[mysql]聚合函数GROUP BY和HAVING的使用和sql查询语句的底层执行逻辑
#GROUP BY的使用
还是先从需求出发,我们现在想求员工表里各个部门的平均工资,最高工资
SELECT department_id,AVG(salary)
FROM employees
GROUP BY department_id

我们就会知道它会把一样的id分组,没有部门的就会分为一组,我们也可以用其他字段来分组,我们想查询不同jb_id的平均工资
SELECT job_id,AVG(salary)
FROM employees
GROUP BY job_id

那这个大家就了解了,还是比较容易理解的
现在我们要使用多个列分组比如我们要计算不同部门的不同工种的平均工资,也就是用job_id和department_id的平均工资
SELECT job_id,department_id,AVG(salary)
FROM employees
GROUP BY department_id, job_id

我们现在想先用job_id先分组,然后再对departmentid分组
这两个是一样的吗.答案是一样的,比如我们先把一个部门给分类,在把一个工种分类,和先把工种分类再把部门分类这个明显是相同的

刚才我们计算的时候,没有加部门和工种,字段,是为了我们的可读性来给它加上了字段,我们能不能在group,by里去掉工种只按照部门分工种

现在mysql最新版已经不支持这个写法了,因为我们用group by只对工种进行分组了,但是剩下的部门没有分,那不就没有位置放部门了
GROUP BY的结论1
我们除了聚合函数的字段,一定要出现在GROUP BY中,但是GROUPBY的字段不一定要出现在查询字段中.
GROUP BY的位置
GROUP BY必须在FROM 和WHERE的后面ORDER BY的前面和LIMIT的前面
GROUP BY的结论3新特性
Mysql中的GROUP BY的WITH ROLLUP
我们在GROUP 字段 WITH ROLLUP

现在我们是不是可以发现最后多了一行,这个数字实际上是公司的平均工资,
我们这里要小心的使用ORDER BY和 WITH ROLLUP 我们不加的话是可以进行运行,但是加入之后就会报错,这是错误的方式,但是mysql最新版已经支持这么做了.


我们要是出现分组了大家就应该注意到是我们要对字段进行相同值分组的时候进行.
HAVING TO的使用
我们现在多了一个HAVING TO
现在我们想查询各个部门中最高工资比10000高的部门信息.
相当于我们想查询各个部门中最高工资

要求1
SELECT后面出现的非聚合函数字段,一定要出现在GROUP BY后面
还有一件事,我们如果字段出现非聚合函数,一定要出现在GROUPBY中,这个大家一定要牢记,那么现在我们发现查询出来的结果有很多是没有超过10000的,和我们的要求不一致,比10000小的我们就不要,我们以前是只讲过WHERE 而且它必须跟在FROM后面,那么我们现在写WHERE MAX(salary)>10000,

要求2
一旦我们的过滤条件中使用的聚合函数,那么我们就必须要使用HAVING TO来替换WHERE 否则就会报错.
现在我们出现了聚合函数,或者说组函数了,我们来写一个正确的写法
不管我们学那个语言我们实际上是有很多规则的,+表示加和连接,这是规范和规则出现的,直接背就好了,就和叫爸爸叫妈妈,一样没有小孩会想为什么要这么叫,下面的东西就可以考虑深层次的原因,后面的东西我们都是可以解释的,也就是一会我们会说HAVING TO 为什么不能用WHERE,
我们把HAVING换进去,发现还是报错了,

要求2:我们要把HAVING TO 放在GROUP BY的后面
他的声明位置必须在GROUP BY的后面,写在前面了自然就错误了
这就是我们正确的情况
要求3
要是没有GROUP BY能不能使用HAVING TO 函数,发现我们是可以使用的,因为我们没有聚合函数了,我们使用的时候,最后聚合函数的结果是不是没有必要去过滤它了.我们用WHERE筛选之后,再用聚合函数之后再用HAVING就没有什么意义了

所以HAVING 要和GROUPBY一起合并使用.
现在我们要查询部门ID为10,20,30,40,4个部门最高工资比10000高的部门信息
这里前面也是一个过滤条件,我们能不能用WHERE来写,这是方式1
SELECT department_id,MAX(salary)
FROM employees
WHERE department_id IN (10,20,30,40)
GROUP BY department_id
HAVING MAX(salary)>10000

我们还能把条件写在WHERE
SELECT department_id,MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary)>10000 AND department_id IN (10,20,30,40)

