《大型语言模型实战指南:应用实践与场景落地》一文详解大型语言模型的11种微调方法
导读:大型预训练模型是一种在大规模语料库上预先训练的深度学习模型,它们可以通过在大量无标注数据上进行训练来学习通用语言表示,并在各种下游任务中进行微调和迁移。随着模型参数规模的扩大,微调和推理阶段的资源消耗也在增加。针对这一挑战,可以通过优化模型结构和训练策略来降低资源消耗。
一般来说,研究者的优化方向从两个方面共同推进:
- 一方面,针对训练参数过多导致资源消耗巨大的情况,可以考虑通过固定基础大型语言模型的参数,引入部分特定参数进行模型训练,大大减少了算力资源的消耗,也加速了模型的训练速度。比较常用的方法包括前缀调优、提示调优等。
- 另一方面,还可以通过固定基础大型语言模型的架构,通过增加一个“新的旁路”来针对特定任务或特定数据进行微调,当前非常热门的LoRA就是通过增加一个旁路来提升模型在多任务中的表现。
接下来,我们将详细介绍11种高效的大型语言模型参数调优的方法。
本文目录
- 前缀调优
- 提示调优
- P-Tuning v2
- LoRA
- DyLoRA
- AdaLoRA
- QLoRA
- QA-LoRA
- LongLoRA
- VeRA
- S-LoRA
- 总结
1前缀调优
前缀调优(Prefix Tuning)是一种轻量级的微调替代方法,专门用于自然语言生成任务。前缀调优的灵感来自于语言模型提示,前缀就好像是“虚拟标记”一样,这种方法可在特定任务的上下文中引导模型生成文本。
前缀调优的独特之处在于它不改变语言模型的参数,而是通过冻结LM参数,仅优化一系列连续的任务特定向量(即前缀)来实现优化任务。前缀调优的架构如图1所示。
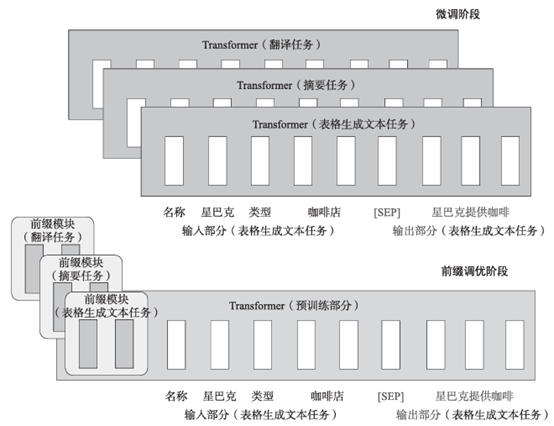
图1 前缀调优的架构
由于在训练中只需要为每个任务存储前缀,前缀调优的轻量级设计避免了存储和计算资源的浪费,同时保持了模型的性能,具有模块化和高效利用空间的特点,有望在NLP任务中提供高效的解决方案。
2提示调优
提示调优(Prompt Tuning)方法是由Brian Lester在论文“The Power of Scale for Parameter-Efficient Prompt Tuning”中提出的。
提示调优采用“软提示”(Soft Prompt)的方式,通过冻结整个预训练模型,只允许每个下游任务在输入文本前面添加k个可调的标记(Token)来优化模型参数,赋予语言模型能够执行特定的下游任务的能力。提示调优的架构如图2所示。

图2 提示调优的架构
在论文的实验对比中,对于T5-XXL模型,每个经过调整的模型副本需要110亿个参数,相较于为每个下游任务制作特定的预训练模型副本,提示调优需要的参数规模仅为20480个参数。该方法在少样本提示方面表现出色。
3P-Tuning v2
尽管提示调优在相应任务上取得了一定的效果,但当底座模型规模较小,特别是小于1000亿个参数时,效果表现不佳。为了解决这个问题,清华大学的团队提出了针对深度提示调优的优化和适应性实现——P-Tuning v2方法。
该方法最显著的改进是对预训练模型的每一层应用连续提示,而不仅仅是输入层。这实际上是一种针对大型语言模型的软提示方法,主要是将大型语言模型的词嵌入层和每个Transformer网络层前都加上新的参数。深度提示调优增加了连续提示的功能,并缩小了在各种设置之间进行微调的差距,特别是对于小型模型和困难的任务。
实验表明,P-Tuning v2在30亿到100亿个参数的不同模型规模下,以及在提取性问题回答和命名实体识别等NLP任务上,都能与传统微调的性能相匹敌,且训练成本大大降低。
4LoRA
微软公司在2021年提出了一种名为Low-Rank Adaptation(LoRA,低秩适配器)的方法。
LoRA的核心思想是通过冻结预训练模型的权重,并将可训练的秩分解矩阵注入Transformer架构的每一层,从而显著减少下游任务中可训练参数的数量。在训练过程中,只需要固定原始模型的参数,然后训练降维矩阵A和升维矩阵B。LoRA的架构如图3所示。

