cmu 15-445学习笔记-3 存储引擎
03 Database Storage-Part Ⅰ
数据库存储上半部分
数据库分层划分结构图:
- Disk Manager:存储引擎,管理磁盘上的文件
- Bufferpool Manager:管理内存的缓存池
- Access Methods:访问方法
- Operator Execution:执行器
- Query Planning:计划、优化器
disk based architecture
基于磁盘的体系结构(存储分层):存储方式分级,高速缓存特性volatile(易失的)(NV,non-volatile不易失的)
- fast smaller expensive(更快、更小、更贵的内存):volatile,random,易失的随机访问
- slower laeger cheaper(更慢更便宜的内存):non-volatile,order,不易失的顺序访问
越往上越贵越快
Volatile Random Access Byte-Addressable:掉电易失、随机访问,可以按照字节获取地址的
CPU:
- CPU Registers:CPU寄存器
- CPU CaChes:CPU高速缓存(CPU上说的L1、L2、L3)
Memory:
- DRAM:内存DDR(Dynamic Random Access Memory:动态随机存取存储器)
Non-Volatile Sequential Access Block-Addressable:不易失的,掉电数据仍然存在、顺序访问,按照块编辑地址,无法精确获取块中的每个字节,只能将整个块读取然后才能获取块中内容(修改块中字节需要先将块中内容读取,修改块中字节,然后将块写回去)(云计算中很多块设备意思相同就是它按照块存储)
- Disk:
- (Non-volatile Memory:新型的存储器,它的速度比SSD快他还是非易失的。市面上还很少但是intel已经把它做出来了,有个Non-Volatile Memoey Database Management System【非易失性备忘录数据库管理系统】,以及intel的OPTANE DC【intel傲腾持久存储】,persistent memory持久化内存。可能会改变数据库的架构,因为落到内存上就不会丢失)
- SSD:固态硬盘
- (Fast Network Storage:云计算高速存储器,云服务器一般是要比本地快,因为是本地高速光纤过来的,挂载云硬盘)
- HDD:机械硬盘
- Network Storage:网盘
access times访问时间(单位对应1sec量化)
- 比如有一些老旧的数据库,不想仍,以后可能有用,但是估计长时间没有用的数据就可以使用磁带的方式存储,磁带是磁化,很稳定适合于存储长时间不使用的大量数据,机械也是类似,只要不去非常频繁的读写,磁化是很稳定的
0.5 ns L1 Cache Ref ← 0.5 sec
7 ns L2 Cache Ref ← 7 sec
100 ns DRAM ← 100 sec
150,000 ns SSD ← 1.7 days
10,000,000 ns HDD ← 16.5 weeks
~30,000,000 ns Network Storage ← 11.4 moths
1,000,000,000 ns Tape Archives(磁带塔) ← 31.7 years
sequential VS. random access
对比顺序存储和随机存储
连续存取要比随机存取要远远快得多
开发数据库的要求,用户的存取是随机的,因为不能要求用户的存取,所以目的就是把用户需要的随机存取尽量转化为数据库对磁盘的连续存取(这是考验数据库设计能力的环节)。例如用户取用随机的数据,我们先将其缓存到内存中,然后找一个合适的时间再将其写道硬盘中去
文件的一个块/也叫一个页,一个页对应一个文件的小分区(存储也有页,数据库自己也有页,页和页概念也不一样)
system design goals
设计这样一个存储引擎的目标是什么?
- Allow the DBMS to manage database that exceed the amount of memory available.【允许DBMS管理超过可用内存量的数据库】(为了将可能大于内存的数据加载到内存中需要有一个好的替换策略,来保证数据库的加载)
- Reading/writing to disk is expensive, so it must be managed carefully to avoid large stalls and performance degradation.【读取/写入磁盘的成本很高,因此必须谨慎管理,以避免出现大的停顿和性能下降】(即使使用ssd读写数据库的成本也是很高的,所以不要经常的读写)
- Random access on disk is usually much slower than sequential access, so the DBMS will want to maximize sequential access.【磁盘上的随机访问通常比顺序访问慢得多,因此DBMS希望最大化顺序访问】(一个优秀的存储引擎应该尽可能的去将随机访问转化为顺序访问)
disk-oriented DBMS
大部分的数据库都是面向硬盘的,(有些数据库是memory数据存在内存中的,面向内存的数据库容量小,但是速度特别快)
Disk Database File(数据库文件):一个大的数据库文件都是存放在一个database中的,这些数据库文件在数据库中是分pages的(db page)结构就是在前面会有一个类似于目录的东西告诉你什么东西在哪一个页,每一个page中每一个页可以认为是一块数据,他有固定的大小(4k/ 8k/ MySQL 16k)每一块数据还有一个header,header就是数据头,对数据进行一些解释(类似于http头)。
Memory Buffer Pool(内存池):会将需要的数据库数据加载到内存池中,(在游戏中是一个loading的过程)需要那部分就加载那部分,池是因为需要控制它的大小,他不能占太大内存,否则要不导致系统崩溃要不被操作系统干掉
Execution(执行器):执行器在内存中获取一个页(Get page #2),内存中会先将目录加载到内存中,然后看需要那页在把需要的页loading到内存中,然后返回给执行器(pointer to page #2)

