从视频中学习的SeeDo:VLM解释视频并生成规划、代码(含通过RGB视频模仿的人形机器人OKAMI、DexMV)
前言
在此文《UMI——斯坦福刷盘机器人:从手持夹持器到动作预测Diffusion Policy(含代码解读)》的1.1节开头有提到
机器人收集训练数据一般有多种方式,比如来自人类视频的视觉演示
- 有的工作致力于从视频数据——例如YouTube视频中进行策略学习
即最常见的方法是从各种被动的人类演示视频中学习,利用被动的人类演示,先前的工作学习了任务成本函数 [37, 8, 1, 21]、可供性函(affordance function) [2]、密集物体描述符[40, 24, 39]、动作对应 [33, 28] 和预训练的视觉表示 [23-R3m: A universal visual representation for robot manipulation,48-Masked visual pre-training for motor control]- 然而,这种方法遇到了一些挑战
首先,大多数视频演示缺乏明确的动作信息(这对于学习可推广的策略至关重要)
为了从被动的人类视频中推断动作数据,先前的工作采用了手部姿态检测器 [44-Mimicplay: Long-horizon imitation learning by watching human play, 1-Human-to-robot imitation in the wild, 38-Videodex: Learning dexterity from internet videos, 28- Dexmv: Imitation learning for dexterous manipulation from human videos],或将人类视频与域内遥操作机器人数据结合以预测动作 [33, 20, 34, 28]
其次,人类和机器人之间明显的embodiment(物理本体,有的翻译为体现)差距阻碍了动作转移(the evident embodiment gap between humans and robots hinders action transfer)
弥合这一差距的努力包括通过手势重定向学习人类到机器人的动作映射 [38-Videodex: Learning dexterity from internet videos, 28-Dexmv: Imitation learning for dexterous manipulation from human videos] ,或提取与体现无关的关键点 [即embodiment-agnostic keypoint,49]
尽管有这些尝试,固有的embodiment差异仍然使得从人类视频到物理机器人的策略转移变得复杂
考虑到
一方面,「从人类视频中学习」早已成为机器人的主流训练方法之一,故打算系统阐述以下这个课题,不然很多朋友可能只是理解其字面意思,但到底具体怎么个模仿学习,则不一定知其里,而通过本文系统的阐述,可以让大家更深刻的理解模仿学习背后更深的细节
二方面,上面不是提到了从人类视频学习中的诸多问题么,那我们也看看该领域的最新进展——比如纽约大学的SeeDo到底有没解决这些问题呢?(当然,你也可以直接看本文的第三部分 SeeDo)
故便有了本文,本文将逐一解读以下这几篇paper
- Learning by Watching: Physical Imitation of Manipulation Skills from Human Videos,18 Jan 2021
- DexMV,12 Aug 2021
- DexVIP,1 Feb 2022
- Robotic Telekinesis: Learning a Robotic Hand Imitator by Watching Humans on YouTube,21 Feb 2022
- R3M: Representations for Robots from Real-World Videos,23 Mar 2022
- VideoDex,8 Dec 2022
- MimicPlay,24 Feb 2023
- VLM See, Robot Do: Human Demo Video to Robot Action Plan via Vision Language Model,11 Oct 2024
- 人形机器人OKAMI: Teaching Humanoid Robots Manipulation Skills through Single Video Imitation,15 Oct 2024
第一部分 从Learning by Watching、DexMV到DexVIP
1.1 Learning by Watching: Physical Imitation of Manipulation Skills from Human Videos
来自多伦多大学、天津大学、NVIDIA的研究者(Haoyu Xiong, Quanzhou Li, Yun-Chun Chen, Homanga Bharadhwaj, Samarth Sinha, Animesh Garg)发布了此篇论文:《Learning by Watching: Physical Imitation of Manipulation Skills from Human Videos》

为了从人类视频中实现物理模仿,作者将问题分解为一系列任务:
- 人类到机器人的翻译,即human to robot translation
- 基于无监督关键点的表示学习
unsupervised keypoint-based representationlearning - 以及使用强化学习进行物理模仿,即physical imitation with RL
在此,回顾前两个任务,因为他们的方法是在现有算法基础上构建的
1.1.1 无监督的图像到图像翻译到无监督关键点检测
对于无监督的图像到图像翻译问题——MUNIT

类似于现有的方法 [9], [10],将人类到机器人翻译视为无监督的图像到图像翻译问题
- 具体而言,目标是学习一个模型,将图像从源域X(例如,人类域)翻译到目标域Y(例如,机器人域),而无需配对的训练数据 [12],[26], [29], [30]
- 在作者的方法中,他们采用MUNIT [30] 作为图像到图像翻译网络来实现人类到机器人的翻译
MUNIT通过假设图像表示可以被解构为一个域不变的内容编码(由内容编码器编码)和一个域特定的风格编码(由风格编码器
编码)来学习在两个域之间翻译图像
内容编码器和
在两个域中是共享的,而两个域的风格编码器
和
则不共享权重(相当于完成同一个任务时,内容本质一致,但人动作和机器人动作的风格、形态必然不一样)
为了将图像从一个域翻译到另一个域,作者将其内容编码与从另一个域采样的风格编码结合
且这些翻译/转换是通过学习生成:与目标域中的图像无法区分的图像来实现的(The translations are learned to generate images that are indistinguishable fromimages in the translated domain)
故,给定来自源域X的图像x和来自目标域Y的图像y,在源域中定义对抗性损失为
其中
是图像
的内容编码,针对目标域/机器人域
是图像
的风格编码,针对源域/人类域
是一个生成器,其接收内容编码
和风格编码
作为输入,并生成与源域中分布相似的图像
是一个判别器,旨在区分由
此外,目标域中对抗损失也可以类似地定义
除了对抗损失外,MUNIT还对图像、内容和风格编码应用重构损失,以规范模型学习
- 对于源域,图像重构损失
定义为
- 内容重建损失
定义为
- 风格重建损失
定义为
目标域中的图像重建损失、内容重建损失
和风格重建损失
可以类似地推导出来
最终,训练MUNIT的总损失LMUNIT为
其中、
和
是用于控制各自损失函数相对重要性的超参数
对于无监督关键点检测——Transporter

为了执行控制任务,现有方法通常依赖于基于图像观测的状态表示学习[10], [45]–[48]
- 然而,图像到图像翻译模型生成的图像观测通常只捕捉宏观特征,而忽略了对下游任务至关重要的显著区域中的细节。通过使用特征编码器对翻译后的图像观测进行编码来推导状态表示会导致次优性能
- 另一方面,现有方法也可能受到图像到图像翻译模型生成的视觉伪影的影响
与这些方法相比,作者利用Transporter[41]在无监督的方式下检测每个翻译后视频帧中的关键点。检测到的关键点形成一种结构化表示,捕捉机器人手臂的姿态和交互物体的位置,为下游控制任务提供语义上有意义的信息,同时避免由于图像到图像翻译不完美而导致的视觉伪影的负面影响
为了实现无监督关键点检测的学习,Transporter利用物体在一对视频帧之间的运动,通过在检测到的关键点位置传输特征,将一个视频帧转换为另一个视频帧
- 比如,给定两个视频帧
提取两个视频帧的特征图
和
,并使用关键点检测器
检测两个视频帧的 K 个二维关键点位置
和
- 然后,Transporter 通过在
中抑制
「Transporter then synthesizes the feature map Φ(x, y) by suppressing the feature map of x around eachkeypoint location in Ψ(x) and Ψ(y) and incorporating thefeature map of y around each keypoint location in Ψ(y)」
其中是一个高斯热图,其峰值集中在
中的每个关键点位置
- 接下来,传输的特征
然后定义用于训练Transporter的损失r为
在下一节中,作者利用Transporter模型来检测每个翻译后的视频帧的关键点。检测到的关键点随后被用作定义奖励函数的结构化表示,并作为策略网络的输入,以预测用于与环境交互的动作
1.1.2 整体理解LbW:从人类视频中学习的改进方法
考虑从人类视频中学习机器人操作技能的物理模仿任务。在这种情况下,作者假设可以访问一个单一的人类演示视频,长度为
,展示了一个人类执行特定任务(例如,推一个块)的过程,作者希望机器人从中学习,其中
,
是
的空间大小
作者注意到,人类的动作在他们的设定中并没有提供。故作者的目标是开发一种学习算法,使机器人能够模仿人类演示视频中展示的人类行为
为实现这一目标,作者提出了LbW,一个由三个组件组成的框架:
- 图像到图像的翻译网络
「来自MUNIT [30]」
- 关键点检测器
「来自Transporter的关键点检测器[41]」
- 策略网络
具体如下图所示

