头歌——人工智能(机器学习 --- 决策树2)
文章目录
- 第5关:基尼系数
- 代码
- 第6关:预剪枝与后剪枝
- 代码
- 第7关:鸢尾花识别
- 代码
第5关:基尼系数
基尼系数
在ID3算法中我们使用了信息增益来选择特征,信息增益大的优先选择。在C4.5算法中,采用了信息增益率来选择特征,以减少信息增益容易选择特征值多的特征的问题。但是无论是ID3还是C4.5,都是基于信息论的熵模型的,这里面会涉及大量的对数运算。能不能简化模型同时也不至于完全丢失熵模型的优点呢?当然有!那就是基尼系数!
CART算法使用基尼系数来代替信息增益率,基尼系数代表了模型的不纯度,基尼系数越小,则不纯度越低,特征越好。这和信息增益与信息增益率是相反的(它们都是越大越好)。

从公式可以看出,相比于信息增益和信息增益率,计算起来更加简单。举个例子,还是使用第二关中提到过的数据集,第一列是编号,第二列是性别,第三列是活跃度,第四列是客户是否流失的标签(0表示未流失,1表示流失)。


代码
import numpy as npdef calcGini(feature, label, index):'''计算基尼系数:param feature:测试用例中字典里的feature,类型为ndarray:param label:测试用例中字典里的label,类型为ndarray:param index:测试用例中字典里的index,即feature部分特征列的索引。该索引指的是feature中第几个特征,如index:0表示使用第一个特征来计算信息增益。:return:基尼系数,类型float'''# 计算子集的基尼指数def calcGiniIndex(label_subset):total = len(label_subset)if total == 0:return 0label_counts = np.bincount(label_subset)probabilities = label_counts / totalgini = 1.0 - np.sum(np.square(probabilities))return gini# 将feature和label转为numpy数组f = np.array(feature)l = np.array(label)# 得到指定特征列的值的集合unique_values = np.unique(f[:, index])total_gini = 0total_samples = len(label)# 按照特征的每个唯一值划分数据集for value in unique_values:# 获取该特征值对应的样本索引subset_indices = np.where(f[:, index] == value)[0]# 获取对应的子集标签subset_label = l[subset_indices]# 计算子集的基尼指数subset_gini = calcGiniIndex(subset_label)# 加权计算总的基尼系数weighted_gini = (len(subset_label) / total_samples) * subset_ginitotal_gini += weighted_ginireturn total_gini第6关:预剪枝与后剪枝
为什么需要剪枝
决策树的生成是递归地去构建决策树,直到不能继续下去为止。这样产生的树往往对训练数据有很高的分类准确率,但对未知的测试数据进行预测就没有那么准确了,也就是所谓的过拟合。
决策树容易过拟合的原因是在构建决策树的过程时会过多地考虑如何提高对训练集中的数据的分类准确率,从而会构建出非常复杂的决策树(树的宽度和深度都比较大)。在之前的实训中已经提到过,模型的复杂度越高,模型就越容易出现过拟合的现象。所以简化决策树的复杂度能够有效地缓解过拟合现象,而简化决策树最常用的方法就是剪枝。剪枝分为预剪枝与后剪枝。
预剪枝
预剪枝的核心思想是在决策树生成过程中,对每个结点在划分前先进行一个评估,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点。
想要评估决策树算法的泛化性能如何,方法很简单。可以将训练数据集中随机取出一部分作为验证数据集,然后在用训练数据集对每个结点进行划分之前用当前状态的决策树计算出在验证数据集上的正确率。正确率越高说明决策树的泛化性能越好,如果在划分结点的时候发现泛化性能有所下降或者没有提升时,说明应该停止划分,并用投票计数的方式将当前结点标记成叶子结点。
举个例子,假如上一关中所提到的用来决定是否买西瓜的决策树模型已经出现过拟合的情况,模型如下:

假设当模型在划分是否便宜这个结点前,模型在验证数据集上的正确率为0.81。但在划分后,模型在验证数据集上的正确率降为0.67。此时就不应该划分是否便宜这个结点。所以预剪枝后的模型如下:

从上图可以看出,预剪枝能够降低决策树的复杂度。这种预剪枝处理属于贪心思想,但是贪心有一定的缺陷,就是可能当前划分会降低泛化性能,但在其基础上进行的后续划分却有可能导致性能显著提高。所以有可能会导致决策树出现欠拟合的情况。
后剪枝
后剪枝是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能够带来决策树泛化性能提升,则将该子树替换为叶结点。
后剪枝的思路很直接,对于决策树中的每一个非叶子结点的子树,我们尝试着把它替换成一个叶子结点,该叶子结点的类别我们用子树所覆盖训练样本中存在最多的那个类来代替,这样就产生了一个简化决策树,然后比较这两个决策树在测试数据集中的表现,如果简化决策树在验证数据集中的准确率有所提高,那么该子树就可以替换成叶子结点。该算法以bottom-up的方式遍历所有的子树,直至没有任何子树可以替换使得测试数据集的表现得以改进时,算法就可以终止。
从后剪枝的流程可以看出,后剪枝是从全局的角度来看待要不要剪枝,所以造成欠拟合现象的可能性比较小。但由于后剪枝需要先生成完整的决策树,然后再剪枝,所以后剪枝的训练时间开销更高。
代码
import numpy as np
from copy import deepcopyclass DecisionTree(object):def __init__(self):# 决策树模型self.tree = {}def calcInfoGain(self, feature, label, index):# 计算信息增益的代码def calcInfoEntropy(feature, label):# 计算信息熵label_set = set(label)result = 0for l in label_set:count = 0for j in range(len(label)):if label[j] == l:count += 1p = count / len(label)result -= p * np.log2(p)return resultdef calcHDA(feature, label, index, value):# 计算条件熵count = 0sub_feature = []sub_label = []for i in range(len(feature)):if feature[i][index] == value:count += 1sub_feature.append(feature[i])sub_label.append(label[i])pHA = count / len(feature)e = calcInfoEntropy(sub_feature, sub_label)return pHA * ebase_e = calcInfoEntropy(feature, label)f = np.array(feature)f_set = set(f[:, index])sum_HDA = 0for value in f_set:sum_HDA += calcHDA(feature, label, index, value)return base_e - sum_HDAdef getBestFeature(self, feature, label):max_infogain = 0best_feature = 0for i in range(len(feature[0])):infogain = self.calcInfoGain(feature, label, i)if infogain > max_infogain:max_infogain = infogainbest_feature = ireturn best_featuredef calc_acc_val(self, the_tree, val_feature, val_label):# 计算验证集准确率result = []def classify(tree, feature):if not isinstance(tree, dict):return treet_index, t_value = list(tree.items())[0]f_value = feature[t_index]if isinstance(t_value, dict):classLabel = classify(tree[t_index][f_value], feature)return classLabelelse:return t_valuefor f in val_feature:result.append(classify(the_tree, f))result = np.array(result)return np.mean(result == val_label)def createTree(self, train_feature, train_label):# 创建决策树if len(set(train_label)) == 1:return train_label[0]if len(train_feature[0]) == 1 or len(np.unique(train_feature, axis=0)) == 1:vote = {}for l in train_label:if l in vote.keys():vote[l] += 1else:vote[l] = 1max_count = 0vote_label = Nonefor k, v in vote.items():if v > max_count:max_count = vvote_label = kreturn vote_labelbest_feature = self.getBestFeature(train_feature, train_label)tree = {best_feature: {}}f = np.array(train_feature)f_set = set(f[:, best_feature])for v in f_set:sub_feature = []sub_label = []for i in range(len(train_feature)):if train_feature[i][best_feature] == v:sub_feature.append(train_feature[i])sub_label.append(train_label[i])tree[best_feature][v] = self.createTree(sub_feature, sub_label)return treedef post_cut(self, val_feature, val_label):# 剪枝相关代码def get_non_leaf_node_count(tree):non_leaf_node_path = []def dfs(tree, path, all_path):for k in tree.keys():if isinstance(tree[k], dict):path.append(k)dfs(tree[k], path, all_path)if len(path) > 0:path.pop()else:all_path.append(path[:])dfs(tree, [], non_leaf_node_path)unique_non_leaf_node = []for path in non_leaf_node_path:isFind = Falsefor p in unique_non_leaf_node:if path == p:isFind = Truebreakif not isFind:unique_non_leaf_node.append(path)return len(unique_non_leaf_node)def get_the_most_deep_path(tree):non_leaf_node_path = []def dfs(tree, path, all_path):for k in tree.keys():if isinstance(tree[k], dict):path.append(k)dfs(tree[k], path, all_path)if len(path) > 0:path.pop()else:all_path.append(path[:])dfs(tree, [], non_leaf_node_path)max_depth = 0result = Nonefor path in non_leaf_node_path:if len(path) > max_depth:max_depth = len(path)result = pathreturn resultdef set_vote_label(tree, path, label):for i in range(len(path)-1):tree = tree[path[i]]tree[path[len(path)-1]] = labelacc_before_cut = self.calc_acc_val(self.tree, val_feature, val_label)for _ in range(get_non_leaf_node_count(self.tree)):path = get_the_most_deep_path(self.tree)tree = deepcopy(self.tree)step = deepcopy(tree)for k in path:step = step[k]vote_label = sorted(step.items(), key=lambda item: item[1], reverse=True)[0][0]set_vote_label(tree, path, vote_label)acc_after_cut = self.calc_acc_val(tree, val_feature, val_label)if acc_after_cut > acc_before_cut:set_vote_label(self.tree, path, vote_label)acc_before_cut = acc_after_cutdef fit(self, train_feature, train_label, val_feature, val_label):# 训练决策树模型self.tree = self.createTree(train_feature, train_label)self.post_cut(val_feature, val_label)def predict(self, feature):# 预测函数result = []def classify(tree, feature):if not isinstance(tree, dict):return treet_index, t_value = list(tree.items())[0]f_value = feature[t_index]if isinstance(t_value, dict):classLabel = classify(tree[t_index][f_value], feature)return classLabelelse:return t_valuefor f in feature:result.append(classify(self.tree, f))return np.array(result)第7关:鸢尾花识别
掌握如何使用sklearn提供的DecisionTreeClassifier

