MLM之Emu3:Emu3(仅需下一个Token预测)的简介、安装和使用方法、案例应用之详细攻略
MLM之Emu3:Emu3(仅需下一个Token预测)的简介、安装和使用方法、案例应用之详细攻略
导读:这篇论文介绍了Emu3,一个基于单一Transformer架构,仅使用下一个token预测进行训练的多模态模型。
>> 背景痛点:
多模态任务的瓶颈: 现有的多模态模型在生成和感知任务上,主要依赖于复杂的扩散模型(如Stable Diffusion)或组合方法(如CLIP结合LLM),这些方法通常结构复杂,难以扩展。 下一个token预测方法虽然在语言模型领域取得了巨大成功,但在多模态领域应用有限,难以达到与特定任务模型相当的性能。
>> 具体的解决方案:Emu3是一个全新的多模态模型套件,它完全摒弃了扩散模型和组合方法,仅依靠下一个token预测进行训练。 通过将图像、文本和视频标记到一个离散空间,Emu3在一个单一的Transformer解码器中进行端到端训练。
>> 核心思路步骤:
● 数据标记化: 将图像、文本和视频数据标记成离散的token。 这需要一个强大的视觉标记器,论文中使用了基于SBER-MoVQGAN的视觉标记器,能够将图像和视频压缩成离散的token。
● 多模态数据融合: 将文本token和视觉token融合成文档式的输入,用于训练Transformer模型。 使用了特殊的token来区分不同模态的数据。
● 下一个token预测: 使用标准的交叉熵损失函数进行下一个token预测训练。 为了避免视觉token主导训练过程,视觉token的损失权重设置为0.5。
● 预训练: 分两个阶段进行预训练。第一阶段使用文本和图像数据,第二阶段加入视频数据。 使用了张量并行、上下文并行和数据并行等技术来加速训练。
● 后训练: 针对图像生成和视觉语言理解任务进行后训练。 图像生成使用了质量微调 (QFT) 和直接偏好优化 (DPO) 来提升生成质量和与人类偏好的对齐程度。 视觉语言理解则分两个阶段进行,先进行图像到文本的训练,再进行指令微调。
>> 优势:
● 模型简洁: 采用单一Transformer架构,结构简洁,易于扩展。
● 性能优越: 在图像生成、视觉语言理解和视频生成等多个任务上,Emu3的性能超过了多个已有的特定任务模型和旗舰级模型,如SDXL和LLaVA-1.6。
● 无需预训练模型: 图像生成和视觉语言理解无需依赖预训练的CLIP和LLM。
● 支持视频生成和扩展: 能够生成高质量的视频,并能通过预测下一个token来扩展视频,预测未来的场景。
● 开源关键技术和模型: 开源了视觉标记器等关键技术和模型,方便后续研究。
>> 结论和观点:
● 下一个token预测的有效性: 论文证明了仅使用下一个token预测就能训练出在多模态任务上达到最先进性能的模型,这为构建通用的多模态智能提供了一种新的范式。
● 模型简洁性的重要性: 简化模型设计,专注于token,可以提高模型的可扩展性和训练效率。
● 多模态智能的未来方向: 下一个token预测是构建通用多模态智能的有前景的途径,这将推动人工智能领域进一步发展。
总而言之,Emu3 通过简洁的模型架构和强大的训练方法,在多模态任务上取得了突破性进展,为未来多模态模型的研究和应用提供了新的思路。 其开源的特性也为社区的进一步研究和发展提供了重要的支持。
目录
Emu3的简介
1、特点
2、每个模块的内容
Emu3的装和使用方法
1、克隆仓库并安装依赖
2、下载模型权重
3、使用Hugging Face Transformers进行推理:
图像生成 (Emu3-Gen/Stage1)
视觉语言理解 (Emu3-Chat)
视觉编码解码 (Emu3-VisionTokenizer)
Emu3的案例应用
Emu3的简介