给定一个人类演示视频和时间
的当前观测
- 首先对人类演示视频
中的每一帧
应用图像到图像的翻译网络
- 接下来,关键点检测器
作为输入,并提取基于关键点的表示
其中表示关键点的数量
同样,也对当前观测应用关键点检测器
- 为了计算物理模仿的奖励,作者定义了一个距离度量d,用于计算当前观测
,与每个翻译后的机器人视频帧
之间的距离
we define adistance metric d that computes the distances between the keypoint-based representation zt of the current observationOt and each of the keypoint-based representations zEi of the translated robot video frames vE - 最后,策略网络以当前观测
的关键点表示
,该动作用于指导机器人与环境交互
1.1.3 深入LbW细节:使用关键点的无监督域转移及使用强化学习进行物理模仿
首先,使用关键点的无监督域转移
为了从人类视频中实现物理模仿,作者开发了一个感知模块,该模块由一个用于人到机器人翻译的MUNIT模型和一个用于关键点检测的Transporter网络组成,如下图所示

为了训练MUNIT模型,我们首先为源域(即人类域)和目标域(即机器人域)收集训练数据
- 源域包含我们希望机器人学习的人类演示视频
为了增加源域训练数据的多样性以促进MUNIT模型的训练,作者遵循AVID [10]的方法,通过让人类在桌子上随机移动手而不执行任务来收集一些随机数据 - 至于目标域训练数据,作者收集了一些通过让机器人从动作空间中随机采样一系列动作生成的机器人视频
因此,收集机器人视频不需要人类的专业知识和努力
利用来自源域和目标域的训练数据,能够使用之前「1.1.1节第一部分中无监督的图像到图像翻译问题」这个公式
中的总损失LMUNIT并按照该1.1.1节第一部分中描述的训练MUNIT模型以实现人到机器人的翻译
在训练MUNIT模型之后,能够通过结合每个人人演示视频帧的内容代码——由内容编码器编码,和从机器人域随机采样的风格代码——由风格编码器
编码,将人类演示视频
逐帧翻译为机器人演示视频
正如在1.1.1节第二部分 无监督关键点检测中提到的,作者旨在以无监督的方式从翻译的机器人视频中学习基于关键点的表示
为实现这一目标,作者利用Transporter在每个翻译的机器人视频帧中以无监督的方式检测关键点,因为没有可用的关键点标注作为真实值
如下图所示
按照1.1.1节第二部分 无监督关键点检测所述的内容
- Transporter模型将翻译的机器人演示视频帧v和通过应用随机策略收集的机器人视频帧y作为输入,分别提取它们的特征并检测关键点位置
- 然后,Transporter模型重建翻译的机器人演示视频帧
为了训练Transporter模型,作者优化总损失
一旦Transporter模型的训练收敛,就可以使用Transporter模型的关键点检测器Ψ来为翻译的机器人演示视频中的每一帧,以形成关键点轨迹
,并为当前观察
翻译的机器人演示视频的关键点轨迹
为机器人操作任务提供语义上有意义的信息
然后,我们使用它们计算奖励,并使用当前观察
其次,使用强化学习进行物理模仿
为了控制机器人,作者使用强化学习从基于图像的观测中学习一个策略,以最大化学习到的奖励函数的累积值。在他们的方法中,他们将策略学习阶段与基于关键点的表示学习阶段分离
给定转换后的机器人演示视频的关键点轨迹
,和当前观察
——基于关键点的表示
,他们的策略网络 π 输出动作
,该动作将在环境中执行,以获得下一步的观察
「Given the keypoints trajectory {zEi }Ni=1 of the translated robot demonstration video {vEi }Ni=1 and the keypoint-based representation zt of the currentobservation Ot, our policy network π outputs an actionat = π(zt) which is executed in the environment to obtainthe next observation Ot+1」
为了实现物理模仿,他们的目标是最小化代理的关键点轨迹与翻译后的机器人演示视频的关键点轨迹之间的距离「To achieve physical imitation, weaim to minimize the distance between the keypoints trajectory of the agent and that of the translated robot demonstration video」
- 具体来说,他们将奖励
其中和
是平衡两个术语重要性的超参数,上述目标施加在
和
上,其定义如下方程式
其中,
,
之间的距离「r1(t) aims to minimizethe distance between the keypoint-based representation zt of the current observation Ot and the most similar (closest)keypoint-based representation zEp in the keypoints trajectory{zEi }Ni=1 of the translated robot demonstration video {vEi }Ni=1」,而
作者将元组添加到重放缓冲区中
然后,策略网络π原则上可以使用任何RL算法进行训练。在作者的实验中,他们使用Soft-Actor Critic (SAC) [49]作为策略学习的RL算法
// 待更
1.2 DexMV
1.2.1 DexMV的三大构成:计算机视觉系统、仿真系统、演示翻译模块
21年8月份,来自UCSD、La Jolla 92093的研究者(Yuzhe Qin, Yueh-Hua Wu, Shaowei Liu, Hanwen Jiang,Ruihan Yang, Yang Fu, and Xiaolong Wang)提出了Dexterous Manipulation from Videos,简称DexMV,其对应的论文为:《DexMV: Imitation Learning for Dexterous Manipulation from Human Videos》

具体而言
- 首先,DexMV从录制的视频中提取3D手-物体姿态(上图第二行)。与之前使用2-DoF夹持器的模仿学习研究[92,81]不同,他们需要人类视频来指导30-DoF机器人手在3D空间中移动每根手指。解析3D结构提供了关键且必要的信息
- 其次,他们流程中的一个重要贡献是一个新颖的演示翻译方法,它连接了计算机视觉系统和仿真系统
他们提出了一种基于优化的方法,将3D人手轨迹转换为机器人手的演示
具体来说,创新体现在两个步骤中:
a)手部运动重定向方法以获得机器人手部状态
b)机器人动作估计以获取学习所需的动作 - 第三,给定机器人演示,他们在仿真任务中进行模仿学习,且研究并基准测试了通过仅状态[64]和状态-动作[32,66]演示来增强RL目标的算法
总之,DexMV平台包含

