预训练 BERT 使用 Hugging Face 和 PyTorch 在 AMD GPU 上
Pre-training BERT using Hugging Face & PyTorch on an AMD GPU — ROCm Blogs

2024年1月26日,作者:Vara Lakshmi Bayanagari.
这篇博客解释了如何从头开始使用 Hugging Face 库和 PyTorch 后端在 AMD GPU 上为英文语料(WikiText-103-raw-v1)预训练 BERT 基础模型的端到端过程。
你可以在 GitHub folder中找到与这篇博客相关的文件。
BERT简介
BERT是一种在2019年提出的语言表示模型。其模型架构基于一个transformer编码器,其中自注意力层对输入的每个token对进行注意力计算,整合了来自两个方向的上下文(因此称为BERT的“双向”特性)。在此之前,像ELMo和GPT这样的模型只使用从左到右的(单向)架构,这极大地限制了模型的表现力;模型性能依赖于微调。
本博客解释了BERT所采用的预训练任务,这些任务在通用语言理解评估(GLUE)基准测试中取得了最先进的成果。在接下来的章节中,我们将展示在PyTorch中的实现。
这篇BERT paper最先提出了一种新的预训练方法,称为掩码语言建模(MLM)。MLM随机掩盖输入的某些部分,并对一批输入进行训练以预测这些被掩盖的tokens。预训练期间,在对输入进行分词之后,15%的tokens被随机挑选。其中,80%被替换为一个`[MASK]`标记,10%被替换为一个随机标记,10%则保持不变。
在下面的示例中,MLM预处理方法如下:`dog`标记保持不变,`Golden`和`years`标记被掩盖,并且`and`标记被随机替换为`paper`标记。预训练的目标是使用`CategoricalCrossEntropy`损失来预测这些标记,以便模型学习语言的语法、模式和结构。
Input sentence: My dog is a Golden Retriever and his is 5 years oldAfter MLM: My dog is a [MASK] Retriever paper his is 5 [MASK] old此外,为了捕捉句子之间的关系,超越掩码语言建模任务,论文提出了第二个预训练任务,称为下一个句子预测(NSP)。在不改变架构的情况下,论文证明了NSP有助于提升问答(QA)和自然语言推理(NLI)任务的结果。
这个任务不直接输入token流,而是输入一对句子的token,例如`A`和`B`,以及一个前置分类标记(`[CLS]`)。分类标记指示句对是随机组合的(label=0)还是`B`是`A`的下一个句子(label=1)。因此,NSP预训练是一种二元分类任务。
_IsNext_ Pair: [1] My dog is a Golden Retriever. He is five years old.Not _IsNext_ Pair: [0] My dog is a Golden Retriever. The next chapter in the book is a biography.总之,数据集首先进行预处理以形成一对句子,然后进行分词,并最终随机掩盖某些tokens。预处理后的输入批次要么*填充*(使用`[PAD]`标记)或*修剪*(到_max_seq_length_超参数),以便所有输入元素在加载到BERT模型中之前都统一为相同的长度。BERT模型配有两个分类头:一个用于MLM(`num_cls_heads = vocab_size),另一个用于NSP(num_cls_heads=2`)。来自两个预训练任务的分类损失之和用于训练BERT。
在多台 AMD GPU 上的实现
在开始之前,确保您已经满足以下要求:
-
在搭载 AMD GPU 的设备上安装 ROCm 兼容的 PyTorch。本实验在 ROCm 5.7.0 和 PyTorch 2.0.1 上进行了测试。
-
运行命令
pip install datasets transformers accelerate以安装 Hugging Face 的相关库。 -
运行
accelerate config命令以设置分布式训练参数,详见此处。在本实验中,我们使用了单节点上的八块 GPU 并行计算,运用了DistributedDataParallel。
实现
Hugging Face 使用 Torch 作为大多数模型的默认后端,从而实现了这两个框架的良好结合。为了简化常规训练步骤并避免样板代码,Hugging Face 提供了一个名为 Trainer 的类,该类模仿了 PyTorch 的功能。类似地,Lightning AI 提供了 Trainer 类。此外,对于分布式训练,Hugging Face 可能更方便,因为代码中没有额外的配置设置,系统会根据 accelerate config 自动检测并利用所有 GPU 设备。然而,如果你希望进一步自定义你的模型并对加载预训练检查点做出额外修改,原生的 PyTorch 是更好的选择。这篇博客解释了使用 Hugging Face 的 transformers 库对 BERT 进行端到端预训练,同时提供了简化的数据预处理管道。
使用 Hugging Face 的 Trainer 进行 BERT 预训练可以用几行代码来总结。transformer 编码器、MLM 分类头和 NSP 分类头都打包在 Hugging Face 的 BertForPreTraining 模型中,该模型返回一个累积分类损失,如我们在 介绍 中所解释的。模型使用默认的 BERT base 配置参数(`NUM_LAYERS`、`ACT_FUNC`、`BATCH_SIZE`、`HIDDEN_SIZE`、`EMBED_DIM` 等)进行初始化。你可以从 Hugging Face 的 BertConfig 中导入这些参数。
那就是全部了吗?几乎。训练最关键的部分是数据预处理。预处理分为三个步骤:
-
将你的数据集重新组织为每个文档的句子字典。这对于从随机文档中选取随机句子以进行 NSP 任务非常有用。为此,可以对整个数据集使用简单的for循环。
-