图3 LoRA的架构
具体来看,假设预训练的矩阵为 ,它的更新可表示为:
,它的更新可表示为: ,其中:
,其中: 。
。
与使用Adam微调的GPT-3 175B相比,LoRA可以将可训练参数的数量减少10000倍,并将GPU内存需求减少3倍。尽管LoRA的可训练参数较少,训练吞吐量较高,但与RoBERTa、DeBERTa、GPT-2和GPT-3等模型相比,LoRA在模型质量性能方面与微调相当,甚至更好。
5DyLoRA
但随着研究的深入,LoRA块存在两大核心问题:
- 一旦训练完成后,LoRA块的大小便无法更改,若要调整LoRA块的秩,则需重新训练整个模型,这无疑增加了大量时间和计算成本;
- LoRA块的大小是在训练前设计的固定超参,优化秩的过程需要精细的搜索与调优操作,仅设计单一的超参可能无法有效提升模型效果。
为解决上述问题,研究者引入了一种全新的方法—DyLoRA(动态低秩适应)。
研究者参考LoRA的基本架构,针对每个LoRA块设计了上投影(Wup)和下投影(Wdw)矩阵及当前LoRA块的规模范围R。为确保增加或减少秩不会明显阻碍模型的表现,在训练过程中通过对LoRA块对不同秩的信息内容进行排序,再结合预定义的随机分布中进行抽样,来对LoRA块镜像上投影矩阵和下投影矩阵截断,最终确认单个LoRA块的大小。DyLoRA的架构如图4所示。

图4 DyLoRA的架构
研究结果表明,与LoRA相比,使用DyLoRA训练出的模型速度可提升4~7倍,且性能几乎没有下降。此外,与LoRA相比,该模型在更广泛的秩范围内展现出了卓越的性能。
6AdaLoRA
正如DyLoRA优化方法一样,提出AdaLoRA的研究者也发现,当前LoRA存在的改进方向:
- 由于权重矩阵在不同LoRA块和模型层中的重要性存在差异,因此不能提前制定一个统一规模的秩来约束相关权重信息,需要设计可以支持动态更新的参数矩阵;
- 需要设计有效的方法来评估当前参数矩阵的重要性,并根据重要性程度,为重要性高的矩阵分配更多参数量,以提升模型效果,对重要性低的矩阵进行裁剪,进一步降低计算量。
根据上述思想,研究者提出了AdaLoRA方法,可以根据权重矩阵的重要性得分,在权重矩阵之间自适应地分配参数规模。在实际操作中,AdaLoRA采用奇异值分解(SVD)的方法来进行参数训练,根据重要性指标剪裁掉不重要的奇异值来提高计算效率,从而进一步提升模型在微调阶段的效果。
7QLoRA
Tim Dettmers等研究者在论文“QLoRA: Efficient Finetuning of Quantized LLMs”中提出了一种高效的模型微调方法——QLoRA。
QLoRA的架构如图5所示。

