OpenAI GPT-o1实现方案记录与梳理
- 本篇文章用于记录从各处收集到的o1复现方案的推测以及介绍
目录
- Journey Learning - 上海交通大学+NYU+MBZUAI+GAIR
- Core Idea
- Key Questions
- Key Technologies
- Training
- Inference
- A Tutorial on LLM Reasoning: Relevant methods behind ChatGPT o1 - UCL汪军教授
- Core Idea
- 先导
- 自回归LLM面临的挑战
- 将LLM推理看作是马尔科夫决策过程
- 实现方法
- Pangu-Agent: A Fine-Tunable Generalist Agent with Structured Reasoning
- Core Idea
Journey Learning - 上海交通大学+NYU+MBZUAI+GAIR
- github:https://github.com/GAIR-NLP/O1-Journey#about-the-team
- paper: https://github.com/GAIR-NLP/O1-Journey/blob/main/resource/report.pdf
Core Idea
- “Journey Learning,” was proposed to teach models to learn through trial and error rather than shortcuts

Key Questions
- o1的思维链有哪些特征:
- 迭代式
- 关键思维方式:结论、路径、反思、计算
- 递归与反思:经常评估与验证中间结果
- 假设探索
- 结论与验证
- 思维链如何工作?
- 团队给出了自己的猜测
- 如何构建长思维链?(本质上是数据集构建方法)
- 尝试1:基于 LLM 和奖励的树搜索
- 反思回溯 (要求有) 推理树 (需要) 细粒度的奖励模型
- 尝试2:提议 - 批评循环
- 为模型预定义了一些可能的行为(即继续、回溯、反思、终止),并让模型自身选择行为来构建推理树
- 如果树没有达到最终答案,可以将这个负面信号告知模型,引导它反思和纠正其方法
- 尝试3:多智能体方法
- 挑战:基于推理树构建长思维存在许多冗余的无效节点,以及存在不依赖于反思行为的推理步骤,从而引起构建的长思维逻辑不一致
- 多智能体辩论的算法:其中一个智能体充当策略模型,持续推理,而另一个智能体充当评论模型,指示策略模型是否应该继续当前推理或执行回溯等行为。两个智能体进行持续对话,在找到正确答案时自然构建长思维数据集
- 完整的人类思维过程注释:通过记录人类思维过程产生高质量的思维链数据
- 尝试1:基于 LLM 和奖励的树搜索
- 如何构建奖励模型?
- 团队将评估粒度定义在步骤层面
- 如何构建on-policy推理树?
- 如何从推理树中导出长思维链?
- 如何进行评估?
- 如何训练?
- 什么是人类和 AI 协同标注的有效策略?
Key Technologies
- Multi-Agent Debate System
- 包含两个Agents
- Agent#1: 生成推理步骤
- Agent#2: 评价Agent#1生成的推理步骤
- 包含两个Agents
- Reasoning Trees
- 用于表示整个思维过程
- Reward Models Design
- 用于对reasoning tree中的每一个步骤进行评价
Training
- Stage#1: Supervised Fine-Tuning(SFT)
- Phase#1: short-cut reasoning data
- Phase#2: journey learning data
- Stage#2: Direct Preference Optimization(DPO)
- 一次性生成多个回答,学习如何判断回答的正确性与有效性
Inference
- Stage#1: Reasoning Tree Construction
- 构建思维树
- Stage#2: Traversal and Output
- 采用深度优先的方式(DFS)进行推理
A Tutorial on LLM Reasoning: Relevant methods behind ChatGPT o1 - UCL汪军教授
- github: https://github.com/openreasoner/openr/blob/main/reports/Tutorial-LLM-Reasoning-Wang.pdf
Core Idea
- o1 的训练使用了强化学习技术,通过显式地嵌入一个**原生「思维链」(NCoT)**过程,可出色地完成复杂的推理任务
- 范式转变:从快速、直接的反应转向缓慢、深思熟虑、多步骤的推理时间计算