- 计算机视觉系统(黄色),作者收集人类操作视频
这些视频涉及操作各种真实物体。在该系统中,构建了一个立方框架(35英寸³),并在顶部前方和顶部左侧安装了两个RealSense D435相机(RGBD相机)
在数据收集过程中,人类将在框架内执行操作任务,例如重新定位糖盒。这些操作视频将通过两个相机记录(前视图和侧视图) - 演示翻译模块(绿色)
从视频中应用3D手-物体姿态估计,随后进行演示翻译以生成机器人演示,然后用于模仿学习 - 仿真系统(蓝色),作者为机器人手设计相同的任务
该仿真系统基于MuJoCo [85]与Adroit Hand[43]构建。作者设计了多个与人类演示对齐的灵巧操作任务。如上图底部所示,作者通过将收集到的(机器人)演示与强化学习相结合来进行模仿学习。一旦策略经过训练,它可以在相同任务下测试不同的目标和物体配置
1.2.2 姿态估计:物体姿态估计、手势估计
在物体姿态估计上
使用6-DoF姿态来表示物体的位置和方向,其中包含平移和旋转
。对于视频中的每一帧
,作者使用在YCB数据集[15]上训练的PVN3D[30]模型来检测物体并估计6-DoF姿态
- 通过将RGB图像和点云作为输入,模型首先估计实例分割掩码
By taking both the RGB image andthe point clouds as inputs, the model first estimates the instance segmentation mask - 然后通过对分割的点云进行密集投票,模型随后预测物体关键点的3D位置
With dense voting on the segmented point clouds, the model then predictsthe 3D location of object key points - 最后,通过最小化PnP匹配误差来优化6-DoF物体姿态
The 6-DoF object pose is optimized byminimizing the PnP matching error
在手势估计上
作者使用MANO模型[67]来表示手部,该模型包括手部姿态参数,用于表示15个关节的3D旋转和根部全局位置
,以及每帧的形状参数
,可以使用手部运动学函数
计算3D手部关节
给定一个视频,使用现成的皮肤分割[41]和手部检测[75]模型来获取手部掩码。作者使用训练好的手部姿态估计模型[47]来预测每一帧t的2D手部关节
和MANO参数
和
,使用RGB图像。我们估计根通过使用由Mt屏蔽的深度图像中心进行关节跟踪
给定每一帧t的初始估计,
,
和相机姿态
,作者将3D手部关节估计表述为一个优化问题
其中,
是一个深度渲染函数[39],
是帧t中的对应深度图。他们最小化2D中的重投影误差,并从深度图中优化手部的3D位置
且上述方程可以通过最小化来自不同相机的目标函数并校准外参,进一步扩展到多相机设置。他们默认使用两个相机来处理遮挡。此外,通过最小化帧间和
的差异来部署后处理程序
1.2.3 演示翻译
常见的模仿学习算法消耗来自专家演示的状态-动作对。它需要机器人的状态和电机的动作作为训练数据,但不直接使用人手的姿态
如下图蓝色框中的运动链所示
尽管机器人和人手都具有相似的五指形态,但它们的运动链不同。人手的MANO模型[67]由15个旋转向量参数化,导致15个球形关节,具有15∗3 = 45个自由度。在模拟中使用的Adroit机器人手[43]具有24个旋转关节和1个自由关节,导致24+1∗6 = 30个自由度。每个指节的手指长度也不同
在DexMV中,作者提出了一种新方法,将以人为中心的姿态估计结果转化为以机器人为中心的模仿数据。具体来说,示范翻译包括两个步骤,如下图中的红框所示

- (i) 手部运动重定向,以对齐人手运动和机器人手运动,尽管它们具有不同的自由度和几何形状
- (ii) 预测机器人动作,即机器人马达的扭矩:在没有任何有线传感器的情况下,需要仅从姿态估计结果中恢复动作
对于手部运动重定向
在计算机图形学和动画中,运动重定向用于将表演者的动作重定向到虚拟角色上,以用于电影和动画等应用[2,31]。虽然动画界强调逼真的视觉效果,但更关注重定向运动在机器人操控背景下的物理效果
也就是说,机器人动作应该是可执行的,并且要遵循电机的物理限制,例如加速度和扭矩。形式上,给定从视频中估计的人手姿态序列,手部姿态重定向可以定义为计算机器人关节角度序列
,其中t是长度为T+1的序列中的步数
将手部姿态重定向表述为一个优化问题
// 待更
1.3 DexVIP
// 待更
第二部分 从Robotic Telekinesis、R3M、VideoDex到MimicPlay
// 待更
第三部分 24年纽约大学最新研究:VLM See, Robot Do
3.1 SeeDo的整体介绍及其与之前工作的对比
受[4-Ok-robot: What really matters in integrating open-knowledge
models for robotics]的启发,24年10月11日,来自纽约大学的研究者们(Beichen Wang, Juexiao Zhang, Shuwen Dong, Irving Fang, Chen Feng)发布此篇论文《VLM See, Robot Do: Human Demo Video to Robot Action Plan via Vision Language Model》
如下图所示,他们设计了一个以VLM为核心的流程,用于解释人类演示视频并为机器人生成任务计划。生成的计划被转换为机器人代码,并部署到模拟和现实世界的机器人中

其与之前工作的区别在于
- 比如Video language planning通过使用一个具身VLM[24-Palm-e: An embodied multimodallanguage model]来构建一个视频-语言规划流程,将长远的语言指令分解为步骤,提示视频模型生成未来的视频回放,并评估当前进度,他们都依赖于人类语言指令来指定任务
SeeDo则探索直接使用真实世界的人类演示视频作为任务规范 - 再比如 Mimicplay: Long-horizon imitation learning by watching human play,提出将模仿学习过程分解为训练一个潜在规划器,以从人类游戏数据中预测手的轨迹,并在机器人数据上训练由规划器指导的模仿策略
虽然其分享了分解规划和动作学习的类似动机,但这项工作专注于规划部分,并采取不同的方法
而SeeDo利用预训练的VLMs直接将人类示范视频解释为文本计划,并将生成的计划处理为LMPs,以调用任何动作原语,无论它们是基于训练的、基于控制的还是预编程的
3.2 SeeDo的三个模块:关键帧选择、视觉感知、VLM推理
进一步,如下图所示,SeeDo由三个模块组成

- 关键帧选择模块
- 视觉感知模块
- VLM推理模块
3.2.1 关键帧选择
在VLM处理视频时,内容长度是一个主要限制。开源VLM通常简单地均匀采样帧[13,45],但这种方法对演示视频效果较差,因为可能会错过显示重要动作的帧
因此,作者采用一种启发式方法,通过检测手速来选择关键帧。手-物体交互在演示视频中至关重要[34,35],他们观察到在拾取或放置物体时,手通常移动得较慢,这为定位关键帧提供了线索。类似的观察在文献中也有报道[50]
具体来说,作者利用一种轻量级方法[51]来检测手并绘制手速随时间变化的图[52]。生成的图经过插值和平滑处理,形成手速的波浪状表示,选择对应于波谷的帧作为关键帧
由于手检测并不总是完美的,一些波谷可能是插值的结果,因此进一步过滤掉噪声关键帧。在VLM推理模块中,作者提示VLM评估这些帧是否包含手-物体交互,结果相当准确
3.2.2 视觉感知
前VLM的视觉缺陷在文献中已有报道[53]。作者也发现VLM常常难以准确确定物体的位置及其空间关系。它们还常常无法在时间上持续区分视觉上相似的物体,这对从人类演示视频中进行规划任务至关重要
为了解决这些问题,作者在SeeDo中引入了一个视觉感知模块,以增强VLM的视觉能力
具体来说,首先指示VLM识别视频中的物体,然后使用开放词汇的目标检测器[54]用于提取第一帧中的目标边界框。这些边界框作为提示用于最新的Segment Anything Model「即SAM2,[55]」进行视频跟踪
生成的跟踪ID和掩码轮廓被标注到先前选择的关键帧上,作为视觉提示[56]。提示过的关键帧随后被交给VLM推理模块
3.2.3 VLM推理
VLM推理模块使用链式思维(即CoT)提示[19]来生成任务规划步骤,作为SeeDo的最终输出
- 对于具体的模型选择,他们选择了GPT-4o作为SeeDo中的VLM,因为其性能优越
- 当然,在研究界使用商业的、闭源的模型并不少见。在机器人学的VLM先前研究中[1,2,3,21,57,58],大多采用了GPT系列或其他闭源模型,如PALM[24,59]
该模块的一个关键设计是将视觉提示整合到推理中。先前的研究表明,为VLM提供包含提示视觉线索的图像对于操控[60]和导航任务[61]是有效的
在SeeDo中,识别物体及理解其空间关系对于解读人类演示视频至关重要,而这通过从视觉感知模块中获得的视频跟踪所衍生的视觉提示得到了极大增强
具体来说,在提示中维持一个从视觉感知模块中获得的物体列表。遮罩轮廓和跟踪ID被用作关键帧中的视觉提示,以帮助物体识别。通过使用轮廓而非完整遮罩,确保了关注的物体在不遮挡其外观的情况下被突出显示。遮罩的中心坐标结合相应的跟踪ID随后被附加到文本提示中,以暗示VLM物体的空间关系
经验上,我们发现这一设计在人类演示视频涉及视觉上相似的物体时,这特别有帮助,例如在玩无色木块时
如下图所示,作者在SeeDo中提供一个CoT提示示例

