String的长度有限,而我对你的思念却无限延伸

公主请阅
- 1. 为什么学习string类?
- 2. string类的常用接口
- 2.1 string类对象的常见构造
- 2.1.1 string
- 2.2 operator[]
- 2.3 迭代器
- 2.4 auto自动推导数据类型
- 2.5 范围for
- 2.6 迭代器第二层
- 2.7 size和length获取字符串的长度
- 2.8 max_size 获取这个字符串能设置的最大长度
- 2.9 capacity
- 2.10 clear
- 2.11 operator以及at
- 2.12 push_back尾插一个字符
- 2.13 append
- 2.14 operator+=
- 2.15 reserve 提前开空间,避免扩容的操作
- 2.16 题目1:仅仅反转字母
- 2.17 题目二:字符串相加
- 2.18 resize
- 2.18.1 使用 `std::vector` 的 `resize()` 函数:
- 2.19 insert
- 2.20 erase
- 2.21 repalce 替换e
- 2.22 rfind
- 2.23 find_first_of
- 2.24 find_last_not_off
- 2.25 substr
- 2.26 to_string
- 2.27总结
- 3. string类的模拟实现
- 3.1 string的模拟实现
- 3.2 三个swap函数
- 3.21 区别
1. 为什么学习string类?
C语言中,字符串是以’\0’结尾的一些字符的集合,为了操作方便,C标准库中提供了一些str系列的库函数,但是这些库函数与字符串是分离开的,不太符合OOP的思想,而且底层空间需要用户自己管理,稍不留神可能还会越界访问。
在OJ中,有关字符串的题目基本以string类的形式出现,而且在常规工作中,为了简单、方便、快捷,基本都使用string类,很少有人去使用C库中的字符串操作函数
string是一个管理字符数组的类
2. string类的常用接口
string是一个管理字符的类,所以里面有很多关于字符的成员函数
2.1 string类对象的常见构造
2.1.1 string
https://legacy.cplusplus.com/reference/string/string/string/

#include<string>
int main()
{//std::string s1;string s1("111111222222");//111111222222string s2("11111111111111",3);// 111string s3(100,'x');//用100个x进行初始化操作string s4(s1, 4,3);//拷贝s2第四个位置的三个字符//112string s5(s1, 4);//拷贝s2第四个位置到结束//11222222//如果我们给的字符串太短了的话,有多少拷贝多少,直到结束cout << s1 << endl;cout << s2 << endl;cout << s3 << endl;cout << s4 << endl;cout << s5 << endl;return 0;
}
2.2 operator[]
我们现在想进行字符串的遍历,那么我们就可以使用string类里面的operator[]
operator[]可以访问数组的第pos位置的元素,越界就会直接报错的
我们的这个operator是一个既可以读也可以写的接口,两个const
所以这个重载函数提供了两个接口,如果我们是const成员对象的话我们提供const operator[],返回pos位置的const引用,那么我们就不能进行修改的操作,那么这里就是只能进行读的
如果是普通对象的话我们就调用普通对象的版本吗,获取pios位置的字符的引用,别名,可以读到这个数据也能写这个数据
对于我们之前学到的普通对象取地址重载我们对const对象和普通对象都有,普通对象返回的是Date* ,const对象返回的是const Date *
class string
{
public:char& operator[](size_t pos){assert(pos < _size);}
private:char* _str;size_t _size;size_t _capacity;
};第一种方法就是使用operator[]进行数组元素的遍历操作
通过下标+[]进行数组元素的遍历操作
int main()
{//我们现在想进行字符串的遍历,那么我们就可以使用string类里面的operator[]//operator[]可以访问数组的第pos位置的元素,越界就会直接报错的string s1("hello world");for (size_t i = 0; i < s1.size(); i++){cout << s1[i];//直接访问第i个位置的字符}return 0;
}
/
2.3 迭代器
第二种方法就是我们通过迭代器进行遍历的实现操作,迭代器可以理解为像指针一样的东西
int main()
{string s1("hello world");string::iterator it1 = s1.begin();//用这个类型定义一个对象//我们这里的话begin访问的是h这个字符,end指向的是\0//这里将begin给到了it1while (it1 != s1.end())//end是最后一个数据的下一个位置{//下面的用法非常像指针,但是不是指针cout << *it1 << " ";++it1;}return 0;
}
//这个s1是一个类对象,然后我们利用这个string类里面的运算符
我们这里视同begin获取第一个字符给到it1
然后这个while循环的条件是it1走到\0之前就停止
然后我们在循环里面就能将这个it1所指向的对象进行打印操作
但是我们需要在it1前面加上*,和指针差不多,但是不是指针
下标+[]很爽,但是我们为什么要学迭代器呢,迭代器写起来很麻烦
日常的通过下标[]访问很方便,但是这个不是通用的访问方式,这个只适合string和vector结构,不适合后面的结构,string和vector结构底层是连续的空间,才回去重载operator[]
下标+[]不是通用的方式,但是迭代器是所有容器通用的方式
我们这个迭代器的遍历这里最好用≠来进行遍历,不要用小于
int main()
{
list <int> lt;//创建一个模版对象lt
//然后进行数据的插入操作
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);//列表
list <int>::iterator it =lt.begin();
while (it != lt.end())
{cout << *it << " ";++it ;
}return 0;
}
迭代器是容器通用的遍历方式
我们这里不能写小于,因为前后直接可能不存在大小关系,所以我们这里使用≠
2.4 auto自动推导数据类型

如果想推导出引用的类型的话我们就得在auto的右边加一个&
而且如果我们需要进行推导的话,那么我们的右边就必须要有一个值,不然是不能进行推导操作的,因为我们不知道类型是啥,推导不出来,就会报错
auto真正的价值到底是什么呢?像下面的迭代器很长的话,我们就可以使用auto了


如果一个类型很长的话,我们要写对应的迭代器的话那么就太长了
auto的核心价值就是为了方便
简化代码,替换长类型,写起来长的类型
auto是一个语法糖
2.5 范围for
C++遍历容器的一个东西
auto和范围for都是C++11提供的
上面我们有下标[]和迭代器进行string进行遍历
那么我们现在可以使用范围for进行遍历的操作

范围for就是一个智能遍历,我们之前都是带有逻辑进行一个遍历的操作,比如说指针里面的像指针一样的++操作
范围for不存在逻辑
我们这里自动取容器对象的数据赋值给左边的值,随便定义
自动++,自动判断结束
我们依次取s1中的数据赋值给ch,然后进行打印操作
下面的链表也是一样的
//范围for我们给的字符串for (char ch : s1){cout << ch << " ";}cout << endl;//范围for 遍历上面的链表for (char e : lt){cout << e << " ";}cout << endl;但是真正的写法不这么写的,我们利用auto自动将数据进行推出来,
利用auto取出什么类型的数据就放到变量里面就行了
//范围for我们给的字符串for (auto ch : s1){cout << ch << " ";}cout << endl;//范围for 遍历上面的链表for (auto e : lt){cout << e << " ";}cout << endl;那么这里就是范围for和auto的一个融合操作

我们在中间进行一个修改的操作,但是最后的结果并没有什么变化
为什么没有起作用呢?