- 疑问与思考:不同的研究者对快慢推理有着很不一样的理解,例如汪教授认为原来的direct autoregressive model就是快推理;而部分研究者从模型的角度进行划分,大模型是慢推理,小模型是快推理
先导
- 思维链方案能够提升大语言模型的执行能力并不是才出现(COT,TOT等);同时,你也可以通过简单的prompt使(o1前)时代的LLM输出思维过程,从而提升整体表现
- 这些方法都基于已有的 LLM,并没有将思维链嵌入到模型本身之中。因此,LLM 无法内化这种学习能力
- 之前人们提出的方法包括收集专门的训练数据、构建奖励模型和增加解码的计算复杂度,但目前还没有一种方法能大规模地在性能上取得重大突破
- 注意:由于OpenAI不再Open,汪军教授表示,我们目前尚不清楚 OpenAI 的 o1 创新是否植根于模型本身,还是依然依赖于外部提示系统。如果它确实涉及在架构中明确嵌入分步推理,那么这将是一个重大突破
- OpenAI表示:“传统上在训练期间应用的扩展原则现在也与推理阶段相关了”
- 算力(重心)逐渐向推理过度
- 如果LLM能够在推理过程中提升自己的能力,那么就是向**自我改进式智能体(self-improving agent)**迈出的重要一步
- 汪军教授表示:这个研究方向暂且称为 LLM 原生思维链(LLM-Native Chain-of-Thought/NativeCoT),其应当能够固有地反映人类系统2思维所具有的深思熟虑的分析过程。
自回归LLM面临的挑战
- 自回归LLM以预测下一个token为目标
- 汪军教授表示,仅仅专注于预测下一个词会限制智能的潜力。为了得到更深层次的智能,可能需要不同的优化目标和学习范式
- 如何使系统超越其训练数据的界限并开发出新颖的、可能更优的策略?
- 汪军教授:如果使用数据来开发更深度的理解或世界模型,就有可能实现复杂策略的演进,进而超越训练数据的限制
- 世界模型(World Model)
- 代表了智能体对环境的理解
- 基于模型的策略(如蒙特卡洛树搜索 (MCTS))是这种方法的经典例证。向系统 2 型推理的过渡(o1 可能就是一个例证)依赖于建立某种类型的世界模型并利用强化学习(奖励最大化),而不仅仅是最小化预测误差。这种方法的转变可能是 OpenAI o1 强大推理能力背后的关键过渡技术之一
- 通过将 LLM 的预测能力与强化学习和世界建模的策略深度相结合,像 o1 这样的 AI 系统可以解决更复杂的问题和实现更复杂的决策过程。这种混合方法既可以实现快速模式识别(类似于系统 1 思维),也可以实现深思熟虑的逐步推理(系统 2 思维的特征)。
- 巨大的计算复杂性
- LLM 运行时受到二次计算复杂性的约束(Transformer架构)。当 LLM 遇到多步数学难题时,这种约束会变得尤为明显
- 思维链却有望减轻这一限制
- 尽管该方法颇具潜力,但它仍然不是一个完全动态的内存系统,并且没有原生地融入解码阶段。这种必要性使得研究社区亟需超越当前 Transformer 解码器网络能力的高级计算架构。
- 需求:在推理和解码阶段实现类似于蒙特卡洛树搜索 (MCTS)的基于模型的复杂策略。
- 这种先进的推理时间计算系统将使 AI 模型能够维护和动态更新问题空间的表征,从而促进更复杂的推理过程(汪军教授这里提到了Working Memory这个概念)
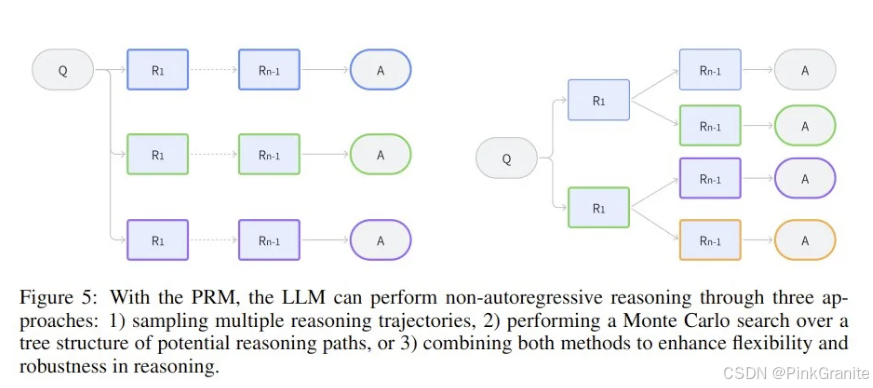
将LLM推理看作是马尔科夫决策过程
- 为了建模问答或问题解答等任务中的推理过程,这里将推理的结构调整成 Q → {R} → A 序列的形式
- Q:表示启动推理过程的问题或提示词;
- R:表示为了得到解答,模型生成的中间推理步骤的序列;
- A:表示推理步骤完成后得到的最终答案或解。
- 汪军教授表示,可以将该推理过程定义为一个马尔可夫决策过程(MDP)
- MDP 能为建模推理提供一个灵活的框架。它允许模型自回归地生成迈向最终答案的顺序推理步骤,同时还通过在每个步骤采样多条路径来实现树结构以获得备选推理轨迹。
- 现在可以使用状态、动作、策略和奖励来描述这个推理过程了。其中 LLM 的任务是逐步生成与推理步骤和最终答案相对应的连贯 token 序列。

