ElasticSearch基础篇——概念讲解,部署搭建,使用RestClient操作索引库和文档数据
目录
一、概念介绍
二、Elasticsearch的Docker容器安装
2.1拉取elasticsearch的镜像文件
2.2运行docker命令启动容器
2.3通过访问端口地址查看部署情况
三、安装Kibana容器
3.1拉取Kibana镜像容器指令(默认拉取最新版本):
3.2拉取完成后运行docker命令,部署Kibana:
3.3访问kibana提供的界面检查是否部署成功
四、配置中文分词器IK分词器
4.1在线安装IK插件
4.2离线安装
4.3通过IK分词器实现拓展词库,以及屏蔽不需要的创建词条的词语
五、elasticsearch的DSL指令使用
5.1创建索引库和mapping的DSL语句如下:
5.2其他常见索引库操作指令:
5.3使用DSL语句对文档数据进行操作
5.3.1新增文档
5.3.2查看删除文档
5.3.3修改文档
六、使用JavaRestClient实现创建、删除索引库,判断索引库是否存在
6.1、引入es的RestHighLevelClient依赖
6.2配置config文件,初始化RestHighLevelClient:
6.3创建索引库
6.4删除索引库
6.5获取索引库
七、使用RestClient操作文档数据
7.1向索引库中添加文档数据
7.2获取文档对象并解析转换为实体对象
7.3更新文档对象数据
7.4删除文档对象
7.5实现批量插入文档对象
一、概念介绍
概念:
什么是ES?
- 从功能上来说,elasticsearchelasticsearchelasticsearch是一款非常强大的开源搜索引擎,可以帮助我们从海量数据中快速找到需要的内容,实现搜索、日志统计、分析、系统监控等功能
- 从架构上说,elasticsearch是elastic stack的核心,负责存储、搜索、分析数据。
什么是elastic stack?
- elasticsearch结合kibana、Logstash、Beats,也就是elastic stack(ELK)。被广泛应用在日志数据分析、实时监控等领域
ES能够实现对数据的快速搜索,主要原因就是它采用倒排索引的方式:
倒排索引中包含两部分内容:
- 词条词典(Term Dictionary):记录所有词条,以及词条与倒排列表(Posting List)之间的关系,会给词条创建索引,提高查询和插入效率
- 倒排列表(Posting List):记录词条所在的文档id、词条出现频率 、词条在文档中的位置等信息
- 文档id:用于快速获取文档
- 词条频率(TF):文档在词条出现的次数,用于评分
简单来说就是将一条条数据划分一个个文档,再对整个文档中的某些字段建立倒排索引,将字段按照语义划分成词语,再将每个不同的词语作为主键,对应的值就是文档的id,如下图:
ES搜索流程:
同时ES也是面向文档进行存储,可以是数据库中的一条商品数据,一个订单信息。
文档数据会被序列化为json格式后存储在elasticsearch中
索引:相同类型的文档的集合
映射(mapping):索引中文档的字段约束信息,类似表的结构约束
下面为了加深读者对ES的认识,有关于elasticsearch和数据库的对比表格
MySQL
Elasticsearch
说明
Table
Index
索引(index),就是文档的集合,类似数据库的表(table)
Row
Document
文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式
Column
Field
字段(Field),就是JSON文档中的字段,类似数据库中的列(Column)
Schema
Mapping
Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema)
SQL
DSL
DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD
架构对比:
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
Elasticsearch:擅长海量数据的搜索、分析、计算




