【Redis】
1、Redis 概述
远程字典服务器(Remote Dictionary Server,Redis):一个开源的、高性能的、轻量级、使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,通过提供多种键值数据类型来试音不同场景下的缓存和存储需求,是跨平台的非关系型数据库。
2、Redis 特性
(1)存储结构
Redis 以字典结构存储数据,允许其他应用通过TCP协议读写字典中的内容。同大多数脚本语言中的字典一样,Redis字典中的键值除了可以是字符串,还可以是其他数据类型。到目前为止Redis支持的键值数据类型:STRING(字符串类型)、LIST(列表类型)、SET(集合类型)、HASH(散列类型)、ZSET(有序集合类型)。
(2)内存存储与持久化
Redis数据库中的所有数据都存储在内存中。由于内存的读写速度远快于硬盘,因此Redis在性能上对比其他基于硬盘存储的数据库有非常明显的优势。
将数据存储在内存中也有问题,比如程序退出后内存中的数据会丢失。不过 Redis提供了对持久化的支持,即可以将内存中的数据异步写入到硬盘中,同时不影响继续提供服务。
Redis 持久化方法有两种:第一种持久化方法为时间点转储( point-in-timedump ),转储操作既可以在“指定时间段内有指定数量的写操作执行”这一条件被满足时执行,又可以通过调用两条转储到硬盘( dump-to-disk)命令中的任何一条来执行;第二种持久化方法将所有修改了数据库的命令都写入一个只追加( append-only )文件里面,用户可以根据数据的重要程度,将只追加写人设置为从不同步( sync)、每秒同步一次或者每写入一个命令就同步一次。
(3)主从复制
执行复制的从服务器会连接上主服务器,接收主服务器发送的整个数据库的初始副本( copy );之后主服务器执行的写命令,都会被发送给所有连接着的从服务器去执行,从而实时地更新从服务器的数据集。
因为从服务器包含的数据会不断地进行更新,所以客户端可以向任意一个从服务器发送读请求,以此来避免对主服务器进行集中式的访问。
(4)多数据库
Redis实例提供多个存储数据的字典,客户端可以指定将数据存储在哪个字典中, 可以将字典理解为数据库。Redis默认链接16个数据库,每个数据库对外都是一个从0开始的递增数字命名,可通过databases参数修改连接数,默认选择0号数据库,可通过SELECT命令更换redis > SELECT 1。
Redis 不支持自定义数据库名称,也不支持为每个数据库设置不同的访问密码。Redis 数据库之间并非完全隔离,如使用FLUSHALL 可以清空一个Redis 实例的所有数据。不同的应用应该使用不同的Redis实例里存储数据,同一实例的多个数据库可用于存储同一应用的不同环境的数据。
3、Redis 数据结构
| data type | describe |
|---|---|
| 字符串(String) | 最基本的数据类型,可以包含任何数据,如数字、字符串、二进制数据等。在Redis中,字符串是二进制安全的,这意味着它们可以有任何长度,并且不会因为包含空字符而被截断。 |
| 哈希表(Hash) | 是键值对的集合,是字符串类型的字段和值的映射表。适合存储对象。 |
| 列表(List) | 简单的字符串列表,按照插入顺序排序。可以添加一个元素到头部(左边)或者尾部(右边)。 |
| 集合(Set) | 是字符串类型的无序集合。它是通过哈希表实现,添加、删除、查找的时间复杂度都是O(1)。 |
| 有序集合(Sorted Set) | 和Set相似,但每个字符串元素都会关联一个浮点数类型的分数。元素的分数用来排序,如果两个成员有相同的分数,那么排名按照字典序计算。 |
| HyperLogLog | Redis HyperLogLog 是用来做基数统计的算法,只会根据输入元素来计算基数,而不会储存输入元素本身 |

4、Redis 底层实现
Redis并没有直接使用上述的高级数据结构进行存储,而是根据数据的特性和大小,选择最合适的内部编码方式。
Redis 通过精巧的数据结构和编码方式,实现了高性能的数据存储和操作。其底层实现不仅考虑了内存的使用效率,还充分考虑了数据操作的性能。这使得Redis能够在处理大量数据和并发请求时,依然保持出色的性能表现。对于开发者而言,理解Redis的数据结构和底层实现,有助于更好地使用和优化Redis,从而提升应用的整体性能。
| 数据结构 | 时间复杂度 |
|---|---|
| 哈希表 | O(1) |
| 跳表 | O(logN) |
| 双向链表 | O(N) |
| 压缩列表 | O(N) |
| 整数数组 | O(N) |
4.1 字符串的底层实现:简单动态字符串(SDS)
Redis的字符串类型并不是直接使用C语言中的原生字符串(以空字符\0结尾的字符数组)进行存储,而是使用了一个称为简单动态字符串(Simple Dynamic String,SDS)的数据结构。这种设计选择为Redis带来了许多优势,尤其是在性能和灵活性方面。
(1)SDS结构
SDS的数据结构定义大致如下(可能根据Redis版本有所不同):
struct sdshdr { int len; // 记录buf数组中已使用字节的数量,等于SDS所保存字符串的长度 int free; // 记录buf数组中未使用字节的数量 char buf[]; // 字节数组,用于保存字符串。注意这里并没有指明数组的长度,这是一个柔性数组(flexible array member)
};

