redis高级篇之skiplist跳表 第164节答疑
跳表查询的空间复杂度分析
比起单纯的单链表,跳表需要存储多级索引,肯定要消耗更多的存储空间。那到底需要消耗多少额外的存储空间呢?
我们来分析一下跳表的空间复杂度。
第一步:首先原始链表长度为n,
第二步:两两取首,每层索引的结点数:n/2,n/4,n/8..,8,4,2 每上升一级就减少一半,直到剩下2个结点,以此类推;如果我们把每层索引的结点数写出来,就是一个等比数列。
原始链表大小为n,每2个结点抽1个,每层索引的结点数:一,平,这,8,4?
这几级索引的结点总和就是n/2+n/4+n/8…+8+4+2=n-2。所以,跳表,我们需要额外再用接近n个结点的存储空间。
跳表的空间复杂度是O(n)
也就是说,如果将包含n个结点的单链表构造成
----
跳表为什么空间复杂度不是1.5n还是n?比如n是8,空间复杂度就是 8+4+2=14 如果n是16 就是16+8+4+2=30,怎么都是1.5n啊,如果是O(n)话,索引不要空间了吗?
你提出的疑问很有道理,让我们进一步分析跳表的空间复杂度。
### 跳表的空间复杂度分析
跳表是一种多级索引的数据结构,用于加速链表的查询操作。它通过在链表上增加多层索引,使得查询时间复杂度从 \(O(n)\) 降低到 \(O(\log n)\)。但这种加速是以增加额外的存储空间为代价的。下面我们详细分析跳表的空间复杂度。
#### 假设
1. **原始链表长度为 \(n\)**。
2. **每层索引的节点数是上一层的一半**。
#### 分析步骤
1. **第一层(原始链表)**:节点数为 \(n\)。
2. **第二层**:节点数为 \(n/2\)。
3. **第三层**:节点数为 \(n/4\)。
4. **以此类推**,直到剩下的节点数为 1 或 2。
这些节点数形成一个等比数列:
\[ n + \frac{n}{2} + \frac{n}{4} + \frac{n}{8} + \cdots + 2 + 1 \]
这个等比数列的和可以表示为:
\[ S = n \left(1 + \frac{1}{2} + \frac{1}{4} + \frac{1}{8} + \cdots \right) \]
这个等比数列的和趋近于 2:
\[ 1 + \frac{1}{2} + \frac{1}{4} + \frac{1}{8} + \cdots = 2 \]
所以总的节点数近似为:
\[ S \approx n \times 2 = 2n \]
### 空间复杂度
虽然总节点数是 \(2n\),但在大 \(O\) 表示法中,我们只关心增长的速率和常数因子的影响。因此,跳表的空间复杂度是 \(O(n)\)。
### 解释为什么不是 \(1.5n\)
你的计算 \(8 + 4 + 2 = 14\) 或 \(16 + 8 + 4 + 2 = 30\) 是对的,但这只是特定 \(n\) 值的具体总和。当 \(n\) 增长时,等比数列的和会趋近于 \(2n\),而不是 \(1.5n\)。在大 \(O\) 表示法中,常数因子不影响复杂度的阶数,所以我们简化为 \(O(n)\)。
### 总结
跳表的空间复杂度是 \(O(n)\),因为它需要额外的存储空间近似为原始链表节点数的两倍。虽然具体的节点总和可能接近 \(1.5n\) 或其他数值,但在大 \(O\) 表示法中,我们忽略常数因子,最终结果是 \(O(n)\)。
======
第三步:思考三三取首,每层索引的结点数:n/3,n/9,n/27.,9,3,1 以此类推;第一级索引需要大约n/3个结点,第二级索引需要大约n/9个结点。每往上一级,索引结点个数都除以3。为了方便计算,我们假设最高一级的索引结点个数是1。我们把每级索引的结点个数都写下来,也是一个等比数列
原始链表大为n,每3个结点抽1个,每层索引的结点数:豆,可可…9,3.1
通过等比数列求和公式,总的索引结点大约就是n/3+n/9+n/27+…+9+3+1=n/2。尽管空间复杂度还是O(n),但比上面的每两个结点抽一个结点的索引构建方法,要减少了,一半的索引结点存储空间。
所以空问复杂度是O(n):
--------------那n+n/3+n/9+n/27+...+3+1怎么计算呢
你提出的问题很好,让我们详细分析一下。
### 跳表的空间复杂度分析(每三个节点抽一个)
假设我们使用每三个节点抽一个节点的方法来构建跳表的索引。我们来看一下这种情况下的空间复杂度。
#### 假设
1. **原始链表长度为 \(n\)**。
2. **每层索引的节点数是上一层的三分之一**。
#### 分析步骤
1. **第一层(原始链表)**:节点数为 \(n\)。
2. **第二层**:节点数为 \(n/3\)。
3. **第三层**:节点数为 \(n/9\)。
4. **以此类推**,直到剩下的节点数为 1。
这些节点数形成一个等比数列:
\[ n + \frac{n}{3} + \frac{n}{9} + \frac{n}{27} + \cdots + 3 + 1 \]
这个等比数列的和可以表示为:
\[ S = n \left(1 + \frac{1}{3} + \frac{1}{9} + \frac{1}{27} + \cdots \right) \]
#### 等比数列求和公式
对于一个无限等比数列 \(a + ar + ar^2 + ar^3 + \cdots\),其和 \(S\) 可以表示为:
\[ S = \frac{a}{1 - r} \]
其中,\(a\) 是首项,\(r\) 是公比。在我们的例子中,首项 \(a = 1\),公比 \(r = \frac{1}{3}\)。
