【项目实战】HuggingFace初步实战,使用HF做一些小型任务
Huggingface初步实战
- 一、前期准备工作
- 二、学习pipline
- 2.1.试运行代码,使用HuggingFace下载模型
- 2.2. 例子1,情感检测分析(只有积极和消极两个状态)
- 2.3. 例子2,文本生成
- 三、学会使用Tokenizer & Model
- 3.1.tokenizer(分词器)是处理文本数据的重要组件
- 3.2.tokenizer对字符串处理过程
- 四、pytorch的简单使用
- 五、模型的保存save & 加载load
- 六、学会使用huggingface的文档!
一、前期准备工作
1.会使用Conda创建自己的虚拟环境
2.会激活自己的虚拟环境
3.了解一定pytorch基础
官方要求:
python 3.6+
pytorch 1.1.0+
TensorFlow 2.0+
本文使用的环境:
python 3.7.1
pytorch 1.13.1 py3.7_cuda11.7_cudnn8_0
tensorflow 1.15.0

二、学习pipline
pipeline是Hugging Face Transformers库中的一个高层API,旨在简化各种自然语言处理任务的执行。通过它,用户可以在几行代码内实现从模型加载到推理的整个流程,而不需要深入了解模型的架构细节。
pipeline 支持多种常见任务,包括:
- 文本分类(如情感分析):对输入文本进行分类,返回类别标签和置信度。
- 问答:基于上下文回答问题。
- 文本生成(如对话生成):基于输入提示生成文本片段。
- 翻译:将文本从一种语言翻译成另一种语言。
- 填空(填充掩码):完成缺失的词或短语,适用于填空任务。
通过指定任务名称,如pipeline("sentiment-analysis"),可以直接加载相关的预训练模型和分词器,使开发过程更加高效直观。
2.1.试运行代码,使用HuggingFace下载模型
Hugging Face的pipeline方法下载的模型默认会保存在用户目录下的.cache文件夹中,具体路径是:

C:/Users/11874/.cache/huggingface/transformers/

- 这里的代码是因为
需要网络代理(科学上网)才可以下载huggingface的模型 - 查找自己网络代理中的端口号,本文的端口号是
7890
2.2. 例子1,情感检测分析(只有积极和消极两个状态)
# 这里从Hugging Face的Transformers库中导入pipeline函数
# pipeline是一个高层API,便于直接调用预训练模型完成特定任务。
from transformers import pipeline# 这里使用Python的os模块设置了环境变量,将代理服务器的地址和端口号设置为
# 127.0.0.1:7890。这种设置通常用于需要通过代理访问互联网的情况
# 帮助解决从Hugging Face Hub下载模型时的网络连接问题。
import os
os.environ["http_proxy"] = "http://127.0.0.1:7890"
os.environ["https_proxy"] = "http://127.0.0.1:7890"# 这里通过pipeline创建了一个情感分析任务的管道。它会自动下载并加载一个适合情感分析的预训练模型(如基于BERT或DistilBERT的模型),并准备好用于推理。
classifier = pipeline("sentiment-analysis")# 这里调用classifier对输入的句子执行情感分析。模型会根据句子内容预测情感标签(例如"positive"或"negative"),并返回分类结果及其置信度。
res = classifier("I have been waiting for a HuggingFace course my whole life.")print(res)
输出:
[{'label': 'NEGATIVE', 'score': 0.9484281539916992}]
2.3. 例子2,文本生成
from transformers import pipelineimport os
os.environ["http_proxy"] = "http://127.0.0.1:7890"
os.environ["https_proxy"] = "http://127.0.0.1:7890"# 通过pipeline函数创建了一个文本生成的管道,并指定模型为distilgpt2,
# 这是一个较轻量的GPT-2模型。pipeline会自动从Hugging Face Hub下载该模型。
generator = pipeline("text-generation", model="distilgpt2")res = generator("In my home, I have a", # 对此内容扩写max_length = 30, # 生成的文本长度上限为30个token。num_return_sequences = 2, # 生成两个不同的文本序列,提供不同的生成结果。
)print(res)
输出:
[{'generated_text': 'In my home, I have a daughter, my son and her own daughter, and I have a son and daughter whose mom has been a patient with'},
{'generated_text': 'In my home, I have a couple dogs. Those were all my pets.\n“I started out in the farmhouse. I used to'}]
三、学会使用Tokenizer & Model
3.1.tokenizer(分词器)是处理文本数据的重要组件
-
exp1代码:使用了Hugging Face提供的高层次
pipeline接口,默认加载一个预训练的情感分析模型。这种方式简单易用,适合快速原型开发,但使用的具体模型和tokenizer不明确。 -
exp2代码:则显式地加载了特定的模型
distilbert-base-uncased-finetuned-sst-2-english及其对应的tokenizer。通过AutoModelForSequenceClassification和AutoTokenizer,用户可以更灵活地选择和定制模型。这种方式适合对模型进行微调或需要特定模型功能的情况。
from transformers import pipeline
from transformers import AutoTokenizer, AutoModelForSequenceClassificationimport os
os.environ["http_proxy"] = "http://127.0.0.1:7890"
os.environ["https_proxy"] = "http://127.0.0.1:7890"# exp 1:这段代码使用了Hugging Face提供的高层次pipeline接口,默认加载一个预训练的情感分析模型。这种方式简单易用,适合快速原型开发,但使用的具体模型和tokenizer不明确。
classifier = pipeline("sentiment-analysis")
res = classifier("I have been waiting for a HuggingFace course my whole life.")
print(res)# exp 2:这段代码则显式地加载了特定的模型distilbert-base-uncased-finetuned-sst-2-english及其对应的tokenizer。通过AutoModelForSequenceClassification和AutoTokenizer,用户可以更灵活地选择和定制模型。这种方式适合对模型进行微调或需要特定模型功能的情况。
model_name = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
res = classifier("I have been waiting for a HuggingFace course my whole life.")
print(res)
输出:
[{'label': 'POSITIVE', 'score': 0.9433633089065552}]
[{'label': 'POSITIVE', 'score': 0.9433633089065552}]
3.2.tokenizer对字符串处理过程
from transformers import AutoTokenizer, AutoModelForSequenceClassificationimport os
os.environ["http_proxy"] = "http://127.0.0.1:7890"
os.environ["https_proxy"] = "http://127.0.0.1:7890"model_name = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)#这一步使用tokenizer对输入的句子进行编码。
sequence = "Playing computer game is simple."
res = tokenizer(sequence)
print(res) # {'input_ids': [101, 2652, 3274, 2208, 2003, 3722, 1012, 102], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1]}# 这一行调用tokenizer.tokenize()方法将句子拆分为tokens(子词或词)。
# 在自然语言处理(NLP)中,分词通常是将文本切分为可以被模型处理的最小单位。
# 输出结果将是一个tokens的列表,例如:
tokens = tokenizer.tokenize(sequence)
print(tokens) # ['Playing', 'computer', 'game', 'is', 'simple', '.']# 这里使用tokenizer.convert_tokens_to_ids()方法将分词后的tokens转换为对应的ID。
# 每个token都有一个唯一的ID,这些ID可以被模型理解。
ids = tokenizer.convert_tokens_to_ids(tokens)
print(ids) # [2652, 3274, 2208, 2003, 3722, 1012]# 使用tokenizer.decode()方法将token ID转换回原始字符串。这个过程将ID映射回对应的tokens,并将它们合并成一个可读的文本。
decoded_string = tokenizer.decode(ids)
print(decoded_string) # playing computer game is simple.
输出:
{'input_ids': [101, 2652, 3274, 2208, 2003, 3722, 1012, 102], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1]}
['playing', 'computer', 'game', 'is', 'simple', '.']
[2652, 3274, 2208, 2003, 3722, 1012]
playing computer game is simple.
四、pytorch的简单使用
from transformers import pipeline
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
import torch.nn.functional as Fimport os
os.environ["http_proxy"] = "http://127.0.0.1:7890"
os.environ["https_proxy"] = "http://127.0.0.1:7890"# 1.还是用之前的pipeline应用
model_name = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)# 2.通常不止一个句子,这里我们多放一个句子,用list
text_Train = ["I love you, my wife.","Suzhou is the worst place!"]
# 3.输出分析的情感
res = classifier(text_Train)
print(res)# 4.使用分词器对输入的文本进行批处理,设置padding=True和truncation=True确保输入序列的长度一致。
max_length=512限制了输入的最大长度,return_tensors="pt"表示将输出转换为PyTorch的张量格式。
batch = tokenizer(text_Train, padding=True, truncation=True, max_length=512, return_tensors="pt")
print(batch)# 5.torch.no_grad()用于关闭梯度计算,以节省内存和加速计算,因为在推理过程中不需要更新模型参数。
# model(**batch)将预处理过的批量输入传递给模型,返回的outputs包含了模型的原始输出(logits)。
# 使用F.softmax(outputs.logits, dim=1)计算每个类的概率分布。
# torch.argmax(predictions, dim=1)用于确定概率最高的类别标签,表示每个输入文本的最终情感预测。
with torch.no_grad():print("====================")outputs = model(**batch)print(outputs)predictions = F.softmax(outputs.logits, dim=1)print(predictions)labels = torch.argmax(predictions, dim=1)print(labels)
输出:

五、模型的保存save & 加载load
1.保存:这里指定了保存路径为当前工作目录下的一个名为saved的文件夹。如果没有特殊路径指定,模型和分词器会默认保存在你运行代码的当前目录下的saved文件夹中。这个文件夹会包含:
-
tokenizer配置文件,例如tokenizer_config.json,vocab.txt,special_tokens_map.json等。 -
模型配置文件和权重,如config.json和pytorch_model.bin,这些文件包含模型的结构和权重。
2.加载:代码在后续使用时可以通过指定保存的目录(例如saved)来加载已经保存的模型和分词器,避免重新下载模型。这在离线使用或需要跨项目共享时非常有用。
from transformers import pipeline
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
import torch.nn.functional as Fimport os
os.environ["http_proxy"] = "http://127.0.0.1:7890"
os.environ["https_proxy"] = "http://127.0.0.1:7890"# 还是用之前的pipeline应用
model_name = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)# 1.保存: tokenizer和model到一个目录下面
save_directory = "saved" # 保存路径为当前工作目录下的一个名为saved的文件夹
tokenizer.save_pretrained(save_directory)
model.save_pretrained(save_directory)# 2.加载:想再次加载他,使用下列方法
tok = AutoTokenizer.from_pretrained(save_directory)
mod = AutoModelForSequenceClassification.from_pretrained(save_directory)
输出:

六、学会使用huggingface的文档!
非常重要,HF的文档可以找到任何你想找到的东西
-
链接: HuggingFace文档
-
链接: 具体例子文档(有语音、情感分析、文本生成、图片识别等等)

相关文章:
【项目实战】HuggingFace初步实战,使用HF做一些小型任务
Huggingface初步实战 一、前期准备工作二、学习pipline2.1.试运行代码,使用HuggingFace下载模型2.2. 例子1,情感检测分析(只有积极和消极两个状态)2.3. 例子2,文本生成 三、学会使用Tokenizer & Model3.1.tokenizer(分词器&am…...

堆的应用——堆排序和TOP-K问题
1.堆排序 想法⼀: 基于已有数组建堆、取堆顶元素完成排序。也就是利用写好的堆数据结构(之前的文章有讲解),去实现排序。 void HeapSort(int* a, int n){HP hp;for(int i 0; i < n; i){HPPush(&hp,a[i]);}int i 0;whi…...

探秘 MySQL 数据类型的艺术:性能与存储的精妙平衡
文章目录 前言🎀一、数据类型分类🎀二、整数类型(举例 TINYINT 和 INT )🎫2.1 TINYINT 和 INT 类型的定义2.1.1 TINYINT2.1.2 INT 🎫2.2 表的操作示例2.2.1 创建包含 TINYINT 和 INT 类型的表2.2.2 插入数据…...

使用任意绘图软件自学并结合上课所学内容完成数据库原理图绘制
本次绘图采用亿图图示软件...

static、 静态导入、成员变量的初始化、单例模式、final 常量(Content)、嵌套类、局部类、抽象类、接口、Lambda、方法引用
static static 常用来修饰类的成员:成员变量、方法、嵌套类 成员变量 被static修饰:类变量、成员变量、静态字段 在程序中只占用一段固定的内存(存储在方法区),所有对象共享可以通过实例、类访问 (一般用类名访问和修…...