图5 QLoRA的架构
QLoRA的创新内容主要如下:
- 4bit NormalFloat(NF4)。NF4是一种新型数据类型,它对正态分布的权重来说是信息理论上的最优选择。
- 双重量化技术。双重量化技术减少了平均内存的使用,它通过对已量化的常量进行再量化来实现。
- 分页优化器。分页优化器有助于管理内存峰值,防止梯度检查点时出现内存不足的错误。
实验表明,QLoRA技术使得研究者能够在单个48GB GPU上微调650亿个参数规模的模型,同时维持16bit精度任务的完整性能。例如,在训练Guanaco模型时,仅需在单个GPU上微调24h,即可达到与ChatGPT相当的99.3%性能水平。通过QLoRA微调技术,可以有效降低模型微调时的显存消耗。
8QA-LoRA
大型语言模型取得了迅猛发展,尽管在许多语言理解任务中表现强大,但由于巨大的计算负担,尤其是在需要将它们部署到边缘设备时,应用受到了限制。具体而言,预训练权重矩阵的每一列只伴随一个缩放和零参数对,但有很多LoRA参数。这种不平衡不仅导致了大量的量化误差(对LLM的准确性造成损害),而且使得将辅助权重整合到主模型中变得困难。
在论文“QA-LoRA: Quantization-aware Low-rank Adaptation of large language models”中,研究者提出了一种量化感知的低秩适应(QA-LoRA)算法。该方法来源于量化和适应的自由度不平衡的思想。
研究者提出采用分组运算符的方式,旨在增加量化自由度的同时减少适应自由度。
QA-LoRA的实现简便,仅需几行代码,同时赋予原始的LoRA两倍的能力:
- 在微调过程中,LLM的权重被量化(如INT4),以降低时间和内存的使用;
- 微调后,LLM和辅助权重能够自然地集成到一个量化模型中,而不损失准确性。
通过在LLaMA和LLaMA2模型系列的实验中证明,QA-LoRA在不同的微调数据集和下游场景中验证了其有效性。
如图6所示,与之前的适应方法LoRA和QLoRA相比,QA-LoRA在微调和推理阶段都具有更高的计算效率。更重要的是,由于不需要进行训练后量化,因此它不会导致准确性损失。在图6中展示了INT4的量化,但QA-LoRA可以推广到INT3和INT2。

图6 LoRA、QLoRA、QA-LoRA的架构对比
9LongLoRA
通常情况下,用较长的上下文长度训练大型语言模型的计算成本较高,需要大量的训练时间和GPU资源。
为了在有限的计算成本下扩展预训练大型语言模型的上下文大小,研究者在论文“LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models”中提出了LongLoRA的方法,整体架构如图7所示。

图7 LongLoRA的整体架构
LongLoRA在两个方面进行了改进:
- 虽然在推理过程中需要密集的全局注意力,但通过采用稀疏的局部注意力,可以有效地进行模型微调。在LongLoRA中,引入的转移短暂的注意力机制能够有效地实现上下文扩展,从而在性能上与使用香草注意力(Vanilla Attention)进行微调的效果相似;
- 通过重新审视上下文扩展的参数高效微调机制,研究者发现在可训练嵌入和规范化的前提下,用于上下文扩展的LoRA表现良好。
LongLoRA在从70亿、130亿到700亿个参数的LLaMA2模型的各种任务上都取得了良好的结果。具体而言,LongLoRA采用LLaMA2-7B模型,将上下文长度从4000个Token扩展到10万个Token,展现了其在增加上下文长度的同时保持了高效计算的能力。这为大型语言模型的进一步优化和应用提供了有益的思路。
10VeRA
LoRA是一种常用的大型语言模型微调方法,它在微调大型语言模型时能够减少可训练参数的数量。然而,随着模型规模的进一步扩大或者需要部署大量适应于每个用户或任务的模型时,存储问题仍然是一个挑战。
研究者提出了一种基于向量的随机矩阵适应(Vector-based Random matrix Adaptation,VeRA)的方法,VeRA的实现方法是通过使用一对低秩矩阵在所有层之间共享,并学习小的缩放向量来实现这一目标。
与LoRA相比,VeRA成功将可训练参数的数量减少了10倍,同时保持了相同的性能水平。VeRA与LoRA的架构对比如图8所示,LoRA通过训练低秩矩阵和来更新权重矩阵,中间秩为。在VeRA中,这些矩阵被冻结,在所有层之间共享,并通过可训练向量和进行适应,从而显著减少可训练参数的数量。在这种情况下,低秩矩阵和向量可以合并到原始权重矩阵中,不引入额外的延迟。这种新颖的结构设计使得VeRA在减少存储开销的同时,还能够保持和LoRA相媲美的性能,为大型语言模型的优化和应用提供了更加灵活的解决方案。