因此,等比数列的和为:
\[ 1 + \frac{1}{3} + \frac{1}{9} + \frac{1}{27} + \cdots = \frac{1}{1 - \frac{1}{3}} = \frac{1}{\frac{2}{3}} = \frac{3}{2} \]
所以总的节点数近似为:
\[ S \approx n \times \frac{3}{2} = \frac{3n}{2} \]
### 空间复杂度
尽管总节点数是 \(\frac{3n}{2}\),在大 \(O\) 表示法中,我们只关心增长的速率和常数因子的影响。因此,跳表的空间复杂度仍然是 \(O(n)\)。
### 总结
通过每三个节点抽一个节点的方法来构建跳表的索引,虽然具体的节点总和是 \(\frac{3n}{2}\),但在大 \(O\) 表示法中,我们忽略常数因子,最终结果仍然是 \(O(n)\)。
这种方法确实减少了索引节点的存储空间,但空间复杂度的阶数没有变化,仍然是 \(O(n)\)。
===========
===========
跳表空间复杂度分析的深入探讨
跳表作为一种提高链表查询效率的数据结构,其空间复杂度分析是一个非常有趣的话题。我们已经从两种不同的索引构建方式(每两个节点抽一个,每三个节点抽一个)分析了跳表的空间复杂度,结果都是O(n)。那么,我们是否可以进一步优化跳表的空间占用呢?
优化索引构建方式
我们之前的分析中,每层索引的节点数都是上一层的一半或三分之一。这种方式虽然简单,但可能存在一些优化空间。
比如,我们可以尝试每四个节点抽一个,或者每五个节点抽一个。这样做的好处是,每层索引的节点数会减少,从而减少整体的空间占用。
假设我们每k个节点抽一个,那么每层索引的节点数就是上一层的1/k。这样,整个跳表的节点总数可以表示为:
plaintext
Copy
n + n/k + n/k^2 + n/k^3 + ... + 1
这个等比数列的求和公式为:
plaintext
Copy
S = n * (1 + 1/k + 1/k^2 + 1/k^3 + ...)= n * (1 / (1 - 1/k))= n * k / (k - 1)
当k趋近于无穷大时,这个公式趋近于n。也就是说,当我们每k个节点抽取一个节点构建索引时,跳表的空间复杂度仍然是O(n),只是常数因子会随着k的增大而减小。
动态调整索引密度
除了固定的索引构建方式,我们还可以尝试动态调整索引的密度。比如,在链表较短的时候,我们可以采用较密集的索引(每两个节点抽一个);当链表变长时,我们可以适当降低索引密度(每三个或四个节点抽一个)。
这种动态调整的好处是,可以在保证查询效率的同时,减少不必要的空间开销。当链表较短时,密集的索引可以带来较大的查询性能提升;当链表变长时,适当降低索引密度可以减少空间占用。
总的来说,跳表的空间复杂度分析是一个值得深入探讨的话题。通过优化索引构建方式,或采用动态调整索引密度的策略,我们可以在保证查询效率的同时,进一步降低跳表的空间开销。这些优化方法为跳表的实际应用提供了更多的可能性。
跳表在实际应用中的应用场景
除了作为链表查询效率的提升方案,跳表还有哪些其他的应用场景呢?让我们一起探讨一下:
-
数据库索引: 跳表可以用作数据库中B+树索引的替代方案。由于跳表的查询效率高,且实现相对简单,在某些场景下可能会比B+树更加高效。
-
内存数据库: 跳表天生适合作为内存数据库的索引结构,因为它可以提供高效的查询、插入和删除操作。Redis就是一个典型的使用跳表作为索引的内存数据库。
-
游戏排行榜: 跳表可以高效地维护游戏玩家的排行榜数据,支持快速的查询、插入和删除操作。
-
网络路由表: 跳表可以用于维护路由器的路由表,支持快速的IP地址查找。
-
事件调度: 跳表可以用于实现高性能的事件调度系统,支持快速的事件查找和触发。
-
空间索引: 跳表可以用于构建quadtree或octree等空间索引结构,支持高效的空间查询。
可以看到,跳表凭借其高效的查询性能和相对简单的实现,在很多实际应用场景中都有着广泛的应用前景。随着技术的不断发展,我相信跳表还会在更多领域发挥它的优势,成为一种更加广泛使用的数据结构。
总结
通过对跳表空间复杂度的深入分析,我们发现跳表的空间复杂度为O(n),无论采用每两个节点抽一个还是每三个节点抽一个的索引构建方式。我们还探讨了一些进一步优化跳表空间占用的方法,如动态调整索引密度。
同时,我们也介绍了跳表在实际应用中的一些典型场景,包括数据库索引、内存数据库、游戏排行榜等。可以看到,跳表凭借其高效的查询性能,在很多领域都有着广泛的应用前景。
总的来说,跳表是一种非常有趣和实用的数据结构,值得我们深入学习和探讨。它不仅在理论上有着独特的特点,在实际应用中也有着广泛的用途。相信随着技术的不断发展,跳表还会在更多领域发挥它的优势,成为一种更加广泛使用的数据结构。
跳表的动态调整策略
我们之前提到,可以通过动态调整跳表的索引密度来进一步优化空间复杂度。那么,具体应该如何实现这种动态调整策略呢?
一种可行的方法是,根据链表的长度动态调整每层索引的节点数。比如:
- 当链表较短时(比如节点数小于1000),我们可以采用每两个节点抽取一个作为索引节点的策略。这样可以获得较高的查询性能。
- 当链表变长时(比如节点数超过1000),我们可以适当降低索引密度,比如每三个或四个节点抽取一个作为索引节点。这样可以减少索引占用的空间。
- 随着链表继续增长,我们可以进一步降低索引密度,比如每五个或六个节点抽取一个。
通过这种动态调整策略,我们可以在保证查询性能的同时,尽量减少跳表占用的空间。当链表较短时,密集的索引可以带来较大的查询性能提升;当链表变长时,适当降低索引密度可以减少空间开销。
