WISE:重新思考大语言模型的终身模型编辑与知识记忆机制
论文地址:https://arxiv.org/abs/2405.14768![]() https://arxiv.org/abs/2405.14768
https://arxiv.org/abs/2405.14768
1. 概述
随着世界知识的不断变化,大语言模型(LLMs)需要及时更新,纠正其生成的虚假信息或错误响应。这种持续的知识更新被称为终身模型编辑。当前的模型编辑方法主要通过两种方式存储新知识:长期记忆(模型参数)和工作记忆(神经网络激活/表示的非参数化知识)。然而,这两种方式在终身编辑情境下存在局限性,无法同时实现可靠性、泛化性和局部性。为了解决这一问题,本文提出了一种新的模型编辑方法——WISE。该方法采用双参数内存机制,在预训练知识与更新知识之间实现了无缝衔接,通过一种知识分片机制来避免知识冲突。
大语言模型在训练时获取的知识是静态的,但世界知识是不断变化的。因此,部署后的LLMs可能生成包含幻觉、偏见或过时的响应。同时,由于重新训练或微调模型代价高昂,无法满足快速增长的知识需求。因此,终身模型编辑成为一种解决方案,通过不断地更新和注入知识来保持模型的准确性。然而,模型编辑面临一个关键问题:更新后的知识应存储在何处。
- 长期记忆编辑:直接修改模型参数存储新知识。这种方式虽然可以保持对新知识的记忆,但会导致与原有预训练知识发生冲突,影响局部性和可靠性。
- 工作记忆编辑:利用非参数化的检索机制存储新知识,不修改模型参数。这种方式虽然可以避免与原有知识的冲突,提升局部性,但难以泛化,无法应对多样化的查询。
在此背景下,如何在终身模型编辑中平衡可靠性、泛化性和局部性,成为模型编辑的一个核心难题。

为了解决上述问题,本文提出了WISE(双参数内存机制的终身模型编辑方法),通过结合长期记忆和工作记忆的优点,打破模型编辑中的“不可能三角”。
-
双参数内存机制:
- 主内存:存储预训练时的原始知识,保持长期记忆的泛化能力。
- 侧内存:专门用于存储和更新新知识,保证可靠性和局部性。
-
路由机制:为了确保编辑后的模型在不同情境下调用合适的知识,WISE设计了一个路由器。该路由器根据输入查询的不同,自动选择是使用主内存中的预训练知识,还是侧内存中的更新知识。这样就能避免对无关知识的干扰。
-
知识分片机制:为了应对不断增加的编辑请求,WISE引入了知识分片机制。每一组编辑知识会被存储在不同的参数子空间中,这些子空间是相互正交的,确保了不同编辑之间不会产生冲突。编辑完成后,这些分片会被合并为一个共享的侧内存,从而实现无冲突的终身编辑。
WISE的设计主要解决了现有模型编辑方法在终身学习中的不足。具体体现在以下几点:
- 可靠性:模型可以记住当前和之前的编辑内容,不会在多次编辑后遗忘新知识。
- 局部性:编辑只会影响到相关的知识,不会破坏与该编辑无关的预训练知识。
- 泛化性:模型不仅能记住具体的查询-目标对,还能理解编辑内容,能够应对不同形式的相同知识查询。
在实验中,WISE显著优于传统的基于长期记忆或工作记忆的模型编辑方法。其在多个LLM架构(如GPT、LLaMA、Mistral等)下的实验表明,WISE在问答任务、幻觉检测和分布外任务等终身模型编辑场景中,均在可靠性、泛化性和局部性三个指标上取得了更好的结果。
2. 方法
2.1 终身模型编辑
终身模型编辑问题,其核心目标是通过连续的编辑,使得大语言模型(LLMs)的输出能够符合人类的期望,同时保持模型之前的知识和能力。

