【mysql进阶】4-6. InnoDB 磁盘文件
InnoDB 磁盘⽂件
1 InnoDB存储引擎包含哪些磁盘⽂件?
🔍 分析过程
✅ 解答问题
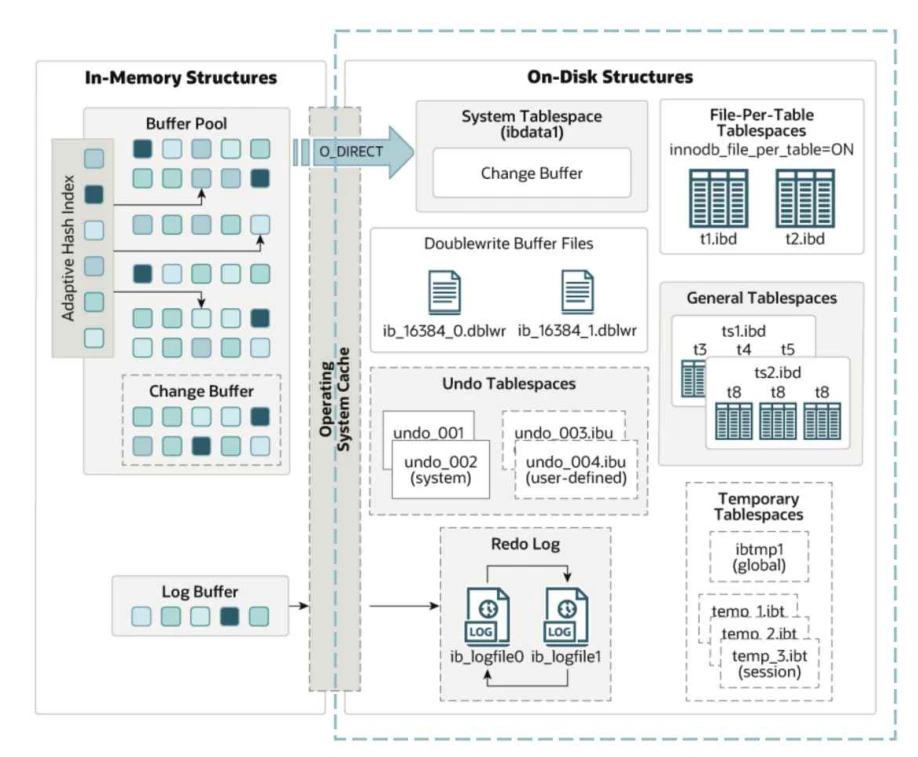
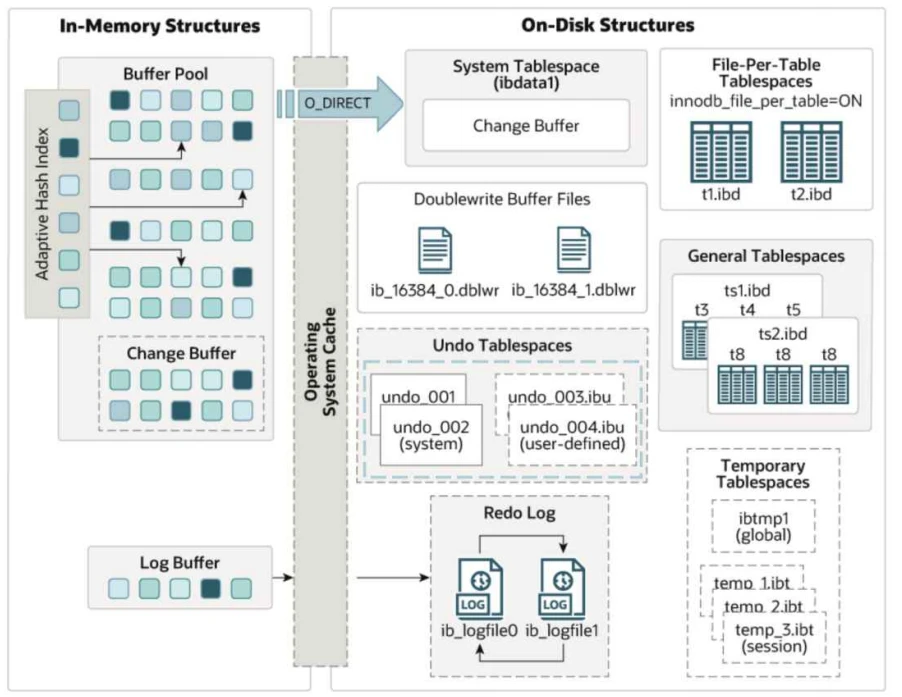
InnoDB的磁盘⽂件主要是表空间⽂件和其他⽂件,表空间包括:系统表空间、独⽴表空间、通⽤表空间、临时表空间和撤销表空间;其他⽂件有重做⽇志和双写缓冲区
1.1 什么是表空间?
- 表空间可以理解为MYSQL为了管理数据⽽设计的⼀种数据结构,主要描述的对结构的定义,表空间⽂件是对定义的具体实现,以⽂件的形式存在于磁盘上,以后我们说的表空间指的就是表空间⽂件
- InnoDB存储引擎的表空间包括:系统表空间、独⽴表空间、通⽤表空间、临时表空间和撤销表空间
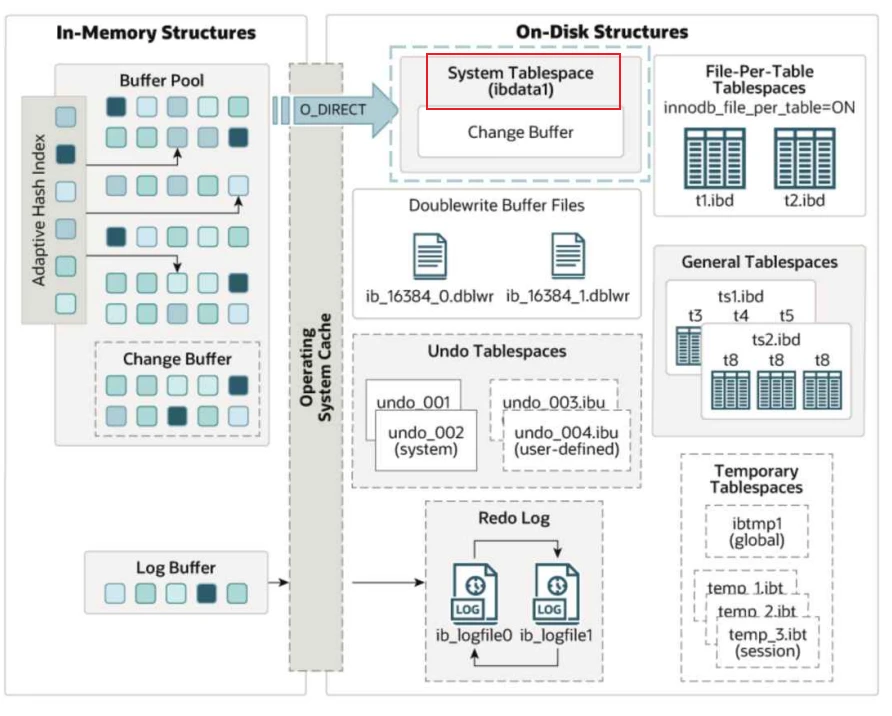
4 系统表空间 - System Tablespace
4.1 系统表空间的作⽤?
✅ 解答问题
- 系统表空间存储了MySQL中所有系统表的数据,也包括数据字典;
- 系统表空间也是变更缓冲区的存储区域,当数据库服务器关闭时,没有合并到缓冲池的⼆级索引修改操作被保存到系统表空间;
- 在以前的版本中,系统表空间也包含双写缓冲区,从MySQL 8.0.20开始,双写缓冲区从系统表空间中移到单独的⽂件中。
4.2 系统表空间⽂件保存在哪⾥?
- 系统表空间可以对应⼀个或多个数据⽂件,默认情况下,MySQL在 data ⽬录中创建⼀个系统表空间数据⽂件 ibdata1 。系统表空间数据⽂件的⼤⼩和数量由
innodb_data_file_path启动选项定义。
4.3 系统表空间都有哪些可以配置的选项?
🔍 分析过程
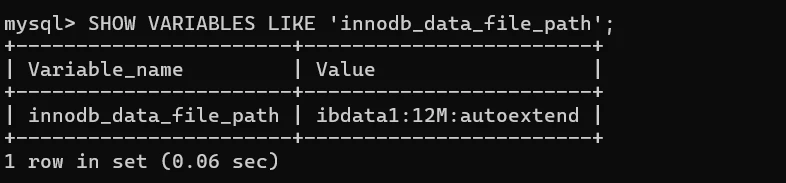
- 可以通过 innodb_data_file_path 选项定义,如果没有指定
innodb_data_file_path的值,则默认创建⼀个⼤⼩可以⾃动扩展的数据⽂件,⽂件名为 ibdata1 ,初始⼤⼩ 12MB 。
- 数据⽂件命名规范的完整语法包括⽂件名、⽂件⼤⼩、⾃动扩展属性和max属性:
file_name:file_size[:autoextend[:max:max_file_size]]
通过在 file_size 值后⾯指定单位 K 、 M 或 G 来设置⽂件⼤⼩,单位为 千字节 、 兆字节 或 千兆字节 。如果以 K 为单位指定⽂件⼤⼩,应设置为1024的倍数。否则,千字节值四舍五⼊到最接近的兆字节 (MB) ,且⽂件⼤⼩⾄少为 12MB 。
- 指定多个数据⽂件可以使⽤分号 ; 分隔。例如:

- autoextend 和 max 属性只能⽤于最后指定的数据⽂件,当指定 autoextend 属性时,数据⽂件的⼤⼩会根据需要⾃动扩容,默认每次增加 64MB 。可以通过系统变量innodb_autoextend_increment 控制增量的⼤⼩;如果要指定数据⽂件的最⼤容量,在autoextend 后⾯指定 max 属性。注意:只有在明确了解限制磁盘使⽤的情况下才使⽤ max 属性。下⾯的配置允许 ibdata1 扩展到 500MB :

- 系统表空间⽂件默认创建在 data ⽬录下。如果指定其他的⽬录,使⽤innodb_data_home_dir 选项。例如,要在名为 myibdata 的⽬录下创建⼀个系统表空间数据⽂件,可以使⽤如下配置:

注意:指定 innodb_data_home_dir 时,必须以斜杠 / 结尾,InnoDB不会⾃动创建⽬录,所以在启动服务器之前要确保指定的⽬录已经存在,最终通过 innodb_data_home_dir 指定的路径与数据⽂件名组合起来⽣成完整路径,如果 innodb_data_home_dir 不指定,默认值为" ./ ",即MySQL的数据⽬录
- 如果 innodb_data_file_path 指定⼀个绝对路径,则不会读取 innodb_data_home_dir 的值,系统表空间⽂件根据指定的绝对路径创建,启动服务器之前必须确保指定的⽬录存在。
- 在添加新的数据⽂件时,不要指定现有的⽂件名,InnoDB在启动服务器时会创建并初始化新的数据⽂件。
✅ 解答问题
- 根据实际应⽤场景通过配置对应的系统变量来指定数据⽂件的⼤⼩、名称、数量和其他属性。
4.4 修改系统表空间配置后什么时候⽣效?
- 在修改系统表空间配置时,先停⽌MySQL服务,修改完成后,再重新启动MySQL服务之后⽣效。
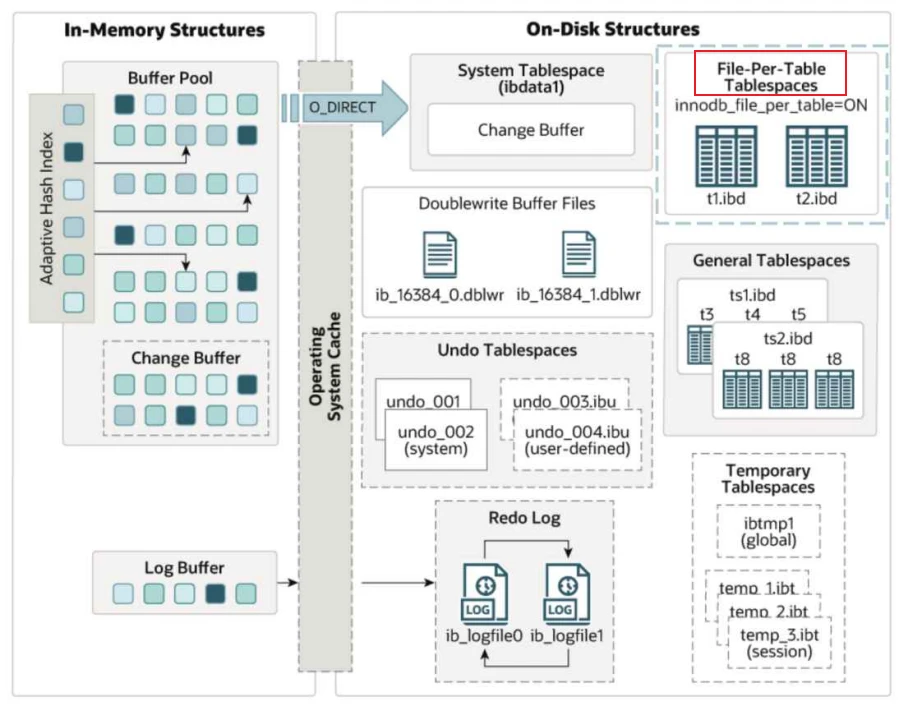
5 独⽴表空间 - File-Per-Table Tablespace
5.1 独⽴表空间的作⽤?
✅ 解答问题
File-Per-Table表空间包含单个InnoDB表的数据和索引,默认情况下每张表都对应⼀个表空间数据⽂件,便于维护,所以称为File-Per-Table Tablespace
5.2 独⽴表空间⽂件保存在哪⾥?
File-Per-Table表空间在data/database_name/⽬录下的 table_name.ibd 表空间数据⽂件中创建。 .ibd ⽂件与表同名。例如,表 test_db.t1 的数据⽂件,如下所⽰:

- 查看数据⽂件
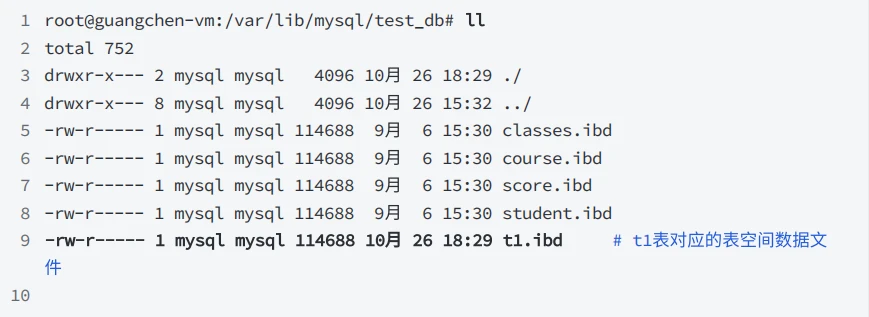
5.3 每个表都对应⼀个独⽴表空间吗?
- 默认每张表都对应⼀个表空间数据⽂件,但也可以通过系统变量 innodb_file_per_table[={OFF|ON}] 控制开启或禁⽤是否为每张表⽣成⼀个独⽴表空间⽂件,如果禁⽤会在系统表空间中创建表;
- 可以在选项⽂件中指定 innodb_file_per_table 设置,也可以在运⾏时使⽤ SET GLOBAL语句设置
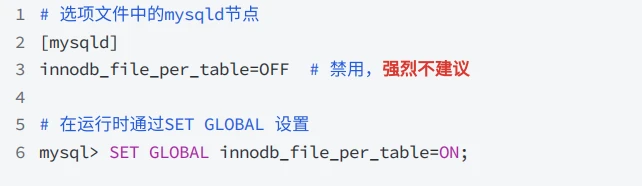
5.4 独⽴表空间的优点和缺点?
✅ 解答问题
- 优点
- 使⽤ TRUNCATE 或 DROP 语句删除 File-Per-Table 表空间中的表后,磁盘空间会返回给操作系统,从⽽提⾼磁盘利⽤率,⽽共享表空间(⽐如: System Tablespace )则不会回收磁盘空间,⽽且在共享表空间中这些空间只能被InnoDB表重新使⽤;
- 执⾏时 TRUNCATE TABLE 时性能更好;
- 可以在其他⽬录或单独的存储设备上创建 File-Per-Table 表空间⽂件的数据⽂件,从⽽达到I/O优化、空间管理或备份的⽬的;
# 指定DATA directory⼦句,可以在外部⽬录中创建表
CREATE TABLE t1 (c1 INT PRIMARY KEY) DATA DIRECTORY = '/external/directory';
- ⽀持与 DYNAMIC 和 COMPRESSED ⾏格式,⽽系统表空间不⽀持;
- 发⽣数据损坏、备份、⼆进制⽇志不可⽤或MySQL服务器实例⽆法重新启动时提⾼成功恢复的机会;
- 单个表容量⼤⼩限制为 64TB ,所以可以存储更多的数据,⽽共享表空间中的表的总容量为64TB 。
- 缺点
- 每个表都可能有未使⽤的空间,这些空间只能由对应的表使⽤,如果管理不当,可能会导致空间浪费;
- 当每个表都有⾃⼰的数据⽂件,操作系统需要维护更多的⽂件描述符,如果表⾮常多,可能会影响性能;
- 可能会出现更多的磁盘碎⽚,会影响 DROP TABLE 表扫描性能;
innodb_autoextend_increment系统变量定义了⾃动扩展共享表空间⽂件的增量⼤⼩,但对于 File-Per-Table 表空间⽂件不起作⽤, File-Per-Table 表空间⽂件始终⾃动扩展,初始⼤⼩根据表定义分配最⼩的空间,之后以 4MB 为增量进⾏扩容。
6 撤销表空间 - Undo Tablespaces
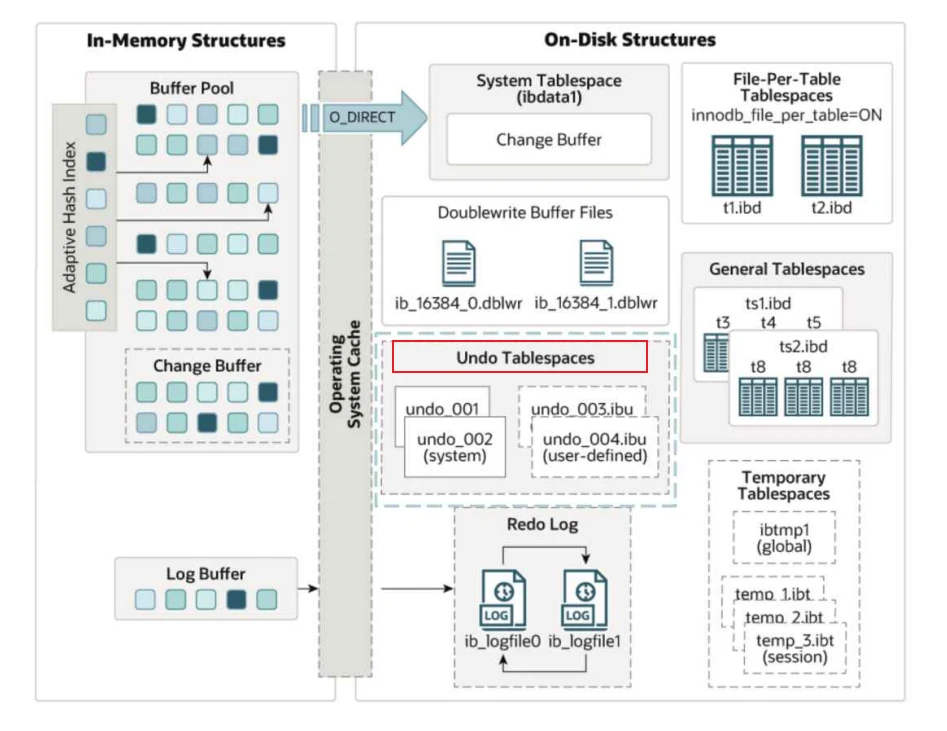
6.1 撤销表空间的作⽤?
✅ 解答问题
- 撤销表空间中包含撤销⽇志(Undo Log),撤销⽇志记录了如何撤销事务对聚集索引记录的最新更改(事务的回滚),通过对事务的回滚,从⽽保证事务ACID特性中的原⼦性。
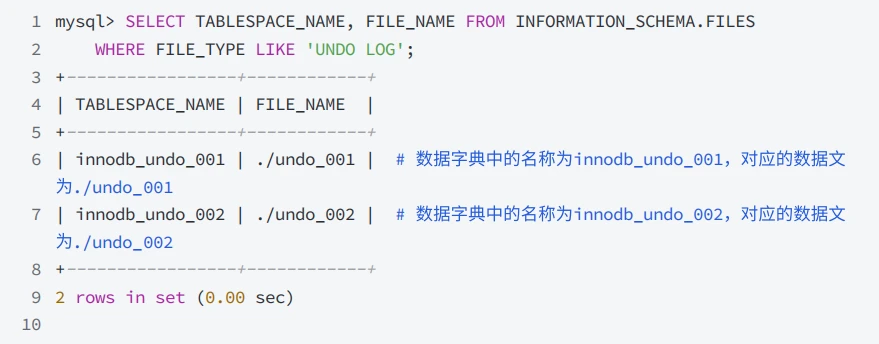
6.2 在使⽤MySQL时并没有⼿动创建撤销表空间,它是什么时候被创建的?
🔍 分析过程
- MySQL初始化时会在数据⽬录下创建两个默认的撤销表空间,数据⽂件名分别为 undo_001 和undo_002 ,数据字典中对应undo表空间名称为 innodb_undo_001 和innodb_undo_002 :