3.3 计划执行
SeeDo生成的任务计划可以通过任何可以接受文本输入的机器人动作模型逐步无缝处理。具体来说,按照[1]和[21]中的方法,我们使用语言模型程序(LMPs)在Pybullet模拟[62]和实际部署中实现UR10e机器人臂的任务计划
3.4 实验结果及与其他模型的比较
- 在与闭源模型的对比下
将 SeeDo 与闭源的商业模型Gemini 1.5 Pro 进行了比较,该模型被评为视频理解领域的最先进模型 [49]
由于其 API 可以直接接收视频输入,作者对提示进行了轻微调整。除此之外,提示的关键部分与 SeeDo 保持一致 - 在与开源VLM的对比下
作者将 SeeDo 与 LLaVA One Vision [13]和 VILA [45] 进行了比较,这些模型在视频分析基准测试中也名列前茅 [49]。且遵循他们的实践和代码,从每个视频中均匀采样 16 帧作为输入。提示稍作调整以优化其模型的行为。完整的提示将会发布 - 与使用 GPT-4o 的 SeeDo 变体的对比下
由于作者选择 GPT-4o 作为 SeeDo 的 VLM,故他们另外测试了包含 GPT-4o 的三个变体。GPT-4o Init+Final仅以视频的初始帧和最终帧作为输入。其目的是验证视频输入是否必要
且为了消除关键帧选择模块的影响,他们测试了 aGPT-4o Unif.,该变体在没有手动检测的情况下均匀采样 16 帧
至于视觉感知模块,我们比较了不使用视觉提示的 aGPT-4o。这些消融结果分别在表 II 和表 III 中报告
第四部分 OKAMI:从单个RGB视频演示中模仿人类操作的人形机器人
4.1 OKAMI:结合GPT4V的open-world vision能力和重定向
24年10.15,来自UT Austin、NVIDIA Research的研究者们(Jinhan Li, Yifeng Zhu, Yuqi Xie, Zhenyu Jiang, Mingyo Seo, Georgios Pavlakos, Yuke Zhu)提出了OKAMI,其对应的论文为《OKAMI: Teaching Humanoid Robots Manipulation Skills through Single Video Imitation》
其类似之前博客内解读过的humanplus(humanplus基于宇树机器人 侧重全身控制,本OKAMI基于傅里叶机器人 侧重上半身控制)、SeeDo等,OKAMI使具有两个灵巧双手的双足人形机器人能够从单个RGB-D视频演示中模仿操作行为
其使用两阶段过程将人类动作重定向到人形机器人,以在不同初始条件下完成任务
- 第一阶段,处理视频以生成参考操作计划

使用视觉基础模型[15-GPT4V,16-Grounding dino]识别与任务相关的物体,从视频中重建人类动作,并在评估期间定位与任务相关的物体
在测试时定位物体还可以实现运动重定向,以适应不同的背景或同类的新物体实例 - 第二阶段,利用该计划通过运动重定向合成人形机器人的动作,以适应目标环境中的对象位置