- 思考:
- 这里可以的动作空间只有两个:选择新推理步骤、结束推理(得到final answer)
- 反思在这里没有具体的体现,但带着新的信息回到原来的推理节点是否同样可以被看作是生成新的推理节点?
- 汪军教授有明确的提到树结构,如何在这里得到体现——State相同
- 是否可以认为:旅行推理对State进行了结构化的定义,而汪军教授提出的方法是一种更加宏观的方法——二者是否具有一致性?

- 过程奖励模型(Process Reward Model, PRM)是一种基于强化学习的模型,专注于对中间步骤或过程的质量进行评估和奖励,而不仅仅是对最终结果进行评分。它的目标是鼓励系统在任务的每个步骤中都做出合理和高质量的决策,从而提高整个任务执行的效率和效果。
- 优势:
- 细粒度反馈:相较于传统的结果奖励模型,针对执行过程提供持续的反馈
- 加快学习速度:更早地提供奖励信号
- 稳定性更高:能过缓解仅依赖最终奖励导致的奖励稀疏问题,减少陷入局部最优解的风险
实现方法
- 核心步骤
-
- 收集中间推理数据
-
- 训练过程奖励模型PRM
-
- 利用PRM来训练LLM
-
- 在解码阶段引导推理过程
-
- 自动获取推理步骤数据
- Self-Taught Reasoner (STaR): 一种无需人类监督,有效的收集数据和提升 LLM 推理的方法
- “The STaR (Self-Taught Reasoner) method is a technique used to improve the reasoning capabilities of language models. It works by having the model generate intermediate reasoning steps (called rationales) for given problems, which helps it learn how to solve more complex tasks. Initially, the model is trained to solve problems and generate reasoning steps. If it fails, it reviews its own rationales, refines them, and learns from the corrected version. This iterative process helps improve the accuracy and reliability of the model’s reasoning abilities over time.”

- 要求:1. LLM有能力生成中间步骤;2. LLM能够通过自己的策略验证正确性
- 收集到的 {Q, {R}, A} 就可进一步用于训练策略 π_LLM,提升有效推理步骤的生成过程
- 当推理序列较长时,还会用到蒙特卡洛树搜索(MCTS)
- Self-Taught Reasoner (STaR): 一种无需人类监督,有效的收集数据和提升 LLM 推理的方法
- 自我增强式训练

- 在训练时:LLM基于policy进行生成;PRM进行评价
- Stage1: PRM价值迭代:训练世界模型——过程奖励模型(PRM)
- 目标:构建引导搜索、推理和解码过程的通用奖励模型——通常被称为验证器vPRM
- 训练方式一:使用有标注的推理步骤数据集进行训练。其训练通常涉及根据推理步骤的正确性优化一个分类损失函数
- 训练方式二:将PRM视为一个可迭代价值函数(贝尔安方程-递归关系)——预测累积奖励,通过选择最佳动作指导推理过程
- 目标:学习一个由 θ \theta θ参数化的价值函数 V θ ( s ) V_\theta(s) Vθ(s),其中 s s s是当前的状态,用于预测从状态 s s s开始的预期累积奖励

- 其中 r ( s ) r(s) r(s)是奖励函数,根据中间推理步骤或最终答案的正确性为状态s分配一个标量奖励, γ \gamma γ是折扣因子,决定了未来奖励的相对重要性
- 疑问:这里的 a a a表示动作空间,LLM的动作本身只有一个“Text generation”,在这种情况下是否意味着该方法同样需要划分明确的动作空间,是否可以理解为这里是对世界模型的特殊定义——包含反思、推理、计算等“动作”?
- 为了学习 θ \theta θ,TD(时序差分)损失函数定义为:
- Stage 2: LLM的策略迭代
- 分组相对策略优化(Group Relative Policy Optimization - GPRO)
- 假设对于每个问题 Q = q,策略都会生成推理步骤 { o 1 , o 2 , . . . , o G } \{o_1, o_2, . . . , o_G\} {o1,o2,...,oG},每个输出 o i o_i oi由多个步骤 { a i , 1 , a i , 2 , . . . , a i , K i } \{a_{i,1}, a_{i,2}, . . . , a_{i,Ki} \} {ai,1,ai,2,...,ai,Ki} 组成,其中 K i K_i Ki 是输出 o i o_i oi 中的推理步骤(或 token)总数
- 优化策略:

- GRPO 没有将 K L KL KL 惩罚直接纳入奖励,其规范策略的方式是将当前策略 π θ π_θ πθ 和参考策略 π θ r e f π_{θ_{ref}} πθref 之间的 K L KL KL 散度直接添加到损失函数中。这可确保更新后的策略在训练期间不会过度偏离参考策略,从而有助于保持稳定性
- 这种 GRPO 形式是通过利用推理步骤和最终步骤中的分组相对奖励来优化 LLM 策略,专门适用于通过过程奖励模型的推理任务
- 归一化的优势函数(advantage function)是根据相对性能计算的,鼓励策略偏向在一组采样输出中表现更好的输出
- K L KL KL 正则化可确保更新后的策略与参考策略保持接近,从而提高训练稳定性和效率
- 其他策略:token-level DPO(direct preference optimization)—— Token-level direct preference optimization —— 一种区别于RLHF的LLM训练方法
- 分组相对策略优化(Group Relative Policy Optimization - GPRO)
- Stage 3: 推理优化
- LLM 常用的方法是自回归,即根据之前的 token 逐一生成新 token。但是,对于推理任务,还必需更复杂的解码技术
- 使用 MCTS 模型
- MCTS 可模拟多条推理路径,并根据奖励系统对其进行评估,选择预期奖励最高的路径。这允许模型在推理过程中探索更大范围的可能性,从而增加其获得最优解的机会
- 使用 MDP对推理过程结构进行定义
- 原生思维链(Native Chain-of-Thought - NCoT)
- 使LLM在无需外部提示词的情况下自动执行逐步式的结构化推理
- 该能力可以表述为一个马尔可夫决策过程(MDP) ( S , A , π , R ) (S, A, π, R) (S,A,π,R)
- S S S 是状态空间,表示生成到给定位置处的 token 序列或推理步骤
- A A A 是动作空间,由潜在推理步骤 R t R_t Rt 或最终答案 A A A 组成
- π L L M ( a t ∣ s t ) π_{LLM (a_t | s_t)} πLLM(at∣st) 是控制动作选择的策略(也是LLM —— 多LLM),其可根据当前状态 s t s_t st 确定下一个推理步骤或最终答案
- R ( s t a t ) R (s_t a_t) R(stat) 是过程奖励模型(PRM,其作用是根据所选动作 a t a_t at 的质量和相关性分配奖励 r t r_t rt,以引导推理过程
- 该模型既可以通过展开 MDP 来遵循顺序推理路径,也可以通过在每个状态下采样不同的推理步骤来探索多个轨迹(树状推理)


Pangu-Agent: A Fine-Tunable Generalist Agent with Structured Reasoning
- paper: https://arxiv.org/abs/2312.14878
Core Idea
- Structured Reasoning Framework: Pangu-Agent引入了内在和外在函数,将先验知识整合到感知-行动循环中,允许智能体将结构化推理纳入其学习过程。内在功能作用于内部记忆,而外在功能则与环境相互作用。
- 内在函数是修改代理的内部状态或记忆的操作。
- Thinking:基于过去的经验或观察,对某一情况产生高层次的思考
- Planning:组织步骤以有效地解决问题
- Reflection:评估过去的行动,为未来的决策提供信息
- Tool Use:利用诸如代码解释器之类的工具来帮助代理改进其推理
- Communication:与其他代理相互作用,进行合作决策
- 外在功能与主体与外部环境的相互作用直接相关。
- 内在函数是修改代理的内部状态或记忆的操作。
- Modularity and Flexibility: 该框架允许人工智能代理通过监督微调和强化学习微调模块化地适应多个任务。该体系结构旨在创建能够跨各种环境进行交互的通才代理,通过结构化推理提高其性能和适应性。
- Supervised fine-tuning (SFT)
- Reinforcement learning fine-tuning (RLFT)
- Improved AI Agent Performance: 实验表明,结构化推理和微调的使用显著提高了人工智能智能体的适应性和泛化性。得益于结构化的模块化功能和内存管理,代理能够跨各种任务实现更高的成功率。
相关文章:
OpenAI GPT-o1实现方案记录与梳理
本篇文章用于记录从各处收集到的o1复现方案的推测以及介绍 目录 Journey Learning - 上海交通大学NYUMBZUAIGAIRCore IdeaKey QuestionsKey TechnologiesTrainingInference A Tutorial on LLM Reasoning: Relevant methods behind ChatGPT o1 - UCL汪军教授Core Idea先导自回归…...
Excel:vba实现生成随机数
Sub 生成随机数字()Dim randomNumber As IntegerDim minValue As IntegerDim maxValue As Integer 设置随机数的范围(假入班级里面有43个学生,学号是从1→43)minValue 1maxValue 43 生成随机数(在1到43之间生成随机数)randomNumber Application.WorksheetFunctio…...