Q. why not use the OS?
- The DBMS can use memory mapping(mmap) to store the contents of a file into the address space of a program.
- 【数据库管理系统可以通过将内存映射,去将文件内容存储到程序的地址空间中】
- The OS is responsible for moving the pages of the file in and out of memory, so the DBMS dosen’t need to worry about it.
- 【操作系统允许文件的页移入和移出内存,所以数据库管理系统不需要担心】
mmap提供虚拟内存,如果想把disk磁盘中的数据全都加载到内存中是不可能的(例如1T硬盘和8G内存)如果想使用就需要一些办法,swap替换、加载一块啊什么的,但是mmap提供了一个虚拟内存virtual memory(这个虚拟内存和实际的物理内存是一样大的)软件直接访问虚拟内存,然后需要访问page1时,操作系统将page1去load到physical memory物理内存中,再把虚拟内存链接过来,mmap访问虚拟内存中的page1就相当于访问了内存中的page1,这样就不需要去管理内存加载卸载的过程了(但是这样的方法会有问题,当物理内存都填满的情况下我还要继续加载新的page页到内存中,这时候操作系统是不知道内存中的页那个可以卸载的,因为两个页都是数据库再用,用完之后没有告诉操作系统那个页不用了,所以新的页需要加入,但是操作系统满了的话就会卡住)
mmap问题
如果只读的话,还可以但是如果有很多并发写的话mmap也会有问题
然后衍生出了一些辅助mmap的方法:
- madvice:告诉操作系统你期望的阅览方式(Tell the OS how you expect to read certain pages.)
- mlock:告诉操作系统那些内存页不使用了(Tell the OS that memory ranges cannot be paged out.)
- msync:告诉操作系统将内存中的内容刷新到磁盘(Tell the OS to flush memory ranges out to disk.)
- DBMS (almost) always wants to control things itself and can do a better job than the OS.
- 【DBMS希望自己管理和控制,并且希望比操作系统管理的更好】
- Flushing dirty pages to disk in the correct order.
- 【按照正确的顺序将脏数据刷新到磁盘中】我们需要自己控制将这些修改的脏数据刷到磁盘中的时间,是立即就放到磁盘中还是等几秒和更多的脏数据一起放到磁盘中,如果不自己控制的话,数据库系统性能会非常的差。
- Specialized prefetching.
- 【预先将磁盘的数据取出来】用户没有需要的时候就取出来,例如用户进行全表扫描,执行器取出第1、2、3块的时候,存储引擎预先将4、5、6块取出送到内存里去,这样执行器访问就省去了等待磁盘加载到内存的过程,这个是需要完全的自己控制的
- Buffer replacement policy.
- 【缓冲区替换策略】来了新数据需要把什么数据替换掉,例如LRU这种
- Thread/process scheduling.
- 【进程/线程调度】用户并发读写时候,先后顺序需要我们自己控制
上述的工作无法交给操作系统完成,所以不去使用操作系统
database storage
数据库存储两大关键问题:
- problem #1:How the DBMS represents the database in files on disk.
- 【如何在磁盘上表示数据库】也就是数据库最终落到一个什么样的文件上
- problem #2:How the DBMS manages its memory and moves data back-and-forth from disk.
- 【DBMS如何管理内存和磁盘来回转移的数据】什么时候将数据复制到内存,什么时候将修改的数据写回磁盘
problem #1
How the DBMS represents the database in files on disk.
数据库最终落到的文件表示,细分为三个小问题:文件、页、一行数据分别长什么样???
-
File storage【文件存储】
-
文件存储就是把用户数据存在操作系统磁盘里一个或者多个文件当中,这些文件内容是什么,操作系统不知道也不关心,操作系统只知道有这些数据你给我存里
-
早期系统在原始存储上使用自定义文件管理系统,就是说,拿到一个磁盘自动进行格式化怎么存的你也不用知道就是一个一体机,现在这种情况越来越少了,更多的是交给操作系统去格式化,操作系统格式化之后例如使用MySQL出现两个文件,你在操作系统中你是可以看到的,格式化的文件系统交给数据库,数据库在里面存
-
storage manager【存储管理】:管理维护操作系统里的数据库文件
- 它会自己管理在时间空间上的存取数据
- 一般来说我们的存储引擎会将这个文件当成一组page页
-
-
database pages【数据库页】
-
一个页就是一小块数据,它可以是元组、元数据、索引、日志。对于数据库来说如果它存索引,那么这个数据库就是存索引,存日志,他就是存日志,存元数据就是存元数据,它不会是存多个数据的。有一些系统会存一些字节页,你不知道数据库存的是什么类型的,你可以根据这几个字节来知道这个数据库存的是什么类型的这几个字节用于告诉存储类型
- 每一个页都有一个唯一的id,为了方便管理
- 页的概念有不同的解释,hardware page硬盘层面的话通常是4KB,操作系统的页通常是4KB(我们无法直接操作硬件,我们需要将我们操作的数据先交给操作系统由操作系统去接触硬件,这个操作的最小单位就是4k),数据库自己的页概念(512B~16KB)512B什么经常是一些便携式设备,例如手机,16K是操作系统和硬盘的整数倍,对于自己来说写了16K就是写了一个页,对于它们来说就是写了4个页(最小管理单位)一个hardware page是最小的保证原子操作的页,如果磁盘告诉我写失败了,那么这4k就全写失败了,如果写了16k告诉我写失败了,哪不知道哪里写失败了
- 4KB:SQLite(移动)、DB2、Oracle
- 8KB:SQLServer、PostgreSQL
- 16KB:MySQL
-
database heap【数据库堆文件】
-
A heap file is an unordered collection of pages with tuples that are stored in random order.
Create/Get/Write/Delete Page
Must also support iterating over all pages. -
【堆文件是一堆无序的页的集合,这些页要满足增删改查的功能,然后这些页必须可以迭代】
-
Two ways to represent a heap file:
Linked List
Page Directory -
多文件【表示堆文件的两种方式:链表和页目录】
- 链表方案:使用空文件链表和数据文件链表表示
- 目录方案:一个目录用于索引告诉你几号页在哪

