【Python知识】一个强大的数据分析库Pandas
文章目录
- Pandas概述
- 1. 安装 Pandas
- 2. 基本数据结构
- 3. 数据导入和导出
- 4. 数据清洗
- 5. 数据选择和过滤
- 6. 数据聚合和摘要
- 7. 数据合并和连接
- 8. 数据透视表
- 9. 时间序列分析
- 10. 数据可视化
- 📈 如何使用 Pandas 进行复杂的数据分析?
- 1. 数据预处理
- 2. 处理缺失值
- 3. 处理异常值
- 4. 数据转换
- 5. 去重
- 6. 特征工程
- 7. 数据划分
Pandas概述
Pandas 是一个强大的 Python 数据分析库,它提供了快速、灵活且富有表现力的数据结构,旨在使数据清洗、处理和分析工作变得更加简单和高效。以下是 Pandas 的详细说明:
1. 安装 Pandas
如果你还没有安装 Pandas,可以通过 pip 命令安装:
pip install pandas
2. 基本数据结构
Pandas 提供了两种主要的数据结构:Series 和 DataFrame。
-
Series:
- 类似于一维数组,可以包含任何数据类型(整数、字符串、浮点数、Python 对象等)。
- 每个
Series都有一个索引(Index),它可以是默认的整数索引,也可以是自定义的标签。
import pandas as pd s = pd.Series([1, 3, 5, np.nan, 6, 8]) print(s) -
DataFrame:
- 类似于二维表格型数据结构,可以被看作是由多个
Series组成的(每列一个Series)。 DataFrame有行索引和列索引,可以包含不同类型的列。
data = {'Column1': [1, 2, 3, 4],'Column2': ['a', 'b', 'c', 'd']} df = pd.DataFrame(data) print(df) - 类似于二维表格型数据结构,可以被看作是由多个
3. 数据导入和导出
Pandas 支持多种格式的数据导入和导出,包括 CSV、Excel、JSON、HTML 和 SQL 数据库等。
# 从 CSV 文件读取数据
df = pd.read_csv('data.csv')# 将数据写入 CSV 文件
df.to_csv('output.csv', index=False)# 从 Excel 文件读取数据
df = pd.read_excel('data.xlsx')# 将数据写入 Excel 文件
df.to_excel('output.xlsx', index=False)
4. 数据清洗
Pandas 提供了丰富的函数来处理缺失数据、重复数据、数据类型转换等。
# 处理缺失值
df.dropna(inplace=True) # 删除缺失值
df.fillna(value='default_value', inplace=True) # 填充缺失值# 删除重复数据
df.drop_duplicates(inplace=True)# 数据类型转换
df['Column'] = df['Column'].astype('int')
5. 数据选择和过滤
Pandas 提供了灵活的方法来选择和过滤数据。
# 选择列
selected_columns = df[['Column1', 'Column2']]# 选择行
selected_rows = df[df['Column'] > value]# 使用条件过滤
filtered_df = df[df['Column'].apply(lambda x: x > value)]
6. 数据聚合和摘要
Pandas 允许你轻松地对数据进行聚合和摘要统计。
# 数据描述性统计
print(df.describe())# 数据聚合
aggregated_data = df.groupby('Column').agg(['mean', 'sum', 'max'])
7. 数据合并和连接
Pandas 提供了 merge、join 和 concat 等函数来合并和连接数据。
# 合并两个 DataFrame
merged_df = pd.merge(df1, df2, on='key', how='inner')# 连接两个 DataFrame
concatenated_df = pd.concat([df1, df2], axis=0)
8. 数据透视表
Pandas 的 pivot_table 功能允许你快速创建数据透视表。
pivot_table = pd.pivot_table(df, values='Column', index='RowColumn', columns='ColumnColumn', aggfunc='mean')
9. 时间序列分析
Pandas 有强大的时间序列分析功能,可以轻松处理和分析时间序列数据。
# 创建时间序列索引
time_series = pd.Series(data, index=pd.date_range('20210101', periods=len(data)))# 时间序列数据的重采样
