天池蚂蚁AFAC大模型挑战赛-冠军方案(含代码)
天池-蚂蚁AFAC大模型挑战赛-冠军方案
===================================================================================================================
前言
❝
作者
彭欣怡 华东师大; 马千里 虾皮; 戎妍 港科广
说在前面
在当今信息技术迅猛发展的背景下,大模型技术已经成为推动人工智能领域进步的重要力量。
前段时间备受瞩目的AFAC赛题聚焦于金融对话领域,旨在推动大模型在金融场景中的应用和落地。我们有幸脱颖而出,拿到冠军。技术之路永无止境,每一次的成功都是新的起点,所以在这里分享我们团队在其中的一些想法,期望能和大家共同进步。
比赛链接
https://tianchi.aliyun.com/competition/entrance/532193/rankingList
赛题背景
参赛者需要根据用户的自然语言查询(用户请求),从给定的API集合中筛选出合适的API列表,设计出正确的API调用逻辑(模型回答),并生成准确的答案。
数据案例解析
下面先给出一个样本案例,帮助大家理解比赛的目标。
-
用户请求(input)
我一年前购买了2000元浙商智选先锋A基金,并且在6个月前追加了3000元,我到现在总的收益是多少? -
模型回答(output)
{ "relevant APIs": [{ "api_id": "0", "api_name": "查询代码", "required_parameters": [["浙商智选先锋一年持有期混合型证券投资基金A类"]], "rely_apis": [], "tool_name": "基金查询" }, { "api_id": "1", "api_name": "查询近期收益率", "required_parameters": ["api_0的结果", "1年"], "rely_apis": ["0"], "tool_name": "基金查询" }, { "api_id": "2", "api_name": "查询近期收益率", "required_parameters": ["api_0的结果", "6个月"], "rely_apis": ["0"], "tool_name": "基金查询" }, { "api_id": "3", "api_name": "乘法计算", "required_parameters": ["api_1的结果", "2000"], "rely_apis": ["1"], "tool_name": "数值计算" }, { "api_id": "4", "api_name": "乘法计算", "required_parameters": ["api_2的结果", "3000"], "rely_apis": ["2"], "tool_name": "数值计算" }, { "api_id": "5", "api_name": "加法计算", "required_parameters": ["api_3的结果", "api_4的结果"], "rely_apis": ["3", "4"], "tool_name": "数值计算" }], "result": ["api_5的结果"] }
- 模型回答解析
这段API链的意思是: 首先提取用户提到的基金名(产品),用"查询代码"提取该产品。然后,根据用户的需求,用"查询近期收益率"提取该产品的近期信息,如一年收益率。最后,用四则运算组合几个数值结果,拿到用户想要的信息并返回。
评价指标
-
评价方法采用API运行通过率作为评价标准,官网给出的具体计算方法如下:
-
最终得分 = 主指标*0.8 + 副指标*0.2 -
执行准确率(主指标) : 执行后得到结果的准确率 -
逻辑准确率(副指标) : 各种出入参的逻辑准确率 -
抖个激灵为了简化评测逻辑hē hē,实际是用字符串提取方法进行静态评估的,但我们没从中找到空子
[旺柴]。
赛题理解
根据对样本进行分析,再结合一些经验,我们可以总结出比赛的三个要点:
-
标准产品名提取 查询类别API需要传入标准产品名(e.g. 浦发银行)才能执行,但query中只有缩写(e.g. 浦发最近一月的最高价是多少),若不加入提示,大模型很难还原真实的标准名称。
-