简言之,其分别重定向身体动作和手部姿态
细言之,首先从任务空间中的参考计划重定向身体动作,然后根据与任务相关物体的位置扭曲重定向的轨迹,其中身体关节的轨迹通过逆运动学获得
至于,手指的关节角从计划映射到灵巧的手上,重现手-物交互。通过物体感知的重定向,OKAMI策略能够系统性地推广到各种空间布局的物体和场景杂乱中
4.1.1 问题表述与开放世界的定义
问题表述
- 作者将人形操作任务表述为一个离散时间马尔可夫决策过程,由一个元组定义:
,其中
是状态空间,
是动作空间,
是转移概率,
是奖励函数,
是折扣因子,
是初始状态分布
- 在他们的背景下,S是捕捉机器人和物体状态的原始RGB-D观测空间,A是人形机器人运动指令的空间,R是稀疏奖励函数,当任务完成时返回1
解决任务的目标是找到一个策略π,以最大化从µ中抽取的广泛初始配置在测试时的预期任务成功率
那又什么叫做开放世界呢
- 考虑“从观察中模仿开放世界”的设定[4-Vision-based manipulation from single human video with open-world object graphs],其中机器人系统以录制的RGB-D人类视频V作为输入,并返回一个人形操控策略π,完成视频
中演示的任务
此设定为“开放世界”,因为机器人对任务中涉及的对象类别或物理状态没有先验知识或真实信息访问,并且是“从观察中”,因为视频 - 值得注意的是,本文对视频
4.1.2 参考计划生成:先识别、后估计、最后生成计划
为了实现对象感知的重定向,OKAMI首先为人形机器人生成一个参考计划。计划生成涉及理解与任务相关的对象是什么以及人类如何操控它们
首先,在识别和定位任务相关的对象
为了从视频中模仿操作任务,OKAMI必须识别出要交互的任务相关对象。尽管之前的方法依赖于无监督方法与简单背景或需要额外的人为注释[50–53],OKAMI则使用现成的视觉语言模型(VLMs),即GPT-4V,通过利用模型内部化的常识知识来识别视频V中的任务相关对象
- 具体来说,OKAMI通过从视频演示
比如,OKAMI 使用以下prompt来调用 GPT4V,以便从提供的人类视频中识别与任务相关的对象
再比如,识别目标物体
还比如,识别参考物体
- 对于这些对象名称,OKAMI使用Grounded-SAM[16]对第一帧中的物体进行分割,并使用视频对象分割模型Cutie[54]在整个视频中跟踪它们的位置
其次,重建人体动作:相当于人体姿态估计和手势估计
为了将人体动作重新定向到人形机器人,OKAMI从中重建人体动作以获得运动轨迹
作者采用改进版的SLAHMR [55],这是一种重建人体动作序列的迭代优化算法。虽然SLAHMR假设手掌是平的,但他们的扩展优化了SMPL-H模型[56]的手部姿势,这些姿势通过HaMeR [57]估计的手部姿势进行初始化
- 此修改使他们能够从单目视频中联合优化身体和手部姿势。输出是一系列捕捉全身和手部姿势的SMPL-H模型,使OKAMI能够将人体动作重新定向到人形机器人(见第3.2节)
- 此外,SMPL-H模型可以表示跨人口差异的人体姿势,从而能够轻松地将人类演示者的动作映射到类人机器人
具体而言
- 第一步,对于3D人体重建,作者首先通过视频跟踪人物,并使用4D Humans[62]获得其3D身体姿态的初步估计
不过,此身体重建无法捕捉手部姿态的细节(即,手是平的)。因此,对于视频中人物的每次检测,作者使用ViTPose[63]检测双手,并对每只手应用HaMeR [57]以获得3D手部姿态的估计
总之,作者先使用4D Humans提供的3D身体姿态估计和HaMeR提供的3D手部姿态来初始化该过程
然后,使用HaMeR预测的3D手部的2D投影,通过重投影损失来约束整体模型的3D手部关键点的投影(Moreover, we usethe 2D projection of the 3D hands predicted by HaMeR to constrain the projection of the 3D handkeypoints of the holistic model using a reprojection loss)- 第二步,由于由HaMeR重建的手可能与身体重建中的手臂不一致(例如,不同的手腕方向和位置)
故为了解决这一问题,作者应用优化改进,使身体和手在每一帧中保持一致,并鼓励整体身体和手的运动随时间平滑
此优化类似于SLAHMR[55],不同之处在于除了SMPL+H模型[56]的身体姿态和位置外,作者还优化手部姿态
具体而言,其可以在视频的持续时间内联合优化所有参数(身体位置、身体姿态、手部姿态),如SLAHMR [55]中所述
他们修改后的SLAHMR结合了SMPL-H模型[56],以在人体运动重建中包括手部姿势「当然,如上面的第一步所述,每一帧中使用HaMeR[57]提供的3D手部估计来初始化手部姿势」
然后,优化过程共同细化视频序列中的身体位置、身体姿势和手部姿势
这种联合优化允许准确建模手与物体的交互方式,且该优化最小化了来自SMPL-H模型的3D关节的2D投影与从视频中检测到的2D关节位置之间的误差
且使用标准参数和设置,如SLAHMR [55]中所述,并对其进行调整以适应SMPL-H模型至于在推理要求上,使用的人体重建模型很大,需要在计算速度足够快的计算机上运行。他们使用的台式机配备了内存大小为24 GB的GPU RTX3090。对于一个10秒的视频,帧率为30,它处理时间为10分钟
接下来,从视频生成计划
在识别出任务相关的物体并重建人类动作后,OKAMI 从视频中生成一个参考计划,以便机器人完成每个子目标
OKAMI 通过对视频进行时间分割来识别子目标,具体过程如下:
- 首先使用 CoTracker [58] 跟踪关键点,并检测关键点的速度变化以确定关键帧,这些关键帧对应于子目标状态
对于每个子目标,识别一个目标物体(由于操作而运动)和一个参考物体(通过接触或非接触关系为目标物体的运动提供空间参考)
目标物体是基于每个物体的平均关键点速度确定的,而参考物体则通过几何启发式或由 GPT-4V预测的语义关系来识别(有关计划生成的更多实现细节,请参见附录 A.4) - 在确定了子目标和相关对象后,生成一个参考计划
,其中每一步
对应一个关键帧,并包括目标对象
、参考对象
的点云,以及 SMPL-H轨迹段
如果不需要参考对象(例如,抓取一个对象),则
4.1.3 面向对象的重定向:主要是重定位
给定视频演示中的参考计划,OKAMI使人形机器人能够在中模仿任务
机器人通过定位任务相关的对象并将SMPL-H轨迹段重定向到类人机器人上来跟随计划中的每个步骤。重定向的轨迹然后通过逆运动学转换为关节命令。此过程重复进行,直到所有步骤执行完毕,并根据任务特定条件评估成功(见附录B.1)
首先,对于测试时对象定位上
在测试时环境中执行计划时,OKAMI 必须在机器人观察中定位与任务相关的对象,提取三维点云以跟踪对象位置。通过关注与任务相关的对象,OKAMI 策略可以在各种视觉条件下泛化,包括不同的背景或出现新的与任务相关的对象实例
其次,将人类动作重新定向到仿人机器人
对象感知的关键方面是将动作适应于新对象的位置。在定位对象后,作者采用分解的重新定向过程,分别合成手臂和手的动作
- OKAMI首先将手臂动作适应于对象位置,以便手指置于以对象为中心的坐标框架内
为了将身体动作从SMPL-H表示重定向到类人机器人,作者从SMPL-H模型中提取肩部、肘部和手腕的姿势
然后使用逆向运动学来解决类人的身体关节,确保它们产生相似的肩部和肘部方向以及相似的手腕姿势「其中的逆向运动学是使用开源库Pink [64]实现的」
至于用于肩部方向、肘部方向、手腕方向和手腕位置的IK权重分别为 0.04, 0.04, 0.08和 1.0 - 然后,OKAMI只需在关节配置中重新定向手指,以模仿示范者如何用手与对象互动
具体来说,我们首先将人体动作映射到人形机器人的任务空间,调整轨迹以适应尺寸和比例的差异
总之,先通过逆向运动学和角度映射的混合实现,将SMPL-H模型的手部重新定向到机器人的灵巧手,以下是该映射执行的详细信息
一旦从视频演示中获得SMPL-H模型,可以从SMPL-H的手部网格模型中获得3D关节的位置
随后,可以计算每个关节对应于特定手部姿势的旋转角度
然后将计算得到的关节角度应用于一个标准的SMPL-H模型的手部网格,该模型预定义为与类人机器人硬件具有相同的尺寸。从这个标准的SMPL-H模型中,我们可以获得手部关节的3D关键点,并使用现有的包dex-retarget,这是一个现成的优化包,直接计算机器人的手部关节角度[65]
对于逆运动学,要强调的是
在扭曲手臂轨迹后,使用逆向运动学来计算机器人的关节配置
将手部位置的权重分配为 1.0,手部旋转的权重分配为 0.08,优先考虑准确的手部放置,同时允许手臂保持自然姿态。
为了将人类手部姿势重定向到机器人,将人类手部关节角度映射到机器人手部的相应关节。这使得机器人能够复制人类展示的细致操作,例如抓取和物体交互
总之,作者实现确保重定向的动作对机器人在物理上是可行的,并且整体执行在任务上看起来自然且有效 - 接着,OKAMI 对重定向的轨迹进行变形,以便机器人手臂能够到达新的目标位置
作者考虑了轨迹变形的两种情况——当目标物体和参考物体之间的关系状态不变时,以及当其发生变化时,分别对变形进行相应调整
在第一种情况下在变形之后,作者使用逆向运动学计算手臂的关节配置序列,同时在逆向运动学计算中平衡位置和旋转目标的权重,以保持自然的姿势
同时,作者将人类手部姿势重新定位到机器人的手指关节,使机器人能够执行细致的操作 - 最终,获得了一个用于执行的全身关节配置轨迹。由于手臂运动重定向是仿射的,他们的过程自然地扩展和调整来自不同人口特征的示范者的运动
通过将手臂轨迹适应于物体位置并独立重定向手部姿势,OKAMI在各种空间布局中实现了泛化
在轨迹扭曲问题上,再根据原论文额外补充下
- 将机器人轨迹表示为
,其从
重定向
、
分别表示
原始重定向轨迹上的每个点可以通过以下函数描述:
其中,
- 在扭曲轨迹时,只需将轨迹适应新的目标物体位置,或将轨迹适应目标物体和参考物体的新位置,一般而言,将起始点的SE(3)变换表示为
,而终点的SE(3)变换表示为
现在,扭曲的轨迹可以通过以下函数描述:
其中,
通过这种方式,有
请注意,这种轨迹扭曲假设轨迹的终点与起点不同,这是大多数操作行为的常见假设
4.2 机器人动作策略的训练
为了在OKAMI展开中训练神经视觉运动策略
- 作者首先在随机初始化的对象布局上运行OKAMI,以生成多个展开并收集成功轨迹的数据集,同时丢弃失败的
- 然后通过行为克隆算法在此数据集上训练神经网络策略。由于平滑执行对于人形操控至关重要,他们使用ACT [61]实现行为克隆,该算法通过其时间集合设计、轨迹平滑组件预测平滑动作,其中ACT中使用的相关超参数如下图所示
且择预训练的DinoV2 [68,69]作为策略的视觉骨干,该策略以单个RGB图像和26维关节位置为输入,并输出机器人要达到的26维绝对关节位置的动作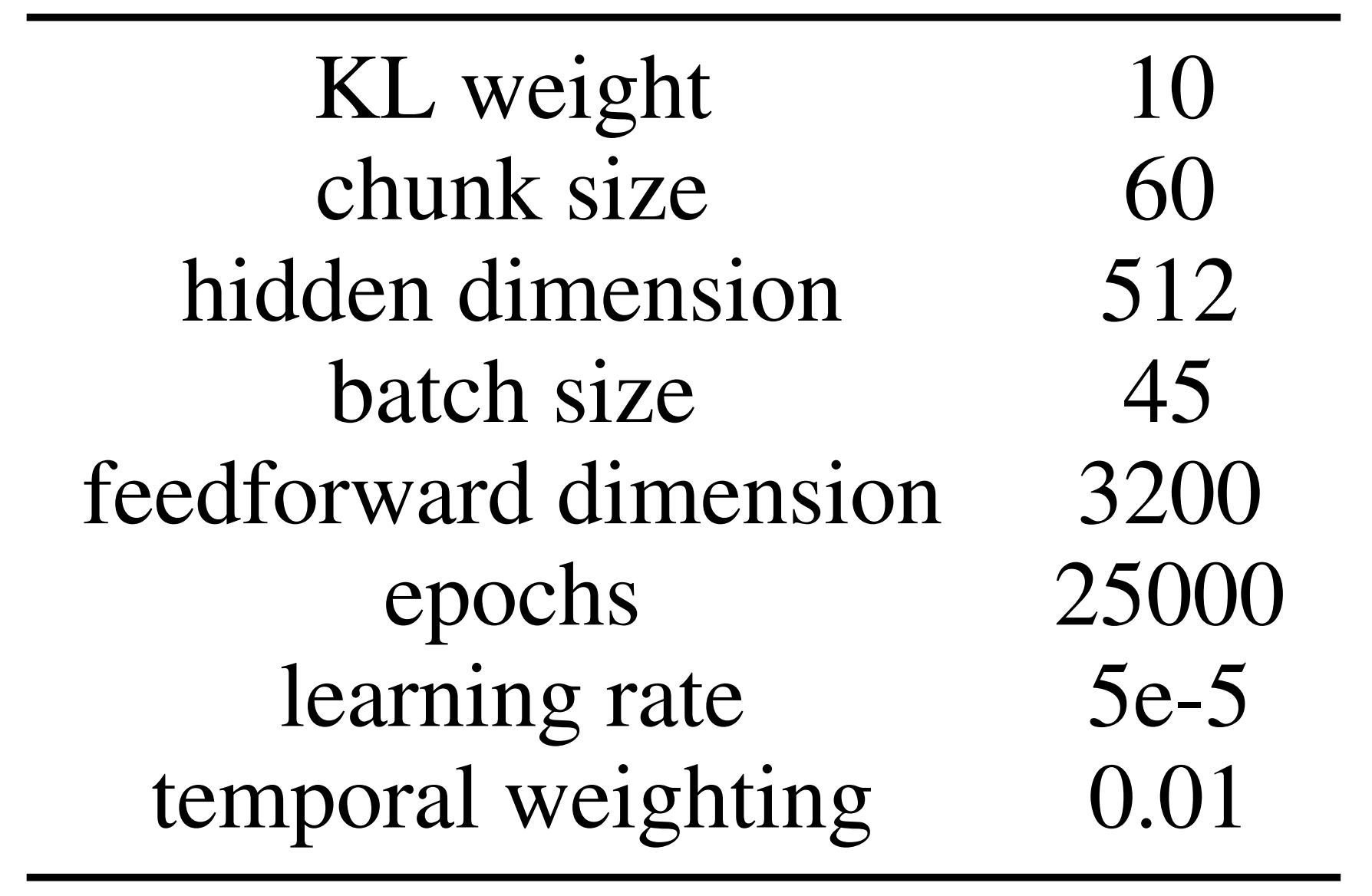
- 此外,随着收集的展开数量增加,学习到的策略会有所改善。这些结果表明可以在不需要繁琐的远程操作的情况下扩展数据收集,以学习人形操控技能的潜力
4.3 实验效果及与基线的对比
在硬件设置上,OKAMI使用Fourier GR1机器人作为硬件平台,配备两个6自由度的Inspire灵巧手和D435i Intel RealSense相机用于视频记录和测试时观察。不过,他们实现了一个以400Hz运行的关节位置控制器。为了避免动作不平稳,他们以40Hz计算关节位置命令,并将这些命令插值到400Hz的轨迹上
在与基线策略ORION的PK上
- 由于ORION是为平行爪夹持器设计的,因此在他们的实验中不能直接适用,故作者对其进行了最小化修改:使用SMPL-H轨迹估计手掌轨迹,并根据新物体位置变形轨迹。变形后的轨迹用于后续的逆运动学中,以计算机器人关节配置
- ORION策略的大多数失败是由于未能以可靠的抓取姿态接近物体(例如,在放置零食在盘子上任务中,ORION试图从侧面抓取零食,而不是像人类视频中那样从上往下抓取),以及未能完全旋转手腕以实现诸如倒水的行为
- 这些行为源于ORION忽略了体现信息,因此在性能上不如OKAMI。OKAMI的优越性能表明,当从人类视频中模仿时,将人类示范者的身体动作重新定位到类人机器人上的重要性
相关文章:
从视频中学习的SeeDo:VLM解释视频并生成规划、代码(含通过RGB视频模仿的人形机器人OKAMI、DexMV)
前言 在此文《UMI——斯坦福刷盘机器人:从手持夹持器到动作预测Diffusion Policy(含代码解读)》的1.1节开头有提到 机器人收集训练数据一般有多种方式,比如来自人类视频的视觉演示 有的工作致力于从视频数据——例如YouTube视频中进行策略学习 即最常见…...