使用 Hugging Face 的
AutoTokenizer来对所有句子进行标记化。 -
使用另一个 for 循环,创建 50% 随机对和 50% 顺序对的句子对。
我已经对 WikiText-103-raw-v1 语料库(2,500 M单词)进行了上述的预处理步骤,并将生成的验证集放在这里。预处理的训练集已上传到 Hugging Face Hub。
接下来,导入 DataCollatorForLanguageModeling 收集器以运行 MLM 预处理,并获取掩码和句子分类标签。在使用 Trainer 类时,我们只需要访问 torch.utils.data.Dataset 和一个收集函数。与 TensorFlow 不同,Hugging Face 的 Trainer 会从数据集和收集器函数中创建数据加载器。为了演示,我们使用了有 3,000+ 句对的 Wikitext-103-raw-v1 验证集。
tokenizer = AutoTokenizer.from_pretrained('bert-base-cased')
collater = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=True, mlm_probability=0.15)
# tokenized_dataset = datasets.load_from_disk(args.dataset_file)
tokenized_dataset_valid = datasets.load_from_disk('./wikiTokenizedValid.hf')创建一个 TrainerArguments 实例,并传递所有必需的参数,如以下代码所示。这部分代码有助于在训练模型时抽象样板代码。该类很灵活,因为它提供了 100 多个参数来适应不同的训练模式;有关更多信息,请参阅 Hugging face transformers 页面。
你现在可以使用 t.train() 来训练模型了。你还可以通过将 resume_from_checkpoint=True 参数传递给 t.train() 来恢复训练。trainer 类会提取 output_dir 文件夹中的最新检查点,并继续训练直到达到总共 num_train_epochs。
train_args = TrainingArguments(output_dir=args.output_dir, overwrite_output_dir =True, per_device_train_batch_size =args.BATCH_SIZE, logging_first_step=True,logging_strategy='epoch', evaluation_strategy = 'epoch', save_strategy ='epoch', num_train_epochs=args.EPOCHS,save_total_limit=50)
t = Trainer(model, args = train_args, data_collator=collater, train_dataset = tokenized_dataset, optimizers=(optimizer, None), eval_dataset = tokenized_dataset_valid)
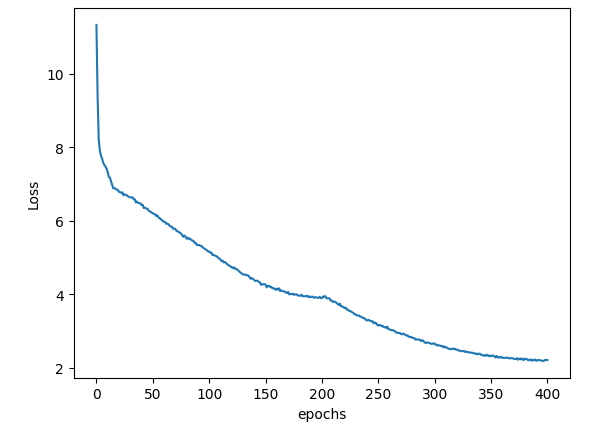
t.train()#resume_from_checkpoint=True)上述模型使用Adam优化器(`learning_rate=2e-5`)和`per_device_train_batch_size=8`进行了大约400个epoch的训练。在一块AMD GPU(MI210,ROCm 5.7.0,PyTorch 2.0.1)上,使用3,000+句对的验证集进行预训练仅需几个小时。训练曲线如图1所示。可以使用最佳模型检查点微调不同的数据集,并在各种NLP任务上测试其表现。
完整的代码如下:
set_seed(42)
parser = argparse.ArgumentParser()
parser.add_argument('--BATCH_SIZE', type=int, default = 8) # 32 is the global batch size, since I use 8 GPUs
parser.add_argument('--EPOCHS', type=int, default=200)
parser.add_argument('--train', action='store_true')
parser.add_argument('--dataset_file', type=str, default= './wikiTokenizedValid.hf')
parser.add_argument('--lr', default = 0.00005, type=float)
parser.add_argument('--output_dir', default = './acc_valid/')
args = parser.parse_args()accelerator = Accelerator()if args.train:args.dataset_file = './wikiTokenizedTrain.hf'args.output_dir = './acc/'
print(args)tokenizer = AutoTokenizer.from_pretrained('bert-base-cased')
collater = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=True, mlm_probability=0.15)
tokenized_dataset = datasets.load_from_disk(args.dataset_file)
tokenized_dataset_valid = datasets.load_from_disk('./wikiTokenizedValid.hf')model = BertForPreTraining(BertConfig.from_pretrained("bert-base-cased"))