-
-
-
Page Layout【页布局】
每个页的布局是什么样的?

-
Every page contains a header of metadata about the page’s contents.【每个页都有一个关于元数据的标题】
pagesize:每个页多大
Checksum:校验(MD5什么的或者说是哈希)
DBMS Version:管理系统版本(防止版本不兼容)
Transaction Visibility:事务的可见性
Compression Information:页怎么压缩的
-
一个页包含一个元数据区和一个数据区,数据区的存取方式有两个流派
-
Tuple-oriented:只存一行行数据
想法就是最初我都数据是0,然后来一个数据我就加入一个数据,但是如果加入1、2、3之后2删除了,1、3之间就会有内存空隙产生,这时候加入一个4就会想到加入到13之间,但是这样可能会产生小的内存碎片难以利用,或者因为过大没办法放进去,出现这样的问题
解决方法是使用一个slots array插槽数组,将数据元素都堆放到后面数组前面只存放地址,然后当元素移除之后堆后面的数据元素进行整理(就像是指针数组一样)

recqrd ids:每一个tuple元组数据需要一个id(id用于在全局寻找这个数据或者这个记录)一般这个id就是pageid+offset/slot然后就可以让数据库定位到每一行数据,这个recqrd id是数据库内部使用的id,外部一般不使用这个id。外部你只能使用主键或者有意义的东西,不能使用它这个无意义的id(比如page页一整理页号就会改变)
PostgreSQL(CTID、6-bytes)、SQLite(ROWID、8-bytes)、Oracle(ROWID、10-bytes)都有自己的行id
-
Log-structured:存log
-
-
-
Tuple Layout【一个元组的布局】
-
数据在磁盘上的表示就是一组二进制的字节,不去解析它的话就是没有意义的。数据库的工作就是把数据编码好然后放到磁盘上
-
一个Tuple也有一个header头,一般来说一个表创建时候,每个字段的数据类型是什么顺序就按照什么顺序存储,因为在一个元组中数据是连续不断的,不按照顺序存会有问题,(一般都是按照字段类型顺序存的)
-
denormalized tuple data【非规范的元组数据】:就是说学术界认为这个问题:有一个表foo和另一个表bar,foo中有字段a(主键)、b,bar表中有字段c、a(外键),这时候学术就认为,你读的时候总要连表读,本来存的时候是分开存的然后就和到一起,但是这种存储方式不利于后期数据的修改
CREATE TABLE foo(a INT PRIMARY KEY,b INT NOT NULL ); CREATE TABLE bar(c INT PRIMARY KEY,a INTREFERGNCES foo (a), );
-
conclusion
- Database is organized in pages.【数据库按页组指的方式】
- Different ways to track pages.【找到页的方式】
- Different ways to store pages.【存储页的方式】
- Different ways to store tuples.【存储数据的方式】
04 Database Storage-Part Ⅱ
log-structured file organization
【日志的结构化文件】:一行中tuple元组存的不是数据的本身而是数据的log,存储的是数据的变化
The system appends log records to the file of how the database was modified:
- Inserts store the entire tuple.
- Deletes mark the tuple as deleted.
- Updates contain the delta of just the attributes that were modified.
【就是说操作系统允许文件记录修改数据库的方式,1、是插入整个元组,2、是记录删除数据的操作,而不是删除数据本身,3、是记录改写数据的操作,而不是改写数据本身】
当读取数据的时候会将该数据相关的所有操作读出来(进行回放),然后推断这个数据应有的样子(推断是从新到旧的),然后如果在日志中寻找某一数据觉得速度比较慢可以做一些索引或者目录。
但是这样存储日志的数据库会比较大(就需要周期性的压缩日志),压缩之后应该保留当页操作之后的数据结果(但是仅仅可以压缩当前页的数据,如果该页中没有出现某个数据的插入只记录了数据的删除,那么这个操作就是不能压缩的)
大概在使用这个log的方式的数据库有hbase(k-v数据库)、cassardra(时序数据库)、levelDB(k-v数据库)、RocksDB(k-v数据库)(levelDB是RockDB的原型)
- log数据库更多的使用在k-v数据库上,因为k-v数据库修改的数据就是最终的数据,所以log在k-v数据库上更加的好用
- relational数据库修改一个字段之后想要拿出这行数据还需要回溯其他字段
log-structured compaction
【日志结构压缩原则】:压缩的时候单个字段记录最终结果
- Level compaction:分层压缩,**Rocks DB(?)**压缩的基本原理,在同一块中的操作(一个插入一个修改),两个块内部之间永远无法合并,所以就对他进行了一个按层压缩,将两个log合并成一个一长串的log然后就能压缩了。然后一共能压缩七层,找的时候就从第0层开始找,如果找到这个文件就返回没有找到就去第1层,以此类推
- Universal compaction:觉得两个块可以合并,就进行压缩是一种比较通用的压缩方法
上述方法 说的就是tuple存的不是数据是块的时候,在插入的时候就可以将随机的写转化为顺序的写(以前存数据的时候就是在需要改数据的时候把数据从页中加载进来,然后修改,然后将修改的数据协会去,之后在需要修改这个数据,就再从磁盘中页加载,修改,然后再写回去。有了这个日志的好除就是,在需要修改这个数据的时候我就用一个新的页一个新的块然后按照日志对这个数据操作就完事了,相当于把随机的写转化成了连续的写)所以着各种方法在持续更新大量数据的时候效率高,但是效率不好的地方就是读起来比较费劲,回放这些日志,再有就是压缩的时候比较麻烦,压缩本身也是有开销的