当然,这种动态调整策略也需要一定的实现成本。我们需要维护链表的长度信息,并根据阈值动态调整索引的构建方式。但相比于固定的索引构建方式,这种动态调整策略可以提供更好的空间利用效率。
跳表的变体和扩展
除了基本的跳表结构,研究人员也提出了一些跳表的变体和扩展,以满足不同的应用需求:
- Concurrent Skiplist: 支持并发访问的跳表实现,可用于多线程环境。
- Probabilistic Skiplist: 使用概率方法构建索引,可以进一步降低空间复杂度。
- Skiplist Forest: 将多个跳表组织成森林结构,支持更复杂的查询操作。
- Skiplist-based Index: 将跳表用作数据库索引结构,替代传统的B+树。
- Skiplist-based Priority Queue: 利用跳表实现高性能的优先级队列。
这些变体和扩展充分体现了跳表作为一种灵活的数据结构,可以被广泛应用于不同的场景中。随着技术的不断发展,我相信跳表及其变体还会在更多领域发挥重要作用。
跳表的实际应用案例
除了前面提到的一些典型应用场景,跳表在实际系统中也有很多成功的应用案例。让我们看看一些具体的例子:
-
Redis: Redis是一款著名的开源内存数据库,它使用跳表作为有序集合(Sorted Set)的底层实现。这使得Redis在执行诸如范围查询、排名等操作时能够高效地完成。
-
LevelDB: LevelDB是Google开源的键值对存储引擎,它使用跳表作为内部索引结构。这使得LevelDB能够提供高效的数据访问性能。
-
Elasticsearch: Elasticsearch是一个分布式搜索和分析引擎,它使用跳表作为倒排索引的底层实现。这使得Elasticsearch能够快速地执行全文搜索和聚合操作。
-
Aerospike: Aerospike是一款面向现代应用的NoSQL数据库,它使用跳表作为索引结构。这使得Aerospike能够提供毫秒级的读写延迟。
-
Lucene/Solr: Lucene和Solr是两个流行的全文搜索引擎,它们都使用跳表作为索引的底层实现。这使得它们能够提供高效的全文检索功能。
可以看到,跳表凭借其高效的查询性能和相对简单的实现,在很多著名的开源项目和商业系统中都得到了广泛应用。这充分证明了跳表作为一种实用的数据结构,在实际应用中的价值和潜力。
总结
通过对跳表空间复杂度的深入分析和优化策略的探讨,我们可以看到跳表是一种非常有趣和实用的数据结构。它不仅在理论上有着独特的特点,在实际应用中也有着广泛的用途。
我们介绍了动态调整索引密度的策略,以及一些跳表的变体和扩展。同时,我们也列举了一些著名项目中跳表的应用案例,进一步证明了跳表在实际系统中的价值。
总的来说,跳表是一种值得深入学习和探讨的数据结构。它不仅能提高链表的查询效率,在很多其他领域也有着广泛的应用前景。相信随着技术的不断发展,跳表还会在更多场景中发挥它的优势,成为一种更加广泛使用的数据结构。
好的,我继续延长这篇关于跳表空间复杂度分析的博客内容:
跳表的理论分析与实践应用
跳表作为一种提高链表查询效率的数据结构,其理论分析和实践应用都值得我们深入探讨。
理论分析
从理论上来看,跳表的空间复杂度分析是一个非常有趣的话题。我们之前已经分析了两种不同的索引构建方式(每两个节点抽一个,每三个节点抽一个),结果都是O(n)。
我们还探讨了一种动态调整索引密度的策略,可以在保证查询性能的同时,进一步优化空间占用。这种动态调整策略可以根据链表的长度,动态选择合适的索引构建方式,从而提高空间利用效率。
除此之外,研究人员还提出了一些跳表的变体和扩展,如并发跳表、概率跳表等,以满足不同的应用需求。这些变体在理论分析和实现细节上都值得我们深入探讨。
实践应用
从实践应用的角度来看,跳表在很多著名的开源项目和商业系统中都得到了广泛应用,充分证明了它的实用价值。
我们列举了一些典型的应用场景,包括数据库索引、内存数据库、游戏排行榜等。这些场景都需要高效的查询性能,跳表正好可以满足这些需求。
我们还介绍了一些具体的应用案例,如Redis、LevelDB、Elasticsearch等。这些系统都使用跳表作为底层的索引结构,从而提供高效的数据访问能力。
通过这些实际应用案例的分析,我们可以更深入地理解跳表在实践中的应用价值,以及它如何帮助这些系统实现高性能和可扩展性。
跳表的未来发展
展望未来,跳表作为一种灵活的数据结构,相信还会在更多领域发挥重要作用。
一方面,随着计算硬件的不断进化,内存容量的不断增加,跳表作为一种内存友好的数据结构,将在内存数据库、缓存系统等领域得到更广泛的应用。
另一方面,随着大数据时代的到来,对于海量数据的高效查询和分析需求也越来越迫切。跳表凭借其优秀的查询性能,将在这些领域扮演越来越重要的角色。
此外,跳表的理论研究也将不断深入。研究人员可能会提出更多优化空间复杂度的策略,或者设计出针对特定应用场景的跳表变体。这些创新性的研究成果,将推动跳表在实践中的更广泛应用。
总的来说,跳表作为一种经典而又富有创新的数据结构,必将在未来的计算机科学领域扮演重要的角色。它不仅在理论上富有挑战性,在实践中也有着广阔的应用前景。让我们一起期待跳表在未来的发展与应用!
跳表的理论分析与实践应用(续)
跳表的理论分析深入
在前面的分析中,我们已经探讨了跳表的基本空间复杂度,以及一些优化策略。但是,我们还可以进一步深入分析跳表的理论特性。
比如,我们可以研究跳表在不同概率分布下的期望高度。也就是说,如果我们采用随机的方式构建跳表的索引,跳表的平均高度会是多少?这个问题涉及到概率论和随机过程的相关知识。