用户意图识别 根据所需要调用的API,可以把用户意图分为4类:基金查询、股票查询、条件选基、条件选股。不同的意图用到的API有较大不同,规范也有差异。
-
相关例子召回 若要让大模型理解各种API的用法,需要给出相似的例子,让模型从例子中理解。例子与目标query的相关性极大程度的影响了模型表现,若只给标准例子,模型难以学会API的规范用法。
- 具体样例
| 用户查询 | 产品名 | 用户意图 | 部分标签 |
|---|---|---|---|
| 我打算用100万元买三羊马的股票,如果按照三羊马的最高价来计算,我能买多少股呢 | 三羊马 | 股票查询 | {“API_id”: “0”, “API_name”: “查询代码”, “required_parameters”: [[“三羊马”]], “rely_APIs”: [], “tool_name”: “股票查询”} |
| 上周结束的时候,有哪些股票的收盘价是不超过0.47元的呢? | / | 条件选股 | {“API_id”: “0”, “tool_name”: “条件选股”, “API_name”: “查询收盘价”, “required_parameters”: [“小于”, “0.47”, “上周”], “rely_APIs”: []} |
| 我今年5月1日用5000块买的国金金腾通C,如果我现在全部卖出,交易费用是多少 | 国金金腾通货币市场证券投资基金C类 | 条件选股 | {“API_id”: “0”, “API_name”: “查询代码”, “required_parameters”: [[“国金金腾通货币市场证券投资基金C类”]], “rely_APIs”: [], “tool_name”: “基金查询”} |
| 请问有哪些基金最近一个月中最长的解套期是20天,并且在今年已经创下新高达70次的? | / | 条件选基 | {“API_id”: “0”, “tool_name”: “条件选基”, “API_name”: “查询近期最长解套天数”, “required_parameters”: [“等于”, “20.0”, “1个月”], “rely_APIs”: []} |
算法实现
分析完赛题和数据,接下来我们将深入探讨实现方案。
框架介绍
首先给出我们的整体框架。根据实现流程,我们可以将框架将分为三个部分:
-
Prompt构造 我们设计了三个核心子模块,以帮助模型规范其输出。这三个子模块分别是产品召回、意图识别和例子召回。这些模块相互配合,确保模型能够更准确地理解和执行任务。
-
训练阶段 为了获得多样化的结果,我们对Prompt中的内容进行了部分删减,并调整了few-shot逻辑,从而得到五个不同的Lora微调模型。这种多样化的训练策略有助于模型在不同场景下的表现更加全面和可靠。
-
推理阶段 除了句子级别的多数投票外,我们还进行了许多其他尝试。同时,我们还实施了一些针对赛题的后处理技巧,如产品名称投票和错误API过滤,这些技巧对提升最终结果也有一定的帮助。同时,为了确保模型严格按照规定生成结果,我们的最终方案是使用五套差异化的Prompt对GLM进行Lora微调,然后对生成的五套执行语句进行句子级别的多数投票,以得出最终结果。
Prompt设计技巧
大模型比赛中最关键的就是prompt设计。这一节我们将深入探讨如何利用意图识别和few-shot技术来设计高质量的Prompt。
需要强调的是,我们采用技术的灵感源自统计学、传统机器学习和推荐系统的相关研究。尽管这些技术在原领域已经得到了广泛应用,但我们通过调整与优化,将它们迁移至大模型场景,并取得了效果。
1.产品名召回-Text Match
-
思路 因为用户的询问往往不够精准,比如用户可能会简称"平安银行"为"平安",但系统只能识别标准名称"平安银行"。所以我们设计了产品召回模块,其核心任务是针对用户查询,找到对应的标准产品名称。
-
实现 具体来说,我们设计了四种字符串匹配算法,包括最长公共子序列匹配、最长公共子串匹配,以及我设计的一个变体算法(公共子串占总字符串比例的算法) 。每个算法找到多个候选结果,然后拼接到一起,再让大模型从中选出最符合意图的一个作为最终结果。
-
细节 之所以需要召回多个结果,是因为整个系统中涉及的产品总数超过三万个,单靠简单的匹配算法很难精准捕捉到用户真正提及的对象。我们的思路是先用这些算法先召回十几个可能正确的候选产品,接着再让大模型从中挑选。
-
示意图