data representation
【数据在磁盘上是怎么表示的】
在C/C++与DB中的数据表达是不一样的
-
浮点数类型
-
在取少数位的时候可能看不出区别,但是如果取小数点后20位甚至更多就会出现精度问题(一般银行系统等对精度要求是很高的)(在写业务的时候一般关于钱的是严谨使用浮点类型的)(在java中有一个Big decimal的类型是专门给这这样高精度的浮点使用的)
-
PG numeric:在数据库中也有类似的实现方式,例如PG(PostgresQL)它里面有一个数据类型是numeric
typedef unsigned char NumericDigit; typedef struct {int ndigits; // 位数int weight; // 权重,或者说数量级int scale; // 指数 乘10 乘100...int sign; // 标志位,正数/负数/没有 positive/negative/NANNumericDigit* digits; // 字面量地址 }numeric;PG源码是全世界源码的模范
-
MySQL numeric:
typedef int32 decimal_digit_t; struct decimal_t {int intg, frac, len; // 小数点 前位数/后位数/数据由多少字节长度bool sign; // 标志 + / -decimal_digit_t *buf; // 字面量指针 }; -
large values:在一行数据中存了一个特别长的字符串,大到这个页都存不下,这时候就会新开一个页(叫Overflow Page溢出页,来存这个字符串)(对于数据库的管理溢出页的管理也是很麻烦的)
- Postgres:TOAST(PG中的常量)>2KB
- MySQL:OverFlow(>1/2 size page)一个页最少存两个数据
- SQL Server:OverFlow(> size page)一个页最少一个数据
- 溢出页后面可以接一个溢出页,但是尽量避免这么使用,因为一个页只存一个数据,对于数据库来说是非常低效的,磁盘存储的单位就是页,读取一次磁盘只能拿到一页的数据,如果真的需要放一个比较大的数据例如图片,就在数据库中放一个地址,把图片存放位置的地址放到数据库中
-
external value storage:有一个外部文件,我不想自己去管理,交给数据库管理,我使用链接连接到数据库,但是这个文件可能系统或者别的软件会修改它,数据库没有办法保证这个数据存储进去别人用没用过。所以尽量使用地址存储到数据库中,不让数据库去管理,自己去管理
-
system catalogs
【系统元数据】
- 表结构、列结构、索引、视图
- 用户、权限
- 内部信息
在链接数据库的三方软件中点开数据库可以直接看到这些表结构
- accessing table schema:访问表方法
SELECT * FROM INFORMATION_SCHEMA.TABLES WHERE table_catalog = '<db name>'; SQL-92
\d; Postgres
SHOW TABLES; MySQL
.table SQLite
- database workloads:数据库工作负载
- On-Line Transaction Processing(OLTP)在线交易数据:更倾向于写
- On-Line Analytical Processing(OLAP)在线分析数据:更倾向于读
- Hybrid Transaction + Analytical Processing(HTAP)交易+分析处理
用户不关心数据存储时候是怎么样的,取出来的是一行是因为想要一行取出来,存储对于用户来说是不可见的
storage models
【存储数据的模型】
-
n-ary storage model(NSM)行存模型:一个元组保存了一行属性,这种按行存储的类型适合TP类型,在用户登录之后只需要将关于用户的一行数据取出来就可以了不涉及到其他任何东西。查询走索引找到行,然后将数据取出。在AP的时候行存会做很多无用功。
- 优势:增删改查都很快、需要一整行数据的时候行存就是优势
- 劣势:需要扫描一整列的时候行存就是劣势(取行的时候需要把所有数据都拿出来然后把一段数据取出来)
-
decomposition storage model(DSM)(拆分数据模型)列存模型:一个tuple存一列,列存对分析的性能是好的
怎么识别取出来的列的行号?两种方法:
- 使用offset偏移量存储,每一列的固定位置有固定的行号
- 给每一列的元素加上id,但是存储开销比较大,但是更好找
- 优点:去更多跑磁盘IO操作的时候所需资源会大量减少,只需要某几列,不需要全表扫描。对于查询和压缩更加的友好
- 缺点:点查询,一行,删除,插入都不友好(不好维护),列存面临数据分裂的问题
现代的数据库很多都做了列存引擎,当TP交易的时候使用行存,存的时候也备份列存一份,当AP的时候就使用列存
conclusion
The storage manager is not entirely independent from the rest of the DBMS.
It is important to choose the right storage model for the target workload:
- OLTP = Row Store
- OLAP = Column Store
数据库存储并非是独立于数据库管理系统的部分,为目标负载选择正确的存储模型很重要
相关文章:
cmu 15-445学习笔记-3 存储引擎
03 Database Storage-Part Ⅰ 数据库存储上半部分 数据库分层划分结构图: Disk Manager:存储引擎,管理磁盘上的文件Bufferpool Manager:管理内存的缓存池Access Methods:访问方法Operator Execution:执行…...

