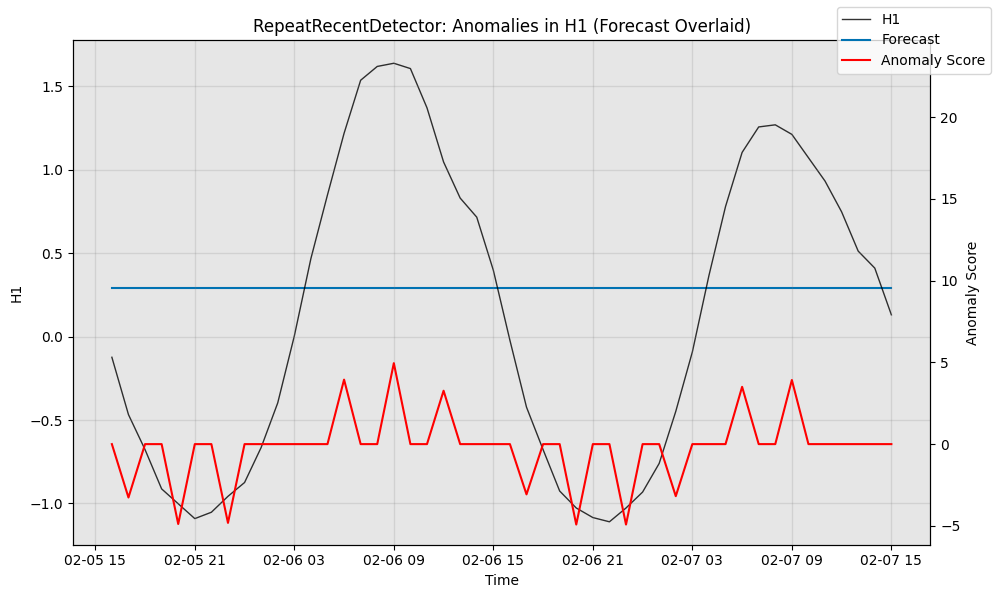
# Visualize the anomaly detection variant's performance, with filtered anomaly scores
fig, ax = model2.plot_anomaly(test_data, time_series_prev=train_data,filter_scores=True, plot_time_series_prev=False,plot_forecast=True)
相关文章:
Merlion笔记(四):添加一个新的预测模型
文章目录 1 模型配置类2 模型类3 运行模型:一个简单的例子4 可视化5 定量评估6 定义一个基于预测器的异常检测器 本文提供了一个示例,展示如何向 Merlion 添加一个新的预测模型,遵循 CONTRIBUTING.md 中的说明。建议在阅读本篇文章之前,先查…...

【论文阅读】ESRGAN
学习资料 论文题目:增强型超分辨率生成对抗网络(ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks)论文地址:[1809.00219] ESRGAN:增强型超分辨率生成对抗网络代码:xinntao / ESRGAN&am…...

电脑异常情况总结
文章目录 笔记本无症状息屏黑屏 笔记本无症状息屏黑屏 🍎 问题描述: 息屏导致黑屏;依次操作计算机--》右键--》管理--》事件查看器--》Windows日志--》系统;从息屏到异常黑屏之间出现了很多错误,如下:事件…...

[项目详解][boost搜索引擎#1] 概述 | 去标签 | 数据清洗 | scp
目录 一、前言 二、项目的相关背景 三、搜索引擎的宏观原理 四、搜索引擎技术栈和项目环境 五、正排索引 VS 倒排索引--原理 正排索引 分词 倒排索引 六、编写数据去除标签和数据清洗模块 Parser 1.数据准备 parser 编码 1.枚举文件 EnumFile 2.去标签ParseHtml(…...

PL/I语言的起源?有C语言,有B语言和A语言吗?为什么shell脚本最开始可能有#!/bin/bash字样?为什么不支持嵌套注释?
PL/I语言的起源 在20世纪50~60年代,当时主流的编程语言是COBOL/FORTRAN/ALGOL等,IBM想要设计一门通用的编程语言,已有的编程语言无法实现此要求,故想要设计一门新语言,即是PL/I. PL/I是Programming Language/One的缩写…...

gin入门教程(3):创建第一个 HTTP 服务器
首先设置golang github代理,可解决拉取git包的时候,无法拉取的问题: export GOPROXYhttps://goproxy.io再查看自己的go版本: go version我这里的版本是:go1.23.2 linux/arm64 准备工作做好之后就可以进行开发了 3.…...