-
示例代码
def match_product(query: str, candidates: list): # query: 用户请求, e.g. 三羊马今日股价是多少 # candidates: 代表所有可能的产品, e.g. ['三羊马','中国平安','浦发银行', ...] products = difflib.get_close_matches(query, candidates, n = 200, cutoff=0.01) pro = [] # 多流量召回 pro += products[:1] products = sorted(products[1:], key=lambda x: len(LCS(x, query)) / len(x), reverse=True) pro += products[:4] products = sorted(products[4:], key=lambda x: len(LCS(x, query)), reverse=True) pro += products[:4] products = sorted(products[4:], key=lambda x: len(LSC(x, query)), reverse=True) pro += products[:4] # 重排 return sorted(pro, key=lambda x: len(LCS(translate(x), query)) / len(translate(x)), reverse=True)
2.意图识别-KNN
-
思路 具有相同意图的查询往往具有许多共性。在API链中,我们将第一条API定义为用户意图识别的节点。根据分析,用户查询主要有四类意图:股票查询、基金查询、条件选股以及条件选基。
-
实现 这里的意图识别方法不同于传统的NLP任务,我们有大量的同源训练样本。所以我们使用了KNN算法来处理用户请求,取最邻近的20个样本的意图的众数作为该请求的最终意图。
-
细节 为了找到最邻近的20个样本,我们选择了四种方法:编辑距离、SimCSE嵌入相似度、E5嵌入相似度和Bge嵌入相似度。每种方法分别召回5个最邻近的样本,最终将这20个邻居样本混合起来,通过投票来确定用户请求的意图。
-
参考 更多的文本嵌入方法可以参考以下链接:
https://huggingface.co/spaces/mteb/leaderboard -
示例代码
def get_intention(row): query = row['query'] # intentions 总共四类意图 intentions = ['基金查询', '股票查询', '条件选基', '条件选股'] # KNN选取每种算法的前五个邻居 for i in range(5): intentions.append(train.iloc[row[f'edit_{i}']]['label']) intentions.append(train.iloc[row[f'sim_{i}']]['label']) intentions.append(train.iloc[row[f'm3e_{i}']]['label']) intentions.append(train.iloc[row[f'e5_{i}']]['label']) # 意图修正 if ('股票' in query and not any([x in query for x in ['型', 'A', 'B', 'C', 'D', 'E', 'F']])): intentions = [x for x in intentions if '股' in x] elif any([x in query for x in stock_word]): intentions = [x for x in intentions if '股' in x] elif any([x in query for x in fund_word]): intentions = [x for x in intentions if '基' in x] if any([x in query for x in search_word]) and '(' not in query and '(' not in query: intentions = [x for x in intentions if '查询' in x] elif any([x in query for x in select_word]): intentions = [x for x in intentions if '选' in x] # 用邻居意图的mode代替 return Counter(intentions).most_common(1)[0][0]
3.例子召回-RAG
-
思路 在大模型的提示词中加入少量示例能够帮助模型更好地理解任务,few-shot是大模型比赛中非常常用的技巧。
-
实现 我们采用了与意图识别类似的思路来实现few-shot。首先,使用多种嵌入算法找到与当前查询相似的邻居并将其对应的问答作为例子,放入Prompt中作为few-shot提示。我们最终选取了三套嵌入方法,并使用蛇形召回算法来逐步从每个模型中提取结果,最终排出了六个示例。
-
参考 更多的prompt构造技术可以参考以下链接:
https://www.Promptingguide.ai/zh/techniques/consistency -
few-shot示例
Q1: Shawn有五个玩具。圣诞节,他从他的父母那里得到了两个玩具。他现在有多少个玩具? A1: 他有5个玩具。他从妈妈那里得到了2个,所以在那之后他有5 + 2 = 7个玩具。然后他从爸爸那里得到了2个,所以总共他有7 + 2 = 9个玩具。答案是9。 Q2: 服务器房间里有9台计算机。从周一到周四,每天都会安装5台计算机。现在服务器房间里有多少台计算机? A2: 从周一到周四有4天。每天都添加了5台计算机。这意味着总共添加了4 * 5 = 20台计算机。一开始有9台计算机,所以现在有9 + 20 = 29台计算机。答案是29。 Q3: Olivia有23美元。她用每个3美元的价格买了五个百吉饼。她还剩多少钱? A3: 她用每个3美元的价格买了5个百吉饼。这意味着她花了15美元。她还剩8美元。 Q4: 当我6岁时,我的妹妹是我的一半年龄。现在我70岁了,我的妹妹多大? A4: ?
训练技巧
1.模型选型
-
限制 为了减少资源chāo piào的影响,让选手们更公平的比拼技术,赛题对参赛者使用的模型大小做出了限制,要求模型参数量不得超过15B。
-
选型 经过多次尝试和比较,我们发现Qwen系列和GLM系列的模型在性能上非常接近,最终我们选择了更经济的GLM-4-9B模型。
2.Lora微调
-
介绍 Lora微调是一种高效的微调方法,特别适用于大型语言模型。其核心理念是避免对整个模型进行训练,而是仅对模型中的一小部分参数进行调整,从而减少计算资源的消耗并提高训练效率。
-
优势 相比与全参微调,Lora微调的优势在于,它可以让模型快速适应新的任务,只需调整与特定任务相关的参数。赛后与其他选手的交流也证实了这一点-Lora微调与全参微调在效果上几乎没有差别。我们认为这是因为微调的主要目标是规范模型的输出格式,而Lora已经足以实现这一目的。
-
实现 最简单的实现方式就是用llama-factory框架,能直接在UI界面完成lora微调。因为后续要用投票法来综合多个模型的答案,我们设计了五套Prompt,分别做了Lora微调,从而得到差异较大的多个模型,然后用它们做投票。
-
微调示意图