[linux]和windows间传输命令scp 执行WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED!错误解决
[linux]和windows间传输命令scp 执行WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED!错误解决. 现象: 原因: 接收方服务器系统做了某些更改,导致登录时会报错。主要因为接收方服务器对登录过它的主机都会把该主机登录标识证书记录下来&a…...

C++ | Leetcode C++题解之第518题零钱兑换II
题目: 题解: class Solution { public:int change(int amount, vector<int>& coins) {vector<int> dp(amount 1), valid(amount 1);dp[0] 1;valid[0] 1;for (int& coin : coins) {for (int i coin; i < amount; i) {valid[…...

高并发-负载均衡
负载均衡在微服务架构中是一个重要的组成部分,旨在优化资源利用、提高服务可用性和确保系统的高可扩展性。以下是对微服务中的负载均衡的详细介绍,包括其原理、类型、实现方式以及相关的技术。 一、负载均衡的原理 负载均衡的基本原理是将进入系统的请…...

Docker 常用命令全解析:提升对雷池社区版的使用经验
Docker 常用命令解析 Docker 是一个开源的容器化平台,允许开发者将应用及其依赖打包到一个可移植的容器中。以下是一些常用的 Docker 命令及其解析,帮助您更好地使用 Docker。 1. Docker 基础命令 查看 Docker 版本 docker --version查看 Docker 运行…...

基于 Postman 和 Elasticsearch 测试乐观锁的操作流程
鱼说,你看不到我眼中的泪,因为我在水中。水说,我能感觉到你的泪,因为你在我心中。 -村上春树 在分布式系统中,多个并发操作对同一资源的修改可能导致数据不一致。为了解决这种问题,Elasticsearch 提供了乐观…...

如何从PPT中导出600dpi的高清图
Step1. 修改PPT注册表 具体过程,参见如下链接:修改ppt注册表,导出高分辨率图片 Step2. 打开PPT,找到自己想要保存的图,选中图像,查看图像尺寸并记录 Step3. 重新新建一个PPT,并根据记录的图片…...
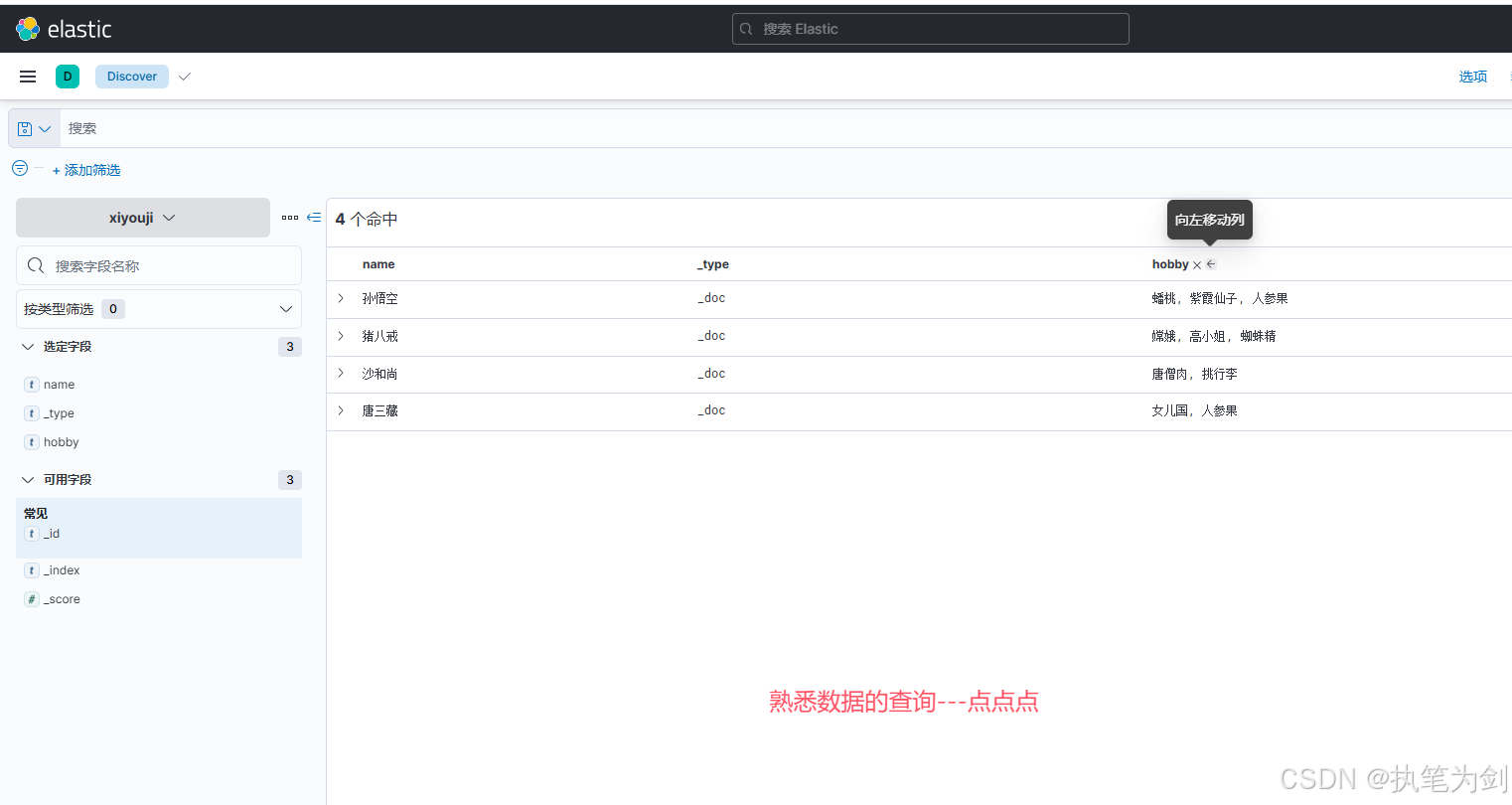
day01-ElasticStack+Kibana
ElasticStack-数据库 #官网https://www.elastic.co/cn/ #下载7.17版环境准备 主机名IP系统版本VMware版本elk110.0.0.91Ubuntu 22.04.417.5.1elk210.0.0.92Ubuntu 22.04.417.5.1elk310.0.0.93Ubuntu 22.04.417.5.1 单机部署ES 1.下载ES软件包,放到/usr/local下 […...