✅ 解答问题
- MySQL初始化时会在数据⽬录下创建两个默认的撤销表空间,数据⽂件名分别为 undo_001 和 undo_002
6.2.1 默认的撤销表空间名称和路径是什么?
- 要查看撤销表空间名称和路径,请查询
INFORMATION_SCHEMA.FILES
6.3 可以⼿动创建撤销表空间吗?
- 可以,通过使⽤
CREATE UNDO TABLESPACE语句可以创建撤销表空间

6.3.1 什么时候需要⼿动创建撤销表空间?
- 对于⻓时间运⾏的⼤事务,撤销⽇志可能会变得很⼤,通过创建额外的撤销表空间来防⽌单个撤销表空间变得太⼤,从 MySQL 8.0.14 开始,可以在运⾏时使⽤
CREATE UNDO TABLESPACE语法创建额外的撤销表空间;
6.3.2 使⽤⾃⼰创建的撤销表空间需要注意什么?
- 通过系统变量
innodb_undo_directory指定撤销表空间的默认存放路径,如果不指定默认位置为数据⽬录; - 撤销表空间⽂件名必须以
.ibu为扩展名,定义undo表空间⽂件名时如果需要指定路径,必须使⽤绝对路径;不允许指定相对路径,建议使⽤唯⼀的撤销表空间⽂件名,避免在以后移动和复制的过程中发⽣⽂件名冲突; - 如果指定其他路径,那么路径必须在
innodb_directories中定义,以便MySQL扫描并识别; - 最多⽀持 127 个 undo 表空间,包括实例初始化时创建的两个默认表空间;
- MySQL 8.0.23 开始初始撤销表空间⼤⼩通常为 16MB,并根据服务器负载以 [16MB, 256MB] 的增量进⾏扩容;
MySQL 8.0.14 之前版本,额外的撤销表空间通过配置系统变量 innodb_undo_tablespaces 来创建,取值范围[2, 127],MySQL 8.0.14 开始,此变量已弃⽤且不再可配置。
6.4 如何删除撤销表空间?
🔍 分析过程
- 从 MySQL 8.0.14开始使⽤
CREATE UNDO TABLESPACE语法创建的撤销表空间可以使⽤DROP UNDO TABALESPAC语法删除; - 撤销表空间在被删除之前必须是空的,要清空撤销表空间,必须⾸先使⽤
ALTER UNDO TABLESPACE语法将撤销表空间标记为不活动,以便该表空间不再⽤于其他新的事务;
# 语法
ALTER UNDO TABLESPACE tablespace_name SET INACTIVE;
- 在将undo表空间标记为⾮活动后,等待当前undo表空间的事务完成后表空间被截断到初始⼤⼩,当undo表空间为空,就可以进⾏删除操作
# 语法
DROP UNDO TABLESPACE tablespace_name;
✅ 解答问题
- 从 MySQL 8.0.14开始使⽤ CREATE UNDO TABLESPACE 语法创建的撤销表空间可以使⽤DROP UNDO TABALESPAC 语法删除,但要确保撤销表空间在被删除之前必须是空的,具体的操作步骤如下:
- 将撤销表空间标记为不活动
- 等待当前undo表空间的事务完成后表空间被截断到初始⼤⼩
- 执⾏删除操作
6.4.1 删除撤销表空间的⽰例
6.4.2 撤销表空间被置为不活动并且已被截断为初始⼤⼩,这时不想删除了是否可以重新启⽤?
- undo表空间状态为空时,可以重新激活,⽅法如下:
# 语法
ALTER undo tablespace tablespace_name SET ACTIVE;
6.5 如何查看撤销表空间的状态?
✅ 解答问题
通过 SHOW STATUS LIKE ‘Innodb_undo_tablespaces%’; 语句可以查看撤销表空间的基本信息

7 撤销⽇志 - Undo Log
7.1 什么是撤销⽇志?
✅ 解答问题
- 当事务对数据进⾏修改的时候,每个修改操作都会在磁盘上创建与之对应的Undo Log,当事务需要回滚时,会根据Undo Log逐⼀进⾏撤销操作,从⽽保证事务的原⼦性。也就是说撤销⽇志是为事务的回滚操作⽽诞⽣的机制,它是⼀个撤销操作记录的集合.
- Undo⽇志保存在Undo⽇志段中,Undo⽇志段位于回滚段中,回滚段位于undo表空间和全局临时表空间中。
7.1.1 撤销⽇志的写⼊时机?
在事务执⾏每个DML之前,会根据DML构建对应的撤销⽇志,并申请⼀个 undo log segments (撤销⽇志段),把⽇志记录在申请到的撤销段中,再执⾏真正的DML操作,执⾏过程如下所⽰:
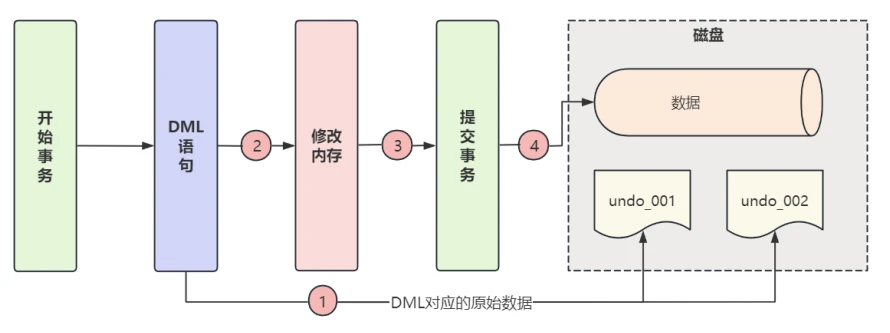
7.2 撤销⽇志在撤销表空间中的组织形式是怎样的?
🔍 分析过程
- ⾸先看来撤销⽇志在撤销表空间中的组织结构图,如下所⽰:
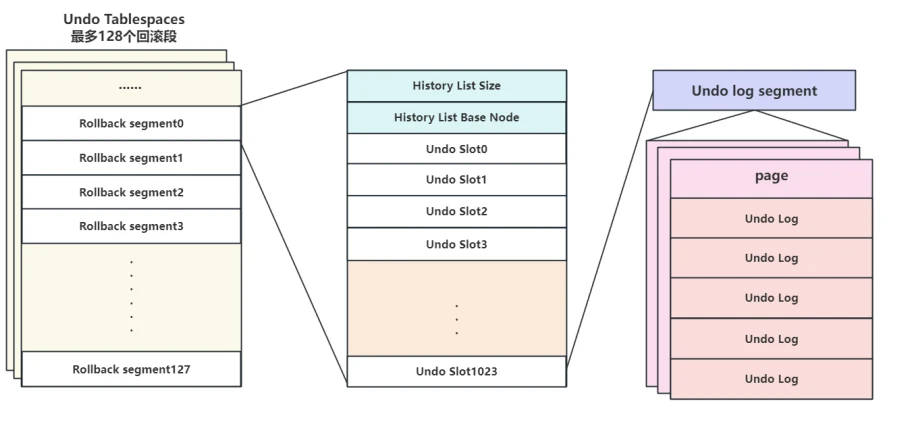
- Undo log segments (撤销⽇志段)也称为撤销段,⼀个撤销⽇志段可以保存多个事务的回滚⽇志,但在同⼀时间只能被⼀个活跃事务使⽤,对应的空间在事务提交或回滚后才可以被重⽤。
rollback segments(回滚段)中包含撤销⽇志段,通常位于undo表空间和全局临时表空间中,使⽤系统变量Innodb_rollback_segments可以定义分配给每个undo表空间和全局临时表空间的回滚段的数量,默认值为128,取值范围是[1, 128];- ⼀个回滚段⽀持的事务数取决于回滚段中的undo slots(槽数)和每个事务所需的undo⽇志数,⼀个回滚段中的undo槽数可以根据InnoDB⻚⾯⼤⼩进⾏计算,公式是(InnoDB Page Size / 16),⽐如默认情况下 InnoDB Page Size ⼤⼩为 16KB ,那么⼀个回滚段就可以包含 1024 个 undo slot ⽤来存储事务的撤销⽇志。
- 回滚段中还记录了 History List 的头节点 History List Base Node ,以及回滚段的⼤⼩
- 通过系统变量 innodb_rollback_segments 可以设置Undo表空间中的回滚段数量,最⼤值和默认值都是128
# 查看Undo表空间中的回滚段数量
mysql> show variables like 'innodb_rollback_segments';
✅ 解答问题
- 撤销表空间中包含 rollback segments (回滚段),每个回滚段中包含若⼲undo slots(槽数),每个槽对应⼀个 Undo log segments (撤销⽇志段),撤销⽇志段中包含具体的撤销⽇志
7.3 撤销⽇志的格式是怎样的?
🔍 分析过程
撤销⽇志格式⽰意图如下:
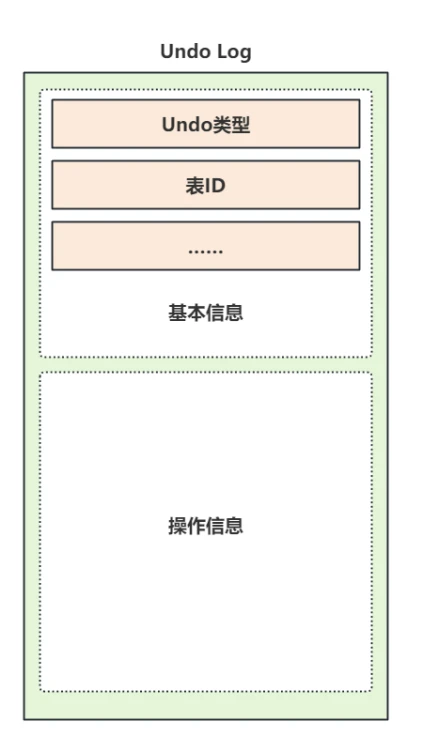
✅ 解答问题
- ⼀条记录在Undo Log⻚中的Undo Log⽇志⼤体包含两部分:分别是记录了Undo类型、表ID、上⼀条、下⼀条⽇志的偏移地址等在内的"基本信息",以及记录了不同操作和数据的"操作信息",如上图所⽰
7.3.1 在事务中不同的DML操作对应的撤销⽇志是否不同?
- 在执⾏DML语句操作数据库时,不同SQL语句对应的撤销操作不同,不同的撤销操作对应的UndoLog存储格式也不相同,按照增、删、改等不同的DML操作,⽣成对应的撤销⽇志。
7.3.2 不同操作对应的撤销⽇志如何区分?
- Undo类型有很多种,最常⻅的就是增、删、改,分别⽤ TRX_UNDO_INSERT_REC 、TRX_UNDO_DEL_MARK_REC 和 TRX_UNDO_UPD_EXIST_REC 表⽰,如图所⽰:
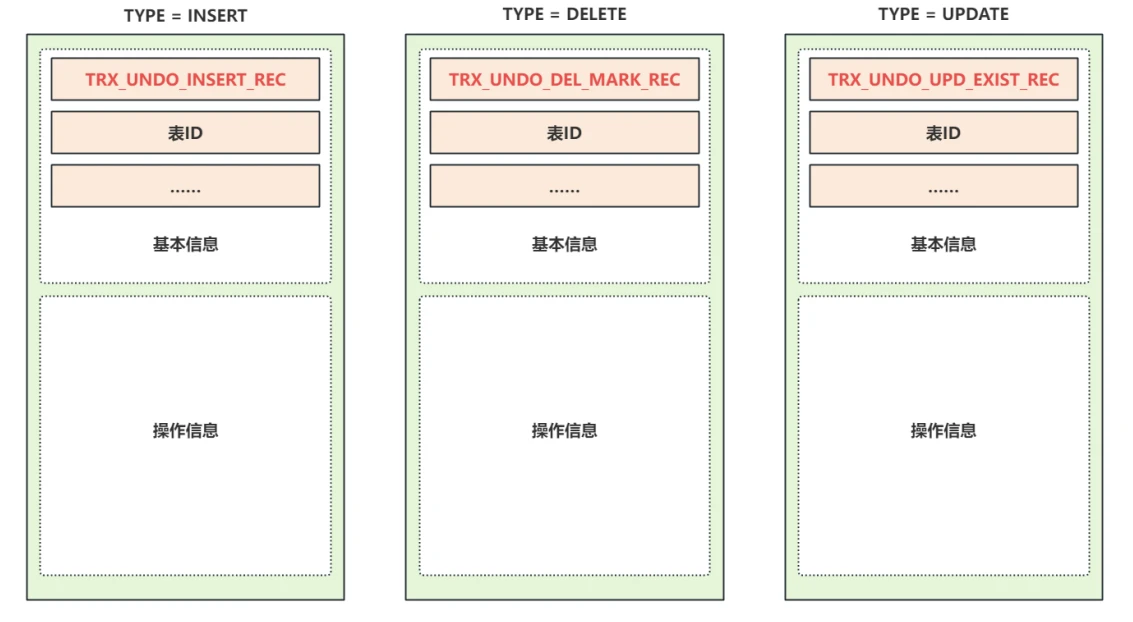
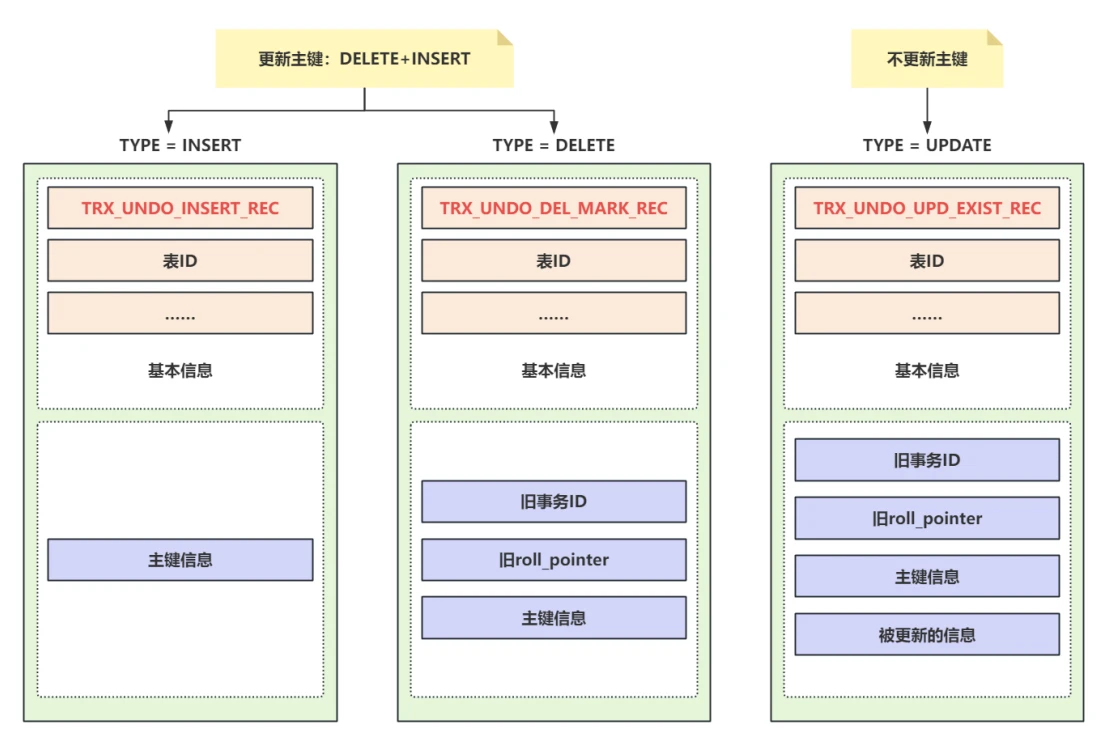
- 新增( TRX_UNDO_INSERT_REC )时的Undo Log操作信息相对简单,只记录了主键值,主键⻓度等主键信息;
- 删除( TRX_UNDO_DEL_MARK_REC )时除了记录主键信息之外,还记录了旧的事务ID,旧的ROLL_POINTER信息,⽤来构建有序的Undo版本链,还会记录⼀些被索引字段的信息;
- 更新( TRX_UNDO_UPD_EXIST_REC )时较为复杂,如果不更新主键则和删除时类似,会记录主键信息、旧的事务ID、旧的ROLL_POINTER信息、被索引字段的信息和被更新的信息;如果更新了主键,则会记录两条Undo Log ,⼀条删除的和⼀条新增的;
7.4 撤销⽇志是如何组织在⼀起的?
🔍 分析过程
- 撤销⽇志的组织⽰意图如下
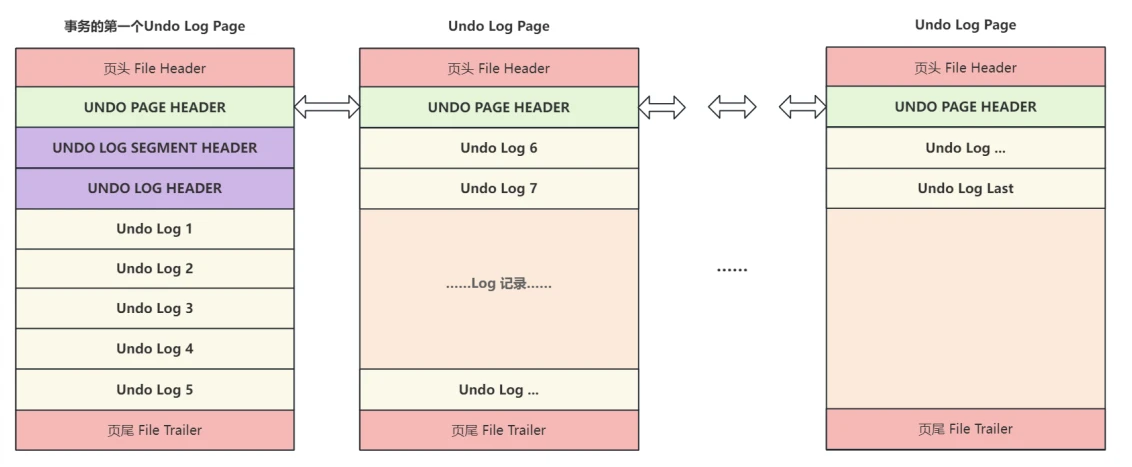
✅ 解答问题
- ⼀条条Undo Log会被逐⼀放在Undo Log⻚中,Undo Log⻚和其他类型的⻚⼀样都会包含头尾信息,除此之外还有Undo Log特有的信息,包括:
UNDO PAGE HEADER:记录了Undo Log⻚类型、⽇志偏移位置、下⼀⻚链表引⽤等信息UNDO LOG SEGMENT HEADER:记录了回滚段信息UNDO LOG HEADER:记录了产⽣这条⽇志的事务Id:Trx ID;事务的提交顺序:Trx No和其他事务相关信息
- 在这三个特有的头信息之外,其他空间都会⽤来记录Undo Log⽇志,如果某个事务很⼤,⼀个Undo Log⻚没有办法完整记录,就需要申请新的Undo Log⻚,然后通过 UNDO PAGE HEADER 中链表引⽤信息链接到前⼀个⻚,后⾯的这些⻚只需要记录Undo Log并不需要记录Undo头信息。
- 这个由Undo Log构成的链表称做Undo链,在事务中会起到⾮常重要的作⽤。
7.4.1 事务提交后Undo Log是否就可以删除了?
- 这⾥强调⼀下,对于新增操作所记录的Undo Log⽇志,在事务提交之后就可以直接删除了,⽽删除和更新的Undo Log⽇志还需要服务事务的MVCC,所以并不能直接删除,⽽是加⼊到hisotry list 中。因些InnoDB为了最⼤程度节省空间提升效率对Undo Log进⾏了分类
7.5 撤销⽇志如何分类?
✅ 解答问题
- Undo Log分为两⼤类:⼀类只记录新增操作,事务提交后可以直接清除;另⼀类记录删除和更新操作,所以相应的回滚链也会被区分为2个:Insert Undo链 和 Update Undo链(Delete + Update)
- 另外普通表和临时表分别对应这两类Undo链,如是⼀个事务既有新增⼜有修改并且⽤到了临时表,那么这个事务最多可以分配四个撤销⽇志,也就是四个Undo链,分别是:
- 对⽤⼾定义的普通表进⾏
INSERT操作 - 对⽤⼾定义的普通表进⾏
UPDATE和DELETE操作 - 对⽤⼾定义的临时表进⾏
INSERT操作 - 对⽤⼾定义的临时表进⾏
UPDATE和DELETE操作
- 对⽤⼾定义的普通表进⾏
- 根据事务的操作按需要写⼊Undo⽇志,⽐如,在普通表和临时表执⾏ INSERT 、 UPDATE 和DELETE 操作的事务需要会写⼊以上四种类型的撤销⽇志;只在普通表上执⾏ INSERT 操作的事务只需要⼀个撤消⽇志
- 对普通表执⾏操作的事务将从指定的系统表空间或undo表空间的回滚段分配undo⽇志。对临时表执⾏操作的事务从指定的临时表空间回滚段分配undo⽇志。
7.6 InnoDB最⼤⽀持并发读写事务的数量如何计算?
✅ 解答问题
-
可以⽤以下公式计算InnoDB能够⽀持的并发读写事务的数量
-
如果每个事务执⾏ INSERT 或 UPDATE 或 DELETE 操作,注意只执⾏⼀种类型的操作,并发读写事务数为:

-
如果每个事务执⾏ INSERT 和 UPDATE 或 DELETE 操作,并发读写事务数为:

- 如果⼀个事务在临时表上执⾏ INSERT 操作,并发读写事务数为:

- 如果⼀个事务在临时表上执⾏ INSERT 和 UPDATE 或 DELETE 操作,并发读写事务数为:

7.7 如何理解Undo链?
✅ 解答问题
- Insert Undo链 和 Update Undo链采⽤了不同的组织⽅式;
- 对于新增操作,Insert Undo链中的每个Undo Log都会对应⼀条新的数据⾏,这个数据⾏中⽤ROLL_POINTER 信息来关联Undo Log,在回滚时就可以通过它找到需要回滚的Undo Log了,如图所⽰:
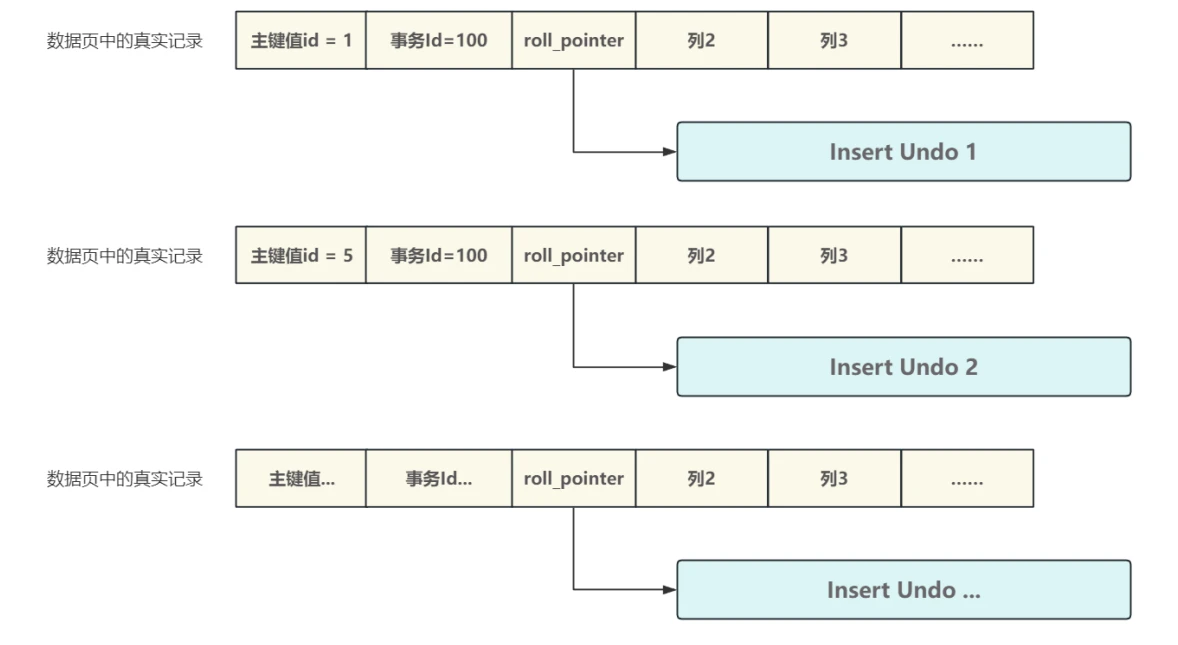
- 对于删除和更新,Update Undo链中的每个Undo Log也都对应⼀个数据⾏,每次更新都会通过Undo Log中的 ROLL_POINTER 进⾏关联,从⽽每个数据⾏都会构成⼀个Undo Log版本链,回滚的时候就可以依序撤销,这个版本链在事务的MVCC中起到了⾮常重要的作⽤,⽤于解决事务的"隔离性",相关内容在事务和锁专题中详细介绍,Update Undo链如下图所⽰:
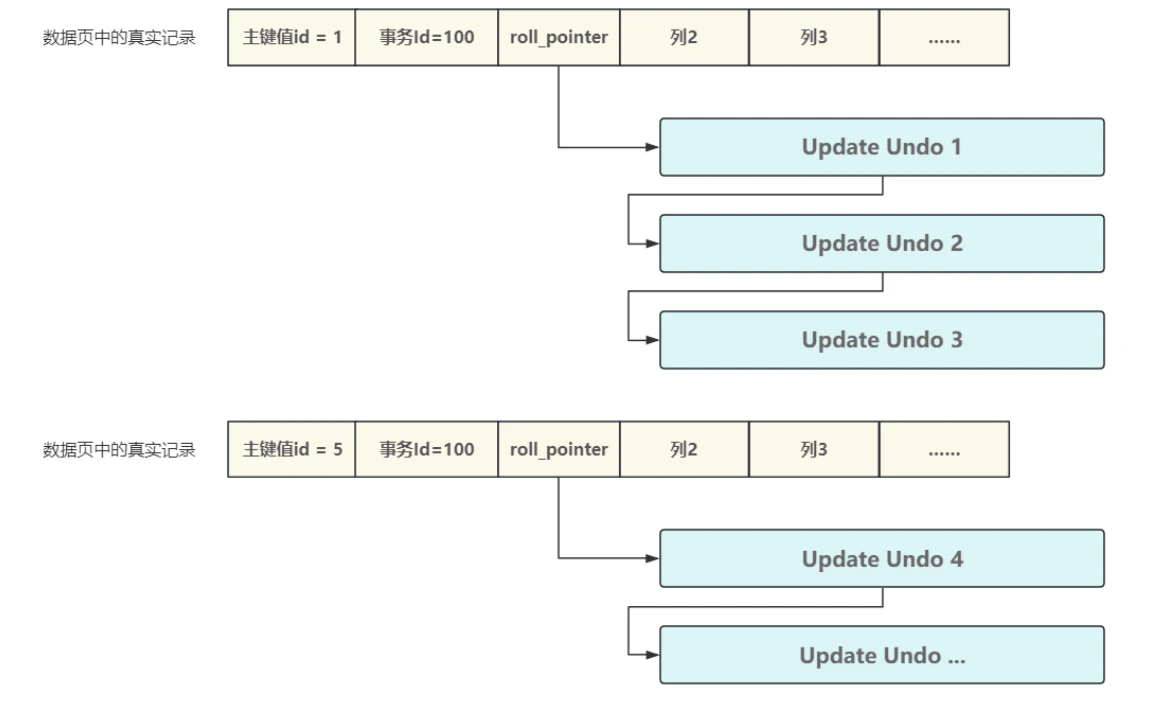
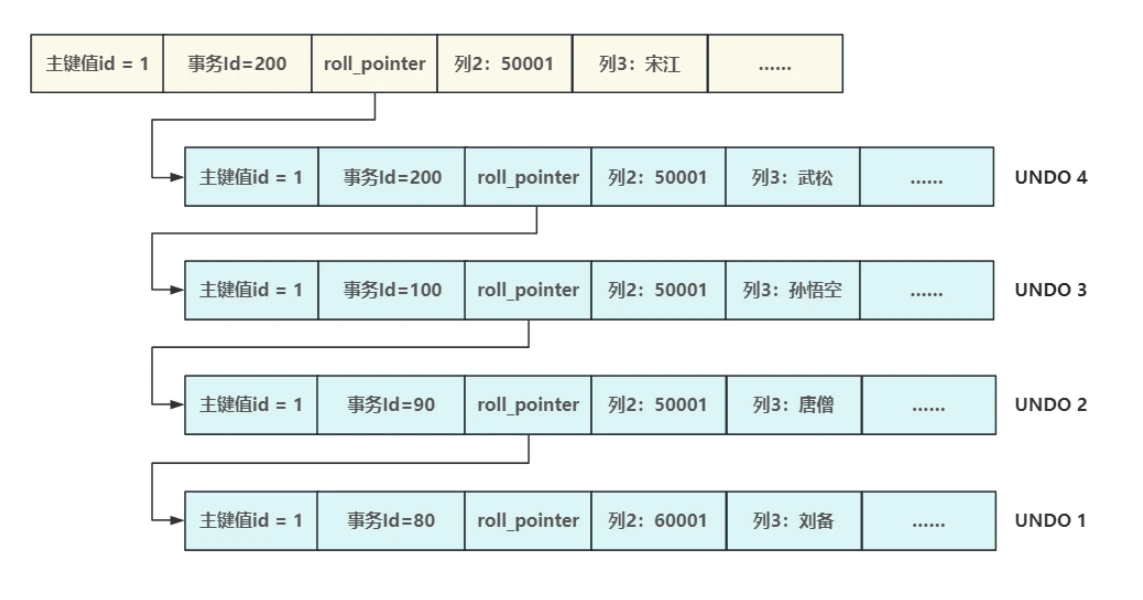
- 以下是⼀个关于更新操作的Undo链
7.8 撤销⽇志为什么需要落盘?
🔍 分析过程
- 在对数据进⾏修改时,都是在内存中操作的,也就是在Buffer Pool中修改对应的数据⻚,在修改数据⻚之前先把对应的撤销⽇志记录在内存中,如果此时事务回滚直接根据内存中的撤销⽇志做回滚操作即可;
- 在修改完成提交事务后,脏⻚进⾏落盘操作,此时事务已提交,不能回滚,所以撤销⽇志也就失效了;
- 当服务器崩溃时,如果事务没有提交,所有的修改都在内存中,还没有落盘,对于修改直接丢弃;如果事务已经提交,则根据重做⽇志和双写缓冲区中的备份进⾏恢复;
- 通过分析看上去撤销⽇志并不需要落盘,其实以上的分析场景并没有考虑到全部的场景,⽐如⼤事务的运⾏、MVCC中版本链什么时候可以销毁、事务的不同隔离级别等因素;
✅ 解答问题
- 在运⾏⼤事务时,InnoDB为了避免⼤事务提交时统⼀落盘操作带来的性能问题,允许在事务进⾏的过程中就进⾏落盘操作并记录对应的UndoLog,当发⽣崩溃恢复时,通过回放UndoLog把未提交的事务进⾏回滚;
- 如果⼀个事务已经提交,但还有其他事务需要访问版本链中对应的UndoLog,那么也需要把相应的撤销⽇志保存到 hisotry list 中。
- 不同隔离级别下,没有提交的事务也可能会落盘,回滚时依然要完成撤销操作
7.8.1 撤销⽇志在内存中如何记录?
- 与数据⻚在内存中的保存⽅式相同,撤销⽇志在内存中也保存在Buffer Pool中,与磁盘中的UndoLog⻚结构⼀致,内存中每个UndoLog⻚通过控制块管理
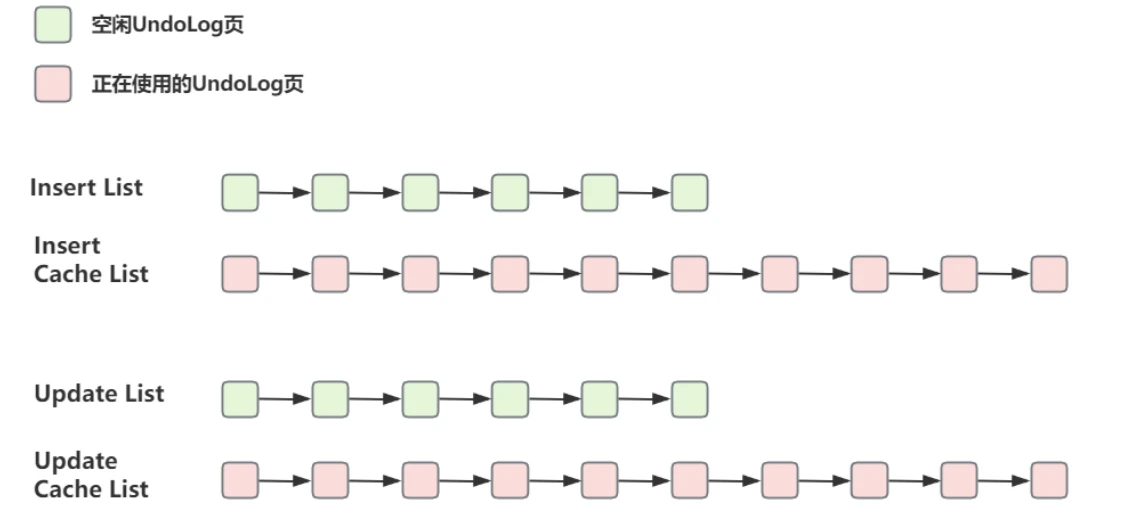
- 在内存中使⽤四个链表来管理正在使⽤的UndoLog⻚和空闲UndoLog⻚,根据不同的⽇志类型分为:
- Insert List :正在被使⽤的⽤来管理Insert类型的UndoLog ⻚
- Insert Cache List :空闲的或被清理后可以被后续事务重⽤的Insert类型UndoLog⻚
- Update List :正在被使⽤的⽤来管理Update类型的UndoLog ⻚
- Update Cache List :空闲的或被清理后可以被后续事务重⽤的Update类型UndoLog⻚
7.8.2 撤销⽇志的写⼊过程是怎样的?
- 当写事务开始时,会先分配⼀个处理 ACTIVE 状态的 Rollback Segment ;
- 当第⼀次DML操作产⽣Undo Record时,会轮询当前 Rollback Segment 中可⽤的 Slot ,以便获取⼀个 Undo Log Segment ;
- 根据撤销⽇志的类型获取UndoLog⻚,并挂载到对应的List当中;
- 在UndoLog⻚顺序写⼊⽇志,当⼀个UndoLog⻚写满之后,会获取新的UndoLog⻚以便继续写⼊当前事务⽣成的⽇志,这⾥注意:单条UndoLog不能跨⻚存储,也就是说当某条⽇志在当前⻚中放不下时,会整体保存下⼀⻚中;
- 由后台线程把⽇志刷⼊磁盘;
- 当事务结束之后(commit或者rollback), insert ⽇志类型对应的 Undo Log Segment 和UndoLog page 会直接回收,⽽ update ⽇志类型对应的 Undo Log Segment 和UndoLog page 会等待后台的清理操作完成后,确保⽇志不会有事务再访问后进⾏回收,回收的UndoLog⻚被挂载到Cache List中。
7.8.3 撤销⽇志的回滚过程是怎样的?
- 回滚操作可以是⽤⼾通过rollback主动触发,也可能发⽣在崩溃恢复时,不论是哪种触发条件,回滚操作都是相同的,基本过程就是读取该事务的Undo Log,从后向前依次进⾏逆向操作,从⽽恢复索引记录;
- 对于 Insert 类型的回滚操作就是 Delete ,在删除的过程中会重新调整主键索引和⼆级索引;
- 对于Update和Delete类型的回滚操作,主要是回退这次操作在所有主键索引和⼆级索引的影响,可能包括重新插⼊被删除的⼆级索引记录、去除⾏管理信息中的Delete Mark标记、将主索引记录修改回之前的值等;
- 完成回滚的Undo Log会进⾏回收,将不再使⽤的UndoLog⻚的磁盘空间还给 Undo Log Segment ,这个过程是写⼊过程的逆操作。
7.8.4 撤销⽇志的清理过程是怎样的?
- InnoDB通过保存多份Undo Log的历史版本来实现MVCC,当某个历史版本已经确认不会被任何现有的和未来的事务访问时,就应该被清理掉;
- 当开启⼀个事务时都会被分配⼀个事务编号 trx_id ,⽽事务进⾏读操作时会创建⼀个ReadView,并记录当前所有事务中的最⼩活跃事务编号 m_low_limit_id ,如果版本链中 ⽇志的trx_id < m_low_limit_id ,则表⽰当前读操作发⽣时,⽇志对应的事务已提交,其修改的新版本是可⻅的, 因此不再需要通过Undo版本链构建之前的版本,这个事务的Undo Log也就可以被清理了。
- Undo的清理⼯作是由专⻔的后台线程进⾏扫描和分发,并由多个线程进⾏清理,并可以通过系统变量
innodb_purge_threads配置清理线程数,系统变量innodb_purge_batch_size可以配置每次清理的⻚数,这⾥不再进⾏过多的讨论。
8 双写缓冲区 - Doublewrite Buffer
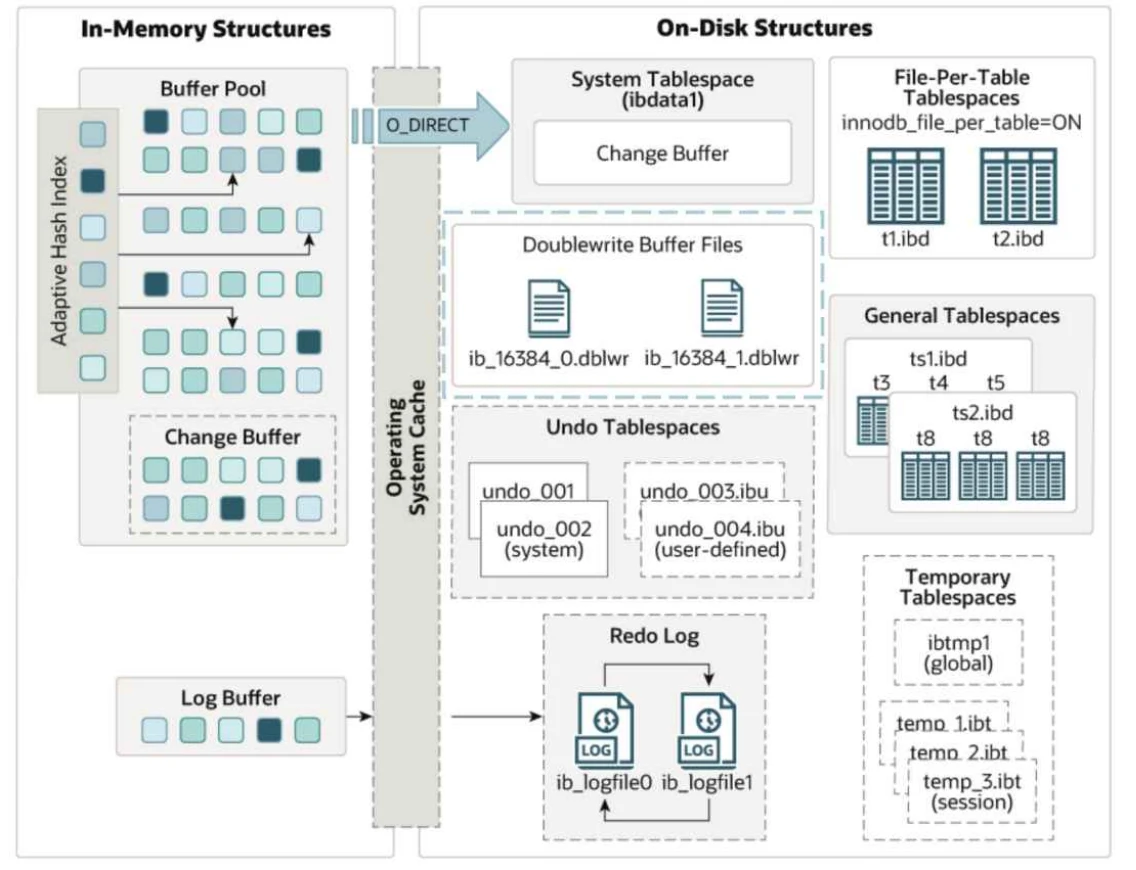
8.1 双写缓冲区的作⽤?
✅ 解答问题
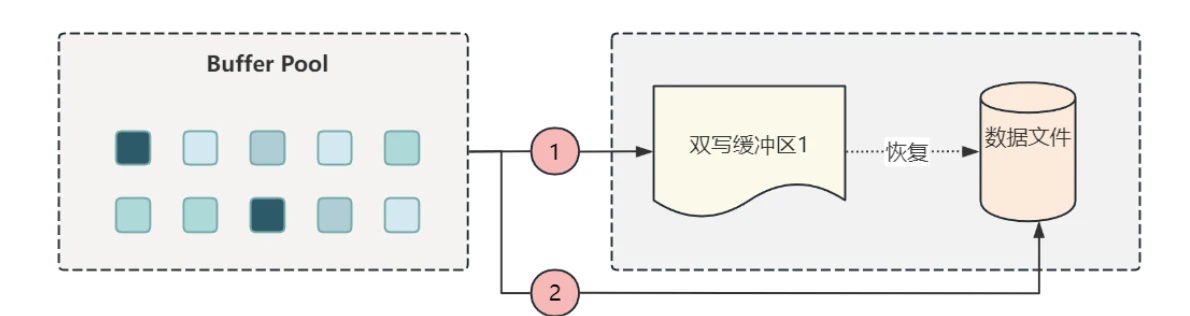
- 双写缓冲区是磁盘上的⼀个存储区域,当 InnoDB 将缓冲池中的数据⻚写⼊到磁盘上表空间数据⽂件之前,先将对应的⻚写到双写缓冲区;如果在数据真正落盘的过程中出现了意外退出,⽐如操作系统、存储⼦系统崩溃或异常断电的情况, InnoDB 在崩溃恢复时可以从双写缓冲区中找到⼀份完好的⻚副本,执⾏过程如下图所⽰:
8.1.1 双写缓冲区中的数据保存在哪⾥?
- 在MySQL 8.0.20之前, doublewrite 缓冲区位于InnoDB系统表空间中。从MySQL 8.0.20开始, doublewrite 缓冲区默认存储区域位于数据⽬录下的 doublewrite ⽂件中。
8.2 如何配置双写缓冲区?
✅ 解答问题
-
是否启⽤ doublewrite 缓冲区可以通过系统变量 innodb_doublewrite[=ON|OFF] 控制,默认为启⽤,如果真实的业务场景更关注性能⽽不是数据完整性,可以考虑禁⽤doublewrite缓冲区,例如在执⾏测试的环境中;
-
doublewrite ⽂件所在⽬录通过系统变量 innodb_doublewrite_dir (MySQL 8.0.20中引⼊)指定,如果不指定则在 innodb_data_home_dir ⽬录(默认为data⽬录)下创建;如果指定doublewrite⽬录,建议设置在最快的存储介质上,以提⾼效率;
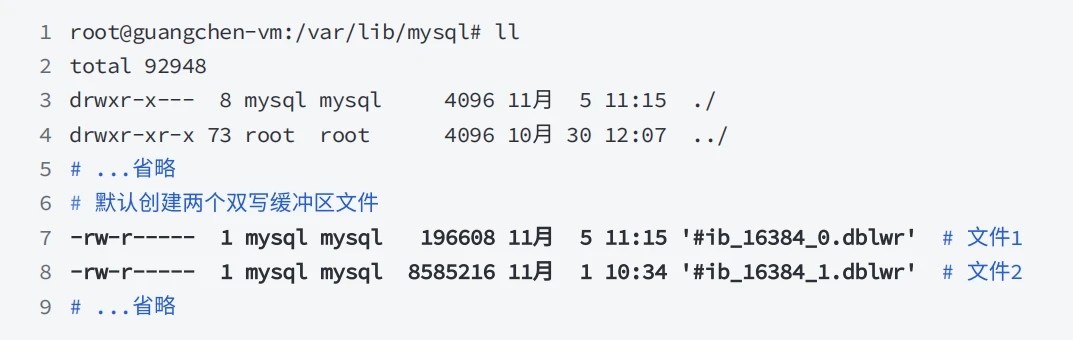
- 命名⽅式为: #ib_page_size_file_number.dblwr ,以上 #ib_16384_0.dblwr 的⽂件表⽰当前数据⻚的⼤⼩为16KB,编号为0
- 双写⽂件的数量通过系统变量 innodb_doublewrite_files 设置,默认情况下,为每个缓冲池实例创建两个doublewrite⽂件,也就是说⽂件数量为 innodb_buffer_pool_instances* 2 ;此变量⽤于⾼级性能调优,⼤多数场景使⽤默认设置即可;
9 重做⽇志 - Redo Log
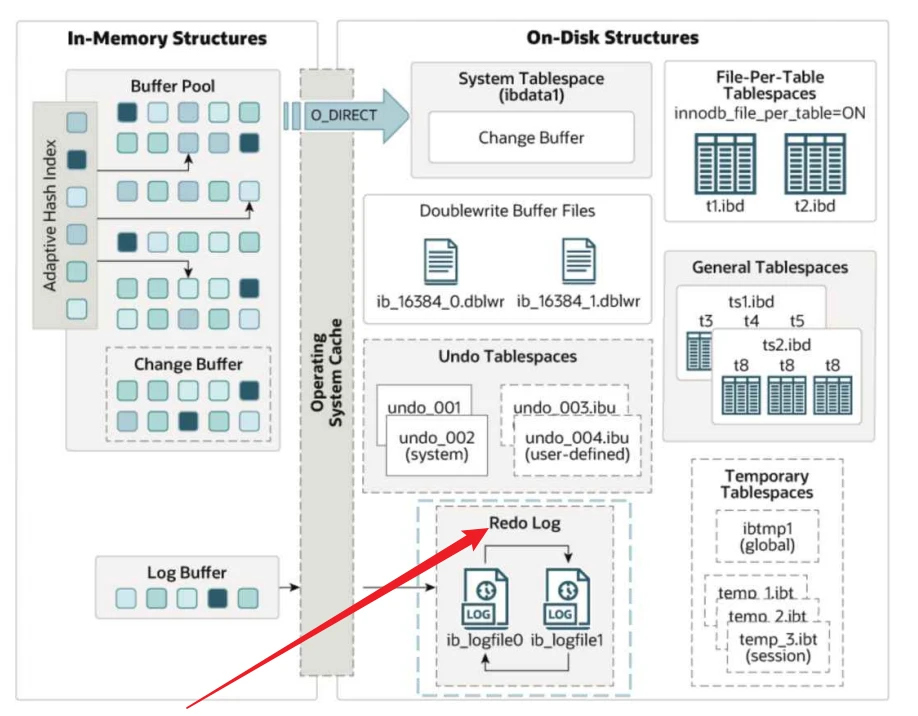
9.1 重做⽇志的作⽤?
- 重做⽇志在保证事务的持久性和⼀致性⽅⾯起到了⾄关重要的作⽤
- 重做⽇志⽤于在数据库崩溃后恢复已提交事务还没有来的及落盘的数据。重做⽇志以⽂件的形式保存在磁盘上,在正常的操作过程中,MySQL根据受影响的记录进⾏编码并写⼊重做⽇志⽂件,这些数据称为"Redo",在重新启动时⾃动读取重做⽇志进⾏数据恢复。
9.1.1 为什么要⽤Redo Log,⽽不是直接写磁盘?
- 我们来分析⼀下,⾸先明确⼀点,我们对数据进⾏的DML操作都会包含在事务当中,当完成修改并且提交事务之后,在内存中被修改的数据⻚就要刷新到磁盘完成持久化;
- 那么如果这次DML操作对应的修改开始刷盘的话,当服务器崩溃,没有被刷到磁盘的数据⻚就从内存中丢失,这时这个事务的修改在磁盘上就是不完整的,也就是没有保证事务的⼀致性
- 为了解决这个问题,InnoDB在执⾏每个DML操作时,当内存中的数据⻚修改完成之后,把修改的内容以⽇志的形式保证在磁盘上,然后再对数据⻚进⾏真正的落盘操作,这样做就相当于对修改进⾏了⼀次备份,即使当服务器崩溃也不会受到影响,当服务器重启之后,可以从磁盘上的⽇志⽂件中找到上次崩溃之前没有来的及落盘的数据继续执⾏落盘操作;
- InnoDB引擎的事务采⽤了 WAL技术(Write-Ahead Logging) ,基本思想是先写⽇志,再写磁盘,只有⽇志写⼊成功,事务才算提交成功,这⾥的⽇志就是Redo Log。当发⽣宕机且数据未刷到磁盘的时候,可以通过Redo Log来恢复,保证ACID中的持久性,这也是Redo Log的作⽤。
9.1.2 Redo Log的写⼊时机?
- 当发⽣数据修改操作时追加重做⽇志,已落盘数据对应的⽇志位置被记录为⼀个检查点,检查点之前的数据被置为⽆效,所以重做⽇志⽂件可以循环使⽤。以⼀个更新操作为例,重做⽇志的写⼊过程与时机,如下图所⽰:
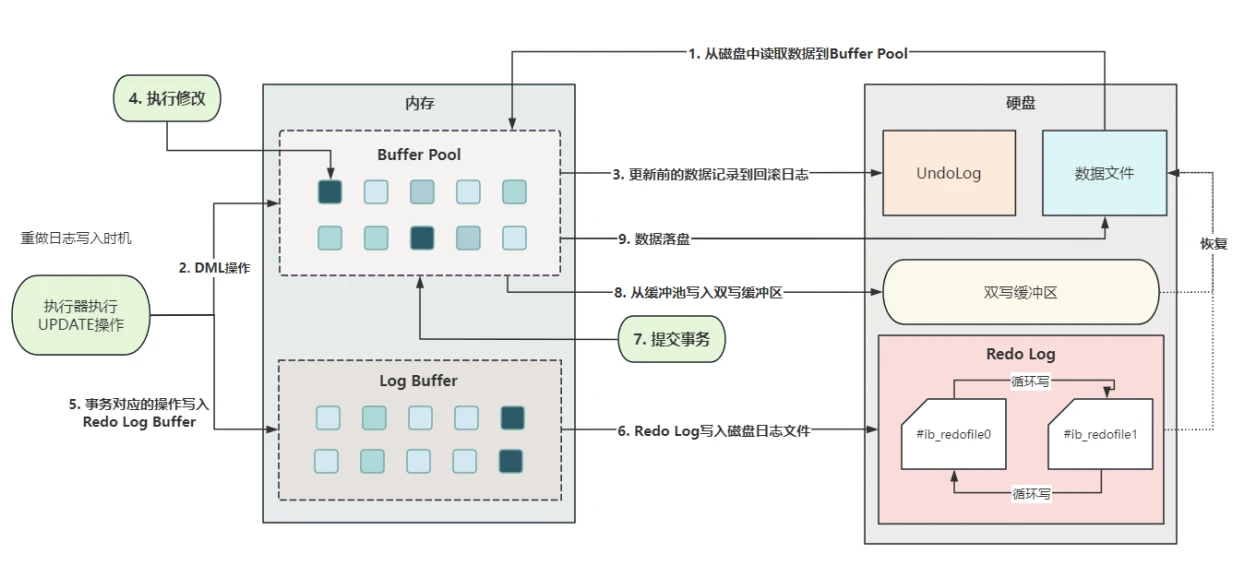
- 前⾯已经介绍过为什么要使⽤Log Buffer,因为每次进⾏DML操作都会进⾏⼀次磁盘I/O,这样会严重影响效率,所以把⽇志统⼀写⼊内存中的Log Buffer,根据刷盘策略统⼀进⾏落盘操作,可以实现⼀次磁盘I/O写⼊多条⽇志,从⽽提升效率。
9.2 Redo Log的格式是怎样的?
🔍 分析过程
- 在介绍RedoLog的格式之前,先来分析⼀下RedoLog中需要记录哪些内容
9.2.1 RedoLog中需要记录哪些内容?
- 当进⾏DML操作时,⾸先要修改内存中的数据⻚,但是修改的数据有可能只是数据⻚中很少的⼀部分内容,甚⾄有可能只修改了⼏个字节,那么在RedoLog中是要记录整个数据⻚吗?当然不是,如果每次保存整个数据⻚的话就有太多的⽆⽤数据写⼊⽇志,严重影响效率⽽且浪费空间
- 为了节省空间提⾼效率,RedoLog只记录被修改的内容,⽐如当前的DML修改了哪个表空间、表空间中的哪个数据⻚,数据⻚中多少偏移量处的值修改成了什么,⽐如:

- 这样就可以⽤很⼩的⽇志记录当前对数据⻚所做的修改,⼤⼤节省了空间
✅ 解答问题
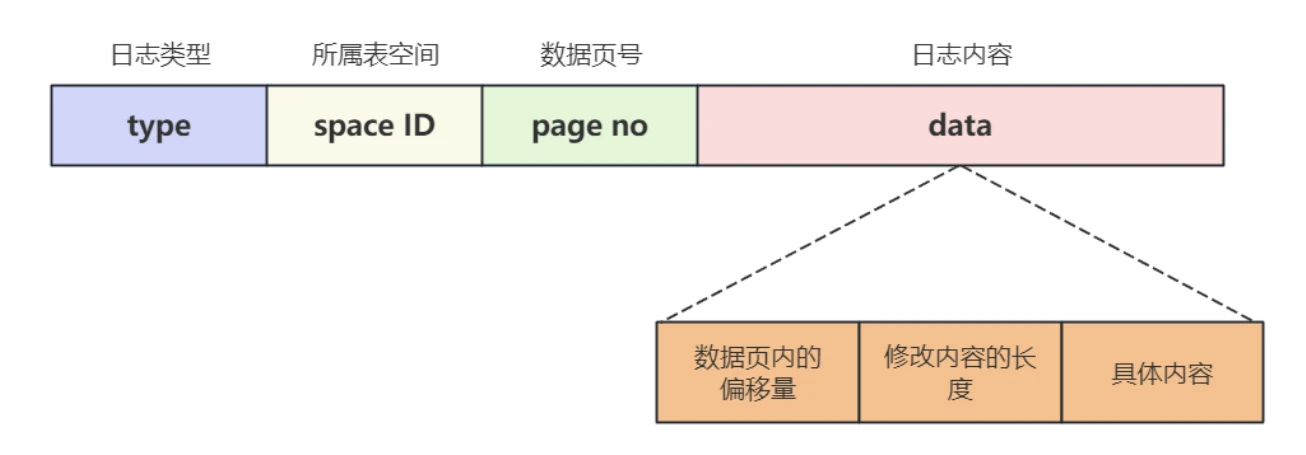
- RedoLog本质上只是记录了事务对数据库做了哪些修改,修改操作包含多种场景,⽐如对数据⾏、索引⻚的增删改,对范围的修改与删除等等,不同场景的 redo ⽇志定义了不同的类型,但是绝⼤部分类型的 redo ⽇志都有下边这种通⽤的结构包括:
- Type : ⽇志类型, 1BTYE
- Space ID : 操作所属的表空间, 4BTYE
- Page no : 操作的数据⻚在表空间中的编号, 4BTYE
- data :⽇志的内容,⻓度不固定
- 如下图所⽰:

9.2.2 data 部分的具体内容是什么?
- data 部分⼜可以分为:数据⻚中的偏移量,修改内容的⻓度和具体的修改内容,如下图所⽰
9.3 RedoLog的类型分为哪些?
🔍 分析过程
- 查看RedoLog的类型,最完整最直观的⽅式就是通过阅读源代码,如下所⽰:
✅ 解答问题
- RedoLog的类型根据数据操作的不同场景和对⽇志的优化⽅式有⼏⼗种之多,总体可以分为:
- ⽤于数据⻚的⽇志类型,⽐如对数据⻚的修改
- ⽤于表空间⽂件的⽇志类型,⽐如对表空间的修改
- ⽤于表空间⽂件的⽇志类型,⽐如对表空间的修改
9.4 不同⽇志类型对应了哪些操作?
🔍 分析过程
-
⽇志类型总体可以分为三⼤类,分别是:⽤于数据⻚的⽇志类型、⽤于表空间⽂件的⽇志类型和提供额外信息的⽇志类型,不同的⽇志类型对应的⽇志内容也不尽相同,⽽进⾏DML操作时,⼤多数RedoLog属于⽤于数据⻚的⽇志类型
-
属于⽤于数据⻚的⽇志类型中的⼏种最常⻅数据操作所对应的⽇志类型如下:
MLOG_WRITE_STRING= 30 , type 对应的值为30,表⽰在⻚⾯的某个偏移量处写⼊⼀个字符串,由于字符串的⻓度不固定,需要⽤到⼀个表⽰⻓度的区域记录,此时⽇志内容格式如下图所⽰:

- MLOG_4BYTES = 4, type 对应的值为4, 这种类型应⽤于对固定⻓度值的修改,⽐如修改整型字段,由于⻓度固定,所以⽤于表⽰⻓度的区域可以省略,从⽽尽可能的减少空间使⽤,此时⽇志内容格式如下图所⽰:

-
类似的类型还有 MLOG_1BYTE = 1 , MLOG_2BYTES = 2 , MLOG_8BYTES = 8 分别表⽰固定修改1字节、2字节、8字节的数据,⽇志格式与 MLOG_4BYTES = 4 相同
-
还有其他⼀些⽇志类型,⽐如:

-
属于⽤于表空间⽂件的⽇志类型:
- MLOG_FILE_CREATE = 33 ,表⽰创建⼀个.ibd表空间⽂件
- MLOG_FILE_RENAME = 34 ,表⽰重命名⼀个表空间⽂件
- MLOG_FILE_DELETE = 35 ,表⽰删除⼀个表空间⽂件
-
属于提供额外信息的⽇志类型:
- MLOG_MULTI_REC_END = 31 ,只由⼀个字节的 Type 构成,⽤于标识⼀个 Mini-Transaction(MTR)的结尾。
Mini-Transaction可以看做是⼀组原⼦性的磁盘操作,⼀个事务由⼀个或多个MTR组成
✅ 解答问题
不同的⽇志类型对应的⽇志内容和作⽤各不相同