(2)优势分析
- 预分配:SDS会为buf分配额外的未使用空间(通过free字段记录),这意味着当向一个SDS字符串追加内容时,如果未使用空间足够,Redis就不需要重新分配内存。这减少了内存分配次数,从而提高了性能。
- 常数时间复杂度获取字符串长度:由于SDS结构内部维护了一个len字段来记录字符串的当前长度,获取字符串长度的操作可以在常数时间复杂度O(1)内完成,而不需要像C语言的原生字符串那样遍历整个字符串。
- 二进制安全:SDS可以存储任意二进制数据,包括空字符\0。C语言的原生字符串以空字符作为结束标志,这限制了它们不能包含空字符。而SDS则通过len字段来明确字符串的长度,因此不受此限制。
- 兼容C语言字符串函数:尽管SDS提供了自己的一套API来进行字符串操作,但它的buf字段实际上就是一个普通的C字符串(以\0结尾),这意味着在必要时,可以直接使用标准的C语言字符串处理函数来操作buf字段(尽管通常不推荐这样做,因为可能会破坏SDS结构的完整性)。
(3)操作优化
SDS提供了一组API来进行字符串的创建、修改、拼接等操作。这些API在内部会处理内存分配、长度更新等细节,使得用户在使用时无需关心底层实现。
例如,当使用sdscat函数向一个SDS字符串追加内容时,该函数会首先检查未使用空间是否足够,如果不够,则会重新分配更大的内存空间,并将原有数据复制到新位置,然后再追加新内容。所有这些操作对用户都是透明的。
小结:通过使用SDS作为字符串的底层实现,Redis实现了字符串操作的高效性和灵活性,为上层提供了丰富的数据操作接口,同时保证了内部数据的一致性和稳定性。这种设计使得Redis在处理大量字符串数据时能够保持出色的性能。
4.2 列表的底层实现:压缩列表和双向链表
(1)压缩列表
当列表的元素数量较少且元素较小时,Redis会使用压缩列表(ziplist)作为底层实现来节省内存。压缩列表是一个紧凑的、连续的内存块,它按顺序存储了列表中的元素。
压缩列表的结构大致如下:
±-------±-------±-------±-----+
| ZLBYTE | LEN | ‘one’ | ‘two’| …
±-------±-------±-------±-----+
- ZLBYTE: 压缩列表的头部信息,包含了特殊编码和压缩列表的长度信息。
- LEN: 每个元素前的长度字段,用于记录该元素的长度或前一个元素到当前元素的偏移量。
- ‘one’, ‘two’: 实际的列表元素,它们被连续地存储在压缩列表中。
使用压缩列表的优势在于:
- 内存利用率高,因为元素是连续存储的,没有额外的指针开销。
- 对于小列表,操作速度可以很快,因为所有数据都在一个连续的内存块中。
操作优化:
Redis的列表实现提供了一组API来进行列表的创建、修改、遍历等操作。这些API在内部会根据列表的大小和元素的特性选择合适的底层数据结构,并且在必要时进行数据结构之间的转换。
例如,当向一个使用压缩列表实现的列表中添加一个新元素时,如果添加后的列表仍然满足压缩列表的使用条件(即元素数量和大小都没有超过预设的阈值),那么Redis会直接在压缩列表的末尾添加新元素。否则,Redis会将压缩列表转换为双向链表,并在链表的尾部添加新元素。
(2)双向链表
当列表的元素数量较多或者元素较大时,Redis会选择使用双向链表作为底层实现。双向链表中的每个节点都保存了前一个节点和后一个节点的指针,这使得在列表的任何位置插入或删除元素都变得相对容易。
双向链表的结构大致如下:
typedef struct listNode { struct listNode *prev; // 指向前一个节点的指针 struct listNode *next; // 指向后一个节点的指针 void *value; // 节点保存的数据
} listNode; typedef struct list { listNode *head; // 指向链表头部的指针 listNode *tail; // 指向链表尾部的指针 unsigned long len; // 链表的长度 // ... 可能还有其他字段,如复制函数、比较函数等
} list;
使用双向链表的优势在于:
- 可以在O(1)时间复杂度内完成在列表头部或尾部的元素插入和删除。
- 当需要遍历列表时,可以从头部或尾部开始,沿着节点的指针依次访问。
通过使用双向链表和压缩列表作为底层实现,Redis的列表数据类型能够在不同的使用场景下提供高效的操作性能。这种灵活的设计使得Redis能够处理各种大小和复杂度的列表数据,同时保持内存的低消耗和操作的快速性。
4.3 哈希的底层实现:压缩列表和字典
Redis的哈希(Hash)类型允许用户在单个键中存储多个字段和对应的值。为了高效地支持这种数据结构,Redis在底层使用了两种主要的数据结构来实现哈希:压缩列表和字典(也称为哈希表)。
(1)压缩列表
当哈希中的字段和值较少且较小时,Redis会使用压缩列表作为底层实现来节省内存。压缩列表是一种紧凑的、连续的内存块,它按顺序存储了哈希中的字段和值对。
压缩列表的结构大致如下:
±-------±-------±-------±-------+
| ZLBYTE | LEN1 | FIELD1 | LEN2 | VALUE2 | …
±-------±-------±-------±-------+
- ZLBYTE:压缩列表的头部信息。
- LEN1、FIELD1:第一个字段的长度和字段本身。
- LEN2、VALUE2:第一个字段对应的值的长度和值本身。
- 以此类推,后续的字段和值对也是按照这个格式存储的。
使用压缩列表的优势在于:
- 内存利用率高,因为字段和值是连续存储的,没有额外的指针和元数据开销。
- 对于小哈希,操作速度可以很快,因为所有数据都在一个连续的内存块中。
操作优化:
-Redis的哈希实现提供了一组API来进行哈希的创建、修改、查找等操作。这些API在内部会根据哈希的大小和字段的特性选择合适的底层数据结构,并且在必要时进行数据结构之间的转换。
例如,当向一个使用压缩列表实现的哈希中添加一个新的字段和值时,如果添加后的哈希仍然满足压缩列表的使用条件(即字段和值的数量和大小都没有超过预设的阈值),那么Redis会直接在压缩列表的末尾添加新的字段和值。否则,Redis会将压缩列表转换为字典,并在字典中插入新的字段和值。
(2)字典(哈希表)
当哈希中的字段和值较多或者较大时,Redis会选择使用字典作为底层实现。字典是一种通过键(在Redis哈希中是字段)来直接访问值的数据结构,它能够在平均情况下提供O(1)时间复杂度的查找、插入和删除操作。