optimizer = torch.optim.Adam(model.parameters(), lr =args.lr)device = accelerator.device
model.to(accelerator.device)
train_args = TrainingArguments(output_dir=args.output_dir, overwrite_output_dir =True, per_device_train_batch_size =args.BATCH_SIZE, logging_first_step=True,logging_strategy='epoch', evaluation_strategy = 'epoch', save_strategy ='epoch', num_train_epochs=args.EPOCHS,save_total_limit=50)#, lr_scheduler_type=None)
t = Trainer(model, args = train_args, data_collator=collater, train_dataset = tokenized_dataset, optimizers=(optimizer, None), eval_dataset = tokenized_dataset_valid)
t.train()#resume_from_checkpoint=True)推理
以一个示例文本为例,使用分词器将其转换为输入tokens,并通过collator生成一个掩码输入。
collater = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=True, mlm_probability=0.15, pad_to_multiple_of=128)
text="The author takes his own advice when it comes to writing: he seeks to ground his claims in clear, concrete examples. He shows specific examples of bad writing to help readers better grasp exactly what he’s critiquing"
tokens = tokenizer.convert_tokens_to_ids(tokenizer.tokenize(text))
inp = collater([tokens])
inp['attention_mask'] = torch.where(inp['input_ids']==0,0,1)使用预训练的权重初始化模型并进行推理。你将看到模型生成的随机tokens没有上下文意义。
config = BertConfig.from_pretrained('bert-base-cased')
model = BertForPreTraining.from_pretrained('./acc_valid/checkpoint-19600/')
model.eval()
out = model(inp['input_ids'], inp['attention_mask'], labels=inp['labels'])print('Input: ', tokenizer.decode(inp['input_ids'][0][:30]), '\n')
print('Output: ', tokenizer.decode(torch.argmax(out[0], -1)[0][:30]))输入和输出如下所示。该模型在一个非常小的数据集(3,000多句子)上进行了训练;你可以通过在更大的数据集上训练,例如`wikiText-103-raw-v1`的训练切分数据,来提高性能。
The author takes his own advice when it comes to writing : he [MASK] to ground his claims in clear, concrete examples. He shows specific examples of bad
The Churchill takes his own, when it comes to writing : he continued to ground his claims in clear, this examples. He shows is examples of bad源代码存储在这个 GitHub 文件夹。
结论
我们所描述的预训练BERT基础模型的过程可以很容易地扩展到不同大小的BERT版本以及不同的数据集。我们使用Hugging Face Trainer和PyTorch后端在AMD GPU上训练了我们的模型。对于训练,我们使用了`wikiText-103-raw-v1`数据集的验证集,但这可以很容易地替换为训练集,只需下载我们在Hugging Face Hub上的仓库中托管的预处理和标记化的训练文件Hugging Face Hub.
在本文中,我们通过MLM和NSP预训练任务复制了BERT的预训练过程,这与许多公共平台上仅使用MLM的方法不同。此外,我们没有使用数据集的小部分,而是预处理并上传了整个数据集到Hub上供您方便使用。在未来的文章中,我们将讨论在多个AMD GPU上使用数据并行和分布式策略来训练各种机器学习应用。
相关文章:
预训练 BERT 使用 Hugging Face 和 PyTorch 在 AMD GPU 上
Pre-training BERT using Hugging Face & PyTorch on an AMD GPU — ROCm Blogs 2024年1月26日,作者:Vara Lakshmi Bayanagari. 这篇博客解释了如何从头开始使用 Hugging Face 库和 PyTorch 后端在 AMD GPU 上为英文语料(WikiText-103-raw-v1)预训练…...