推理技巧
1.温度设置
-
解释LLM推理过程中有一个耐人寻味的参数温度。其用于调整模型生成文本时创造性和多样性的超参数。温度会影响模型生成文本时采样预测词汇的概率分布。
-
用法当模型的温度较高时,模型会更倾向于从较多样且不同的词汇中选择,这使得生成的文本风险性更高、创意性更强。反之,模型主要会从具有较高概率的词汇中选择,从而产生更平稳、更连贯的文本。在你需要稳定的结果时,尽量把温度调低。在vllm推理框架中,当你将温度设置为0时,代表使用贪心推理生成新文本,在本题中,我们使用贪心推理生成文本。
-
示例代码
from vllm import LLM, SamplingParams TEMP = 0 SEED = 42 MAX_TOKENS = 1024 sampling_params = SamplingParams(temperature=TEMP, seed=SEED, max_tokens=MAX_TOKENS) model = LLM( model=model_path, enforce_eager=True, max_model_len=2048 ) outputs = model.generate(prompts = prompts, sampling_params=sampling_params)
- 推理采样示意图

2.多数投票
-
方案 在推理阶段,我们使用了产品级别和句子级别的多数投票方法。首先,对于五个模型输出的最终产品结果,选择出现次数最多的产品作为最终结果。其次,我们对五条API取句子级别的众数,若没有,就随机抽一条。
-
优势 这种双层多数投票的策略,有助于增强结果的稳定性和一致性,特别是在多个模型输出稍有差异的情况下,可以有效避免单一模型可能带来的偶然性错误。
-
示例代码
model_list = ['model1','model2','model3'] for model_name in model_list: model = models[model_name] df[model_name] = model.predict(df[feature_cols]) df['pred'] = df[model_list].mode(axis=1)[0]
结尾

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

相关文章:
天池蚂蚁AFAC大模型挑战赛-冠军方案(含代码)
天池-蚂蚁AFAC大模型挑战赛-冠军方案 前言 ❝ 作者 彭欣怡 华东师大; 马千里 虾皮; 戎妍 港科广 说在前面 在当今信息技术迅猛发展的背景下,大模型技术已经成为推动人工智能领域进步的重要力量。 前段时间备受瞩目的AFAC赛题聚焦于金融对话…...

[QUIC] Packets 和 Frames 概述
Packets 和 Frames 概述 受保护的数据包 (Protected Packets) 基于不同的包类型, QUIC 使用不同等级的保护机制. Version Negotoation 包不受保护. Retry 包使用 AEAD 进行保护。 Initial 包使用 AEAD 进行保护, 但是使用的 Key 是由一个网络可见的值计算出来的。 因此 Ini…...

QT编辑框带行号
很可惜,qt的几个编辑框并没有相关功能。所以我们要自己实现一个。 先讲讲原理: QPlainTextEdit继承自QAbstractScrollArea,编辑发生在其viewport()的边距内。我们可以通过将视口的左边缘设置一个空白区域,…...

Kafka认证时Successfully logged in真的认证成功了?
背景 某个应用需要配置 Kafka 集群信息,且需要在验证集群是否可达。基本实现思路是创建一个生产者对象,然后发送一条测试数据,调用 Producer 的 send 方法发送消息后,再调用 get() 方法,即同步发送消息,测…...