那么大家就会纳闷了,那么大家应该就有一个疑惑了,WHERE和HAVING有什么区别呢.
大家可以逆向思维.存在就是合理的,WHERE 里面是不能加聚合函数,那我们直接用HAVING不就好了,我们这里就会推荐大家使用方式1,因为方式1的执行效率比方式2高,,
当过滤条件中有聚合函数时间,这个过滤条件必须声明在HAVING中,没有聚合函数时,此过滤条件声明在WHERE中和HAVING都可以,建议大家声明在WHERE中
这不是同情,因为WHERE的效率高,虽然是建议,大家还是直接当成规则用了.
WHERE和HAVING的对比1从适用范围来讲HAVING的适用范围更广,HAVING可以完成聚合函数的过滤
2如果过滤函数里没有聚合函数,这种情况WHERE效率高于HAVING,开发中选择
,子查询是一个查询中套了一个查询,基本的知识点我们已经讲到,子查询只是在结构里嵌套另一个结构,所以我们可以直接开始讲SELECT 语句的结构了
SELECT语句的完整结构:
sql92语法
SELECT (含有聚合函数)
FROM 表1,表2,表3
WHERE 多表的连接条件 AND 过滤条件,不包含聚合函数
GROUP BY 分组操作,….
HAVING 包含聚合函数的过滤条件
ORDER BY
LIMIT
sql99语法
SELECT ……(含有聚合函数)
FROM 表1 (left/right)JOIN
ON 表2
(left/right)JOIN
ON表2
WHERE 不包含 聚合函数的过滤条件
GROUP BY
HAVING
ORDER BY
LIMIT
SQL语句的执行过程
第一部分
SELECT ……(含有聚合函数)
第二部分
FROM 表1 (left/right)JOIN
ON 表2
(left/right)JOIN
ON表2
WHERE 不包含 聚合函数的过滤条件
GROUP BY
HAVING
第三部分
ORDER BY
LIMIT
正常情况我们以为是按顺序运行的,实际上我们的是先执行的第二部分,然后第一部分最后第三部分.
上来我们先FROM 表1 (left/right)JOIN
ON 表2
(left/right)JOIN
ON表2
WHERE 不包含 聚合函数的过滤条件
GROUP BY
HAVING
如下
FROM ->ON->(left/right)JOIN->WHERE->GROUP->HAVING ->SELECT->DISTINCT->ORDER BY->LIMIT
我们先找到一张表连接另一张表,进行笛卡尔交叉的连接,然后用ON来把不关联的去掉了,限制了连接的条件,这是在后台的虚拟表,每执行一步就变化一步,过滤了之后,由于可能是左外和右外的连接,,虚拟表也会进行保留,然后进行WHERE条件的过滤,保留需要的内容,然后对其中内容进行分组,分组之后我们再进行HAVING聚合函数的条件筛选,然后看看SELECT想要的是那几个字段,因为字段是全部保留之前虚拟表里,用SELECT筛选出我们要的字段,,因为这里面还有可能有DISTINCT去重的操作,再过滤一小部分,确定了最后的数据,对数据进行排序,和分页的操作
现在我们就可以解释为什么where比HAVING的数据效率高了,因为我们分组之前可能10万条数据,我们对它进行筛选了只剩下10条,然后我们分组,那是不是很简单,如果我们用的是HAVING那么就吭哧吭哧对它进行10万条分组,,最后HAVING说只要最后2个条件,那前面8万条都浪费操作了,
为什么WHERE 不能放聚合条件呢,因为我们还没分组,聚合条件根本用不了,你只能前向引用,HAVING可以向分组的GROUPBY进行计算函数,但是 WHERE不能向未来运行GROUPBY进行前向引用,这里就解释完了,
我们在SELECT中查询一个字段我们可以在ORDERBY里使用别名,但是不能再WHERE里使用,也是因为这个原因
每个过程中都会形成一个虚拟表,这就是一个执行过程,是不是感觉挺高端的,之后我们还会讲更多SQL的底层逻辑我们才能将SQL的优化问题.得知道粮食里的结构才能养生,我们要能辨别知识的结构.我们就得有一个完善的体系架构
相关文章:
[mysql]聚合函数GROUP BY和HAVING的使用和sql查询语句的底层执行逻辑
#GROUP BY的使用 还是先从需求出发,我们现在想求员工表里各个部门的平均工资,最高工资 SELECT department_id,AVG(salary) FROM employees GROUP BY department_id 我们就会知道它会把一样的id分组,没有部门的就会分为一组,我们也可以用其他字段来分组,我们想查询不同jb_id…...