鸿蒙是必经之路
少了大嘴的发布会,老实讲有点让人昏昏入睡。关于技术本身的东西,放在后面。 我想想来加把油~ 鸿蒙发布后褒贬不一,其中很多人不太看好鸿蒙,一方面是开源性、一方面是南向北向的利益问题。 不说技术的领先点,我只扯扯…...

Java项目实战II基于微信小程序的马拉松报名系统(开发文档+数据库+源码)
目录 一、前言 二、技术介绍 三、系统实现 四、文档参考 五、核心代码 六、源码获取 全栈码农以及毕业设计实战开发,CSDN平台Java领域新星创作者,专注于大学生项目实战开发、讲解和毕业答疑辅导。获取源码联系方式请查看文末 一、前言 马拉松运动…...

家用wifi的ip地址固定吗?换wifi就是换ip地址吗
在探讨家用WiFi的IP地址是否固定,以及换WiFi是否就意味着换IP地址这两个问题时,我们首先需要明确几个关键概念:IP地址、家用WiFi网络、以及它们之间的相互作用。 一、家用WiFi的IP地址固定性 家用WiFi环境中的IP地址通常涉及两类:…...

codeforces _ 补题
C. Ball in Berland 传送门:Problem - C - Codeforces 题意: 思路:容斥原理 考虑 第 i 对情侣组合 ,男生为 a ,女生为 b ,那么考虑与之匹配的情侣 必须没有 a | b ,一共有 k 对情侣&#x…...

DataSophon集成ApacheImpala的过程
注意: 本次安装操作系统环境为Anolis8.9(Centos7和Centos8应该也一样) DataSophon版本为DDP-1.2.1 整合的安装包我放网盘了: 通过网盘分享的文件:impala-4.4.1.tar.gz等2个文件 链接: https://pan.baidu.com/s/18KfkO_BEFa5gVcc16I-Yew?pwdza4k 提取码: za4k 1…...

深入探讨TCP/IP协议基础
在当今数字化的时代,计算机网络已经成为人们生活和工作中不可或缺的一部分。而 TCP/IP 协议作为计算机网络的核心协议,更是支撑着全球互联网的运行。本文将深入探讨常见的 TCP/IP 协议基础,带你了解计算机网络的奥秘。 一、计算机网络概述 计…...

《Windows PE》7.4 资源表应用
本节我们将通过两个示例程序,演示对PE文件内图标资源的置换与提取。 本节必须掌握的知识点: 更改图标 提取图标资源 7.4.1 更改图标 让我们来做一个实验,替换PE文件中现有的图标。如果手工替换,一定是先找到资源表,…...