那么这里进行一个说明
这个范围for的作用是将自动容器的数据赋值给左边的对象
然后就是相当于拷贝的操作
那么我们在循环里面对拷贝的数据进行修改,但是不影响原来容器中存在的数据的
如果我们想通过这个拷贝的对容器中的数据进行一个修改的操作
那么我们就需要在auto的后面加上一个&
我们可以通过引用进行原来数据的改变的操作的

范围for的话存在两种情况我们是需要进行引用的操作的
一种是我们需要对容器中的数据进行一个修改操作的
一种是容器中存放的是比较大的对象,那么我们使用引用可以少一次拷贝的操作
如果我们现在引用了一个很大的数但是不想这个数后面被修改,那么我们就在auto的前面加一个const进行限制
那么现在进行回顾下,对于string而言的话,我们遍历数组有三种方法
下表+[] 、 迭代器 、范围for
范围for是用来遍历容器的,就是这些数据结构的
原因是范围for的底层是迭代器
下面的两个代码编译成指令以后在底层几乎是类似的,都变成了去调用迭代器了

范围for和suto都是语法糖,都是为了简化代码,用起来更加方便
从此以后遍历数组会更加方便了

范围for适用于容器和数组的遍历操作
auto当前是不能作为形参的
C++20开始支持auto作参数
auto可以支持作为返回值的

auto写返回值得把注释写清楚了

#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<string>
#include<assert.h>
#include<list>
using namespace std;//class string
//{
//public:
// char& operator[](size_t pos)
// {
// assert(pos < _size);
// }
//private:
// char* _str;
// size_t _size;
// size_t _capacity;
//};
//int main()
{////我们现在想进行字符串的遍历,那么我们就可以使用string类里面的operator[]//operator[]可以访问数组的第pos位置的元素,越界就会直接报错的string s1("hello world");//通过下标+[]进行数组元素的遍历操作for (size_t i = 0; i < s1.size(); i++){cout << s1[i];//直接访问第i个位置的字符}string::iterator it1 = s1.begin();//用这个类型定义一个对象//我们这里的话begin访问的是h这个字符,end指向的是\0//这里将begin给到了it1while (it1 != s1.end())//end是最后一个数据的下一个位置{//下面的用法非常像指针,但是不是指针cout << *it1 << " ";++it1;}list <int> lt;//创建一个模版对象lt//然后进行数据的插入操作lt.push_back(1);lt.push_back(2);lt.push_back(3);lt.push_back(4);//列表//list <int>::iterator it =lt.begin();auto it=lt.begin();while (it != lt.end()){cout << *it << " ";++it ;}//范围for我们给的字符串for (auto ch : s1){cout << ch << " ";}cout << endl;//范围for我们给的字符串for (auto& ch : s1){ch++;}cout << endl;for (auto ch : s1){cout << ch << " ";}cout << endl;//范围for 遍历上面的链表for (auto e : lt){cout << e << " ";}cout << endl;return 0;
}
//这个s1是一个类对象,然后我们利用这个string类里面的运算符//
//int main()
//{
// list <int> a1;
// return 0;
//}
2.6 迭代器第二层
我们现在如果想倒着遍历呢
下标肯定是可以进行倒着遍历的,那么迭代器怎么进行实现这个操作呢
迭代器分为Iterator(正向迭代器)

还有一个叫做反向迭代器(reverse iterator)

int main()
{string s1("hello world");string::reverse_iterator rit= s1.rbegin();//这个rbegin我们可以想成指向最后一个位置while (rit!=s1.rend())//rend指向第一个数据的前一个位置{cout << *rit << " ";++rit;//往左边走}cout << endl;//上面的代码就实现了逆序输出的操作了return 0;
}
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
#include<string>
using namespace std;int main()
{string s1 = "hello world";const string s2(s1);string::iterator it1 = s2.begin();while (it1 != s2.end()){cout << *it1<< " ";}cout << endl;return 0;
}
const对象调用的begin是第二个,const对象不能调用普通迭代器,所以上面的代码我们是运行不了的

正确的修改方式是代码进行匹配
int main()
{string s1 = "hello world";const string s2(s1);string::const_iterator it1 = s2.begin();while (it1 != s2.end()){cout << *it1<< " ";}cout << endl;return 0;
}
我们在iterator前面加上const_就可以解决这个问题了
因为我们的s2是拷贝s1的const对象,那么我们后面的begin()也是调用的是const的版本的
那么我们的这个对象就不能进行修改操作了,比如下面的操作就会报错

int main()
{//正序string s1 = "hello world";const string s2(s1);string::const_iterator it1 = s2.begin();while (it1 != s2.end()){cout << *it1<< " ";}cout << endl;//逆序string::const_reverse_iterator rit1 = s2.rbegin();while (rit1!= s2.rend()){cout << *rit1 << " ";++rit1;}cout << endl;return 0;
}
不管是正序遍历还是逆序遍历,对于这个const对象而言我们都需要在iterator前面加上const_
下面是改进的地方,我们直接使用auto自己推出数据的类型
int main()
{//正序string s1 = "hello world";const string s2(s1);//string::const_iterator it1 = s2.begin();auto it1 = s2.begin();while (it1 != s2.end()){cout << *it1<< " ";}cout << endl;//逆序//string::const_reverse_iterator rit1 = s2.rbegin();auto rit1 = s2.rbegin();while (rit1!= s2.rend()){cout << *rit1 << " ";++rit1;}cout << endl;return 0;
}
2.7 size和length获取字符串的长度
int main()
{string s1("hello world");cout << s1.size() << endl;cout << s1.length() << endl;//最后我们得到的就是11//是不包含最后结尾的\0的return 0;
}
计算长度是不包含最后结尾的\0的
2.8 max_size 获取这个字符串能设置的最大长度
不同编译器返回的结果是不同的
int main()
{string s1("hello world");cout << s1.max_size() << endl;//9223372036854775807//不同编译器返回的结果是不同的return 0;
}
2.9 capacity
int main()
{string s1("hello world");cout << s1.capacity() << endl;//15return 0;
}
计算存储的空间大小,其实我们这里11个字符,但是我们是15个空间,空间实际是16个
capacity是指的是能存储多少个有效字符
扩容要一次多开点空间
2.10 clear
直接将空间清0,但是空间大小不变

2.11 operator以及at
at越界的话是捕获异常的,但是[]越界之后是通过断言进行处理的
对于[]而言的话,程序直接终止而且会有一个弹窗的

at是可以抛异常,我们是可以进行捕获操作的
2.12 push_back尾插一个字符
int main()
{string s1("hello world");s1.push_back(' ');s1.push_back('x');cout << s1 << endl;return 0;
}

2.13 append
尾插一个字符串
int main()
{string s1("hello world");s1.push_back(' ');s1.push_back('x');cout << s1 << endl;s1.append("abc");cout << s1 << endl;return 0;
}

利用append进行多个字符的追加

int main()
{string s1("hello world");s1.push_back(' ');s1.push_back('x');cout << s1 << endl;s1.append("abc");cout << s1 << endl;s1.append(10, '!');cout << s1 << endl;//hello world xabc!!!!!!!!!!return 0;
}
我们在对应的string对象后面加上一段迭代区间
int main()
{string s1("hello world");s1.push_back(' ');s1.push_back('x');cout << s1 << endl;s1.append("abc");cout << s1 << endl;s1.append(10, '!');cout << s1 << endl;//hello world xabc!!!!!!!!!!string s2("hello bit hello world");s1.append(s2.begin(), s2.end());cout << s1 << endl;return 0;
}

但是现在我想从这个bit开始进行追加的操作
我们在begin()后面进行+6的操作

2.14 operator+=
其实上面的append和push_back我们除了特定的方法我们是不会使用到的
我们使用+=就行了
int main()
{string s1("hello world");string s2("hello bit hello world");string s3("hello");s3 += ',';s3 += "world";cout << s3 << endl;return 0;
}