Python | Leetcode Python题解之第506题相对名次
题目: 题解: class Solution:desc ("Gold Medal", "Silver Medal", "Bronze Medal")def findRelativeRanks(self, score: List[int]) -> List[str]:ans [""] * len(score)arr sorted(enumerate(score), …...
)
安全见闻(6)
声明:学习视频来自b站up主 泷羽sec,如涉及侵权马上删除文章 感谢泷羽sec 团队的教学 视频地址:安全见闻(6)_哔哩哔哩_bilibili 学无止境,开拓自己的眼界才能走的更远 本文主要讲解通讯协议涉及的安全问题。…...

Promise、async、await 、异步生成器的错误处理方案
1、Promise.all 的错误处理 Promise.all 方法接受一个 Promise 数组,并返回所有解析 Promise 的结果数组: const promise1 Promise.resolve("one"); const promise2 Promise.resolve("two");Promise.all([promise1, promise2]).…...

腾讯云:数智教育专场-学习笔记
15点13分2024年10月21日(短短5天的时间,自己的成长速度更加惊人)-开始进行“降本增效”学习模式,根据小米手环对于自己的行为模式分析(不断地寻找数据之间的关联性),每天高效记忆时间࿰…...

Ovis: 多模态大语言模型的结构化嵌入对齐
论文题目:Ovis: Structural Embedding Alignment for Multimodal Large Language Model 论文地址:https://arxiv.org/pdf/2405.20797 github地址:https://github.com/AIDC-AI/Ovis/?tabreadme-ov-file 今天,我将分享一项重要的研…...

python的Django的render_to_string函数和render函数模板的使用
一、render_to_string render_to_string 是 Django 框架中的一个便捷函数,用于将模板渲染为字符串。 render_to_string(template_name.html, context, requestNone, usingNone) template_name.html:要渲染的模板文件的名称。context:传递给…...
基于Python大数据的王者荣耀战队数据分析及可视化系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、Vue项目源码、SSM项目源码、微信小程序源码 精品专栏:…...

【Linux学习】(3)Linux的基本指令操作
前言 配置Xshell登录远程服务器Linux的基本指令——man、cp、mv、alias&which、cat&more&less、head&tail、date、cal、find、grep、zip&tar、bc、unameLinux常用热键 一、配置Xshell登录远程服务器 以前我们登录使用指令: ssh 用户名你的公网…...

Mac 使用脚本批量导入 Apple 歌曲
最近呢,买了一个 iPad,虽然家里笔记本台式都有,显示器都是 2个,比较方便看代码(边打游戏边追剧)。 但是在床上拿笔记本始终还是不方便,手机在家看还是小了点,自从有 iPad 之后&…...

全桥PFC电路及MATLAB仿真
一、PFC电路原理概述 PFC全称“Power Factor Correction”(功率因数校正),PFC电路即能对功率因数进行校正,或者说是能提高功率因数的电路。是开关电源中很常见的电路。功率因数是用来描述电力系统中有功功率(实际使用…...
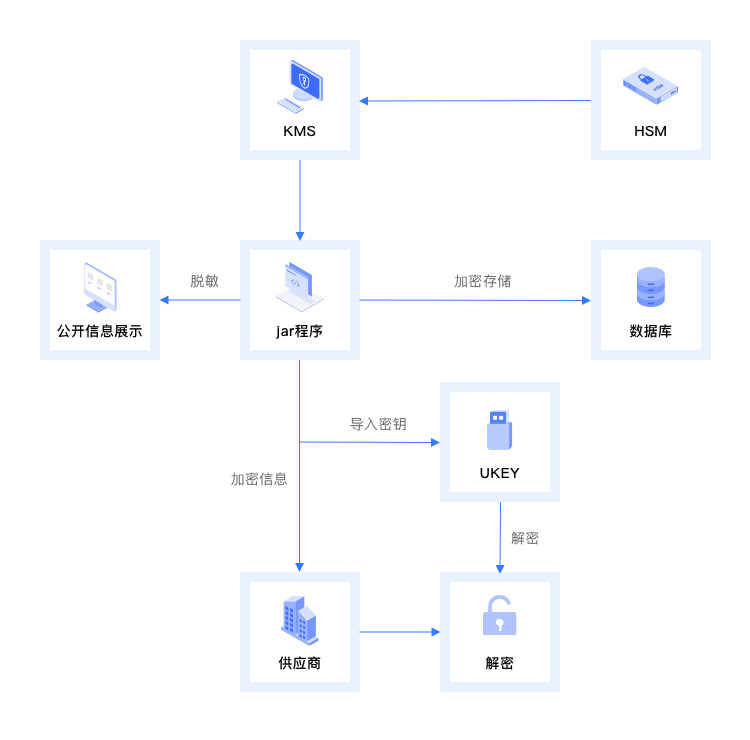
【安当产品应用案例100集】025-确保数据安全传输——基于KMS与HSM的定期分发加密解决方案
引言: 在当今快速发展的数字化时代,企业面临着前所未有的信息安全挑战。尤其是在需要向供应商定期分发敏感数据的情况下,如何保证这些数据在传输过程中的安全性变得至关重要。为此,我们推出了结合安当KMS密钥管理平台与HSM密码机…...