从数据中台到数据飞轮:实现数据驱动的升级之路
从数据中台到数据飞轮:实现数据驱动的升级之路 随着数字化转型的推进,数据已经成为企业最重要的资产之一,企业普遍搭建了数据中台,用于整合、管理和共享数据;然而,近年来,数据中台的风潮逐渐减退…...

小记:SpringBoot中,@Alisa和@ApiModelProperty的区别
在 Spring Boot 中,Alias和ApiModelProperty 这两个注解用于不同的目的。 Alias Alias是一个用于定义别名的注解,通常用于 Bean 属性的别名功能,这样在使用某些框架(如 JPA 或 Jackson)时,可以将一个属性名…...

信捷 PLC C语言 定时器在FC中的使用
传统梯形图的定时器程序写起来简单,本文用C语言写定时器的使用。 定时器在c语言中使用,和普通梯形图中使用的区别之一是既有外部条件,也有内部条件。 1.建全局变量 2.建立FC POU 这个是功能POU程序。 这里的Enable是内部条件 3.调用包含定…...

k8s常用对象简介
Pod Pod 是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元。 Pod 是一组(一个或多个) 容器; 这些容器共享存储、网络、以及怎样运行这些容器的声明。 Pod 中的内容总是并置(colocated)的并且一同调度&…...

【Kaggle | Pandas】练习2:索引,选择和分配
文章目录 数据总表1、读取列2、读取某列的第几行的值3、第一行数据4、读取列中前10个值5、读取索引标签为1 、 2 、 3 、 5和8的记录6、包含索引标签为0 、1 、10和100的记录的country 、province 、 region_1和region_2列7、 前 100 条记录的country和variety列8、包含Italy葡…...

【flask】 flask redis的使用
目的:如何使用在flask web项目中连接redis,并简单的使用 使用的库包:flask-redis pip install falsk-redis下面的写法是对项目代码进行模块化拆分的写法,在app.py中只进行对象的初始化等操作;exts.py中创建对象&…...

【Unity基础】Unity中的特殊文件夹详解
在Unity项目中,通常可以根据需要创建任意名称的文件夹来组织项目内容,但有一些特定的文件夹名称会触发Unity对其中资源和脚本的特殊处理。这篇文章将详细介绍这些特殊文件夹,帮助开发者在项目中合理地使用它们。 1. Assets 文件夹 Assets文…...

矩阵蠕虫,陈欣出品
第一章 陈欣是一名资深的软件工程师,专门从事分布式系统和人工智能的研究。她的最新项目叫做“MatrixWorm”,目标是创建一个简单而强大的远程控制系统。在这个系统中,控制端可以通过文字命令,让被控制端利用大语言模型的能力来理…...

python 爬虫 入门 五、抓取图片、视频
目录 一、图片、音频 二、下载视频: 一、图片、音频 抓取图片的手法在上一篇python 爬虫 入门 四、线程,进程,协程-CSDN博客里面其实有,就是文章中的图片部分,在那一篇文章,初始代码的28,29行…...

ubantu 编译安装ceph 18.2.4
下载ceph代码 git clone https://github.com/ceph/ceph.git #切换tag git checkout v18.2.4 -b v18.2.4 #下载子模块 会有报错重新执行即可 git submodule update --init --recursive安装ceph所需要的依赖 #curl命令安装 sudo apt install curl#安装ceph依赖 ./install-deps.…...

哈希封装“unordered_set·map“
本文与对setmap的封装高度相似,可以参考我之前的对setmap封装的文章: 链接:(没看过的话就点点我吧😚😚😚😚😚😚😚😚😚&am…...

Bi-LSTM-CRF实现中文命名实体识别工具(TensorFlow)
项目源码获取方式见文章末尾! 回复暗号:13,免费获取600多个深度学习项目资料,快来加入社群一起学习吧。 **《------往期经典推荐------》**项目名称 1.【MobileNetV2实现实时口罩检测tensorflow】 2.【卫星图像道路检测DeepLabV3P…...

从JDK 17 到 JDK 21:Java 新特性
JDK17 密封类 概念:密封类允许开发者控制哪些类可以继承或实现特定的类或接口。通过这种方式,密封类为类的继承提供了更高的安全性和可维护性。 定义:使用sealed代表该类为密封类,并用permits限制哪些类可以继承。 public sea…...