另外,我们还可以分析跳表在并发环境下的性能表现。由于跳表的结构特点,它天生适合支持并发访问。我们可以研究如何设计高效的并发控制机制,以最大化跳表的并发性能。
这些理论分析不仅有助于我们更深入地理解跳表的特性,也可能带来一些实践上的启发和优化。比如,通过分析跳表的期望高度,我们可以确定合理的索引密度,从而在查询性能和空间开销之间达到最佳平衡。
跳表在实践中的应用案例
在前面的内容中,我们已经介绍了一些跳表在实际系统中的应用案例,如Redis、LevelDB、Elasticsearch等。这些案例充分证明了跳表在实践中的价值和潜力。
但是,我们还可以进一步深入探讨这些案例,分析跳表在这些系统中扮演的具体角色,以及它如何帮助这些系统实现高性能和可扩展性。
比如,我们可以研究Redis是如何利用跳表实现有序集合(Sorted Set)的,以及这种实现方式带来的性能优势。又或者,我们可以分析LevelDB是如何使用跳表作为内部索引结构的,以及这种设计如何影响LevelDB的整体性能。
通过深入分析这些实际应用案例,我们不仅可以更好地理解跳表在实践中的应用价值,还可以获得一些有价值的设计和实现经验。这些经验对于我们在自己的项目中使用跳表也会很有帮助。
跳表在未来计算机科学中的发展
展望未来,跳表作为一种灵活的数据结构,必将在计算机科学的各个领域发挥重要作用。
一方面,随着计算硬件的不断进化,内存容量的不断增加,跳表作为一种内存友好的数据结构,将在内存数据库、缓存系统等领域得到更广泛的应用。这些领域对于高效的查询性能有着迫切需求,跳表正好可以满足这些需求。
另一方面,随着大数据时代的到来,对于海量数据的高效查询和分析需求也越来越迫切。跳表凭借其优秀的查询性能,将在这些领域扮演越来越重要的角色。比如,在分布式存储系统、搜索引擎等大数据应用中,跳表可能会成为重要的索引结构。
此外,跳表的理论研究也将不断深入。研究人员可能会提出更多优化空间复杂度的策略,或者设计出针对特定应用场景的跳表变体。这些创新性的研究成果,将推动跳表在实践中的更广泛应用。
总的来说,跳表作为一种经典而又富有创新的数据结构,必将在未来的计算机科学领域扮演重要的角色。它不仅在理论上富有挑战性,在实践中也有着广阔的应用前景。让我们一起期待跳表在未来的发展与应用!
跳表的理论分析与实践应用(续)
跳表的理论分析进阶
在前面的分析中,我们已经探讨了跳表的基本空间复杂度,以及一些优化策略。但是,我们还可以进一步深入分析跳表的理论特性。
比如,我们可以研究跳表在不同概率分布下的期望高度。也就是说,如果我们采用随机的方式构建跳表的索引,跳表的平均高度会是多少?这个问题涉及到概率论和随机过程的相关知识。
另外,我们还可以分析跳表在并发环境下的性能表现。由于跳表的结构特点,它天生适合支持并发访问。我们可以研究如何设计高效的并发控制机制,以最大化跳表的并发性能。
这些理论分析不仅有助于我们更深入地理解跳表的特性,也可能带来一些实践上的启发和优化。比如,通过分析跳表的期望高度,我们可以确定合理的索引密度,从而在查询性能和空间开销之间达到最佳平衡。
跳表在实践中的应用案例深入
在前面的内容中,我们已经介绍了一些跳表在实际系统中的应用案例,如Redis、LevelDB、Elasticsearch等。这些案例充分证明了跳表在实践中的价值和潜力。
但是,我们还可以进一步深入探讨这些案例,分析跳表在这些系统中扮演的具体角色,以及它如何帮助这些系统实现高性能和可扩展性。
比如,我们可以研究Redis是如何利用跳表实现有序集合(Sorted Set)的,以及这种实现方式带来的性能优势。又或者,我们可以分析LevelDB是如何使用跳表作为内部索引结构的,以及这种设计如何影响LevelDB的整体性能。
通过深入分析这些实际应用案例,我们不仅可以更好地理解跳表在实践中的应用价值,还可以获得一些有价值的设计和实现经验。这些经验对于我们在自己的项目中使用跳表也会很有帮助。
跳表在未来计算机科学中的发展
展望未来,跳表作为一种灵活的数据结构,必将在计算机科学的各个领域发挥重要作用。
一方面,随着计算硬件的不断进化,内存容量的不断增加,跳表作为一种内存友好的数据结构,将在内存数据库、缓存系统等领域得到更广泛的应用。这些领域对于高效的查询性能有着迫切需求,跳表正好可以满足这些需求。
另一方面,随着大数据时代的到来,对于海量数据的高效查询和分析需求也越来越迫切。跳表凭借其优秀的查询性能,将在这些领域扮演越来越重要的角色。比如,在分布式存储系统、搜索引擎等大数据应用中,跳表可能会成为重要的索引结构。
此外,跳表的理论研究也将不断深入。研究人员可能会提出更多优化空间复杂度的策略,或者设计出针对特定应用场景的跳表变体。这些创新性的研究成果,将推动跳表在实践中的更广泛应用。
跳表在未来计算机科学中的发展(续)
除了上述领域,跳表在未来计算机科学中还可能有其他广泛的应用:
-
边缘计算和物联网:随着边缘设备计算能力的提升,跳表可能会在这些设备上扮演重要的角色。它可以用于高效管理和查询设备状态、事件等数据。
-
区块链和分布式账本:跳表的特性也可能在区块链和分布式账本系统中发挥作用。它可以用于构建高效的交易索引和查询机制。
-
机器学习和人工智能:跳表的查询性能优势也可能在机器学习模型的索引和检索中发挥作用,提高模型的推理效率。
-
图数据库和图计算:跳表可能会成为图数据库和图计算系统中的重要索引结构,支持高效的图遍历和查询。
总的来说,跳表作为一种经典而又富有创新的数据结构,必将在未来的计算机科学领域扮演重要的角色。它不仅在理论上富有挑战性,在实践中也有着广阔的应用前景。让我们一起期待跳表在未来的发展与应用!
相关文章:

redis高级篇之skiplist跳表 第164节答疑
跳表查询的空间复杂度分析 比起单纯的单链表,跳表需要存储多级索引,肯定要消耗更多的存储空间。那到底需要消耗多少额外的存储空间呢? 我们来分析一下跳表的空间复杂度。 第一步:首先原始链表长度为n, 第二步:两两取首,每层索引的…...

Java 线程池:深入理解与高效应用
在 Java 并发编程中,线程池是一种非常重要的技术。它可以有效地管理和复用线程,提高系统的性能和资源利用率。本文将深入探讨 Java 线程池的概念、原理、使用方法以及最佳实践,帮助读者更好地理解和应用线程池。 一、引言 在现代软件开发中&a…...

week08 zookeeper多种安装与pandas数据变换操作-new
课程1-hadoop-Zookeeper安装 Ububtu18.04安装Zookeeper3.7.1 环境与版本 这里采用的ubuntu18.04环境的基本配置为: hostname 为master 用户名为hadoop 静态IP为 192.168.100.3 网关为 192.168.100.2 防火墙已经关闭 /etc/hosts已经配置全版本下载地址࿱…...

js构造函数和原型对象,ES6中的class,四种继承方式
一、构造函数 1.构造函数是一种特殊的函数,主要用来初始化对象 2.使用场景 常见的{...}语法允许创建一个对象。可以通过构造函数来快速创建多个类似的对象。 const Peppa {name: 佩奇,age: 6,sex: 女}const George {name: 乔治,age: 3,sex: 男}const Mum {nam…...