Redis的字典实现通常包含两个哈希表,用于处理哈希表扩容时的数据迁移。每个哈希表节点保存了字段的哈希值、字段本身和对应的值。结构大致如下:
typedef struct dictEntry { void *key; // 字段 union { void *val; uint64_t u64; int64_t s64; // ... 其他可能的值类型 } v; // 值 struct dictEntry *next; // 指向下一个节点的指针,用于解决哈希冲突
} dictEntry; typedef struct dict { dictEntry **table; // 哈希表数组 unsigned long size; // 哈希表大小 unsigned long sizemask; // 用于计算索引的掩码 unsigned long used; // 已使用的节点数量 // ... 可能还有其他字段,如哈希函数、复制函数等
} dict;
使用字典的优势在于:
- 提供了快速的字段查找、插入和删除操作。
- 哈希表的扩容机制可以保持较低的哈希冲突率,从而保证操作的效率。
通过使用字典和压缩列表作为底层实现,Redis的哈希数据类型能够在不同的使用场景下提供高效的操作性能。这种灵活的设计使得Redis能够处理各种大小和复杂度的哈希数据,同时保持内存的低消耗和操作的快速性。
4.4 集合的底层实现:整数集合和字典
Redis的集合(Set)是一个无序的、元素不重复的集合。为了高效地支持这种数据结构及其操作,Redis在底层使用了两种主要的数据结构:整数集合(intset)和字典(hashtable)。
(1)整数集合(intset)
当集合中的元素都是整数,并且元素数量较少时,Redis会选择使用整数集合作为底层实现。整数集合是一个紧凑的数组,数组中的每个元素都是集合中的一个整数。

整数集合的优势在于:
- 内存利用率高:整数集合将整数紧密地存储在一个连续的内存块中,没有额外的指针或元数据开销。
- 操作速度快:对于整数集合中的元素,Redis可以直接通过数组索引访问,这使得查找、添加和删除整数的操作非常快速。 然而,整数集合也有其局限性。由于它要求集合中的元素必须是整数,并且元素数量较少,因此在处理非整数元素或大量元素时,整数集合可能不是最优的选择。
(2)字典(hashtable)
当集合中的元素不满足整数集合的条件(即元素不是整数或元素数量较多)时,Redis会使用字典作为底层实现。字典是一种哈希表,它通过哈希函数将元素的哈希值映射到相应的桶(bucket)中,以支持快速的查找、插入和删除操作。
字典的优势在于:
- 灵活性高:字典可以存储任意类型的元素,而不仅仅是整数。
- 操作效率高:通过哈希函数,字典可以在平均情况下提供O(1)时间复杂度的查找、插入和删除操作。
然而,字典也有一定的开销。每个字典元素都需要额外的空间来存储哈希值、指针等元数据。此外,当哈希表发生哈希冲突时,可能需要通过链表或其他方式解决冲突,这可能会降低操作的效率。
(3)操作优化和转换
Redis的集合实现提供了一组API来进行集合的创建、修改、查找等操作。这些API在内部会根据集合的大小和元素的特性选择合适的底层数据结构,并且在必要时进行数据结构之间的转换。
例如,当向一个使用整数集合实现的集合中添加一个新的整数元素时,如果添加后的集合仍然满足整数集合的使用条件(即元素数量没有超过预设的阈值),那么Redis会直接在整数集合的末尾添加新的元素。否则,Redis会将整数集合转换为字典,并在字典中插入新的元素。
小结:Redis的集合在底层使用了整数集合和字典两种数据结构来实现。整数集合适用于元素较少且都是整数的场景,而字典适用于元素数量较多或元素类型不限的场景。通过这种灵活的设计,Redis能够在不同的使用场景下提供高效的操作性能,同时保持内存的低消耗和操作的快速性。
4.5 有序集合的底层实现:压缩列表和跳表
Redis的有序集合(Sorted Set)是一个有序的、元素不重复的集合,其中每个元素都关联了一个分数(score)。为了实现这种数据结构及其相关操作的高效性,Redis在底层主要使用了两种数据结构:压缩列表(ziplist)和跳表(skiplist)。
(1)跳表(skiplist)
当有序集合的元素数量较多或元素的大小较大时,Redis会使用跳表作为底层实现。跳表是一种多层的有序链表,它通过维护多个层次的指针来加快查找、插入和删除操作的速度。

跳表的优势在于:
- 查找效率高:通过维护多个层次的指针,跳表可以在平均情况下提供O(log N)时间复杂度的查找操作,其中N是元素的数量。
- 插入和删除操作快速:跳表的插入和删除操作只需要局部地调整指针,而不需要移动大量的数据。
- 支持范围查询:跳表可以方便地支持按照分数范围查询元素的操作
然而,跳表也有一定的开销。每个元素在跳表中都有多个指向前驱和后继的指针,这些指针会占用额外的内存空间。