图8 VeRA与LoRA的架构对比
实验证明,VeRA在GLUE和E2E基准测试中展现了其有效性,并在使用LLaMA2 7B模型时仅使用140万个参数的指令就取得了一定的效果。这一方法为在大型语言模型微调中降低存储开销提供了一种新的思路,有望在实际应用中取得更为显著的效益。
11S-LoRA
LoRA作为一种参数高效的大型语言模型微调方法,通常用于将基础模型适应到多种任务中,从而形成了大量派生自基础模型的LoRA模型。由于多个采用LoRA形式训练的模型的底座模型都为同一个,因此可以参考批处理模式进行推理。
据此,研究者提出了一种S-LoRA(Serving thousands of con current LoRA adapters)方法,S-LoRA是一种专为可伸缩地服务多个LoRA适配器而设计的方法。
S-LoRA的设计理念是将所有适配器存储在主内存中,并在GPU内存中动态获取当前运行查询所需的适配器。为了高效使用GPU内存并减少碎片,S-LoRA引入了统一分页。统一分页采用统一的内存池来管理具有不同秩的动态适配器权重以及具有不同序列长度的KV缓存张量。此外,S-LoRA还采用了一种新颖的张量并行策略和高度优化的自定义CUDA核心,用于异构批处理LoRA计算。这些特性使得S-LoRA能够在单个GPU或跨多个GPU上提供数千个LoRA适配器,而开销相对较小。
通过实验发现,S-LoRA的吞吐量提高了4倍多,并且提供的适配器数量增加了数个数量级。因此,S-LoRA在实现对许多任务特定微调模型的可伸缩服务方面取得了显著进展,并为大规模定制微调服务提供了潜在的可能性。
12总结
本文从背景、来源、技术路线及性能等方面综述了11种在模型参数调优阶段进行的方法,其中前缀调优、提示调优和P-Tuning v2属于引入特定参数来减少算力消耗、提升训练速度;基于LoRA的各种方法的基本思想是添加新的旁路,对特定任务或特定数据进行微调。
开源社区Hugging Face将这11种方法归纳为高效参数调优方法(Parameter-Efficient Fine-Tuning,PEFT)。PEFT方法能够在不微调所有模型参数的情况下,有效地让预训练语言模型适应各种下游应用。PEFT方法只微调了少量额外的模型参数,从而大幅降低了大模型训练和微调的计算与存储成本。通过合理使用PEFT方法,不但能提高模型的训练效率,还能在特定任务上达到大型语言模型的效果。有关基于PEFT的微调实战案例,推荐您阅读刘聪、沈盛宇、李特丽和杜振东的新书《大型语言模型实战指南:应用实践与场景落地》。
那么,如何系统的去学习大模型LLM?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~

篇幅有限,部分资料如下:
👉LLM大模型学习指南+路线汇总👈
💥大模型入门要点,扫盲必看!

💥既然要系统的学习大模型,那么学习路线是必不可少的,这份路线能帮助你快速梳理知识,形成自己的体系。

👉大模型入门实战训练👈
💥光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉国内企业大模型落地应用案例👈
💥《中国大模型落地应用案例集》 收录了52个优秀的大模型落地应用案例,这些案例覆盖了金融、医疗、教育、交通、制造等众多领域,无论是对于大模型技术的研究者,还是对于希望了解大模型技术在实际业务中如何应用的业内人士,都具有很高的参考价值。 (文末领取)

💥《2024大模型行业应用十大典范案例集》 汇集了文化、医药、IT、钢铁、航空、企业服务等行业在大模型应用领域的典范案例。

👉LLM大模型学习视频👈
💥观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。 (文末领取)

👉640份大模型行业报告👈
💥包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

👉获取方式:
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓

相关文章:
《大型语言模型实战指南:应用实践与场景落地》一文详解大型语言模型的11种微调方法
导读:大型预训练模型是一种在大规模语料库上预先训练的深度学习模型,它们可以通过在大量无标注数据上进行训练来学习通用语言表示,并在各种下游任务中进行微调和迁移。随着模型参数规模的扩大,微调和推理阶段的资源消耗也在增加。…...

嵌入式浏览器 -- Chromium VS Firefox
嵌入式浏览器概念 嵌入式浏览器是嵌入式系统中的核心组件之一,用于为设备提供网络访问能力和内容显示功能。与传统PC浏览器相比,嵌入式浏览器更加注重性能优化和资源效率,同时确保核心功能可用,如HTML渲染、JavaScript支持和多媒…...

权限大、数量多、破坏强、管理难......企业特权访问管理怎么管?
特权账号,通往企业数据大门的“钥匙”。 它权限大,具有高危命令或操作的执行权限; 破坏性强,操作可能影响他人使用或其他系统故障; 信息泄露风险大,操作可能获取别人或其他系统相关隐私信息;…...