resampled_data = time_series.resample('M').sum()
10. 数据可视化
Pandas 可以与 Matplotlib 集成,提供数据可视化功能。
df.plot(kind='line', x='Column1', y='Column2')
plt.show()
Pandas 是 Python 数据分析和处理的强大工具,它的功能远远超出了这里介绍的内容。通过学习 Pandas,你可以更有效地处理和分析数据,从而提高工作效率。更多详细信息和使用指南,可以参考 Pandas 的官方文档。
📈 如何使用 Pandas 进行复杂的数据分析?
使用Pandas进行复杂的数据清洗通常涉及多个步骤,包括数据预处理、异常值处理、缺失值处理、数据转换、去重、特征工程等。以下是一些常用的数据清洗技巧和示例代码:
1. 数据预处理
读取数据:
import pandas as pd# 读取CSV文件
df = pd.read_csv('data.csv')# 读取Excel文件
df = pd.read_excel('data.xlsx')# 读取数据库
from sqlalchemy import create_engine
engine = create_engine('database_url')
df = pd.read_sql_query('SELECT * FROM table_name', con=engine)
初步查看数据:
# 查看数据前几行
print(df.head())# 查看数据基本信息
print(df.info())# 查看数据描述性统计
print(df.describe())
2. 处理缺失值
删除缺失值:
# 删除含有缺失值的行
df = df.dropna()# 删除含有缺失值的列
df = df.dropna(axis=1)
填充缺失值:
# 用常数填充缺失值
df = df.fillna(value=0)# 用前一个值填充缺失值
df = df.fillna(method='ffill')# 用后一个值填充缺失值
df = df.fillna(method='bfill')
插值填充缺失值:
# 线性插值填充缺失值
df = df.interpolate(method='linear')
3. 处理异常值
识别异常值:
# 假设数值列的Z分数大于3或小于-3为异常值
from scipy import stats
df = df[(np.abs(stats.zscore(df['column'])) < 3)]
处理异常值:
# 将异常值替换为中位数
median_value = df['column'].median()
df['column'] = np.where(np.abs(stats.zscore(df['column'])) > 3, median_value, df['column'])
4. 数据转换
类型转换:
# 将列转换为数值类型
df['column'] = pd.to_numeric(df['column'], errors='coerce')# 将列转换为日期类型
df['date_column'] = pd.to_datetime(df['date_column'])
编码分类数据:
# 将分类变量转换为哑变量(One-Hot Encoding)
df = pd.get_dummies(df, columns=['categorical_column'])
5. 去重
删除重复数据:
# 删除完全重复的行
df = df.drop_duplicates()# 删除基于某些列的重复行
df = df.drop_duplicates(subset=['column1', 'column2'])
6. 特征工程
创建新特征:
# 根据现有数据创建新特征
df['new_column'] = df['column1'] * df['column2']
特征选择:
# 使用方差选择特征
from sklearn.feature_selection import VarianceThreshold
selector = VarianceThreshold(threshold=0.5)
df = df.iloc[:, selector.get_support(indices=True)]
7. 数据划分
训练集和测试集划分:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df.drop('target_column', axis=1), df['target_column'], test_size=0.2, random_state=42)
这些是使用Pandas进行复杂数据清洗的一些关键步骤和技巧。在实际应用中,你可能需要根据具体的数据特点和分析目标来调整这些步骤。Pandas提供了丰富的功能和灵活性,使得它成为数据清洗和预处理的强大工具。
相关文章:

【Python知识】一个强大的数据分析库Pandas
文章目录 Pandas概述1. 安装 Pandas2. 基本数据结构3. 数据导入和导出4. 数据清洗5. 数据选择和过滤6. 数据聚合和摘要7. 数据合并和连接8. 数据透视表9. 时间序列分析10. 数据可视化 📈 如何使用 Pandas 进行复杂的数据分析?1. 数据预处理2. 处理缺失值…...

10.26学习
1.整形的定义和输出 在C语言中,整形(Integer)是一种基本数据类型,用于存储整数。整形变量可以是正数、负数或零。在定义和输出整形变量时,需要注意以下几点: ①定义整形变量: 使用 int 关键字…...
CSS易漏知识
复杂选择器可以通过(id的个数,class的个数,标签的个数)的形式,计算权重。 如果我们需要将某个选择器的某条属性提升权重,可以在属性后面写!important;注意!importent要写在;前面 很多公司不允许…...

【10天速通Navigation2】(三) :Cartographer建图算法配置:从仿真到实车,从原理到实现
前言 往期内容: 第一期:【10天速通Navigation2】(一) 框架总览和概念解释第二期:【10天速通Navigation2】(二) :ROS2gazebo阿克曼小车模型搭建-gazebo_ackermann_drive等插件的配置和说明 本教材将贯穿nav2的全部内容,…...

测试造数,excel转insert语句
目录 excel转sql的insert语句一、背景二、直接上代码 excel转sql的insert语句 一、背景 在实际测试工作中,需要频繁地进行测试造数并插入数据库验证,常规的手写sql语句过于浪费时间,为此简单写个脚本,通过excel来造数࿰…...
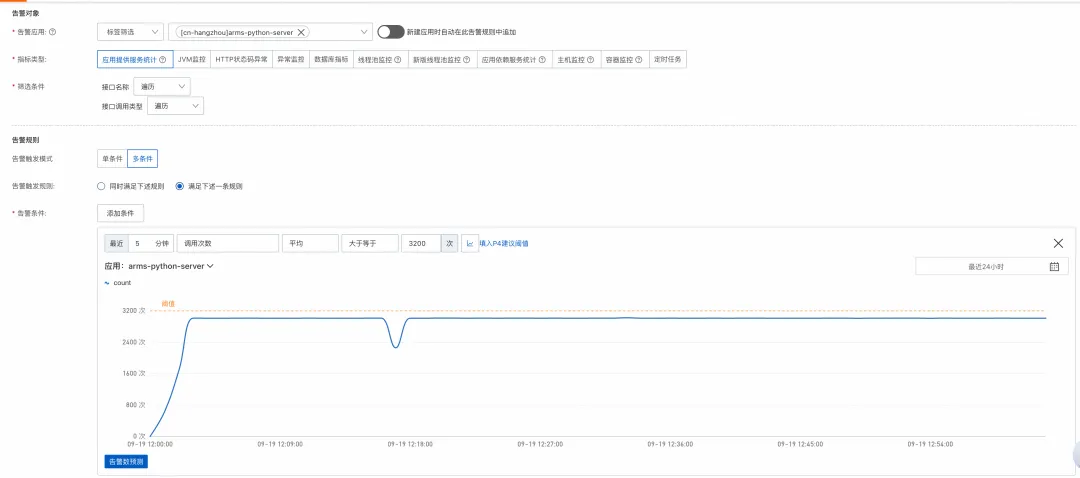
Python 应用可观测重磅上线:解决 LLM 应用落地的“最后一公里”问题
作者:彦鸿 背景 随着 LLM(大语言模型)技术的不断成熟和应用场景的不断拓展,越来越多的企业开始将 LLM 技术纳入自己的产品和服务中。LLM 在自然语言处理方面表现出令人印象深刻的能力。然而,其内部机制仍然不明确&am…...

从零开始:用Spring Boot搭建厨艺分享网站
2 相关技术 2.1 Spring Boot框架简介 Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程。该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。通过这种方式,Sprin…...
《2024中国泛娱乐出海洞察报告》解析,垂直且多元化方向发展!
随着以“社交”为代表的全球泛娱乐市场规模不断扩大以及用户需求不断细化,中国泛娱乐出海产品正朝着更加垂直化、多元化的方向发展。基于此,《2024中国泛娱乐出海洞察报告》深入剖析了中国泛娱乐行业出海进程以及各细分赛道出海现状及核心特征。针对中国…...