操作优化和转换:
Redis的有序集合实现提供了一组API来进行集合的创建、修改、查找等操作。这些API在内部会根据集合的大小和元素的特性选择合适的底层数据结构,并且在必要时进行数据结构之间的转换。
例如,当向一个使用压缩列表实现的有序集合中添加一个新的元素时,如果添加后的集合仍然满足压缩列表的使用条件(即元素数量没有超过预设的阈值),那么Redis会直接在压缩列表的末尾添加新的元素。否则,Redis会将压缩列表转换为跳表,并在跳表中插入新的元素。
小结:Redis的有序集合在底层使用了压缩列表和跳表两种数据结构来实现。压缩列表适用于元素较少且大小较小的场景,而跳表适用于元素数量较多或元素大小较大的场景。通过这种灵活的设计,Redis能够在不同的使用场景下提供高效的操作性能,同时保持内存的低消耗和操作的快速性。有序集合的实现使得Redis能够支持按照分数排序、范围查询等复杂操作,满足了业务上的多样化需求。
5、Redis 客户端常用命令
5.1 KEY
| command | describe |
|---|---|
| exists(key) | 确认一个key是否存在 |
| del(key) | 删除一个key |
| type(key) | 返回值的类型 |
| keys(pattern) | 返回满足给定pattern的所有key |
| randomkey | 随机返回key空间的一个 |
| keyrename(oldname, newname) | 重命名key |
| dbsize | 返回当前数据库中key的数目 |
| expire | 设定一个key的活动时间(s) |
| ttl | 获得一个key的活动时间 |
| move(key, dbindex) | 移动当前数据库中的key到dbindex数据库 |
| flushdb | 删除当前选择数据库中的所有key |
| flushall | 删除所有数据库中的所有key |
5.2 String
| command | describe |
|---|---|
| set(key, value) | 给数据库中名称为key的string赋予值value |
| get(key) | 返回数据库中名称为key的string的value |
| getset(key, value) | 给名称为key的string赋予上一次的value |
| mget(key1, key2,…, key N) | 返回库中多个string的value |
| setnx(key, value) | 添加string,名称为key,值为value |
| setex(key, time, value) | 向库中添加string,设定过期时间time |
| mset(key N, value N) | 批量设置多个string的值 |
| msetnx(key N, value N) | 如果所有名称为key i的string都不存在 |
| incr(key) | 名称为key的string增1操作 |
| incrby(key, integer) | 名称为key的string增加integer |
| decr(key) | 名称为key的string减1操作 |
| decrby(key, integer) | 名称为key的string减少integer |
| append(key, value) | 名称为key的string的值附加value |
| substr(key, start, end) | 返回名称为key的string的value的子串 |
5.3 List
| command | describe |
|---|---|
| rpush(key, value) | 在名称为key的list尾添加一个值为value的元素 |
| lpush(key, value) | 在名称为key的list头添加一个值为value的 元素 |
| llen(key) | 返回名称为key的list的长度 |
| lrange(key, start, end) | 返回名称为key的list中start至end之间的元素 |
| ltrim(key, start, end) | 截取名称为key的list |
| lindex(key, index) | 返回名称为key的list中index位置的元素 |
| lset(key, index, value) | 给名称为key的list中index位置的元素赋值 |
| lrem(key, count, value) | 删除count个key的list中值为value的元素 |
| lpop(key) | 返回并删除名称为key的list中的首元素 |
| rpop(key) | 返回并删除名称为key的list中的尾元素 |
| blpop(key1, key2,… key N, timeout) | lpop命令的block版本。 |
| brpop(key1, key2,… key N, timeout) | rpop的block版本。 |
| rpoplpush(srckey, dstkey) | 返回并删除名称为srckey的list的尾元素,并将该元素添加到名称为dstkey的list的头部 |
5.4 Set
| command | describe |
|---|---|
| sadd(key, member) | 向名称为key的set中添加元素member |
| srem(key, member) | 删除名称为key的set中的元素member |
| spop(key) | 随机返回并删除名称为key的set中一个元素 |
| smove(srckey, dstkey, member) | 移到集合元素 |
| scard(key) | 返回名称为key的set的基数 |
| sismember(key, member) | member是否是名称为key的set的元素 |
| sinter(key1, key2,…key N) | 求交集 |
| sinterstore(dstkey, (keys)) | 求交集并将交集保存到dstkey的集合 |
| sunion(key1, (keys)) | 求并集 |
| sunionstore(dstkey, (keys)) | 求并集并将并集保存到dstkey的集合 |
| sdiff(key1, (keys)) | 求差集 |
| sdiffstore(dstkey, (keys)) | 求差集并将差集保存到dstkey的集合 |
| smembers(key) | 返回名称为key的set的所有元素 |
| srandmember(key) | 随机返回名称为key的set的一个元素 |
5.5 Hash
| command | describe |
|---|---|
| hset(key, field, value) | 向名称为key的hash中添加元素field |
| hget(key, field) | 返回名称为key的hash中field对应的value |
| hmget(key, (fields)) | 返回名称为key的hash中field i对应的value |
| hmset(key, (fields)) | 向名称为key的hash中添加元素field |
| hincrby(key, field, integer) | 将名称为key的hash中field的value增加integer |
| hexists(key, field) | 名称为key的hash中是否存在键为field的域 |
| hdel(key, field) | 删除名称为key的hash中键为field的域 |
| hlen(key) | 返回名称为key的hash中元素个数 |
| hkeys(key) | 返回名称为key的hash中所有键 |
| hvals(key) | 返回名称为key的hash中所有键对应的value |
| hgetall(key) | 返回名称为key的hash中所有的键(field)及其对应的value |
5.6 HyperLogLog
| command | describe |
|---|---|
| PFADD key element [element …] | 添加指定元素到 HyperLogLog 中。 |
| PFCOUNT key [key …] | 返回给定 HyperLogLog 的基数估算值。 |
| PFMERGE destkey sourcekey [sourcekey …] | 将多个 HyperLogLog 合并为一个 HyperLogLog |
6、Reids 可执行文件
| script | describe |
|---|---|
| redis-server | Redis服务器 |
| redis-cli | Redis命令行客户端 |
| redis-benchmark | Redis性能测试工具 |
| redis-check-aof | AOF文件修补工具 |
| redis-check-dump | RDB文件检查工具 |
| redis-sentinel | Sentinel服务器 |
6.2 redis-cli
(1)连接 Redis 服务器
- 第一种:交互式方式
$redis-cli -h 127.0.0.1 -p 6379 -a redis_password 127.0.0.1:6379>set hello world OK 127.0.0.1:6379>get hello "world" - 第二种方式:命令方式
$redis-cli -h 127.0.0.1 -p 6379 get hello "world"
(2)常用参数
# 命令查询参数
[appuser@localhost app]$ redis-cli -help
redis-cli 6.x.x