项目集群部署定时任务重复执行......怎么解决???
项目集群部署在不同服务器,导致定时任务重复执行 1、可以在部署时只让一个服务器上有定时任务模块,不过这样如果这台服务器宕机,就会导致整个定时任务崩溃 2、使用分布式锁,使用redis setNX命令加lua脚本在定时任务执行的时候只…...
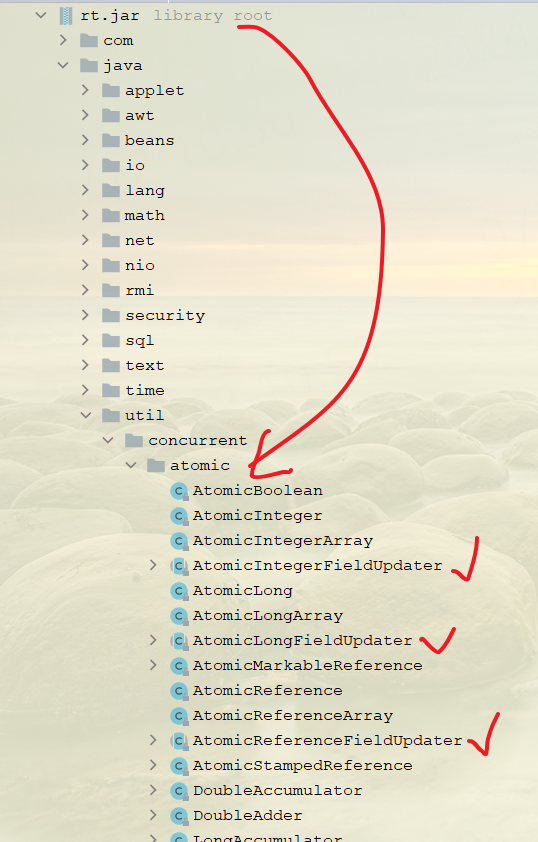
使用JUC包的AtomicXxxFieldUpdater实现更新的原子性
写在前面 本文一起来看下使用JUC包的AtomicXxxxFieldUpdater实现更新的原子性。代码位置如下: 当前有针对int,long,ref三种类型的支持。如果你需要其他类型的支持的话,也可以照葫芦画瓢。 1:例子 1.1:普…...