软考信息系统管理师,系统集成项目管理工程师,考哪一个合适?
根据2024年的考试安排,高级项目管理师和系统集成工程师考试改为每年一次。 2024年上半年考高级项目管理师,下半年考系统集成项目管理工程师。 根据这个调整,建议先报名5月份的高级项目管理师考试。如果通过了,大家都高兴&#x…...
)
AI学习指南自然语言处理篇-位置编码(Positional Encoding)
AI学习指南自然语言处理篇-位置编码(Positional Encoding) 目录 引言位置编码的作用位置编码的原理绝对位置编码相对位置编码位置编码在Transformer中的应用位置编码的意义总结 引言 在自然语言处理中,文本数据通常以序列的形式存在。然而…...

macOS 15 Sequoia dmg格式转用于虚拟机的iso格式教程
想要把dmg格式转成iso格式,然后能在虚拟机上用,最起码新版的macOS镜像是不能用UltraISO,dmg2iso这种软件了,你直接转放到VMware里绝对读不出来,办法就是,在Mac系统中转换为cdr,然后再转成iso&am…...

【01初识】-初识 RabbitMQ
目录 学习背景1- 初识 MQ1-1 同步调用什么是同步调用?小结:同步调用优缺点 1-2 异步调用什么是异步调用?小结:异步调用的优缺点,什么时候使用异步调用? 1-3 MQ 技术选型 学习背景 异步通讯的特点ÿ…...

CTF-RE 从0到N:汇编层函数调用
windows 在 Windows 平台上的汇编语言中,调用函数的方式通常遵循特定的调用约定(Calling Convention)。最常见的调用约定包括: cdecl: C 默认调用约定,调用者清理堆栈。stdcall: Windows API 默认调用约定࿰…...

雷池社区版compose配置文件解析-mgt
在现代网络安全中,选择合适的 Web 应用防火墙至关重要。雷池(SafeLine)社区版免费切好用。为网站提供全面的保护,帮助网站抵御各种网络攻击。 compose.yml 文件是 Docker Compose 的核心文件,用于定义和管理多个 Dock…...
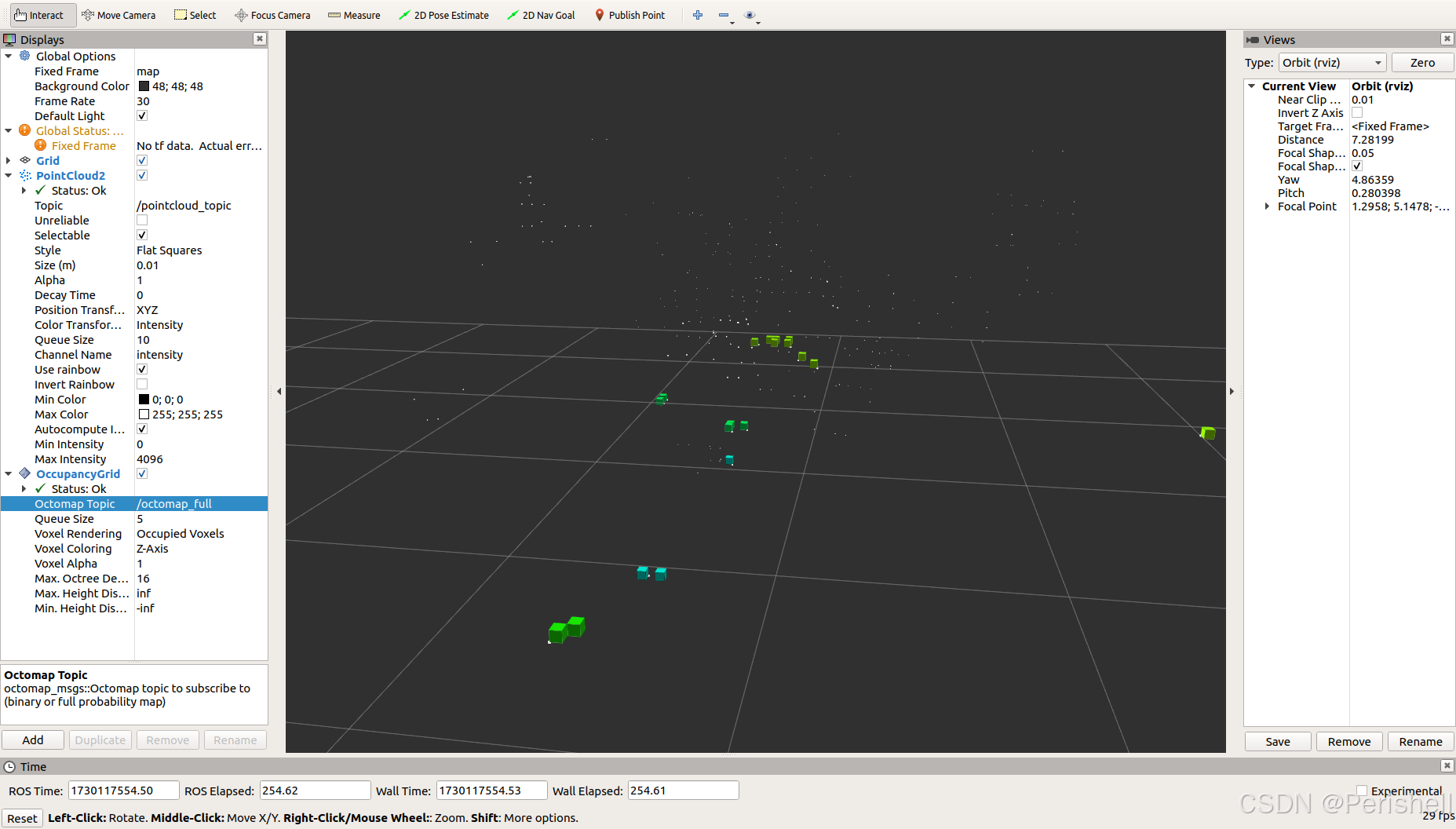
无人机避障——4D毫米波雷达Octomap从点云建立三维栅格地图
Octomap安装 sudo apt-get install ros-melodic-octomap-ros sudo apt-get install ros-melodic-octomap-msgs sudo apt-get install ros-melodic-octomap-server sudo apt-get install ros-melodic-octomap-rviz-plugins # map_server安装 sudo apt-get install ros-melodic-…...