Usage: redis-cli [OPTIONS] [cmd [arg [arg ...]]] -h <hostname> Server hostname (default: 127.0.0.1). -p <port> Server port (default: 6379). -s <socket> Server socket (overrides hostname and port). -a <password> Password to use when connecting to the server. -r <repeat> Execute specified command N times. -i <interval> When -r is used, waits <interval> seconds per command. -n <db> Database number. -x Read last argument from STDIN. -d <delimiter> Delimiter to be used by -x when reading from STDIN. --raw Use raw formatting for replies (default when STDOUT is not a tty). --no-raw Force formatted output (default when STDOUT is a tty). --csv Output in CSV format. --scan SCAN command for keys with patterns. --pattern <pat> Pattern to match. --bigkeys Sample random keys to understand memory distribution. --eval <script> Execute Lua script, keys must be passed next to script as args. --latency Sample latency in milliseconds. --latency-history Sample latency with histogram. --latency-dist Sample latency distribution. --slaveof <host:port> Turn the server into a replica of another instance. --cluster <command> Run a cluster command (check, create, fix, reshard, call, etc.). --pipe Read commands from STDIN and send them to the server. --bigkeys-summary Only show summary stats in --bigkeys mode. -v Verbose mode. Warning: use with care as it may show sensitive information. --help Show this help message and exit. --version Show version. Examples: redis-cli ping echo "SET foo bar" | redis-cli redis-cli -r 100 -i 1 info redis-cli --eval myscript.lua key1,key2 , arg1 arg2 arg3 redis-cli --scan --pattern '*'(3)集群客户端命令
- 集群
- cluster info :打印集群的信息
- cluster nodes :列出集群当前已知的所有节点( node),以及这些节点的相关信息。
- 节点
- cluster meet :将 ip 和 port 所指定的节点添加到集群当中,让它成为集群的一份子。
- cluster forget <node_id> :从集群中移除 node_id 指定的节点。
- cluster replicate <node_id> :将当前节点设置为 node_id 指定的节点的从节点。
- cluster saveconfig :将节点的配置文件保存到硬盘里面。
- 槽(slot)
- cluster addslots [slot …] :将一个或多个槽( slot)指派( assign)给当前节点。
- cluster delslots [slot …] :移除一个或多个槽对当前节点的指派。
- cluster flushslots :移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。
- cluster setslot node <node_id> :将槽 slot 指派给 node_id 指定的节点,如果槽已经指派给另一个节点,那么先让另一个节点删除该槽>,然后再进行指派。
- cluster setslot migrating <node_id> :将本节点的槽 slot 迁移到 node_id 指定的节点中。
- cluster setslot importing <node_id> :从 node_id 指定的节点中导入槽 slot 到本节点。
- cluster setslot stable :取消对槽 slot 的导入( import)或者迁移( migrate)。
- 键
- cluster keyslot :计算键 key 应该被放置在哪个槽上。
- cluster countkeysinslot :返回槽 slot 目前包含的键值对数量。
- cluster getkeysinslot :返回 count 个 slot 槽中的键
[appuser@localhost app]$ redis-cli --cluster help
Cluster Manager Commands:create host1:port1 ... hostN:portN #创建集群--cluster-replicas <arg> #从节点个数check host:port #检查集群--cluster-search-multiple-owners #检查是否有槽同时被分配给了多个节点info host:port #查看集群状态fix host:port #修复集群--cluster-search-multiple-owners #修复槽的重复分配问题reshard host:port #指定集群的任意一节点进行迁移slot,重新分slots--cluster-from <arg> #需要从哪些源节点上迁移slot,可从多个源节点完成迁移,以逗号隔开,传递的是节点的node id,还可以直接传递--from all,这样源节点就是集群的所有节点,不传递该参数的话,则会在迁移过程中提示用户输入--cluster-to <arg> #slot需要迁移的目的节点的node id,目的节点只能填写一个,不传递该参数的话,则会在迁移过程中提示用户输入--cluster-slots <arg> #需要迁移的slot数量,不传递该参数的话,则会在迁移过程中提示用户输入。--cluster-yes #指定迁移时的确认输入--cluster-timeout <arg> #设置migrate命令的超时时间--cluster-pipeline <arg> #定义cluster getkeysinslot命令一次取出的key数量,不传的话使用默认值为10--cluster-replace #是否直接replace到目标节点rebalance host:port #指定集群的任意一节点进行平衡集群节点slot数量 --cluster-weight <node1=w1...nodeN=wN> #指定集群节点的权重--cluster-use-empty-masters #设置可以让没有分配slot的主节点参与,默认不允许--cluster-timeout <arg> #设置migrate命令的超时时间--cluster-simulate #模拟rebalance操作,不会真正执行迁移操作--cluster-pipeline <arg> #定义cluster getkeysinslot命令一次取出的key数量,默认值为10--cluster-threshold <arg> #迁移的slot阈值超过threshold,执行rebalance操作--cluster-replace #是否直接replace到目标节点add-node new_host:new_port existing_host:existing_port #添加节点,把新节点加入到指定的集群,默认添加主节点--cluster-slave #新节点作为从节点,默认随机一个主节点--cluster-master-id <arg> #给新节点指定主节点del-node host:port node_id #删除给定的一个节点,成功后关闭该节点服务call host:port command arg arg .. arg #在集群的所有节点执行相关命令set-timeout host:port milliseconds #设置cluster-node-timeoutimport host:port #将外部redis数据导入集群--cluster-from <arg> #将指定实例的数据导入到集群--cluster-copy #migrate时指定copy--cluster-replace #migrate时指定replacehelp For check, fix, reshard, del-node, set-timeout you can specify the host and port of any working node in the cluster.
示例:
- 创建集群主节点
./redis-cli --cluster create host1:port1 host2:port2 host3:port3 - 创建集群主从节点
# 说明:--cluster-replicas 参数为数字,1表示每个主节点需要1个从节点 ./redis-cli --cluster create host1:port1 host2:port2 host3:port3 host4:port4 host5:port5 host6:port6 --cluster-replicas 1 -a 123456 - 添加集群主节点
# 新节点:host1:port1 集群中任意一节点:host2:port2 ./redis-cli --cluster add-node host1:port1 host2:port2 - 添加集群从节点
./redis-cli --cluster add-node host1:port1 host2:port2 --cluster-slave --cluster-master-id master_node_id # 新节点:host1:port1 # 集群中任意一节点:host2:port2 # 指定新节点的主节点的节点ID:master_node_id,不指定将随机分配给某个主节点 - 删除节点
#指定IP、端口和node_id 来删除一个节点,从节点可以直接删除,有slot分配的主节点不能直接删除 ./redis-cli --cluster del-node target_host:target_port target_node_id - 检查集群
# host:port:集群中任意节点 ./redis-cli --cluster check host:port --cluster-search-multiple-owners - 查看集群信息 key、slots、从节点个数的分配情况
./redis-cli --cluster info host:port - 修复集群和槽的重复分配问题
./redis-cli --cluster fix host:port --cluster-search-multiple-owners - 设置集群的超时时间
./redis-cli --cluster set-timeout host:port 10000 - 集群中执行相关命令
