【spark】spark structrued streaming读写kafka 使用kerberos认证
spark版本:2.4.0
官网
Spark --files使用总结
Spark --files理解
一、编写jar
import org.apache.kafka.clients.CommonClientConfigs
import org.apache.kafka.common.config.SaslConfigs
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.streaming.Trigger
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.slf4j.{Logger, LoggerFactory}import scala.collection.mutable/*** 在集群使用以下脚本发送和接受消息!* kafka-console-producer.sh --bootstrap-server xxx.01.com:6667,xxx.02.com,xxx.03.com:6667 --topic tp-read --producer-property security.protocol=SASL_PLAINTEXT* kafka-console-consumer.sh --bootstrap-server xxx.01.com:6667,xxx.02.com,xxx.03.com:6667 --topic tp-write --from-beginning --consumer-property security.protocol=SASL_PLAINTEXT --group tester*/
object SparkKafka {val LOG = LoggerFactory.getLogger(classOf[SparkSession])val bootstrapServers = "xxx.01.com:6667,xxx.02.com,xxx.03.com:6667"val readTopic = "tp-read"val writeTopic = "tp-write"def main(args: Array[String]): Unit = {val SparkKafkaProps: mutable.Map[String, String] = mutable.Map.empty// Kafka’s own configurations can be set via DataStreamReader.option with kafka. prefix, e.g, stream.option("kafka.bootstrap.servers", "host:port").// For possible kafka parameters, see Kafka consumer config docs for parameters related to reading data, and Kafka producer config docs for parameters related to writing data.SparkKafkaProps.put("kafka." + CommonClientConfigs.SECURITY_PROTOCOL_CONFIG, "SASL_PLAINTEXT")SparkKafkaProps.put("kafka." + SaslConfigs.SASL_MECHANISM, "GSSAPI")SparkKafkaProps.put("kafka." + SaslConfigs.SASL_KERBEROS_SERVICE_NAME, "kafka")val spark = SparkSession.builder().appName("spark-jar-job").config("spark.sql.streaming.checkpointLocation", "hdfs:///tmp/spark/chkp/test-job") // 必须设置!.enableHiveSupport().getOrCreate()// no useful! this api is for spark DStreams not for Structured Streaming!!!
// val sc=spark.sparkContext
// val ssc=new StreamingContext(sc,Seconds(5))spark.sparkContext.setLogLevel("debug")val read = spark.readStream.format("kafka").options(SparkKafkaProps).option("kafka.bootstrap.servers", bootstrapServers).option("subscribe", readTopic).option("group.id", "sr").option("includeHeaders", "false").load()val write=read.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)").writeStream.format("kafka").outputMode("update").options(SparkKafkaProps).option("kafka.bootstrap.servers", bootstrapServers).option("topic", writeTopic).trigger(Trigger.ProcessingTime("1 second")) // only change in query.start()write.awaitTermination()LOG.warn("job has started!!!")val secConfig = System.getProperty("java.security.auth.login.config")LOG.warn(s"Got `java.security.auth.login.config` as: ${secConfig}")// You can start any number of queries in a single SparkSession.// They will all be running concurrently sharing the cluster resources.// You can use sparkSession.streams() to get the StreamingQueryManager// block until any one of them terminates 任何一个流结束就会停止!// spark.streams.awaitAnyTermination() // 如果定义多流则使用此项。}
}
打jar。提交yarn运行
二、启动任务on yarn:
相对路径使用文件名直接表示,绝对路径使用/xxx/文件名表示
spark 任务启动后会有driver和executor。
client模式下的driver就是本机的黑窗口,cluster模式下driver就是就到某一节点机器。
所有模式下executor都是集群的各个节点机器。
# client模式
# 此模式下driver-java-options内的路径就是本机路径,jaas-abs.conf文件内的keytab路径也是本机路径(绝对路径)
# spark.executor.extraJavaOptions 因为是集群的机器,在--files上传到集群各个机器后需要使用相对路径,jaas-rel.conf文件内的keytab路径也是相对路径
# spark.yarn.keytab 文件会和 --files /xxx/user.keytab 文件在上传至集群其他机器后会在同一个文件夹内造成冲突(yarn.Client: Same name resource file:///xxx/user.keytab added multiple times to distributed cache),其实文件是一样的,user-bak.keytab只是user.keytab的一个副本。
# driver-java-options 和 spark.driver.extraJavaOptions 是一样的,但更推荐在client模式下使用driver-java-options
spark-submit \--class com.xxx.SparkKafka \--verbose \--master yarn \--deploy-mode client \--executor-memory 10G \--total-executor-cores 6 \--conf spark.yarn.principal=user@XXXXX.COM \--conf spark.yarn.keytab=/xxx/user-bak.keytab \--driver-java-options "-Djava.security.auth.login.config=/xxx/jaas-abs.conf" \--conf "spark.executor.extraJavaOptions=-Djava.security.auth.login.config=jaas-rel.conf" \--files /xxx/jaas-rel.conf,/xxx/user.keytab \