Python(数据结构2)
常见数据结构 队列 队列(Queue),它是一种运算受限的线性表,先进先出(FIFO First In First Out) Python标准库中的queue模块提供了多种队列实现,包括普通队列、双端队列、优先队列等。 1 普通队列 queue.Queue 是 Python 标准库 queue 模块中的一个类…...
深入解析HTTP与HTTPS的区别及实现原理
文章目录 引言HTTP协议基础HTTP响应 HTTPS协议SSL/TLS协议 总结参考资料 引言 HTTP(HyperText Transfer Protocol)超文本传输协议是用于从Web服务器传输超文本到本地浏览器的主要协议。随着网络安全意识的提高,HTTPS(HTTP Secure…...

Java IO 模型
I/O 何为 I/O? I/O(Input/Output) 即输入/输出 。 我们先从计算机结构的角度来解读一下 I/O。 根据冯.诺依曼结构,计算机结构分为 5 大部分:运算器、控制器、存储器、输入设备、输出设备。 输入设备(比…...

安装双系统后ubuntu无法联网(没有wifi标识)网卡驱动为RTL8852BE
安装双系统后ubuntu没有办法联网,(本篇博客适用的版本为ubuntu20.04)且针对情况为无线网卡驱动未安装的情况 此时没有网络,可以使用手机数据线连接,使用USB共享网络便可解决无法下载的问题。 打开终端使用命令lshw -C …...

Sqoop的安装配置及使用
Sqoop安装前需要检查之前是否安装了Tez,否则会产生版本或依赖冲突,我们需要移除tez-site.xml,并将hadoop中的mapred-site.xml配置文件中的mapreduce驱动改回成yarn,然后分发到其他节点,hive里面配置的tez也要移除,然后…...

R语言机器学习算法实战系列(十三)随机森林生存分析构建预后模型 (Random Survival Forest)
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍教程加载R包案例数据数据预处理数据描述构建randomForestSRC模型评估模型C-indexBrier score特征重要性构建新的随机森林生存模型风险打分高低风险分组的生存分析时间依赖的ROC(Ti…...

三款计算服务器配置→如何选择科学计算服务器?
科学计算在众多领域都扮演着关键角色,无论是基础科学研究还是实际工程应用,强大的计算能力都是不可或缺的。而选择一台合适的科学计算服务器,对于确保科研和工作的顺利进行至关重要。 首先,明确自身需求是重中之重。要仔细考虑计算…...