【重生之我要苦学C语言】猜数字游戏和关机程序的整合
今天来把学过的猜数字游戏和关机程序来整合一下 如果有不明白的可以看往期的博客 废话不多说,上代码: #define _CRT_SECURE_NO_WARNINGS #include <stdio.h> #include <time.h> #include <stdlib.h> #include <string.h> void…...

基于centos7脚本一键部署gpmall商城
基于centos7脚本一键部署单节点gpmall商城,该商城可单节点,可集群,可高可用集群部署,VMware17,虚拟机IP:192.168.200.100 将软件包解压到/root目录 [rootlocalhost ~]# ls dist …...

Mac book英特尔系列?M系列?两者有什么区别呢
众所周知,Mac book有M系列,搭载的是苹果自研的M芯片,也有着英特尔系列,搭载的是英特尔的处理器,虽然从 2020 年开始,苹果公司逐步推出了自家研发的 M 系列芯片,并逐渐将 MacBook 产品线过渡到 M…...

Python unstructured库详解:partition_pdf函数完整参数深度解析
Python unstructured库详解:partition_pdf函数完整参数深度解析 1. 简介2. 基础文件处理参数2.1 文件输入参数2.2 页面处理参数 3. 文档解析策略3.1 strategy参数详解3.2 策略选择建议 4. 表格处理参数4.1 表格结构推断 5. 语言处理参数5.1 语言设置 6. 图像处理参数…...

<项目代码>YOLOv8路面病害识别<目标检测>
YOLOv8是一种单阶段(one-stage)检测算法,它将目标检测问题转化为一个回归问题,能够在一次前向传播过程中同时完成目标的分类和定位任务。相较于两阶段检测算法(如Faster R-CNN),YOLOv8具有更高的…...

广告牌和标签学习
效果: 知识学习: entities添加标签label和广告牌billboard label: text:文本添加 font:字体大小和字体类型 fillColor:字体颜色 outlineColor:字体外轮廓颜色 outlineWidth:字体外轮…...
GDB 从裸奔到穿戴整齐
无数次被问道:你在终端下怎么调试更高效?或者怎么在 Vim 里调试?好吧,今天统一回答下,我从来不在 vim 里调试,因为它还不成熟。那除了命令行 GDB 裸奔以外,终端下还有没有更高效的方法ÿ…...

WPF的触发器(Trigger)
WPF(Windows Presentation Foundation)是微软.NET框架的一部分,用于构建Windows客户端应用程序。在WPF中,触发器(Triggers)是一种强大的功能,允许开发者根据控件的状态或属性值来动态改变控件的…...

全能大模型GPT-4o体验和接入教程
GPT-4o体验和接入教程 前言一、原生API二、Python LangchainSpring AI总结 前言 Open AI发布了产品GPT-4o,o表示"omni",全能的意思。 GPT-4o可以实时对音频、视觉和文本进行推理,响应时间平均为 320 毫秒,和人类之间对…...

详解Apache版本、新功能和技术前景
文章目录 一、 版本溯源二、新功能和特性举例1. 模块化和可扩展性增强2. 多处理模块(MPMs)3. 异步支持4. 更细粒度的日志级别控制5. 通用表达式解析器6. HTTP/2支持7. Server Push8. Early Hints9. 更好的SSL/TLS支持10. 更安全的默认设置 三、 技术前景…...

Docker Redis集群3主3从模式
主从集群 docker run -d --name redis-node1 --net host --privilegedtrue -v /home/redis/node1:/data redis:7.0 --cluster-enabled yes --appendonly yes --port 9371docker run -d --name redis-node2 --net host --privilegedtrue -v /home/redis/node2:/data redis:7.0 …...

【Go语言】
type关键字的用法 定义结构体定义接口定义类型别名类型定义类型判断 别名实际上是为了更好地理解代码/ 这里要分点进行记录 使用传值的例子,当两个类型不一样需要进行类型转换 type Myint int // 自定义类型,基于已有的类型自定义一个类型type Myin…...