2.2 重新思考终身模型编辑的内存设计
表1列出了当前主要模型编辑方法在内存类型和终身编辑能力上的对比。对比的关键维度包括:
- 长期记忆编辑(修改模型参数)
- 工作记忆编辑(检索时使用神经网络激活/表示的非参数化知识)
- 参数化知识与检索知识
- 是否支持终身编辑
- 可靠性、泛化性和局部性
表1中的方法对比总结如下:
- FT-EWC、ROME、MEMIT、MEND:这些方法通过修改 LLM 模型参数来编辑长期记忆,但无法支持连续编辑,或者会对无关知识产生负面影响,导致局部性较差。
- GRACE:基于工作记忆,通过检索知识避免了对无关知识的冲突,但由于检索机制只记忆查询,不理解其含义,泛化能力较差。
WISE 方法则通过结合长期记忆和工作记忆的优势,提供了一种更有效的终身模型编辑方案。它利用一个双参数内存机制,同时保持 LLM 的长期记忆(泛化能力)和工作记忆(可靠性和局部性),使其在终身模型编辑中表现出色。

2.3 WISE: 侧内存与知识分片、合并及路由
WISE 的侧内存包含两个关键组成部分:
-
侧内存设计:
- 侧内存:侧内存是 LLM 某一前馈神经网络(FFN)层的副本,用于存储编辑流。通过这种设计,避免直接修改主内存而可能带来的遗忘和副作用。
- 路由机制:为了决定使用主内存还是侧内存,设计了路由激活组件,来识别编辑的范围。在推理过程中,该组件决定是使用主内存还是侧内存来完成推理。
-
知识分片与合并:
- 知识在随机子空间中的分片:为了避免遗忘,将侧内存分为多个随机子空间,保证知识编辑的密度和分布性。
- 知识合并:利用模型合并技术,将不同的侧内存片段合并为一个共享的侧内存,避免知识丢失。
2.3.1 侧内存设计 (Side Memory Design)
(1)侧内存设计的基本原理:
在Transformer中,每层包含一个多头自注意力机制(MHA)和一个前馈神经网络(FFN),而FFN占据了模型中大量的参数。为避免直接修改主内存(模型预训练时学到的知识),WISE引入了侧内存,用来存储编辑过的知识。

 (2)主内存与侧内存之间的路由 (Routing between Side Memories and Main Memory)
(2)主内存与侧内存之间的路由 (Routing between Side Memories and Main Memory)


(3)基于边界的损失函数 (Margin-based Loss Function)


2.3.2 知识分片与合并 (Knowledge Sharding and Merging)
(1)知识密度问题 (Knowledge Density)
为了在终身模型编辑中有效存储更新的知识,作者引入了知识密度的概念,它类似于知识容量,用于描述在模型的参数中存储了多少知识。在这个背景下,存在以下两难问题:
- 知识密度过低:如果编辑次数较少或对整个内存进行微调,知识密度低,可能导致过拟合;
- 知识密度过高:如果编辑过于频繁,知识密度过高,导致已编辑的知识发生冲突,可能引发灾难性遗忘。
为解决此问题,作者提出了一种知识分片和合并机制,将侧内存编辑划分为多个子片段,存储在不同的参数子空间中,随后通过合并这些子空间,形成一个完整的侧内存。这样设计的好处在于避免了知识冲突,同时实现高效存储。
(2)随机子空间中的知识 (Knowledge in Random Memory Subspaces)
 (3)知识合并 (Knowledge Merging)
(3)知识合并 (Knowledge Merging)
在完成多次编辑后,多个子空间中的知识需要合并为一个共享的侧内存。由于不同的子空间通过随机掩码生成,这些子空间可能存在重叠部分和不相交部分。作者提出了如下定理来描述这些子空间重叠的情况:


(3)知识合并技术:Ties-Merge
Ties-Merge 的合并过程分为三步:
- 修剪:修剪每个任务向量中的冗余参数;
- 符号选择:为每个参数选择最合适的符号;
- 不相交合并:计算不相交子空间的参数均值,并将结果合并到一个统一的侧内存中。
通过 Ties-Merge,多个子空间中的知识能够有效合并,减少了子空间合并时的冲突。
(4)路由与检索多个侧内存 (Routing and Retrieving among Several Side Memories)
由于单个侧内存的知识容量有限,WISE 设计了一个多侧内存系统,能够产生多个侧内存并在推理过程中进行检索。检索过程通过激活评分路由机制(activation score routing)来实现,系统会根据不同的激活指示器分数,选择最合适的内存进行推理。该设计被称为WISE-Retrieve,允许模型应对更复杂的终身编辑场景。
3.实验
3.1 实验设置和评估指标
(1)数据集与模型
- 选择了几种流行的自回归大型语言模型(LLMs)进行实验,包括:
- LLaMA-2-7B
- Mistral-7B
- GPT-J-6B
论文使用了三个不同的数据集:
- ZsRE(零样本关系抽取,用于问答任务)
- SelfCheckGPT(用于修正语言模型生成的幻觉现象)
- Temporal(用于评估编辑模型在分布外数据上的泛化能力)
表格3中给出了这些数据集的统计信息,以及编辑数据和评估时使用的无关数据。

(2)基线方法
实验中,比较了多种基线方法和WISE,包括:
- FT-L:直接微调,使用了KL散度损失。
- FT-EWC:基于弹性权重合并(EWC)的连续学习微调方法。
- GPT风格编辑器:如ROME和MEMIT,用于批量编辑模型。
- MEND:基于超网络的编辑器。
- DEFER 和 GRACE:基于检索的记忆编辑方法。
(3)评估指标
每个编辑示例包含三个主要测试指标:
- Reliability(可靠性):模型编辑的成功率。
- Generalization(泛化能力):编辑后的模型在其他类似查询上的表现。
- Locality(局部性):编辑后的模型应保持无关数据的输出不变。

3.2 实验结果
(1)WISE的竞争性表现
WISE 在实验中展示了相对于基线模型的卓越性能,特别是在以下几个方面:
- WISE 超越了现有方法,尤其是在长编辑序列任务中;
- 直接编辑长期记忆(如 ROME 和 MEMIT 等)会导致与预训练知识的冲突,导致局部性差;
- 使用检索工作记忆的方法(如 GRACE 和 DEFER 等)在泛化能力上表现不佳,难以适应多样化查询。
在 问答任务(QA setting) 中,编辑次数 T=1000 时,WISE 在 LLaMA 和 Mistral 模型上分别获得了 0.83 和 0.79 的平均分数,相较于最接近的竞争对手提高了 18% 和 11%。这说明了 WISE 在处理长序列编辑时具有良好的稳定性和有效的管理能力。
相比之下,尽管 MEND 和 ROME 在编辑初期表现良好,但随着编辑序列的扩展,它们的表现明显下降,尤其在局部性方面。直接编辑长期记忆的方式(如 MEMIT、FT-EWC 和 MEND)会显著破坏模型的知识结构,且在 T=100 或 1000 时表现出局部性的大幅下降。


(2)分布外泛化评估(Out-of-Distribution Evaluation)
理想的模型编辑方法应能够在复杂分布转换(distributional shift)中从公式化编辑例子泛化到自然文本。基于此,使用 Temporal 数据集 测试了分布外的泛化能力。WISE 在该数据集上取得了最佳表现,在 OOD Gen.(泛化能力) 和整体性能上表现出色,尤其是表5所展示的结果。
- GRACE 在处理长文本时表现不佳,主要因为它的有限参数训练能力。
- WISE 通过在有限记忆中进行检索路由,避免了 GRACE 和 MEMIT 在处理分布外泛化时所面临的问题,尤其是在应对单个输入词元(token)表示时遇到的问题。
这段内容的主要总结是 WISE 在不同任务和编辑场景下,相对于其他基线方法具有更好的鲁棒性、泛化能力和局部性表现,特别是在长编辑序列和分布外任务中的优异表现。

3.3 进一步分析(Further Analysis)
(1)WISE的路由激活可视化(Visualization of WISE’s Routing Activation)
为了展示记忆路由的效果,实验记录了1000个问答任务(QA)和600个幻觉检测任务中的查询激活值。结果表明,几乎所有无关查询的激活值都较低,而WISE可以精确地将编辑查询和未见过的同义词路由到侧记忆中。这确保了编辑的局部性,并防止了在长期编辑中模型偏离预训练分布。