Emu3是由BAAI(北京人工智能研究院)的Emu团队在2024年9月27日发布的一系列最先进的多模态模型。该模型的核心创新在于它仅仅使用下一个Token预测进行训练,无需依赖扩散模型或组合式架构。通过将图像、文本和视频标记到离散空间,Emu3在一个单一的Transformer模型中处理各种多模态序列。 Emu3在生成和感知任务上都表现出色,超过了SDXL、LLaVA-1.6和OpenSora-1.2等旗舰级开源模型。
总而言之,Emu3是一个很有潜力的多模态模型,其基于下一个Token预测的训练方法和单一Transformer架构非常具有创新性。 虽然项目目前尚不完整,但提供的示例代码已经展示了其强大的能力,值得关注其未来的发展。
GitHub地址:GitHub - baaivision/Emu3: Next-Token Prediction is All You Need
论文地址:https://arxiv.org/abs/2409.18869
1、特点
>> 基于下一个Token预测: Emu3的训练完全依赖于下一个Token预测,这与许多依赖扩散模型或其他复杂架构的多模态模型形成对比。
>> 单一Transformer架构: 使用单一的Transformer模型处理图像、文本和视频等多种模态数据,简化了模型结构。
>> 高性能: 在图像生成、视觉语言理解和视频生成等任务上,Emu3的性能超过了多个已建立的特定任务模型以及一些旗舰级开源模型。
>> 灵活的图像生成: 能够根据文本输入生成高质量的图像,自然支持灵活的分辨率和风格。
>> 强大的视觉语言理解能力: 无需依赖CLIP和预训练的LLM,就能实现强大的视觉语言理解能力。
>> 因果视频生成: 能够通过预测视频序列中的下一个Token来生成视频,不同于Sora等视频扩散模型。
>> 视频扩展预测: 在给定视频上下文的情况下,可以自然地扩展视频并预测接下来会发生什么。
2、每个模块的内容
assets: 包含示例图像和视频等资源文件。
emu3: 核心模型代码。
replicate_demo: 用于复现演示的代码。
scripts: 训练脚本 (目前仅提供部分)。
autoencode.py: 图像和视频自动编码的代码。
gradio_demo.py: Gradio演示的代码 (目前似乎缺失)。
image_generation.py: 图像生成的代码。
multimodal_understanding.py: 多模态理解的代码。
需要注意的是,该项目目前仍处于开发阶段,一些模块的代码尚未发布,例如推理代码、评估代码以及部分训练脚本。
Emu3的装和使用方法
1、克隆仓库并安装依赖
git clone https://github.com/baaivision/Emu3
cd Emu3pip install -r requirements.txt2、下载模型权重
Emu3 提供了多个预训练模型,包括 Emu3-Stage1(图像预训练模型)、Emu3-Chat(视觉语言理解模型)和 Emu3-Gen(图像生成模型),以及 Emu3-VisionTokenizer(视觉标记器)。这些模型的权重可以在 Hugging Face、ModelScope 和 WiseModel 上获取 (链接在GitHub页面上提供,但此处未列出具体链接)。
3、使用Hugging Face Transformers进行推理:
该项目提供了使用Hugging Face Transformers库进行推理的示例代码,分别演示了图像生成、视觉语言理解和视觉编码解码三个任务:
图像生成 (Emu3-Gen/Stage1)
代码展示了如何使用 Emu3-Gen 或 Emu3-Stage1 模型根据文本提示生成图像。 代码中使用了 Classifier Free Guidance,并支持负向提示词来控制生成结果。
from PIL import Image
from transformers import AutoTokenizer, AutoModel, AutoImageProcessor, AutoModelForCausalLM
from transformers.generation.configuration_utils import GenerationConfig
from transformers.generation import LogitsProcessorList, PrefixConstrainedLogitsProcessor, UnbatchedClassifierFreeGuidanceLogitsProcessor
import torchfrom emu3.mllm.processing_emu3 import Emu3Processor# model path
EMU_HUB = "BAAI/Emu3-Gen"
VQ_HUB = "BAAI/Emu3-VisionTokenizer"# prepare model and processor
model = AutoModelForCausalLM.from_pretrained(EMU_HUB,device_map="cuda:0",torch_dtype=torch.bfloat16,attn_implementation="flash_attention_2",trust_remote_code=True,
)tokenizer = AutoTokenizer.from_pretrained(EMU_HUB, trust_remote_code=True, padding_side="left")
image_processor = AutoImageProcessor.from_pretrained(VQ_HUB, trust_remote_code=True)
image_tokenizer = AutoModel.from_pretrained(VQ_HUB, device_map="cuda:0", trust_remote_code=True).eval()
processor = Emu3Processor(image_processor, image_tokenizer, tokenizer)# prepare input
POSITIVE_PROMPT = " masterpiece, film grained, best quality."
NEGATIVE_PROMPT = "lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry."classifier_free_guidance = 3.0
prompt = "a portrait of young girl."
prompt += POSITIVE_PROMPTkwargs = dict(mode='G',ratio="1:1",image_area=model.config.image_area,return_tensors="pt",padding="longest",
)
pos_inputs = processor(text=prompt, **kwargs)
neg_inputs = processor(text=NEGATIVE_PROMPT, **kwargs)# prepare hyper parameters
GENERATION_CONFIG = GenerationConfig(use_cache=True,eos_token_id=model.config.eos_token_id,pad_token_id=model.config.pad_token_id,max_new_tokens=40960,do_sample=True,top_k=2048,
)h = pos_inputs.image_size[:, 0]
w = pos_inputs.image_size[:, 1]
constrained_fn = processor.build_prefix_constrained_fn(h, w)
logits_processor = LogitsProcessorList([UnbatchedClassifierFreeGuidanceLogitsProcessor(classifier_free_guidance,model,unconditional_ids=neg_inputs.input_ids.to("cuda:0"),),PrefixConstrainedLogitsProcessor(constrained_fn ,num_beams=1,),
])# generate