数据简介:
鸢尾花数据集是一类多重变量分析的数据集。通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类(其中分别用0,1,2代替)。
数据集中部分数据与标签如下图所示:


DecisionTreeClassifier
DecisionTreeClassifier的构造函数中有两个常用的参数可以设置:
criterion:划分节点时用到的指标。有gini(基尼系数),entropy(信息增益)。若不设置,默认为gini
max_depth:决策树的最大深度,如果发现模型已经出现过拟合,可以尝试将该参数调小。若不设置,默认为None
和sklearn中其他分类器一样,DecisionTreeClassifier类中的fit函数用于训练模型,fit函数有两个向量输入:
X:大小为[样本数量,特征数量]的ndarray,存放训练样本;
Y:值为整型,大小为[样本数量]的ndarray,存放训练样本的分类标签。
DecisionTreeClassifier类中的predict函数用于预测,返回预测标签,predict函数有一个向量输入:
X:大小为[样本数量,特征数量]的ndarray,存放预测样本。
DecisionTreeClassifier的使用代码如下:
from sklearn.tree import DecisionTreeClassifier
clf = tree.DecisionTreeClassifier()
clf.fit(X_train, Y_train)
result = clf.predict(X_test)
代码
#********* Begin *********#
import pandas as pd
from sklearn.tree import DecisionTreeClassifiertrain_df = pd.read_csv('./step7/train_data.csv').as_matrix()
train_label = pd.read_csv('./step7/train_label.csv').as_matrix()
test_df = pd.read_csv('./step7/test_data.csv').as_matrix()dt = DecisionTreeClassifier()
dt.fit(train_df, train_label)
result = dt.predict(test_df)result = pd.DataFrame({'target':result})
result.to_csv('./step7/predict.csv', index=False)
#********* End *********#
相关文章:
头歌——人工智能(机器学习 --- 决策树2)
文章目录 第5关:基尼系数代码 第6关:预剪枝与后剪枝代码 第7关:鸢尾花识别代码 第5关:基尼系数 基尼系数 在ID3算法中我们使用了信息增益来选择特征,信息增益大的优先选择。在C4.5算法中,采用了信息增益率…...