(2)WISE侧记忆的局部化分析(Localization Analysis of WISE’s Side Memory)
为了验证在Transformer模型中中到晚层编辑的优势,实验选择了解码器的早期、中期和晚期层进行对比。结果表明,早期和最终层的编辑效果不佳,而中到晚层的编辑效果显著。例如,选择第26层进行编辑可以保持80%的成功率和泛化率,同时保持100%的局部性。这表明中到晚层非常适合作为侧记忆的编辑层。
(3)对ρ和k的分析(Analysis of ρ and k for WISE)
通过对WISE的重要超参数(掩码比例ρ和子空间数量k)的分析,结果表明,当k⋅ρ=0.4<1 时,子空间设计的知识密度较高,有助于更好的泛化。最佳的子空间重叠概率是0.03,这在合并时作为锚点,同时避免了冲突。实验表明,约20%的FFN参数可以存储至少500个编辑示例。
(4)扩展到3000次编辑(Scale Up to 3K of Edits)
实验将连续编辑次数扩展到3000次,比较了WISE的多次合并方法(WISE-Merge)和基于路由和检索的WISE-Retrieve方法。实验表明,WISE在应对大规模编辑时保持了高可扩展性,并且WISE-Retrieve在3000次编辑中表现出最佳的性能。

(5)路由器设计的贡献(Contribution of Router Designs in WISE)
实验对比了没有路由策略的情况下,所有输入均通过主记忆或侧记忆。通过实验验证,WISE的路由器设计在识别编辑范围和最小化副作用方面具有显著效果。表7显示了不同编辑次数下路由器对性能的影响。

(6)WISE的推理时间分析(Inference Time Analysis of WISE)
推理时间分析表明,随着编辑次数的增加,WISE-Merge保持了稳定的推理时间延迟(约3%),而WISE-Retrieve由于引入了检索机制,推理时间有所增加,但总体仍在可接受范围内,约增加了7%的时间成本。

存在的潜在问题:
(1)副记忆检索的可扩展性:作者承认在处理非常长的编辑流时,副记忆的检索还有改进的空间。随着编辑数量的增加,特别是在WISE-Retrieve模式下,这可能会导致效率低下。
(2)推理时间的增加:随着编辑次数的增加,特别是在WISE-Retrieve模式中,推理时间会变长。这对于实时应用(需要低延迟响应)来说是一个问题。
(3)合并过程中潜在的知识冲突:虽然WISE采用了Ties-Merge技术来合并副记忆并减少冲突,但在存在多个重叠编辑的情况下,仍可能会出现知识冲突的场景
相关文章:
WISE:重新思考大语言模型的终身模型编辑与知识记忆机制
论文地址:https://arxiv.org/abs/2405.14768https://arxiv.org/abs/2405.14768 1. 概述 随着世界知识的不断变化,大语言模型(LLMs)需要及时更新,纠正其生成的虚假信息或错误响应。这种持续的知识更新被称为终身模型编…...

网络安全证书介绍
网络安全领域有很多专业的证书,可以帮助你提升知识和技能,增强在这个行业中的竞争力。以下是一些常见的网络安全证书: 1. CompTIA Security 适合人群:初级安全专业人员证书内容:基础的网络安全概念和实践,…...

【已解决】【hadoop】【hive】启动不成功 报错 无法与MySQL服务器建立连接 Hive连接到MetaStore失败 无法进入交互式执行环境
启动hive显示什么才是成功 当你成功启动Hive时,通常会看到一系列的日志信息输出到控制台,这些信息包括了Hive服务初始化的过程以及它与Metastore服务连接的情况等。一旦Hive完成启动并准备就绪,你将看到提示符(如 hive> &#…...