vue3组件通信--props
目录 1.父传子2.子传父 最近在做项目的过程中发现,props父子通信忘的差不多了。下面写个笔记复习一下。 1.父传子 父组件(FatherComponent.vue): <script setup> import ChildComponent from "/components/ChildComp…...
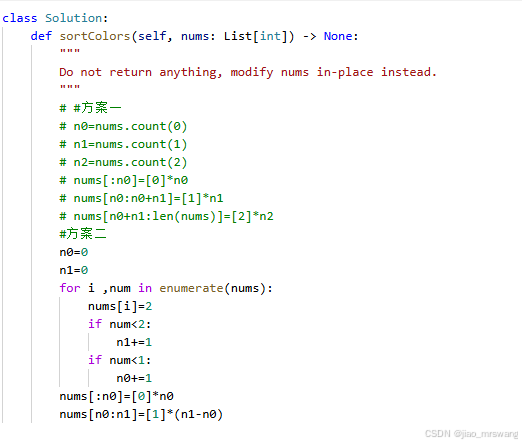
leetcode-75-颜色分类
题解(方案二): 1、初始化变量n0,代表数组nums中0的个数; 2、初始化变量n1,代表数组nums中0和1的个数; 3、遍历数组nums,首先将每个元素赋值为2,然后对该元素进行判断统…...

【嵌入式原理设计】实验三:带报警功能的数字电压表设计
目录 一、实验目的 二、实验环境 三、实验内容 四、实验记录及处理 五、实验小结 六、成果文件提取链接 一、实验目的 熟悉和掌握A/D转换及4位数码管、摇杆、蜂鸣器的联合工作方式 二、实验环境 Win10ESP32实验开发板 三、实验内容 1、用摇杆传感器改变接口电压&…...

C#中的接口的使用
定义接口 public interface IMyInterface {int MyProperty { get; set; }void MyMethod(); } 实现类 internal class MyClass : IMyInterface {public int MyProperty { get; set; }public void MyMethod(){Console.WriteLine("MyMethod is called");} } 目录结构…...
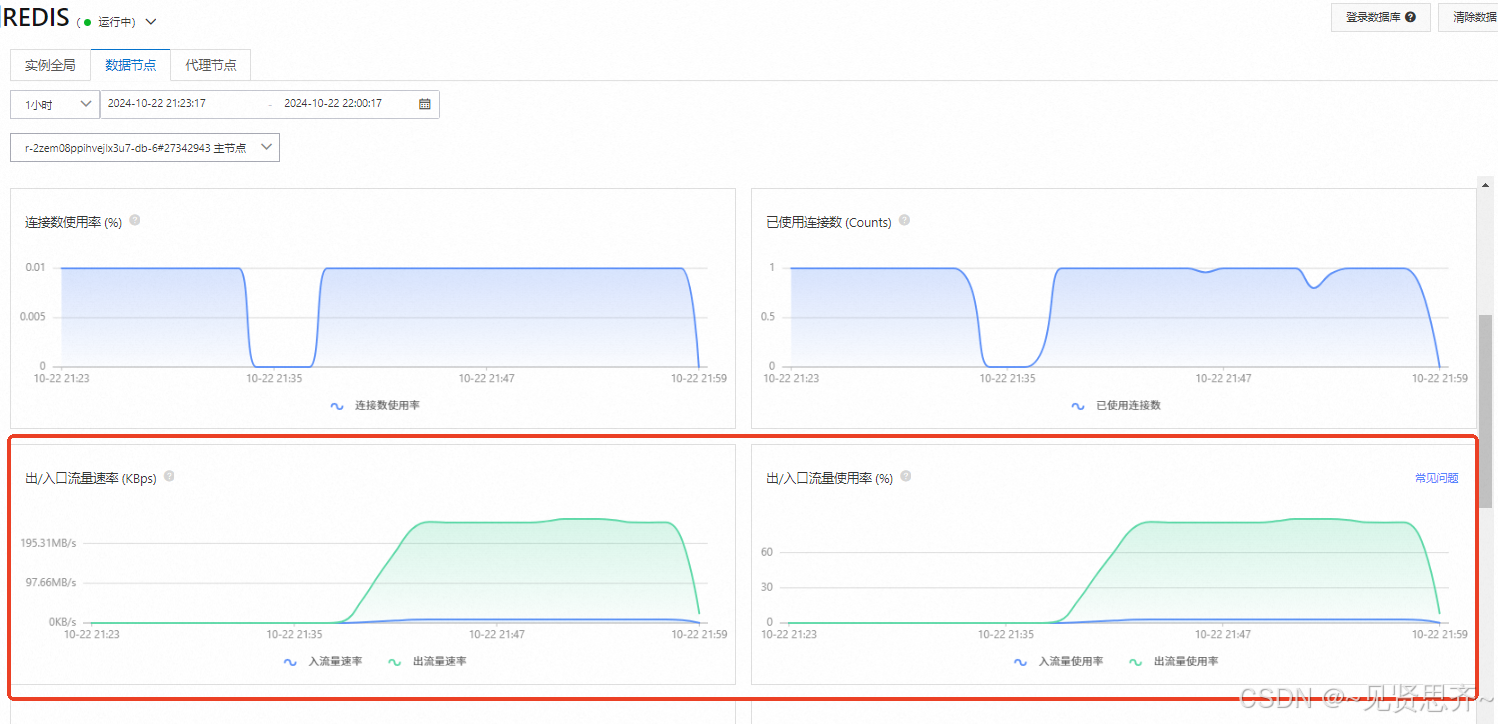
记一次真实项目的性能问题诊断、优化(阿里云redis分片带宽限制问题)过程
前段时间,接到某项目的压测需求。项目所有服务及中间件(redis、kafka)、pg库全部使用的阿里云。 压测工具:jmeter(分布式部署),3组负载机(每组1台主控、10台linux 负载机) 问题现象࿱…...
LeetCode - 4. 寻找两个正序数组的中位数
. - 力扣(LeetCode) 题目 给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。 算法的时间复杂度应该为 O(log (mn)) 。 示例 1: 输入:nums1 …...
算法设计与分析——动态规划
1.动态规划基础 1.1动态规划的基本思想 动态规划建立在最优原则的基础上,在每一步决策上列出可能的局部解,按某些条件舍弃不能得到最优解的局部解,通过逐层筛选减少计算量。每一步都经过筛选,以每一步的最优性来保证全局的最优性…...