Vue+ECharts+iView实现大数据可视化大屏模板
Vue数据可视化 三个大屏模板 样式还是比较全的 包括世界地图、中国地图、canvas转盘等 项目演示: 视频: vue大数据可视化大屏模板...

el-table 表格设置必填项
el-table 表格设置必填项 要在 el-table 中集成 el-form 来设置必填项,并进行表单验证,可以使用 Element UI 提供的表单验证功能。下面是一个详细的示例,展示了如何在 el-table 中使用 el-form 来设置必填项,并进行验证。 示例代…...

vivo 轩辕文件系统:AI 计算平台存储性能优化实践
在早期阶段,vivo AI 计算平台使用 GlusterFS 作为底层存储基座。随着数据规模的扩大和多种业务场景的接入,开始出现性能、维护等问题。为此,vivo 转而采用了自研的轩辕文件系统,该系统是基于 JuiceFS 开源版本开发的一款分布式文件…...

Vue学习笔记(四)
事件处理 我们可以使用 v-on 指令 (通常缩写为 符号) 来监听 DOM 事件,并在触发事件时执行一些 JavaScript。用法为 v-on:click"methodName" 或使用快捷方式 click"methodName" 事件处理器的值可以是: 内联事件处理器࿱…...

发送短信,验证码
短信 注册阿里云的账号 开通短信服务 测试短信服务是否可用 导入jar <!-- 短信相关 --><dependency><groupId>com.aliyun</groupId><artifactId>aliyun-java-sdk-core</artifactId><version>4.6.0</version><…...

国内大语言模型哪家更好用?
大家好,我是袁庭新。 过去一年,AI大语言模型在爆发式增长,呈现百家争鸣之态。国内外相关厂商积极布局,并相继推出自家研发的智能化产品。 我在工作中已习惯借助AI来辅助完成些编码、创作、文生图等任务,甚至对它们产…...

OTP一次性密码、多因子认证笔记
文章目录 双因子认证(多因子认证)otp算法(ONE-TIME PASSWORD)otp算法大概分为几部 otp的机制服务端客户端(app端)两种主流算法otp流程图 otp是通用的吗 手机验证码天天在用,但是居然不知道这个是otp,伤自尊了,必须弄清原理。 先要知道几个概念…...

玉米生长阶段检测系统源码&数据集全套:改进yolo11-dysample
改进yolo11-DLKA等200全套创新点大全:玉米生长阶段检测系统源码&数据集全套 1.图片效果展示 项目来源 人工智能促进会 2024.10.24 注意:由于项目一直在更新迭代,上面“1.图片效果展示”和“2.视频效果展示”展示的系统图片或者视…...

【机器学习】决策树算法
目录 一、决策树算法的基本原理 二、决策树算法的关键概念 三、决策树算法的应用场景 四、决策树算法的优化策略 五、代码实现 代码解释: 在机器学习领域,决策树算法是一种简单直观且易于理解的分类和回归方法。它通过学习数据特征和决策规则&#…...

P2818 天使的起誓
天使的起誓 题目描述 Tenshi 非常幸运地被选为掌管智慧之匙的天使。在正式任职之前,她必须和其他新当选的天使一样要宣誓。 宣誓仪式是每位天使各自表述自己的使命,他们的发言稿放在 n n n 个呈圆形排列的宝盒中。这些宝盒按顺时针方向被编上号码 1…...

数字信号处理实验简介
数字信号处理(Digital Signal Processing,简称DSP)是电子工程、通信、计算机科学等领域中的一个重要分支,它涉及到对离散时间信号进行分析、处理和合成的理论和方法。数字信号处理课程的实验环节通常旨在帮助学生将理论知识应用于实际问题中,通过实践加深对DSP概念和技术的…...

Flask-SQLAlchemy 组件
一、ORM 要了解 ORM 首先了解以下概念。 什么是持久化 持久化 (Persistence),即把数据(如内存中的对象)保存到可永久保存的存储设备中(如磁盘)。持久化的主要应用是将内存中的数据存储在关系型的数据库中,…...