基于架设一台NFS服务器实操作业
架设一台NFS服务器,并按照以下要求配置 首先需要关闭防火墙和SELinux 1、开放/nfs/shared目录,供所有用户查询资料 赋予所有用户只读的权限,sync将数据同步写到磁盘上 在客户端需要创建挂载点,把服务端共享的文件系统挂载到所创建…...

eachers中的树形图在点击其中某个子节点时关闭其他同级子节点
答案在代码末尾!!!!! tubiaoinit(params: any) {// 手动触发变化检测this.changeDetectorRef.detectChanges();if (this.myChart ! undefined) {this.myChart.dispose();}this.myChart echarts.init(this.pieChart?…...

Maven 介绍与核心概念解析
目录 1. pom文件解析 2. Maven坐标 3. Maven依赖范围 4. Maven 依赖传递与冲突解决 Maven,作为一个广泛应用于 Java 平台的自动化构建和依赖管理工具,其强大功能和易用性使得它在开发社区中备受青睐。本文将详细解析 Maven 的几个核心概念&a…...
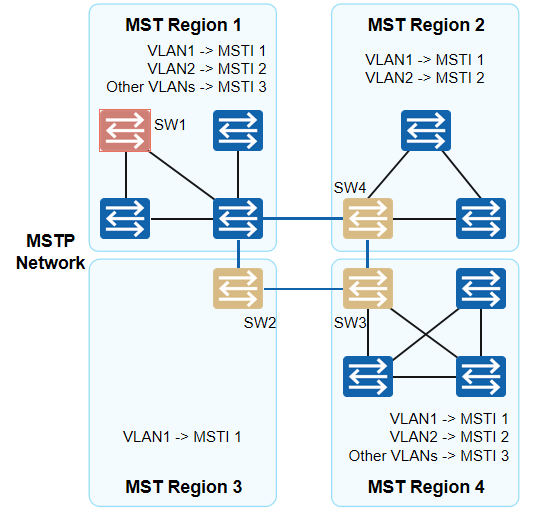
计算机网络-MSTP概述
一、RSTP/STP的缺陷与不足 前面我们学习了RSTP对于STP的一些优化与快速收敛机制。但在划分VLAN的网络中运行RSTP/STP,局域网内所有的VLAN共享一棵生成树,被阻塞后的链路将不承载任何流量,无法在VLAN间实现数据流量的负载均衡,导致…...

Redisson(三)应用场景及demo
一、基本的存储与查询 分布式环境下,为了方便多个进程之间的数据共享,可以使用RedissonClient的分布式集合类型,如List、Set、SortedSet等。 1、demo <parent><groupId>org.springframework.boot</groupId><artifact…...
1)
考研要求掌握的C语言程度(堆排序)1
含义 堆排序就是把数组的内容在心中建立为大根堆,然后每次循环把根顶和没交换过的根末进行调换,再次建立大根堆的过程 建树的几个公式 一个数组有n个元素 最后一个父亲节点是n/2-1; 假如父亲节点在数组的下标为a 那么左孩子节点在数组下标为2*a1,…...

chronyd配置了local的NTP server之后, NTP报文中出现public IP的问题
描述 客户在Rocky Linux 9.4的VM上配了一个local的NTP server(IP: 10.64.1.76)。 配置完成后, 时钟可以同步,但一段时间后客户的firewall收到告警, 拒绝了大量目标端口为123的请求, 且这些请求的目的IP并不是客户指定的NTP server的IP,客户要求解释原因…...

docker常用命令整理
文章目录 docker 常用操作命令一、镜像类操作1.构建镜像2.从容器创建镜像3.查看镜像列表4.删除镜像5. 从远程镜像仓库拉取镜像6. 将镜像推送到镜像仓库中7. 将镜像导出8. 导入镜像9. 登录镜像仓库 二、容器相关操作1. 运行容器2. 进入容器3. 查看容器的运行状态4. 查看容器的日…...