电脑连接海康相机并在PictureBox和HWindowControl中分别显示。
展示结果: 下面附上界面中所有控件的Name,只需照着红字设置对应的控件Name即可 下面附上小编主界面的全部代码: using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; …...

直播系统源码技术搭建部署流程及配置步骤
系统环境要求 PHP版本:5.6、7.3 Mysql版本:5.6,5.7需要关闭严格模式 Nginx:任何版本 Redis:需要给所有PHP版本安装Redis扩展,不需要设置Redis密码 最好使用面板安装:宝塔面板 - 简单好用的…...

Spring+ActiveMQ
1. 环境搭建 1.1 env-version JDK 1.8 Spring 2.7.13 Maven 3.6 ActiveMQ 5.15.2 1.2 docker-compose.yml version: 3.8services:activemq:image: rmohr/activemq:5.16.3container_name: activemqports:- "61616:61616"- "8161:8161"environment…...

Linux 常用命令总汇
查询所有wifi nmcli dev wifi list 链接wifi sudo nmcli dev wifi connect XXXX password XXXX 查询本机IP ifconfig 查询联网情况 ping www.baidu.com 进入.bash gedit ~/.bashrc sudo dpkg -i XXX.deb 安装超级终端 sudo apt install terminator 超级终端常用…...

fmql之Linux RTC
模拟i2c,连接rtc芯片。 dts: /{ // 根节点i2c_gpio: i2c-gpio {#address-cells <1>;#size-cells <0>;compatible "i2c-gpio";// MIO56-SDA, MIO55-SCL // 引脚编号gpios <&portc 2 0&portc 1 0 >;i2c-gp…...

Flask-SocketIO 简单示例
用于服务端和客户端通信,服务端主动给客户端发送消息 前提: 确保安装了socket库: pip install flask-socketio python-socketio服务端代码 from flask import Flask from flask_socketio import SocketIO import threading import timeap…...
)
Vue 3 的组件式开发(2)
1 Vue 3 组件的插槽 插槽(Slot)是Vue组件中的一个重要概念,它允许父组件向子组件中插入HTML结构或其他组件,从而实现内容的自定义和复用。以下是对Vue 3组件插槽的详细讲解: 1.1 插槽的基本概念 插槽可以被视为子组…...

python 爬虫 入门 四、线程,进程,协程
目录 一、进程 特征: 使用: 初始代码 进程改装代码 二、线程 特征: 使用: 三、协程 后续:五、抓取图片、视频 线程和进程大部分人估计都知道,但协程就不一定了。 一、进程 进程是操作系统分配资…...

cloak斗篷伪装下的独立站
随着互联网的不断进步,越来越多的跨境电商卖家开始认识到独立站的重要性,并纷纷建立自己的独立站点。对于那些有志于进入这一领域的卖家来说,独立站是什么呢?独立站是指个人或小型团队自行搭建和运营的网站。 独立站能够帮助跨境…...