UE5 第一人称示例代码阅读0 UEnhancedInputComponent
UEnhancedInputComponent使用流程 我的总结示例分析firstthenand thenfinally&代码关于键盘输入XYZ 我的总结 这个东西是一个对输入进行控制的系统,看了一下第一人称例子里,算是看明白了,但是感觉这东西使用起来有点绕,特此梳…...

如何在Linux下安装和配置Docker
文章目录 安装前的准备在Debian/Ubuntu上安装Docker添加Docker仓库安装Docker验证安装 在CentOS/RHEL上安装Docker安装必要的软件包设置Docker仓库安装Docker启动Docker服务 Docker的基本使用拉取一个镜像运行一个容器 配置Docker创建Docker目录使用非root用户运行Docker 结语 …...

apisix的原理及作用,跟spring cloud gateway有什么区别?
apache APISIX 是一个高性能、可扩展的开源 API 网关,它主要用于处理 API 请求、流量管理、安全控制和服务治理。APISIX 可以将复杂的服务架构中的不同服务通过统一的网关来进行管理和监控,为微服务架构提供了便捷的流量入口管理方式。 APISIX 的原理 …...

华为HarmonyOS实现实时语音识别转文本
场景介绍 将一段音频信息(短语音模式不超过60s,长语音模式不超过8h)转换为文本,音频信息可以为pcm音频文件或者实时语音。 开发步骤 在使用语音识别时,将实现语音识别相关的类添加至工程。 import { speechRecogni…...

DIY可视化-uniapp悬浮菜单支持拖动、吸附-代码生成器
在Uniapp中,悬浮菜单支持拖动和吸附功能,可以为用户带来更加灵活和便捷的操作体验。以下是对这两个功能的详细解释: 悬浮菜单支持拖动 提高用户体验:用户可以根据自己的需要,将悬浮菜单拖动到屏幕上的任意位置&#x…...

HTTP cookie 与 session
一.Cookie 定义: 是服务器发送到用户浏览器并保存在浏览器上的一小块数据, 它会在浏览器之后向同一服务器再次发起请求时被携带并发送到服务器上。 通常, 它用于告知服务端两个请求是否来自同一浏览器, 如保持用户的登录状态、 …...

智慧停车场导航系统架构及反向寻车系统解决方案
一、系统概述: 随着当前室内定位导航技术在大型公共场所如政务中心、商业综合体、车站中的应用越来越多,人们对智慧停车场的需求也日益凸显出来,并且智慧停车场对大型公共场所智慧化的整体建设起到重要作用。如何更有效提高停车效率…...

【小程序上传图片封装2024,支持多图,带进度,上传头像】
import config from ./config;// 支持多图,显示进度 export function uploadImages(count 1, sourceType, onLoading null, showProgress false, fileKey file) {return new Promise((resolve, reject) > {wx.chooseMedia({count: count, // 可以选择的图片数…...

[A-14]ARMv8/ARMv9-Memory-内存模型的类型(Device Normal)
ver0.1 [看前序文章有惊喜。] 前言 前面花了很大的精力把ARM构建的VMSA中的几个核心的议题给大家做了介绍,相信大家已经能够理解并掌握ARM的内存子系统的工作原理大致框架。接下来我们会规划一些文章,对ARM内存子系统的一些细节做一下介绍,使ARM的内存子系统更加的丰满。本…...

驾校管理系统|基于java和小程序的驾校管理系统设计与实现(源码+数据库+文档)
驾校管理系统平台 目录 基于java和小程序的驾校管理系统设计与实现 一、前言 二、系统设计 三、系统功能设计 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介绍:✌️大厂码农|毕设布道师&#…...

@Mapper使用中遇到的问题解法汇总
最近终于有时间写点代码相关的文章了,工作真的太忙了,果然又要测试又要开发的人最🐂🐴。 1.查询数据库有数据,但是代码中写select语句的时候查出为null Select("SELECT * FROM xx_manager order by id limit 1&q…...

深度学习:YOLO V3 网络架构解析
引言 YOLO V3(You Only Look Once Version 3)是YOLO系列算法的第三个版本,相比之前的版本,它在多个方面进行了优化和改进,不仅提升了检测精度,还保持了较快的检测速度。本文将详细介绍YOLO V3的主要改进以…...