/xxx/spark-kafka-example-0.1.jar# cluster模式
# 此模式下spark.driver.extraJavaOptions和spark.executor.extraJavaOptions 因为driver运行在是集群的机器,不一定是本机。在--files上传到集群各个机器后需要使用相对路径,jaas-rel.conf文件就是--files上传的,其的keytab路径也是相对路径
# spark.yarn.keytab 文件会和 --files /xxx/user.keytab 文件在上传至集群其他机器后会在同一个文件夹内造成冲突(yarn.Client: Same name resource file:///xxx/user.keytab added multiple times to distributed cache),其实文件是一样的,user-bak.keytab只是user.keytab的一个副本。
spark-submit \--class com.xxx.SparkKafka \--verbose \--master yarn \--deploy-mode cluster \--executor-memory 10G \--total-executor-cores 6 \--conf spark.yarn.principal=user@XXXXX.COM \--conf spark.yarn.keytab=/xxx/user-bak.keytab \--conf "spark.driver.extraJavaOptions=-Djava.security.auth.login.config=jaas-rel.conf" \--conf "spark.executor.extraJavaOptions=-Djava.security.auth.login.config=jaas-rel.conf" \--files /xxx/jaas-rel.conf,/xxx/user.keytab \
/xxx/spark-kafka-example-0.1.jar
三、spark shell运行
spark shell其driver运行在本地
bin/spark-shell \
--conf spark.yarn.principal=user@XXXXX.COM \
--conf spark.yarn.keytab=/xxx/user.keytab \
--driver-java-options "-Djava.security.auth.login.config=/xxx/jaas-abs.conf" \
--conf spark.executor.extraJavaOptions=-Djava.security.auth.login.config=jaas-rel.conf \
--files /xxx/jaas-rel.conf,/xxx/jaas-abs.conf,/xxx/user.keytab \
-Dsun.security.krb5.debug=true \
-Dsun.security.spnego.debug=true \
--verbose
// 测试是否存在user.keytab文件val secConfig=System.getProperty("java.security.auth.login.config") // 是指driver端的。println(secConfig)import java.io.Fileval shortKeyPath=new File("user.keytab")shortKeyPath.exists()val longKeyPath=new File("/xxx/user.keytab")longKeyPath.exists()// 测试kafka-batch: spark.read
import scala.collection.mutable
val props:mutable.Map[String,String]=mutable.Map.empty
props.put("kafka.bootstrap.servers","xxx.01.com:6667,xxx.02.com,xxx.03.com:6667")
props.put("subscribe","tp-read")
props.put("kafka.security.protocol","SASL_PLAINTEXT")
props.put("kafka.sasl.mechanism","GSSAPI")
props.put("kafka.sasl.kerberos.service.name","kafka")
spark.read.format("kafka").options(props.toMap).load().show// 测试kafka-stream: spark.readStream
import scala.collection.mutable
import org.apache.spark.sql.streaming.Triggerval props:mutable.Map[String,String]=mutable.Map.empty
props.put("kafka.bootstrap.servers","xxx.01.com:6667,xxx.02.com,xxx.03.com:6667")
props.put("subscribe","tp-read")
props.put("kafka.security.protocol","SASL_PLAINTEXT")
props.put("kafka.sasl.mechanism","GSSAPI")
props.put("kafka.sasl.kerberos.service.name","kafka")
val rd=spark.readStream.format("kafka").options(props.toMap).load()
rd.writeStream.outputMode("update").format("console").trigger(Trigger.ProcessingTime("3 seconds")).start() // 可以没有 .awaitAnyTermination()
四、jaas.conf文件内容:
KafkaClient 是kafka客户端使用的,Client 是zookeeper客户端使用的
jaas-abs.conf文件内容
KafkaClient {com.sun.security.auth.module.Krb5LoginModule requireduseKeyTab=truestoreKey=trueuseTicketCache=falsekeyTab="/xxx/user.keytab"principal="user@XXXXX.COM";
};Client {com.sun.security.auth.module.Krb5LoginModule requireduseKeyTab=truestoreKey=truekeyTab="/xxx/user.keytab"principal="user@XXXXX.COM";
}
jaas-rel.conf文件内容
keyTab="user.keytab"和keyTab="./user.keytab"完全一样。
KafkaClient {com.sun.security.auth.module.Krb5LoginModule requireduseKeyTab=truestoreKey=trueuseTicketCache=falsekeyTab="user.keytab"principal="user@XXXXX.COM";
};Client {com.sun.security.auth.module.Krb5LoginModule requireduseKeyTab=truestoreKey=truekeyTab="user.keytab"principal="user@XXXXX.COM";
}
五、其他
如下:报错大多是因为kafka没连接上,也多因为kerberos认证没通过。请仔细检查jaas-*.conf先关的内容。kafka使用jaas.conf配置kerberos。
[Kafka Offset Reader] clients.NetworkClient: [Consumer clientId=consumer-2, groupId=spark-kafka-relation-589f753a-51b2-498d-971e-e513b067ca87-driver-0] Bootstrap broker xxx.com:6667 (id: -3 rack: null) disconnected
2024-10-24 13:17:34,787 WARN [Kafka Offset Reader] clients.NetworkClient: [Consumer clientId=consumer-2, groupId=spark-kafka-relation-589f753a-51b2-498d-971e-e513b067ca87-driver-0] Bootstrap broker broker xxx.com:6667 (id: -1 rack: null) disconnected
相关文章:

【spark】spark structrued streaming读写kafka 使用kerberos认证
spark版本:2.4.0 官网 Spark --files使用总结 Spark --files理解 一、编写jar import org.apache.kafka.clients.CommonClientConfigs import org.apache.kafka.common.config.SaslConfigs import org.apache.spark.sql.SparkSession import org.apache.spark.sql.streaming.T…...

【脚本】B站视频AB复读
控制台输入如下代码,回车 const video document.getElementsByTagName("video")[0];//获取bpx-player-control-bottom-center容器,更改其布局方式const div document.getElementsByClassName("bpx-player-control-bottom-center")[0];div.sty…...
leetcode - 257. 二叉树的所有路径
257. 二叉树的所有路径 题目 解决 做法一:深度优先搜索 回溯 深度优先搜索(Depth-First Search, DFS)是一种用于遍历或搜索树或图的算法。这种搜索方式会尽可能深地探索每个分支,直到无法继续深入为止,然后回溯到上…...

python 相关
python 1. pip 安装某个版本范围的软件 pip install “elasticsearch>6,<7” pip install elasticsearchX.Y.Z 2. pip 查看包版本 pip show pandas 3. pip 下载whl包 https://tendcode.com/subject/article/pip-offline-download/ (更多平台与架构)pip downl…...

静态分析2:控制流分析(构建CFG)
参考:南京大学《软件分析》课程2 1、控制流分析 控制流分析实际上指的是构建控制流图(Control Flow Graph,CFG)CFG是静态分析的基础数据结构CFG的节点可以是单个指令、基本块(Basic Block,BB)…...

Linux 应用领域
目录 服务器领域 桌面环境 软件开发 数据分析与科学计算 嵌入式系统 虚拟化和云计算 人工智能与机器学习 物联网(IoT) 网络安全 服务器领域 Linux在服务器领域的应用是其最为广泛和成熟的领域之一。由于其开源、稳定、高效和安全的特性…...