【计算机网络 - 基础问题】每日 3 题(五十七)
✍个人博客:https://blog.csdn.net/Newin2020?typeblog 📣专栏地址:http://t.csdnimg.cn/fYaBd 📚专栏简介:在这个专栏中,我将会分享 C 面试中常见的面试题给大家~ ❤️如果有收获的话,欢迎点赞…...

第十二章 章节练习created的应用
目录 一、引言 二、运行效果图 三、完整代码 一、引言 构建一个新闻的页面,页面在响应式数据准备好之后(即created),就向后台接口请求获取新闻数据列表,然后赋值给Vue实例中的list列表,这个请求逻辑我…...

Unity 游戏性能优化实践:内存管理与帧率提升技巧
1. 引言 随着移动设备性能的逐步提升,游戏玩家对画质和流畅度的要求越来越高。优化 Unity 游戏性能不仅可以提升用户体验,还能降低设备的功耗,延长电池寿命。这篇文章将深入探讨如何在 Unity 中优化游戏的内存管理与帧率,通过多方…...

C++游戏开发详解
C 是一种广泛使用的编程语言,尤其在游戏开发领域有着不可替代的地位。它提供了对底层硬件的直接访问能力,允许开发者优化性能,这对于追求高帧率和低延迟的游戏来说至关重要。本文将详细介绍使用 C 进行游戏开发的基础知识和技术要点ÿ…...
微调面)
三、大模型(LLMs)微调面
本文精心汇总了多家顶尖互联网公司在大模型基础知识考核中的核心考点,并针对这些考点提供了详尽的解答。并提供电子版本,见于文末百度云盘链接中,供读者查阅。 一、大模型微调 • 1 如果想要在某个模型基础上做全参数微调,究竟需要…...

Flutter升级与降级
升级 版本升级 // 升级到指定版本flutter upgrade 版本号// 升级到最新版本flutter upgrade 降级 1.需要先确定想要降级的版本号。 2.切换到系统安装Flutter的目录 3.在https://github.com/flutter/flutter,找到要回退的版本号对应的commit序号(具…...
。】2022-5-15)
【根据当天日期输出明天的日期(需对闰年做判定)。】2022-5-15
缘由根据当天日期输出明天的日期(需对闰年做判定)。日期类型结构体如下: struct data{ int year; int month; int day;};-编程语言-CSDN问答 struct mdata{ int year; int month; int day; }mdata; int 天数(int year, int month) {switch (month){case 1: case 3:…...
)
React Native 开发环境搭建(全平台详解)
React Native 开发环境搭建(全平台详解) 在开始使用 React Native 开发移动应用之前,正确设置开发环境是至关重要的一步。本文将为你提供一份全面的指南,涵盖 macOS 和 Windows 平台的配置步骤,如何在 Android 和 iOS…...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

STM32标准库-DMA直接存储器存取
文章目录 一、DMA1.1简介1.2存储器映像1.3DMA框图1.4DMA基本结构1.5DMA请求1.6数据宽度与对齐1.7数据转运DMA1.8ADC扫描模式DMA 二、数据转运DMA2.1接线图2.2代码2.3相关API 一、DMA 1.1简介 DMA(Direct Memory Access)直接存储器存取 DMA可以提供外设…...