【Nas】X-DOC:在Mac OS X 中使用 WOL 命令唤醒局域网内 PVE 主机
【Nas】X-DOC:在Mac OS X 中使用 WOL 命令唤醒局域网内 PVE 主机 1、Mac OS X 端2、PVE 端(Debian Linux) 1、Mac OS X 端 (1)安装 wakeonlan 工具 brew install wakeonlan(2)唤醒 PVE 命令 …...

u盘装win10系统提示“windows无法安装到这个磁盘,选中的磁盘采用GPT分区形式”解决方法
我们在u盘安装原版win10 iso镜像时,发现在选择硬盘时提示了“windows无法安装到这个磁盘,选中的磁盘采用GPT分区形式”,直接导致了无法继续安装下去。出现这种情况要怎么解决呢?下面小编分享u盘安装win10系统提示“windows无法安装到这个磁盘…...

Linux系统之dc计算器工具的基本使用
Linux系统之dc计算器工具的基本使用 一、DC工具介绍二、dc命令的基本用法2.1 dc命令的help帮助信息2.2 dc命令基本用法2.3 dc命令常用操作符 三、dc命令的基本使用3.1dc命令的用法步骤3.2 简单数学计算3.3 通过文件来计算3.4 使用--expression计算3.5 使用dc命令进行高精度计算…...

使用Python计算相对强弱指数(RSI)进阶
使用Python计算相对强弱指数(RSI)进阶 废话不多说,直接上主题:> 代码实现 以下是实现RSI计算的完整代码: # 创建一个DataFramedata {DATE: date_list, # 日期CLOSE: close_px_list, # 收盘价格 }df pd.DataF…...

vue 解决:npm ERR! code ERESOLVE 及 npm ERR! ERESOLVE could not resolve 的方案
1、问题描述: 其一、需求为: 想要安装项目所需依赖,成功运行 vue 项目,想要在浏览器中能成功访问项目地址 其二、问题描述为: 在 package.json 文件打开终端平台,通过执行 npm install 命令,…...

Android 原生开发与Harmony原生开发浅析
Android系统 基于Linux ,架构如下 底层 (Linux )> Native ( C层) > FrameWork层 (SystemService) > 系统应用 (闹钟/日历等) 从Android发版1.0开始到现在15,经历了大大小小的变革 从Android6.0以下是个分水岭,6.0之前权限都是直接卸载Manifest中配置 6.0开始 则分普…...
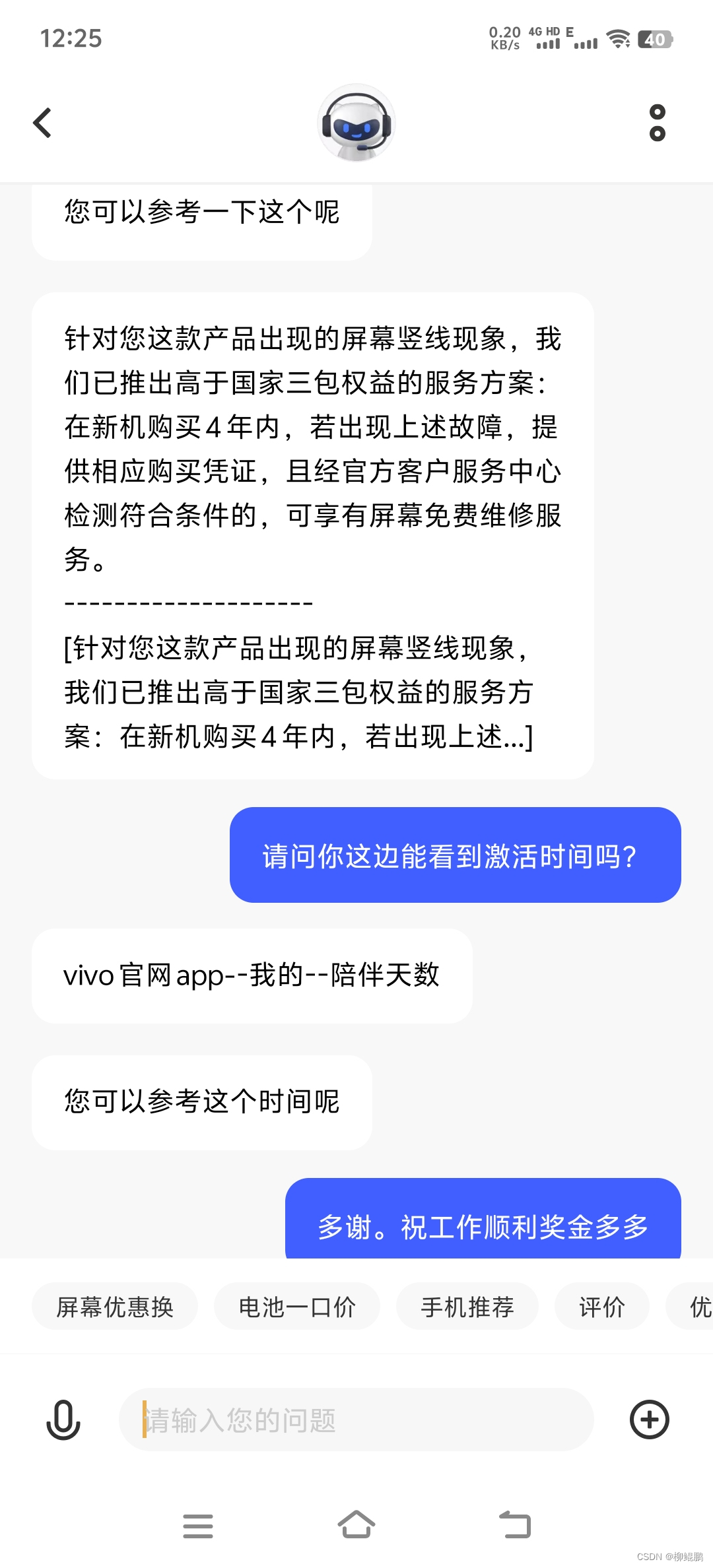
VIVO售后真好:屏幕绿线,4年免费换屏
只要亮屏就有。这也太影响使用了。 本来想换趁机换手机,看了VIVO发布的X200,决定等明年的X200 ULTRA。手头这个就准备修。 查了一下价格,换屏1600,优惠1100。咸鱼上X70 PRO也就800。能不能简单维修就解决呢?于是联系…...