【实战篇】GEO是什么?还可以定义新的数据类型吗?
背景 之前,我们学习了 Redis 的 5 大基本数据类型:String、List、Hash、Set 和 Sorted Set,它们可以满足大多数的数据存储需求,但是在面对海量数据统计时,它们的内存开销很大,而且对于一些特殊的场景&…...
SpringBoot最佳实践之 - 项目中统一记录正常和异常日志
1. 前言 此篇博客是本人在实际项目开发工作中的一些总结和感悟。是在特定需求背景下,针对项目中统一记录日志(包括正常和错误日志)需求的实现方式之一,并不是普适的记录日志的解决方案。所以阅读本篇博客的朋友,可以参考此篇博客中记录日志的…...
)
【Flutter】状态管理:高级状态管理 (Riverpod, BLoC)
当项目变得更加复杂时,简单的状态管理方式(如 setState() 或 Provider)可能不足以有效地处理应用中状态的变化和业务逻辑的管理。在这种情况下,高级状态管理框架,如 Riverpod 和 BLoC,可以提供更强大的工具…...

OAK相机的RGB-D彩色相机去畸变做对齐
▌低畸变标准镜头的OAK相机RGB-D对齐的方法 OAK相机内置的RGB-D管道会自动将深度图和RGB图对齐。其思想是将深度图像中的每个像素与彩色图像中对应的相应像素对齐。产生的RGB-D图像可以用于OAK内置的图像识别模型将识别到的2D物体自动映射到三维空间中去,或者产生的…...

smartctl硬盘检查工具
一、smartctl工具简介 Smartmontools是一种硬盘检测工具,通过控制和管理硬盘的SMART(Self Monitoring Analysis and Reporting Technology),自动检测分析及报告技术)技术来实现的,SMART技术可以对硬盘的磁头单元、盘片电机驱动系统、硬盘…...

清空MySQL数据表
要清空 MySQL 数据表,您可以使用 TRUNCATE 或 DELETE 命令 使用 TRUNCATE 命令 TRUNCATE 命令用于删除表中的所有数据,并重置自增 ID(如果存在): TRUNCATE TABLE table_name;将 table_name 替换为您要清空的表的名称…...

2024年妈杯MathorCup大数据竞赛A题超详细解题思路
2024年妈杯大数据竞赛初赛整体难度约为0.6个国赛。A题为台风中心路径相关问题,为评价预测问题;B题为库存和销量的预测优化问题。B题难度稍大于A题,可以根据自己队伍情况进行选择。26日早六点之前发布AB两题相关解题代码论文。 下面为大家带来…...

Kafka系列之:Kafka集群磁盘条带划分和Kafka集群磁盘扩容详细方案
Kafka系列之:Kafka集群磁盘条带划分和Kafka集群磁盘扩容详细方案 一、lsblk命令二、Kafka节点磁盘条带化方案一三、Kafka节点磁盘条带化方案二四、理解逻辑区块LE五、查看kafka节点磁盘条带划分情况六、Kafka节点磁盘扩容一、lsblk命令 lsblk命令用于列出块设备的信息,包括磁…...

【LeetCode】修炼之路-0007- Reverse Integer (整数反转)【python】
题目 Reverse Integer Given a signed 32-bit integer x, return x with its digits reversed. If reversing x causes the value to go outside the signed 32-bit integer range [-231, 231 - 1], then return 0. Assume the environment does not allow you to store 64-b…...
)
【Flutter】页面布局:线性布局(Row 和 Column)
在 Flutter 中,布局(Layout)是应用开发的核心之一。通过布局组件,开发者可以定义应用中的控件如何在屏幕上排列。Row 和 Column 是 Flutter 中最常用的两种线性布局方式,用于水平和垂直排列子组件。在本教程中…...

告别Steam清单配置烦恼:Onekey智能配置工具的优雅解决方案
告别Steam清单配置烦恼:Onekey智能配置工具的优雅解决方案 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 作为游戏开发者或资深玩家,你是否曾因Steam游戏清单配置而头疼…...

雀魂AI助手Akagi:革新麻将竞技的智能决策系统
雀魂AI助手Akagi:革新麻将竞技的智能决策系统 【免费下载链接】Akagi 支持雀魂、天鳳、麻雀一番街、天月麻將,能夠使用自定義的AI模型實時分析對局並給出建議,內建Mortal AI作為示例。 Supports Majsoul, Tenhou, Riichi City, Amatsuki, wit…...

如何将应用程序从三星传输到三星 [快速传输]
升级到像三星 Galaxy S25/S25 Ultra 这样的新手机总是令人兴奋的,但当涉及到将应用程序等数据从旧三星手机传输到新三星手机时,就会变得棘手。在新三星手机上手动安装 Play 商店中所有常用的应用程序非常耗时。那么,如何高效地将应用程序从三…...

【Agent】大模型在线API接入基础入门
大模型在线API接入基础入门一、全球AI模型版图与平台选型1、OpenRouter突破封锁的中转平台2、国内模型生态:性价比与可用性的平衡4、模型选型决策二、获取并保存API KEY三、调用API1、非SDK方式调用2、 OpenAI SDK方式调用(1)什么是SDK&#…...
)
避坑指南:Electron 31.2.0 开发中常见的5个安全与配置陷阱(含解决方案)
Electron 31.2.0 开发实战:5个高频安全陷阱与工程化解决方案 当你第一次用Electron构建跨平台桌面应用时,控制台突然弹出的安全警告是否让你措手不及?本文将揭示Electron 31.2.0版本中最危险的5个配置陷阱,并提供经过生产验证的解…...

释放CPU隐藏性能:CPUDoc的4大核心优化策略
释放CPU隐藏性能:CPUDoc的4大核心优化策略 【免费下载链接】CPUDoc 项目地址: https://gitcode.com/gh_mirrors/cp/CPUDoc 你的电脑是否经常在高负载任务下卡顿?游戏帧率忽高忽低?多任务处理时响应迟缓?CPUDoc作为一款开源…...

Speechless:微博内容永久保存的终极解决方案
Speechless:微博内容永久保存的终极解决方案 【免费下载链接】Speechless 把新浪微博的内容,导出成 PDF 文件进行备份的 Chrome Extension。 项目地址: https://gitcode.com/gh_mirrors/sp/Speechless 当你多年积累的微博内容因平台政策调整突然消…...

个人开发者如何用隧道代理实现“代理自由”?
那个被反爬逼疯的周末去年有个周末,我窝在家里写一个比价脚本。想爬几个主流电商平台的价格数据,做个小工具自己用。代码写得挺顺,Requests库套上代理,循环跑起来。前50次请求一切正常,第51次——啪,403。换…...

用快马AI十分钟搭建班级宠物园应用下载页,快速验证教育产品原型
最近在帮小学老师朋友设计一个班级宠物园应用,想快速验证这个教育产品的可行性。传统开发流程太耗时,于是尝试用InsCode(快马)平台的AI生成功能,十分钟就搭出了可交互的下载页原型。分享下具体实现思路: 需求拆解与框架搭建 先明确…...

终极视频编码神器StaxRip:Windows平台最强大GUI工具完全指南
终极视频编码神器StaxRip:Windows平台最强大GUI工具完全指南 【免费下载链接】staxrip 🎞 Video encoding GUI for Windows. 项目地址: https://gitcode.com/gh_mirrors/st/staxrip 🎞️ 你是否正在寻找一款功能强大、灵活高效的视频编…...