强化学习数学原理学习(一)
前言 总之开始学! 正文 先从一些concept开始吧,有一个脉络比较好 state 首先是就是状态和状态空间,显而易见,不多说了 action 同理,动作和动作空间 state transition 状态转换,不多说 policy 策略,不多说 reward 奖励,不多说 MDP(马尔科夫) 这里需要注意到就是这个是无…...

获 Sei 基金会投资的 MetaArena :掀起新一轮链上游戏革命
MetaArena 是一个综合性的 Web3 游戏开发和发布平台,集成了最先进的技术架构,包括 Unreal Engine 5.3、去中心化虚拟资产交易市场和分布式计算资源支持。平台不仅为开发者提供了高效的开发工具,还通过跨链功能和 AI 模块,极大简化…...

react-signature-canvas 实现画笔与橡皮擦功能
react-signature-canvas git 地址 代码示例 import React, { Component } from react import { createRoot } from react-dom/clientimport SignaturePad from ../../src/index.tsximport * as styles from ./styles.module.cssclass App extends Component {state { trimmed…...

004:ABBYY PDF Transformer安装教程
引言:本文主要讲解。 一、软件介绍 ABBYY PDF Transformer由ABBYY公司出品,属于一款家庭及商业都适用的PDF文档转换工具。它结合了ABBYY的OCR(光学字符识别)技术和Adobe PDF库技术,以确保能够便捷地处理任何类型的PDF…...

FlinkSQL之temporary join开发
在实时开发中,双流join获取目标对应时刻的属性时,经常使用temporary join。笔者在流量升级的实时迭代中,需要让流量日志精准的匹配上浏览时间里对应的商品属性,使用temporary join开发过程中踩坑不少,将一些经验沉淀在…...

第二十六节 直方图均衡化
图像直方图均衡化 图像直方图均衡化可以增强图像增强,对输入图像进行直方图均衡化处理,提升后续对象检测的准确率在Opencv人脸检测的代码演示中已经很常见了,此外对医学影像图像与卫星遥感图像也经常通过直方图均衡化来提升图像质量 Opencv…...
工单管理用什么工具好?8款推荐清单
本文推荐的8款项目工单管理系统有:1. PingCode; 2.Worktile; 3.Teambition; 4.致远OA; 5.TAPD; 6.Gitee; 7.Wrike; 8.Trello。 很多企业在处理项目工单时,依然依赖电子邮件、Excel表格,甚至是手动记录。这样做不仅效率低下,还容易导致工单遗漏…...
工地安全新突破:AI视频监控提升巡检与防护水平
在建筑工地和其他劳动密集型行业,工人的安全一直是管理工作的重中之重。为了确保工地的安全管理更加高效和智能化,AI视频监控卫士。通过人工智能技术,系统不仅能实时监控,还能自动识别工地现场的安全隐患,为工地管理者…...

World of Warcraft [CLASSIC][80][the Ulduar]
Ulduar 奥杜尔副本介绍 奥杜尔共计14个BOSS,通常说的10H就是10个苦难模式就是全通,9H就是除了【观察者奥尔加隆】,特别说明开启【观察者奥尔加隆】,是需要打掉困难模式4个守护者的。 所以人们经常说的类似“10H 观察者”、“10H…...

python实现数据库的增删改查功能,图形化版本
import tkinter from tkinter import * import psycopg2 from tkinter import messagebox#连接信息 t_conn{"dbname": "d1","user": "u1","password": "123qqq...A","port": "15400","h…...

pipeline开发笔记
pipeline开发笔记 jenkins常用插件Build Authorization Token Root配置GitLab的webhooks(钩子)配置构建触发器--示例 piblish over sshBlue OceanWorkspace Cleanup PluginGit插件PipelineLocalization: Chinese (Simplified) --中文显示Build Environment Plugin 显示构建过程…...

spark读取parquet文件
源码 parquet文件读取的入口是FileSourceScanExec,用parquet文件生成对应的RDD 非bucket文件所以走createNonBucketedReadRDD方法。 createNonBucketedReadRDD 过程: 确定文件分割参数 openCostInBytes4M 相关参数spark.sql.files.openCostInBytes4M…...