基于SSM的智能养生平台管理系统源码带本地搭建教程
技术栈与架构 技术框架:采用SSM(Spring Spring MVC MyBatis)作为后端开发框架,结合前端技术栈layui、JSP、Bootstrap与jQuery,以及数据库MySQL 5.7,共同构建项目。 运行环境:项目在JDK 8环境…...

Latex中文排版字体和字号
中文排版 最近常用latex排版,也遇到了很多问题。这里对于主要的参考文章做一个总结和推荐。 一份不太简短的 LaTeX2ε 介绍【中文资料】ctex宏包用户手册,用户手册使用 命令行texdoc ctex 这两个文档都是中文的,而且几乎解决了我90%的排版…...

[C++ 11] 列表初始化:轻量级对象initializer_list
C发展历史 C11是C语言的第二个主要版本,也是自C98以来最重要的一次更新。它引入了大量的新特性,标准化了已有的实践,并极大地改进了C程序员可用的抽象能力。在2011年8月12日被ISO正式采纳之前,人们一直使用“C0x”这个名称&#…...
:API说明(暂时完结,后续考虑将在线版mongoDB变为本地版))
【NodeJS】NodeJS+mongoDB在线版开发简单RestfulAPI (八):API说明(暂时完结,后续考虑将在线版mongoDB变为本地版)
本项目旨在学习如何快速使用 nodejs 开发后端api,并为以后开展其他项目的开启提供简易的后端模版。(非后端工程师) 由于文档是代码写完之后,为了记录项目中需要注意的技术点,因此文档的叙述方式并非开发顺序࿰…...

manictime整合两个数据库的数据
作用 老电脑崩溃了,有个1t.db, 新电脑有个3t.db 那么重装系统后就想整合起来用。 整合前文件大小 整合命令 .\mtdb.exe importtimelines -sdbpa ManicTimeCore-1t.db -dbpa ManicTimeCore-3t.db -tt ManicTime/ComputerUsage,ManicTime/Applications,ManicTime…...

Spring Boot植物健康系统:智慧农业的新趋势
6系统测试 6.1概念和意义 测试的定义:程序测试是为了发现错误而执行程序的过程。测试(Testing)的任务与目的可以描述为: 目的:发现程序的错误; 任务:通过在计算机上执行程序,暴露程序中潜在的错误。 另一个…...

(三)第一个Qt程序“Qt版本的HelloWorld”
一、随记 我们在学习编程语言的时候,各种讲解编程语言的书籍中通常都会以一个非常经典的“HelloWorld”程序展开详细讲解。程序虽然简短,但是“麻雀虽小,五脏俱全”,但是却非常适合用来熟悉程序结构、规范,快速形成对编…...

【Python知识】一个强大的数据分析库Pandas
文章目录 Pandas概述1. 安装 Pandas2. 基本数据结构3. 数据导入和导出4. 数据清洗5. 数据选择和过滤6. 数据聚合和摘要7. 数据合并和连接8. 数据透视表9. 时间序列分析10. 数据可视化 📈 如何使用 Pandas 进行复杂的数据分析?1. 数据预处理2. 处理缺失值…...