2.15 reserve 提前开空间,避免扩容的操作
这个需要和之前的reverse进行区分
reserve是保留、预留的意思
利用reserve开出一个比我们给的空间更大的空间
int main()
{string s1;s1.reserve(200);//给出一个比200大的空间,这里就是207size_t old = s1.capacity();//记录之前的容量cout << "capacity:" << old << endl;for (size_t i = 0; i < 100; i++){s1 += 'x';if (s1.capacity() != old){cout << "capacity:"<<s1.capacity() << endl;old = s1.capacity();}}return 0;
}2.16 题目1:仅仅反转字母
https://leetcode.cn/problems/reverse-only-letters/
class Solution
{
public:bool isLetter(char ch){if(ch>='a'&&ch<='z'){return true;}if(ch>='A'&&ch<='Z'){return true;}return false;}string reverseOnlyLetters(string S){if(S.empty())//检查字符串是空的话,我们直接将s进行返回了{return S;}size_t begin=0,end=S.size()-1;//创建两个指针while(begin<end){while(begin<end&&!isLetter(S[begin]))//不是字母的话就直接跳过了,不进行后面的交换操作了{++begin;}while(begin<end&&!isLetter(S[end])){--end;}swap(S[begin],S[end]);++begin;--end;}return S;//返回结果}
};
2.17 题目二:字符串相加
https://leetcode.cn/problems/add-strings/description/
class Solution {
public:string addStrings(string num1, string num2){string str;int end1=num1.size()-1,end2=num2.size()-1;//指向结束位置int next=0;//进位while(end1>=0||end2>=0)//两个都结束才能结束,有一个没结束就可以继续{//分别取到对应的值//如果有一个结束的话我们就给个0就行了int x1=end1>=0?num1[end1--]-'0':0;//字符0的ASCII是48,'1'是49,转换成对应的整型值int x2=end2>=0?num2[end2--]-'0':0;//计算完之后我们进行--操作int ret=x1+x2+next;next=ret/10;ret=ret%10;/*假如我们的x1=1 x2=2 那么ret=3+0next=3/10=0那么我们就不会进位ret=3%10=3如果相加的是小于10的值的话是不会有影响的如果我们是9+9=18的话那么next=next=18/10=1ret=18%10=8那么我们就需要进位1了小于10的模10不会变,大于10的模10就将个位留了下来*///我们将结果+=到开始设置的string 字符串//这里不能用尾插,得头插//str+=('0'+ret);//几加'0'就变成字符几了//头插str.insert(str.begin(),'0'+ret);//第一个位置就是迭代器}if(next==1)//这个进位还没有进行处理的操作,如果进位是0的话还没有关系的{str.insert(str.begin(),'1');//插入一个字符1}return str;}
};
头插的话是会拉低效率的
头插一个数据,那么原先的数据就得往后挪动
那么我们如何优化这个程序呢?
我们就使用尾插的操作,然后使用reverse进行逆置操作
但是我们的尾插需要进行申请空间的操作,那么我们先使用reserve将空间开好了,然后就可以避免扩容操作了
str.reserve(max(num1.size(),num2.size())+1);//避免扩容
class Solution {
public:string addStrings(string num1, string num2){string str;str.reserve(max(num1.size(),num2.size())+1);//避免扩容int end1=num1.size()-1,end2=num2.size()-1;//指向结束位置int next=0;//进位while(end1>=0||end2>=0)//两个都结束才能结束,有一个没结束就可以继续{//分别取到对应的值//如果有一个结束的话我们就给个0就行了int x1=end1>=0?num1[end1--]-'0':0;//字符0的ASCII是48,'1'是49,转换成对应的整型值int x2=end2>=0?num2[end2--]-'0':0;//计算完之后我们进行--操作int ret=x1+x2+next;next=ret/10;ret=ret%10;/*假如我们的x1=1 x2=2 那么ret=3+0next=3/10=0那么我们就不会进位ret=3%10=3如果相加的是小于10的值的话是不会有影响的如果我们是9+9=18的话那么next=next=18/10=1ret=18%10=8那么我们就需要进位1了小于10的模10不会变,大于10的模10就将个位留了下来*///我们将结果+=到开始设置的string 字符串str+=('0'+ret);}if(next==1)str+='1';//我们写一个逆置函数就行了reverse(str.begin(),str.end());return str;}
};
这样就可以极大的提高了效率
2.18 resize
rresize的功能还是比较复杂的,有插入删除扩容的操作
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<string>
using namespace std;
int main()
{string s1("1111111111111111111111");cout << s1 << endl;cout << s1.size() << endl;cout << s1.capacity() << endl;//n<size 删除s1.resize(15);cout << s1 << endl;cout << s1.size() << endl;cout << s1.capacity() << endl;//size<n<capacity 插入s1.resize(25, 'x');cout << s1 << endl;cout << s1.size() << endl;cout << s1.capacity() << endl;//n>capacity 进行扩容s1.resize(40,'x');cout << s1 << endl;cout << s1.size() << endl;cout << s1.capacity() << endl;return 0;
}
//如果我们resize给的值比原先的size的值小的话,那么就会将多余的删除了
//如果我们resize给的值比原先的size的值大的话,新增的元素会使用默认值进行填充
如果我们resize给的值比原先的size的值小的话,那么就会将多余的删除了
如果我们resize给的值比原先的size的值大的话,新增的元素会使用默认值进行填充
resize在string中使用的不多,但是vector中用的多
在C++中,resize() 通常与STL容器(如 std::vector、std::string 等)有关。它用于调整容器的大小。
2.18.1 使用 std::vector 的 resize() 函数:
resize() 函数可以改变 std::vector 的大小。如果新大小比当前大小大,新增的元素会使用默认值进行填充;如果新大小比当前大小小,后面的元素将被移除。
语法:
void resize(size_t new_size);
void resize(size_t new_size, const T& value);
-
new_size: 目标大小(类型为size_t)。 -
value: 当新大小比当前大小大时,用来填充新增元素的值(可选参数)。
示例:
调整为更大的大小:
#include <iostream>
#include <vector>int main() {std::vector<int> vec = {1, 2, 3};// 调整大小为5,新增元素使用默认值0vec.resize(5);for (int i : vec) {std::cout << i << " ";}return 0;
}
输出:
1 2 3 0 0
调整为更小的大小:
#include <iostream>
#include <vector>int main() {std::vector<int> vec = {1, 2, 3, 4, 5};// 调整大小为3,移除后面的元素vec.resize(3);for (int i : vec) {std::cout << i << " ";}return 0;
}
输出:
1 2 3
使用特定值填充新增元素:
#include <iostream>
#include <vector>int main() {std::vector<int> vec = {1, 2, 3};// 调整大小为5,新增元素使用特定值10vec.resize(5, 10);for (int i : vec) {std::cout << i << " ";}return 0;
}
输出:
1 2 3 10 10
总结:
resize() 可以灵活地增加或减少容器的大小,增加的部分可以使用默认值或者指定的值填充。减少大小则会移除多余的元素。
2.19 insert

在指定位置进行字符串的插入操作操作
int main()
{string s1("hello world");s1.insert(5,"xxxx");//在第5个位置进行中间插入//后面的数据就是往后面进行挪动的cout << s1 << endl;//helloxxxx worldreturn 0;
}