二、Elasticsearch的Docker容器安装
2.1拉取elasticsearch的镜像文件
默认拉取最新版本,内容较大可能拉取失败,可以提前在windows下载好,上传到linux中
docker pull docker.elastic.co/elasticsearch/elasticsearch导入上传的镜像的tar包
docker load -i es.tar2.2运行docker命令启动容器
这里指定运行内存大小为512M,读者可更更具需求自行变更,详细命令解释如下
docker run -d \--name es \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \-e "discovery.type=single-node" \-v es-data:/usr/share/elasticsearch/data \-v es-plugins:/usr/share/elasticsearch/plugins \--privileged \--network es-net \-p 9200:9200 \-p 9300:9300 \
elasticsearch:7.12.1命令解释:
-e "cluster.name=es-docker-cluster":设置集群名称-e "http.host=0.0.0.0":监听的地址,可以外网访问-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小-e "discovery.type=single-node":非集群模式-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录--privileged:授予逻辑卷访问权--network es-net:加入一个名为es-net的网络中,方便之后创建Kibana容器后,两者互相连接-p 9200:9200:端口映射配置
2.3通过访问端口地址查看部署情况

查询如上图所示,则表示查询成功
三、安装Kibana容器
为了实现对elasticsearch可视化操作,我们需要使用Kibana,帮助我们搭建一个页面实现对es的操作
注意:Kibana和ES版本必须一致
3.1拉取Kibana镜像容器指令(默认拉取最新版本):
docker pull docker.elastic.co/kibana/kibana3.2拉取完成后运行docker命令,部署Kibana:
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1指令解释:
-
--network es-net:加入一个名为es-net的网络中,与elasticsearch在同一个网络中 -
-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch -
-p 5601:5601:端口映射配置
3.3访问kibana提供的界面检查是否部署成功

四、配置中文分词器IK分词器
官方提供的分词器对中文的支持很不友好,所以我们需要引入第三方的IK分词器插件
ik分词器包含两种模式:
- ik_smart:最少切分,粗粒度
- ik_max_word:最细切分,细粒度
4.1在线安装IK插件
注意:IK分词器插件的版本需要对应自己的ES版本,比如我这里的7.12.1
官方插件下载地址:
# 进入容器内部
docker exec -it elasticsearch /bin/bash# 在线下载并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip#退出
exit
#重启容器
docker restart elasticsearch4.2离线安装
如果提前在官方网址下载好了对应的IK分词器,可通过上传到数据卷的方式完成安装
安装插件需要知道elasticsearch的plugins目录位置,而我们用了数据卷挂载,因此需要查看elasticsearch的数据卷目录,通过下面命令查看:
docker volume inspect es-plugins地址:

将下载好的IK分词器的zip包解压成ik文件并上传到/var/lib/docker/volumes/es-plugins/_data文件内

重新启动容器完成插件安装
4.3通过IK分词器实现拓展词库,以及屏蔽不需要的创建词条的词语
要拓展ik分词器的词库,只需要修改一个ik分词器目录中的config目录中的IkAnalyzer.cfg.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict">ext.dic</entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords">stopword.dic</entry><!--用户可以在这里配置远程扩展字典 --><!-- <entry key="remote_ext_dict">words_location</entry> --><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
ext.dic文本文件格式示例:直接换行输入你想要添加的扩展词汇

stopword.dic文本文件格式如上
五、elasticsearch的DSL指令使用
在创建索引库中需要了解索引库的Mapping属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
- type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true
- analyzer:使用哪种分词器
- properties:该字段的子字段
总结:
Mapping常见属性:
- type:数据类型
- index:是否索引
- analyzer:分词器
- properties:子字段
常见type类型:
- 字符串:text、keyword
- 数字:long、integer、short、byte、double、float
- 布尔:boolean
- 日期:date
- 对象:object
5.1创建索引库和mapping的DSL语句如下:
ES中通过Restful请求操作索引库、文档,所以第一行Kibana需要发送一段请求,请求中携带DSL语句完成创建demo索引库
PUT /demo
{"mappings": {"properties": {"info":{"type": "text","analyzer": "ik_smart"},"email":{"type": "keyword","index": "false"},"name":{"properties": {"firstName": {"type": "keyword"}}},// ... 略}}
}
5.2其他常见索引库操作指令:
查看索引库语法:
GET /替换为需要查询的索引库名称删除索引库的语法:
DELETE /替换为需要查询的索引库名称修改索引库语法
注意: 索引库和mapping一旦创建无法修改,但是可以添加新的字段,语法如下:
PUT /索引库名/_mapping
{"properties": {"新字段名":{"type": "integer"}}
}
总结:
索引库操作
- 创建索引库:PUT /索引库名
- 查询索引库:GET /索引库名
- 删除索引库:DELETE /索引库名
- 添加字段:PUT /索引库名/_mapping
5.3使用DSL语句对文档数据进行操作
5.3.1新增文档
语法:
POST /索引库名/_doc/文档id
{"字段1": "值1","字段2": "值2","字段3": {"子属性1": "值3","子属性2": "值4"},// ...
}
如:

注意:
- 插入文档时,es会检查文档中的字段是否有mapping,如果没有则按照默认mapping规则来创建索引。
- 如果默认mapping规则不符合你的需求,一定要自己设置字段mapping
5.3.2查看删除文档
查看文档语法:
GET /索引库名/_doc/文档id 删除索引库的语法:
DELETE /索引库名/_doc/文档id 5.3.3修改文档
方式一:全量修改语法:删除原文档数据,再新增本文档数据
PUT /索引库名/_doc/文档id
{"字段1": "值1","字段2": "值2",// ... 略
}
方式二:增量修改,修改指定字段值语法:
POST /索引库名/_update/文档id
{"doc": {"字段名": "新的值",}
}六、使用JavaRestClient实现创建、删除索引库,判断索引库是否存在
6.1、引入es的RestHighLevelClient依赖
<properties><java.version>1.8</java.version><elasticsearch.version>7.12.1</elasticsearch.version>
</properties>
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>6.2配置config文件,初始化RestHighLevelClient:
@Configuration
public class ClientConfiguration {@Beanpublic RestHighLevelClient client() {return new RestHighLevelClient(RestClient.builder(new HttpHost("192.168.150.128", 9200, "http")));}}6.3创建索引库
@Testvoid createIndex() throws IOException {//1.创建Request对象CreateIndexRequest request = new CreateIndexRequest("demo");//2.准备请求的参数:DSL语句request.source(HOTEL_CONSTANT, XContentType.JSON);//3.发送请求client.indices().create(request, RequestOptions.DEFAULT);}6.4删除索引库
@Testvoid deleteIndex() throws IOException {DeleteIndexRequest request = new DeleteIndexRequest("demo");client.indices().delete(request, RequestOptions.DEFAULT);}6.5获取索引库
@Testvoid getIndex() throws IOException {GetIndexRequest request = new GetIndexRequest("demo");boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);log.info(exists ? "exists" : "not exists");}
七、使用RestClient操作文档数据
7.1向索引库中添加文档数据
@Testvoid testAddDocument() throws IOException {//准备数据,数据来源于数据库Hotel hotel = hotelService.getById(36934L);//转换为文档类型HotelDoc hotelDoc = new HotelDoc(hotel);//1.准备Request对象IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());//2.准备JSON数据request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);//3.发送请求client.index(request, RequestOptions.DEFAULT);}
7.2获取文档对象并解析转换为实体对象
@Testvoid testGetDocument() throws IOException {//准备Request对象GetRequest hotel = new GetRequest("hotel", "36934");//发送请求得到结果GetResponse response = client.get(hotel, RequestOptions.DEFAULT);//解析结果String source = response.getSourceAsString();//反序列化的hotel对象HotelDoc hotelDoc = JSON.parseObject(source, HotelDoc.class);log.info(hotelDoc.toString());}7.3更新文档对象数据
@Testvoid testUpdateDocument() throws IOException {//准备Request对象UpdateRequest request = new UpdateRequest("hotel", "36934");//准备请求参数request.doc("price", "99");//发送请求client.update(request, RequestOptions.DEFAULT);}7.4删除文档对象
@Testvoid testDeleteDocument() throws IOException {DeleteRequest request = new DeleteRequest("hotel", "36934");client.delete(request, RequestOptions.DEFAULT);}7.5实现批量插入文档对象
@Testvoid testBulk() throws IOException {//查询所有酒店数据List<Hotel> hotels = hotelService.list();//创建request对象BulkRequest bulkRequest = new BulkRequest();//将hotel对象转换为hotelDoc对象for (Hotel hotel : hotels) {HotelDoc hotelDoc = new HotelDoc(hotel);bulkRequest.add(new IndexRequest("hotel").id(hotelDoc.getId().toString()).source(JSON.toJSONString(hotelDoc), XContentType.JSON));}//发送请求信息client.bulk(bulkRequest, RequestOptions.DEFAULT);}相关文章:
ElasticSearch基础篇——概念讲解,部署搭建,使用RestClient操作索引库和文档数据
目录 一、概念介绍 二、Elasticsearch的Docker容器安装 2.1拉取elasticsearch的镜像文件 2.2运行docker命令启动容器 2.3通过访问端口地址查看部署情况 三、安装Kibana容器 3.1拉取Kibana镜像容器指令(默认拉取最新版本): 3.2拉取完…...
k8s 二进制部署安装(一)
目录 环境准备 初始化操作系统 部署docker 引擎 部署 etcd 集群 准备签发证书环境 部署 Master01 服务器相关组件 apiserver scheduler controller-manager.sh admin etcd 存储了 Kubernetes 集群的所有配置数据和状态信息,包括资源对象、集群配置、元数据…...
115页PPT华为管理变革:制度创新与文化塑造的核心实践
集成供应链(ISC)体系 集成供应链(ISC)体系是英文Integrated Supply Chain的缩写,是一种先进的管理思想,它指的是由相互间提供原材料、零部件、产品和服务的供应商、合作商、制造商、分销商、零售商、顾客等…...