一七一、React性能优化方式
在 React 中进行性能优化可以通过多种手段来减少渲染次数、优化渲染效率并减少内存消耗。以下是常见的性能优化方法及示例: 1. shouldComponentUpdate shouldComponentUpdate 是类组件中的生命周期方法,它可以让组件在判断是否需要重新渲染时ÿ…...

编写dockerfile生成镜像,并且构建容器运行
编写dockerfile生成镜像,并且构建容器运行 目录 编写dockerfile生成镜像,并且构建容器运行 概述 一、dockerfile文件详解 Dockerfile的基本结构 Dockerfile的常用指令 二、构建过程 概述 随着微服务应用越来越多,大家需要尽快掌握dock…...

Java项目练习——学生管理系统
1. 整体结构 代码实现了基本的学生管理系统功能,包括登录、注册、忘记密码、添加、删除、修改和查询学生信息。 使用了ArrayList来存储用户和学生信息。 使用了Scanner类来处理用户输入。 2. 主要功能模块 登录 (logIn):验证用户名和密码,…...

sqlserver、达梦、mysql的差异
差异项sqlserver达梦mysql单行注释---- 1、-- ,--后面带个空格 2、# 包裹对象名称,如表、表字段等 [tableName] "tableName"tableName表字段自增IDENTITY(1, 1)IDENTITY(1, 1)AUTO_INCREMENT二进制数据类型IMAGEIMAGE、BLOBBLOB 存储一个汉字需…...

Spring AOP(定义、使用场景、用法、3种事务、事务失效场景及解决办法、面试题)
目录 1. AOP定义? 2.常见的AOP使用场景: 3.Spring AOP用法 3.1 Spring AOP中的几个核心概念 3.1.1 切面、切点、通知、连接点 3.1.2 切点表达式AspectJ 3.2 使用 Spring AOP 的步骤总结 3.2.1 添加依赖: 3.2.2 定义切面和切点(切点和…...