# 连接到集群的任意一节点来对整个集群的所有节点进行设置 redis-cli --cluster call 192.168.163.132:6381 config set requirepass cc redis-cli -a cc --cluster call 192.168.163.132:6381 config set masterauth cc redis-cli -a cc --cluster call 192.168.163.132:6381 config rewrite - 集群伸缩:
- 根据提示迁移:
./redis-cli -a cc --cluster reshard host:port - 根据参数迁移
# 连接到集群的任意一节点来对指定节点指定数量的slot进行迁移到指定的节点 ./redis-cli -a cc --cluster reshard host1:port1 --cluster-from node_id1 --cluster-to node_id2 --cluster-slots 10 --cluster-yes --cluster-timeout 5000 --cluster-pipeline 10 --cluster-replace
- 根据提示迁移:
- 平衡(rebalance)slot :
- 平衡集群中各个节点的slot数量
./redis-cli -a cc --cluster rebalance host:port - 根据集群中各个节点设置的权重等平衡slot数量(不执行,只模拟)
./redis-cli -a cc --cluster rebalance --cluster-weight node_id1=5 node_id2=4 node_id3=3 --cluster-simulate host:port
- 平衡集群中各个节点的slot数量
- 导入集群
注意:测试下来发现参数–cluster-replace没有用,如果集群中已经包含了某个key,在导入的时候会失败,不会覆盖,只有清空集群key才能导入。# 外部Redis实例(host2:port2)导入到集群中的任意一节点 ./redis-cli --cluster import host1:port1 --cluster-from host2:port2 --cluster-replace
如果集群设置了密码,也会导入失败,需要设置集群密码为空才能进行导入(call)*** Importing 97847 keys from DB 0 Migrating 9223372011174675807 to 192.168.163.132:6381: Source 192.168.163.132:9021 replied with error: ERR Target instance replied with error: BUSYKEY Target key name already exists
通过monitor(9021)的时候发现,在migrate的时候需要密码进行auth认证。
7、事务
Redis 事务:https://zhuanlan.zhihu.com/p/135241403
Redis watch命令:http://c.biancheng.net/view/4544.html
8、时间空间
Redis 过期时间:https://www.cnblogs.com/xiaoxiongcanguan/p/9937433.html
Redis 限制访问频率:https://blog.csdn.net/weixin_44922018/article/details/100181454
Redis 数据淘汰策略:https://blog.csdn.net/qq_37286668/article/details/110631680
9、排序
https://www.cnblogs.com/-wenli/p/13034628.html
10、消息通知
https://blog.csdn.net/men_wen/article/details/62237970
11、管道
https://www.cnblogs.com/xiaoxiongcanguan/p/9954254.html
12、脚本
Redis在2.6版推出了脚本功能,允许开发者使用Lua语言编写脚本传到Redis中执行,在Lua脚本中可以调用大部分的Redis命令。使用脚本的好处:
-
减少网络开销:使用脚本功能完成的操作只需要发送一个请求即可,减少了网络往返时延。
-
原子操作:Redis会将整个脚本作为一个整体执行,中间不会被其他命令插入。换句话说在编写脚本的过程中无需担心会出现竞态条件,也就无需使用事务。事务可以完成的所有功能都可以用脚本来实现。
-
复用:客户端发送的脚本会永久存储在 Redis 中,这就意味着其他客户端(可以是其他语言开发的项目)可以复用这一脚本而不需要使用代码完成同样的逻辑。
Redis中使用Lua脚本:https://zhuanlan.zhihu.com/p/77484377
Redis Lua脚本入门:https://www.cnblogs.com/felordcn/p/13838321.html
Lua 教程:https://www.w3cschool.cn/lua/
13、持久化
Redis 的强劲性能很大程度上是由于其将所有数据都存储在了内存中,然而当Redis重启后,所有存储在内存中的数据就会丢失。在一些情况下,我们会希望 Redis在重启后能够保证数据不丢失,例如:
- 将Redis 作为数据库使用时。
- 将Redis作为缓存服务器,但缓存被穿透后会对性能造成较大影响,所有缓存同时失效会导致缓存雪崩,从而使服务无法响应。
这时我们希望Redis能将数据从内存中以某种形式同步到硬盘中,使得重启后可以根据硬盘中的记录恢复数据。这一过程就是持久化。
Redis支持两种方式的持久化:
- RDB方式:根据指定的规则“定时”将内存中的数据存储在硬盘上
- AOF 方式:在每次执行命令后将命令本身记录下来。
两种持久化方式可以单独使用其中一种,但更多情况下是将二者结合使用。
Redis 持久化详解:https://blog.csdn.net/qq_45722267/article/details/124525345
14、管理
(1)安全
- 可信的环境
- 数据库密码
- 命令命令
(2)通信协议
- 简单协议
- 统一请求协议
(3)管理工具
- redis-cli
- phpRedisAdmin
- Rdbtools
15、节省时间
(1)精简键名和键值
精简键名和键值是最直观的减少内存占用的方式,如将键名 very.important.person:20改成VIP:20。当然精简键名一定要把握好尺度,不能单纯为了节约空间而使用不易理解的键名(比如将VIP:20修改为V:20,这样既不易维护,还容易造成命名冲突)。又比如一个存储用户性别的字符串类型键的取值是male和 female,我们可以将其修改成m和f来为每条记录节约几个字节的空间(更好的方法是使用0和1来表示性别)。
(2)内部编码优化
https://blog.csdn.net/sinat_33087001/article/details/110387844
16、性能问题
- Master AOF持久化,Master调用BGREWRITEAOF重写AOF文件,AOF在重写的时候会占大量的CPU和内存资源,导致服务load过高,出现短暂服务暂停现象。如果不重写AOF文件,这个持久化方式对性能的影响是最小的,但是AOF文件会不断增大,AOF文件过大会影响Master重启的恢复速度
- Master写内存快照,save命令调度rdbSave函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务,所以Master最好不要写内存快照
- Master最好不要做任何持久化工作,包括内存快照和AOF日志文件,特别是不要启用内存快照做持久化
- 如果数据比较关键,某个Slave开启AOF备份数据,策略为每秒同步一次
- Redis主从复制的性能问题:为了主从复制的速度和连接的稳定性,Master和Slave最好在同一个局域网内
- 尽量避免在压力很大的主库上增加从库
- 主从复制不要用图状结构,用单向链表结构更为稳定,即:Master ⬅ Slave1 ⬅ Slave2 ⬅Slave3 …
这样的结构方便解决单点故障问题,实现Slave对Master的替换。如果Master挂了,可以立刻启用Slave1做Master,其他不变。
17、适合的场景
Redis 适合所有数据in-momory的场景,虽然Redis也提供持久化功能,但实际更多的是一个disk-backed的功能
- 会话缓存(Session Cache)
Redis提供持久化,当维护一个不是严格要求一致性的缓存时,避免用户数据丢失 - 全页缓存(FPC)
即使重启了Redis实例,因为有磁盘的持久化,用户也不会看到页面加载速度的下降,这是一个极大改进 - 队列
Reids 提供 list 和 set 操作,这使得Redis能作为一个很好的消息队列平台来使用 - 排行榜/计数器
Redis在内存中对数字进行递增或递减的操作实现的非常好。集合(Set)和有序集合(Sorted Set)执行这些操作的时候变的非常简单,Redis只是正好提供了这两种数据结构 - 发布/订阅
18、SpringBoot 集成Redis + Redisson
Jedis 作为 Redis客户端的 java版实现实现了绝大部分的Redis原生功能,但是却没有对分布式线程控制做很好的支持。而Redisson是Redis官方推荐的支持分布式操作的Redis Java版客户端,但它却不支持一些基础的Redis原生功能。所以Jedis和Redisson只有整合到一起使用,才能更好的满足用户的需求。
19、集群
(3)Redis-Cluster 投票容错机制
(4)集群扩容
https://cloud.tencent.com/developer/article/1534189
(5)集群缩容
https://blog.csdn.net/JSWANGCHANG/article/details/118724170
(6)卡槽分配
获取与插槽对应的节点:
(7)故障恢复
实践:挂掉(kill)一个主节点(如7002),查看集群状态,再重启集群,查看集群状态
20、参考资料
- Redis数据结构与底层实现
- redis cli 常用命令
- Redis Command
- Redis 教程
- Redis 入门指南 - 李子骅
- redis集群搭建
- redis cluster 搭建实践
- Redis 5.0 redis-cli --cluster help说明
- Redis数据备份与恢复
- Redis 数据备份与恢复(持久化)
- 常用的redis客户端Jedis 、Lettuce 、Redisson 介绍以及对比
- Springboot集成Jedis + Redisson
相关文章:
【Redis】
1、Redis 概述 远程字典服务器(Remote Dictionary Server,Redis):一个开源的、高性能的、轻量级、使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,通过提供多种键值数据类型来试音不同场景下的缓…...