2.20 erase
int main()
{string s1("hello world");s1.insert(5,"xxxx");//在第5个位置进行中间插入//后面的数据就是往后面进行挪动的cout << s1 << endl;//helloxxxx worlds1.erase(5, 4);//将插入的给删除了cout << s1 << endl;return 0;将我们上面利用insert插入的元素删除了
所以erase得作用是从指定位置开始进行元素的删除操作
如何通过ereasr实现头删呢?
第0个位置进行头删操作,第0个位置开始删除一个元素
还有一种就是我们给个迭代器begin().直接从字符串开始进行删除操作
如果我们只给一个参数的话,就从我们给的位置开始进行删除操作,后面的元素都删除了,这是因为我们没有指定删除的元素的个数
2.21 repalce 替换e

如果我们对两个元素进行替换的话是没有问题的,但是如果我们将一个字符替换成多个字符的话那么就意味着挪动数据了
replace在对平替的效率比较高,当前是几个字符就替换几个字符
利用find找到空格,返回空格的位置,然后我们就行这个位置的替换操作
int main()
{string s1("hello woprld hello bit");s1.replace(5, 1, "%%");//从第5个字符开始的第一个字符替换成%%//本质是将后面的字符往后挪了一位的,但是效率很低的cout << s1 << endl;size_t i = s1.find(" ");//没有找到就返回npos ,返回了就正常返回下标while (i != string::npos){s1.replace(i, 1, "%%");//找到空格,然后从这个位置开始的一个空格替换为%%i = s1.find(" ");//找到了就一直进行替换}cout << s1 << endl;return 0;
}

find的默认位置是从0开始找的,我们给什么值就从什么位置开始找
下面是优化的
int main()
{string s1("hello woprld hello bit");s1.replace(5, 1, "%%");//从第5个字符开始的第一个字符替换成%%//本质是将后面的字符往后挪了一位的,但是效率很低的cout << s1 << endl;size_t i = s1.find(" ");//没有找到就返回npos ,返回了就正常返回下标while (i != string::npos){s1.replace(i, 1, "%%");//找到空格,然后从这个位置开始的一个空格替换为%%i = s1.find(" ",i+2);//第一次们已经找到了这个空格,然后我们就从这个i+2的位置开始找空格就行了}cout << s1 << endl;return 0;
}
每次替换都需要进行数据的挪动,这种效率很低的
还有一种写法:
利用范围for
int main()
{string s1("hello woprld hello bit");cout << s1 << endl;string s2;for (auto ch : s1)//遍历s1{if (ch != ' '){s2 += ch;}else{s2 += "%%";}}cout << s2 << endl;s1 = s2;return 0;
}
//相当于造出了一个新的字符,然后进行赋值操作
2.22 rfind
倒着找
下面是我们进行实现我们获取文件的后缀的操作
先利用rfind倒着找,然后找到的话我们利用substr获取子串,从我们的pos位置开始取
int main()
{string s3("test.cpp");//现在我们想将后缀取出来//那么我们后缀的特征就是前面有一个点,以点进行区分操作//那么这个时候就可以使用rfind了size_t pos = s3.rfind('.');if (pos != string::npos)//找到的话{//这个时候我们就找到位置了,那么我们就要利用substr这个从pos位置开始取子串string sub = s3.substr(pos);//从pos位置开始取;cout << sub << endl;}
}
find就是正向找,
rfind就是倒着找
2.23 find_first_of

int main()
{std::string str("Please, replace the vowels in this sentence by asterisks.");cout << str << endl;std::size_t found = str.find_first_of("aeiou");while (found != std::string::npos){str[found] = '*';found = str.find_first_of("aeiou", found + 1);}std::cout << str << '\n';return 0;
}
只要你这个字符串里面有我给的这个字符串里面任意一个字符的话,我们就将这个字符变成*
将元音字母变成*
2.24 find_last_not_off
int main()
{std::string str("Please, replace the vowels in this sentence by asterisks.");cout << str << endl;std::size_t found = str.find_first_not_of("aeiou");while (found != std::string::npos){str[found] = '*';found = str.find_first_not_of("aeiou", found + 1);}std::cout << str << '\n';return 0;
}
保留元音字母,其他字母全部屏蔽掉,只有aeiou留下来了
2.25 substr
从pos位置取len个字符
然后将这几个衣服构成资格子串string
2.26 to_string
将数据转换为字符串
2.27总结
常用的:构造、迭代器、容量里面的几个