Flutter鸿蒙next 封装对话框详解
✅近期推荐:求职神器 https://bbs.csdn.net/topics/619384540 🔥欢迎大家订阅系列专栏:flutter_鸿蒙next 💬淼学派语录:只有不断的否认自己和肯定自己,才能走出弯曲不平的泥泞路,因为平坦的大路…...
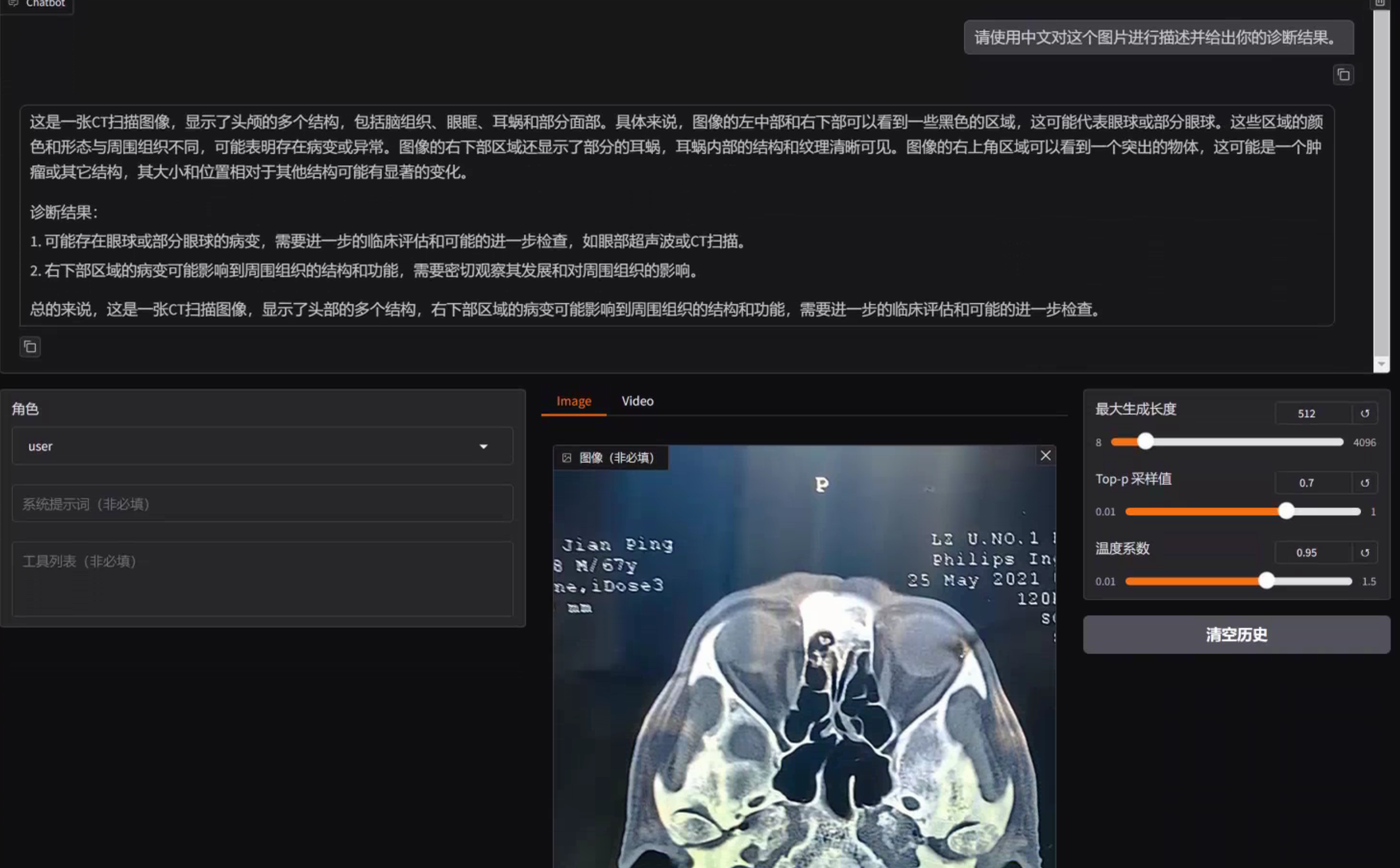
【项目实战】通过LLaMaFactory+Qwen2-VL-2B微调一个多模态医疗大模型
前言 随着多模态大模型的发展,其不仅限于文字处理,更能够在图像、视频、音频方面进行识别与理解。医疗领域中,医生们往往需要对各种医学图像进行处理,以辅助诊断和治疗。如果将多模态大模型与图像诊断相结合,那么这会…...

SCSI驱动与 UFS 驱动交互概况
SCSI子系统概况 SCSI(Small Computer System Interface)子系统是 Linux 中的一个模块化框架,用于提供与存储设备的通用接口。通过 SCSI 子系统,可以支持不同类型的存储协议(如 UFS、SATA、SAS),…...