outputs = model.generate(pos_inputs.input_ids.to("cuda:0"),GENERATION_CONFIG,logits_processor=logits_processor,attention_mask=pos_inputs.attention_mask.to("cuda:0"),
)mm_list = processor.decode(outputs[0])
for idx, im in enumerate(mm_list):if not isinstance(im, Image.Image):continueim.save(f"result_{idx}.png")视觉语言理解 (Emu3-Chat)
代码展示了如何使用 Emu3-Chat 模型根据图像描述图像内容。
from PIL import Image
from transformers import AutoTokenizer, AutoModel, AutoImageProcessor, AutoModelForCausalLM
from transformers.generation.configuration_utils import GenerationConfig
import torchfrom emu3.mllm.processing_emu3 import Emu3Processor# model path
EMU_HUB = "BAAI/Emu3-Chat"
VQ_HUB = "BAAI/Emu3-VisionTokenier"# prepare model and processor
model = AutoModelForCausalLM.from_pretrained(EMU_HUB,device_map="cuda:0",torch_dtype=torch.bfloat16,attn_implementation="flash_attention_2",trust_remote_code=True,
)# used for Emu3-Chat
tokenizer = AutoTokenizer.from_pretrained(EMU_HUB, trust_remote_code=True, padding_side="left")
# used for Emu3-Stage1
# tokenizer = AutoTokenizer.from_pretrained(
# EMU_HUB,
# trust_remote_code=True,
# chat_template="{image_prompt}{text_prompt}",
# padding_side="left",
# )
image_processor = AutoImageProcessor.from_pretrained(VQ_HUB, trust_remote_code=True)
image_tokenizer = AutoModel.from_pretrained(VQ_HUB, device_map="cuda:0", trust_remote_code=True).eval()
processor = Emu3Processor(image_processor, image_tokenizer, tokenizer)# prepare input
text = "Please describe the image"
image = Image.open("assets/demo.png")inputs = processor(text=text,image=image,mode='U',return_tensors="pt",padding="longest",
)# prepare hyper parameters
GENERATION_CONFIG = GenerationConfig(pad_token_id=tokenizer.pad_token_id,bos_token_id=tokenizer.bos_token_id,eos_token_id=tokenizer.eos_token_id,max_new_tokens=1024,
)# generate
outputs = model.generate(inputs.input_ids.to("cuda:0"),GENERATION_CONFIG,attention_mask=inputs.attention_mask.to("cuda:0"),
)outputs = outputs[:, inputs.input_ids.shape[-1]:]
print(processor.batch_decode(outputs, skip_special_tokens=True)[0])视觉编码解码 (Emu3-VisionTokenizer)
代码展示了如何使用 Emu3-VisionTokenizer 模型对图像和视频进行编码和解码。 提供了图像和视频的自动编码示例。
import os
import os.path as ospfrom PIL import Image
import torch
from transformers import AutoModel, AutoImageProcessorMODEL_HUB = "BAAI/Emu3-VisionTokenizer"model = AutoModel.from_pretrained(MODEL_HUB, trust_remote_code=True).eval().cuda()
processor = AutoImageProcessor.from_pretrained(MODEL_HUB, trust_remote_code=True)# TODO: you need to modify the path here
VIDEO_FRAMES_PATH = "YOUR_VIDEO_FRAMES_PATH"video = os.listdir(VIDEO_FRAMES_PATH)
video.sort()
video = [Image.open(osp.join(VIDEO_FRAMES_PATH, v)) for v in video]images = processor(video, return_tensors="pt")["pixel_values"]
images = images.unsqueeze(0).cuda()# image autoencode
image = images[:, 0]
print(image.shape)
with torch.no_grad():# encodecodes = model.encode(image)# decoderecon = model.decode(codes)recon = recon.view(-1, *recon.shape[2:])
recon_image = processor.postprocess(recon)["pixel_values"][0]
recon_image.save("recon_image.png")# video autoencode
images = images.view(-1,model.config.temporal_downsample_factor,*images.shape[2:],
)print(images.shape)
with torch.no_grad():# encodecodes = model.encode(images)# decoderecon = model.decode(codes)recon = recon.view(-1, *recon.shape[2:])
recon_images = processor.postprocess(recon)["pixel_values"]
for idx, im in enumerate(recon_images):im.save(f"recon_video_{idx}.png")这些示例代码提供了详细的步骤,包括模型加载、输入预处理、超参数设置和输出后处理。 用户需要根据自己的需求修改代码中的模型路径、输入数据和超参数。
Emu3的案例应用
提供的示例代码展示了Emu3在图像生成和视觉语言理解方面的应用。 图像生成示例可以生成各种风格和分辨率的图像,视觉语言理解示例可以对图像进行准确的描述。 视频自动编码示例演示了模型处理视频数据的能力。
相关文章:
MLM之Emu3:Emu3(仅需下一个Token预测)的简介、安装和使用方法、案例应用之详细攻略
MLM之Emu3:Emu3(仅需下一个Token预测)的简介、安装和使用方法、案例应用之详细攻略 导读:这篇论文介绍了Emu3,一个基于单一Transformer架构,仅使用下一个token预测进行训练的多模态模型。 >> 背景痛点: 多模态任…...