10.26学习
1.整形的定义和输出 在C语言中,整形(Integer)是一种基本数据类型,用于存储整数。整形变量可以是正数、负数或零。在定义和输出整形变量时,需要注意以下几点: ①定义整形变量: 使用 int 关键字…...
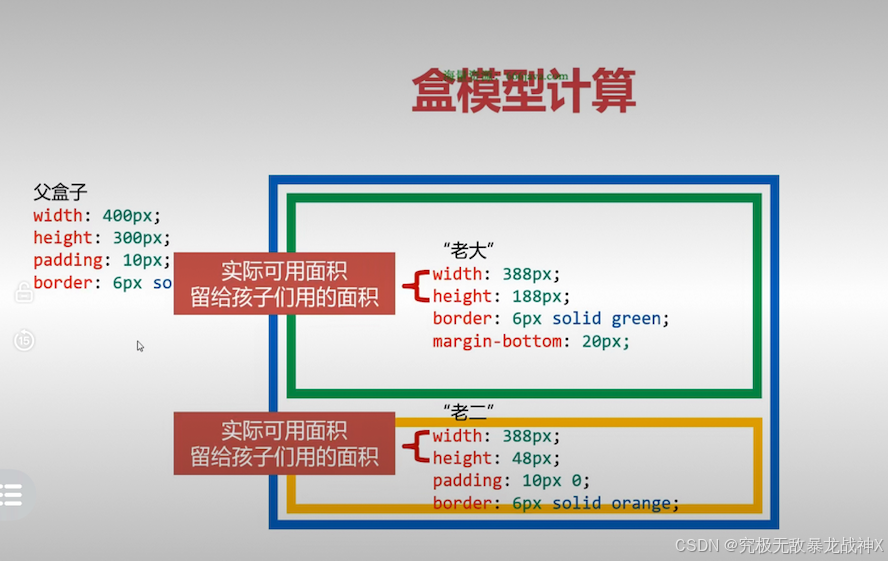
CSS易漏知识
复杂选择器可以通过(id的个数,class的个数,标签的个数)的形式,计算权重。 如果我们需要将某个选择器的某条属性提升权重,可以在属性后面写!important;注意!importent要写在;前面 很多公司不允许…...

【10天速通Navigation2】(三) :Cartographer建图算法配置:从仿真到实车,从原理到实现
前言 往期内容: 第一期:【10天速通Navigation2】(一) 框架总览和概念解释第二期:【10天速通Navigation2】(二) :ROS2gazebo阿克曼小车模型搭建-gazebo_ackermann_drive等插件的配置和说明 本教材将贯穿nav2的全部内容,…...

测试造数,excel转insert语句
目录 excel转sql的insert语句一、背景二、直接上代码 excel转sql的insert语句 一、背景 在实际测试工作中,需要频繁地进行测试造数并插入数据库验证,常规的手写sql语句过于浪费时间,为此简单写个脚本,通过excel来造数࿰…...
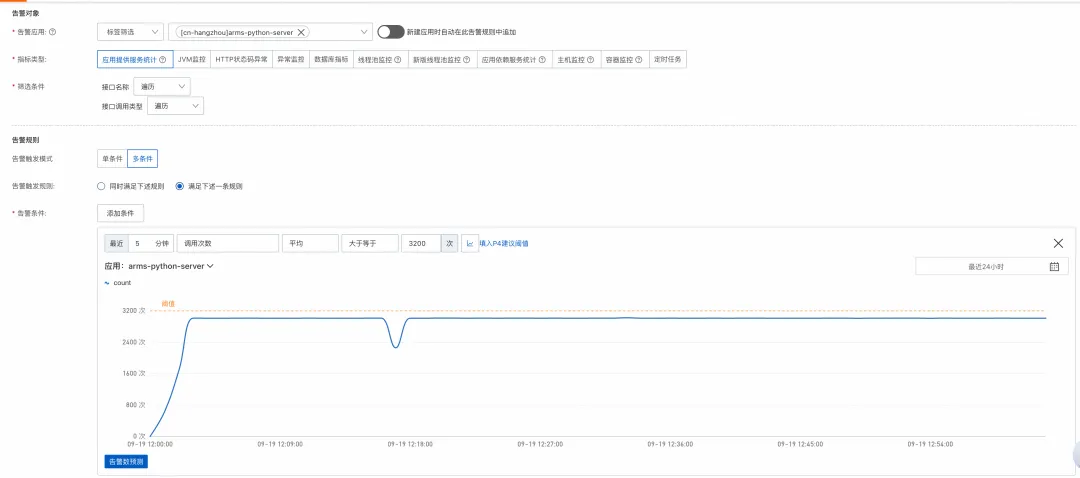
Python 应用可观测重磅上线:解决 LLM 应用落地的“最后一公里”问题
作者:彦鸿 背景 随着 LLM(大语言模型)技术的不断成熟和应用场景的不断拓展,越来越多的企业开始将 LLM 技术纳入自己的产品和服务中。LLM 在自然语言处理方面表现出令人印象深刻的能力。然而,其内部机制仍然不明确&am…...