HTML 约束验证
HTML5引入了表单相关的一些新机制:它为<input>元素和约束验证增加了一些新的语义类型,使得客户端检查表单内容变得容易。基本上,通过设置一些新的属性,常用的约束条件可以无需 JavaScript 代码而检测到;对于更复…...

vue3项目开发一些必备的内容,该安装安装,该创建创建
重新整理了一下项目开发必备的一些操作,以后直接复制黏贴运行,随着项目开发,后期会陆续补充常用插件或组件等 如果你是还没有安装过的新人,建议从《通过安装Element UI/Plus来学习vue之如何创建项目、搭建vue脚手架、npm下载、封装…...

2D拓扑图
2D拓扑图主要指的是在二维平面上表示物体形状和关系的一种图形表示方法。 一、基本概念 2D网格拓扑结构:在二维平面上,由一系列的节点(node)和边(edge)组成。每个节点代表一个具体的位置或坐标点…...

大数据面试题整理——Hive
系列文章目录 大数据面试题专栏点击进入 文章目录 系列文章目录Hive 面试知识点全面解析一、函数相关(一)函数分类与特点(二)concat和concat_ws的区别 二、SQL 的书写和执行顺序(一)书写顺序(二…...
锐化:梯度锐化、Roberts 算子、Laplace算子、Sobel算子的详细方法)
Python实现图像(边缘)锐化:梯度锐化、Roberts 算子、Laplace算子、Sobel算子的详细方法
目录 Python实现图像(边缘)锐化:梯度锐化、Roberts算子、Laplace算子、Sobel算子的详细方法引言一、图像锐化的基本原理1.1 什么是图像锐化?1.2 边缘检测的基本概念 二、常用的图像锐化算法2.1 梯度锐化2.1.1 实现步骤 2.2 Robert…...

【电机控制】相电流重构——单电阻采样方案
【电机控制】相电流重构——单电阻采样方案 文章目录 [TOC](文章目录) 前言一、基于单电阻采样电流重构技术原理分析1.1 单电阻采样原理图1.2 基本电压矢量与电流采样关系 二、非观测区2.1 扇区过渡区2.2 低压调制区 三、非观测区补偿——移相法四、参考文献总结 前言 使用工具…...

#基础算法
1 差分练习 1 模板题 代码实现: import java.util.Scanner;public class Main {public static void main(String[] args) {Scanner sc new Scanner(System.in);int n sc.nextInt();int m sc.nextInt();int num sc.nextInt();long[][] arr new long[n 2][m …...