3. string类的模拟实现
3.1 string的模拟实现
string.h
#define _CRT_SECURE_NO_WARNINGS 1
#pragma once
#include<iostream>
#include<assert.h>using namespace std;namespace kaizi
{class string{public://typedef char* iterator;using iterator=char*;//迭代器using const_iterator = const char*;//迭代器//无参构造函数//string();//带参构造函数//如果用strlen进行计算的话,都是运行的时候计算,o(n)复杂度//这里三个strlen就很坑了//那么我们第一个将size进行初始化就行了,后面的初始化直接用size进行初始化操作就行了//但是还是存在风险的,我们让一个走初始化就行了,剩下的走函数体就行了string(const char* str = "");//缺省参数只能在声明给//无参的构造函数和右参数的构造函数尽量合并下,提供一个全缺省的string(const string& s);//string& operator=(const string& s);//赋值string& operator=(string s);//析构函数~string();//遍历// void reserve(size_t n);void push_back(char ch);void append(const char* str);string& operator+=(char ch);string& operator+=(const char* str);void insert(size_t pos, char ch);void insert(size_t pos, const char *str);void erase(size_t pos, size_t len=npos);size_t find(char ch, size_t pos = 0);//查找字符size_t find(const char* str, size_t pos = 0);//查找字符串void clear()//将内容都清理掉{_str[0] = '\0';//直接将第一个元素变成\0了_size = 0;}//普通对象版本char& operator[](size_t i){assert(i < _size);return _str[i];}//const版本const char& operator[](size_t i) const{assert(i < _size);return _str[i];}iterator begin(){//返回开始位置的迭代器return _str;//返回第一个位置的指针}iterator end(){//返回结束位置的迭代器return _str+_size;//返回最后一个位置的下一个位置的指针}const_iterator begin()const{//返回开始位置的迭代器return _str;//返回第一个位置的指针}const_iterator end()const{//返回结束位置的迭代器return _str + _size;//返回最后一个位置的下一个位置的指针}size_t size() const{ return _size;}const char* c_str() const{return _str;}void swap(string& s);string substr(size_t pos, size_t len = npos);private:size_t _size;size_t _capacity;char* _str;public://静态成员变量是不能给缺省值的,但是const静态可以static const size_t npos=-1;//静态成员变量是不能给缺省值的,类里面声明,类外面定义//静态成员变量在.h文件声明,在.cpp文件定义/*声明 静态成员变量在头文件(.h 文件)中,是为了让类的使用者知道该类有这个静态成员变量。
定义 静态成员变量在实现文件(.cpp 文件)中,
是为了分配内存并避免多次定义的问题。*/};void swap(string& s1, string& s2);//全局函数bool operator==(const string& lhs, const string& rhs);bool operator!=(const string& lhs, const string& rhs);bool operator>(const string & lhs, const string & rhs);bool operator<(const string& lhs, const string& rhs);bool operator>=(const string& lhs, const string& rhs);bool operator<=(const string& lhs, const string& rhs);//istream和ostream都要用引用,如果是用传值肯定是不行的,不支持拷贝的ostream& operator<<(ostream& os, const string& str);istream& operator>>(istream& is, string& str);//我们要进行输出,那么我们就不能带constistream& getline(istream& is, string& str,char delim='\n');//我们要进行输出,那么我们就不能带const}string.cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include"string.h"
namespace kaizi//多个命名空间会认为是一个的
{//const size_t string::npos=-1;//string::string()// :_str(new char[1] {'\0'})//不能是nullptr,这个调用string类里面的重载函数会报错的// , _size(0)// , _capacity(0)//{//}//带参构造函数//如果用strlen进行计算的话,都是运行的时候计算,o(n)复杂度//这里三个strlen就很坑了//那么我们第一个将size进行初始化就行了,后面的初始化直接用size进行初始化操作就行了//但是还是存在风险的,我们让一个走初始化就行了,剩下的走函数体就行了string::string(const char* str):_size(strlen(str)){_capacity = _size;_str = new char[_size + 1];//+1d的原因是strlen不计算\0的大小,我们还得多加一个空间给\0预留strcpy(_str, str);//将源字符串 str 复制到目标字符串 _str 中。}//s2(s1)//传统写法//string::string(const string& s)//{// //拷贝构造不能让他们指向同一块空间,解决方法就是深拷贝// //不是单纯的对值进行拷贝,而是对资源同样也是需要进行拷贝的// //我们再开一段空间,有着一样的值// _str = new char[s._capacity + 1];// strcpy(_str, s._str);// _size = s._size;// _capacity = s._capacity;//}// //s2(s1)//现代写法string::string(const string& s)//这里你的this->_str是野指针没有初始化哦 :_str(nullptr){string tmp(s._str);//构造一个tmp的对象//开一段一样大的空间,然后将数据进行拷贝//tmp和s1有着一样大的空间一样大的值//并且tmp里面有着和s1一样的数据,//然后我们将s2和tmp进行交换//这个就相当于s2是s1的拷贝swap(tmp);//这里本质是this调用的swap函数//tmp是局部对象,出了作用域就会被销毁//这里的swap调用的是成员函数的swap//拷贝构造可以是这个思路,那么赋值也可以是这个思路}//s1=s3//不能自己给自己赋值,如果自己给自己赋值的话我们释放的时候就会出问题了//string& string::operator=(const string& s)//赋值//{// if (this != &s)// {// //这里的this指针指向我们的s1// delete[] _str;//先将我们的空间释放了,然后再开一块一样大的空间// _str = new char[s._capacity + 1];// strcpy(_str, s._str);// _size = s._size;// _capacity = s._capacity;// }// return *this;//}//赋值的现代写法//string& string::operator=(const string& s)//赋值//{// if (this != &s)// {// string tmp(s._str);//构造一个tmp的对象// swap(tmp);//这里本质是this调用的swap函数// }// return *this;//}//s1=s3//我们这里传值传参,然后将s3拷贝给s了//然后我们在函数里面利用隐藏的this调用成员函数交换,将s的值交换给s1//那么我们就实现了s3赋值给s1的操作了string& string::operator=(string s)//这里调用的是传值传参,传值传参就要调用拷贝构造{//这里存在一个this指针swap(s);//这里本质是this调用的swap函数return *this;//s1传值调用拷贝构造,s3去拷贝构造这个s//s就开了一段和s3一样大的空间,一样的值//我们让s和s1进行一个交换//那么s1就指向s拷贝构造出的东西了//那么s1指向的空间和s3指向的空间一样大了}//现代写法没有效率的提升,只是简介一点,本质是复用//析构函数string::~string(){delete[] _str;//C++ 中用于释放动态分配的数组内存的语句_str = nullptr;_size = 0;_capacity = 0;}void string::reserve(size_t n)//进行扩容操作{if (n > _capacity){char* tmp = new char[n + 1];//开空间永远要多开一个位置,因为\0是不计算_capaicty的strcpy(tmp, _str);//将_str拷贝到新空间里面delete[]_str;_str = tmp;_capacity = n;}}void string::push_back(char ch){尾插之前先看内存够不够,再进行尾插的操作//if (_size == _capacity)//满了//{// reserve(_capacity == 0 ? 4 : _capacity * 2);//如果大小是0的话我们给个4,如果不是的话我们进行两倍扩容操作//}//_str[_size] = ch;//在size位置插入字符然后_size++就行了//_size++;//当我们实现insert之后,我们直接写insert就行了insert(_size, ch);}void string::append(const char* str){//size_t len = strlen(str);//要插入的字符个数//if (_size + len > _capacity)//{// size_t newcapacity = 2*_capacity;// //扩容二倍不够,则需要多少扩多少// if (newcapacity < _size + len)// {// newcapacity = _size + len;// }// reserve(newcapacity);//} 进行插入操作//strcpy(_str + _size, str);//将str拷贝到_str+_size这个位置_str是字符串的字符指针//_size += len;//已经插入了,那么我们的_size就需要更新了 ,加上插入的字符串的长度insert(_size, str);}string& string::operator+=(char ch){push_back(ch);return *this;}string& string::operator+=(const char* str){append(str);return *this;}void string::insert(size_t pos, char ch)//在pos位置插入字符{//先判断内容够不够if (_size == _capacity)//满了{reserve(_capacity == 0 ? 4 : _capacity * 2);//如果大小是0的话我们给个4,如果不是的话我们进行两倍扩容操作}//将Pos位置后面的数据往后挪动//使用 int 进行循环和索引操作,便于处理负数和一些边界情况。尽管 pos 不太可能是负数,因为它是 size_t 类型的无符号整数,// 但将其转换为 int 可以在处理逻辑时让程序更灵活。//所以这里我们需要将pos从size_t转换为int类型的数据//pos=0的时候存在风险的//下面的这个逻辑是进行强转的,但是我们假如不进行强转的话//我们将end初始化为_size+1//int end = _size;//while (end >= (int)pos)//{// _str[end + 1] = _str[end];// --end;//}//_str[pos] = ch;//进行数据的插入//_size++;size_t end = _size+1;//我们让end的起点位置从_size变成_size+1while (end >pos)//在pos后面就停下来{_str[end] = _str[end-1];//我们将end的前一个位置挪过来--end;}_str[pos] = ch;//进行数据的插入_size++;}void string::insert(size_t pos, const char* str)//在pos位置插入串{assert(pos <= _size);//不能越界插入了size_t len = strlen(str);//要插入的字符个数if (_size + len > _capacity){size_t newcapacity = 2 * _capacity;//扩容二倍不够,则需要多少扩多少if (newcapacity < _size + len){newcapacity = _size + len;}reserve(newcapacity);}//int end = _size;//while (end >= (int)pos)//{// _str[end + len] = str[end];//end位置的元素挪到end+len// end--;//}// // size_t end = _size+len;//pos + len - 1 是插入的起点的最后一个字符的位置,// 这确保了数据不会在移动过程中覆盖自己。//如果不使用 pos + len - 1,直接用 pos 可能会导致覆盖还没挪动的数据,或者处理越界错误。因此,通过这个条件// 可以防止在数据搬移的过程中发生越界和错误写入的情况。while (end >=pos+len-1)//防止越界的情况{_str[end ] = str[end-len];//将前面的数据挪到后面end--;}//然后将这几个字符放进去for (size_t i = 0; i < len; i++){_str[pos + i] = str[i];}_size += len; }void string::erase(size_t pos, size_t len){if (len >= _size - pos)//如果给的len是空的话,我们直接将后面的全部删除了//len == npos 如果len要删除的长度大于pos后面剩余的元素的长度的话,那么我们直接将后面全部删除了{_str[pos] = '\0';_size = pos;}else//仅仅删除一部分{//假设删除pos位置后面的两个数的话,那么剩下的元素就得往前面挪动了///这个end的位置指向的就是要删除的元素后面的第一个元素开始的位置//将这些元素挪动到要删除元素的位置上进行覆盖操作size_t end = pos + len;while (end <= _size)//从end这个位置开始,将后面的数据挪动到前面来{_str[end - len] = _str[end];//将end的值往前挪进行覆盖操作end++;}_size -= len;//少了len个元素,那么我们直接将size进行减去len的操作}}size_t string::find(char ch, size_t pos )//查找字符{assert(pos < _size);//pos不能越界了for (size_t i = pos; i < _size; i++){if (ch == _str[i]){return i;}}return npos;//没有找到}size_t string::find(const char* str, size_t pos )//查找字符串{assert(pos < _size);//pos不能越界了//返回的是一个指针,str2在str1中的位置const char* ptr = strstr(_str+pos, str);//从pos位置开始找的if (ptr == nullptr){return npos;//没有匹配的就返回空}else{return ptr - _str;//返回的指针减去数组开头的指针就是我们要找的字符串开始的下标}//返回的是下标 }string string::substr(size_t pos, size_t len)//获取pos位置后面len个字符串{assert(pos < _size);//pos不能越界了//如果大于后面剩余串的长度,那么我们直接取到结尾就行了if (len > (_size - pos))//size-pos就是我们这个串剩下的字符了{len = _size - pos;}kaizi::string sub;sub.reserve(len);//将空间开好for (size_t i = 0; i < len; i++){sub += _str[pos + i];//从pos位置开始的len个字符全部加等到我们的sub数组中}return sub;//传值返回也是需要拷贝构造的}void string::swap(string& s){std::swap(_str, s._str);//去命名空间域里面找std::swap(_size, s._size);//去命名空间域里面找std::swap(_capacity, s._capacity);//去命名空间域里面找}///void swap(string& s1, string& s2){s1.swap(s2);}bool operator==(const string& lhs, const string& rhs){return strcmp(lhs.c_str(), rhs.c_str()) == 0;}bool operator!=(const string& lhs, const string& rhs){return !(lhs == rhs);}bool operator>(const string& lhs, const string& rhs){return !(lhs <= rhs);}bool operator<(const string& lhs, const string& rhs){//第一个值比第二个值小的话那么直接返回小于0的数return strcmp(lhs.c_str(), rhs.c_str())<0;}bool operator>=(const string& lhs, const string& rhs){return !(lhs < rhs);}bool operator<=(const string& lhs, const string& rhs){return lhs < rhs || lhs==rhs;}//os就是coutostream& operator<<(ostream& os, const string& str){for (size_t i = 0; i < str.size(); i++){os << str[i];}return os;}istream& operator>>(istream& is, string& str) // 我们要进行输入重载{//栈上开空间比堆上开空间的效率高str.clear();//因此,str.clear() 是用来确保每次输入操作时,//str 都是干净的、没有之前内容的字符串//str.reserve(1024);//进行扩容的操作//如果我们不扩容的话,那么我们这里是需要扩容好几次的int i = 0;char buff[256]; // 定义一个大小为 256 的字符数组,用作缓冲区char ch; // 定义一个字符变量//用流提取的符号会忽略换行,所以我们这里使用get//is >> ch; // 从输入流读取一个字符ch = is.get();while (ch != ' ' && ch != '\n') // 碰到空格或者是换行符这个循环就结束{buff[i++] = ch; // 将字符 ch 存储到 buff 的第 i 个位置,并使 i 自增// 我们将输出的内容拼接到字符串中if (i == 255)//已经放了255个字符了{buff[256] = '\0';//给\0留一个位置str += buff;//这里会一次进行扩容操作的,不会一次一次的进行扩容操作的i = 0;//将i重置了}ch = is.get(); // 再从输入流读取下一个字符}if (i > 0){buff[i] = '\0';str += buff;}return is; // 返回输入流对象}/*
每次读取一个字符后,buff[i++] = ch 会将字符放入缓冲区,同时增加索引 i。
当 i 达到 255 时,意味着缓冲区几乎满了。此时,代码将缓冲区的第 256 个字符设为 '\0'(空字符),
使其成为一个合法的 C 字符串。
接着,str += buff 将缓冲区的内容拼接到字符串 str 中,然后重置 i 为 0,继续存储后续字符。处理剩余字符:在循环结束后,可能缓冲区还有未满的部分(i > 0)。此时,代码会再次将 buff 中的字符加上 '\0',
并将剩余的内容追加到 str 中。即用即销毁
用几个空间开几个空间
*/istream& getline(istream& is, string& str, char delim)//我们要进行输出,那么我们就不能带const{//getline是以delim为结束符的//栈上开空间比堆上开空间的效率高str.clear();//因此,str.clear() 是用来确保每次输入操作时,//str 都是干净的、没有之前内容的字符串//str.reserve(1024);//进行扩容的操作//如果我们不扩容的话,那么我们这里是需要扩容好几次的int i = 0;char buff[256]; // 定义一个大小为 256 的字符数组,用作缓冲区char ch; // 定义一个字符变量//用流提取的符号会忽略换行,所以我们这里使用get//is >> ch; // 从输入流读取一个字符ch = is.get();while (ch != delim) //分隔符{buff[i++] = ch; // 将字符 ch 存储到 buff 的第 i 个位置,并使 i 自增// 我们将输出的内容拼接到字符串中if (i == 255)//已经放了255个字符了{buff[256] = '\0';//给\0留一个位置str += buff;//这里会一次进行扩容操作的,不会一次一次的进行扩容操作的i = 0;//将i重置了}ch = is.get(); // 再从输入流读取下一个字符}if (i > 0){buff[i] = '\0';str += buff;}return is; // 返回输入流对象}//对于getline只有我们输入固定的结束符 我们才能结束这个操作}test.cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include"string.h"
#include<string>
#include<iostream>
using namespace std;void test1()
{kaizi::string s1("hello world");std::cout << s1.c_str();cout << endl;s1[0] = 'x';std::cout << s1.c_str();cout << endl;for (size_t i = 0; i < s1.size(); i++){cout << s1[i] << " ";}cout << endl;kaizi::string::iterator it1 = s1.begin();while (it1 != s1.end()){(*it1)--;++it1;}cout << endl;it1 = s1.begin();while (it1 != s1.end()){cout << *it1 << " ";++it1;}cout << endl;//修改// 范围for的底层是迭代器支持的//意味着支持迭代器就是支持范围forfor (auto& ch : s1){ch++;}for (auto ch : s1){cout << ch << " ";}cout << endl;const kaizi::string s3("xxxxxxx");//我们如果想使用范围for的话我们得有const迭代器for (auto ch : s3){//ch++;我们这里是不能进行修改操作的cout << ch << " ";}cout << endl;s1 += "hello bit";std::cout << s1.c_str();cout << endl;s1.insert(6, 'x');std::cout << s1.c_str();cout << endl;s1.insert(0, 'x');//当我们实现头插的时候我们这里就出现问题了//我们是需要考虑下边界问题的std::cout << s1.c_str();cout << endl;//中间插入string s2("hello bit");s2.insert(6, "xxx");std::cout << s2.c_str();cout << endl;//头插s2.insert(0, "xxx");std::cout << s2.c_str();cout << endl;s2.erase(5);std::cout << s2.c_str();cout << endl;s2 += "hah";std::cout << s2.c_str();cout << endl;cout << s2.find("hah") << endl;kaizi::string s5 = "https://bbs.huaweicloud.com/blogs/330588";size_t pos1 = s5.find(':');size_t pos2 = s5.find('/', pos1 + 3);//从pos1+3这个位置开始找//找到的/就是中间的///if (pos1 != string::npos && pos2 != string::npos)//{// kaizi::string domain = s5.substr(pos1 + 3, pos2 - (pos1 + 3));// cout << domain.c_str() << endl;//}//kaizi::string s7("xxxxxxxxxxxxxxxxxxxxxx");//s1 = s7;//std::cout << s1.c_str();//cout << endl;//cout << (s3 == s3) << endl;
}
void test2()
{kaizi::string s1("hello world");kaizi::string s2("xxxxxxxxxxxxxxxxxx");swap(s1, s2);s1.swap( s2);//调用成员函数的swap,既能完成交换,代价也很小的cout << s1 << endl;cout << s2 << endl;}
void test3()
{kaizi::string s1("hello world");kaizi::string s2(s1);cout << s1 << endl;cout << s2 << endl;
}
void test4()
{kaizi::string s1("hello world");kaizi::string s2(s1);cout << s1 << endl;cout << s2 << endl;kaizi::string s3("xxxxxxxxxxxxxxxxxxx");s1 = s3;cout << s1 << endl;
}int main()
{test4();return 0;
}3.2 三个swap函数
无论我们是调用成员函数还是全局函数,都不会调用到这个算法库的swap函数
算法库这个swap这个要深拷贝,代价很大