Spring Boot与Flyway实现自动化数据库版本控制
一、为什么使用Flyway 最简单的一个项目是一个软件连接到一个数据库,但是大多数项目中我们不仅要处理我们开发环境的副本,还需要处理其他很多副本。例如:开发环境、测试环境、生产环境。想到数据库管理,我们立刻就能想到一系列问…...

input角度:I2C触摸屏驱动分析和编写一个简单的I2C驱动程序
往期内容 本专栏往期内容: input子系统的框架和重要数据结构详解-CSDN博客input device和input handler的注册以及匹配过程解析-CSDN博客input device和input handler的注册以及匹配过程解析-CSDN博客编写一个简单的Iinput_dev框架-CSDN博客GPIO按键驱动分析与使用&…...

SQL-lab靶场less1-4
说明:部分内容来源于网络,如有侵权联系删除 前情提要:搭建sql-lab本地靶场的时候发现一些致命的报错: 这个程序只能在php 5.x上运行,在php 7及更高版本上,函数“mysql_query”和一些相关函数被删除…...

【生成模型之二】diffusion model模型
【算法简历修改、职业规划、校招实习咨询请私信联系】 【Latent-Diffusion 代码】 生成模型分类概述 Diffusion Model,这一深度生成模型,源自物理学中的扩散现象,呈现出令人瞩目的创新性。与传统的生成模型,如VAE、GAN相比&…...

记录 Maven 版本覆盖 Bug 的解决过程
背景 在使用 Maven 进行项目管理时,依赖版本的管理是一个常见且重要的环节。最近,在我的项目中遇到了一个关于依赖版本覆盖的 Bug,这个问题导致了 Apollo 框架的版本不一致,影响了项目的正常运行。以下是我解决这个问题的过程记录…...

【K8S系列】Kubernetes Service 基础知识 详细介绍
在 Kubernetes 中,Service 是一种抽象的资源,用于定义一组 Pod 的访问策略。它为这些 Pod 提供了一个稳定的访问入口,解决了 Pod 可能频繁变化的问题。本文将详细介绍 Kubernetes Service 的类型、功能、使用场景、DNS 和负载均衡等方面。 1.…...

python在物联网领域的数据应用分析与实战!
引言 物联网(IoT)是一个快速发展的领域,涉及到各种设备和传感器的连接与数据交换。随着设备数量的激增,数据的产生速度也在不断加快。 如何有效地分析和利用这些数据,成为了物联网应用成功的关键。Python作为一种强大的编程语言,因其简洁易用的特性和丰富的库支持,成为…...