FPM383C指纹模块超详解 附驱动
0. 本人使用环境介绍 0.1 硬件环境 ESP32-C3FPM383C指纹模块一根破旧的usb数据线 0.2 软件环境 Clion2024.2.2ESP-IDF5.3.1Clion插件ESP-IDF 1. 硬件接口说明 1.1 UART UART 缺省波特率为 57.6Kbps,数据格式:8 位数据位,2 位停止位&am…...

若依框架篇-若依集成 X-File-Storage 框架(实现图片上传阿里云 OSS 服务器)、EasyExcel 框架(实现 Excel 数据批量导入功能)
🔥博客主页: 【小扳_-CSDN博客】 ❤感谢大家点赞👍收藏⭐评论✍ 文章目录 1.0 实现使用 Excel 文件批量导入 1.1 导入功能的前端具体实现 1.2 导入功能的后端具体实现 1.3 使用 EasyExcel 框架实现 Excel 读、写功能 1.4 将 Easy Excel 集成到…...

.rmallox勒索病毒肆虐:如何有效防范与应对
引言 在当今这个数字化时代,网络安全已成为一个不可忽视的重要议题。随着信息技术的飞速发展,网络空间的安全威胁也日益复杂多变。病毒、木马、勒索软件等恶意程序层出不穷,比如.rmallox勒索病毒。它们利用先进的技术手段,如代码…...

人工智能能否影响未来生活:一场深刻的社会与技术变革
随着人工智能技术的不断发展,我们已经目睹了它在各行各业掀起的巨大变革浪潮。从医疗行业的病例诊断、药物研发,到企业运营的数据分析、智能决策,再到日常生活中的智能语音助手、自动驾驶汽车、智能家居,人工智能正以前所未有的速…...

cmu 15-445学习笔记-3 存储引擎
03 Database Storage-Part Ⅰ 数据库存储上半部分 数据库分层划分结构图: Disk Manager:存储引擎,管理磁盘上的文件Bufferpool Manager:管理内存的缓存池Access Methods:访问方法Operator Execution:执行…...

[linux]和windows间传输命令scp 执行WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED!错误解决
[linux]和windows间传输命令scp 执行WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED!错误解决. 现象: 原因: 接收方服务器系统做了某些更改,导致登录时会报错。主要因为接收方服务器对登录过它的主机都会把该主机登录标识证书记录下来&a…...

C++ | Leetcode C++题解之第518题零钱兑换II
题目: 题解: class Solution { public:int change(int amount, vector<int>& coins) {vector<int> dp(amount 1), valid(amount 1);dp[0] 1;valid[0] 1;for (int& coin : coins) {for (int i coin; i < amount; i) {valid[…...

高并发-负载均衡
负载均衡在微服务架构中是一个重要的组成部分,旨在优化资源利用、提高服务可用性和确保系统的高可扩展性。以下是对微服务中的负载均衡的详细介绍,包括其原理、类型、实现方式以及相关的技术。 一、负载均衡的原理 负载均衡的基本原理是将进入系统的请…...

Docker 常用命令全解析:提升对雷池社区版的使用经验
Docker 常用命令解析 Docker 是一个开源的容器化平台,允许开发者将应用及其依赖打包到一个可移植的容器中。以下是一些常用的 Docker 命令及其解析,帮助您更好地使用 Docker。 1. Docker 基础命令 查看 Docker 版本 docker --version查看 Docker 运行…...

基于 Postman 和 Elasticsearch 测试乐观锁的操作流程
鱼说,你看不到我眼中的泪,因为我在水中。水说,我能感觉到你的泪,因为你在我心中。 -村上春树 在分布式系统中,多个并发操作对同一资源的修改可能导致数据不一致。为了解决这种问题,Elasticsearch 提供了乐观…...