从零开始:用Spring Boot搭建厨艺分享网站
2 相关技术 2.1 Spring Boot框架简介 Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程。该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。通过这种方式,Sprin…...
《2024中国泛娱乐出海洞察报告》解析,垂直且多元化方向发展!
随着以“社交”为代表的全球泛娱乐市场规模不断扩大以及用户需求不断细化,中国泛娱乐出海产品正朝着更加垂直化、多元化的方向发展。基于此,《2024中国泛娱乐出海洞察报告》深入剖析了中国泛娱乐行业出海进程以及各细分赛道出海现状及核心特征。针对中国…...

从85分到95+:复盘我在科大奥锐虚拟仿真实验平台踩过的那些‘坑’
从85分到95:科大奥锐虚拟仿真实验平台的实战避坑指南 第一次接触科大奥锐虚拟仿真实验平台时,我和大多数同学一样,以为这不过是传统实验的电子版。直到连续三次实验分数卡在85分上下,才意识到这个平台对操作细节的严苛程度远超预期…...

Mapbox GL JS 新手必看:GeoJSON 数据坐标填错,地图显示全乱套?
Mapbox GL JS 开发避坑指南:GeoJSON 坐标系问题全解析 刚接触 Mapbox GL JS 的开发者经常会遇到一个令人抓狂的问题:明明按照文档写了代码,GeoJSON 数据也加载成功了,但地图上的点线面全都显示在错误的位置,有的甚至跑…...

UI-Grid 终极贡献指南:如何从零开始参与开源项目并提交完美代码
UI-Grid 终极贡献指南:如何从零开始参与开源项目并提交完美代码 【免费下载链接】ui-grid UI Grid: an Angular Data Grid 项目地址: https://gitcode.com/gh_mirrors/ui/ui-grid UI-Grid 作为一款基于 Angular 的数据表格组件,为开发者提供了强大…...

TFLint Docker终极指南:在容器中轻松运行Terraform代码检查
TFLint Docker终极指南:在容器中轻松运行Terraform代码检查 【免费下载链接】tflint A Pluggable Terraform Linter 项目地址: https://gitcode.com/gh_mirrors/tf/tflint TFLint是一个可插拔的Terraform代码检查工具,帮助开发者发现Terraform配置…...

DLSS Swapper深度解析:游戏性能优化实战指南
DLSS Swapper深度解析:游戏性能优化实战指南 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper作为一款开源游戏性能优化工具,专为解决PC玩家面临的DLSS版本管理难题而生。在3A游戏对…...

如何一次删除iPad上的多个应用程序? - 5 种有效方法
随着时间的推移,您的 iPad 可能会积累许多不必要的应用程序,导致存储空间不足并影响设备性能。因此,最好的方法是删除这些应用程序。然而,逐个删除它们可能很耗时;一次性删除多个应用程序可以更有效地释放空间并提高设…...

DETR训练避坑大全:Windows10+PyCharm环境下的5个常见报错解决方案
DETR实战指南:Windows 10环境下的5大典型问题深度解析与解决方案 在目标检测领域,DETR(Detection Transformer)作为首个完全基于Transformer架构的端到端检测系统,正在改变传统计算机视觉任务的实现方式。不同于Faste…...

基于jqktrader的自动化交易解决方案:技术架构与实战应用
基于jqktrader的自动化交易解决方案:技术架构与实战应用 【免费下载链接】jqktrader 同花顺自动程序化交易 项目地址: https://gitcode.com/gh_mirrors/jq/jqktrader 自动化交易技术正逐步改变传统量化投资的运作模式,jqktrader作为一款基于Pytho…...
Pixel Aurora Engine部署案例:边缘计算设备(Jetson Orin)轻量化部署
Pixel Aurora Engine部署案例:边缘计算设备(Jetson Orin)轻量化部署 1. 项目背景与价值 Pixel Aurora Engine是一款基于AI扩散模型的创意工具,专为生成复古像素艺术设计。其独特的8-bit游戏风格界面和高效生成能力,使…...

mT5分类增强版中文-base效果惊艳:同一输入生成‘正式/口语/幽默’三风格文本示例
mT5分类增强版中文-base效果惊艳:同一输入生成‘正式/口语/幽默’三风格文本示例 1. 模型介绍:零样本学习的文本增强利器 mT5分类增强版中文-base是一个基于mT5架构的文本增强模型,专门针对中文场景进行了深度优化。这个模型最大的特点是采…...