ubuntu限制网速方法
sudo apt-get install trickle sudo trickle -d <下载速度> -u <上传速度> <命令>例如git clone sudo trickle -d 1024 git clone http://xxxxxxxxxx.git如果想简化指令可以在bashrc中添加如下指令 alias gitttrickle -u 1024 gitgitt为自定义 使用方法&am…...

三品PLM研发管理系统:企业产品研发过程的得力助手
三品PLM系统:全方位赋能企业产品生命周期管理的优选方案 在当今竞争激烈的市场环境中,产品生命周期管理PLM系统已成为企业实现高效、灵活和创新产品开发的关键工具。PLM系统集成了信息技术、先进管理思想与企业业务流程,旨在帮助企业优化产品…...
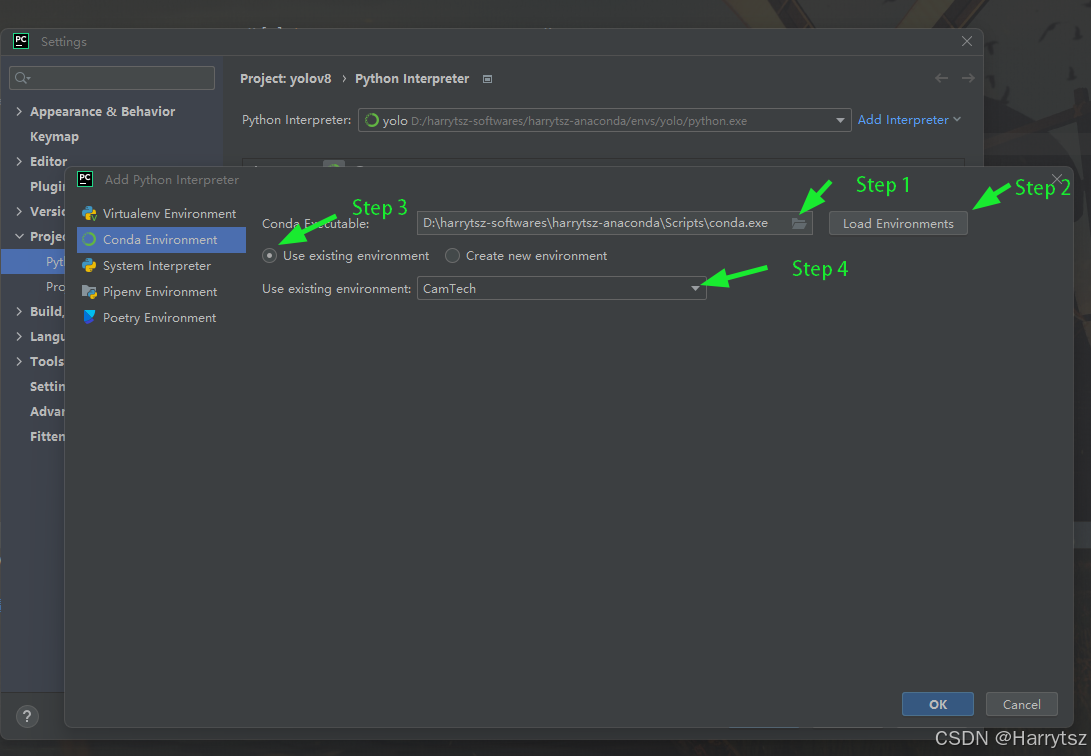
PyCharm 添加不了 Anaconda 环境
经常会遇到 PyCharm 无法添加新创建的 Anaconda 环境, Setting --> Python Interpreter --> Add Python Interperter --> Conda Environment 中为空,即使打开右侧文件夹路径按钮,选择新创建的 conda 环境,也无法找到 pyt…...