十 缺陷检测解决策略之三:频域+空域
十 缺陷检测解决策略之三:频域空域 read_image (Image, 矩形) * 中间低频,四周高频 fft_image (Image, ImageFFT) * 中间低频,四周高频 fft_generic (Image, ImageFFT1, to_freq, -1, sqrt, dc_center, complex) * 中间高频,四周低频 rft_ge…...

有望第一次走出慢牛
A股已走完30多年历程。 大约每十年,会经历一轮牛熊周期。特点是每一轮周期,大约九成的时间都是熊市主导。就是我们常说的 快牛慢熊。 这一次,会不会重复历史? 历史不会简单重复。已经感受到了盘面的变化。 有人说,股市爆涨爆…...
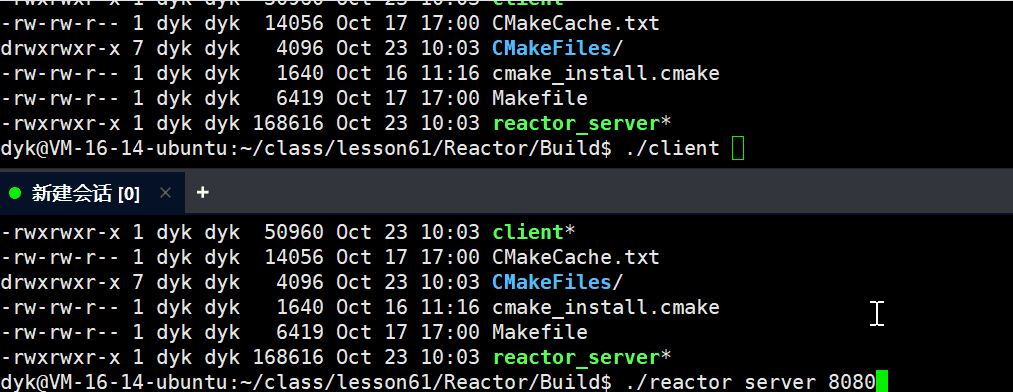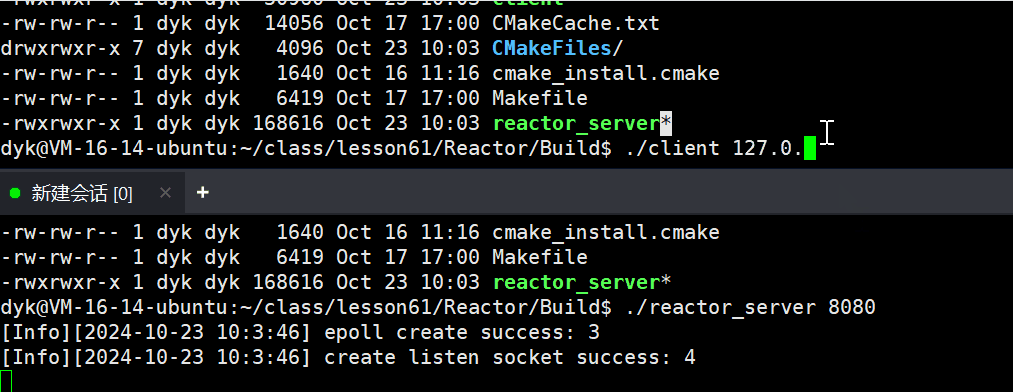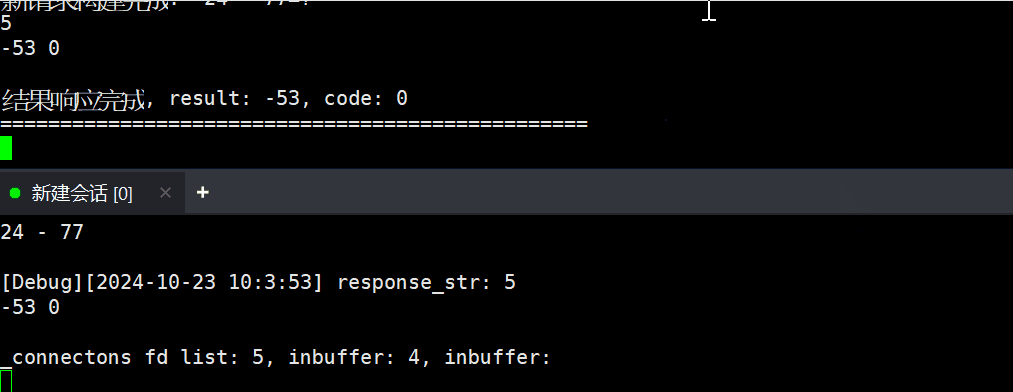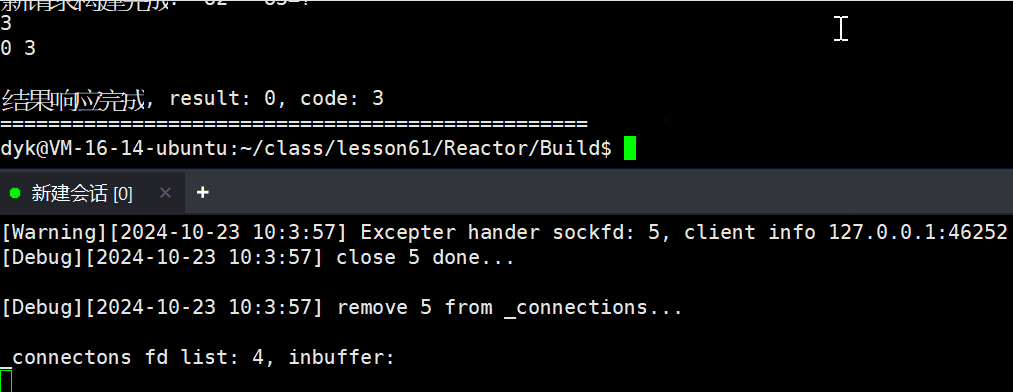
计算机网络(十二) —— 高级IO
#1024程序员节 | 征文# 目录 一,预备 1.1 重新理解IO 1.2 五种IO模型 1.3 非阻塞IO 二,select 2.1 关于select 2.2 select接口参数解释 2.3 timeval结构体和fd_set类型 2.4 socket就绪条件 2.5 select基本工作流程 2.6 简单select的服务器代…...