将CSDN博客转换为PDF的Python Web应用开发--Flask实战
文章目录 项目概述技术栈介绍 项目目录应用结构 功能实现单页博客转换示例: 专栏合集博客转换示例: PDF效果: 代码依赖文件requirements.txt:app.py:代码解释: /api/onepage.py:代码解释: /api/zhuanlan.py…...
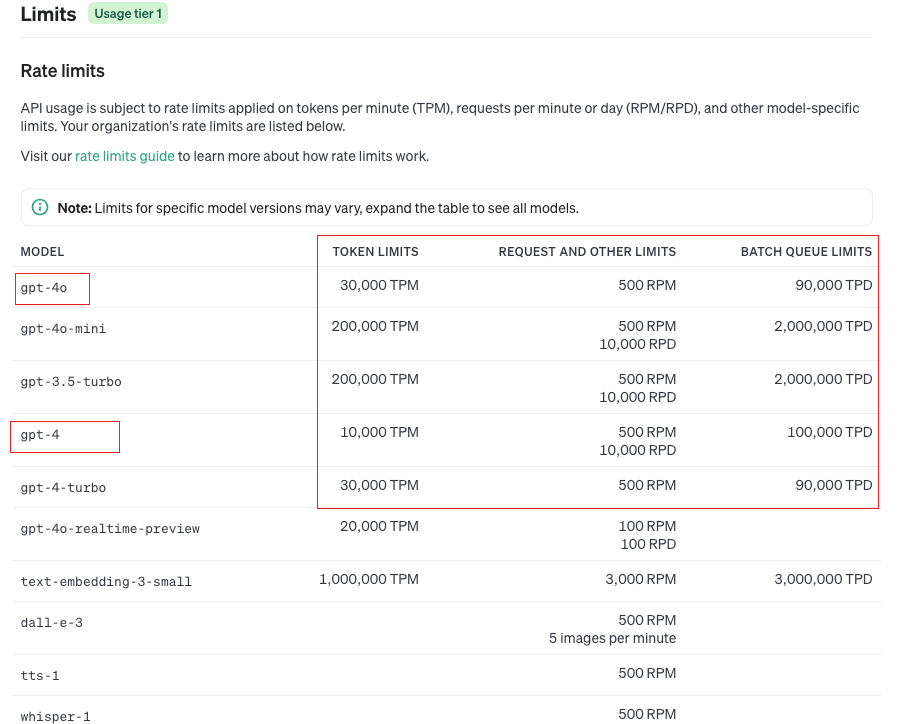
AIGC学习笔记(3)——AI大模型开发工程师
文章目录 AI大模型开发工程师002 GPT大模型开发基础1 OpenAI账户注册2 OpenAI官网介绍3 OpenAI GPT费用计算4 OpenAI Key获取与配置5 OpenAI 大模型总览6 代码演示安装依赖导入依赖初始化客户端执行代码遇到的问题 AI大模型开发工程师 002 GPT大模型开发基础 1 OpenAI账户注册…...

Windows server 2003服务器的安装
Windows server 2003服务器的安装 安装前的准备: 1.镜像SN序列号 图1-1 Windows server 2003的安装包非常人性化 2.指定一个安装位置 图1-2 选择好安装位置 3.启动虚拟机打开安装向导 图1-3 打开VMware17安装向导 图1-4 给虚拟光驱插入光盘镜像 图1-5 输入SN并…...

HTML作业
作业 复现下面的图片 复现结果 代码 <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title></head><body><form action"#"method"get"enctype"text/plain"><…...

MYSQL-SQL-04-DCL(Data Control Language,数据控制语言)
DCL(数据控制语言) DCL英文全称是Data Control Language(数据控制语言),用来管理数据库用户、控制数据库的访问权限。 一、管理用户 1、查询用户 在MySQL数据库管理系统中,mysql 是一个特殊的系统数据库名称,它并不…...

多线程进阶——线程池的实现
什么是池化技术 池化技术是一种资源管理策略,它通过重复利用已存在的资源来减少资源的消耗,从而提高系统的性能和效率。在计算机编程中,池化技术通常用于管理线程、连接、数据库连接等资源。 我们会将可能使用的资源预先创建好,…...

C++网络编程之C/S模型
C网络编程之C/S模型 引言 在网络编程中,C/S(Client/Server,客户端/服务器)模型是一种最基本且广泛应用的架构模式。这种模型将应用程序分为两个部分:服务器(Server)和客户端(Clien…...