大厂面试真题-MVCC有哪些不好
MVCC(Multi-Version Concurrency Control,多版本并发控制)虽然具有提高数据库并发性能、避免脏读等优势,但也存在一些缺点。以下是对MVCC缺点的详细归纳: 一、存储开销增加 MVCC需要为每个数据行存储多个版本&#x…...

一篇教你多排轮播效果
多排轮播 提示:demo案例 效果看看把 这些都是可以单独左右滑动的 文章目录 多排轮播前言一、上才艺总结 前言 今天想着想着 看着别人这样 哎还挺好看,就自己弄了 提示:以下是本篇文章正文内容,下面案例可供参考 一、上才艺 &…...

安全警告您正在访问危险网站怎么关闭
在上网时,很多人可能遇到过“安全警告:您正在访问危险网站”的提示。这类警告通常由浏览器或安全软件自动弹出,旨在保护用户免受钓鱼网站、恶意软件等潜在安全威胁的侵害。这篇文章将带您了解这种安全警告的来源、关闭提示的步骤以及应采取的…...

群控系统服务端开发模式-应用开发-业务架构逻辑开发第一轮测试
整个系统的第一个层次已经开发完毕,已经有简单的中控,登录、退出、延迟登录时长、黑名单、数据层封装、验证层封装、RSA加解密、Redis等功能,还缺获取个人、角色按钮权限、角色菜单权限功能。角色按钮权限以及角色菜单权限等明后天开发&#…...

git 怎么保留某个文件夹忽略其下面的所有文件?
在 Git 中,如果你想要保留某个文件夹(比如 folder/)但忽略其下面的所有文件,可以使用 .gitignore 文件来实现。需要注意的是,Git 不会自动创建空目录。因此,为了让 Git 记录这个空目录,你需要在…...

Linux Shell 实现一键部署mariadb11.6
mariadb MariaDB数据库管理系统是MySQL的一个分支,主要由开源社区在维护,采用GPL授权许可 MariaDB的目的是完全兼容MySQL,包括API和命令行,使之能轻松成为MySQL的代替品。在存储引擎方面,使用XtraDB来代替MySQL的InnoDB。 MariaDB由MySQL的创始人Michael Widenius主导开发…...

Servlet 3.0 注解开发
文章目录 Servlet3.0注解开发修改idea创建注解的servlet模板内容讲解 关于servlet3.0注解开发的疑问_配置路径省略了属性urlPatterns内容讲解内容小结 Servlet3.0注解开发 【1】问题 说明:之前我们都是使用web.xml进行servlet映射路径的配置。这样配置的弊端&…...

rom定制系列------红米note8_miui14安卓13定制修改固件 带面具root权限 刷写以及界面预览
💝💝💝红米note8机型代码:ginkgo。高通芯片。此固件官方最终版为稳定版12.5.5安卓11的版本。目前很多工作室需要高安卓版本的固件来适应他们的软件。并且需要root权限。根据客户要求。修改固件为完全root。并且修改为可批量刷写的…...