SpringCloudAlibaba-Sentinel-熔断与限流
版本说明 <spring.boot.version>3.2.0</spring.boot.version> <spring.cloud.version>2023.0.0</spring.cloud.version> <spring.cloud.alibaba.version>2023.0.1.2</spring.cloud.alibaba.version>是什么 能干嘛 面试题 服务雪崩 安装使…...

mysql中的mvcc理解
是什么:MVCC指的是在读已提交、可重复读这两种隔离级别下的事务在执行普通的select操作时,访问记录的版本链的过程,可以使不同事务的读写操作并发执行,提高性能。 MVCC 隐藏字段 undo log 版本链 ReadView 1.隐藏字段…...

ETF申购赎回指南:详解注意事项与低费率券商推荐!
ETF 申购&赎回 ETF申购赎回是个啥业务? 01 ETF申购、赎回是一种交易委托方式,指投资者通过申购方式(买入方向)获得ETF份额,通过赎回的方式(卖出方向)换掉/卖出ETF份额。ETF申购,通常是通过一篮子成…...
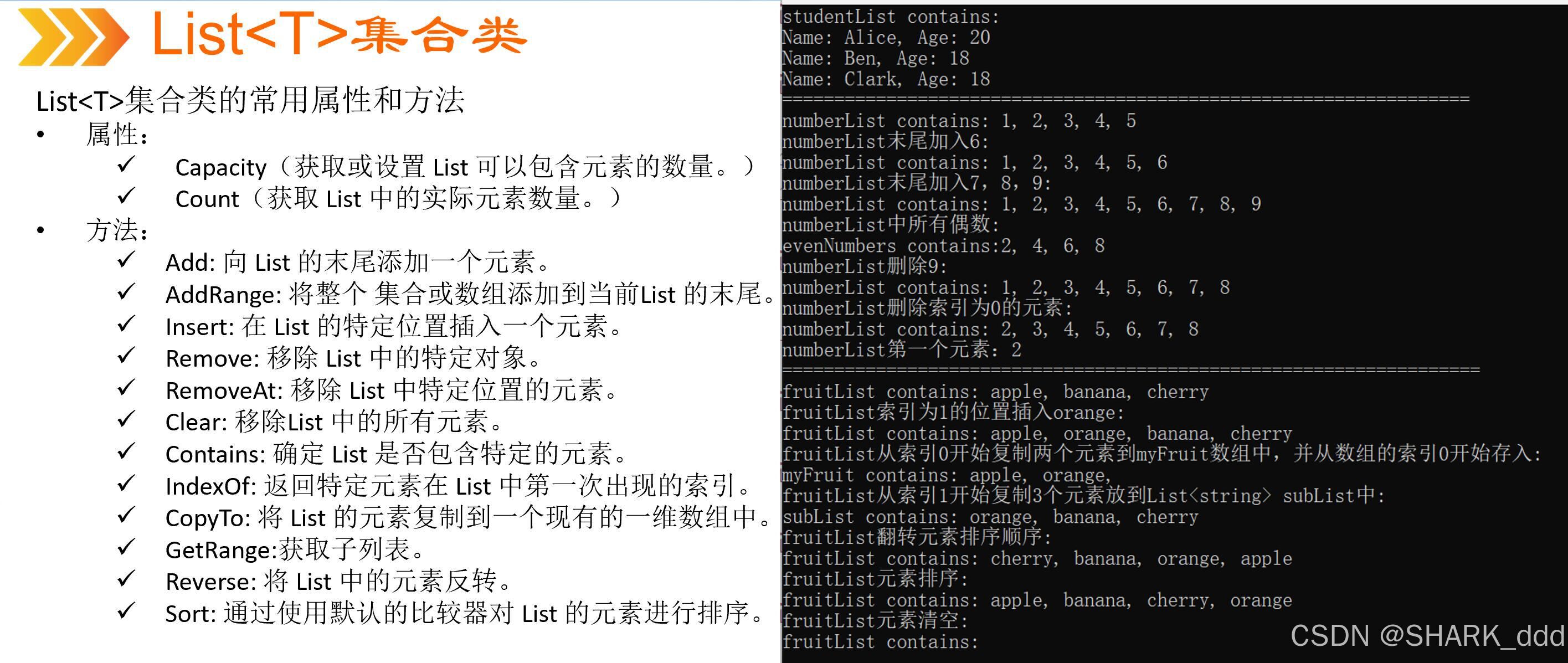
List<T>属性和方法使用
//author:shark_ddd using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks;//使用函数来减少长度namespace List_T {class Student{public string Name { get; set; }public int Age { get; set; …...