Could not retrieve mirrorlist http://mirrorlist.centos.org错误解决方法
文章目录 背景解决方法 背景 今天在一台新服务器上安装nginx,在这个过程中需要安装相关依赖,在使用yum install命令时,发生了以下报错内容: Could not retrieve mirrorlist http://mirrorlist.centos.org/?release7&archx8…...

最新PHP网盘搜索引擎系统源码 附教程
最新PHP网盘搜索引擎系统源码 附教程,这是一个基于thinkphp5.1MySQL开发的网盘搜索引擎,可以批量导入各大网盘链接,例如百度网盘、阿里云盘、夸克网盘等。 功能特点:网盘失效检测,后台管理功能,网盘链接管…...

《JVS-APS全景解读:算法驱动+低代码融合的智能排产系统》
引言:制造业排产的“三座大山”制造业生产管理最常被吐槽的三个痛点:紧急插单乱套:销售一个电话进来,计划员就要花半天时间重排所有工序,越改越乱资源冲突频发:设备、模具、人员同时被多个订单争抢…...

C语言编译报错:invalid suffix ‘x‘ on integer constant 的根源剖析与解决之道
1. 当数学思维遇上C语言:为什么"2x"会报错? 刚接触C语言的朋友们经常会遇到一个让人困惑的报错:invalid suffix x on integer constant。这个错误通常出现在类似y 2x-1这样的表达式中。我第一次遇到这个错误时也是一头雾水——数学…...

Apache Ambari入门指南:5分钟快速掌握Hadoop集群管理
Apache Ambari入门指南:5分钟快速掌握Hadoop集群管理 【免费下载链接】ambari Apache Ambari simplifies provisioning, managing, and monitoring of Apache Hadoop clusters. 项目地址: https://gitcode.com/gh_mirrors/am/ambari Apache Ambari是一款强大…...

Meta烧Token成KPI,OpenClaw引发AI成本结构重塑:不拼算力拼效率
Meta内部烧Token成风近日,据The Information报道,Meta公司内部出现了名为“Claudeonomics”(源自Anthropic旗舰产品Claude)的AI token消费排行榜,由员工自愿在公司内网创建,追踪超8.5万名员工的token使用情…...
与版本控制:那些年我们追过的传输请求)
《SAP FICO系统配置从入门到精通共40篇》039、FICO配置传输管理(CTS)与版本控制:那些年我们追过的传输请求
039、FICO配置传输管理(CTS)与版本控制:那些年我们追过的传输请求一、凌晨三点的紧急电话 上个月某个深夜,手机突然狂震。客户生产系统的一个关键成本中心会计凭证突然报错,追溯后发现是某个成本要素类别配置被意外覆盖…...

如何彻底释放华硕笔记本的隐藏性能?G-Helper轻量控制工具全解析
如何彻底释放华硕笔记本的隐藏性能?G-Helper轻量控制工具全解析 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, …...

如何将微信读书笔记转化为结构化知识资产:Obsidian Weread插件深度指南
如何将微信读书笔记转化为结构化知识资产:Obsidian Weread插件深度指南 【免费下载链接】obsidian-weread-plugin Obsidian Weread Plugin is a plugin to sync Weread(微信读书) hightlights and annotations into your Obsidian Vault. 项目地址: https://gitco…...
)
告别网络依赖!用Cesium + 离线瓦片打造内网可用的三维GIS应用(保姆级部署教程)
企业级三维GIS离线解决方案:Cesium与本地瓦片深度整合指南 在军工、能源、国土规划等敏感领域,三维地理信息系统往往面临严格的网络隔离要求。传统依赖在线地图服务的GIS方案在这些场景下寸步难行——这不仅是技术问题,更关乎数据主权与业务连…...

如何在5分钟内开始使用LCM:大型概念模型快速入门教程
如何在5分钟内开始使用LCM:大型概念模型快速入门教程 【免费下载链接】large_concept_model Large Concept Models: Language modeling in a sentence representation space 项目地址: https://gitcode.com/gh_mirrors/la/large_concept_model LCM࿰…...

图的基本遍历DFS与BFS
1. 引言 图是一种非常重要的数据结构,广泛应用于社交网络、地图导航、网页链接分析等领域。图的遍历是最基础的操作之一,主要有两种方式: 深度优先搜索 (Depth First Search, DFS) —— 沿着一条路径走到底,再回溯。广度优先搜索 …...