SpringBoot 3.2.0 项目里,如何优雅地引入 Flowable 7.1.0 工作流引擎?
SpringBoot 3.2.0 项目优雅集成 Flowable 7.1.0 工作流引擎实战指南 在微服务架构中引入工作流引擎,往往意味着需要在不破坏现有架构的前提下实现业务流程的自动化管理。本文将深入探讨如何在已具备MyBatis-Plus、Spring Cloud Alibaba等技术栈的SpringBoot 3.2.0项…...

Zephyr与MCUBoot的深度整合:从构建到安全启动的完整指南
1. 为什么需要安全启动? 在嵌入式开发中,设备固件的安全性往往是最容易被忽视的一环。想象一下,如果你的智能门锁固件被恶意篡改,或者医疗设备的程序被非法替换,后果会有多严重?这就是为什么我们需要MCUBoo…...

终极英雄联盟工具集:3大核心功能让你轻松掌控游戏全局
终极英雄联盟工具集:3大核心功能让你轻松掌控游戏全局 【免费下载链接】League-Toolkit 兴趣使然的、简单易用的英雄联盟工具集。支持战绩查询、自动秒选等功能。基于 LCU API。 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League-Toolkit…...

【Python内存管理终极指南】:20年专家实测5大智能策略,90%开发者忽略的GC优化盲区揭晓
第一章:Python智能体内存管理策略对比评测报告全景概览本报告聚焦于当前主流Python智能体(Agent)框架在内存管理层面的设计差异与运行表现,涵盖LangChain、LlamaIndex、AutoGen及自研轻量Agent Runtime四大实现。评测维度包括对象…...

中兴光猫配置解密工具:突破运营商限制,掌握家庭网络自主权
中兴光猫配置解密工具:突破运营商限制,掌握家庭网络自主权 【免费下载链接】ZET-Optical-Network-Terminal-Decoder 项目地址: https://gitcode.com/gh_mirrors/ze/ZET-Optical-Network-Terminal-Decoder 在家庭网络管理中,你是否曾因…...
;应用:控制图形属性)
【Matlab】MATLAB教程:图形句柄;案例:h=plot(x,y);应用:控制图形属性
MATLAB教程:图形句柄;案例:h=plot(x,y);应用:控制图形属性 在MATLAB数据可视化、实验报告绘图、工程结果展示等场景中,仅仅通过plot函数绘制基础图形远远不够。实际科研与工程应用中,往往需要精准调整图形的线条样式、颜色、标记点、坐标轴、图例等属性,让图形更清晰、…...

从原理图到实测:手把手打造Ti电量计通讯盒EV2400
1. 为什么需要自制EV2400通讯盒 搞锂电池开发的朋友应该都熟悉Ti的电量计芯片,比如bq系列。这些芯片需要通过I2C/SMBus或者HDQ接口与电脑通信,这时候就需要一个通讯盒作为桥梁。官方EV2400虽然好用,但价格实在不亲民,而且功能上可…...
Pixel Language Portal快速部署:Hunyuan-MT-7B支持ONNX Runtime加速推理
Pixel Language Portal快速部署:Hunyuan-MT-7B支持ONNX Runtime加速推理 1. 项目概述 像素语言跨维传送门(Pixel Language Portal)是一款基于Tencent Hunyuan-MT-7B核心引擎构建的创新翻译工具。与传统翻译软件不同,它将语言转换过程重新设计为一场16-…...

什么是 AI Agent?它和直接调用大模型 API 做一次问答有什么本质区别?
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:AI大模型原理和应用面试题 文章目录一、🍀AI Agent概念、AI Agent和直接…...

SAP BAPI实战指南:核心模块高频接口速查与应用解析
1. SAP BAPI入门:为什么开发者需要这份速查手册 第一次接触SAP BAPI时,我盯着满屏的接口文档差点崩溃——光是FICO模块就有二十多个常用BAPI,每个接口的参数列表长得像毕业论文。后来在项目上踩过几次坑才明白,BAPI的难点不在于技…...