Leetcode 二叉树的右视图
好的,我来用中文详细解释这段代码的算法思想。 问题描述 题目要求给定一个二叉树的根节点,从树的右侧看过去,按从上到下的顺序返回看到的节点值。即,我们需要找到每一层的最右侧节点并将其加入结果中。 算法思想 这道题可以通…...

console.log(“res.data = “ + JSON.stringify(res.data));
res.data[object Object] 说明你在控制台打印 res.data 时,它是一个 JavaScript 对象,而不是字符串。这种情况下,console.log 输出的 [object Object] 表示它无法直接显示对象的内容。 要查看 res.data 的实际内容,你需要将其转换…...

node和npm
背景(js) 1、为什么js能操作DOM和BOM? 原因:每个浏览器都内置了DOM、BOM这样的API函数 2、浏览器中的js运行环境? v8引擎:负责解析和执行js代码 内置API:由运行环境提供的特殊接口,只能在所…...

通过四元数求机器人本体坐标旋转量
是的,通过两次姿态数据(以四元数表示)的差值,可以确定机器人在两个时刻之间的旋转角度变化。具体步骤如下: 获取四元数:假设两个时刻的四元数分别为 ( q_1 ) 和 ( q_2 )。计算四元数的差值: 将…...
-QL语法(递归))
CodeQL学习笔记(2)-QL语法(递归)
最近在学习CodeQL,对于CodeQL就不介绍了,目前网上一搜一大把。本系列是学习CodeQL的个人学习笔记,根据个人知识库笔记修改整理而来的,分享出来共同学习。个人觉得QL的语法比较反人类,至少与目前主流的这些OOP语言相比&…...

Video-XL:面向小时级视频理解的超长视觉语言模型
在人工智能领域,视频理解一直是一个挑战性的任务,尤其是对于长时间视频内容的理解。现在,Video-XL的问世标志着我们在这一领域迈出了重要的一步。Video-XL是一个专为小时级视频理解设计的超长视觉语言模型,它能够处理超长视频序列…...
postgresql subtransaction以及他的效能
文章目录 什么是subtransaction使用子事务PL/pgSQL 中的子事务与其他数据库的兼容性运行性能测试Subtransaction的实现子事务和可见性解释测试结果诊断子事务过多的问题结论 什么是subtransaction 在 PostgreSQL 中,当处于自动提交模式时,必须使用 BEGI…...

新手逆向实战三部曲之二——通过更改关键跳注册软件(爆破)
教程开始: 软件已无壳,具体脱壳请移步"新手逆向实战三部曲之一",这里略去查壳脱壳。 先用OD打开软件试运行了解下注册流程,以便找到突破口 经过对软件的了解,本次教程采用的是下bp MessageBoxA断点的方法找…...