Oracle 19c RAC删除多余的PDB的方式
文章目录 一、删除PDB并删除数据文件二、删除PDB并保留数据文件三、插拔PDB 一、删除PDB并删除数据文件 所删除的pdb必须是mount的状态才可以删除: #1、关闭pdb alter pluggable database pdb_name close immediate instancesall; #2、删除pdb以及数据文件 drop p…...
什么是云渲染?云渲染有什么用?一篇看懂云渲染意思
你知道云渲染是怎么回事吗? 其实就是把3D模型变成2D图像的过程,只不过这个过程是在云端完成的。我们在本地啥都不用做,只需要等结果就行。 现在云渲染主要有两种类型:一种是物理机房云渲染,另一种是服务器机房云渲染。…...

ComfyUI Video Combine节点3个核心技巧:解决视频合并常见问题
ComfyUI Video Combine节点3个核心技巧:解决视频合并常见问题 【免费下载链接】ComfyUI-VideoHelperSuite Nodes related to video workflows 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-VideoHelperSuite 在AI动画创作中,ComfyUI的Vi…...

3大突破性功能:如何用QtScrcpy彻底改变你的Android投屏体验
3大突破性功能:如何用QtScrcpy彻底改变你的Android投屏体验 【免费下载链接】QtScrcpy Android real-time display control software 项目地址: https://gitcode.com/GitHub_Trending/qt/QtScrcpy 你是否曾经为了在电脑上操作手机而烦恼?无论是游…...

Python自动化Excel数据抓取:OpenClaw技能实战指南
1. 项目概述:从Excel表格到智能数据抓取如果你每天的工作都离不开Excel,并且经常需要从各种网页、文档甚至PDF里手动复制粘贴数据,然后费劲地整理到表格里,那你一定对“Excel大师”这个称号既向往又头疼。我们总希望Excel能更“聪…...

Godot游戏集成Discord状态:RPC插件原理与实战指南
1. 项目概述:在Godot引擎中点亮你的Discord状态 如果你是一名独立游戏开发者,或者正在用Godot引擎捣鼓一些有趣的个人项目,你可能会想让你的朋友或社区成员知道你现在正在“玩”什么。不是通过截图发到社交媒体,而是更实时、更优…...

fold命令行工具:高效文本数据聚合与分析的瑞士军刀
1. 项目概述:一个为“折叠”而生的高效工具 最近在折腾一些数据处理和文件整理的工作流时,我一直在寻找一个能让我“折叠”起来思考的工具。我说的“折叠”,不是物理上的,而是逻辑上的——把复杂的、多维度的信息,按照…...

基于Nginx-Lua镜像构建高性能可编程网关的实践指南
1. 项目概述:一个为现代Web架构而生的Nginx镜像如果你和我一样,长期在容器化环境中部署和管理Web服务,那么你一定对Nginx的灵活性和Lua脚本的强大能力印象深刻。但将这两者结合,并打包成一个稳定、安全、功能齐全的Docker镜像&…...

开源大模型推理引擎Takeoff部署指南:从原理到生产实践
1. 项目概述:一个让大模型推理“起飞”的开源引擎 如果你正在为如何将那些动辄几十GB、几百亿参数的大语言模型(LLM)部署到生产环境而头疼,或者厌倦了为每一次API调用支付高昂的费用,那么今天聊的这个项目,…...

Flutter桌面端窗口控制:从隐藏标题栏到自定义全屏交互
1. 为什么需要自定义窗口控制? 当你用Flutter开发Windows桌面应用时,系统默认的标题栏和窗口样式往往显得格格不入。想象一下,你精心设计了一套深色主题的UI,结果顶部突然冒出一条灰白色的标准标题栏——就像给西装革履的绅士戴了…...

ARM Cortex-X系列处理器参数配置与性能优化指南
1. ARM Cortex-X系列处理器参数配置概述在移动计算和嵌入式系统领域,ARM Cortex-X系列处理器代表了ARM架构中的高性能核心设计。作为芯片设计工程师,我经常需要对这些处理器的参数进行精细调整,以实现最佳的性能和能效平衡。处理器参数配置本…...
基于Particle Photon与NeoPixel的物联网徽章:实时追踪ISS空间站
1. 项目概述:一个会“感知”太空的智能徽章 如果你和我一样,对头顶那片星空充满好奇,特别是当得知国际空间站(ISS)这个重达数百吨的大家伙,其实每天都会数次悄无声息地掠过我们的城市上空时,总…...