std::string::swap (string& str)
-
这是
std::string类的成员函数,用于交换两个std::string对象的内容。 -
用法:
str1.swap(str2),这种情况下,str1和str2的内容会被交换。 -
特点:这是针对
std::string的专用函数,只能交换两个std::string对象。
std::swap (string& x, string& y)
-
这是标准库中的一个普通函数,它不是
std::string的成员,而是一个全局函数,用于交换两个字符串。 -
用法:
std::swap(str1, str2),可以直接在两个std::string对象之间交换它们的内容。 -
特点:这是一个全局函数,功能上与
string::swap类似,交换两个std::string的内容。
std::swap (template)
-
这是 C++ 标准库中的模板函数
swap,用于交换任意类型的两个对象。 -
它使用模板参数,因此可以用于交换任意类型的对象,而不仅仅是
std::string。例如,你可以交换int、double、vector等任何支持赋值的类型。 -
用法:
std::swap(a, b),a和b可以是任意类型的对象,只要它们支持交换操作。 -
特点:这是一个通用模板,广泛适用于所有类型,不仅限于
std::string。
3.21 区别
-
第一个
swap是std::string类的成员函数,专门用于交换std::string的内容。 -
第二个
swap是全局的std::swap函数,适用于std::string对象的内容交换,它提供了与string::swap类似的功能,但不是类的成员函数。 -
第三个
swap是一个模板函数,它的用途更广泛,可以用于交换任意类型的两个对象,而不局限于std::string。
总结起来:
-
如果只涉及
std::string对象,可以使用std::string::swap或std::swap,两者效果相同。 -
如果需要交换其他类型的对象(比如
int、float等),应使用模板版本的std::swap。
相关文章:
String的长度有限,而我对你的思念却无限延伸
公主请阅 1. 为什么学习string类?2. string类的常用接口2.1 string类对象的常见构造2.1.1 string 2.2 operator[]2.3 迭代器2.4 auto自动推导数据类型2.5 范围for2.6 迭代器第二层2.7 size和length获取字符串的长度2.8 max_size 获取这个字符串能设置的最大长度2.9 …...