目标检测:YOLOv11(Ultralytics)环境配置,适合0基础纯小白,超详细
目录 1.前言 2. 查看电脑状况 3. 安装所需软件 3.1 Anaconda3安装 3.2 Pycharm安装 4. 安装环境 4.1 安装cuda及cudnn 4.1.1 下载及安装cuda 4.1.2 cudnn安装 4.2 创建虚拟环境 4.3 安装GPU版本 4.3.1 安装pytorch(GPU版) 4.3.2 安装ultral…...
面试域——岗位职责以及工作流程
摘要 介绍互联网岗位的职责以及开发流程。在岗位职责方面,详细阐述了产品经理、前端开发工程师、后端开发工程师、测试工程师、运维工程师等的具体工作内容。产品经理负责需求收集、产品规划等;前端专注界面开发与交互;后端涉及系统架构与业…...

【OSG学习笔记】Day 18: 碰撞检测与物理交互
物理引擎(Physics Engine) 物理引擎 是一种通过计算机模拟物理规律(如力学、碰撞、重力、流体动力学等)的软件工具或库。 它的核心目标是在虚拟环境中逼真地模拟物体的运动和交互,广泛应用于 游戏开发、动画制作、虚…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

unix/linux,sudo,其发展历程详细时间线、由来、历史背景
sudo 的诞生和演化,本身就是一部 Unix/Linux 系统管理哲学变迁的微缩史。来,让我们拨开时间的迷雾,一同探寻 sudo 那波澜壮阔(也颇为实用主义)的发展历程。 历史背景:su的时代与困境 ( 20 世纪 70 年代 - 80 年代初) 在 sudo 出现之前,Unix 系统管理员和需要特权操作的…...

Unit 1 深度强化学习简介
Deep RL Course ——Unit 1 Introduction 从理论和实践层面深入学习深度强化学习。学会使用知名的深度强化学习库,例如 Stable Baselines3、RL Baselines3 Zoo、Sample Factory 和 CleanRL。在独特的环境中训练智能体,比如 SnowballFight、Huggy the Do…...

pikachu靶场通关笔记22-1 SQL注入05-1-insert注入(报错法)
目录 一、SQL注入 二、insert注入 三、报错型注入 四、updatexml函数 五、源码审计 六、insert渗透实战 1、渗透准备 2、获取数据库名database 3、获取表名table 4、获取列名column 5、获取字段 本系列为通过《pikachu靶场通关笔记》的SQL注入关卡(共10关࿰…...

Mac下Android Studio扫描根目录卡死问题记录
环境信息 操作系统: macOS 15.5 (Apple M2芯片)Android Studio版本: Meerkat Feature Drop | 2024.3.2 Patch 1 (Build #AI-243.26053.27.2432.13536105, 2025年5月22日构建) 问题现象 在项目开发过程中,提示一个依赖外部头文件的cpp源文件需要同步,点…...

人机融合智能 | “人智交互”跨学科新领域
本文系统地提出基于“以人为中心AI(HCAI)”理念的人-人工智能交互(人智交互)这一跨学科新领域及框架,定义人智交互领域的理念、基本理论和关键问题、方法、开发流程和参与团队等,阐述提出人智交互新领域的意义。然后,提出人智交互研究的三种新范式取向以及它们的意义。最后,总结…...

华为OD机试-最短木板长度-二分法(A卷,100分)
此题是一个最大化最小值的典型例题, 因为搜索范围是有界的,上界最大木板长度补充的全部木料长度,下界最小木板长度; 即left0,right10^6; 我们可以设置一个候选值x(mid),将木板的长度全部都补充到x,如果成功…...

通过MicroSip配置自己的freeswitch服务器进行调试记录
之前用docker安装的freeswitch的,启动是正常的, 但用下面的Microsip连接不上 主要原因有可能一下几个 1、通过下面命令可以看 [rootlocalhost default]# docker exec -it freeswitch fs_cli -x "sofia status profile internal"Name …...