目标跟踪算法-卡尔曼滤波详解
卡尔曼滤波是一种递归的优化算法,用于估计一个系统的动态状态,常用于跟踪、导航、时间序列分析等领域。它的关键在于使用一系列测量数据(通常含噪声)来估计系统的真实状态,使得估计值更接近实际情况。卡尔曼滤波器适合…...

SpringBoot后端开发常用工具详细介绍——application多环境配置与切换
文章目录 引言介绍application.yml(主配置文件)application-dev.yml(开发环境配置)application-test.yml(测试环境配置)application-prod.yml(生产环境配置)激活配置文件参考内容 引…...

php反序列化漏洞典型例题
1.靶场环境 ctfhub-技能树-pklovecloud 引用题目: 2021-第五空间智能安全大赛-Web-pklovecloud 2.过程 2.1源代码 启动靶场环境,访问靶场环境,显示源码:直接贴在下面: <?php include flag.php; class pks…...

浅析Android View绘制过程中的Surface
前言 在《浅析Android中View的测量布局流程》中我们对VSYNC信号到达App进程之后开启的View布局过程进行了分析,经过对整个App界面的View树进行遍历完成了测量和布局,确定了View的大小以及在屏幕中所处的位置。但是,如果想让用户在屏幕上看到…...

基于卷积神经网络的大豆种子缺陷识别系统,resnet50,mobilenet模型【pytorch框架+python源码】
更多目标检测和图像分类识别项目可看我主页其他文章 功能演示: 大豆种子缺陷识别系统,卷积神经网络,resnet50,mobilenet【pytorch框架,python源码】_哔哩哔哩_bilibili (一)简介 基于卷积神…...

HarmonyOS项目开发一多简介
目录 一、布局能力概述 二、自适应布局 三、响应式布局 四、典型布局场景 一、布局能力概述 布局决定页面元素排布及显示:在页面设计及开发中,布局能力至关重要,主要通过组件结构来确定使用何种布局。 自适应布局与响应式布局࿱…...

C++基础三
构造函数 构造函数(初始化类成员变量): 1、属于类的成员函数之一 2、构造函数没有返回类型 3、构造函数的函数名必须与类名相同 4、构造函数不允许手动调用(不能通过类对象调用) 5、构造函数在类对象创建时会被自动调用 6、如果没有显示声…...

利用ChatGPT完成2024年MathorCup大数据挑战赛-赛道A初赛:台风预测与分析
利用ChatGPT完成2024年MathorCup大数据挑战赛-赛道A初赛:台风预测与分析 引言 在2024年MathorCup大数据挑战赛中,赛道A聚焦于气象数据分析,特别是台风的生成、路径预测、和降水风速特性等内容。本次比赛的任务主要是建立一个分类评价模型&…...

Linux系统操作篇 one -文件指令及文件知识铺垫
Linux操作系统入门-系统篇 前言 Linux操作系统与Windows和MacOS这些系统不同,Linux是黑屏的操作系统,操作方式使用的是指令和代码行来进行,因此相对于Windows和MacOS这些带有图形化界面的系统,Linux的入门门槛和上手程度要更高&…...

隨筆20241028 ISR 的收缩与扩展及其机制解析
在 Kafka 中,ISR(In-Sync Replicas) 是一组副本,它们与 Leader 保持同步,确保数据一致性。然而,ISR 的大小会因多种因素而变化,包括收缩和扩展。以下是 ISR 收缩与扩展的详细解释及其背后的机制…...

linux-字符串相关命令
1、cut 提取文件每一行中的内容 下面是一些常用的 cut 命令选项的说明: -c, --characters列表:提取指定字符位置的数据。-d, --delimiter分界符:指定字段的分隔符,默认为制表符。-f, --fieldsLIST:提取指定字段的数据…...

ES6 函数的扩展
ES6 之前,不能直接为函数的参数指定默认值,只能采用变通的方法 ES6 允许为函数的参数设置默认值,即直接写在参数定义的后面 参数变量是默认声明的,所以不能用 let 或 const 再次声明 使用参数默认值时,函数不能有同名参…...