OWL ADVENTURE应用场景解析:如何用AI助手提升工作效率
OWL ADVENTURE应用场景解析:如何用AI助手提升工作效率 1. 为什么选择OWL ADVENTURE作为AI助手 在当今快节奏的工作环境中,我们每天都要处理大量视觉信息——从产品图片到数据图表,从设计稿到文档扫描件。传统的工作流程往往需要人工逐一查看…...

SUNFLOWER MATCH LAB在CSDN技术社区的分享:从部署到创新的完整旅程
SUNFLOWER MATCH LAB在CSDN技术社区的分享:从部署到创新的完整旅程 最近在CSDN上看到不少关于AI模型部署和应用的讨论,其中SUNFLOWER MATCH LAB这个项目引起了我的注意。它不是一个简单的模型调用工具,更像是一个围绕特定AI能力构建的完整实…...

基于深度学习的CT肺部分割技术:在医学影像分析中实现95% Dice系数的精准自动化方案
基于深度学习的CT肺部分割技术:在医学影像分析中实现95% Dice系数的精准自动化方案 【免费下载链接】lungmask Automated lung segmentation in CT 项目地址: https://gitcode.com/gh_mirrors/lu/lungmask 在医学影像分析领域,CT肺部分割一直是临…...

如何快速上手OneMore:OneNote插件的安装与基础设置教程
如何快速上手OneMore:OneNote插件的安装与基础设置教程 【免费下载链接】OneMore A OneNote add-in with simple, yet powerful and useful features 项目地址: https://gitcode.com/gh_mirrors/on/OneMore 想要提升OneNote的使用效率吗?OneMore插…...

Qwen2.5-Coder-1.5B应用案例:快速生成网页爬虫代码实战
Qwen2.5-Coder-1.5B应用案例:快速生成网页爬虫代码实战 1. 引言:为什么选择Qwen2.5-Coder生成爬虫代码 在日常开发工作中,网页爬虫是数据采集和分析的重要工具。传统编写爬虫代码需要开发者熟悉HTTP请求、HTML解析、反爬机制处理等多个技术…...

14届蓝桥杯省赛Java A 组Q4~Q5
题目链接: Q4 蓝桥云课:棋盘 洛谷:P13879 [蓝桥杯 2023 省 Java A] 棋盘 Q5 蓝桥云课:互质数的个数 洛谷:P13880 [蓝桥杯 2023 省 Java A] 互质数的个数 算法原理: Q4解法:前缀和差分 时间…...

RexUniNLU开源镜像免配置教程:自动下载权重+端口映射一步到位
RexUniNLU开源镜像免配置教程:自动下载权重端口映射一步到位 1. 这不是另一个NLP工具,而是一站式中文语义理解中枢 你有没有遇到过这样的情况:想快速验证一段中文文本里藏着多少信息——谁说了什么、发生了什么事、情绪是好是坏、背后有哪些…...
)
Spring Boot项目实战:Flowable工作流引擎从入门到部署(附完整代码示例)
Spring Boot深度整合Flowable:企业级工作流开发实战与架构解析 从业务流程管理到技术实现:Flowable的核心价值 在数字化转型浪潮中,企业流程自动化已成为提升运营效率的关键。想象一下这样的场景:当员工提交报销申请后,…...

网盘直链下载助手完整教程:如何轻松获取百度、阿里云盘等八大平台真实下载地址
网盘直链下载助手完整教程:如何轻松获取百度、阿里云盘等八大平台真实下载地址 【免费下载链接】Online-disk-direct-link-download-assistant 可以获取网盘文件真实下载地址。基于【网盘直链下载助手】修改(改自6.1.4版本) ,自用…...
)
手把手教你实现glitch free的时钟切换电路(附Verilog代码)
手把手教你实现glitch free的时钟切换电路(附Verilog代码) 时钟切换电路是数字系统设计中的关键模块,尤其在多时钟域系统中,可靠的时钟切换能确保系统稳定运行。本文将深入探讨如何实现无毛刺(glitch free)…...