如何用猿大师办公助手实现OA系统中Word公文/合同在线编辑及流转?
在OA系统或者合同管理系统中,我们会经常遇到网页在线编辑Word文档形式的公文及合同的情况,并且需要上级对下级的公文进行批注等操作,或者不同部门的人需要签字审核,这就需要用到文档流转功能,如何用猿大师办公助手实现…...

Python中的列表是什么?它们有什么用途?
1、Python中的列表是什么?它们有什么用途? 在Python中,列表是一种有序的集合,可以包含不同类型的元素。列表可以存储一组值,并且可以方便地访问、修改和操作这些值。 列表的主要用途包括: 数据存储&…...

探索现代软件开发中的持续集成与持续交付(CI/CD)实践
探索现代软件开发中的持续集成与持续交付(CI/CD)实践 随着软件开发的飞速进步,现代开发团队已经从传统的开发模式向更加自动化和灵活的开发流程转变。持续集成(CI) 与 持续交付(CD) 成为当下主…...

React 前端框架开发入门案例
以下是一个使用 React 进行前端框架开发的入门案例,实现一个简单的待办事项列表应用。 一、准备工作 安装 Node.js:React 需要 Node.js 环境来运行。你可以从 Node.js 官方网站下载并安装适合你操作系统的版本。 创建项目目录:在你的电脑上…...

模拟 DDoS 攻击与防御实验
模拟 DDoS 攻击与防御实验可以帮助理解攻击原理和防御策略。在进行这种实验时,必须确保在受控、合法的环境中进行,避免对真实网络造成损害。以下是具体步骤: 环境要求 硬件:至少两台计算机(或虚拟机)&…...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

【JavaEE】-- HTTP
1. HTTP是什么? HTTP(全称为"超文本传输协议")是一种应用非常广泛的应用层协议,HTTP是基于TCP协议的一种应用层协议。 应用层协议:是计算机网络协议栈中最高层的协议,它定义了运行在不同主机上…...

FastAPI 教程:从入门到实践
FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API,支持 Python 3.6。它基于标准 Python 类型提示,易于学习且功能强大。以下是一个完整的 FastAPI 入门教程,涵盖从环境搭建到创建并运行一个简单的…...

P3 QT项目----记事本(3.8)
3.8 记事本项目总结 项目源码 1.main.cpp #include "widget.h" #include <QApplication> int main(int argc, char *argv[]) {QApplication a(argc, argv);Widget w;w.show();return a.exec(); } 2.widget.cpp #include "widget.h" #include &q…...

OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别
OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别 直接训练提示词嵌入向量的核心区别 您提到的代码: prompt_embedding = initial_embedding.clone().requires_grad_(True) optimizer = torch.optim.Adam([prompt_embedding...
)
【HarmonyOS 5 开发速记】如何获取用户信息(头像/昵称/手机号)
1.获取 authorizationCode: 2.利用 authorizationCode 获取 accessToken:文档中心 3.获取手机:文档中心 4.获取昵称头像:文档中心 首先创建 request 若要获取手机号,scope必填 phone,permissions 必填 …...
)
是否存在路径(FIFOBB算法)
题目描述 一个具有 n 个顶点e条边的无向图,该图顶点的编号依次为0到n-1且不存在顶点与自身相连的边。请使用FIFOBB算法编写程序,确定是否存在从顶点 source到顶点 destination的路径。 输入 第一行两个整数,分别表示n 和 e 的值(1…...

Linux --进程控制
本文从以下五个方面来初步认识进程控制: 目录 进程创建 进程终止 进程等待 进程替换 模拟实现一个微型shell 进程创建 在Linux系统中我们可以在一个进程使用系统调用fork()来创建子进程,创建出来的进程就是子进程,原来的进程为父进程。…...

在Ubuntu24上采用Wine打开SourceInsight
1. 安装wine sudo apt install wine 2. 安装32位库支持,SourceInsight是32位程序 sudo dpkg --add-architecture i386 sudo apt update sudo apt install wine32:i386 3. 验证安装 wine --version 4. 安装必要的字体和库(解决显示问题) sudo apt install fonts-wqy…...

SpringAI实战:ChatModel智能对话全解
一、引言:Spring AI 与 Chat Model 的核心价值 🚀 在 Java 生态中集成大模型能力,Spring AI 提供了高效的解决方案 🤖。其中 Chat Model 作为核心交互组件,通过标准化接口简化了与大语言模型(LLM࿰…...