记一次:使用使用Dbeaver连接Clickhouse
前言:使用了navicat连接了clickhouse我感觉不太好用,就整理了一下dbeaver连接 0、使用Navicat连接clickhouse 测试连接 但是不能双击打开,可是使用命令页界面,右键命令页界面,然后可以用sql去测试 但是不太好用&#…...

SD-PPP:跨软件创意能量流的无缝协同解决方案
SD-PPP:跨软件创意能量流的无缝协同解决方案 【免费下载链接】sd-ppp Getting/sending picture from/to Photoshop in ComfyUI or SD 项目地址: https://gitcode.com/gh_mirrors/sd/sd-ppp 问题诊断:创意工作流中的效率断层与技术瓶颈 创意能量流…...
无需训练直接使用:lite-avatar形象库150+高质量数字人体验
无需训练直接使用:lite-avatar形象库150高质量数字人体验 1. 数字人技术的新选择 在虚拟主播、智能客服、在线教育等场景快速发展的今天,数字人技术正变得越来越重要。然而,传统数字人开发面临一个关键痛点:从零开始训练一个高质…...

Realistic Vision V5.1写实人像生成案例:汉服/西装/运动装三类风格统一输出
Realistic Vision V5.1写实人像生成案例:汉服/西装/运动装三类风格统一输出 1. 项目概述 Realistic Vision V5.1虚拟摄影棚是一款基于当前最先进的写实人像生成模型开发的本地化工具。这个解决方案让普通用户无需专业摄影设备,就能生成媲美单反相机拍摄…...

Face3D.ai Pro优化升级:从12万面到流畅交互,模型轻量化实战
Face3D.ai Pro优化升级:从12万面到流畅交互,模型轻量化实战 1. 为什么需要3D模型轻量化 在数字内容创作领域,高精度3D人脸模型的需求正在爆发式增长。从影视特效到虚拟主播,从医美模拟到游戏角色,12万面级别的高精度…...

WOPI协议实战:从零开始将Office编辑器嵌入你的Web应用
1. 为什么你的Web应用需要WOPI协议 第一次听说WOPI协议时,我也是一头雾水。直到接手一个企业网盘项目,客户要求在网页里直接编辑Office文档,我才真正理解它的价值。想象一下:用户在你的SaaS平台点击Word文档,不需要下载…...

从理论到实践:深入解析有源滤波器的设计与应用
1. 有源滤波器的核心原理与分类 有源滤波器是现代电子系统中的关键组件,它通过运算放大器与无源元件(电阻、电容)的协同工作,实现对特定频率信号的选择性处理。与无源滤波器相比,有源滤波器最显著的优势在于能够提供信…...

AppleRa1n完整指南:iOS 15-16激活锁绕过的3个关键步骤
AppleRa1n完整指南:iOS 15-16激活锁绕过的3个关键步骤 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n AppleRa1n是一款专为iOS 15至16.6.1系统设计的专业激活锁绕过工具,通过整…...

.NET 9实战|最新C# AI Agent开发,Semantic Kernel+OpenClaw双剑合璧
文章目录别再用Python写Agent了,C#也能整!先搞明白:Semantic Kernel和OpenClaw到底是个啥?环境准备:.NET 9装起来,5分钟搞定第一招:Semantic Kernel基础,先把AI大脑接进来第二招&…...

Gemini Embedding 2:五大模态统归一境,跨模态 Agent 的最强“大脑”!
本文内容来源于谷歌官方,由谷歌云钻石合作伙伴、谷歌地图一级代理商 CloudAce 深圳云一进行翻译发布。导语:Google 正式发布了基于 Gemini 架构构建的首款全多模态嵌入模型 Gemini Embedding 2 的公开预览版 。该模型打破了传统文本嵌入的局限࿰…...

指纹浏览器为什么要自建IP检测?基于IP数据云离线库的架构实践
一、为什么指纹浏览器必须自建IP检测? 2026年,亚马逊、Temu等平台的风控已从“指纹识别”升级到“IP信誉优先”。一个被标记为“数据中心”或“高代理风险”的IP,即使浏览器指纹伪装得再完美,也会在登录瞬间被判定为“非自然人操…...