二叉树的后序遍历
给你一棵二叉树的根节点 root ,返回其节点值的 后序遍历 。 示例 1: 输入:root [1,null,2,3] 输出:[3,2,1] 解释: 示例 2: 输入:root [1,2,3,4,5,null,8,null,null,6,7,9] 输出…...

Nvidia未来的Blackwell Ultra GPU将更名为B300系列
据TrendForce报道,英伟达(Nvidia)计划将其Blackwell Ultra产品线重新命名为B300系列,以更好地与即将推出的B100和B200产品进行区分。Blackwell Ultra系列将是一个具有更高性能的升级版本。但据报道,这种升级后的内存配…...

BUUCTF靶场Misc练习
在BUUCTF中,你需要留意各种关于涉及 flag{ } 的信息。只要找的到flag,你就算成功。本文记录我刷BUUCTF的Misc类方法和个人感悟。 Misc第一题 签到 题解在题目中,如图所示 flag是 flag{buu_ctf} 第二题 (题目如图所示ÿ…...

ChatGPT、Python和OpenCV支持下的空天地遥感数据识别与计算——从0基础到15个案例实战
从无人机监测农田到卫星数据支持气候研究,空天地遥感数据正以前所未有的方式为科研和商业带来深刻变革。然而,对于许多专业人士而言,如何高效地处理、分析和应用遥感数据仍是一个充满挑战的课题。本教程应运而生,致力于为您搭建一…...

Flume采集Kafka数据到Hive
版本: Kafka:2.4.1 Flume:1.9.0 Hive:3.1.0 Kafka主题准备: Hive表准备:确保hive表为:分区分桶、orc存储、开启事务 Flume准备: 配置flume文件: /opt/datasophon/flume-1…...
)
大语言模型训练与推理模型构建源码解读(huggingface)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、llama训练模型构建源码解读1、模型构建代码(自己搭建)2、训练模型3、模型调用方法4、训练模型init方法(class LlamaForCausalLM(LlamaPreTrainedModel))5、训练模型forward方法(class Llam…...

第三十三篇:TCP协议如何避免/减少网络拥塞,TCP系列八
一、流量控制 一般来说,我们总是希望数据传输得更快一些,但是如果发送方把数据发送得太快,接收方可能来不及接收,造成数据的丢失,数据重发,造成网络资源的浪费甚至网络拥塞。所谓的流量控制(fl…...

并发编程(2)——线程管控
目录 二、day2 1. 线程管控 1.1 归属权转移 1.2 joining_thread 1.2.1 如何使用 joining_thread 1.3 std::jthread 1.3.1 零开销原则 1.3.2 线程停止 1.4 容器管理线程对象 1.4.1 使用容器 1.4.2 如何选择线程运行数量 1.5 线程id 二、day2 今天学习如何管理线程&a…...

【数据仓库】
数据仓库:概念、架构与应用 目录 什么是数据仓库数据仓库的特点数据仓库的架构 3.1 数据源层3.2 数据集成层(ETL)3.3 数据存储层3.4 数据展示与应用层 数据仓库的建模方法 4.1 星型模型4.2 雪花模型4.3 星座模型 数据仓库与数据库的区别数据…...

计算机毕业设计——ssm基于HTML5的互动游戏新闻网站的设计与实现录像演示2021
作者:程序媛9688开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等。 🌟文末获取源码数据库🌟感兴趣的可以先收藏起来,还有大家在毕设选题(免费咨询指导选题)࿰…...

ubuntu上申请Let‘s Encrypt HTTPS 证书
Ubuntu 16.04及以上版本通常自带Snapd,如果你的系统还没有安装,可以通过以下命令安装: 安装Certbot# 使用Snap安装Certbot,确保你获得的是最新版本: bash sudo snap install --classic certbot准备Certbot命令# 确保C…...
解决VMware虚拟机的字体过小问题
前言: (1)先装VMware VMware17Pro虚拟机安装教程(超详细)-CSDN博客 (2)通过清华等镜像网站安装好Ubuntu镜像,下面贴上链接 教程虚拟机配置我没有做,因为学校给了现成的虚拟机~~大家需要的自己…...

java-web-day6-下-知识点小结
JDBC JDBC --是sun公司定义的一套操作所有关系型数据库的规范, 也就是接口api 数据库驱动 --是各个数据库厂家根据JDBC规范的具体实现, 例如mysql的驱动依赖 Lombok 简介 Lombok是一个实用的java类库, 通过注解的方式自动生成构造器, getter/setter, equals, hashcode, toStr…...