高级SQL技巧:提升数据查询与分析能力的关键
高级SQL技巧:提升数据查询与分析能力的关键 在数据驱动的时代,SQL(结构化查询语言)是数据分析和数据库管理的基础工具。掌握高级SQL技巧不仅能提高查询效率,还能优化数据库结构,使数据分析和报告更加精准高…...

IntelliJ IDEA 安装 Maven 工具并更换阿里源
Maven是一个强大的项目管理工具,可以帮助Java开发者管理项目依赖、构建项目等。在IntelliJ IDEA中安装Maven工具并将其源更改为阿里源的步骤如下: 1. 安装 Maven 通过 IntelliJ IDEA 自带 Maven 打开 IntelliJ IDEA。创建或打开一个项目。点击菜单栏中…...

MIT 6.824 Lab1记录
MapReduce论文阅读 1. 编程模型 Map 函数(kv -> kv) Map 函数将输入的键值对处理为一系列中间值(键值对),并将所有的中间结果传递给 Reduce 处理。 map(String key, String value):// key: document name// val…...

C语言数据结构学习:[汇总]
介绍 这些是我在学习C语言数据结构时练习的一些题目以及个人笔记 大家也可以参考着来学习 正在更新 大家可以在我的gitee仓库 中下载笔记源文件 笔记源文件可以在Notion中导入 内容导航 C语言数据结构学习:单链表-CSDN博客...
unity游戏开发之塔防游戏
如何制作塔防游戏 让我们以迷你游戏的形式创建一个休闲塔防。 从基本处理到适用技术,应有尽有,因此您只需制作一次即可获得 Unity 中的游戏制作专业知识。 与背景素材结合使用时,您将获得以下游戏视图: 由于在创建过程中使用了 …...

前端项目接入sqlite轻量级数据库sql.js指南
前端项目接入sqlite轻量级数据库sql.js指南 引言 sql.js 是一个强大的JavaScript库,它使得SQLite数据库能够在网页浏览器中运行。这个开源项目提供了一种方式,让开发者可以在前端环境中实现轻量级的数据库操作,无需依赖服务器端数据存储&…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

LeetCode - 394. 字符串解码
题目 394. 字符串解码 - 力扣(LeetCode) 思路 使用两个栈:一个存储重复次数,一个存储字符串 遍历输入字符串: 数字处理:遇到数字时,累积计算重复次数左括号处理:保存当前状态&a…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

leetcodeSQL解题:3564. 季节性销售分析
leetcodeSQL解题:3564. 季节性销售分析 题目: 表:sales ---------------------- | Column Name | Type | ---------------------- | sale_id | int | | product_id | int | | sale_date | date | | quantity | int | | price | decimal | -…...

前端开发面试题总结-JavaScript篇(一)
文章目录 JavaScript高频问答一、作用域与闭包1.什么是闭包(Closure)?闭包有什么应用场景和潜在问题?2.解释 JavaScript 的作用域链(Scope Chain) 二、原型与继承3.原型链是什么?如何实现继承&a…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...

云原生玩法三问:构建自定义开发环境
云原生玩法三问:构建自定义开发环境 引言 临时运维一个古董项目,无文档,无环境,无交接人,俗称三无。 运行设备的环境老,本地环境版本高,ssh不过去。正好最近对 腾讯出品的云原生 cnb 感兴趣&…...

C++使用 new 来创建动态数组
问题: 不能使用变量定义数组大小 原因: 这是因为数组在内存中是连续存储的,编译器需要在编译阶段就确定数组的大小,以便正确地分配内存空间。如果允许使用变量来定义数组的大小,那么编译器就无法在编译时确定数组的大…...

Docker 本地安装 mysql 数据库
Docker: Accelerated Container Application Development 下载对应操作系统版本的 docker ;并安装。 基础操作不再赘述。 打开 macOS 终端,开始 docker 安装mysql之旅 第一步 docker search mysql 》〉docker search mysql NAME DE…...