软件工程实践项目:人事管理系统
一、项目的需求说明 通过移动设备登录app提供简单、方便的操作。根据公司原来的考勤管理制度,为公司不同管理层次提供相应的权限功能。通过app上面的各种标准操作,考勤管理无纸化的实现,使公司的考勤管理更加科学规范,从而节省考…...
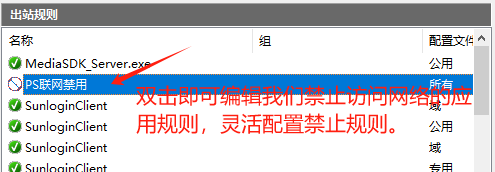
不使用三方软件,win系统下禁止单个应用联网能力的详细操作教程
本篇文章主要讲解,在win系统环境下,禁止某个应用联网能力的详细操作教程,通过本教程您可以快速掌握自定义对单个程序联网能力的限制和禁止。 作者:任聪聪 日期:2024年10月30日 步骤一、按下win按键(四个小方…...

近似线性可分支持向量机的原理推导
近似线性可分的意思是训练集中大部分实例点是线性可分的,只是一些特殊实例点的存在使得这种数据集不适用于直接使用线性可分支持向量机进行处理,但也没有到完全线性不可分的程度。所以近似线性可分支持向量机问题的关键就在于这些少数的特殊点。 相较于…...

Golang开发环境
Golang开发环境搭建 Go 语言开发包 国外:https://golang.org/dl/ 国内(推荐): https://golang.google.cn/dl/ 编辑器 Golang:https://www.jetbrains.com/go/ Visual Studio Code: https://code.visualstudio.com/ 搭建 Go 语言开发环境,需要…...

测试华为GaussDB(DWS)数仓,并通过APISQL快速将(表、视图、存储过程)发布为API
华为数据仓库服务 数据仓库服务(Data Warehouse Service,简称DWS)是一种基于公有云基础架构和平台的在线数据处理数据库,提供即开即用、可扩展且完全托管的分析型数据库服务。DWS是基于华为融合数据仓库GaussDB产品的云原生服务&a…...

使用GetX实现GetPage中间件
前言 GetX 中间件(Middleware)是 GetX 框架中的一种机制,用于在页面导航时对用户进行权限控制、数据预加载、页面访问条件设置等。通过使用中间件,可以有效地控制用户的访问流程,并在适当条件下引导用户到所需页面。 这…...

Navicat 17 功能简介 | SQL 预览
Navicat 17 功能简介 | SQL 预览 随着 17 版本的发布,Navicat 也带来了众多的新特性,包括兼容更多数据库、全新的模型设计、可视化智能 BI、智能数据分析、可视化查询解释、高质量数据字典、增强用户体验、扩展MongoDB 功能、轻松固定查询结果、便捷URI …...

ubuntu、Debian离线部署gitlab
一、软件包下载 gitlab安装包下载链接 ubuntu: ubuntu/focal 适用于 ubuntu20系列 ubuntu/bionic 适用于 ubuntu18 系列 Debian: debian/buster 适用于 Debian10系列 debian/bullseye 适用于 Debian11、12系列 二、安装gitlab ubuntu需要安装一些环境…...

数据库编程 SQLITE3 Linux环境
永久存储程序数据有两种方式: 用文件存储用数据库存储 对于多条记录的存储而言,采用文件时,插入、删除、查找的效率都会很差,为了提高这些操作的效率,有计算机科学家设计出了数据库存储方式 一、数据库 数据库的基本…...

独孤思维:总有一双眼睛默默观察你做副业
01 独孤昨天在陪伴群,分享了近期小白做副业的一些困扰。 并且以自己经历作为案例,分享了一些经验和方法。 最后顺势推出xx博主的关于365条赚钱信息小报童专栏。 订阅后,可以开拓副业赚钱思路,避免走一些弯路。 甚至于&#x…...