Kafka入门-生产者
生产者 生产者发送流程: 延迟时间为0ms时,也就意味着每当有数据就会直接发送 异步发送API 异步发送和同步发送的不同在于:异步发送不需要等待结果,同步发送必须等待结果才能进行下一步发送。 普通异步发送 首先导入所需的k…...
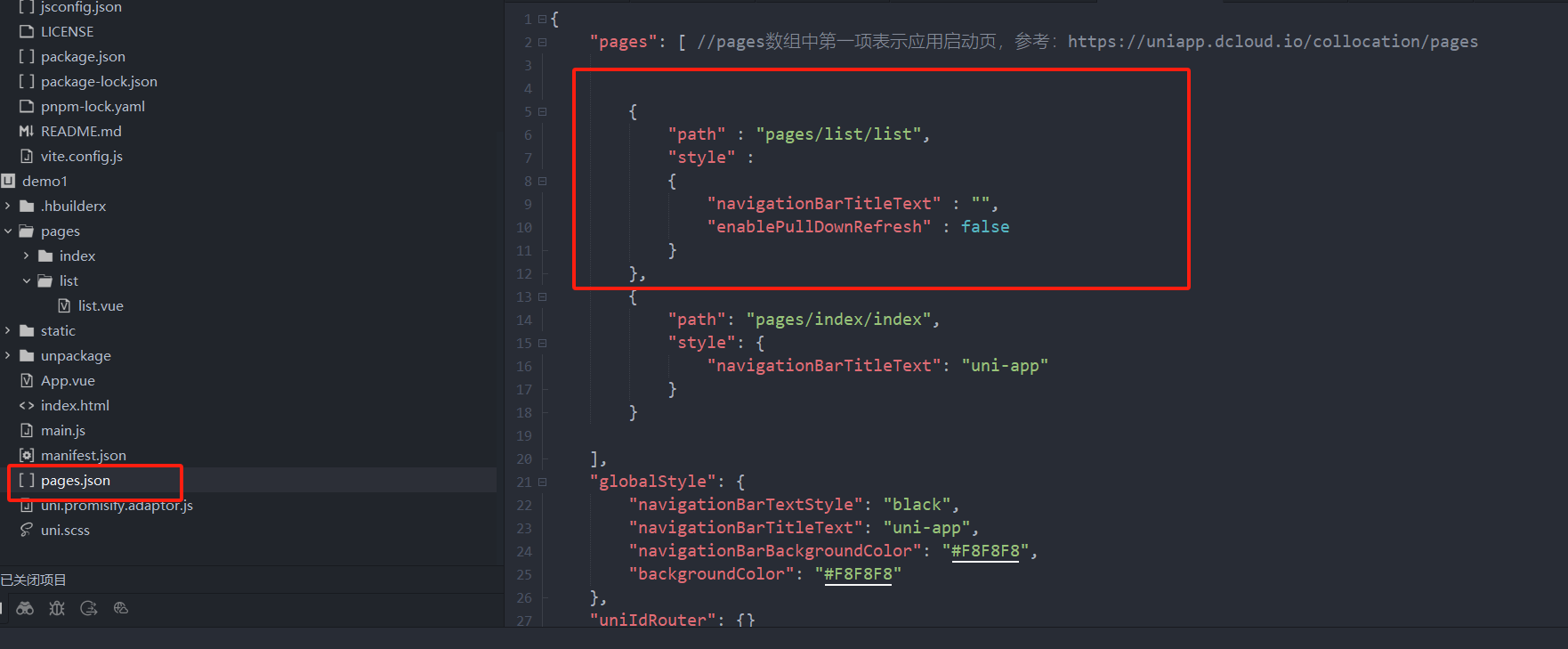
uniapp 小程序 学习(一)
利用Hbuilder 创建项目 运行到内置浏览器看效果 下载微信小程序 安装到Hbuilder 下载地址 :开发者工具默认安装 设置服务端口号 在Hbuilder中设置微信小程序 配置 找到运行设置,将微信开发者工具放入到Hbuilder中, 打开后出现 如下 bug 解…...
:工厂方法模式、单例模式和生成器模式)
上位机开发过程中的设计模式体会(1):工厂方法模式、单例模式和生成器模式
简介 在我的 QT/C 开发工作中,合理运用设计模式极大地提高了代码的可维护性和可扩展性。本文将分享我在实际项目中应用的三种创造型模式:工厂方法模式、单例模式和生成器模式。 1. 工厂模式 (Factory Pattern) 应用场景 在我的 QT 项目中曾经有一个需…...
uni-app学习笔记三十五--扩展组件的安装和使用
由于内置组件不能满足日常开发需要,uniapp官方也提供了众多的扩展组件供我们使用。由于不是内置组件,需要安装才能使用。 一、安装扩展插件 安装方法: 1.访问uniapp官方文档组件部分:组件使用的入门教程 | uni-app官网 点击左侧…...

车载诊断架构 --- ZEVonUDS(J1979-3)简介第一篇
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 做到欲望极简,了解自己的真实欲望,不受外在潮流的影响,不盲从,不跟风。把自己的精力全部用在自己。一是去掉多余,凡事找规律,基础是诚信;二是…...

(12)-Fiddler抓包-Fiddler设置IOS手机抓包
1.简介 Fiddler不但能截获各种浏览器发出的 HTTP 请求,也可以截获各种智能手机发出的HTTP/ HTTPS 请求。 Fiddler 能捕获Android 和 Windows Phone 等设备发出的 HTTP/HTTPS 请求。同理也可以截获iOS设备发出的请求,比如 iPhone、iPad 和 MacBook 等苹…...