如何从PPT中导出600dpi的高清图
Step1. 修改PPT注册表 具体过程,参见如下链接:修改ppt注册表,导出高分辨率图片 Step2. 打开PPT,找到自己想要保存的图,选中图像,查看图像尺寸并记录 Step3. 重新新建一个PPT,并根据记录的图片…...
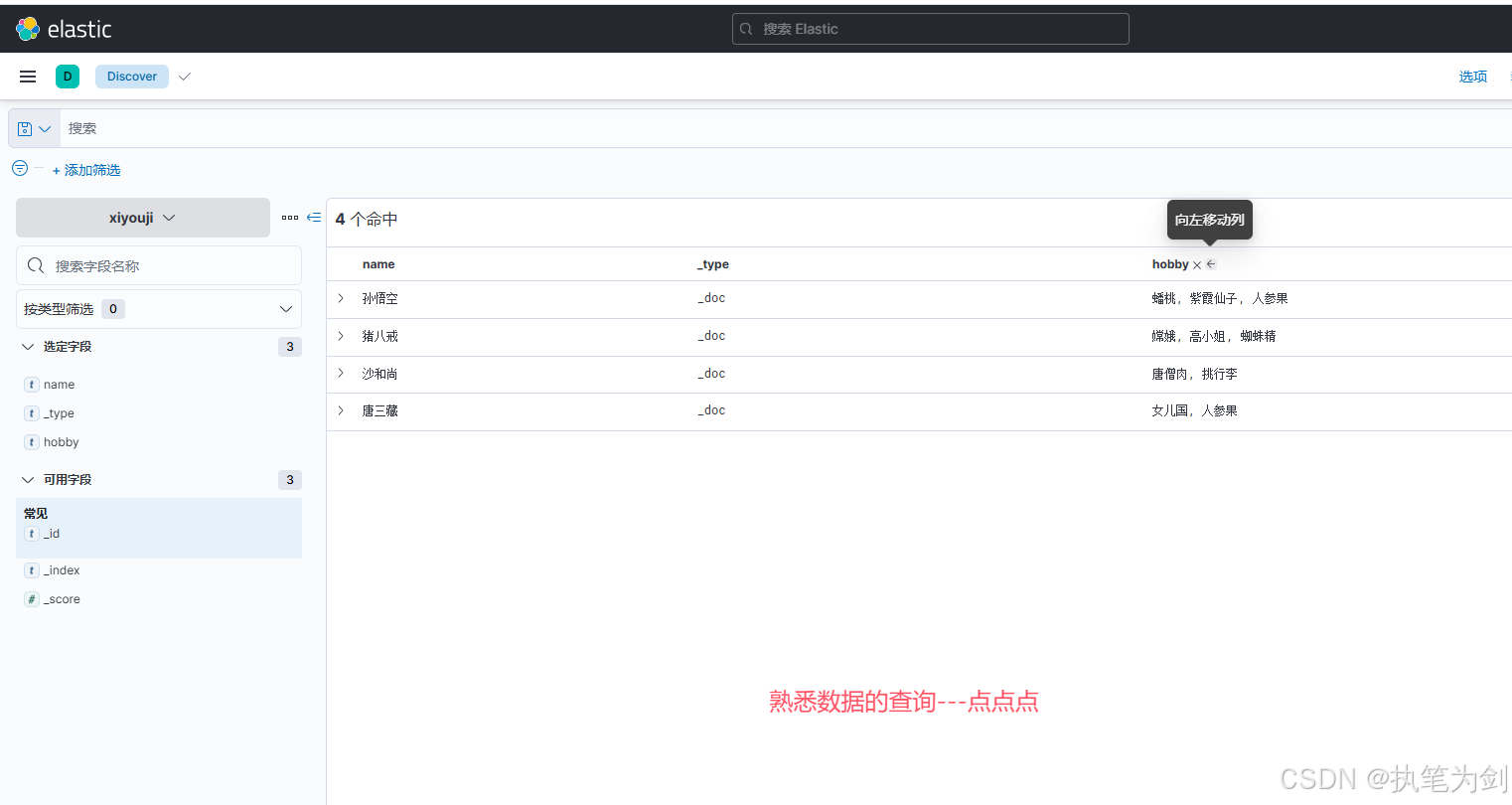
day01-ElasticStack+Kibana
ElasticStack-数据库 #官网https://www.elastic.co/cn/ #下载7.17版环境准备 主机名IP系统版本VMware版本elk110.0.0.91Ubuntu 22.04.417.5.1elk210.0.0.92Ubuntu 22.04.417.5.1elk310.0.0.93Ubuntu 22.04.417.5.1 单机部署ES 1.下载ES软件包,放到/usr/local下 […...