ES6从入门到精通:前言
ES6简介 ES6(ECMAScript 2015)是JavaScript语言的重大更新,引入了许多新特性,包括语法糖、新数据类型、模块化支持等,显著提升了开发效率和代码可维护性。 核心知识点概览 变量声明 let 和 const 取代 var…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...

OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别
OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别 直接训练提示词嵌入向量的核心区别 您提到的代码: prompt_embedding = initial_embedding.clone().requires_grad_(True) optimizer = torch.optim.Adam([prompt_embedding...

LINUX 69 FTP 客服管理系统 man 5 /etc/vsftpd/vsftpd.conf
FTP 客服管理系统 实现kefu123登录,不允许匿名访问,kefu只能访问/data/kefu目录,不能查看其他目录 创建账号密码 useradd kefu echo 123|passwd -stdin kefu [rootcode caozx26420]# echo 123|passwd --stdin kefu 更改用户 kefu 的密码…...
提供了哪些便利?)
现有的 Redis 分布式锁库(如 Redisson)提供了哪些便利?
现有的 Redis 分布式锁库(如 Redisson)相比于开发者自己基于 Redis 命令(如 SETNX, EXPIRE, DEL)手动实现分布式锁,提供了巨大的便利性和健壮性。主要体现在以下几个方面: 原子性保证 (Atomicity)ÿ…...

STM32---外部32.768K晶振(LSE)无法起振问题
晶振是否起振主要就检查两个1、晶振与MCU是否兼容;2、晶振的负载电容是否匹配 目录 一、判断晶振与MCU是否兼容 二、判断负载电容是否匹配 1. 晶振负载电容(CL)与匹配电容(CL1、CL2)的关系 2. 如何选择 CL1 和 CL…...

DBLP数据库是什么?
DBLP(Digital Bibliography & Library Project)Computer Science Bibliography是全球著名的计算机科学出版物的开放书目数据库。DBLP所收录的期刊和会议论文质量较高,数据库文献更新速度很快,很好地反映了国际计算机科学学术研…...
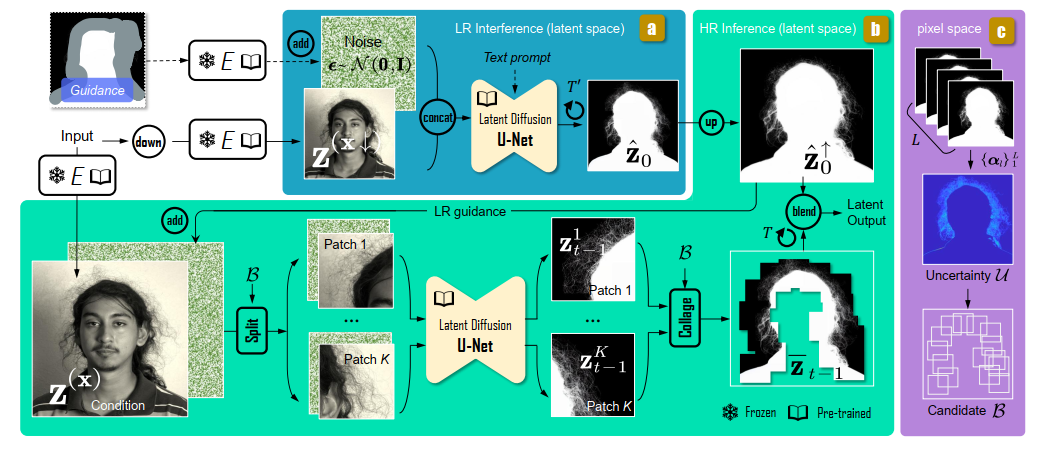
论文阅读:Matting by Generation
今天介绍一篇关于 matting 抠图的文章,抠图也算是计算机视觉里面非常经典的一个任务了。从早期的经典算法到如今的深度学习算法,已经有很多的工作和这个任务相关。这两年 diffusion 模型很火,大家又开始用 diffusion 模型做各种 CV 任务了&am…...

uni-app 项目支持 vue 3.0 详解及版本升级方案?
uni-app 支持 Vue 3.0 详解及升级方案 一、uni-app 对 Vue 3.0 的支持现状 uni-app 从 3.0 版本 开始支持 Vue 3.0,主要变化包括: 核心框架升级: 基于 Vue 3.0 的 Composition API 和 Options API 双模式支持提供 vueuse/core 等组合式 API…...