Kaspa钱包ts代码封装
文章目录 1. 配置wasm2. 钱包地址创建3. KAS转账&余额查询4. KRC-20 处理5. 使用demo 1. 配置wasm 下载wasm地址:https://kaspa.aspectron.org/nightly/downloads/ 在项目根目录下添加wasm目录, 将下载的wasm文件中web目录下kaspa和kaspa-dev文件家…...

MySQL 数据库中 MyISAM 和 InnoDB 的区别:深入解析
MySQL 是目前最流行的开源数据库管理系统之一,支持多种存储引擎,其中最常用的就是 MyISAM 和 InnoDB。这两种存储引擎各有其特点,适用于不同的使用场景。理解它们之间的区别有助于数据库开发者和管理者根据应用需求选择合适的存储引擎。本文将…...

python中怎样实现闭包?
在Python中,闭包是指一个函数可以访问其自身范围之外的变量,即可以访问其外部函数作用域中的变量。要实现一个闭包,可以按照以下步骤进行: 内部函数引用外部函数的变量:在外部函数中定义一个内部函数,并在…...

论文阅读:MultiUI 利用网页UI进行丰富文本的视觉理解
《HARNESSING WEBPAGE UIS FOR TEXT-RICH VISUAL UNDERSTANDING》 利用网页UI进行丰富文本的视觉理解 总结 grounding和QA部分的数据集占比较大、同时消融实验显示其作用相对较大,并且grounding部分作用和效果呈现scaling正相关提供了很多web数据处理成多模态训练…...

【云原生】云原生后端详解:架构与实践
目录 引言一、云原生后端的核心概念1.1 微服务架构1.2 容器化1.3 可编排性1.4 弹性和可伸缩性 二、云原生后端的架构示意图三、云原生后端的最佳实践3.1 使用服务网格3.2 监控与日志管理3.3 CI/CD 流水线3.4 安全性 总结参考资料 引言 随着云计算的迅猛发展,云原生…...

MySQL覆盖索引
覆盖索引(Covering Index)是数据库优化中的一种重要技术 覆盖索引是指一个查询语句在执行时,所需的数据可以完全通过索引来获取,而无需访问实际的数据行。也就是说,查询语句所需的列都包含在了创建的索引中,…...

「C/C++」C/C++ 之 循环结构详解
✨博客主页何曾参静谧的博客📌文章专栏「C/C」C/C程序设计📚全部专栏「VS」Visual Studio「C/C」C/C程序设计「UG/NX」BlockUI集合「Win」Windows程序设计「DSA」数据结构与算法「UG/NX」NX二次开发「QT」QT5程序设计「File」数据文件格式「PK」Parasoli…...

json-server的基本使用
一、json-server工具的使用 可以快速的搭建符合RESTful API服务。返回符合RESTful规范的数据; 1、全局引入json-server包 npm install -g json-server2、创建json格式的db.json文件 {"jsonData": [{"name": "小明"}] }3、在json文…...

华为配置BFD状态与接口状态联动实验
组网图形 图1 配置BFD状态与接口状态联动组网图 BFD简介配置注意事项组网需求配置思路操作步骤配置文件 BFD简介 为了减小设备故障对业务的影响,提高网络的可靠性,网络设备需要能够尽快检测到与相邻设备间的通信故障,以便及时采取措施&…...

计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-10-22
计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-10-22 目录 文章目录 计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-10-22目录1. PoisonedRAG: Knowledge corruption attacks to retrieval-augmented generation of large language models摘要创新点…...

理解消息队列
消息队列(Message Queue)有下面四大作用: 解耦。几个业务系统之间可以通过 MQ 解耦,例如做数据同步数据的顺序性和可恢复性异步通讯缓冲能力 理解 MQ MQ 的前两个特点且不说,我们看看另外两个的。 异步通讯&#x…...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

【HarmonyOS 5.0】DevEco Testing:鸿蒙应用质量保障的终极武器
——全方位测试解决方案与代码实战 一、工具定位与核心能力 DevEco Testing是HarmonyOS官方推出的一体化测试平台,覆盖应用全生命周期测试需求,主要提供五大核心能力: 测试类型检测目标关键指标功能体验基…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

工程地质软件市场:发展现状、趋势与策略建议
一、引言 在工程建设领域,准确把握地质条件是确保项目顺利推进和安全运营的关键。工程地质软件作为处理、分析、模拟和展示工程地质数据的重要工具,正发挥着日益重要的作用。它凭借强大的数据处理能力、三维建模功能、空间分析工具和可视化展示手段&…...

OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别
OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别 直接训练提示词嵌入向量的核心区别 您提到的代码: prompt_embedding = initial_embedding.clone().requires_grad_(True) optimizer = torch.optim.Adam([prompt_embedding...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...

Bean 作用域有哪些?如何答出技术深度?
导语: Spring 面试绕不开 Bean 的作用域问题,这是面试官考察候选人对 Spring 框架理解深度的常见方式。本文将围绕“Spring 中的 Bean 作用域”展开,结合典型面试题及实战场景,帮你厘清重点,打破模板式回答,…...
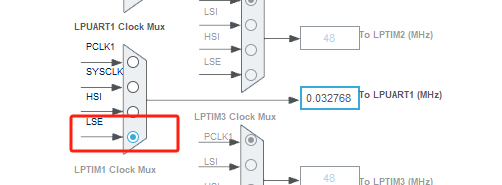
stm32wle5 lpuart DMA数据不接收
配置波特率9600时,需要使用外部低速晶振...

如何配置一个sql server使得其它用户可以通过excel odbc获取数据
要让其他用户通过 Excel 使用 ODBC 连接到 SQL Server 获取数据,你需要完成以下配置步骤: ✅ 一、在 SQL Server 端配置(服务器设置) 1. 启用 TCP/IP 协议 打开 “SQL Server 配置管理器”。导航到:SQL Server 网络配…...
ZYNQ学习记录FPGA(一)ZYNQ简介
一、知识准备 1.一些术语,缩写和概念: 1)ZYNQ全称:ZYNQ7000 All Pgrammable SoC 2)SoC:system on chips(片上系统),对比集成电路的SoB(system on board) 3)ARM:处理器…...