9.4.1 如果⼀个DML操作修改了表中的多个字段,⽇志如何表⽰?
上⾯的分析过程介绍了简单的DML操作对应的⽇志,通常情况下,⼀个DML操作会修改表中的多个字段,也可能修改多条记录,对于正常的增删改对应不同的⽇志类型,对应⽇志所包含的主要信息如下图所⽰:
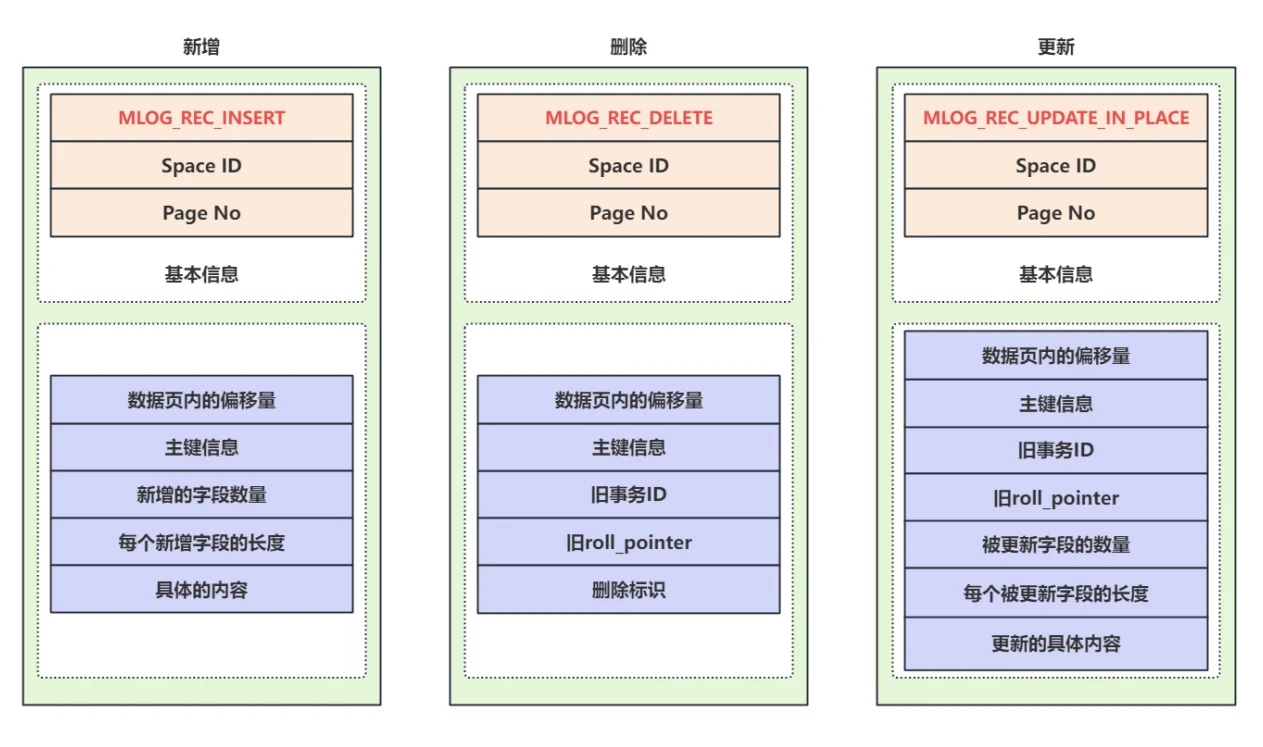
- 新增操作:主要包含数据⻚内的偏移量,主键信息,新增的字段个数,每个字段的内容的实际⻓度,具体的内容等
- 删除操作:主要包含数据⻚内的偏移量,主键信息、旧事务的Id,旧roll_pointer,是否删除标识
- 更新操作:主要包含数据⻚内的偏移量,主键信息、旧事务的Id,旧roll_pointer,被更新字段的数据,每个被更新字段的实际⻓度,更新的具体内容