电力行业 | 等保测评(网络安全等级保护)工作全解
电力行业为什么要做网络安全等级保护? 电力行业是关系到国家安全和社会稳定的基础性行业,电力行业信息化程度相对较高,是首批国家信息安全等级保护的重点行业。 01 国家法律法规的要求 1994《计算机信息系统安全保护条例》(国务…...

总裁主题CeoMax-Pro主题7.6开心版
激活方式: 1.授权接口源码ceotheme-auth-api.zip搭建一个站点,绑定www.ceotheme.com域名,并配置任意一个域名的 SSL 证书。 2.在 hosts 中添加:127.0.0.1 www.ceotheme.com 3.上传class-wp-http.php到wp-includes目录ÿ…...

深入探讨编程的核心概念、学习路径、实际应用以及对未来的影响
在当今这个数字化时代,编程已成为连接现实与虚拟世界的桥梁,它不仅塑造了我们的生活方式,还推动了科技的飞速发展。从简单的网页制作到复杂的人工智能系统,编程无处不在,其重要性不言而喻。本文旨在深入探讨编程的核心…...
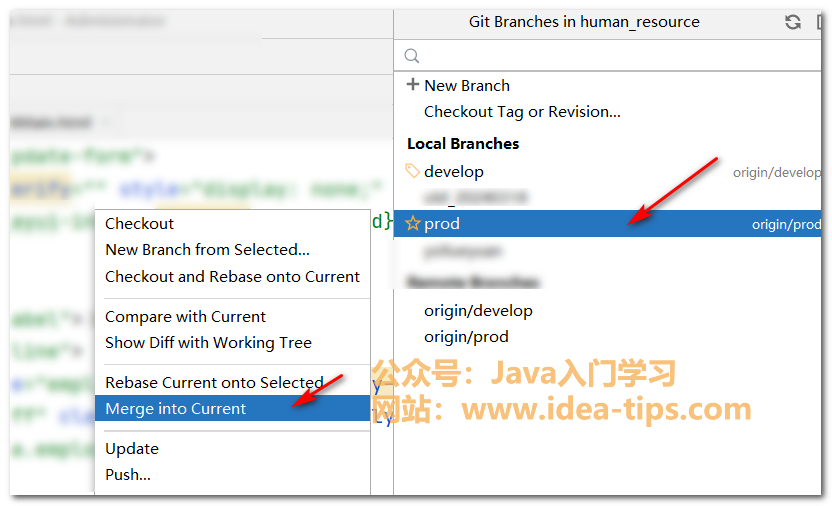
IDEA如何将一个分支的代码合并到另一个分支(当前分支)
前言 我们在使用IDEA开发Java应用时,经常是和git一起使用的。我们对于git常用的操作包括提交,推送,拉取代码等。还有一个重要的功能是合并代码。 那么,我们应该如何合并代码呢? 如何合并代码 首先,我们…...
)
ROS路径规划实战:用move_base让机器狗在Gazebo中自主导航(避坑指南)
ROS路径规划实战:用move_base让机器狗在Gazebo中自主导航(避坑指南) 当机器狗在仿真环境中流畅地绕过障碍物走向目标点时,那种成就感就像看着自家宠物第一次成功接住飞盘。作为ROS开发者,掌握move_base实现自主导航的能…...

成长规划师 - OpenClaw助力个人发展
每周进步1%,一年后你会比现在优秀37倍你有没有过这样的感觉: 一周忙忙碌碌,周五回顾时却想不起做了什么重要的事?年初立下的flag,到了年底发现一个都没实现?羡慕别人技能满满,自己却不知道从哪里…...
)
OpenLayers飞机航线动画实战:如何让SVG图标随航线动态转向(附完整代码)
OpenLayers飞机航线动画实战:SVG图标动态转向与轨迹平滑渲染技术解析 在航空监控、物流追踪等地理信息系统中,飞机或运输工具的实时轨迹展示一直是核心需求。传统静态路径显示已无法满足现代交互需求,如何实现图标随航线动态转向的平滑动画成…...