HTML 约束验证
HTML5引入了表单相关的一些新机制:它为<input>元素和约束验证增加了一些新的语义类型,使得客户端检查表单内容变得容易。基本上,通过设置一些新的属性,常用的约束条件可以无需 JavaScript 代码而检测到;对于更复…...

vue3项目开发一些必备的内容,该安装安装,该创建创建
重新整理了一下项目开发必备的一些操作,以后直接复制黏贴运行,随着项目开发,后期会陆续补充常用插件或组件等 如果你是还没有安装过的新人,建议从《通过安装Element UI/Plus来学习vue之如何创建项目、搭建vue脚手架、npm下载、封装…...

Python 爬虫数据处理:重复页面数据智能合并去重
前言 在规模化 Python 爬虫采集项目中,重复页面数据是高频出现的核心问题,源于站点分页逻辑错乱、镜像页面分发、动态接口返回冗余数据、多入口同源页面采集等多重因素。重复数据若不做处理,不仅会造成数据库存储冗余、占用服务器资源&#…...

多层板钻靶精度为什么越来越难控制?一套X-RAY预对位+六轴机械手的自动化方案解析
背景在高多层板和HDI板生产中,钻靶精度是影响良率的核心环节之一。压合后内层靶点被外层铜箔覆盖,传统视觉系统只能识别表面标记,无法获取真实的内层位置数据。同时,上料对位若依赖人工操作,放板角度和位置存在批次差异…...

macOS桌面歌词神器LyricsX:免费开源歌词同步工具完整指南
macOS桌面歌词神器LyricsX:免费开源歌词同步工具完整指南 【免费下载链接】Lyrics Swift-based iTunes plug-in to display lyrics on the desktop. 项目地址: https://gitcode.com/gh_mirrors/lyr/Lyrics LyricsX是一款专为macOS设计的开源桌面歌词显示工具…...

MTKClient实战指南:联发科设备刷机与逆向工程全面解决方案
MTKClient实战指南:联发科设备刷机与逆向工程全面解决方案 【免费下载链接】mtkclient MTK reverse engineering and flash tool 项目地址: https://gitcode.com/gh_mirrors/mt/mtkclient MTKClient是一款专为联发科芯片设备设计的开源逆向工程与刷机工具&am…...
:超出3个指标即触发强制重构——你达标了吗?)
DeepSeek Clean Code终极阈值(v2.3.1正式版):超出3个指标即触发强制重构——你达标了吗?
更多请点击: https://intelliparadigm.com 第一章:DeepSeek Clean Code终极阈值的演进与哲学内核 DeepSeek Clean Code 的“终极阈值”并非静态指标,而是代码可维护性、语义清晰度与执行确定性三者动态收敛的临界点。它源于对 LLM 推理链中 …...

202X年CSDN年度技术趋势大预测
好的,以下是一篇关于CSDN年度技术趋势预测的技术文章大纲:202X年CSDN年度技术趋势预测:引领未来的技术变革一、引言技术发展的加速与变革年度技术趋势对行业的影响本文预测的依据与方法论二、人工智能与生成式AI的深化应用大模型技术的演进方…...

上午题_程序设计语言
编译程序和解释程序...

如何快速找回压缩包密码:ArchivePasswordTestTool完整使用指南
如何快速找回压缩包密码:ArchivePasswordTestTool完整使用指南 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾经遇到过…...

百度网盘Mac版破解SVIP插件:3步实现免费高速下载的终极方案
百度网盘Mac版破解SVIP插件:3步实现免费高速下载的终极方案 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 还在为百度网盘Mac版的龟速下载…...

2026年项目管理工具测评:10款主流软件对比与企业选型建议
本文测评 ONES、Tower、Jira、Asana、monday、ClickUp、Notion、Trello、Microsoft Project、Smartsheet 十款项目管理工具,帮助选型人员从组织规模、项目复杂度、协作方式与治理需求出发,判断哪类项目管理工具更适合自身团队。一、10款项目管理工具速览…...