9.5 什么是Mini-Transaction?
🔍 分析过程
9.5.1 DML操作会对数据⻚产⽣什么样的影响?
-
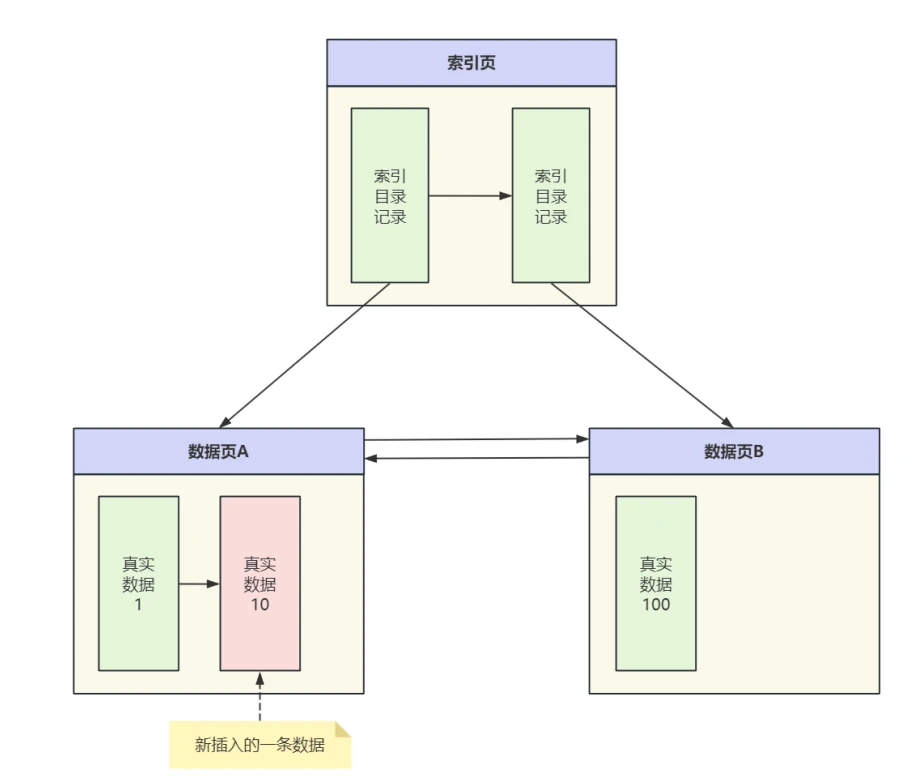
以⼀个Insert操作为例,对数据⻚的影响⼀般分为两种情况:
- 如果写⼊记录所在的数据⻚空间充⾜,⾜够存储⼀条将要写⼊的记录,那么就可以直接写⼊,如下图所⽰:
-
如果写⼊的数据⻚空间不充⾜,⽆法放下这条记录,由于在数据⻚中真实数据是按主键顺序排列的,那么就要新建⼀个数据⻚,对原来的数据进⾏调整,把⼀部分数据复制到新的数据⻚中,以便在⽬标数据⻚上留出⾜够的空间来保存即将写⼊的记录,此时对应的⽰意图如下所⽰:
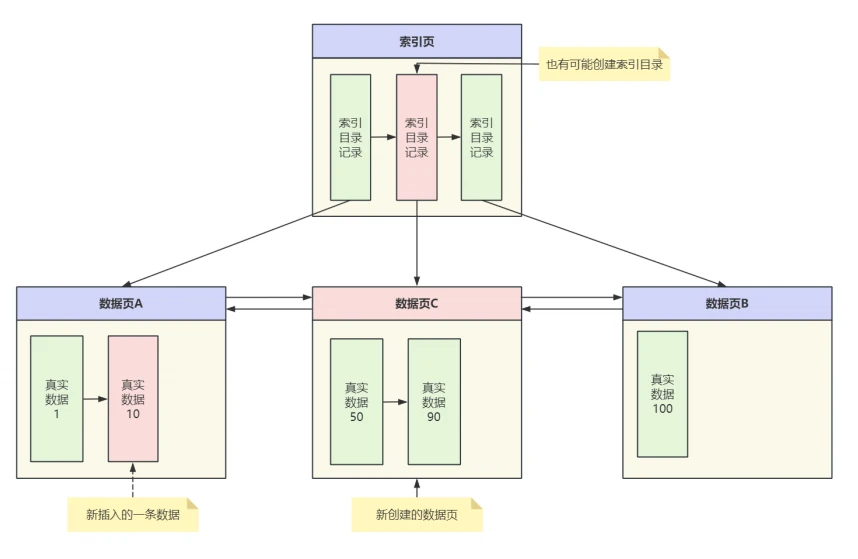
- 通过以上两种情况下插⼊⼀条记录的分析可以看出,当数据⻚空间充⾜的情况下可以直接写⼊数据,并记录⼀条对应RedoLog即可
- 当数据⻚空间不充⾜⽆法放下这条记录的情况下,会创建⼀个新数据⻚,同时还有数据的复制和写⼊,索引树⾮叶⼦节点上修改,在实际的执⾏过程中还有对表空间中段、区中统计信息的修改等等,这意味⼀个简单的Insert操作有会产⽣很多条RedoLog。
9.5.2 在记录RedoLog时服务器崩溃了导致⽇志不完整怎么办?
- 那么这时有⼀个问题需要考虑,试想⼀下如果执⾏这⼀系统操作的时候,RedoLog只记录了⼀半服务器就崩溃了,那么当服务器重启的时候如果按照RedoLog进⾏恢复,得到的结果肯定是错误的,所以在记录RedoLog的时候要保证⼀个DML所对应的⼀系列⽇志必须是完整的才可以执⾏恢复操作,否则就不执⾏恢复。
9.5.3 Mini-Transaction的定义
- Mini-Transaction就是针对以上的操作过程定义的概念,也就是说把记录⼀个DML操作的过程称为⼀个 Mini-Transaction ,简称 MTR ,⼀个所谓的MTR包含⼀个DML操作产⽣的⼀组完整⽇志,在进⾏崩溃恢复时这⼀组RedoLog做为⼀个不可分割的整体。
- 这⾥所说的不可分割的组是MySQL中定义的,常⻅的有:
- 向聚簇索引对应B+树的⻚⾯中插⼊⼀条记录时产⽣的RedoLog不可分割;
- 向某个⼆级索引对应B+树的⻚⾯中插⼊⼀条记录时产⽣的RedoLog不可分割;
- 还有其他的⼀些对⻚⾯的访问操作时产⽣的RedoLog不可分割。
- 每条语句根据具体的执⾏情况可能会产⽣多个MTR。
✅ 解答问题
- Mini-Transaction是MySQL内部对底层数据⻚的⼀个原⼦操作,包含⼀个DML操作产⽣的⼀组完整⽇志,保证数据库异常恢复时数据⻚中数据的⼀致性。
9.5.4 如何标识⼀组RedoLog属于同⼀个MTR?
- 在执⾏DML操作的过程中,每⼀个对数据⻚的修改都会记录⼀条RedoLog,这些⽇志会被顺序记录下来,并在这组⽇志的最后加⼀条特殊的⽇志标识作为⼀个MRT的结尾,这条特殊的⽇志结构⾮常简单,只有⼀个 TYPE 字段,类型为
MLOG_MULTI_REC_END= 31 ,也就是⽇志分类中的提供额外信息的⽇志类型,⼀个MTR对应的⽇志组,如下图所⽰:
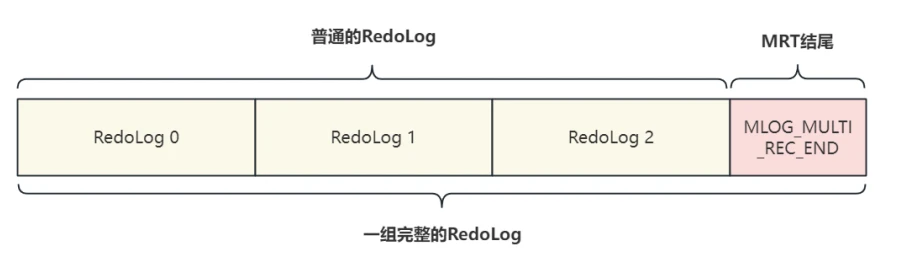
9.5.5 如果⼀个MTR中只有⼀条⽇志是否可以优化?
- 当然可以,如果⼀个MTR只有⼀条⽇志,直接在这条⽇志后加⼀个类型为
MLOG_MULTI_REC_END = 31的标识可以做为MTR的结尾,但这样做有点浪费空间; - InnoDB为了尽可能的节省空间,在MTR只有⼀条⽇志的情况下,做了⼀个优化。通过上⾯的介绍了解了⽇志类型虽然很多,但也只有⼏⼗种,⽽⽤来表⽰⽇志类型的 TYPE 字段⻓度为 1BTYE ,⽽这 1BTYE 中只⽤7个⽐特位,代表整数127,就完全可以表⽰所有的⽇志类型,与是省出来⼀个⽐特位就可以⽤来表⽰当前MTR包含⼀条还是⼀组RedoLog,也就是说如果 TYPE 字段的第⼀个⽐特位为 1 ,表⽰MTR只包含⼀条RedoLog,为 0 表⽰MTR包含⼀组RedoLog,如下图所⽰:
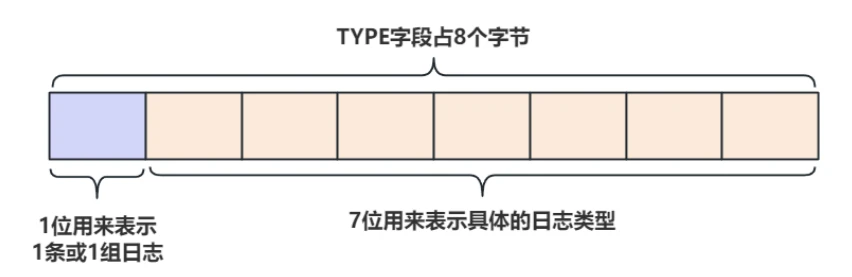
9.5.6 事务与Mini-Transaction是什么关系?
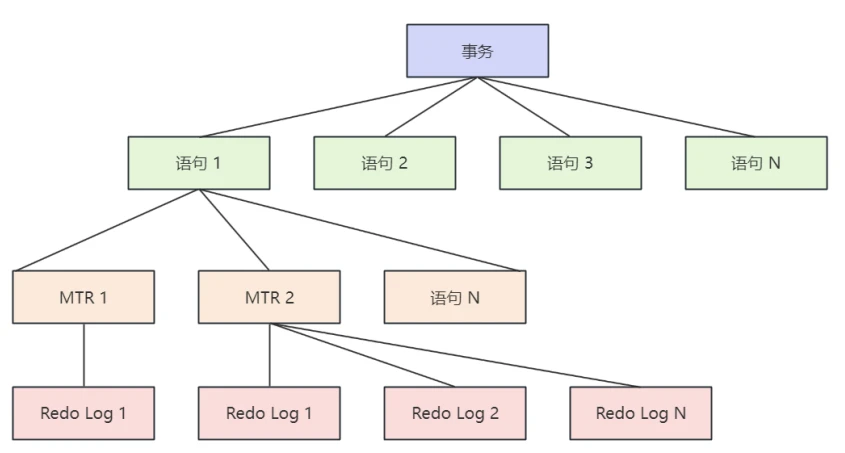
- Mini-Transaction是包含的是⼀个DML操作对应的⼀组RedoLog,⽽⼀个事务中可能会包含多个DML操作,所以⼀个事务中包含⼀个或多个SQL语句,⼀个SQL语句包含⼀个或多个MRT,⼀个MTR包含⼀条或多条RedoLog,他们之间的关系如下图所⽰:
9.6 RedoLog的是如何写⼊缓冲区的?
💡 前置知识
- 这个问题可以理解为RedoLog的写⼊过程,要了解写⼊过程,必须先介绍RedoLog在内存和⽂件中是如何进⾏描述和组织的,我们提出以下⼏个问题:
9.6.1 ⽤来组织RedoLog的数据结构是什么?
- ⽤来组织RedoLog的数据结构是Redo⻚,⻚的⼤⼩是 512B ,也可以称为⼀个 Redo LogBlock ,这个⼤⼩刚好对应磁盘上⼀个扇区,当⽇志写⼊磁盘时可以保证连续性, Redo Log Block 的⽰意图如下所⽰:
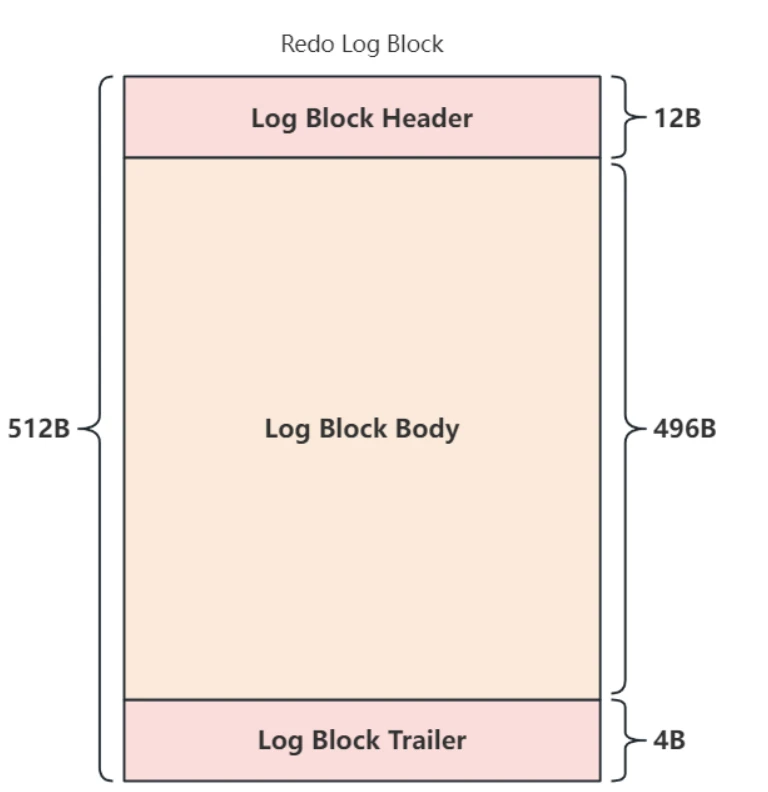
- 在⼀个
Redo Log Block中,包含⽤来存储管理信息的块头 Log Block Header (占12Byte)和块尾 Log Block Trailer (占4Byte),其他的空间是真正⽤来存储⽇志的区域 Log Block Body (占496B)
9.6.2 Log Block Header和Log Block Trailer都记录了哪些信息?
- Log Block Header 和 Log Block Trailer 包含的信息如下图所⽰:
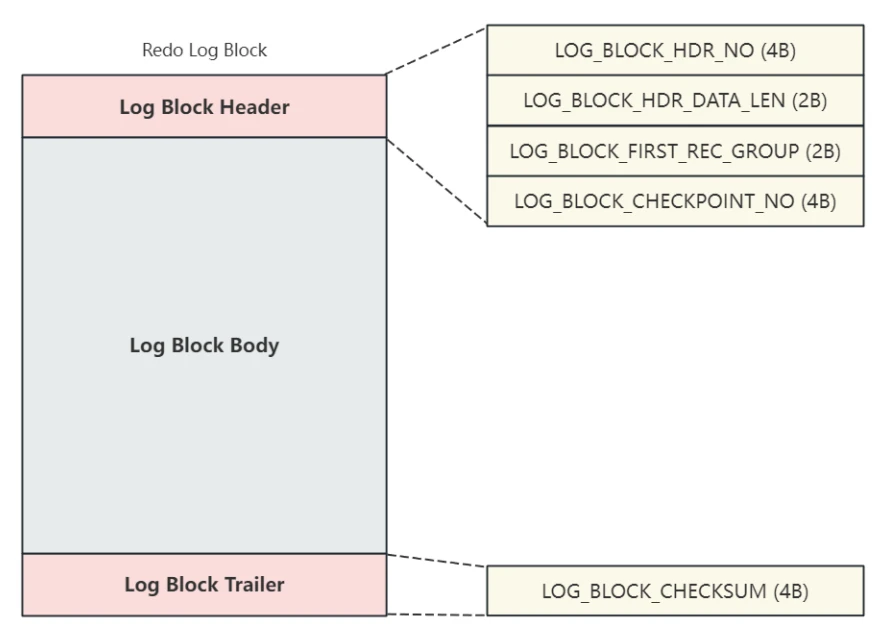
Log Block HeaderLOG_BLOCK_HDR_NO:Block的唯⼀标识,是⼀个⼤于0的值,取值范围1~0x40000000UL,⽽0x40000000UL对应的整数是1073741824即1GB,也就是说InnoDB最多能够⽣成1GB个⽇志块,每个⽇志块为512B,所以InnoDB允许维护⽇志的最⼤容量为 512GB ,在后⾯介绍配置⽇志相关的选项时,关于⽇志容量的⼤⼩就是以此为依据;LOG_BLOCK_HDR_DATA_LEN:表⽰Block中已经使⽤了多少字节,由于块头占⽤了12B的空间,所以初始值为12,当 Log Block Body 被全部写满时那么这个值就是512;LOG_BLOCK_FIRST_REC_GROUP:如果⼀个MTR会⽣产多条redo⽇志记录,这些⽇志记录被称之为⼀个redo⽇志记录组,LOG_BLOCK_FIRST_REC_GROUP代表该Block中第⼀个MTR中第⼀条⽇志的偏移量。
Log Block TrailerLOG_BLOCK_CHECKSUM:表⽰Block的校验和,⽤于正确性校验。
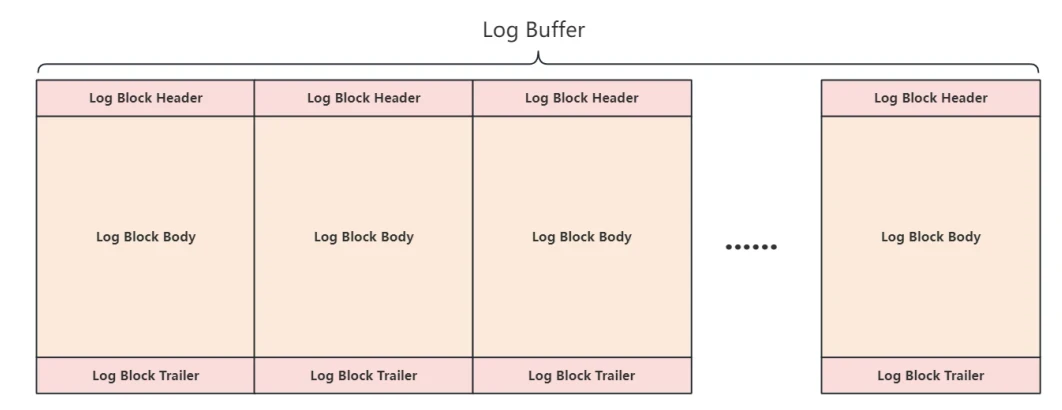
9.6.3 Redo Log Block在Log Buffer中是如何组织的?
- 在内存中RedoLog存储在⽇志缓冲区(Log Buffer)中,⽇志缓冲区是服务器启动时向操作系统申请的⼀⽚连续的内存区域,并被划分成若⼲个连续的 Redo Log Block ,⽤来存储即将要写⼊磁盘⽇志⽂件的数据,如下图所⽰:
- ⽇志缓冲区⼤⼩可以通过系统变量
innodb_log_buffer_size指定,默认⼤⼩为 16MB ,取值范围1048576(1MB) ~ 4294967295(4GB)
🔍 分析过程
- 向⽇志缓冲区中写⼊⽇志是⼀个顺序写⼊的过程,也就是从缓冲区的第⼀个 Redo Log Block 的 Log Block Body 开始依次向后写,⼀个block的空间空间⽤完之后再写下⼀个block,那么有⼀个⾸先要解决的问题,当有⼀记⽇志需要写⼊缓冲区时,应该往哪个block中的哪个位置写呢?
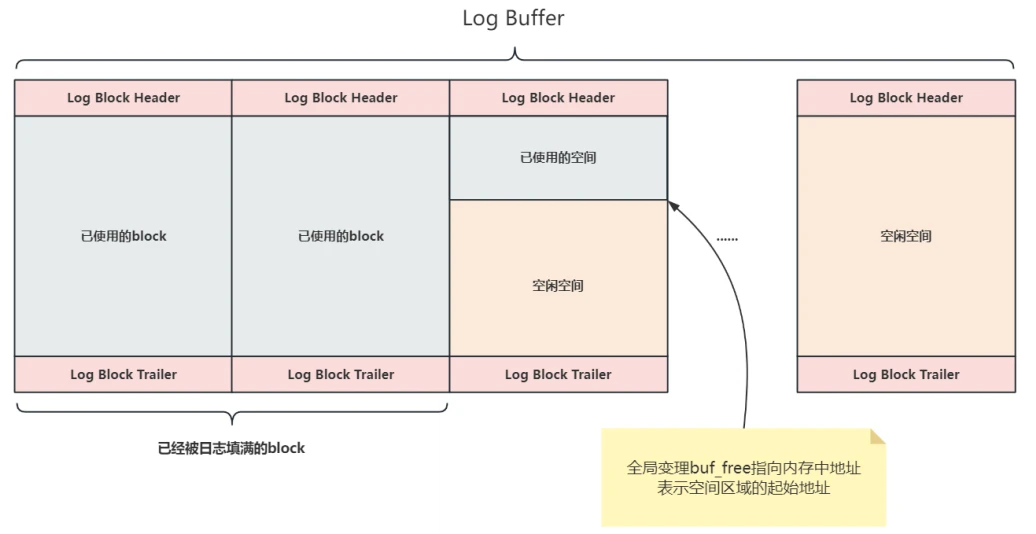
9.6.4 从⽇志缓冲区写RedoLog时从内存中的哪个地址开始写?
- InnoDB 的提供了⼀个名为 buf_free 的全局变量,该变量表⽰后续写⼊⽇志在 Log Buffer中的起始位置,如图所⽰:
9.6.5 不同的事务在并发执⾏时如何记录RedoLog?
- 通过前⾯的介绍了解到,InnoDB以MTR为单位记录RedoLog,⼀个事务中包含多个MTR,⼀个MTR包含多条RedoLog,这些RedoLog是⼀个不可分割的⽇志组;
- ⼀个事务在执⾏过程中并不是每⽣成⼀条RedoLog就写⼊到Log Buffer中,⽽是把⽣成的RedoLog先缓存在内存的⼀个区域中,当⼀个MTR执⾏完成后把这组⽇志⼀起复制到Log Buffer;
- 假设有两个事务T1, T2并发执⾏,每个事务中都包含2个MRT,即事务T1包含mtr_t1_1和mtr_t1_2,T2包含mtr_t2_1和mtr_t2_2,如下图所⽰:
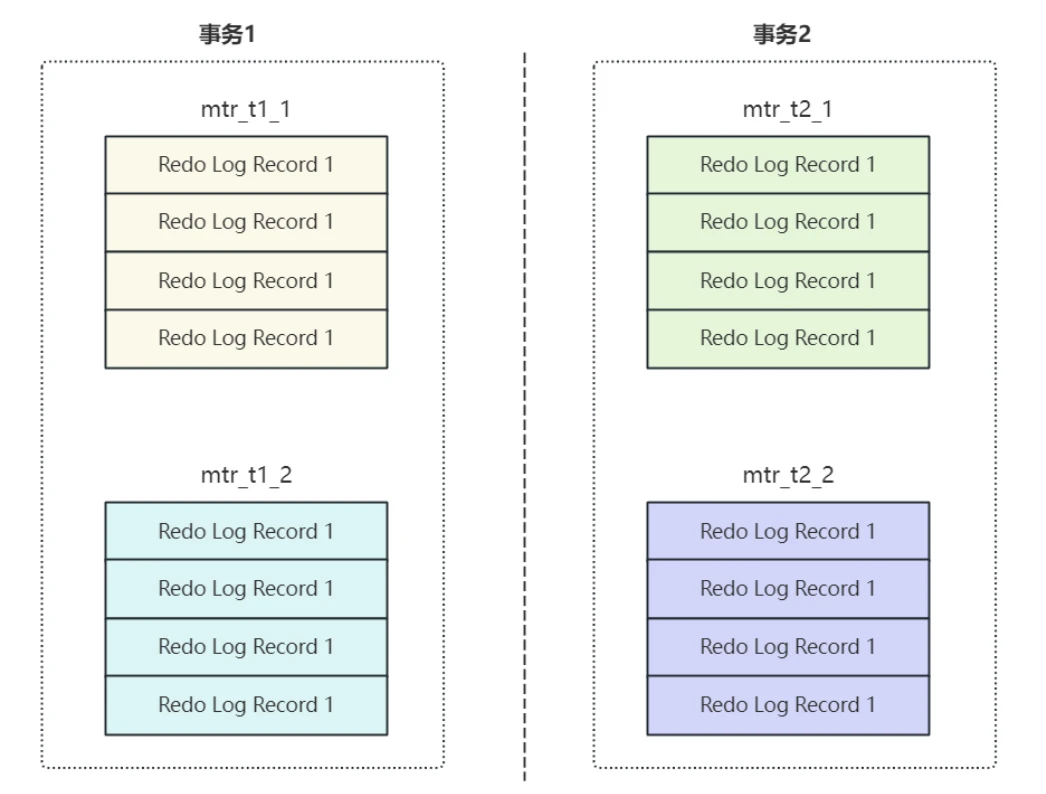
- 在并发环境下不同事务中的MTR是交替执⾏的,当MTR执⾏完成之后对应⽣成的RedoLog会被写⼊ Log Buffer
所以在Log Buffer中⽇志的写⼊形式如下图所⽰: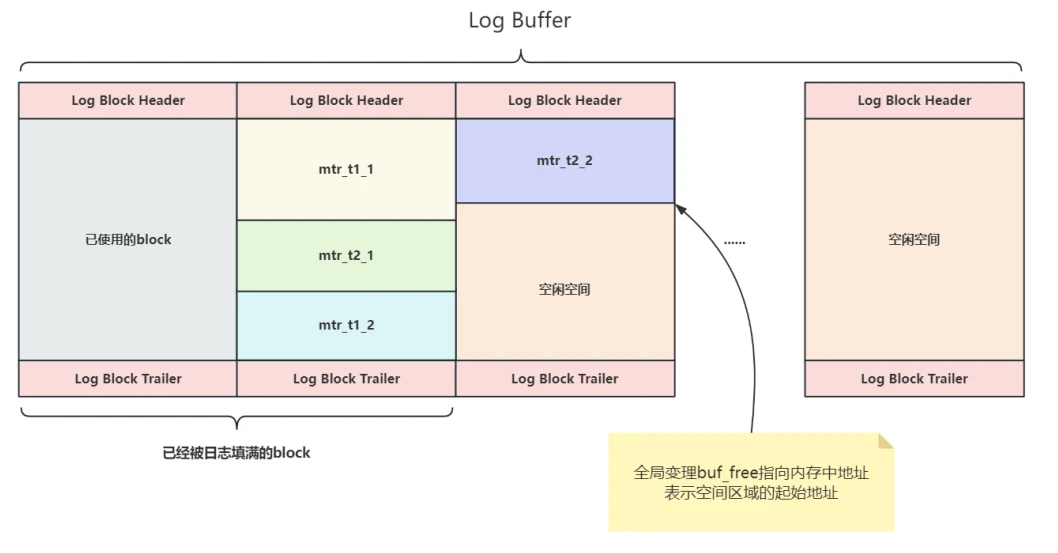
- 需要说明⼀点,不同的MTR产⽣的⽇志组占⽤的存储空间可能不⼀样,有的MTR产⽣的⽇志很少,有的MTR产⽣的⽇志量⾮常多。
✅ 解答问题
- RedoLog在内存中⽤Redo⻚进⾏组织,称为 Redo Log Block ,每个 Redo Log Block ⼤⼩固定为512B,对应磁盘上⼀个扇区,⽇志被顺序安排在 Log Block Body 中;
- 在Log Buffer中多个 Redo Log Block 顺序排列, Redo Log Block 的个数由Log Buffer的⼤⼩决定;
- 当执⾏事务时,不同的语句对应不同的数据库操作,⼀条SQL语句可能包含多个MTR,⼀个MTR包含多条RedoLog,MTR中的多条⽇志称为⼀个⽇志组,写⼊Log Buffer的⽇志是以MTR对应的⽇志组为⼀个单位,这组⽇志不可分割。
9.7 Redo Log的刷盘时机?
🔍 分析过程
- 当⼀个MTR执⾏完成后,RedoLog会被写⼊Log Buffer,⽽Log Buffer⼤⼩是有限的,并且这些记录⽇志的⽬的是为了服务器崩溃后的数据恢复,在内存中保存也不安全,所以在把它们刷到磁盘上进⾏保存
✅ 解答问题
- InnoDB在以下情况会把RedoLog刷到磁盘:
- Log Buffer 空间不⾜时:Log Buffer⼤⼩是有限的,可以通过系统变量innodb_log_buffer_size 设置,如果当前Log Buffer中的RedoLog占⽤了Log Buffer总容量⼀半左右会触发刷盘;
- 事务提交时:当事务提交时,事务中对应的MTR已经完全记录在了Log Buffer中,在数据真正落盘之前,需要把对应的RedoLog刷新到磁盘;
- 后台线程定时刷盘:后台的 Master Thread 线程,⼤约每秒都会把Log Buffer中的RedoLog刷新到磁盘;
- 正常关闭服务器时:在服务关闭之前会把会把Log Buffer中的RedoLog刷新到磁盘;
- 做检查点( checkpoint )操作时
9.7.1 刷盘策略可以进⾏配置吗?
- 可以
- ⽇志缓冲区的内容定期刷新到磁盘,可以通过系统变量 Innodb_flush_log_at_timeout=N 设置,N默认为1,单位为秒;
- 通过设置系统变量
innodb_flush_log_at_trx_commit设置写⼊和刷盘策略,默认值为1- 0 :⽇志每秒写⼊系统缓冲区并刷新到磁盘,未写⼊系统缓冲区的事务⽇志可能会在MYSQL崩溃时丢失;
- 1 :⽇志在每次事务提交时写⼊系统缓冲区并刷新到磁盘;
- 2 :⽇志在每次事务提交后写⼊系统缓冲区并每秒⼀次刷新到磁盘,未刷新到磁盘的⽇志可能在系统崩溃时丢失。
- 如果启⽤⼆进制⽇志且设置 sync_binlog = 1 时,则必须设置innodb_flush_log_at_trx_commit = 1
9.7.2 不同的刷盘策略有什么影响?
⾸先看⼀下Log Buffer、操作系统缓存和磁盘中⽇志⽂件的关系,如图所⽰:
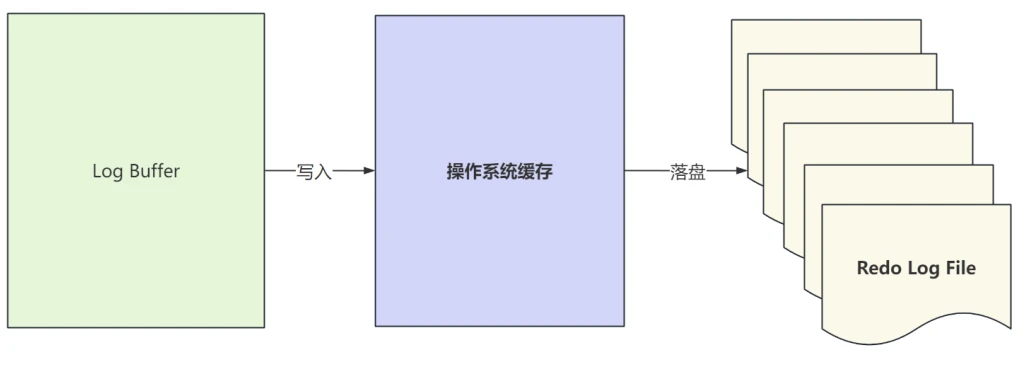
- 这⾥主要讨论系统变量 innodb_flush_log_at_trx_commit 对应的⼏种情况:
- 值为0时:表⽰⽇志每秒写⼊操作系统缓存并刷新到磁盘,如果MySQL崩溃,那么在⼀秒内没有写⼊操作系统缓存的Redo Log将会丢失;
- 值为2时:⽇志在每次事务提交后写⼊系统缓冲区并每秒⼀次刷新到磁盘,此时已提交的事务Redo Log全部都写⼊了操作系统缓存,MySQL⽆论是否崩溃,Redo Log都会以指定的时间刷新到磁盘,但是如果服务器崩溃或断电,将会导致操作系统缓存中的Redo Log丢失;
- 值为 1 时:⽇志在每次事务提交时写⼊系统缓冲区并刷新到磁盘,此时Redo Log从Log Buffer中写⼊操作系统缓存并⽴即刷新到磁盘,从⽽尽可能的保证⽇志的完整性,推荐使⽤。
9.8 Redo Log对应磁盘上的⽂件是什么?
🔍 分析过程
- 重做⽇志⽂件位于数据⽬录下的 #innodb_redo ⽬录中
- 重做⽇志⽂件分为普通类型和备⽤类型,普通类型是正在使⽤的⽇志⽂件,备⽤是准备使⽤的⽇志⽂件,InnoDB 共维护 32 个重做⽇志⽂件,每个⽂件的⼤⼩等于 1/32 * innodb_redo_log_capacity
- 重做⽇志⽂件使⽤ #ib_redoN 命名约定,其中 N 是重做⽇志⽂件编号,备⽤的重做⽇志⽂件使⽤ _tmp 为后缀。如下⽰例显⽰有21个活动(普通)重做⽇志⽂件和11个备⽤重做⽇志⽂件:

- 每个普通的重做⽇志⽂件都与⼀个特定的 LSN 取值范围相关联,⽤于崩溃恢时快速定位到要执⾏重做的⽇志,可以使⽤下⾯的查询显⽰活动重做⽇志⽂件的 START_LSN 和 END_LSN 值;
✅ 解答问题
- 重做⽇志⽂件位于数据⽬录下的 #innodb_redo ⽬录中,在MySQL8.0中InnoDB 共维护 32 个重做⽇志⽂件,每个⽂件的⼤⼩等于 1/32 * innodb_redo_log_capacity
- 重做⽇志⽂件分为普通类型和备⽤类型,并且使⽤ #ib_redoN 命名约定,其中 N 是重做⽇志⽂件编号,备⽤的重做⽇志⽂件使⽤ _tmp 为后缀
- 重做⽇志的总容量可以通过系统变量 innodb_redo_log_capacity 设置,8.0.34版本开始最⼤为512GB
9.8.1 这么多⽇志⽂件⽇志写到哪个⽂件中?
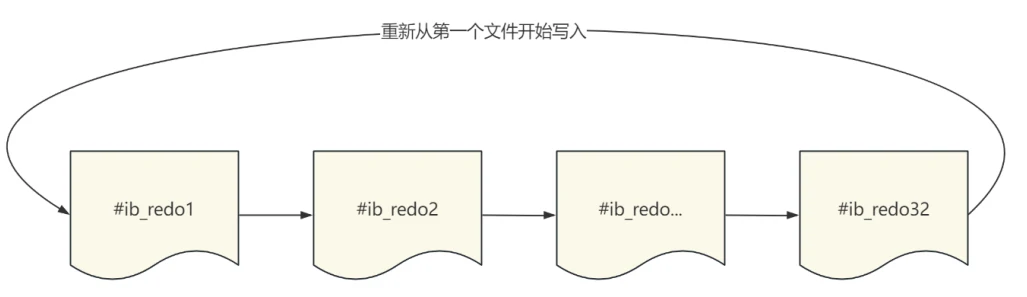
- 通过查看 #innodb_redo ⽬录,可以看到系统⽣成了32个RedoLog⽂件,当RedoLog从内存刷到磁盘时,先从第⼀个⽇志⽂件开始写,第⼀个写满之后顺序写到第⼆个,以此类推;如果最后⼀个也写满了,就会重新从第⼀个⽂件开始写,也就是说重做⽇志⽂件可以循环使⽤,如图所⽰:
- 这⾥可能会出现⼀个问题,如果循环写⼊的话,那么后写⼊的⽇志会不会把之前写⼊的内容覆盖了?当然有这个可能,为了解决这个问题,InnoDB提出checkpoint的概念,关于checkpoint后⾯会详细介绍。
9.8.2 什么是LSN?
-
LSN是 Log Sequence Number 的简写,称为⽇志序号;
-
MySQL在运⾏期间,只要执⾏DML操作就会修改数据⻚,意味着会不断的⽣成RedoLog,InnoDB为了记录⽣成的⽇志总量(字节数),设计了⼀个只增不减的全局变量,这个全局变量就是LSN,起始值: 16*512 = 8192 ,最⼤值 2^64 - 1 ;
-
当⼀个MTR所包含的⼀组RedoLog被记录在 Redo Log Block 中时,实际是保存在 Log Block Body 区域,但是在统计LSN增量时,如果MTR跨 Block 保存时,是按照实际写⼊的⽇志⼤⼩加上 Log Block Header 所占的12Byte)和块尾 Log Block Trailer 所占4Byte;
-
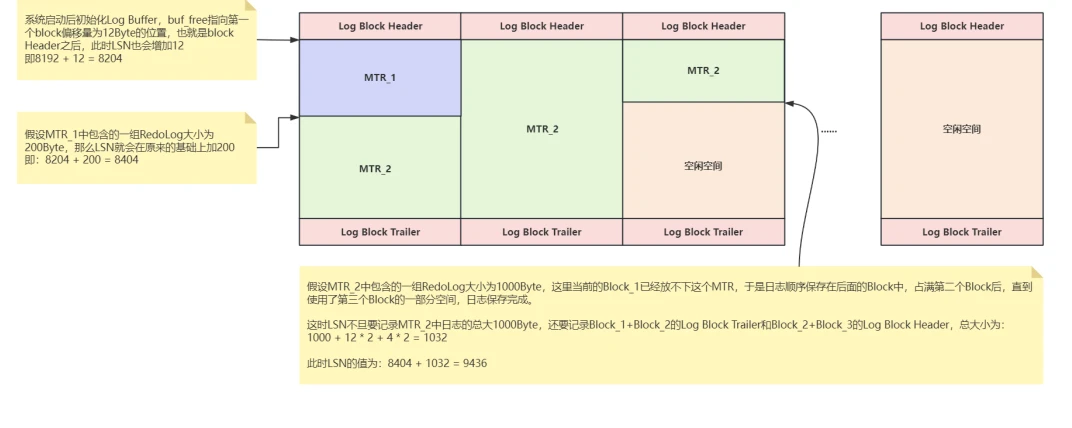
⽰例:
- 系统启动后初始化Log Buffer,buf_free指向第⼀个block偏移量为12Byte的位置,也就是block Header之后,此时LSN也会增加12,即8192 + 12 = 8204
- 假设MTR_1中包含的⼀组RedoLog⼤⼩为200Byte,那么LSN就会在原来的基础上加200,即:8204 + 200 = 8404
- 假设MTR_2中包含的⼀组RedoLog⼤⼩为1000Byte,这⾥当前的Block_1已经放不下这个MTR,于是⽇志顺序保存在后⾯的Block中,占满第⼆个Block后,直到使⽤了第三个Block的⼀部分空间,⽇志保存完成;
这时LSN不但要记录MTR_2中⽇志的总⼤1000Byte,还要记录Block_1+Block_2的Log BlockTrailer和Block_2+Block_3的Log Block Header,总⼤⼩为:1000 + 12 * 2 + 4 * 2 = 1032,此时LSN的值为:8404 + 1032 = 9436,如下图所⽰:
9.9 Redo Log⽇志⽂件的格式?
🔍 分析过程
9.9.1 Log Buffer中的Redo Log Block与磁盘中的Redo Log Block有哪些不同?
-
在内存中Log Buffer是⼀⽚连续的内存空间,被划分成了若⼲个 512 字节⼤⼩的 Redo Log Block ⽤来保存Redo Log,将Log Buffer中的Redo Log刷新到磁盘,本质就是把 Redo Log Block 的写⼊⽇志⽂件中,所以Redo Log对应的⽇志⽂件其实也是由若⼲个 512 字节⼤⼩的block 组成。MySQL会根据配置⽣成⼀组撤销⽇志⽂件,每个⽂件的格式和⼤⼩都⼀样,由两部分组成:
- 管理区:前 2048 个字节,也就是前4个block存储⼀些⽇志⽂件的管理信息
- 数据区:从第2048字节往后是⽤来存储Log Buffer对应的 Redo Log Block
-
也就是说真实的⽇志是从每个⽇志⽂件的第2048个字节开始写⼊,如图所⽰

-
所以Log Buffer中的Redo Log Block与磁盘中的Redo Log Block在结构上是相同的,只不过在磁盘上多了⽤于⽂件管理的⽂件头信息
✅ 解答问题
- 磁盘中RedoLog的格式与内存中的格式相同,在内存中Log Buffer是⼀⽚连续的内存空间,被划分成了若⼲个 512 字节⼤⼩的 Redo Log Block ⽤来保存Redo Log,将Log Buffer中的Redo Log刷新到磁盘,本质就是把 Redo Log Block 的写⼊⽇志⽂件中,所以Redo Log对应的⽇志⽂件其实也是由若⼲个 512 字节⼤⼩的 block 组成,只不过在磁盘上多了⽤于⽂件管理的⽂件头信息。
9.9.2 重做⽇志⽂件管理区包含哪些信息?
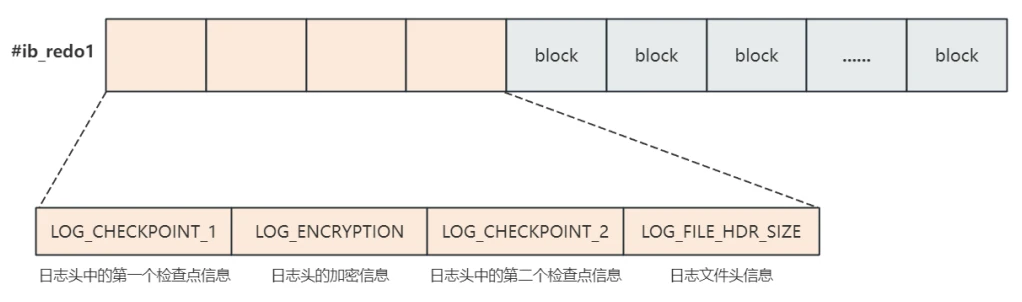
- 关于 Redo Log Block :的结构与内存结构相同,前 2048字节 分为4个Block分别为:
LOG_CHECKPOINT_1:第⼀个⽇志⽂件中⽇志头的第⼀个检查点信息LOG_ENCRYPTION⽇志⽂件头信息中的加密信息LOG_CHECKPOINT_2:第⼀个⽇志⽂件中⽇志头的第⼆个检查点信息LOG_FILE_HDR_SIZE:⽇志⽂件头信息
9.9.3 管理区中具体管理了什么信息?
- 管理区各字段中的信息随着MySQL版本迭代变化⾮常⼤,这⾥主要介绍⼀些关键信息
LOG_CHECKPOINT_1、LOG_CHECKPOINT_2:主要是记录CHECKPOINT操作时对应的LSN,LSN会交替写⼊到 LOG_CHECKPOINT_1 和 LOG_CHECKPOINT_2 中,具体写⼊规则后⾯介绍- LOG_ENCRYPTION : LOG_FILE_HDR_SIZE 中的加密信息
- LOG_FILE_HDR_SIZE :主要记录⽇志⽂件的⼀些信息,主要包括:
- LOG_HEADER_FORMAT :占4字节,⽇志的格式标识,和MySQL版本相关,有重⼤更新的版本才设置相应的值,在MySQL5.7.9之前⼀直都是0
- LOG_HEADER_START_LSN :占8字节,⽇志⽂件中第⼀个LSN编号
LOG_HEADER_CREATOR:占32字节,记录⽇志的创建者,正常⽣成的⽇志⼀般为"MEB"+MySQL的版本号,如果是运⾏mysqlbackup程序,在备份过程中⽣成的⽇志,则记录MySQL的版本号
9.10 什么是CHECKPOINT - 检查点?
🔍 分析过程
- RedoLog从内存刷到磁盘上的⽇志⽂件使⽤循环写⼊的⽅式,也就是从第⼀个⽇志⽂件顺序写到最后⼀个⽇志⽂件,当最后⼀个⽇志⽂件写满时⼜重新写第⼀个⽇志⽂件,那么就可能出现⽇志被覆盖的情况,那么哪些⽇志可以被覆盖哪些不能被覆盖呢?
9.10.1 哪些RedoLog可以被覆盖?
- ⾸先回顾⼀下RedoLog的作⽤,RedoLog是⽤作崩溃后恢复没有完成落盘的事务,也就是说当Buffer Pool中的脏⻚写⼊RedoLog,但数据⻚还没有落盘时发⽣的崩溃,当服务器重启之后可以根据RedoLog进⾏恢复,这也是RedoLog的应⽤时机,所以这种状态下的RedoLog不能被覆盖,如下图所⽰:
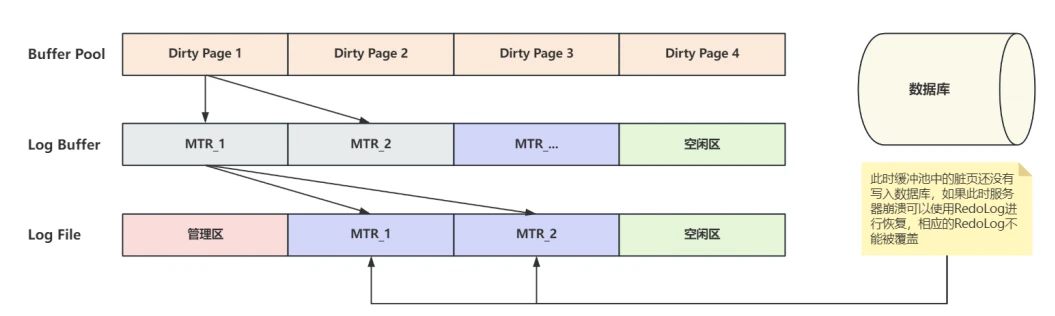
- 如果缓冲池中的脏⻚在记录RedoLog之后,也完成了真正的落盘操作,那么相应的RedoLog就没有⽤了,所以这部分RedoLog就可以被覆盖,如下图所⽰:
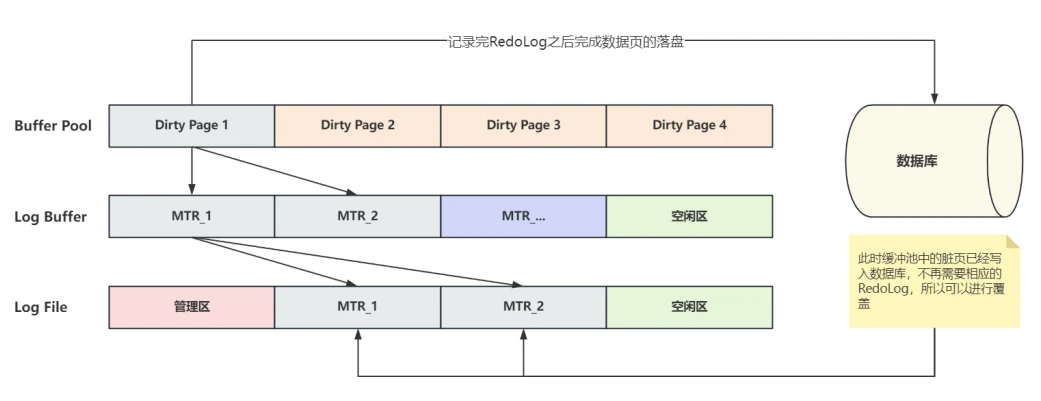
- 经过分析可以看出,判断⽇志⽂件中的RedoLog是否可以覆盖的依据是它对应的数据⻚是否已经刷新到磁盘。
9.10.2 如何记录可以覆盖的⽇志⽂件位置?
- 前⾯介绍过InnoDB使⽤LSN是来记录RedoLog总字节数,在这个基础上InnoDB采⽤⼀个全局变量checkpoint_lsn 来记录当前系统中可以被覆盖⽇志总量是多少,也就是说checkpoint_lsn 记录已落盘脏⻚对应的⽇志结束时LSN的值,此时LSN⼩于checkpoint_lsn 的RedoLog就可以被覆盖,如图所⽰:
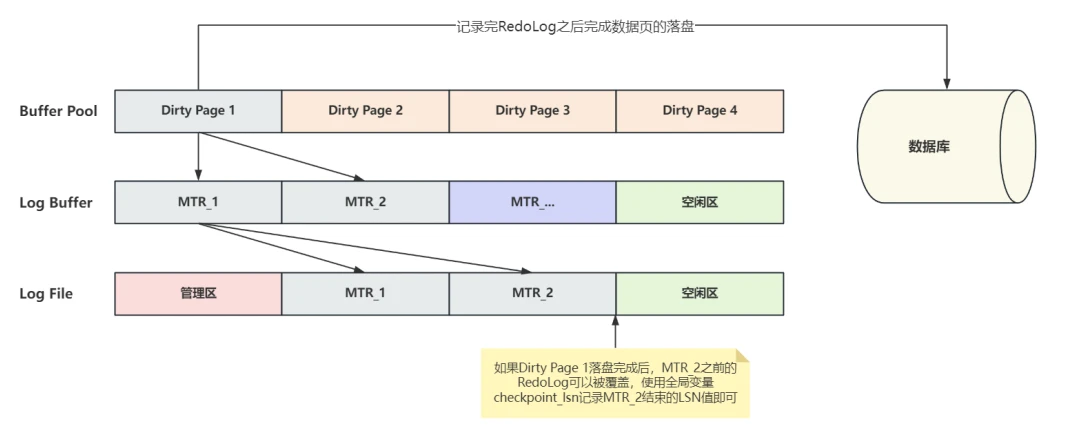
- 当脏⻚刷新到磁盘之后,重新计算 checkpoint_lsn 的操作,称为⼀次 CHECKPOINT 操作,也可以说是重置⼀次检查点,系统会⽤⼀个 checkpoint_no 变量记录发⽣ CHECKPOINT 操作的次数,每做⼀ CHECKPOINT 操作 checkpoint_no 就会加1
- 由于RedoLog⽂件的⼤⼩是固定的,在系统启动时已经分配好了对应的 Redo Log Block ,所以很容易就可以根据 checkpoint_lsn 计算写⼊位置在⽇志⽂件中的偏移量
- 关于检查点相关的 checkpoint_no 、 checkpoint_lsn 以及写⼊偏移量的信息会被记录在第⼀个⽇志⽂件的管理区,同时InnoDB规定,当checkpoint_no的值是偶数时写到checkpoint1 中,是奇数时写到 checkpoint2 中。
✅ 解答问题
CHECKPOINT也称为检查点,由于RedoLog⽂件是可以循环使⽤的,当最后⼀个⽂件写满时⼜会从第⼀个⽂件开始写⼊,这必将导致⽼的⽇志被覆盖, CHECKPOINT 是标记已被刷新到磁盘的脏⻚刷对应的RedoLog可以被覆盖的⼀种操作,当⽇志的LSN⼩于已落盘脏⻚对应的LSN都可以被覆盖。
9.10.3 如果没有⼩于 checkpoint_lsn 的⽇志时如何处理?
- 如果⽇志⽂件中没有⼩于 checkpoint_lsn 的⽇志时,表明⽇志⽂件已经使⽤完了,这时原来的⽇志不能被覆盖,InnoDB会先优先刷新脏⻚到磁盘,再做 CHECKPOINT 操作,之后再继续进⾏⽇志记录。
9.11 重做⽇志还有哪些主要的配置项?
🔍 分析过程
- 重做⽇志在磁盘上所占的空间可以通过系统变量
innodb_redo_log_capacity控制,变量值以字节为单位,最⼤值 549755813888 ,表⽰ 512GB ,可以在选项⽂件或在运⾏时使⽤ SET GLOBAL 语句进⾏设置,如下所⽰:
# 将RedoLog的最⼤容量设置为8GB
SET GLOBAL innodb_redo_log_capacity = 8589934592;
- 重做⽇志的⽬录可以通过系统变量 innodb_log_group_home_dir 进⾏设置,如果没有指定则⽇志⽂件位于数据⽬录的 #innodb_redo ⽬录中,如果定义了innodb_log_group_home_dir 变量,则⽇志⽂件存放在该⽬录下的 #innodb_redo ⽬录中;
✅ 解答问题
- 根据实际应⽤场景通过配置对应的系统变量来指定 Redo Log 在磁盘上所占的空间的⼤⼩、所在⽬录等属性。
9.12 如何查看重做⽇志的状态?
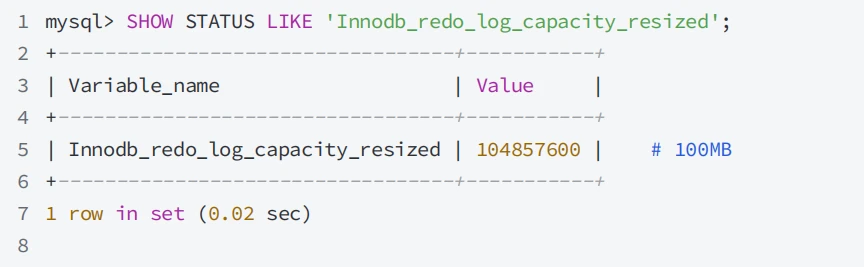
- 通过状态变量 innodb_redo_log_capacity_resized 显⽰当前重做⽇志容量限制:
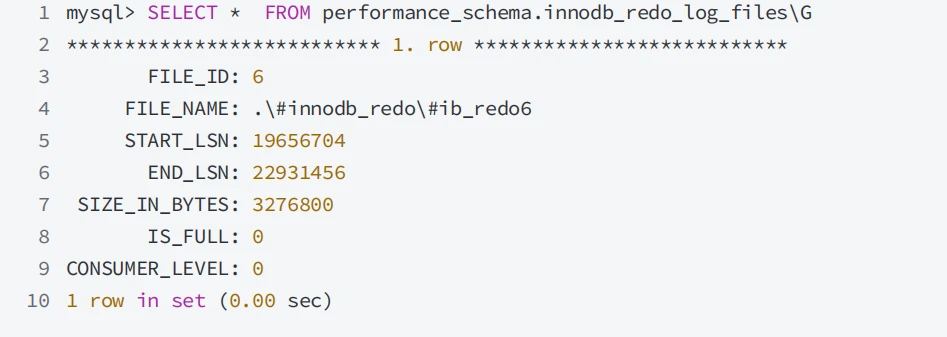
- 可以通过查询 performance_schema.innodb_redo_log_files 表来查看活动重做⽇志⽂件的信息
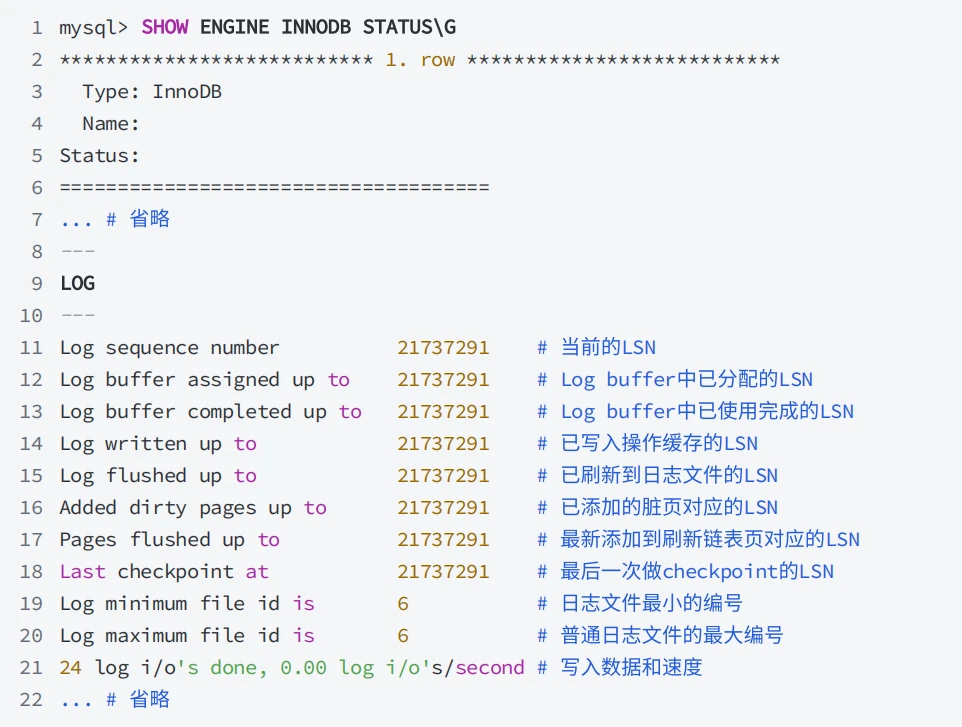
- 通过使⽤
SHOW ENGINE InnoDB STATUS访问 InnoDB 标准监视器输出中 LOG 部分查看有关Redo Log的信息
9.13 如何根据RedoLog进⾏崩溃恢复?
🔍 分析过程
- 在MySQL正常运⾏时,RedoLog不仅发挥不了它的作⽤⽽且还会对服务器的性能造成影响,但是服务器⼀旦崩溃,在重新启动时,就可以根据RedoLog中的记录把数据⻚恢复到崩溃前的状态
9.13.1 如何确定哪些⽇志需要恢复?
- 前⾯我们介绍过每⼀次 CHECKPOINT 操作都会重新计算 checkpoint_lsn ,checkpoint_lsn 之前的⽇志表⽰已经被刷到磁盘数据⻚所⽣成的RedoLog,既然已被刷到磁盘,也就没有必要进⾏恢复,所以需要恢复的是 checkpoint_lsn 之后的⽇志
9.13.2 如何获取最新的 checkpoint_lsn 和恢复的起点?
- RedoLog⽂件组中的第⼀个⽂件的管理信息中有两个block checkpoint1 和 checkpoint2 ,其中都存储了 checkpoint_lsn 和 checkpoint_no 信息,每次做 CHECKPOINT 操作时,会在这两个block中交替写⼊ CHECKPOINT 信息,只要需要把这两个block中保存的checkpoint_no 值⽐较⼀下,哪个值⼤就表⽰哪个block存储的就是最近的⼀次checkpoint信息。这样我们就能拿到最近发⽣的 checkpoint 对应的 checkpoint_lsn 值以及它在RedoLog⽂件组中的偏移量 checkpoint_offset 。
9.13.3 如何确认恢复的终点?
- 我们⽤之前已经掌握的内容分析⼀下这个问题,⾸先RedoLog是顺序写⼊的,当⼀个block写满了之后再写下⼀个,⽽每⼀个block的 log block header 中都有⼀个名为LOG_BLOCK_HDR_DATA_LEN 的属性,该属性记录了当前block使⽤了多少字节,对于写满的block来说,该值⼀定是 512 ,所以找到第⼀个 LOG_BLOCK_HDR_DATA_LEN 的值不为512,就可以确定恢复扫描的最后⼀个block,这个block中的最后⼀条⽇志就是恢复的终点。
9.13.4 如何进⾏恢复?
- 确定了需要扫描哪些⽇志进⾏崩溃恢复之后,接下来就是怎么进⾏恢复了,假设现在的⽇志⽂件中有RedoLog,如图所⽰:

-
第⼀条⽇志在 checkpoint_lsn 之前,表⽰已经落盘不⽤恢复;
-
checkpoint_lsn 之后的⽇志可以通过顺序扫描的⽅式,根据⽇志记录的内容依次恢复对应的数据⻚
-
InnoDB在顺序读取⽇志进⾏恢复的过程中采⽤了⼀些优化措施:⾸先根据⽇志的 Space Id 和Page No 计算出散列值,以这个散列值为 KEY ,把 Space Id 和 Page No 相同的⽇志放到哈希表的同⼀个槽⾥,如果有多个 Space Id 和 Page No 相同的⽇志,那么按照⽇志⽣成的先后顺序使⽤链表连接起来,如下图所⽰:
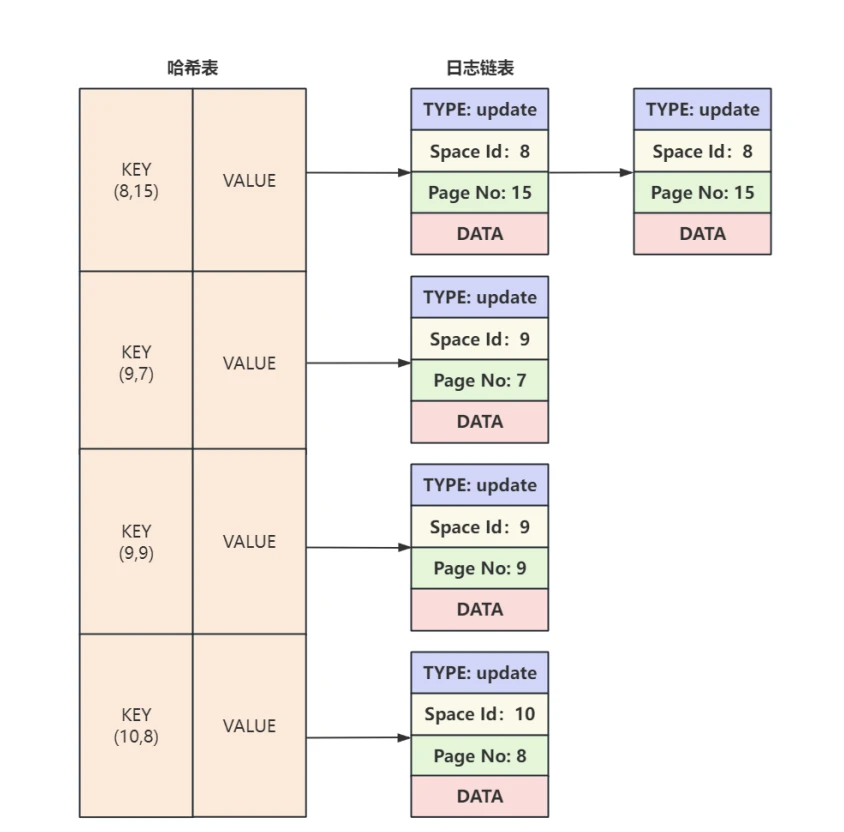
- 组织好⽇志后,通过遍历哈希表,就可以⼀次把⼀个数据⻚中的修改全部恢复好,减少了读取数据⻚时的随机I/O次数
9.13.5 如何确定哪些⽇志在崩溃前已经落盘?
-
checkpoint_lsn 之后的⽇志有可能就根本没有落盘,也有可能已经落盘但没有来的及做CHECKPOINT ,在恢复时如何区分呢?
-
在⻚结构章节介绍过,磁盘上的每个⻚都包含⼀个 File Header 信息,其中⼜包含已被刷到磁盘的LSN: FIL_PAGE_FILE_FLUSH_LSN 信息,在恢复时就可以通过当前⽇志对应的LSN与FIL_PAGE_FILE_FLUSH_LSN 进⾏⽐较,如果⽇志的LSN⼩于已刷新到磁盘的LSN,那就证明⽇志对应的数据在崩溃之前已经落盘,直接跳过即可
✅ 解答问题
恢复的过程主要分为以下⼏步:
-
通过 checkpoint_lsn 和第⼀个没有写满的⽇志⻚确定需要恢复⽇志的起始和结束位置;
-
遍历⽇志并把Space Id 和 Page No相同的⽇志组织在⼀起,以便⼀次性恢复完相应数据⻚的所有内容;
-
⽇志的LSN⼩于磁盘数据⻚⽂件记录的已刷新LSN时,表⽰这些数据在崩溃之前已落盘,跳过即可。
⼩结

相关文章:
【mysql进阶】4-6. InnoDB 磁盘文件
InnoDB 磁盘⽂件 1 InnoDB存储引擎包含哪些磁盘⽂件? 🔍 分析过程 ✅ 解答问题 InnoDB的磁盘⽂件主要是表空间⽂件和其他⽂件,表空间包括:系统表空间、独⽴表空间、通⽤表空间、临时表空间和撤销表空间;其他⽂件有重做…...
HexForge:一款用于扩展安全汇编和十六进制视图的IDA插件
关于HexForge HexForge是一款用于扩展安全汇编和十六进制视图的IDA插件,在该工具的帮助下,广大研究人员可以方便地直接从 IDA Pro 界面数据解码、解密或执行安全数据审计任务。 功能介绍 1、从 IDA 的反汇编或十六进制视图复制原始十六进制;…...
WORFBENCH:一个创新的评估基准,目的是全面测试大型语言模型在生成复杂工作流 方面的性能。
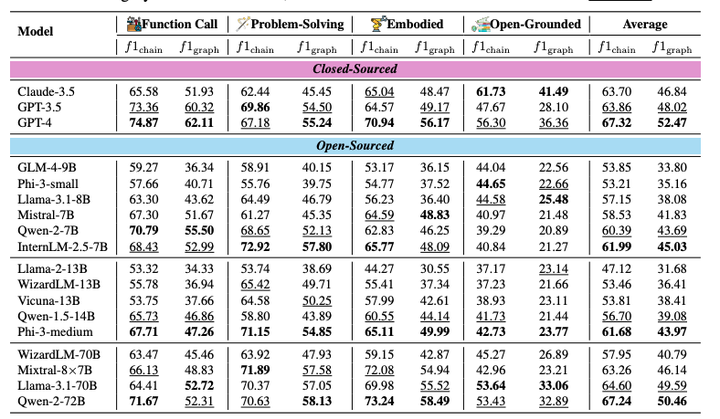
2024-10-10,由浙江大学和阿里巴巴集团联合创建的WORFBENCH,一个用于评估大型语言模型(LLMs)生成工作流能力的基准测试。它包含了一系列的测试和评估协议,用于量化和分析LLMs在处理复杂任务时分解问题和规划执行步骤的能力。WORFBE…...

SpringBoot 集成 Activiti 7 工作流引擎
一. 版本信息 IntelliJ IDEA 2023.3.6JDK 17Activiti 7 二. IDEA依赖插件安装 安装BPM流程图插件,如果IDEA的版本超过2020,则不支持actiBPM插件。我的IDEA是2023版本我装的是 Activiti BPMN visualizer 插件。 在Plugins 搜索 Activiti BPMN visualizer 安装创建…...

UVM初学篇 -(22)UVM field_automation 域的自动化机制
field_automation机制是域的自动化的机制,这个机制的最大的优点是可以对一些变量进行批量的处理,比如对象拷贝、克隆、打印之类的变量。 一、 成员变量的注册 使用field_automation机制首先要用uvm_field 系列宏完成变量的注册,类中的成员变…...

STL二分查找
本课主要介绍容器部分里面的二分查找函数。涉及的函数有 3 个,这 3 个函数的强两个输入参数都和迭代器有关,或者说参数是可以迭代的,而第三个参数则是你要查找的值。 1. binary_search binary_search 的返回结果是 bool 值,如果找…...

啤酒游戏—企业经营决策沙盘
感谢黄浦区文华学院的邀请,今年是为南房集团开展系统思考培训的第二年。我们现在为客户设计的一整年系统思考训练中,会将系统环路结构图与真实议题研讨作为前置内容,让大家在理解整体框架后,再体验麻省理工学院系统动力学著名的“…...
尚硅谷-react教程-求和案例-@redux-devtools/extension 开发者工具使用-笔记
## 7.求和案例_react-redux开发者工具的使用(1).npm install redux-devtools/extension(2).store中进行配置import { composeWithDevTools } from redux-devtools/extension;export default createStore(allReducer,composeWithDevTools(applyMiddleware(thunk))) src/redux/s…...

【动手学强化学习】part2-动态规划算法
阐述、总结【动手学强化学习】章节内容的学习情况,复现并理解代码。 文章目录 一、什么是动态规划?1.1概念1.2适用条件 二、算法示例2.1问题建模2.2策略迭代(policyiteration)算法2.2.1伪代码2.2.2完整代码2.2.3运行结果2.2.4代码…...

【python爬虫实战】爬取全年天气数据并做数据可视化分析!附源码
由于篇幅限制,无法展示完整代码,需要的朋友可在下方获取!100%免费。 一、主题式网络爬虫设计方案 1. 主题式网络爬虫名称:天气预报爬取数据与可视化数据 2. 主题式网络爬虫爬取的内容与数据特征分析: - 爬取内容&am…...

初识Linux · 动静态库(incomplete)
目录 前言: 静态库 动态库 前言: 继上文,我们从磁盘的理解,到了文件系统框架的基本搭建,再到软硬链接部分,我们开始逐渐理解了为什么运行程序需要./a.out了,这个前面的.是什么我们也知道了。…...

华为OD机试 - 匿名信(Java 2024 E卷 100分)
华为OD机试 2024E卷题库疯狂收录中,刷题点这里 专栏导读 本专栏收录于《华为OD机试(JAVA)真题(E卷D卷A卷B卷C卷)》。 刷的越多,抽中的概率越大,私信哪吒,备注华为OD,加…...
通过rancher2.7管理k8s1.24及1.24以上版本的k8s集群
目录 初始化实验环境 安装Rancher 登录Rancher平台 通过Rancher2.7管理已存在的k8s最新版集群 文档中的YAML文件配置直接复制粘贴可能存在格式错误,故实验中所需要的YAML文件以及本地包均打包至网盘. 链接:https://pan.baidu.com/s/1oYX4eGoBtW_R-7i…...

text-align的属性justify
text-align常用的属性是left、center、right,具体的可参考css解释,今天重点记录的对象是justify justify 可以使文本的两端都对齐在两端对齐文本中,文本行的左右两端都放在父元素的内边界上。然后,调整单词和字母间的间隔&#x…...

使用python自制桌面宠物,好玩!——枫原万叶桌宠,可以直接打包成exe去跟朋友炫耀。。。
大家好,我是小黄。 今天我们使用python实现一个桌面宠物。只需要gif动态图片就行。超级简单容易上手。 #完整源代码可在下方图片免费获取 一:下载相关的库文件。 我们本次使用到的库文件为:tkinter和pyautogui 下载命令: pip…...
使用 ASP.NET Core 8.0 创建最小 API
构建最小 API,以创建具有最小依赖项的 HTTP API。 它们非常适合需要在 ASP.NET Core 中仅包括最少文件、功能和依赖项的微服务和应用。 本教程介绍使用 ASP.NET Core 生成最小 API 的基础知识。 在 ASP.NET Core 中创建 API 的另一种方法是使用控制器。 有关在最小 …...
气候服务平台ClimateSERV2.0简介(python)
1 简介 ClimateSERV 2.0允许开发从业者、科学家/研究人员和政府决策者可视化和下载历史降雨数据、植被状况数据以及 180 天的降雨和温度预报,以增进对农业和水资源供应相关问题的理解并做出改进的决策。 这些数据可以通过 Web 应用程序直接访问,也可以…...

Docker | centos7上对docker进行安装和配置
安装docker docker配置条件安装地址安装步骤2. 卸载旧版本3. yum 安装gcc相关4. 安装需要的软件包5. 设置stable镜像仓库6. 更新yum软件包索引7. 安装docker引擎8. 启动测试9. 测试补充:设置国内docker仓库镜像 10. 卸载 centos7安装docker https://docs.docker.com…...

React--》掌握Valtio让状态管理变得轻松优雅
Valtio采用了代理模式,使状态管理变得更加直观和易于使用,同时能够与React等框架无缝集成,本文将深入探讨Valtio的核心概念、使用场景以及其在提升应用性能中的重要作用,帮助你掌握这一强大工具,从而提升开发效率和用户…...

python爬虫百度图片
直接给代码,可直接用,个人需要修改的地方有两处: self.directory 这是本地存储地址,修改为自己电脑的地址,另外,**{}**不要删spider.json_count 10 这是下载的图像组数,一组有30张图像&#x…...

ImageStrike深度解析:CTF图像隐写技术的实战应用之旅
ImageStrike深度解析:CTF图像隐写技术的实战应用之旅 【免费下载链接】ImageStrike ImageStrike是一款用于CTF中图片隐写的综合利用工具 项目地址: https://gitcode.com/gh_mirrors/im/ImageStrike 在网络安全竞赛的战场上,图像隐写技术就像一场无…...

RT-Thread Studio 2.2.5 vs 2.2.6:版本差异对STM32项目开发的影响实测
RT-Thread Studio 2.2.5 vs 2.2.6:版本差异对STM32项目开发的影响实测 在嵌入式开发领域,RT-Thread Studio作为一款集成开发环境,已经成为许多STM32开发者的首选工具。最近,其2.2.6版本的发布引发了不少讨论——这个看似微小的版本…...

南北阁Nanbeige 4.1-3B与Typora集成:智能文档创作工具
南北阁Nanbeige 4.1-3B与Typora集成:智能文档创作工具 1. 引言 写技术文档是很多开发者和技术作者的日常任务,但往往耗时耗力。你需要构思结构、组织内容、调整格式,还要反复校对确保准确。现在,有了南北阁Nanbeige 4.1-3B模型与…...

腾讯云二级域名配置全攻略:从解析到Nginx部署一步到位
腾讯云二级域名配置全攻略:从解析到Nginx部署一步到位 在数字化浪潮中,拥有一个专属的二级域名不仅能提升品牌形象,还能为不同业务模块提供独立的访问入口。本文将手把手教你如何在腾讯云平台完成从域名解析到Nginx配置的全流程操作ÿ…...
保姆级教程:从GitHub克隆到网页实时显示)
ESP32驱动OV7670摄像头(无FIFO)保姆级教程:从GitHub克隆到网页实时显示
ESP32驱动OV7670摄像头(无FIFO)全流程实战指南 在智能硬件开发领域,视觉感知一直是提升项目智能化水平的关键。对于预算有限的学生团队和物联网爱好者来说,ESP32搭配OV7670摄像头无疑是最经济实惠的视觉解决方案之一。本文将带你…...

OpenHarmony开发避坑指南:手把手教你写对BUILD.gn,解决90%的编译问题
OpenHarmony开发避坑指南:手把手教你写对BUILD.gn,解决90%的编译问题 在OpenHarmony开发中,BUILD.gn文件是构建系统的核心配置文件,它决定了代码如何被编译、链接和打包。然而,许多开发者在编写BUILD.gn时常常陷入各种…...
)
IFRS/IAS 核心财务概念中英对照速查手册(附实务应用场景)
1. IFRS/IAS核心财务概念入门指南 刚接触国际财务报告准则时,我完全被那些英文缩写搞晕了。记得第一次看到IFRS 16和IAS 38时,还以为是什么密码代号。其实这些术语就像财务界的"普通话",掌握它们才能在全球商业舞台上顺畅交流。 国…...

深入解析ASCAD数据集:从元数据到侧信道攻击实践
1. ASCAD数据集基础解析 第一次接触ASCAD数据集时,我和大多数研究者一样感到困惑——这个被广泛引用的侧信道分析基准数据集,实际操作起来却像在迷宫里找出口。经过半年的实战摸索,我终于理清了它的脉络。ASCAD全称"ANSSI Side-Channel …...

Windows NTFS硬链接技术深度解析:EternalBlaze如何实现磁盘空间零成本释放
在Windows操作系统中,NTFS文件系统提供了一项被大多数用户忽视的强大功能——硬链接(Hard Link)。 这项技术允许单个文件在文件系统中拥有多个路径引用,而所有引用均指向同一份物理数据块。 EternalBlaze正是基于这一底层机制开…...

从路径遍历到RCE:深度剖析Ollama CVE-2024-37032漏洞原理与利用链
1. Ollama与CVE-2024-37032漏洞背景 Ollama作为本地运行大型语言模型的工具链,近年来在开发者社区中迅速走红。它简化了从模型下载、配置到交互的全流程,甚至能让不懂机器学习原理的用户快速体验AI能力。但正是这种"开箱即用"的特性ÿ…...