CasRel在电商商品知识图谱中的应用:标题-品牌-品类-功效三元组生成
CasRel在电商商品知识图谱中的应用:标题-品牌-品类-功效三元组生成 1. 理解CasRel关系抽取模型 CasRel(Cascade Binary Tagging Framework)是一个专门从文本中自动提取结构化信息的智能模型。想象一下,你有一大段描述商品的文字…...

知识管理工具选型指南:从Confluence、语雀到Notion、Sward的深度场景适配
1. 知识管理工具的核心价值与选型逻辑 第一次搭建团队知识库时,我犯了个典型错误——直接选了当时最火的工具。结果三个月后,技术团队抱怨Markdown支持太弱,产品团队嫌弃界面太复杂,最终这个价值十几万的系统成了摆设。这个教训让…...

Matlab与VeriStand无缝集成:开发环境配置全攻略
1. 环境准备:软件安装与版本匹配 搞过Matlab和VeriStand集成的朋友都知道,最头疼的不是写代码,而是环境配置。我当年第一次尝试时,光软件版本兼容性问题就折腾了两天。这里分享几个血泪教训: 首先Matlab和VeriStand的版…...

ncmdumpGUI终极指南:解锁你的音乐收藏,告别NCM格式束缚
ncmdumpGUI终极指南:解锁你的音乐收藏,告别NCM格式束缚 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经遇到过这样的情况&am…...
TranslucentTB:颠覆传统的Windows任务栏透明化解决方案
TranslucentTB:颠覆传统的Windows任务栏透明化解决方案 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 在当今数字化工作环境…...

Qwen2.5-Coder-1.5B应用案例:快速生成网页爬虫代码实战
Qwen2.5-Coder-1.5B应用案例:快速生成网页爬虫代码实战 1. 引言:为什么选择Qwen2.5-Coder生成爬虫代码 在日常开发工作中,网页爬虫是数据采集和分析的重要工具。传统编写爬虫代码需要开发者熟悉HTTP请求、HTML解析、反爬机制处理等多个技术…...
)
告别散斑噪声困扰:用PyTorch手把手实现DenoDet的频域去噪模块(附完整代码)
频域魔法:用PyTorch实现SAR图像去噪的工程实践 当你在处理SAR图像时,是否曾被那些恼人的散斑噪声困扰?这些像胡椒粒一样随机分布的噪声点不仅影响视觉效果,更会严重干扰目标检测的准确性。传统方法试图在空间域直接对抗噪声&#…...