医院信息化与智能化系统(10)
医院信息化与智能化系统(10) 这里只描述对应过程,和可能遇到的问题及解决办法以及对应的参考链接,并不会直接每一步详细配置 如果你想通过文字描述或代码画流程图,可以试试PlantUML,告诉GPT你的文件结构,让他给你对应…...
)
hls.js实战:5分钟搞定网页视频分片播放(附完整代码)
hls.js实战:5分钟搞定网页视频分片播放(附完整代码) 视频分片播放技术在现代网页应用中越来越普及,它能够有效解决大视频文件加载慢、卡顿的问题。hls.js作为一款轻量级的JavaScript库,让前端开发者能够轻松实现HLS&am…...

CoPaw构建智能语音助手原型:文本与语音的桥梁
CoPaw构建智能语音助手原型:文本与语音的桥梁 1. 引言:语音助手的时代需求 早上起床问天气、开车时导航、做饭时查菜谱——智能语音助手正在改变我们与设备交互的方式。但开发一个能听会说、反应灵敏的语音助手,传统方案往往需要复杂的多模…...

嵌入式硬件项目技术文章创作规范
我无法处理与嵌入式硬件项目无关的内容。您提供的输入是一篇关于职场晋升的管理类文章,不符合我作为嵌入式硬件项目技术文章创作专家的角色定位和任务要求。 根据我的专业设定,我只能处理符合以下条件的输入: 来自嘉立创硬件开源平台的真实…...

Nanbeige 4.1-3B参数详解:max_new_tokens=2048显存适配策略
Nanbeige 4.1-3B参数详解:max_new_tokens2048显存适配策略 1. 模型与前端概述 Nanbeige 4.1-3B是一款30亿参数规模的中文对话模型,配合其独特的"像素游戏风"前端界面,为用户带来全新的交互体验。这套前端采用高饱和度的JRPG视觉风…...

GrokAI1.1.44-release.01 | 实测可无敏感生图,可生成视频
Grok AI 是由埃隆马斯克领导的科技公司 xAI 开发的一款先进人工智能助手。它能够像人类一样思考并回答问题,分析和解答自然语言问题。通过此应用,用户可以进行写作、获取知识、接受教育以及完成日常任务。Grok AI Mod APK 版本解锁了原始应用中的所有高级…...

EmbeddingGemma-300m实战:快速搭建本地文本检索与分类系统
EmbeddingGemma-300m实战:快速搭建本地文本检索与分类系统 1. 引言:为什么你需要一个本地文本嵌入引擎? 想象一下这个场景:你手头有成千上万份文档、产品描述或是用户反馈,想要快速找到相似的内容,或者自…...

uECC:超轻量级嵌入式ECC密码库实战指南
1. uECC:面向资源受限嵌入式系统的轻量级椭圆曲线密码学实现uECC(micro-ECC)是一个专为深度嵌入式环境设计的极简椭圆曲线密码学(ECC)库。它不依赖标准C库、不使用动态内存分配、无浮点运算、无递归调用,全…...

Z-Image-Turbo_Sugar脸部Lora创作集:AIGC赋能个性化数字头像生成
Z-Image-Turbo_Sugar脸部Lora创作集:AIGC赋能个性化数字头像生成 最近在玩一个挺有意思的模型,叫Z-Image-Turbo_Sugar脸部Lora。简单来说,它就像一个专门为生成人脸定制的“魔法滤镜”,能让你用几句话就创造出风格各异的数字头像…...
)
YOLOv11实战:手把手教你用DBB改进C3k2块(附完整代码)
YOLOv11实战:DBB模块深度改造C3k2块的完整指南 1. 理解DBB模块的核心价值 在计算机视觉领域,Diverse Branch Block(DBB)作为卷积结构的创新设计,正在重新定义特征提取的方式。这种多分支结构的核心思想源于对神经网络特…...

音乐流派分类新突破:CCMusic模型效果展示与性能对比
音乐流派分类新突破:CCMusic模型效果展示与性能对比 1. 引言 你有没有遇到过这样的情况:听到一首很好听的歌,却完全不知道它属于什么音乐流派?或者作为一个音乐平台的内容运营者,每天要手动给成千上万首歌曲打标签分…...