接口测试中缓存处理策略
在接口测试中,缓存处理策略是一个关键环节,直接影响测试结果的准确性和可靠性。合理的缓存处理策略能够确保测试环境的一致性,避免因缓存数据导致的测试偏差。以下是接口测试中常见的缓存处理策略及其详细说明: 一、缓存处理的核…...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...

从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

ArcGIS Pro制作水平横向图例+多级标注
今天介绍下载ArcGIS Pro中如何设置水平横向图例。 之前我们介绍了ArcGIS的横向图例制作:ArcGIS横向、多列图例、顺序重排、符号居中、批量更改图例符号等等(ArcGIS出图图例8大技巧),那这次我们看看ArcGIS Pro如何更加快捷的操作。…...

pikachu靶场通关笔记22-1 SQL注入05-1-insert注入(报错法)
目录 一、SQL注入 二、insert注入 三、报错型注入 四、updatexml函数 五、源码审计 六、insert渗透实战 1、渗透准备 2、获取数据库名database 3、获取表名table 4、获取列名column 5、获取字段 本系列为通过《pikachu靶场通关笔记》的SQL注入关卡(共10关࿰…...

python报错No module named ‘tensorflow.keras‘
是由于不同版本的tensorflow下的keras所在的路径不同,结合所安装的tensorflow的目录结构修改from语句即可。 原语句: from tensorflow.keras.layers import Conv1D, MaxPooling1D, LSTM, Dense 修改后: from tensorflow.python.keras.lay…...

springboot整合VUE之在线教育管理系统简介
可以学习到的技能 学会常用技术栈的使用 独立开发项目 学会前端的开发流程 学会后端的开发流程 学会数据库的设计 学会前后端接口调用方式 学会多模块之间的关联 学会数据的处理 适用人群 在校学生,小白用户,想学习知识的 有点基础,想要通过项…...

【C++进阶篇】智能指针
C内存管理终极指南:智能指针从入门到源码剖析 一. 智能指针1.1 auto_ptr1.2 unique_ptr1.3 shared_ptr1.4 make_shared 二. 原理三. shared_ptr循环引用问题三. 线程安全问题四. 内存泄漏4.1 什么是内存泄漏4.2 危害4.3 避免内存泄漏 五. 最后 一. 智能指针 智能指…...
Linux基础开发工具——vim工具
文章目录 vim工具什么是vimvim的多模式和使用vim的基础模式vim的三种基础模式三种模式的初步了解 常用模式的详细讲解插入模式命令模式模式转化光标的移动文本的编辑 底行模式替换模式视图模式总结 使用vim的小技巧vim的配置(了解) vim工具 本文章仍然是继续讲解Linux系统下的…...
大模型——基于Docker+DeepSeek+Dify :搭建企业级本地私有化知识库超详细教程
基于Docker+DeepSeek+Dify :搭建企业级本地私有化知识库超详细教程 下载安装Docker Docker官网:https://www.docker.com/ 自定义Docker安装路径 Docker默认安装在C盘,大小大概2.9G,做这行最忌讳的就是安装软件全装C盘,所以我调整了下安装路径。 新建安装目录:E:\MyS…...