Cisco Packet Tracer 8.0 路由器静态路由配置
文章目录 静态路由简介一、定义与特点二、配置与命令三、优点与缺点四、应用场景 一,搭建拓扑图二,配置pc IP地址三,pc0 ping pc1 timeout四,配置路由器Router0五,配置路由器Router1六,测试 静态路由简介 …...

Unity3D学习FPS游戏(3)玩家第一人称视角转动和移动
前言:上一篇实现了角色简单的移动控制,但是实际游戏中玩家的视角是可以转动的,并根据转动后视角调整移动正前方。本篇实现玩家第一人称视角转动和移动,觉得有帮助的话可以点赞收藏支持一下! 玩家第一人称视角 修复小问…...

引领数字未来:通过企业架构推动数字化转型的策略与实践
在全球经济迅速数字化的背景下,企业正面临日益复杂的挑战。为了保持竞争优势,企业必须迅速调整其业务模式,采用先进的技术,推动业务创新。企业架构(EA)作为企业转型的战略工具,在这一过程中发挥…...

计算机毕业设计Python+大模型恶意木马流量检测与分类 恶意流量监测 随机森林模型 深度学习 机器学习 数据可视化 大数据毕业设计 信息安全 网络安全
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! Python大模型恶意木马流量检…...
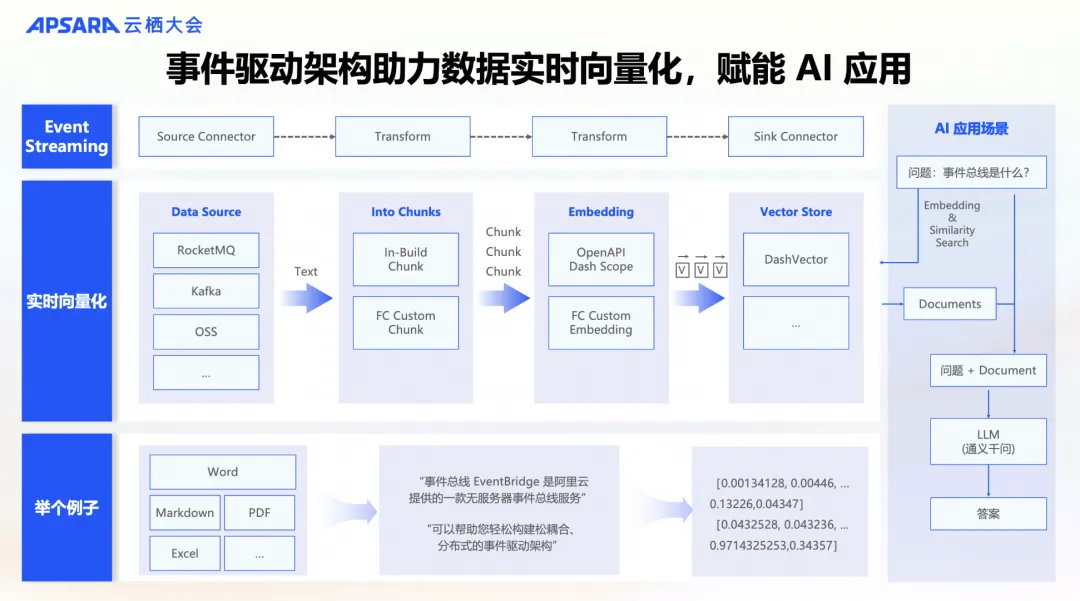
ApsaraMQ Serverless 能力再升级,事件驱动架构赋能 AI 应用
本文整理于 2024 年云栖大会阿里云智能集团高级技术专家金吉祥(牟羽)带来的主题演讲《ApsaraMQ Serverless 能力再升级,事件驱动架构赋能 AI 应用》 云消息队列 ApsaraMQ 全系列产品 Serverless 化,支持按量付费、自适应弹性、跨可…...

Xcode 16.1 (16B40) 发布下载 - Apple 平台 IDE
Xcode 16.1 (16B40) 发布下载 - Apple 平台 IDE IDE for iOS/iPadOS/macOS/watchOS/tvOS/visonOS 发布日期:2024 年 10 月 28 日 Xcode 16.1 包含适用于 iOS 18.1、iPadOS 18.1、Apple tvOS 18.1、watchOS 11.1、macOS Sequoia 15.1 和 visionOS 2.1 的 SDK。Xco…...

浅谈 React Hooks
React Hooks 是 React 16.8 引入的一组 API,用于在函数组件中使用 state 和其他 React 特性(例如生命周期方法、context 等)。Hooks 通过简洁的函数接口,解决了状态与 UI 的高度解耦,通过函数式编程范式实现更灵活 Rea…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...

C++:std::is_convertible
C++标志库中提供is_convertible,可以测试一种类型是否可以转换为另一只类型: template <class From, class To> struct is_convertible; 使用举例: #include <iostream> #include <string>using namespace std;struct A { }; struct B : A { };int main…...

java调用dll出现unsatisfiedLinkError以及JNA和JNI的区别
UnsatisfiedLinkError 在对接硬件设备中,我们会遇到使用 java 调用 dll文件 的情况,此时大概率出现UnsatisfiedLinkError链接错误,原因可能有如下几种 类名错误包名错误方法名参数错误使用 JNI 协议调用,结果 dll 未实现 JNI 协…...

【第二十一章 SDIO接口(SDIO)】
第二十一章 SDIO接口 目录 第二十一章 SDIO接口(SDIO) 1 SDIO 主要功能 2 SDIO 总线拓扑 3 SDIO 功能描述 3.1 SDIO 适配器 3.2 SDIOAHB 接口 4 卡功能描述 4.1 卡识别模式 4.2 卡复位 4.3 操作电压范围确认 4.4 卡识别过程 4.5 写数据块 4.6 读数据块 4.7 数据流…...

P3 QT项目----记事本(3.8)
3.8 记事本项目总结 项目源码 1.main.cpp #include "widget.h" #include <QApplication> int main(int argc, char *argv[]) {QApplication a(argc, argv);Widget w;w.show();return a.exec(); } 2.widget.cpp #include "widget.h" #include &q…...

ServerTrust 并非唯一
NSURLAuthenticationMethodServerTrust 只是 authenticationMethod 的冰山一角 要理解 NSURLAuthenticationMethodServerTrust, 首先要明白它只是 authenticationMethod 的选项之一, 并非唯一 1 先厘清概念 点说明authenticationMethodURLAuthenticationChallenge.protectionS…...

在WSL2的Ubuntu镜像中安装Docker
Docker官网链接: https://docs.docker.com/engine/install/ubuntu/ 1、运行以下命令卸载所有冲突的软件包: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done2、设置Docker…...

Docker 本地安装 mysql 数据库
Docker: Accelerated Container Application Development 下载对应操作系统版本的 docker ;并安装。 基础操作不再赘述。 打开 macOS 终端,开始 docker 安装mysql之旅 第一步 docker search mysql 》〉docker search mysql NAME DE…...

push [特殊字符] present
push 🆚 present 前言present和dismiss特点代码演示 push和pop特点代码演示 前言 在 iOS 开发中,push 和 present 是两种不同的视图控制器切换方式,它们有着显著的区别。 present和dismiss 特点 在当前控制器上方新建视图层级需要手动调用…...